
Compressive Strength Prediction of High-Strength Concrete Using Long Short-Term Memory and Machine Learning Algorithms


Abstract
:1. Introduction
2. Methodology
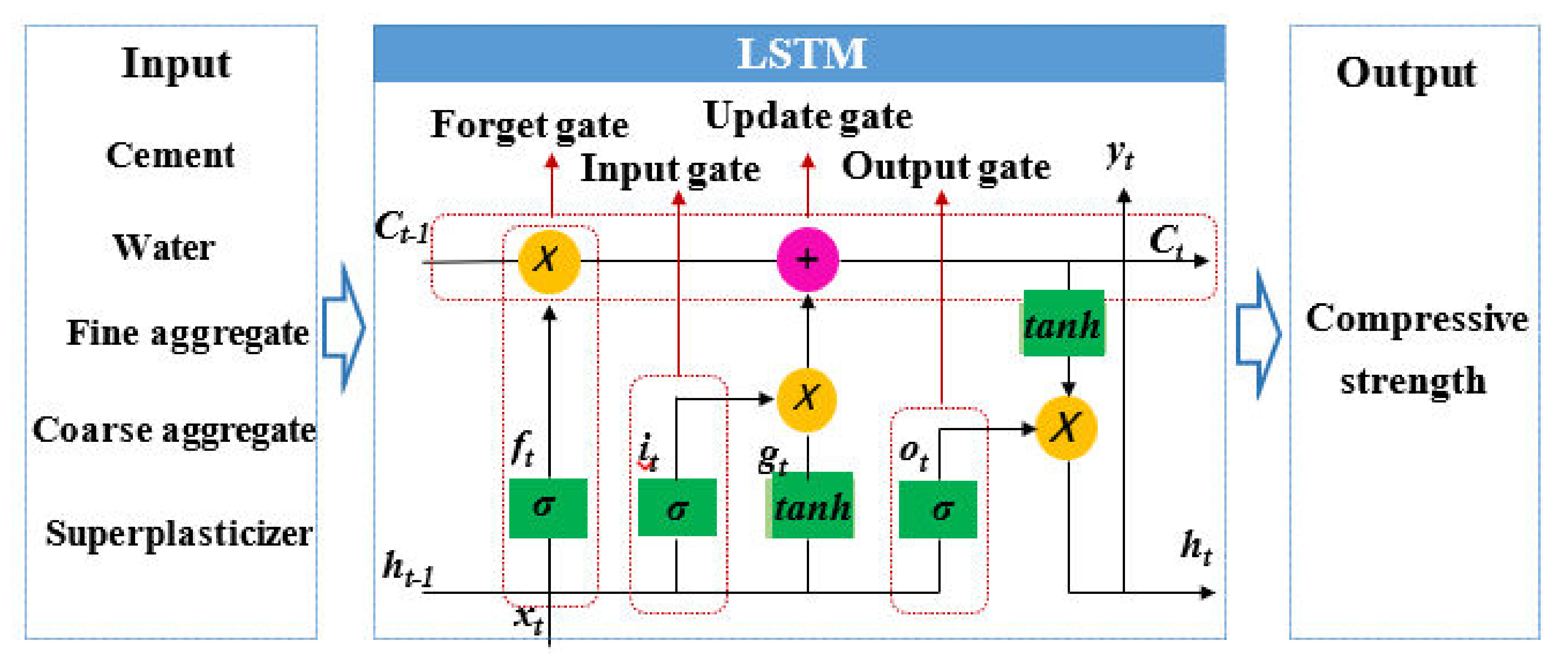
2.1. LSTM
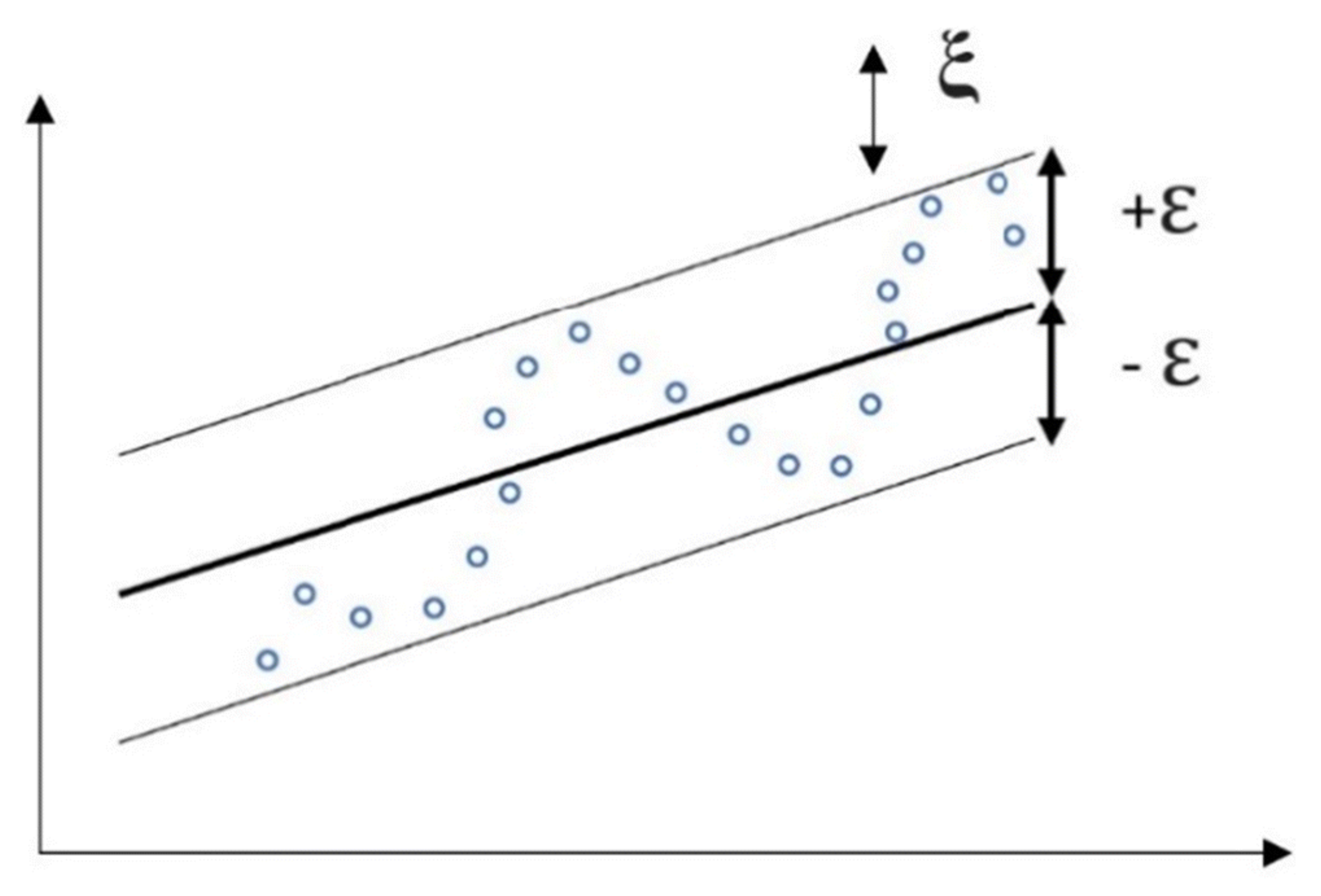
2.2. Support Vector Regression
3. Materials and Dataset
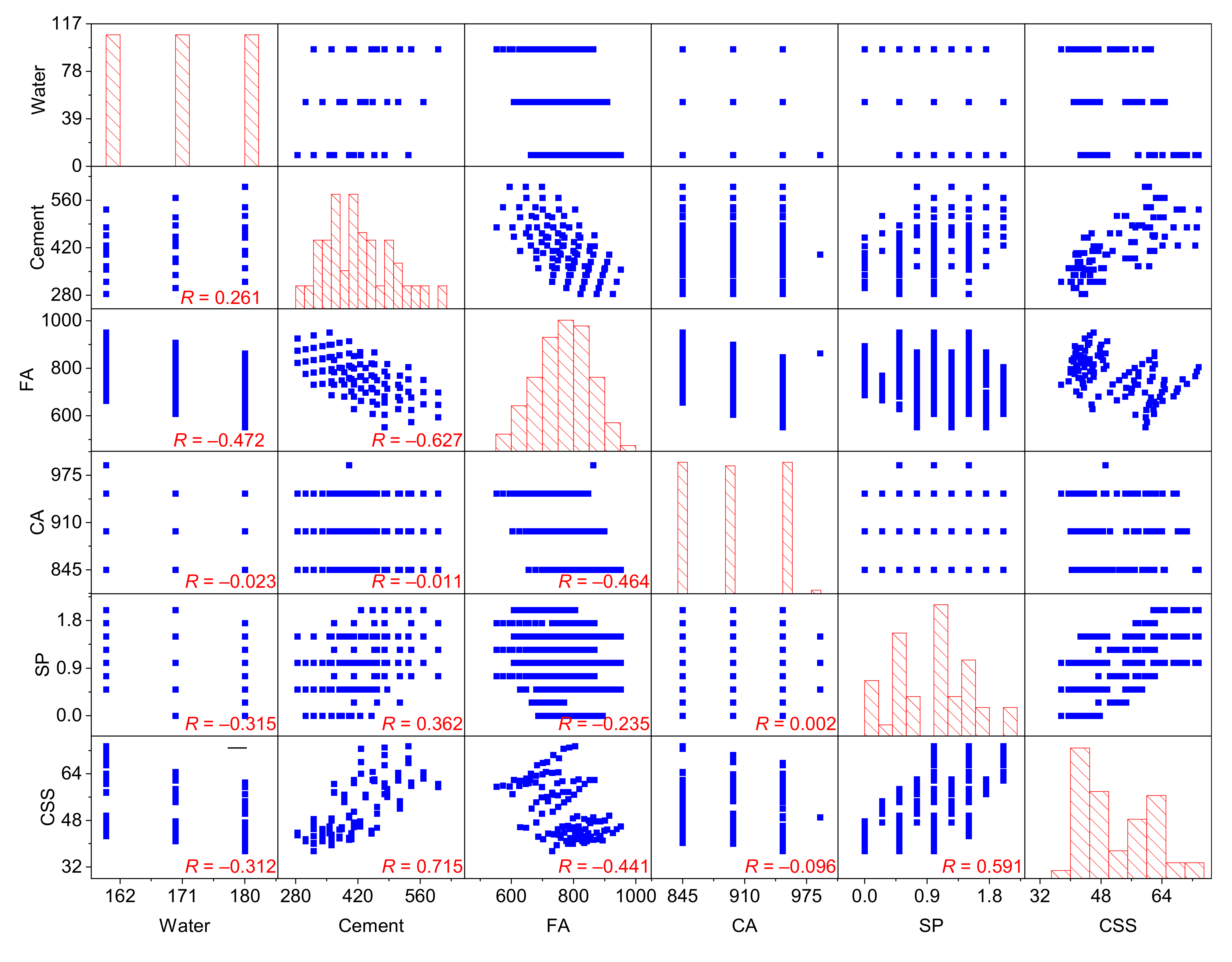
3.1. Dataset Description
3.2. Performance-Evaluation Methods
4. Model Building and Training
4.1. Model Building
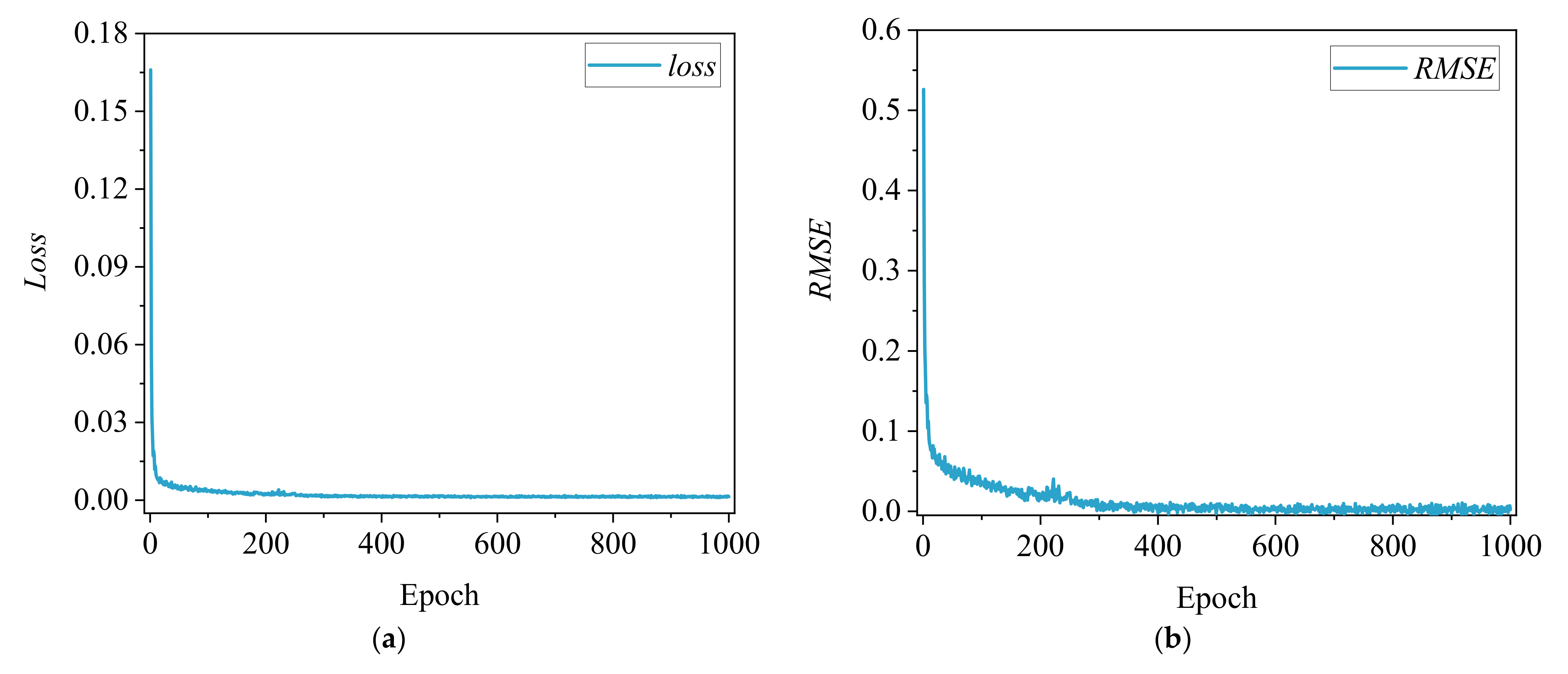
4.2. Model Training
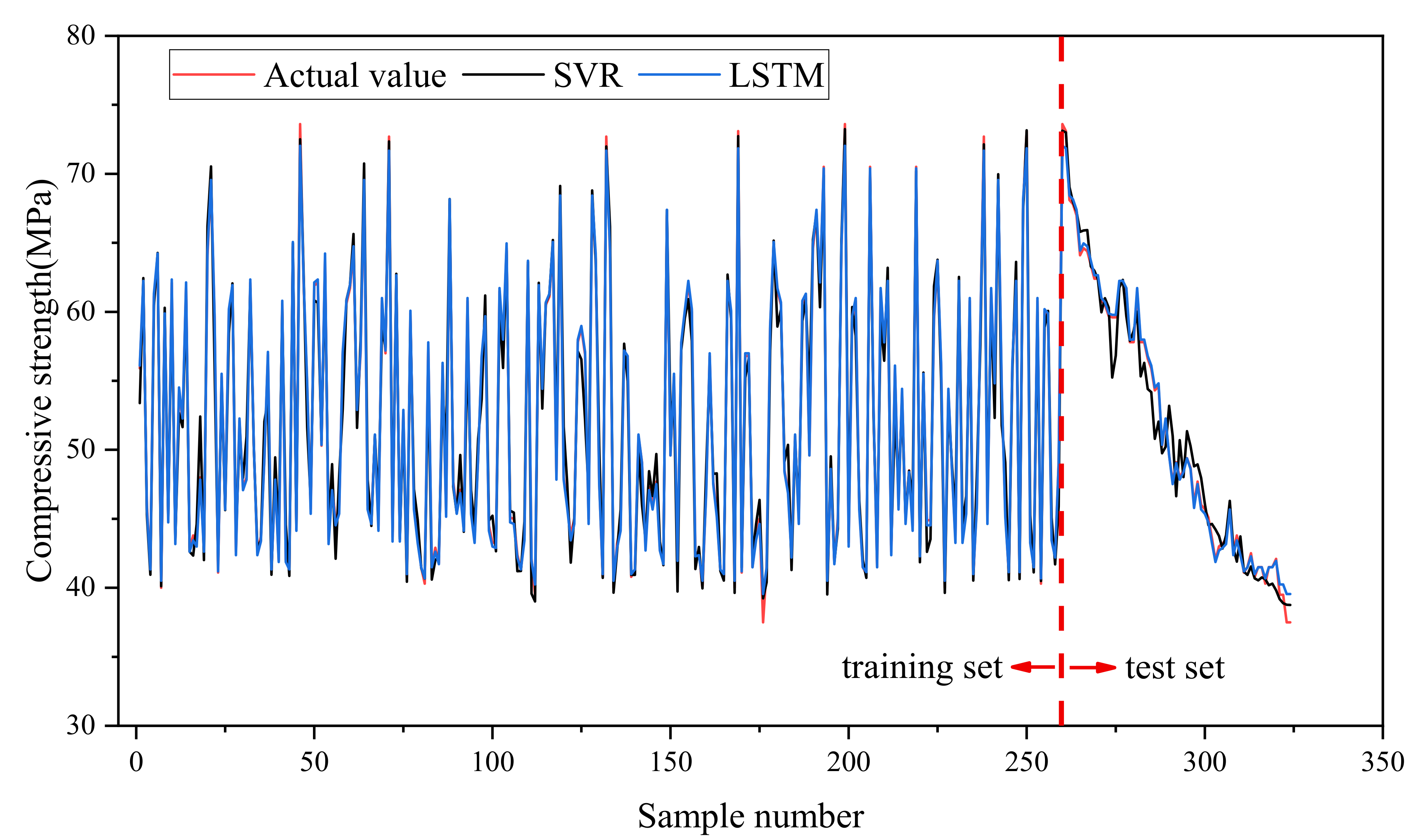
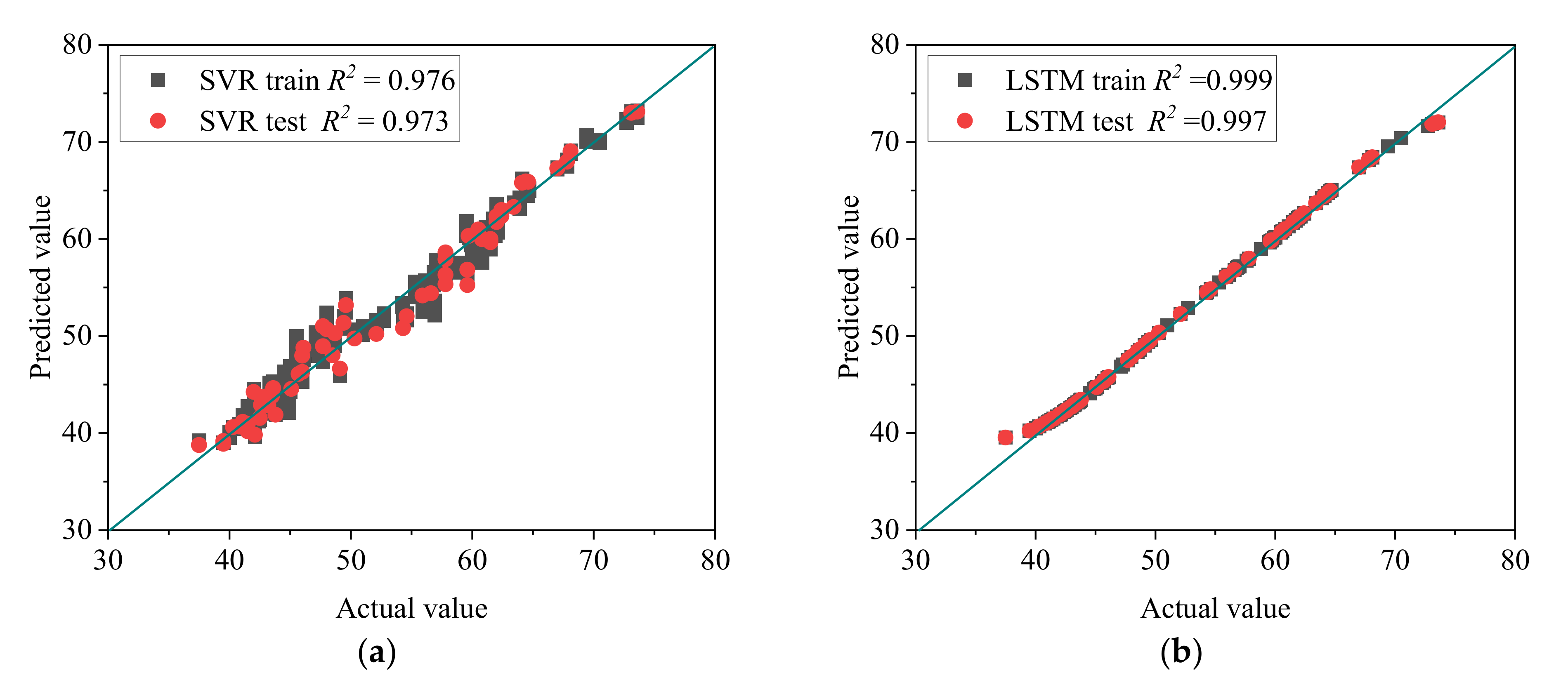
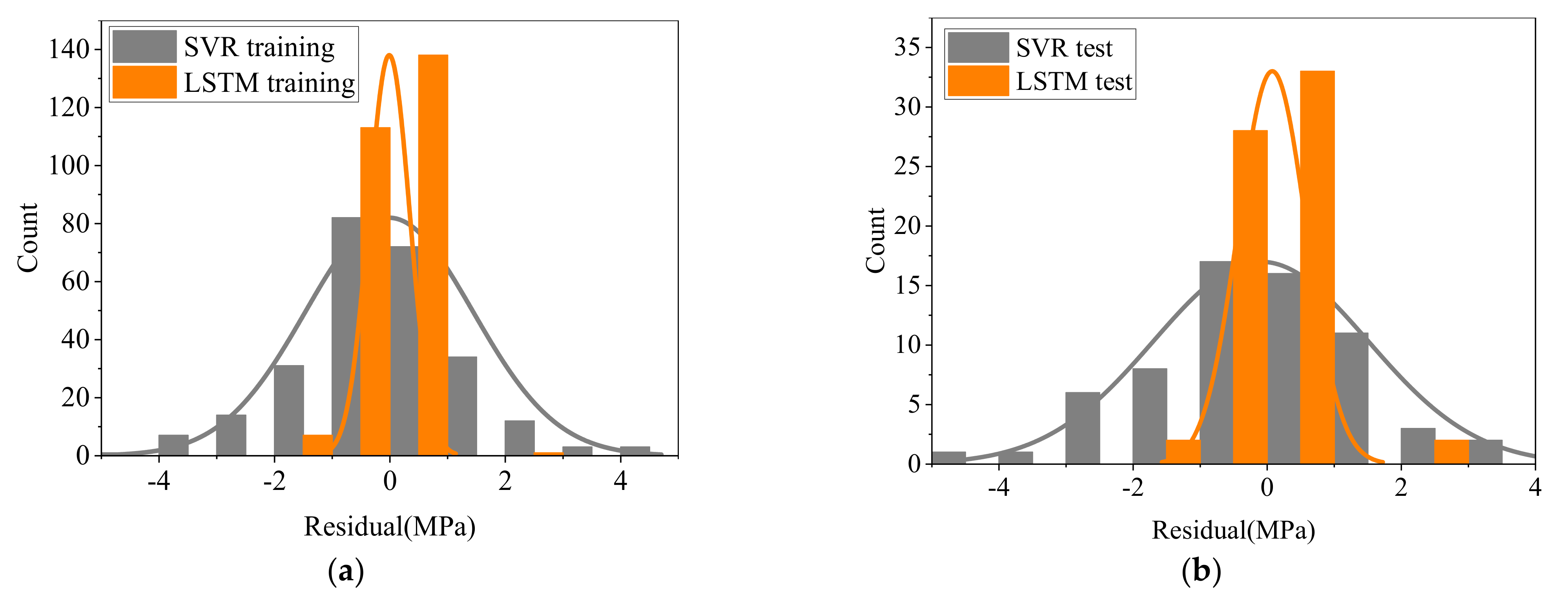
5. Comparison of Prediction Results
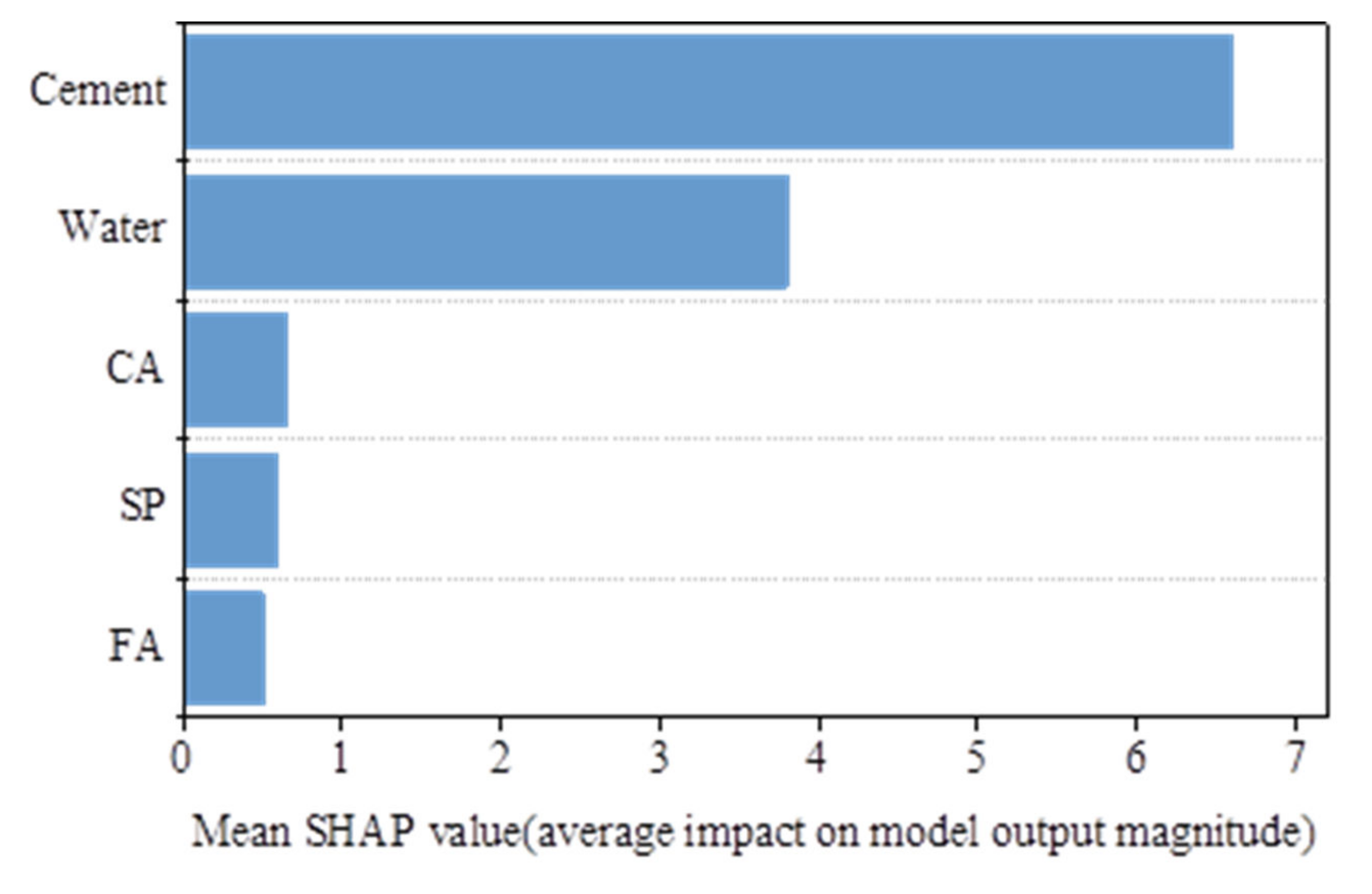
6. Importance Analysis of Input Variables on Output
7. Conclusions
- (1)
- The LSTM model can capture the complex nonlinear relationship between the five input parameters and the compressive strength of HSC with R2 exceeding 0.99 in both training and testing stages.
- (2)
- Compared with the conventional SVR model, the prediction capacity of the LSTM model is superior, which is recommended as an alternative method for the compressive strength prediction of HSC. The pre-estimate HSC compressive strength can be obtained prior to the implementation of laboratory compression tests using the LSTM model, which will greatly reduce the time and cost of laboratory compression tests.
- (3)
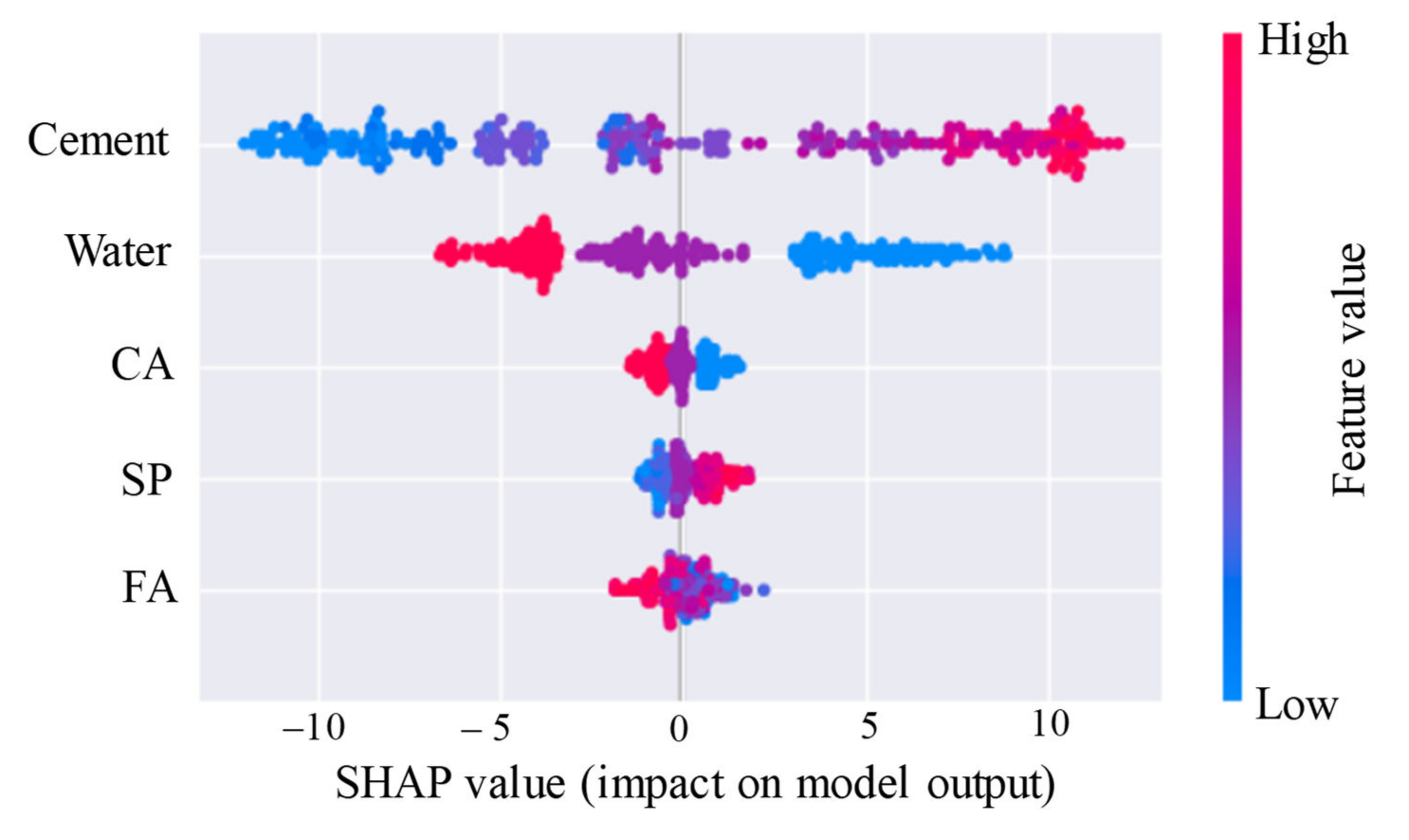
- Among the five input variables shown in this paper, cement and water are the two most sensitive and important variables for compressive strength.
- (4)
- Cement and superplasticizer are positive for compressive strength, the value of compressive strength increases with their increase, while water, coarse aggregate, and fine aggregate are negative for compressive strength, their increase will lead to the decrease of compressive strength of HSC.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| HSC | High-strength concrete |
| RMSE | Root mean square error |
| MAE | Mean absolute error |
| MAPE | Mean absolute percentage error |
| SHAP | Shapley additive explanations |
| DNN | Deep neural network |
| RNN | Recurrent neural network |
| KNN | K-nearest neighbor |
| CA | Coarse aggregate |
| SP | Superplasticizer |
| LSTM | Long short-term memory |
| ANN | Artificial neural network |
| RF | Random forest |
| DT | Decision tree |
| SVM | Support vector machine |
| SVR | Support vector regression |
| GEP | Gene expression programming |
| ELM | Extreme learning machine |
| FA | Fine aggregate |
| CCS | Compressive strength |
References
- Henry, G.R. ACI Defines High-Performance Concrete. Concr. Int. 1999, 21, 56–57. [Google Scholar]
- Mbessa, M.; Péra, J. Durability of high-strength concrete in ammonium sulfate solution. Cem. Concr. Res. 2001, 31, 1227–1231. [Google Scholar] [CrossRef]
- Moradi, M.J.; Khaleghi, M.; Salimi, J.; Farhangi, V.; Ramezanianpour, A.M. Predicting the compressive strength of concrete containing metakaolin with different properties using ANN. Measurement 2021, 183, 109790. [Google Scholar] [CrossRef]
- Azimi-Pour, M.; Eskandari-Naddaf, H.; Pakzad, A. Linear and non-linear SVM prediction for fresh properties and compressive strength of high volume fly ash self-compacting concrete. Constr. Build. Mater. 2020, 230, 117021. [Google Scholar] [CrossRef]
- Nguyen-Sy, T.; Wakim, J.; To, Q.-D.; Vu, M.-N.; Nguyen, T.-D.; Nguyen, T.-T. Predicting the compressive strength of concrete from its compositions and age using the extreme gradient boosting method. Constr. Build. Mater. 2020, 260, 119757. [Google Scholar] [CrossRef]
- Han, Q.; Gui, C.; Xu, J.; Lacidogna, G. A generalized method to predict the compressive strength of high-performance concrete by improved random forest algorithm. Constr. Build. Mater. 2019, 226, 734–742. [Google Scholar] [CrossRef]
- Li, H.; Lin, J.; Lei, X.; Wei, T. Compressive strength prediction of basalt fiber reinforced concrete via random forest algorithm. Mater. Today Commun. 2022, 30, 103117. [Google Scholar] [CrossRef]
- Ahmad, A.; Ahmad, W.; Aslam, F.; Joyklad, P. Compressive strength prediction of fly ash-based geopolymer concrete via advanced machine learning techniques. Case Stud. Constr. Mater. 2022, 16, e00840. [Google Scholar] [CrossRef]
- Barkhordari, M.S.; Armaghani, D.J.; Mohammed, A.S.; Ulrikh, D.V. Data-Driven Compressive Strength Prediction of Fly Ash Concrete Using Ensemble Learner Algorithms. Buildings 2022, 12, 132. [Google Scholar] [CrossRef]
- Silva, F.A.N.; Delgado, J.M.P.Q.; Cavalcanti, R.S.; Azevedo, A.C.; Guimarães, A.S.; Lima, A.G.B. Use of Nondestructive Testing of Ultrasound and Artificial Neural Networks to Estimate Compressive Strength of Concrete. Buildings 2021, 11, 44. [Google Scholar] [CrossRef]
- Ahmad, A.; Chaiyasarn, K.; Farooq, F.; Ahmad, W.; Suparp, S.; Aslam, F. Compressive Strength Prediction via Gene Expression Programming (GEP) and Artificial Neural Network (ANN) for Concrete Containing RCA. Buildings 2021, 11, 324. [Google Scholar] [CrossRef]
- Ly, H.-B.; Nguyen, T.-A.; Thi Mai, H.-V.; Tran, V.Q. Development of deep neural network model to predict the compressive strength of rubber concrete. Constr. Build. Mater. 2021, 301, 124081. [Google Scholar] [CrossRef]
- Al-Shamiri, A.K.; Kim, J.H.; Yuan, T.-F.; Yoon, Y.S. Modeling the compressive strength of high-strength concrete: An extreme learning approach. Constr. Build. Mater. 2019, 208, 204–219. [Google Scholar] [CrossRef]
- Muliauwan, H.N.; Prayogo, D.; Gaby, G.; Harsono, K. Prediction of Concrete Compressive Strength Using Artificial Intelligence Methods. J. Phys. Conf. Ser. 2020, 1625, 012018. [Google Scholar] [CrossRef]
- Song, H.; Ahmad, A.; Farooq, F.; Ostrowski, K.A.; Maślak, M.; Czarnecki, S.; Aslam, F. Predicting the compressive strength of concrete with fly ash admixture using machine learning algorithms. Constr. Build. Mater. 2021, 308, 125021. [Google Scholar] [CrossRef]
- Farooq, F.; Ahmed, W.; Akbar, A.; Aslam, F.; Alyousef, R. Predictive modeling for sustainable high-performance concrete from industrial wastes: A comparison and optimization of models using ensemble learners. J. Clean. Prod. 2021, 292, 126032. [Google Scholar] [CrossRef]
- Tanyildizi, H. Predicting the geopolymerization process of fly ash-based geopolymer using deep long short-term memory and machine learning. Cem. Concr. Compos. 2021, 123, 104177. [Google Scholar] [CrossRef]
- Latif, S.D. Concrete compressive strength prediction modeling utilizing deep learning long short-term memory algorithm for a sustainable environment. Environ. Sci. Pollut. Res. 2021, 28, 30294–30302. [Google Scholar] [CrossRef]
- Tanyildizi, H.; Şengür, A.; Akbulut, Y.; Şahin, M. Deep learning model for estimating the mechanical properties of concrete containing silica fume exposed to high temperatures. Front. Struct. Civ. Eng. 2020, 14, 1316–1330. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A Search Space Odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef] [Green Version]
- Shrestha, A.; Mahmood, A. Review of Deep Learning Algorithms and Architectures. IEEE Access 2019, 7, 53040–53065. [Google Scholar] [CrossRef]
- Wang, K.; Qi, X.; Liu, H. Photovoltaic power forecasting based LSTM-Convolutional Network. Energy 2019, 189, 116225. [Google Scholar] [CrossRef]
- Moradzadeh, A.; Teimourzadeh, H.; Mohammadi-Ivatloo, B.; Pourhossein, K. Hybrid CNN-LSTM approaches for identification of type and locations of transmission line faults. Int. J. Electr. Power Energy Syst. 2022, 135, 107563. [Google Scholar] [CrossRef]
- Moradzadeh, A.; Zakeri, S.; Shoaran, M.; Mohammadi-Ivatloo, B.; Mohammadi, F. Short-Term Load Forecasting of Microgrid via Hybrid Support Vector Regression and Long Short-Term Memory Algorithms. Sustainability 2020, 12, 7076. [Google Scholar] [CrossRef]
- Naderpour, H.; Rafiean, A.H.; Fakharian, P. Compressive strength prediction of environmentally friendly concrete using artificial neural networks. J. Build. Eng. 2018, 16, 213–219. [Google Scholar] [CrossRef]
- Wu, Y.; Li, S. Damage degree evaluation of masonry using optimized SVM-based acoustic emission monitoring and rate process theory. Measurement 2022, 190, 110729. [Google Scholar] [CrossRef]
- Jiang, W.; Xie, Y.; Li, W.; Wu, J.; Long, G. Prediction of the splitting tensile strength of the bonding interface by combining the support vector machine with the particle swarm optimization algorithm. Eng. Struct. 2021, 230, 111696. [Google Scholar] [CrossRef]
- Ahmad, M.; Kamiński, P.; Olczak, P.; Alam, M.; Iqbal, M.J.; Ahmad, F.; Sasui, S.; Khan, B.J. Development of Prediction Models for Shear Strength of Rockfill Material Using Machine Learning Techniques. Appl. Sci. 2021, 11, 6167. [Google Scholar] [CrossRef]
- Ray, S.; Haque, M.; Rahman, M.M.; Sakib, M.N.; Al Rakib, K. Experimental investigation and SVM-based prediction of compressive and splitting tensile strength of ceramic waste aggregate concrete. J. King Saud Univ.-Eng. Sci. 2021; in press. [Google Scholar] [CrossRef]
- Nguyen, M.S.T.; Kim, S.-E. A hybrid machine learning approach in prediction and uncertainty quantification of ultimate compressive strength of RCFST columns. Constr. Build. Mater. 2021, 302, 124208. [Google Scholar] [CrossRef]
- Ling, H.; Qian, C.; Kang, W.; Liang, C.; Chen, H. Combination of Support Vector Machine and K-Fold cross validation to predict compressive strength of concrete in marine environment. Constr. Build. Mater. 2019, 206, 355–363. [Google Scholar] [CrossRef]
- Chakraborty, D.; Awolusi, I.; Gutierrez, L. An explainable machine learning model to predict and elucidate the compressive behavior of high-performance concrete. Results Eng. 2021, 11, 100245. [Google Scholar] [CrossRef]
- Mangalathu, S.; Hwang, S.-H.; Jeon, J.-S. Failure mode and effects analysis of RC members based on machine-learning-based SHapley Additive exPlanations (SHAP) approach. Eng. Struct. 2020, 219, 110927. [Google Scholar] [CrossRef]
- Bakouregui, A.S.; Mohamed, H.M.; Yahia, A.; Benmokrane, B. Explainable extreme gradient boosting tree-based prediction of load-carrying capacity of FRP-RC columns. Eng. Struct. 2021, 245, 112836. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Water | Cement | Fine Aggregate | Coarse Aggregate | Superplasticizer | Compressive Strength | |
|---|---|---|---|---|---|---|---|
| Abbreviation | Water | Cement | FA | CA | SP | CSS | |
| Unit | kg/m3 | kg/m3 | kg/m3 | kg/m3 | kg/m3 | MPa | |
| Training set | max | 180 | 600 | 951 | 989 | 2 | 73.6 |
| min | 160 | 284 | 552 | 845 | 0 | 37.5 | |
| average | 168.02 | 410.76 | 712.05 | 902.76 | 0.80 | 51.98 | |
| standard deviation | 5.19 | 81.93 | 103.45 | 37.34 | 0.52 | 9.36 | |
| kurtosis | −1.01 | −1.01 | −1.01 | −1.01 | −1.01 | −1.01 | |
| skewness | 0.46 | 0.46 | 0.46 | 0.46 | 0.46 | 0.46 | |
| Test set | max | 180 | 600 | 951 | 989 | 2 | 73.6 |
| min | 160 | 284 | 552 | 845 | 0 | 37.5 | |
| average | 167.89 | 408.68 | 709.42 | 901.81 | 0.79 | 51.74 | |
| standard deviation | 5.38 | 84.99 | 107.31 | 38.73 | 0.54 | 9.71 | |
| kurtosis | −1.05 | −1.05 | −1.05 | −1.05 | −1.05 | −1.05 | |
| skewness | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | 0.40 | |
| Model Type | Dataset | RMSE | MAE | MAPE(%) | R2 |
|---|---|---|---|---|---|
| SVR | Training set | 1.447 | 1.083 | 2.134 | 0.976 |
| Test set | 1.595 | 0.312 | 2.469 | 0.973 | |
| LSTM | Training set | 0.354 | 0.271 | 0.528 | 0.999 |
| Test set | 0.508 | 0.080 | 0.653 | 0.997 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Li, X.; Wu, Y.; Zuo, L.; Lu, M.; Zhou, Y. Compressive Strength Prediction of High-Strength Concrete Using Long Short-Term Memory and Machine Learning Algorithms. Buildings 2022, 12, 302. https://doi.org/10.3390/buildings12030302
Chen H, Li X, Wu Y, Zuo L, Lu M, Zhou Y. Compressive Strength Prediction of High-Strength Concrete Using Long Short-Term Memory and Machine Learning Algorithms. Buildings. 2022; 12(3):302. https://doi.org/10.3390/buildings12030302
Chicago/Turabian StyleChen, Honggen, Xin Li, Yanqi Wu, Le Zuo, Mengjie Lu, and Yisong Zhou. 2022. "Compressive Strength Prediction of High-Strength Concrete Using Long Short-Term Memory and Machine Learning Algorithms" Buildings 12, no. 3: 302. https://doi.org/10.3390/buildings12030302
APA StyleChen, H., Li, X., Wu, Y., Zuo, L., Lu, M., & Zhou, Y. (2022). Compressive Strength Prediction of High-Strength Concrete Using Long Short-Term Memory and Machine Learning Algorithms. Buildings, 12(3), 302. https://doi.org/10.3390/buildings12030302