An Algorithm for Surface Defect Identification of Steel Plates Based on Genetic Algorithm and Extreme Learning Machine



Abstract
:1. Introduction
2. ELM and Genetic Algorithm
2.1. ELM Algorithm
2.2. Genetic Algorithm
3. G-ELM
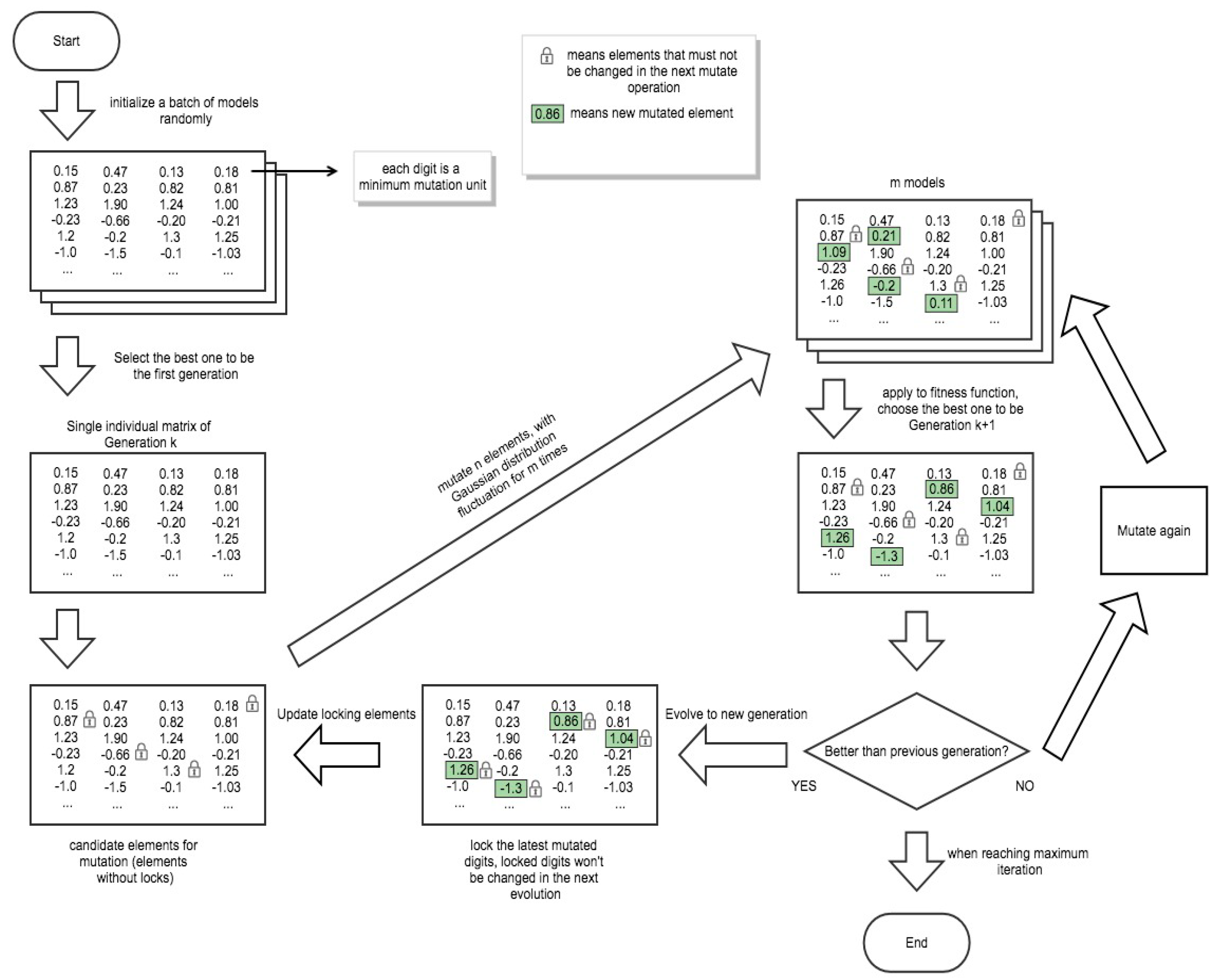
3.1. The G-ELM Procedure
3.2. Mutation Operation Rules
4. Surface Inspection and Defects of Hot Rolled Steel Plates
4.1. Surface Inspection of Hot Rolled Steel Plates
4.2. Surface Defects of Steel Plates
5. Experiments
5.1. Comparison between ELM and G-ELM
5.2. Analysis of the Perfomance of G-ELM
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Xu, K.; Xu, J.W.; Chen, Y.L. On-line Inspection System for Surface Defects of Cold Rolled Strip. J. Univ. Sci. Technol. Beijing 2002, 24, 329–332. [Google Scholar]
- Qin, D.G.; Xu, K. Study on the On-line Detection Technology of Continuous Casting Slab Surface “Trajectory”. Met. World 2010, 5, 13–16. [Google Scholar]
- Ai, Y.H.; Xu, K. Development and Prospect of Online Detection Technology for Steel Plate Surface. Met. World 2010, 5, 37–39. [Google Scholar]
- Han, B.A.; Xiang, H.Y.; Li, Z.; Huang, J.J. Defects Detection of Sheet Metal Parts Based on HALCON and Region Morphology. Appl. Mech. Mater. 2013, 365–366, 729–732. [Google Scholar] [CrossRef]
- Suresh, B.R.; Fundakowski, R.A.; Levitt, T.S. A real-time automated visual inspection system for hot steel slabs. IEEE Trans. Pattern Anal. Mach. Intell. 1983, 6, 563–572. [Google Scholar] [CrossRef]
- Jouetetal, J. Defect Classification in surface inspection of strip steel. Steel Times 1992, 16, 214–216. [Google Scholar]
- Canella, G.; Falessi, R. Surface inspection and classification plant for stainless steel strip. Nondestruct. Test. 1992, 72, 1185–1189. [Google Scholar]
- Badger, J.C.; Enright, S.T. Automated surface inspection system. Iron Steel Eng. 1996, 73, 48–51. [Google Scholar]
- Rodrick, T.J. Software controlled on-line su–rface inspection. Steel Times Int. 1998, 22, 30. [Google Scholar]
- Carisetti, C.A.; Fong, T.Y.; Fromm, C. Selflearning defect classifier. Iron Steel Eng. 1998, 75, 50–53. [Google Scholar]
- Parsytec Computer Corp. Software controlled on 2 line surface inspection. Steel Times Int. 1998, 22, 30. [Google Scholar]
- Ceracki, P.; Reizig, H.J.; Rudolphi, U.; Lucking, F. On-line surface inspection of hot-rolled strip. Metall. Plant Technol. Int. 2000, 23, 66–68. [Google Scholar]
- Bailleul, M. Dynamic surface inspection at the hot-strip mill. Steel Times Int. 2005, 29, 24. [Google Scholar]
- Jordan, M.I.; Bishop, C.M. Neural networks. ACM Comput. Surv. 1996, 28, 73–75. [Google Scholar] [CrossRef]
- Vishwakarma, V.P.; Gupta, M.N. A New Learning Algorithm for Single hidden Layer Feedforward Neural Networks. Int. J. Comput. Appl. 2011, 28, 26–33. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Huang, G.; Zhu, Q.; Siew, C. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Liang, N.Y.; Huang, G.B.; Saratchandran, P.; Sundararajan, N. A fast and accurate online sequential learning algorithm for feedforward networks. IEEE Trans. Neural Netw. 2006, 17, 1411–1423. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.B.; Chen, L.; Siew, C.K. Universal approximation using incremental constructive feedforward networks with random hidden nodes. IEEE Trans. Neural Netw. 2006, 4, 879–892. [Google Scholar] [CrossRef] [PubMed]
- Miche, Y.; Sorjamaa, A.; Lendasse, A. OP-ELM: Theory, experiments and a toolbox. Artif. Neural Netw. 2008, 5163, 145–154. [Google Scholar]
- Feng, G.; Huang, G.B.; Lin, Q.; Gay, R. Error minimized extreme learning machine with growth of hidden nodes and incremental learning. IEEE Trans. Neural Netw. 2009, 20, 1352–1357. [Google Scholar] [CrossRef] [PubMed]
- Lan, Y.; Soh, Y.C.; Huang, G.B. Ensemble of online sequential extreme learning machine. Neurocomputing 2009, 72, 3391–3395. [Google Scholar] [CrossRef]
- Goodman, E.D. Introduction to genetic algorithms. In Proceedings of the Conference Companion on Genetic and Evolutionary Computation, Dublin, Ireland, 12–16 July 2011; pp. 839–860. [Google Scholar]
- Zhang, C.; Liu, H.; Zhang, C. The Detection of Solder Joint Defect and Solar Panel Orientation Based on ELM and Robust Least Square Fitting. In Proceedings of the Chinese Control and Decision Conference (CCDC), Mianyang, China, August 2011; pp. 561–565. [Google Scholar]
- Li, S.X.; Huang, Z.H. Research on the detection method of glass mouth defect based on extreme learning machine. J. Computing Technol. Autom. 2016, 4, 117–120. [Google Scholar]
- Barata, J.C.; Hussein, M.S. The Moore-Penrose Pseudoinverse: A Tutorial Review of the Theory. Braz. J. Phys. 2011, 42, 146–165. [Google Scholar] [CrossRef]
- Xu, K.; Zhou, P.; Yang, C.L. Online Detection Technology of Surface Defects in Continuous Casting Slab and Its Application. In Proceedings of the Scientific and Technological Progress and Fine Arts Symposium on Continuous Casting Equipment Technology, Xi’an, China, May 2013; pp. 1195–1200. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
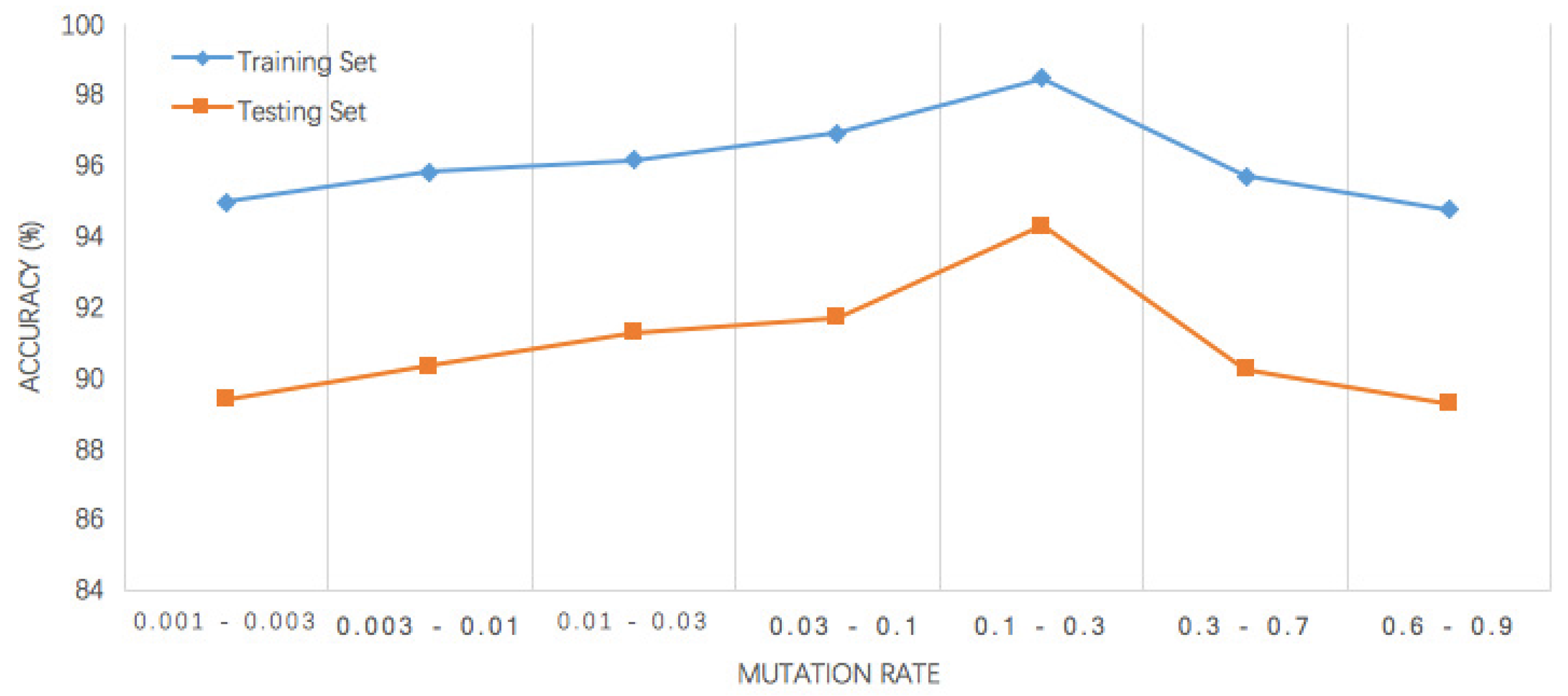
| Algorithm | Training Set (%) | Testing Set (%) | ||
|---|---|---|---|---|
| ELM | - | - | 93.32 | 89.12 |
| G-ELM | 0.001 | 0.003 | 94.98 | 89.39 |
| 0.003 | 0.01 | 95.81 | 90.35 | |
| 0.01 | 0.03 | 96.14 | 91.29 | |
| 0.03 | 0.1 | 96.92 | 91.71 | |
| 0.1 | 0.3 | 98.46 | 94.30 | |
| 0.3 | 0.7 | 95.69 | 90.23 | |
| 0.6 | 0.9 | 94.74 | 89.27 |
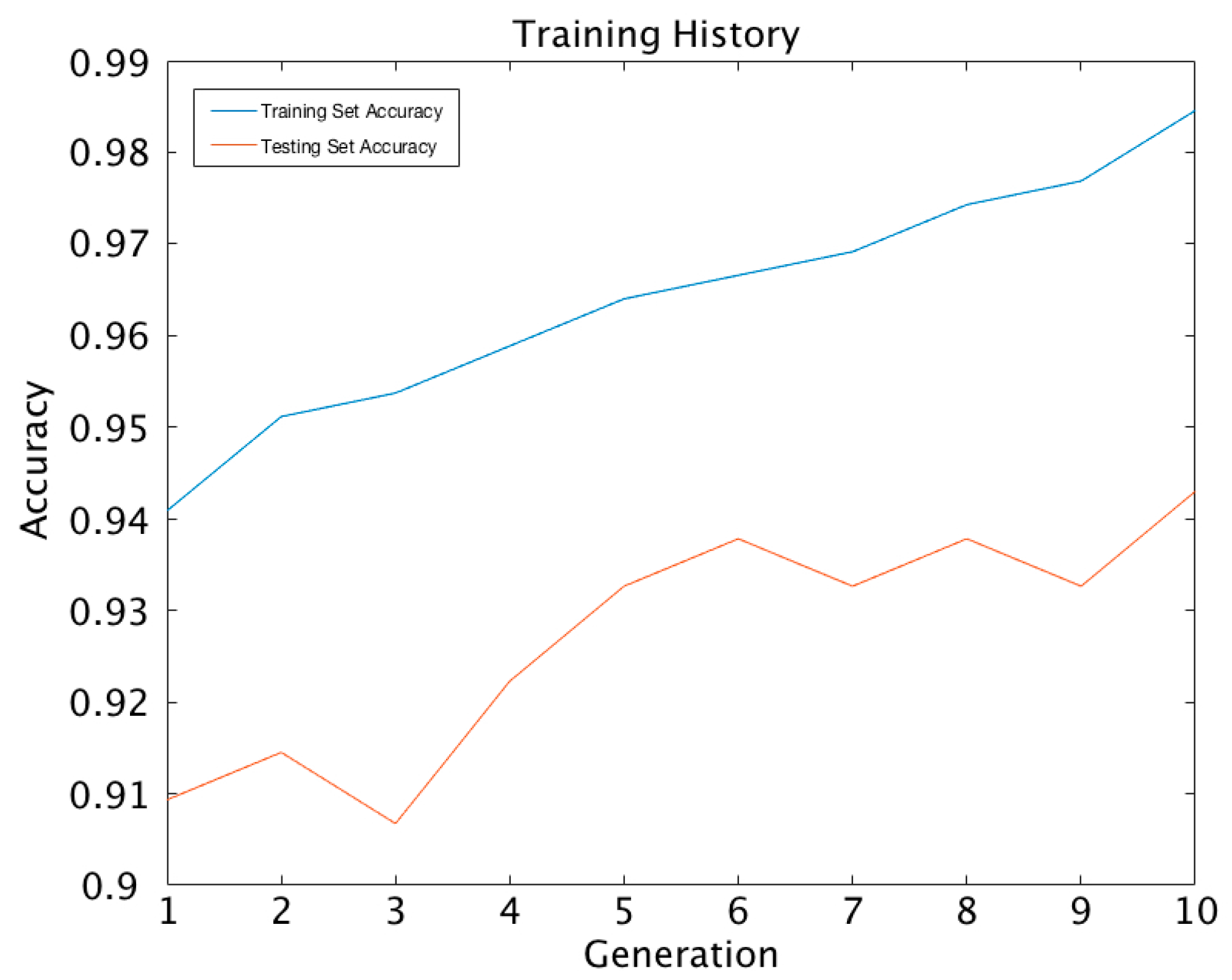
| Generation | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Iterations | - | 10 | 50 | 60 | 170 | 200 | 210 | 830 | 5690 | 7170 |
| Training Accuracy (%) | 94.09 | 95.12 | 95.37 | 95.89 | 96.40 | 96.66 | 96.92 | 97.43 | 97.69 | 98.46 |
| Testing Accuracy (%) | 90.93 | 91.45 | 90.67 | 92.23 | 93.26 | 93.78 | 93.26 | 93.78 | 93.26 | 94.30 |
| TCPU (s) | 0.035 | 0.35 | 1.75 | 2.1 | 5.95 | 7 | 7.35 | 29.05 | 199.15 | 250.95 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, S.; Xu, K. An Algorithm for Surface Defect Identification of Steel Plates Based on Genetic Algorithm and Extreme Learning Machine. Metals 2017, 7, 311. https://doi.org/10.3390/met7080311
Tian S, Xu K. An Algorithm for Surface Defect Identification of Steel Plates Based on Genetic Algorithm and Extreme Learning Machine. Metals. 2017; 7(8):311. https://doi.org/10.3390/met7080311
Chicago/Turabian StyleTian, Siyang, and Ke Xu. 2017. "An Algorithm for Surface Defect Identification of Steel Plates Based on Genetic Algorithm and Extreme Learning Machine" Metals 7, no. 8: 311. https://doi.org/10.3390/met7080311
APA StyleTian, S., & Xu, K. (2017). An Algorithm for Surface Defect Identification of Steel Plates Based on Genetic Algorithm and Extreme Learning Machine. Metals, 7(8), 311. https://doi.org/10.3390/met7080311