
Perspectives of Machine Learning and Natural Language Processing on Characterizing Positive Energy Districts

 ,
,  , ,
, ,  , and
, and
Abstract
:1. Introduction
1.1. Background
1.2. The Importance of PED Characterization and the Need of AI Techniques
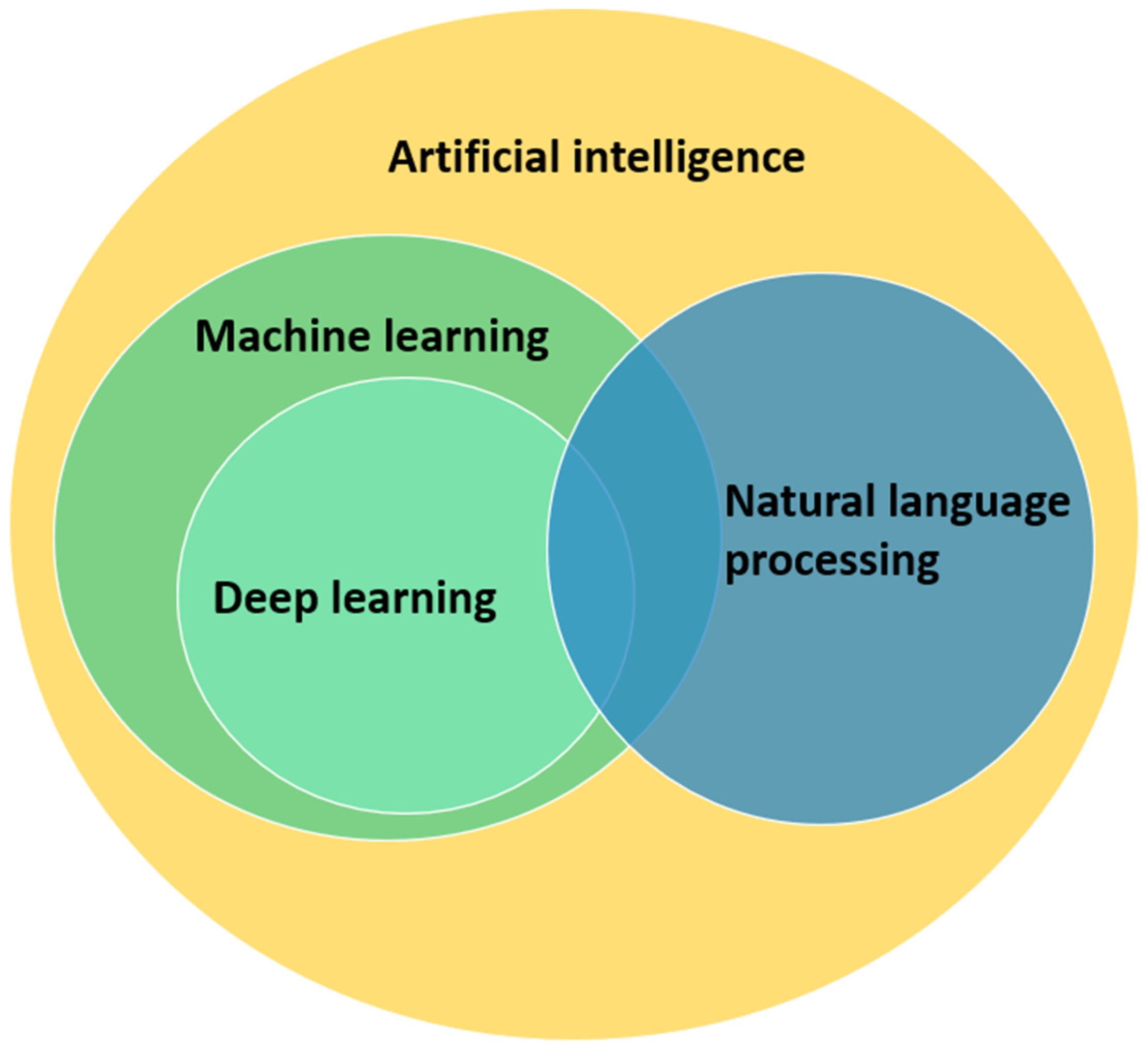
1.3. AI Techniques
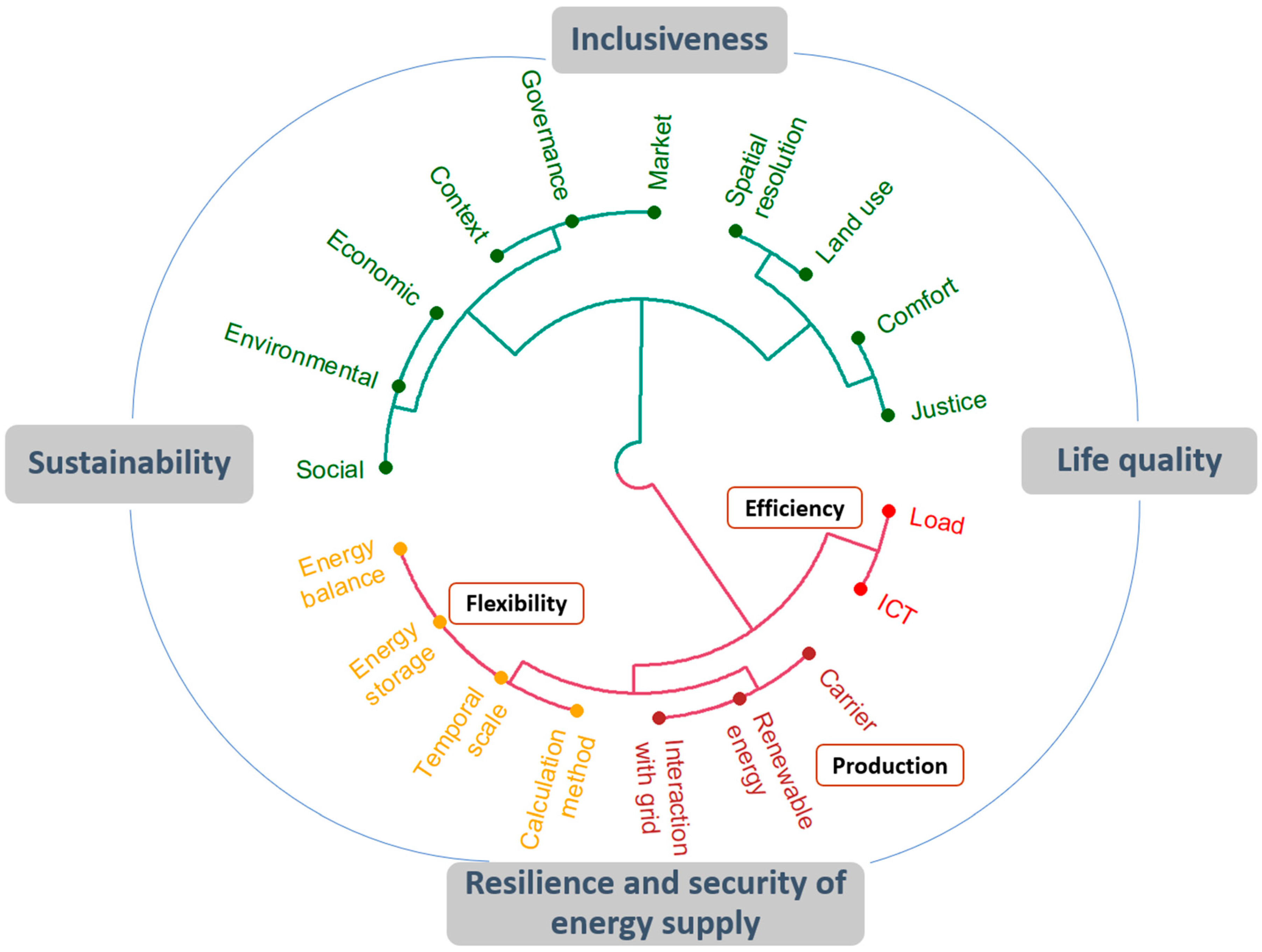
2. Elements of PEDs and Research Method
2.1. Elements of a PED
2.2. Research Method
3. Machine Learning and Natural Language Processing
3.1. Features and General Machine Learning Processes
3.1.1. Features of ML
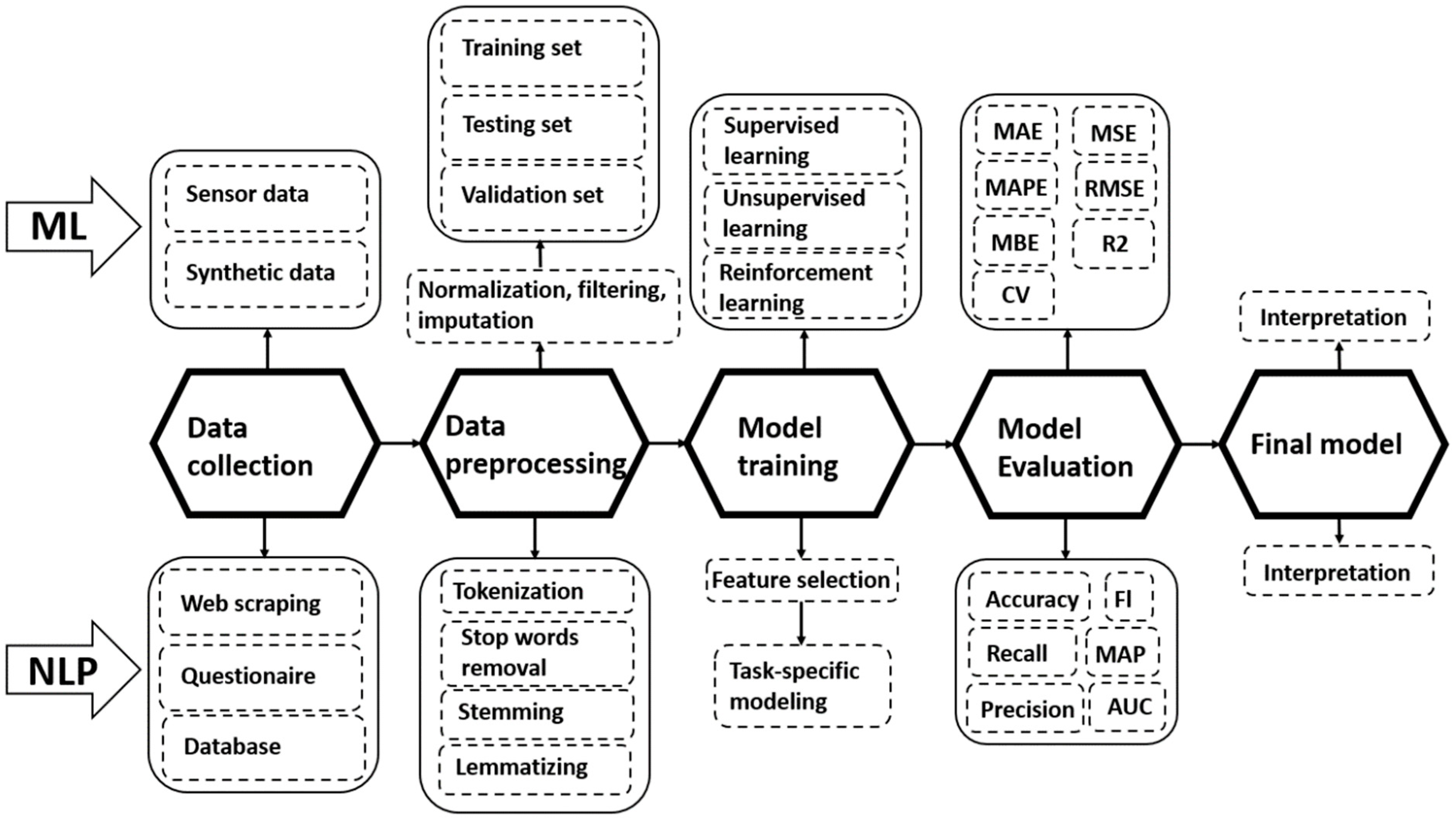
3.1.2. General Process of ML
- Data collection—ML requires input data that is mostly collected by sensors or generated synthetically [55]. The Internet of Things (IoT) has a significant potential to enhance the efficiency, effectiveness, and scalability of sensor techniques, while computer simulations and statistical methods are often used for generating synthetic data.
- Data pre-processing—The ranges of the acquired data may be significantly dissimilar from one another or the data may contain outliers, which could lead ML models to inadequate accuracy or learning. In order to tackle these challenges, data pre-processing is used to prepare and transform data into an appropriate form so that useful patterns can be extracted from the data [56]. This pre-processing includes data cleaning, data reduction, data transformation, and data integration [55]. Data splitting can further divide data into training data (for model training), testing data (for testing and evaluating the model) and validation data (for the tuning of model parameters) [57].
- Model training—An algorithm is selected to adjust the parameters in the model based on the training set. The goal is to deploy the trained model on the testing set until it is able to make accurate predictions or optimal decisions.
- Model evaluation—The performance of the ML models is evaluated based on different metrics including, among others, mean absolute error (MAE), mean absolute percentage error (MAPE), mean bias error (MBE), mean square error (MSE), root mean square error (RMSE), coefficient of determination (R2), and coefficient of variation (CV). These performance metrics enable the comparison of different models. Apart from these main steps, hyperparameter tuning sets the optimal parameters necessary to improve the performance of algorithms [58]. Despite being a computationally expensive process, hyperparameter tuning leads to the increased accuracy, robustness, and reliability of ML models [59].
3.2. Natural Language Processing
3.2.1. Features of NLP
3.2.2. General Process of NLP
- Tokenization—This is a process of separating words, sentences, and phrases into meaningful pieces from a stream of text-making elements called tokens. These tokens are then used as input for further processing. Some textual data contains punctuation marks, dates, and time formats which can create inconsistencies.
- Removing stop words—A number of common words that do not add meaning or generate results in their own right need to be eliminated. Eliminating the most frequently observed stop words such as ‘and’, ‘are’, ‘the’, and ‘that’ also reduces the size of the data and enhances the performance of the model.
- Stemming—This is a process whereby one word with variant forms is converged into a single ‘stem’. For example, the words ‘decarbonization’, ‘decarbonizing’, and ‘decarbonized’ can all be reduced to the single term ‘decarboni’. Stemming gives the root or base word, removes the last few characters of a word, and gives a short word, even though this word usually does not have a meaning.
- Lemmatizing—This is a process similar to stemming but one where the context of the root word is understood and used to generate meaningful representations and aid in information retrieval (IR). Lemmatizing is based on the presumption that an occurrence of the term ‘decarbonizing’, for example, indicates a connection to data where words like ‘decarbonized’ and ‘decarbonization’ are present.
- Feature selection—A process that encodes words into a data type that a computer can use for computation. Bag-of-words, one-hot encoding, and word2vec are all examples of feature selection. Term frequency–inverse document frequency (TF-IDF) is usually used in combination with feature selection to determine the importance of a word in a document.
- Task-specific modeling—In addition to statistical methods, many ML methods can be used for modeling complex problems. A specific NLP task needs to be defined so that the ML model can learn the parameters. When the model is trained, evaluation criteria can be used to measure its performance.
4. Overview of the Literature
4.1. Applications of ML to PED Elements
4.1.1. Common Approaches in ML
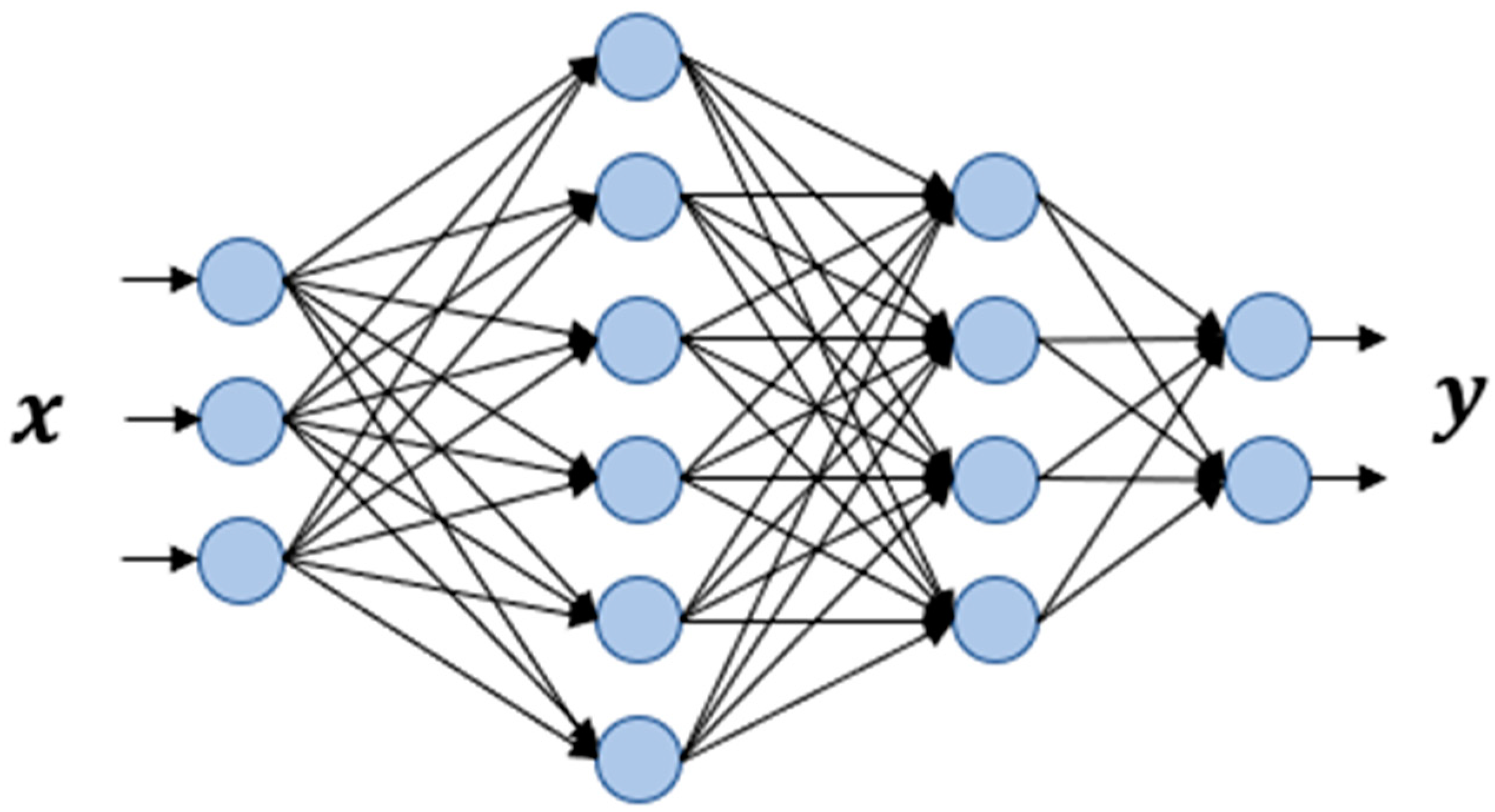
ANN-Based Approaches
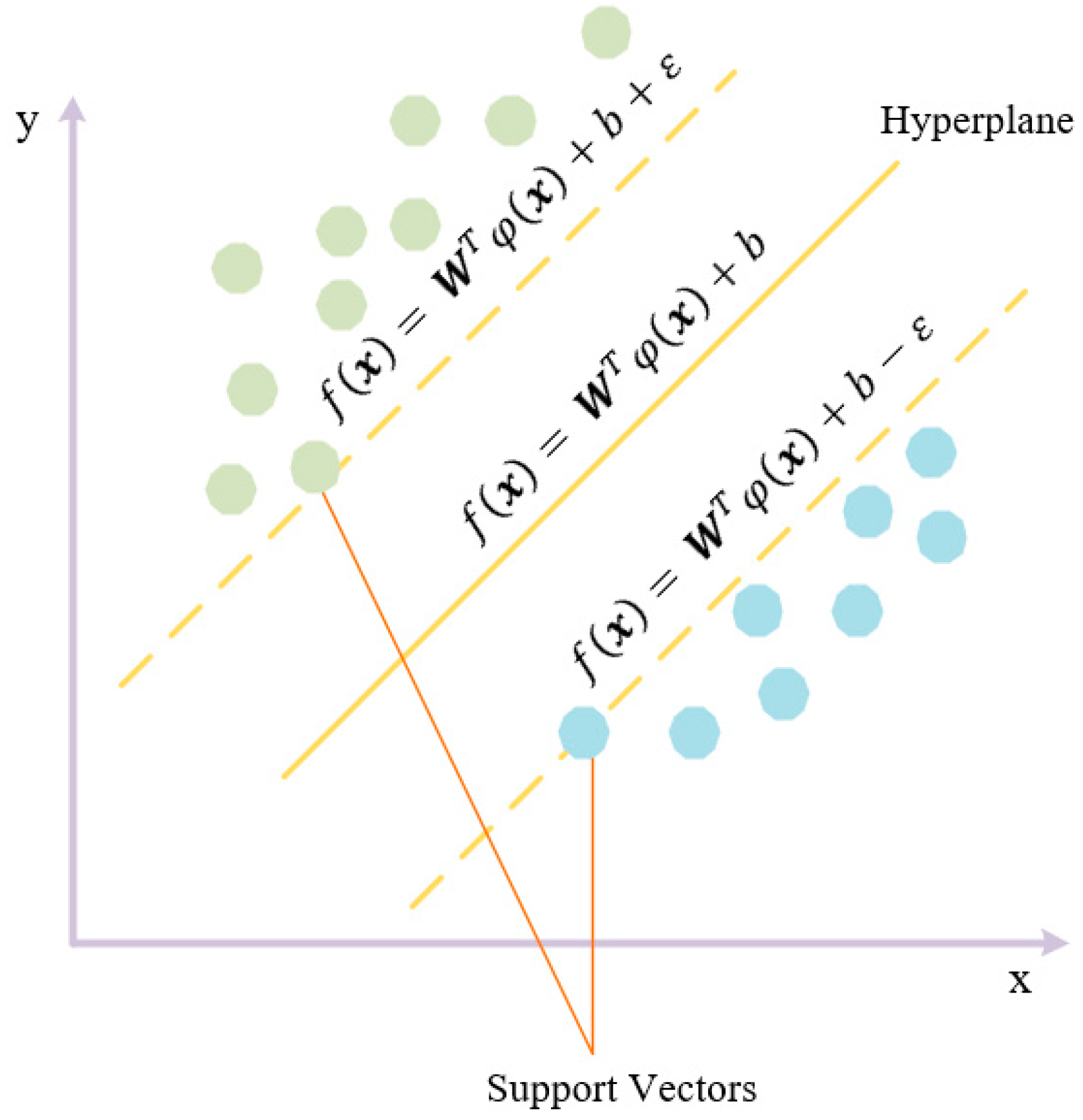
Support Vector Machines
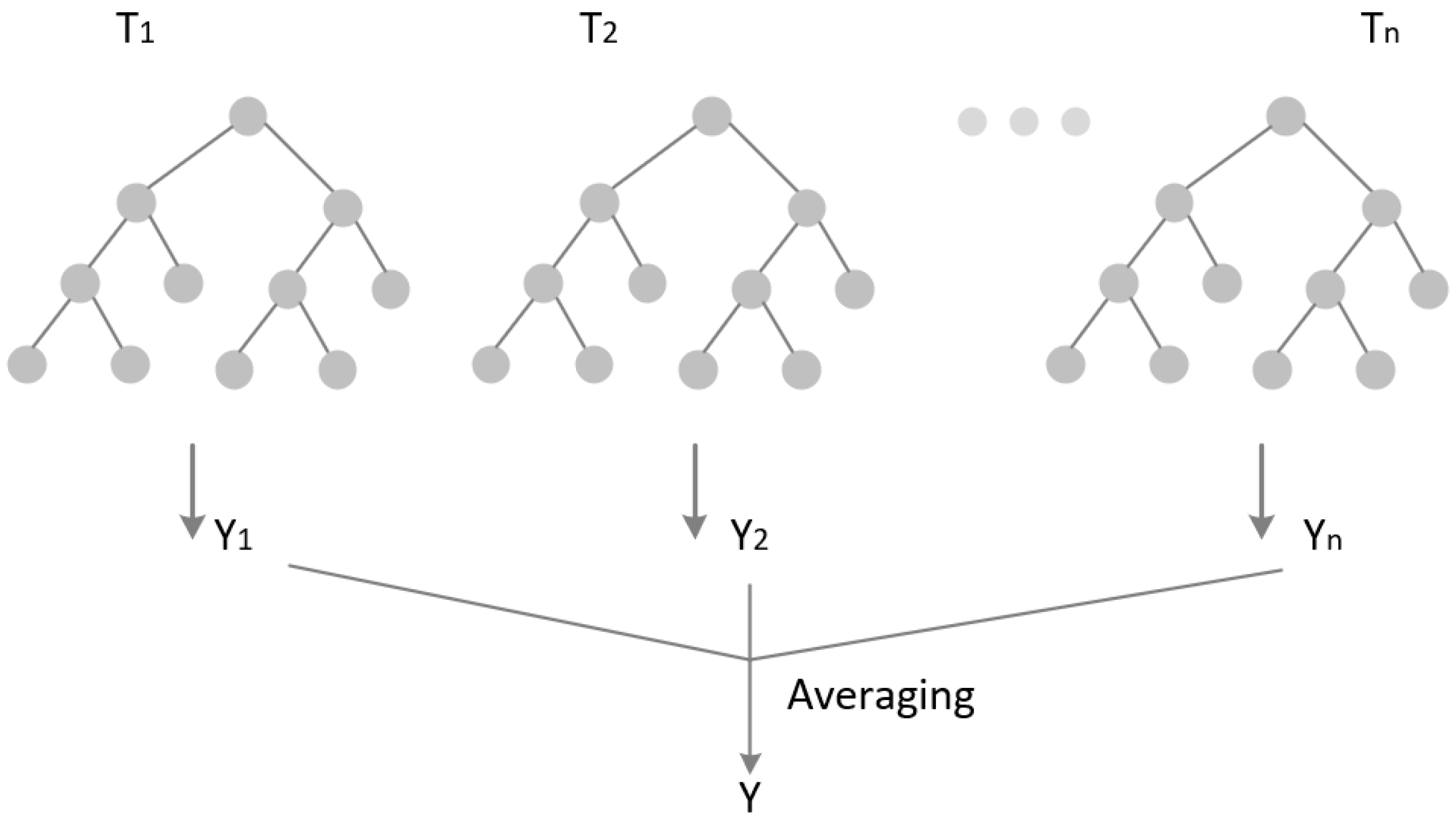
Tree-Based Approaches
4.1.2. Energy Efficiency
Information and Communication Technology (ICT)
Load
4.1.3. Renewable Energy
4.1.4. Sustainability and Environment
4.1.5. Comfort
4.2. Applications of NLP to PED Elements
4.2.1. NLP Techniques
Word2vec
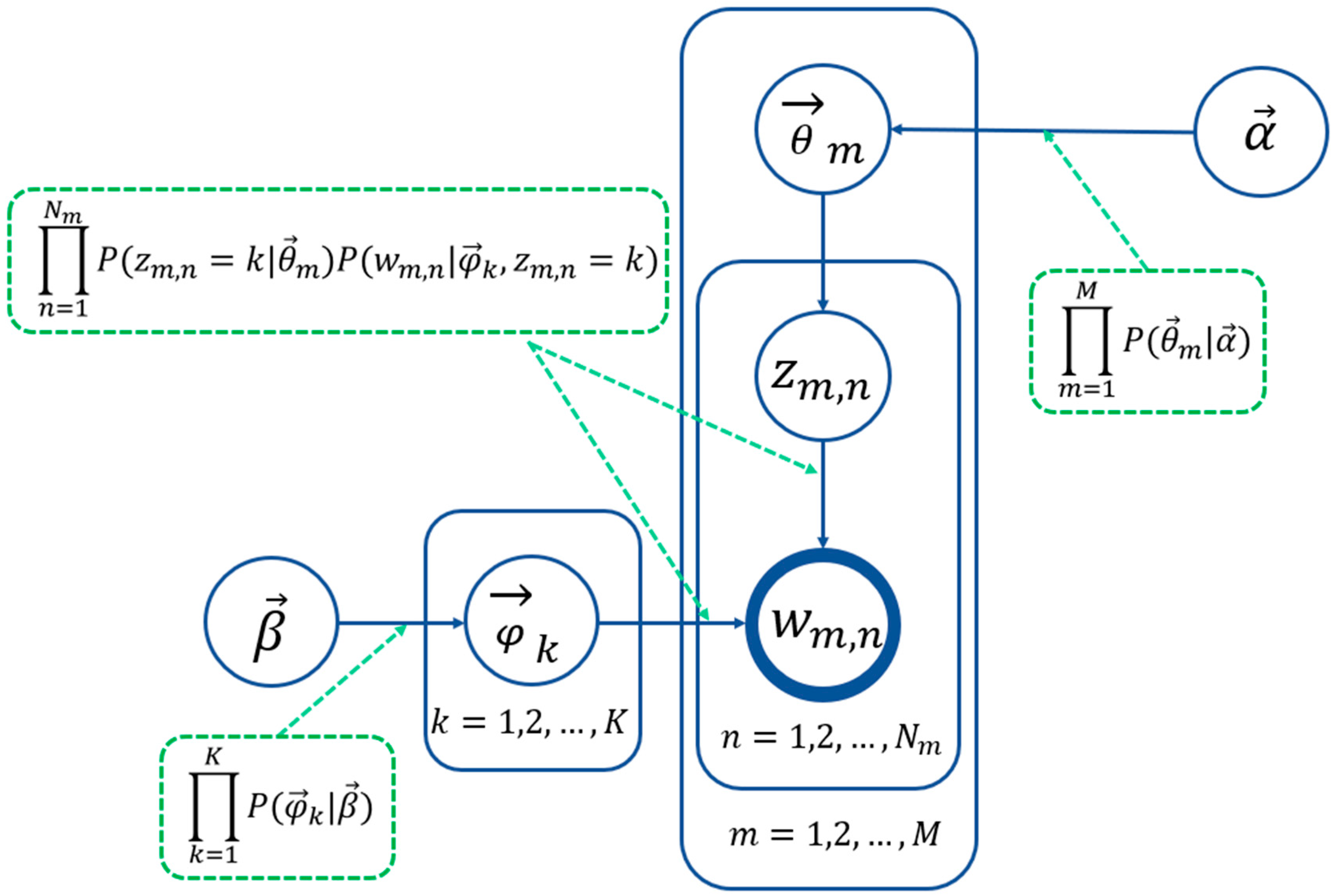
LDA Topic Modeling
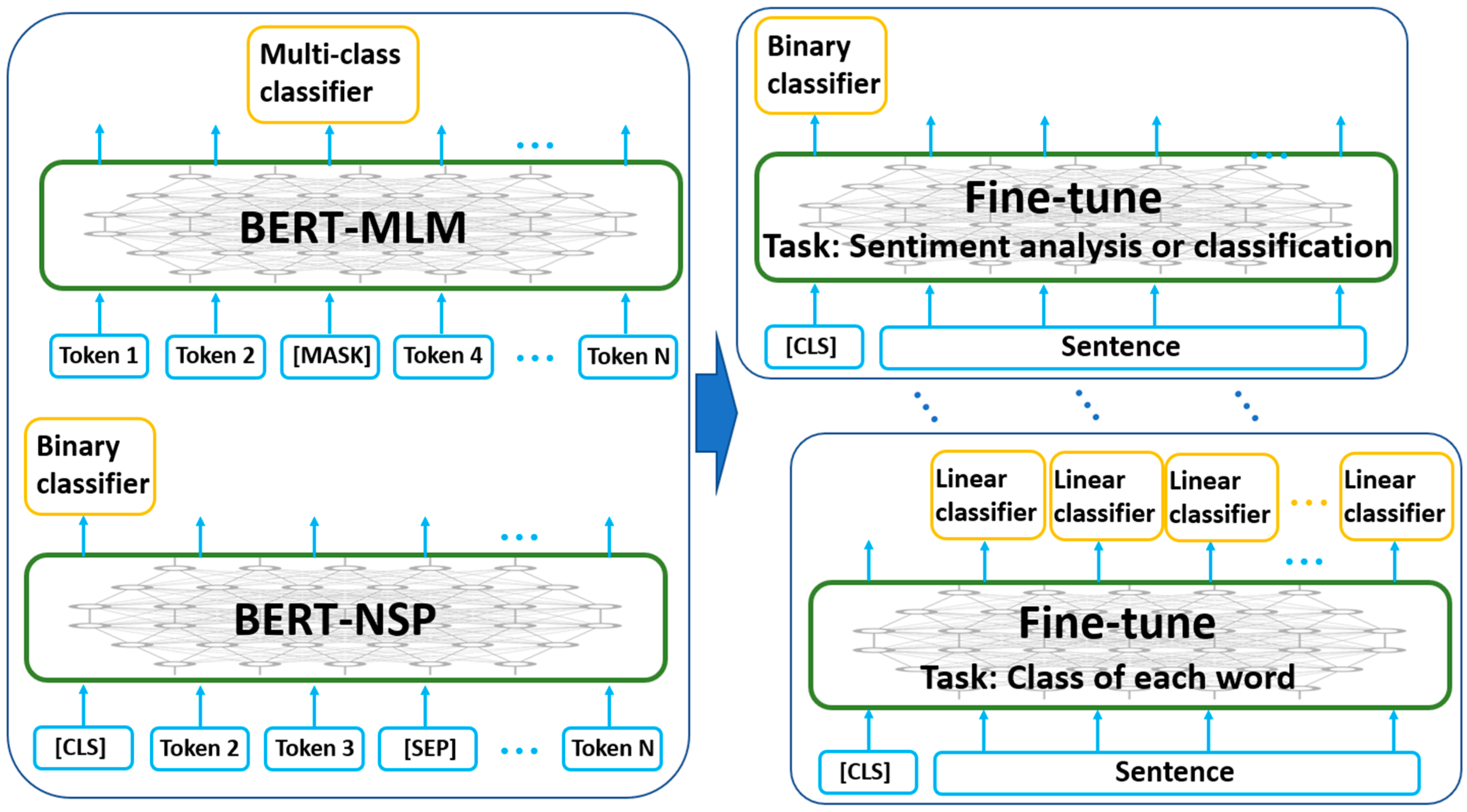
BERT
4.2.2. Energy Efficiency
ICT
Load
4.2.3. Renewable Energy
4.2.4. Sustainability and Environment
4.2.5. Context and Market
4.2.6. Land Use
5. Discussions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hedman, Å.; Rehman, H.U.; Gabaldón, A.; Bisello, A.; Albert-Seifried, V.; Zhang, X.; Guarino, F.; Grynning, S.; Eicker, U.; Neumann, H.-M.; et al. IEA EBC Annex83 Positive Energy Districts. Buildings 2021, 11, 130. [Google Scholar] [CrossRef]
- Koutra, S.; Terés-Zubiaga, J.; Bouillard, P.; Becue, V. ‘Decarbonizing Europe’ A Critical Review on Positive Energy Districts Approaches. Sustain. Cities Soc. 2023, 89, 104356. [Google Scholar] [CrossRef]
- SET-Plan ACTION N°3.2 Implementation Plan; European Commission: Brussels, Belgium, 2018.
- Bossi, S.; Gollner, C.; Theierling, S. Towards 100 Positive Energy Districts in Europe: Preliminary Data Analysis of 61 European Cases. Energies 2020, 13, 6083. [Google Scholar] [CrossRef]
- Albert-Seifried, V.; Murauskaite, L.; Massa, G.; Aelenei, L.; Baer, D.; Krangsås, S.G.; Alpagut, B.; Mutule, A.; Pokorny, N.; Vandevyvere, H. Definitions of Positive Energy Districts: A Review of the Status Quo and Challenges. In Sustainability in Energy and Buildings 2021; Littlewood, J.R., Howlett, R.J., Jain, L.C., Eds.; Smart Innovation, Systems and Technologies; Springer: Singapore, 2022; Volume 263, pp. 493–506. ISBN 9789811662683. [Google Scholar]
- Cheng, C.; Albert-Seifried, V.; Aelenei, L.; Vandevyvere, H.; Seco, O.; Nuria Sánchez, M.; Hukkalainen, M. A Systematic Approach Towards Mapping Stakeholders in Different Phases of PED Development—Extending the PED Toolbox. In Sustainability in Energy and Buildings 2021; Littlewood, J.R., Howlett, R.J., Jain, L.C., Eds.; Smart Innovation, Systems and Technologies; Springer: Singapore, 2022; Volume 263, pp. 447–463. ISBN 9789811662683. [Google Scholar]
- Belda, A.; Giancola, E.; Williams, K.; Dabirian, S.; Jradi, M.; Volpe, R.; Abolhassani, S.S.; Fichera, A.; Eicker, U. Reviewing Challenges and Limitations of Energy Modelling Software in the Assessment of PEDs Using Case Studies. In Sustainability in Energy and Buildings 2021; Littlewood, J.R., Howlett, R.J., Jain, L.C., Eds.; Smart Innovation, Systems and Technologies; Springer: Singapore, 2022; Volume 263, pp. 465–477. ISBN 9789811662683. [Google Scholar]
- Steemers, K.; Gohari Krangsas, S.; Ashrafan, T.; Giancola, E.; Konstantinou, T.; Liu, M.; Maas, N.; Murauskaite, L.; Prebreza, B.; Soutullo, S. Challenges for a Positive Energy District Framework. Sustain. Energy Build. Res. Adv. 2021, 8, 10–19. [Google Scholar] [CrossRef]
- Fatima, Z.; Padilla, M.; Kuzmic, M.; Huovila, A.; Schaj, G.; Effenberger, N. Positive Energy Districts: The 10 Replicated Solutions in Maia, Reykjavik, Kifissia, Kladno and Lviv. Smart Cities 2022, 6, 1–18. [Google Scholar] [CrossRef]
- Leone, F.; Reda, F.; Hasan, A.; Rehman, H.U.; Nigrelli, F.C.; Nocera, F.; Costanzo, V. Lessons Learned from Positive Energy District (PED) Projects: Cataloguing and Analysing Technology Solutions in Different Geographical Areas in Europe. Energies 2022, 16, 356. [Google Scholar] [CrossRef]
- Shnapp, S.; Paci, D.; Bertoldi, P. Enabling Positive Energy Districts across Europe: Energy Efficiency Couples Renewable Energy; Publications Office of the European Union: Luxembourg, 2020; ISBN 978-92-76-21043-6. [Google Scholar]
- Derkenbaeva, E.; Yoo, H.K.; Hofstede, G.J.; Galanakis, K.; Ackrill, R. Positive Energy Districts in Europe: One Size Does Not Fit All. In Proceedings of the 2022 IEEE International Smart Cities Conference (ISC2), Pafos, Cyprus, 26 September 2022; pp. 1–6. [Google Scholar]
- Bruck, A.; Díaz Ruano, S.; Auer, H. One Piece of the Puzzle towards 100 Positive Energy Districts (PEDs) across Europe by 2025: An Open-Source Approach to Unveil Favourable Locations of PV-Based PEDs from a Techno-Economic Perspective. Energy 2022, 254, 124152. [Google Scholar] [CrossRef]
- Rueda Castellanos, S.; Oregi, X. Positive Energy District (PED) Selected Projects Assessment, Study towards the Development of Further PEDs. Environ. Clim. Technol. 2021, 25, 281–294. [Google Scholar] [CrossRef]
- Zhang, X.; Penaka, S.; Giriraj, S.; Sánchez, M.; Civiero, P.; Vandevyvere, H. Characterizing Positive Energy District (PED) through a Preliminary Review of 60 Existing Projects in Europe. Buildings 2021, 11, 318. [Google Scholar] [CrossRef]
- Lindholm, O.; Rehman, H.U.; Reda, F. Positioning Positive Energy Districts in European Cities. Buildings 2021, 11, 19. [Google Scholar] [CrossRef]
- Uspenskaia, D.; Specht, K.; Kondziella, H.; Bruckner, T. Challenges and Barriers for Net-Zero/Positive Energy Buildings and Districts—Empirical Evidence from the Smart City Project SPARCS. Buildings 2021, 11, 78. [Google Scholar] [CrossRef]
- Alpagut, B.; Akyürek, Ö.; Mitre, E.M. Positive Energy Districts Methodology and Its Replication Potential. In Proceedings of the Sustainable Places 2019, Cagliari, Italy, 5–7 June 2019; p. 8. [Google Scholar]
- Bambara, J.; Athienitis, A.K.; Eicker, U. Residential Densification for Positive Energy Districts. Front. Sustain. Cities 2021, 3, 630973. [Google Scholar] [CrossRef]
- Zhou, Y.; Cao, S.; Hensen, J.L.M. An Energy Paradigm Transition Framework from Negative towards Positive District Energy Sharing Networks—Battery Cycling Aging, Advanced Battery Management Strategies, Flexible Vehicles-to-Buildings Interactions, Uncertainty and Sensitivity Analysis. Appl. Energy 2021, 288, 116606. [Google Scholar] [CrossRef]
- Civiero, P.; Pascual, J.; Arcas Abella, J.; Bilbao Figuero, A.; Salom, J. PEDRERA. Positive Energy District Renovation Model for Large Scale Actions. Energies 2021, 14, 2833. [Google Scholar] [CrossRef]
- Soutullo, S.; Aelenei, L.; Nielsen, P.S.; Ferrer, J.A.; Gonçalves, H. Testing Platforms as Drivers for Positive-Energy Living Laboratories. Energies 2020, 13, 5621. [Google Scholar] [CrossRef]
- Fatima, Z.; Pollmer, U.; Santala, S.-S.; Kontu, K.; Ticklen, M. Citizens and Positive Energy Districts: Are Espoo and Leipzig Ready for PEDs? Buildings 2021, 11, 102. [Google Scholar] [CrossRef]
- Baer, D.; Loewen, B.; Cheng, C.; Thomsen, J.; Wyckmans, A.; Temeljotov-Salaj, A.; Ahlers, D. Approaches to Social Innovation in Positive Energy Districts (PEDs)—A Comparison of Norwegian Projects. Sustainability 2021, 13, 7362. [Google Scholar] [CrossRef]
- Zhou, Y. Advances of Machine Learning in Multi-Energy District Communities—Mechanisms, Applications and Perspectives. Energy AI 2022, 10, 100187. [Google Scholar] [CrossRef]
- Zhang, X.; Shen, J.; Saini, P.K.; Lovati, M.; Han, M.; Huang, P.; Huang, Z. Digital Twin for Accelerating Sustainability in Positive Energy District: A Review of Simulation Tools and Applications. Front. Sustain. Cities 2021, 3, 663269. [Google Scholar] [CrossRef]
- Sareen, S.; Albert-Seifried, V.; Aelenei, L.; Reda, F.; Etminan, G.; Andreucci, M.-B.; Kuzmic, M.; Maas, N.; Seco, O.; Civiero, P.; et al. Ten Questions Concerning Positive Energy Districts. Build. Environ. 2022, 216, 109017. [Google Scholar] [CrossRef]
- Wei, Y.; Zhang, X.; Shi, Y.; Xia, L.; Pan, S.; Wu, J.; Han, M.; Zhao, X. A Review of Data-Driven Approaches for Prediction and Classification of Building Energy Consumption. Renew. Sustain. Energy Rev. 2018, 82, 1027–1047. [Google Scholar] [CrossRef]
- Deb, C.; Schlueter, A. Review of Data-Driven Energy Modelling Techniques for Building Retrofit. Renew. Sustain. Energy Rev. 2021, 144, 110990. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T.M. Machine Learning: Trends, Perspectives, and Prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef] [PubMed]
- Hinterberger, R.; Gollne, C.; Noll, M.; Meyer, S.; Schwarz, H.-G. White Paper on PED Reference Framework for Positive Energy Districts and Neighbourhoods; Austrian Research Promotion Agency: Wien, Austria, 2020. [Google Scholar]
- Casamassima, L.; Bottecchia, L.; Bruck, A.; Kranzl, L.; Haas, R. Economic, Social, and Environmental Aspects of Positive Energy Districts—A Review. WIREs Energy Environ. 2022, 11, e452. [Google Scholar] [CrossRef]
- Cellura, M.; Fichera, A.; Guarino, F.; Volpe, R. Sustainable Development Goals and Performance Measurement of Positive Energy District: A Methodological Approach. In Sustainability in Energy and Buildings 2021; Littlewood, J.R., Howlett, R.J., Jain, L.C., Eds.; Smart Innovation, Systems and Technologies; Springer: Singapore, 2022; Volume 263, pp. 519–527. ISBN 9789811662683. [Google Scholar]
- Guarino, F.; Bisello, A.; Frieden, D.; Bastos, J.; Brunetti, A.; Cellura, M.; Ferraro, M.; Fichera, A.; Giancola, E.; Haase, M.; et al. State of the Art on Sustainability Assessment of Positive Energy Districts: Methodologies, Indicators and Future Perspectives. In Sustainability in Energy and Buildings 2021; Littlewood, J.R., Howlett, R.J., Jain, L.C., Eds.; Smart Innovation, Systems and Technologies; Springer: Singapore, 2022; Volume 263, pp. 479–492. ISBN 9789811662683. [Google Scholar]
- Neumann, H.-M.; Garayo, S.D.; Gaitani, N.; Vettorato, D.; Aelenei, L.; Borsboom, J.; Etminan, G.; Kozlowska, A.; Reda, F.; Rose, J.; et al. Qualitative Assessment Methodology for Positive Energy District Planning Guidelines. In Sustainability in Energy and Buildings 2021; Littlewood, J.R., Howlett, R.J., Jain, L.C., Eds.; Smart Innovation, Systems and Technologies; Springer: Singapore, 2022; Volume 263, pp. 507–517. ISBN 9789811662683. [Google Scholar]
- Bottecchia, L.; Gabaldón, A.; Castillo-Calzadilla, T.; Soutullo, S.; Ranjbar, S.; Eicker, U. Fundamentals of Energy Modelling for Positive Energy Districts. In Sustainability in Energy and Buildings 2021; Littlewood, J.R., Howlett, R.J., Jain, L.C., Eds.; Smart Innovation, Systems and Technologies; Springer: Singapore, 2022; Volume 263, pp. 435–445. ISBN 9789811662683. [Google Scholar]
- Derkenbaeva, E.; Halleck Vega, S.; Hofstede, G.J.; van Leeuwen, E. Positive Energy Districts: Mainstreaming Energy Transition in Urban Areas. Renew. Sustain. Energy Rev. 2022, 153, 111782. [Google Scholar] [CrossRef]
- Ngarambe, J.; Yun, G.Y.; Santamouris, M. The Use of Artificial Intelligence (AI) Methods in the Prediction of Thermal Comfort in Buildings: Energy Implications of AI-Based Thermal Comfort Controls. Energy Build. 2020, 211, 109807. [Google Scholar] [CrossRef]
- Wang, Z.; Srinivasan, R.S. A Review of Artificial Intelligence Based Building Energy Use Prediction: Contrasting the Capabilities of Single and Ensemble Prediction Models. Renew. Sustain. Energy Rev. 2017, 75, 796–808. [Google Scholar] [CrossRef]
- Halhoul Merabet, G.; Essaaidi, M.; Ben Haddou, M.; Qolomany, B.; Qadir, J.; Anan, M.; Al-Fuqaha, A.; Abid, M.R.; Benhaddou, D. Intelligent Building Control Systems for Thermal Comfort and Energy-Efficiency: A Systematic Review of Artificial Intelligence-Assisted Techniques. Renew. Sustain. Energy Rev. 2021, 144, 110969. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, T.; Zhang, X.; Zhang, C. Artificial Intelligence-Based Fault Detection and Diagnosis Methods for Building Energy Systems: Advantages, Challenges and the Future. Renew. Sustain. Energy Rev. 2019, 109, 85–101. [Google Scholar] [CrossRef]
- Sacks, R.; Wang, Z.; Ouyang, B.; Utkucu, D.; Chen, S. Toward Artificially Intelligent Cloud-Based Building Information Modelling for Collaborative Multidisciplinary Design. Adv. Eng. Inform. 2022, 53, 101711. [Google Scholar] [CrossRef]
- Ahmed, W.; Ansari, H.; Khan, B.; Ullah, Z.; Ali, S.M.; Mehmood, C.A.A.; Qureshi, M.B.; Hussain, I.; Jawad, M.; Khan, M.U.S.; et al. Machine Learning Based Energy Management Model for Smart Grid and Renewable Energy Districts. IEEE Access 2020, 8, 185059–185078. [Google Scholar] [CrossRef]
- Ntakolia, C.; Anagnostis, A.; Moustakidis, S.; Karcanias, N. Machine Learning Applied on the District Heating and Cooling Sector: A Review. Energy Syst. 2022, 13, 1–30. [Google Scholar] [CrossRef]
- Husiev, O.; Ukar Arrien, O.; Enciso-Santocildes, M. What Does Horizon 2020 Contribute to? Analysing and Visualising the Community Practices of Europe’s Largest Research and Innovation Programme. Energy Res. Soc. Sci. 2023, 95, 102879. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. arXiv 2018, arXiv:1802.05365. [Google Scholar] [CrossRef]
- Hong, T.; Chen, Y.; Luo, X.; Luo, N.; Lee, S.H. Ten Questions on Urban Building Energy Modeling. Build. Environ. 2020, 168, 106508. [Google Scholar] [CrossRef]
- Österbring, M.; Mata, É.; Thuvander, L.; Mangold, M.; Johnsson, F.; Wallbaum, H. A Differentiated Description of Building-Stocks for a Georeferenced Urban Bottom-up Building-Stock Model. Energy Build. 2016, 120, 78–84. [Google Scholar] [CrossRef]
- Goy, S.; Maréchal, F.; Finn, D. Data for Urban Scale Building Energy Modelling: Assessing Impacts and Overcoming Availability Challenges. Energies 2020, 13, 4244. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer Science & Business Media, LLC: New York, NY, USA, 2006. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; Adaptive Computation and Machine Learning Series; The MIT Press: Cambridge, MA, USA, 2018; ISBN 978-0-262-03924-6. [Google Scholar]
- Mohri, M.; Rostamizadeh, A.; Talwalkar, A. Foundations of Machine Learning, 2nd ed.; Adaptive Computation and Machine Learning; The MIT Press: Cambridge, MA, USA, 2018; ISBN 978-0-262-03940-6. [Google Scholar]
- Foucquier, A.; Robert, S.; Suard, F.; Stéphan, L.; Jay, A. State of the Art in Building Modelling and Energy Performances Prediction: A Review. Renew. Sustain. Energy Rev. 2013, 23, 272–288. [Google Scholar] [CrossRef]
- Amasyali, K.; El-Gohary, N.M. A Review of Data-Driven Building Energy Consumption Prediction Studies. Renew. Sustain. Energy Rev. 2018, 81, 1192–1205. [Google Scholar] [CrossRef]
- Alasadi, S.A.; Bhaya, W.S. Review of Data Preprocessing Techniques in Data Mining. J. Eng. Appl. Sci. 2017, 12, 4102–4107. [Google Scholar]
- Ayoub, M. A Review on Machine Learning Algorithms to Predict Daylighting inside Buildings. Sol. Energy 2020, 202, 249–275. [Google Scholar] [CrossRef]
- Wu, J.; Chen, X.-Y.; Zhang, H.; Xiong, L.-D.; Lei, H.; Deng, S.-H. Hyperparameter Optimization for Machine Learning Models Based on Bayesian Optimization. J. Electron. Sci. Technol. 2019, 17, 26–40. [Google Scholar]
- Seyedzadeh, S.; Rahimian, F.P.; Glesk, I.; Roper, M. Machine Learning for Estimation of Building Energy Consumption and Performance: A Review. Vis. Eng. 2018, 6, 5. [Google Scholar] [CrossRef]
- Conforti, C.; Hirmer, S.; Morgan, D.; Basaldella, M.; Or, Y.B. Natural Language Processing for Achieving Sustainable Development: The Case of Neural Labelling to Enhance Community Profiling. arXiv 2020, arXiv:2004.12935. [Google Scholar] [CrossRef]
- Tshitoyan, V.; Dagdelen, J.; Weston, L.; Dunn, A.; Rong, Z.; Kononova, O.; Persson, K.A.; Ceder, G.; Jain, A. Unsupervised Word Embeddings Capture Latent Knowledge from Materials Science Literature. Nature 2019, 571, 95–98. [Google Scholar] [CrossRef] [PubMed]
- Zekić-Sušac, M.; Mitrović, S.; Has, A. Machine Learning Based System for Managing Energy Efficiency of Public Sector as an Approach towards Smart Cities. Int. J. Inf. Manag. 2021, 58, 102074. [Google Scholar] [CrossRef]
- Narciso, D.A.C.; Martins, F.G. Application of Machine Learning Tools for Energy Efficiency in Industry: A Review. Energy Rep. 2020, 6, 1181–1199. [Google Scholar] [CrossRef]
- Zhang, W.; Wu, Y.; Calautit, J.K. A Review on Occupancy Prediction through Machine Learning for Enhancing Energy Efficiency, Air Quality and Thermal Comfort in the Built Environment. Renew. Sustain. Energy Rev. 2022, 167, 112704. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, J.; Zhang, Y.; Yuan, H.; Zhang, R.; Srinivasan, R.S. Practical Issues in Implementing Machine-Learning Models for Building Energy Efficiency: Moving beyond Obstacles. Renew. Sustain. Energy Rev. 2021, 143, 110929. [Google Scholar] [CrossRef]
- Said, O.; Tolba, A. Accurate Performance Prediction of IoT Communication Systems for Smart Cities: An Efficient Deep Learning Based Solution. Sustain. Cities Soc. 2021, 69, 102830. [Google Scholar] [CrossRef]
- Ullah, Z.; Al-Turjman, F.; Mostarda, L.; Gagliardi, R. Applications of Artificial Intelligence and Machine Learning in Smart Cities. Comput. Commun. 2020, 154, 313–323. [Google Scholar] [CrossRef]
- Bhattacharya, S.; Somayaji, S.R.K.; Gadekallu, T.R.; Alazab, M.; Maddikunta, P.K.R. A Review on Deep Learning for Future Smart Cities. Internet Technol. Lett. 2022, 5, e187. [Google Scholar] [CrossRef]
- Serrano, W. Deep Reinforcement Learning Algorithms in Intelligent Infrastructure. Infrastructures 2019, 4, 52. [Google Scholar] [CrossRef]
- Benavente-Peces, C.; Ibadah, N. Buildings Energy Efficiency Analysis and Classification Using Various Machine Learning Technique Classifiers. Energies 2020, 13, 3497. [Google Scholar] [CrossRef]
- Olu-Ajayi, R.; Alaka, H.; Sulaimon, I.; Sunmola, F.; Ajayi, S. Building Energy Consumption Prediction for Residential Buildings Using Deep Learning and Other Machine Learning Techniques. J. Build. Eng. 2022, 45, 103406. [Google Scholar] [CrossRef]
- Shapi, M.K.M.; Ramli, N.A.; Awalin, L.J. Energy Consumption Prediction by Using Machine Learning for Smart Building: Case Study in Malaysia. Dev. Built Environ. 2021, 5, 100037. [Google Scholar] [CrossRef]
- Khalil, M.; McGough, A.S.; Pourmirza, Z.; Pazhoohesh, M.; Walker, S. Machine Learning, Deep Learning and Statistical Analysis for Forecasting Building Energy Consumption—A Systematic Review. Eng. Appl. Artif. Intell. 2022, 115, 105287. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, D.; Liu, Y.; Han, Z.; Lun, L.; Gao, J.; Jin, G.; Cao, G. Accuracy Analyses and Model Comparison of Machine Learning Adopted in Building Energy Consumption Prediction. Energy Explor. Exploit. 2019, 37, 1426–1451. [Google Scholar] [CrossRef]
- Wang, Z.; Hong, T.; Piette, M.A. Building Thermal Load Prediction through Shallow Machine Learning and Deep Learning. Appl. Energy 2020, 263, 114683. [Google Scholar] [CrossRef]
- Forouzandeh, N.; Zomorodian, Z.S.; Shaghaghian, Z.; Tahsildoost, M. Room Energy Demand and Thermal Comfort Predictions in Early Stages of Design Based on the Machine Learning Methods. Intell. Build. Int. 2022, 15, 3–20. [Google Scholar] [CrossRef]
- Fathi, S.; Srinivasan, R.; Fenner, A.; Fathi, S. Machine Learning Applications in Urban Building Energy Performance Forecasting: A Systematic Review. Renew. Sustain. Energy Rev. 2020, 133, 110287. [Google Scholar] [CrossRef]
- Ahmadiahangar, R.; Haring, T.; Rosin, A.; Korotko, T.; Martins, J. Residential Load Forecasting for Flexibility Prediction Using Machine Learning-Based Regression Model. In Proceedings of the 2019 IEEE International Conference on Environment and Electrical Engineering and 2019 IEEE Industrial and Commercial Power Systems Europe (EEEIC/I&CPS Europe), Genova, Italy, 11–14 June 2019; pp. 1–4. [Google Scholar]
- Kim, S.-G.; Jung, J.-Y.; Sim, M. A Two-Step Approach to Solar Power Generation Prediction Based on Weather Data Using Machine Learning. Sustainability 2019, 11, 1501. [Google Scholar] [CrossRef]
- Avila, D.; Marichal, G.N.; Padrón, I.; Quiza, R.; Hernández, Á. Forecasting of Wave Energy in Canary Islands Based on Artificial Intelligence. Appl. Ocean Res. 2020, 101, 102189. [Google Scholar] [CrossRef]
- Zhang, Z.; Ye, L.; Qin, H.; Liu, Y.; Wang, C.; Yu, X.; Yin, X.; Li, J. Wind Speed Prediction Method Using Shared Weight Long Short-Term Memory Network and Gaussian Process Regression. Appl. Energy 2019, 247, 270–284. [Google Scholar] [CrossRef]
- Zhang, X.; Peng, Y.; Xu, W.; Wang, B. An Optimal Operation Model for Hydropower Stations Considering Inflow Forecasts with Different Lead-Times. Water Resour. Manag. 2019, 33, 173–188. [Google Scholar] [CrossRef]
- khan, M.; Raza Naqvi, S.; Ullah, Z.; Ali Ammar Taqvi, S.; Nouman Aslam Khan, M.; Farooq, W.; Taqi Mehran, M.; Juchelková, D.; Štěpanec, L. Applications of Machine Learning in Thermochemical Conversion of Biomass-A Review. Fuel 2023, 332, 126055. [Google Scholar] [CrossRef]
- Okoroafor, E.R.; Smith, C.M.; Ochie, K.I.; Nwosu, C.J.; Gudmundsdottir, H.; Aljubran, M.J. Machine Learning in Subsurface Geothermal Energy: Two Decades in Review. Geothermics 2022, 102, 102401. [Google Scholar] [CrossRef]
- Khan, P.W.; Byun, Y.-C.; Lee, S.-J.; Kang, D.-H.; Kang, J.-Y.; Park, H.-S. Machine Learning-Based Approach to Predict Energy Consumption of Renewable and Nonrenewable Power Sources. Energies 2020, 13, 4870. [Google Scholar] [CrossRef]
- Abd El-Aziz, R.M. Renewable Power Source Energy Consumption by Hybrid Machine Learning Model. Alex. Eng. J. 2022, 61, 9447–9455. [Google Scholar] [CrossRef]
- Aslam, M.; Lee, J.-M.; Kim, H.-S.; Lee, S.-J.; Hong, S. Deep Learning Models for Long-Term Solar Radiation Forecasting Considering Microgrid Installation: A Comparative Study. Energies 2019, 13, 147. [Google Scholar] [CrossRef]
- Malakouti, S.M. Use Machine Learning Algorithms to Predict Turbine Power Generation to Replace Renewable Energy with Fossil Fuels. Energy Explor. Exploit. 2023, 41, 836–857. [Google Scholar] [CrossRef]
- Rohani, A.; Taki, M.; Abdollahpour, M. A Novel Soft Computing Model (Gaussian Process Regression with K-Fold Cross Validation) for Daily and Monthly Solar Radiation Forecasting (Part: I). Renew. Energy 2018, 115, 411–422. [Google Scholar] [CrossRef]
- Kaab, A.; Sharifi, M.; Mobli, H.; Nabavi-Pelesaraei, A.; Chau, K. Combined Life Cycle Assessment and Artificial Intelligence for Prediction of Output Energy and Environmental Impacts of Sugarcane Production. Sci. Total Environ. 2019, 664, 1005–1019. [Google Scholar] [CrossRef] [PubMed]
- Nilashi, M.; Rupani, P.F.; Rupani, M.M.; Kamyab, H.; Shao, W.; Ahmadi, H.; Rashid, T.A.; Aljojo, N. Measuring Sustainability through Ecological Sustainability and Human Sustainability: A Machine Learning Approach. J. Clean. Prod. 2019, 240, 118162. [Google Scholar] [CrossRef]
- Valladares, W.; Galindo, M.; Gutiérrez, J.; Wu, W.-C.; Liao, K.-K.; Liao, J.-C.; Lu, K.-C.; Wang, C.-C. Energy Optimization Associated with Thermal Comfort and Indoor Air Control via a Deep Reinforcement Learning Algorithm. Build. Environ. 2019, 155, 105–117. [Google Scholar] [CrossRef]
- Kim, J.; Zhou, Y.; Schiavon, S.; Raftery, P.; Brager, G. Personal Comfort Models: Predicting Individuals’ Thermal Preference Using Occupant Heating and Cooling Behavior and Machine Learning. Build. Environ. 2018, 129, 96–106. [Google Scholar] [CrossRef]
- Pinto, G.; Deltetto, D.; Capozzoli, A. Data-Driven District Energy Management with Surrogate Models and Deep Reinforcement Learning. Appl. Energy 2021, 304, 117642. [Google Scholar] [CrossRef]
- Han, M.; May, R.; Zhang, X.; Wang, X.; Pan, S.; Yan, D.; Jin, Y.; Xu, L. A Review of Reinforcement Learning Methodologies for Controlling Occupant Comfort in Buildings. Sustain. Cities Soc. 2019, 51, 101748. [Google Scholar] [CrossRef]
- Das, H.S.; Roy, P. A Deep Dive Into Deep Learning Techniques for Solving Spoken Language Identification Problems. In Intelligent Speech Signal Processing; Elsevier: Amsterdam, The Netherlands, 2019; pp. 81–100. ISBN 978-0-12-818130-0. [Google Scholar]
- Olu-Ajayi, R.; Alaka, H.; Sulaimon, I.; Sunmola, F.; Ajayi, S. Machine Learning for Energy Performance Prediction at the Design Stage of Buildings. Energy Sustain. Dev. 2022, 66, 12–25. [Google Scholar] [CrossRef]
- Wang, H.; Lei, Z.; Zhang, X.; Zhou, B.; Peng, J. A Review of Deep Learning for Renewable Energy Forecasting. Energy Convers. Manag. 2019, 198, 111799. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ma, J.; Cheng, J.C.P. Identifying the Influential Features on the Regional Energy Use Intensity of Residential Buildings Based on Random Forests. Appl. Energy 2016, 183, 193–201. [Google Scholar] [CrossRef]
- Lai, J.-P.; Chang, Y.-M.; Chen, C.-H.; Pai, P.-F. A Survey of Machine Learning Models in Renewable Energy Predictions. Appl. Sci. 2020, 10, 5975. [Google Scholar] [CrossRef]
- De Las Heras, A.; Luque-Sendra, A.; Zamora-Polo, F. Machine Learning Technologies for Sustainability in Smart Cities in the Post-COVID Era. Sustainability 2020, 12, 9320. [Google Scholar] [CrossRef]
- Rangel-Martinez, D.; Nigam, K.D.P.; Ricardez-Sandoval, L.A. Machine Learning on Sustainable Energy: A Review and Outlook on Renewable Energy Systems, Catalysis, Smart Grid and Energy Storage. Chem. Eng. Res. Des. 2021, 174, 414–441. [Google Scholar] [CrossRef]
- Ding, Z.; Liu, R.; Li, Z.; Fan, C. A Thematic Network-Based Methodology for the Research Trend Identification in Building Energy Management. Energies 2020, 13, 4621. [Google Scholar] [CrossRef]
- Khanuja, A.; Webb, A.L. What We Talk about When We Talk about EEMs: Using Text Mining and Topic Modeling to Understand Building Energy Efficiency Measures (1836-RP). Sci. Technol. Built Environ. 2023, 29, 4–18. [Google Scholar] [CrossRef]
- Chen, W.; Zhou, Y.; Wu, Q.; Chen, G.; Huang, X.; Yu, B. Urban Building Type Mapping Using Geospatial Data: A Case Study of Beijing, China. Remote Sens. 2020, 12, 2805. [Google Scholar] [CrossRef]
- Xue, X.; Zhang, J. Part-of-Speech Tagging of Building Codes Empowered by Deep Learning and Transformational Rules. Adv. Eng. Inform. 2021, 47, 101235. [Google Scholar] [CrossRef]
- Ding, Z.; Li, Z.; Fan, C. Building Energy Savings: Analysis of Research Trends Based on Text Mining. Autom. Constr. 2018, 96, 398–410. [Google Scholar] [CrossRef]
- Bickel, M.W. Reflecting Trends in the Academic Landscape of Sustainable Energy Using Probabilistic Topic Modeling. Energy Sustain. Soc. 2019, 9, 49. [Google Scholar] [CrossRef]
- Jeong, S.-Y.; Kim, J.-W.; Joo, H.-Y.; Kim, Y.-S.; Moon, J.-H. Development and Application of a Big Data Analysis-Based Procedure to Identify Concerns about Renewable Energy. Energies 2021, 14, 4977. [Google Scholar] [CrossRef]
- Saheb, T.; Dehghani, M.; Saheb, T. Artificial Intelligence for Sustainable Energy: A Contextual Topic Modeling and Content Analysis. Sustain. Comput. Inform. Syst. 2022, 35, 100699. [Google Scholar] [CrossRef]
- Wu, Z.; He, Q.; Chen, Q.; Xue, H.; Li, S. A Topical Network Based Analysis and Visualization of Global Research Trends on Green Building from 1990 to 2020. J. Clean. Prod. 2021, 320, 128818. [Google Scholar] [CrossRef]
- Abdelrahman, M.M.; Zhan, S.; Miller, C.; Chong, A. Data Science for Building Energy Efficiency: A Comprehensive Text-Mining Driven Review of Scientific Literature. Energy Build. 2021, 242, 110885. [Google Scholar] [CrossRef]
- Wang, B.; Wang, Z. Heterogeneity Evaluation of China’s Provincial Energy Technology Based on Large-Scale Technical Text Data Mining. J. Clean. Prod. 2018, 202, 946–958. [Google Scholar] [CrossRef]
- Lai, Y.; Papadopoulos, S.; Fuerst, F.; Pivo, G.; Sagi, J.; Kontokosta, C.E. Building Retrofit Hurdle Rates and Risk Aversion in Energy Efficiency Investments. Appl. Energy 2022, 306, 118048. [Google Scholar] [CrossRef]
- Copiello, S. Economic Parameters in the Evaluation Studies Focusing on Building Energy Efficiency: A Review of the Underlying Rationale, Data Sources, and Assumptions. Energy Procedia 2019, 157, 180–192. [Google Scholar] [CrossRef]
- Zeng, R.; Chini, A. A Review of Research on Embodied Energy of Buildings Using Bibliometric Analysis. Energy Build. 2017, 155, 172–184. [Google Scholar] [CrossRef]
- Jung, N.; Lee, G. Automated Classification of Building Information Modeling (BIM) Case Studies by BIM Use Based on Natural Language Processing (NLP) and Unsupervised Learning. Adv. Eng. Inform. 2019, 41, 100917. [Google Scholar] [CrossRef]
- Waterworth, D.; Sethuvenkatraman, S.; Sheng, Q.Z. Advancing Smart Building Readiness: Automated Metadata Extraction Using Neural Language Processing Methods. Adv. Appl. Energy 2021, 3, 100041. [Google Scholar] [CrossRef]
- Xue, X.; Zhang, J. Building Codes Part-of-Speech Tagging Performance Improvement by Error-Driven Transformational Rules. J. Comput. Civ. Eng. 2020, 34, 04020035. [Google Scholar] [CrossRef]
- Jiao, Y.; Li, J.; Wu, J.; Hong, D.; Gupta, R.; Shang, J. SeNsER: Learning Cross-Building Sensor Metadata Tagger. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 950–960. [Google Scholar]
- Zhan, S.; Chong, A.; Lasternas, B. Automated Recognition and Mapping of Building Management System (BMS) Data Points for Building Energy Modeling (BEM). Build. Simul. 2021, 14, 43–52. [Google Scholar] [CrossRef]
- Stinner, F.; Neißer-Deiters, P.; Baranski, M.; Müller, D. Aikido: Structuring Data Point Identifiers of Technical Building Equipment by Machine Learning. J. Phys. Conf. Ser. 2019, 1343, 012039. [Google Scholar] [CrossRef]
- Nalmpantis, C.; Krystalakos, O.; Vrakas, D. Energy Profile Representation in Vector Space. In Proceedings of the 10th Hellenic Conference on Artificial Intelligence, Patras, Greece, 9–12 July 2018; pp. 1–5. [Google Scholar]
- Peng, J.; Kimmig, A.; Wang, J.; Liu, X.; Niu, Z.; Ovtcharova, J. Dual-Stage Attention-Based Long-Short-Term Memory Neural Networks for Energy Demand Prediction. Energy Build. 2021, 249, 111211. [Google Scholar] [CrossRef]
- Nie, Z.; Yang, Y.; Xu, Q. An Ensemble-Policy Non-Intrusive Load Monitoring Technique Based Entirely on Deep Feature-Guided Attention Mechanism. Energy Build. 2022, 273, 112356. [Google Scholar] [CrossRef]
- Abdelaziz, A.; Santos, V.; Dias, M.S. Machine Learning Techniques in the Energy Consumption of Buildings: A Systematic Literature Review Using Text Mining and Bibliometric Analysis. Energies 2021, 14, 7810. [Google Scholar] [CrossRef]
- Kumar, M.; Ng, J. Using Text Mining and Topic Modelling to Understand Success and Growth Factors in Global Renewable Energy Projects. Renew. Energy Focus 2022, 42, 211–220. [Google Scholar] [CrossRef]
- Kim, S.Y.; Ganesan, K.; Dickens, P.; Panda, S. Public Sentiment toward Solar Energy—Opinion Mining of Twitter Using a Transformer-Based Language Model. Sustainability 2021, 13, 2673. [Google Scholar] [CrossRef]
- Milia, M.F. Global Trends, Local Threads. The Thematic Orientation of Renewable Energy Research in Mexico and Argentina between 1992 and 2016. JSCIRES 2021, 10, s32–s45. [Google Scholar] [CrossRef]
- Acaru, S.F.; Abdullah, R.; Lai, D.T.C.; Lim, R.C. Hydrothermal Biomass Processing for Green Energy Transition: Insights Derived from Principal Component Analysis of International Patents. Heliyon 2022, 8, e10738. [Google Scholar] [CrossRef] [PubMed]
- Jain, A.; Jain, V. Sentiment Classification of Twitter Data Belonging to Renewable Energy Using Machine Learning. J. Inf. Optim. Sci. 2019, 40, 521–533. [Google Scholar] [CrossRef]
- Matsui, T.; Suzuki, K.; Ando, K.; Kitai, Y.; Haga, C.; Masuhara, N.; Kawakubo, S. A Natural Language Processing Model for Supporting Sustainable Development Goals: Translating Semantics, Visualizing Nexus, and Connecting Stakeholders. Sustain. Sci. 2022, 17, 969–985. [Google Scholar] [CrossRef] [PubMed]
- Tie, M.; Zhu, M. Interpreting Low-Carbon Transition at the Subnational Level: Evidence from China Using a Natural Language Processing Approach. Resour. Conserv. Recycl. 2022, 187, 106636. [Google Scholar] [CrossRef]
- Nicolas, C.; Kim, J.; Chi, S. Natural Language Processing-Based Characterization of Top-down Communication in Smart Cities for Enhancing Citizen Alignment. Sustain Cities Soc. 2021, 66, 102674. [Google Scholar] [CrossRef]
- Cai, R.; Qin, B.; Chen, Y.; Zhang, L.; Yang, R.; Chen, S.; Wang, W. Sentiment Analysis About Investors and Consumers in Energy Market Based on BERT-BiLSTM. IEEE Access 2020, 8, 171408–171415. [Google Scholar] [CrossRef]
- Yao, Y.; Li, X.; Liu, X.; Liu, P.; Liang, Z.; Zhang, J.; Mai, K. Sensing Spatial Distribution of Urban Land Use by Integrating Points-of-Interest and Google Word2Vec Model. Int. J. Geogr. Inf. Sci. 2017, 31, 825–848. [Google Scholar] [CrossRef]
- Zhai, W.; Bai, X.; Shi, Y.; Han, Y.; Peng, Z.-R.; Gu, C. Beyond Word2vec: An Approach for Urban Functional Region Extraction and Identification by Combining Place2vec and POIs. Comput. Environ. Urban Syst. 2019, 74, 1–12. [Google Scholar] [CrossRef]
- Zhong, Y.; Su, Y.; Wu, S.; Zheng, Z.; Zhao, J.; Ma, A.; Zhu, Q.; Ye, R.; Li, X.; Pellikka, P.; et al. Open-Source Data-Driven Urban Land-Use Mapping Integrating Point-Line-Polygon Semantic Objects: A Case Study of Chinese Cities. Remote Sens. Environ. 2020, 247, 111838. [Google Scholar] [CrossRef]
- Yuan, J.; Zheng, Y.; Xie, X. Discovering Regions of Different Functions in a City Using Human Mobility and POIs. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 186–194. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. arXiv 2013, arXiv:1310.4546. [Google Scholar] [CrossRef]
- Rong, X. Word2vec Parameter Learning Explained. arXiv 2016, arXiv:1411.2738. [Google Scholar]
- Blei, D.M.; NG, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Blei, D.M. Probabilistic Topic Models. Commun. ACM 2012, 55, 77–84. [Google Scholar] [CrossRef]
- Asuncion, A.; Welling, M.; Smyth, P.; Teh, Y.W. On Smoothing and Inference for Topic Models. arXiv 2012, arXiv:1205.2662. [Google Scholar] [CrossRef]
- ASHRAE Standard 100-2018; Energy Efficiency in Existing Buildings. ASHRAE: Atlanta, GA, USA, 2018.
- Zhivov, A.; Cyrus, N. Energy Efficient Technologies and Measures for Building Renovation: Sourcebook. IEA ECBS Annex 46. 2014. Available online: https://www.iea-ebc.org/Data/publications/EBC_Annex_46_Technologies_and_Measures_Sourcebook.pdf (accessed on 25 January 2024).
- Doty, S. Commercial Energy Auditing Reference Handbook, 2nd ed.; Fairmont Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- National Renewable Energy Laboratory. National Residential Energy Efficiency Measures Database, Version 3.1.0. 2018. Available online: https://remdb.nrel.gov/ (accessed on 25 January 2024).
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar] [CrossRef]
- Neumann, H.-M.; Hainoun, A.; Stollnberger, R.; Etminan, G.; Schaffler, V. Analysis and Evaluation of the Feasibility of Positive Energy Districts in Selected Urban Typologies in Vienna Using a Bottom-Up District Energy Modelling Approach. Energies 2021, 14, 4449. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
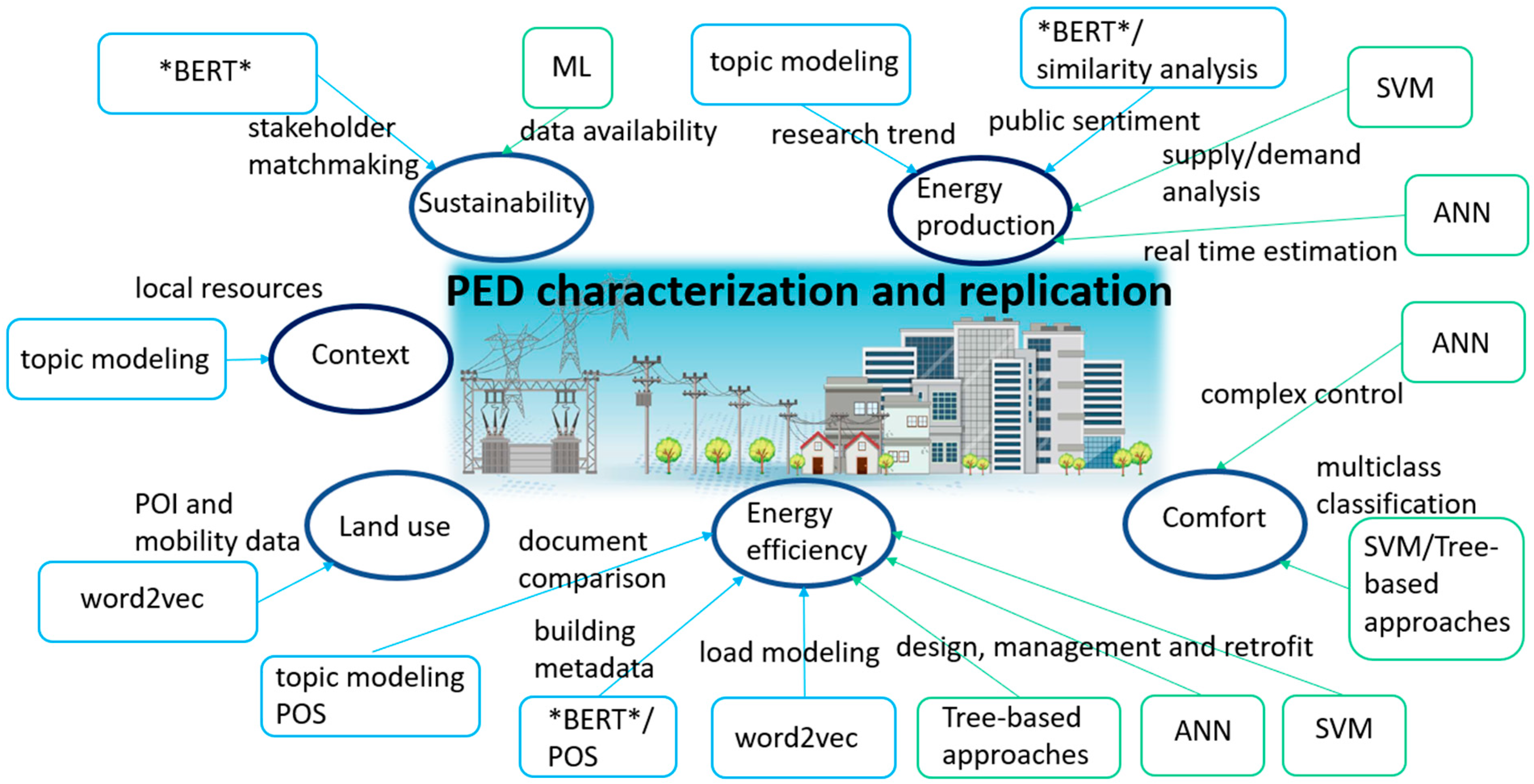{kind=link}
| PED Elements | ML Method | |||
|---|---|---|---|---|
| ANN | SVM | Tree-Based Approaches | Other | |
| Energy efficiency | [62,63,64,65] | [63,64,65] | [62,64,65] | [63,64,65] |
| [66,67,68,69,70] | [67] | [67,69] | |
| [71,72,73,74,75,76,77] | [71,72,73,74,75,77] | [73,75,76,77] | [73,75,76,77,78] |
| Energy production | ||||
| [79,80,81,82,83,84,85,86] | [79,84,85,86,87] | [84,85,86,88] | [81,84,89] |
| Sustainability | [90] | [91] | [90,91] | |
| Comfort | [92] | [93] | [93] | [92,93,94,95] |
| PED Elements | NLP Method | ||||||
|---|---|---|---|---|---|---|---|
| Word2vec | Topic Modeling | *BERT* | POS | TF-IDF | Similarity/Co-Occurrence | Other | |
| Energy efficiency | [105,114] | [105,106,115] | [106,116] | [117,118] | |||
| [107,119] | [108,120] | [108,121] | [107] | [122,123,124] | ||
| [125,126,127] | [109] | [109] | [128] | |||
| Energy production | |||||||
| [110,115,129] | [130] | [110] | [111] | [111] | [131,132,133] | |
| Sustainability | [112] | [112,134] | |||||
| [113] | [113] | |||||
| Context | [135,136] | ||||||
| Market | [137] | ||||||
| Land use | [138,139,140] | [141] | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, M.; Canli, I.; Shah, J.; Zhang, X.; Dino, I.G.; Kalkan, S. Perspectives of Machine Learning and Natural Language Processing on Characterizing Positive Energy Districts. Buildings 2024, 14, 371. https://doi.org/10.3390/buildings14020371
Han M, Canli I, Shah J, Zhang X, Dino IG, Kalkan S. Perspectives of Machine Learning and Natural Language Processing on Characterizing Positive Energy Districts. Buildings. 2024; 14(2):371. https://doi.org/10.3390/buildings14020371
Chicago/Turabian StyleHan, Mengjie, Ilkim Canli, Juveria Shah, Xingxing Zhang, Ipek Gursel Dino, and Sinan Kalkan. 2024. "Perspectives of Machine Learning and Natural Language Processing on Characterizing Positive Energy Districts" Buildings 14, no. 2: 371. https://doi.org/10.3390/buildings14020371
APA StyleHan, M., Canli, I., Shah, J., Zhang, X., Dino, I. G., & Kalkan, S. (2024). Perspectives of Machine Learning and Natural Language Processing on Characterizing Positive Energy Districts. Buildings, 14(2), 371. https://doi.org/10.3390/buildings14020371