
A Representation Generation Approach of Transmission Gear Based on Conditional Generative Adversarial Network


Abstract
:1. Introduction
- 1.
- A novel approach is proposed as a pretreatment for the gear reliability assessment of vehicle transmissions. With an estimated global distribution, this approach produces credible transmission gear representations to expand existing space and raises the efficiency of the gear reliability assessment.
- 2.
- In the CGAN-based model, label information gains access to the distribution estimation to generate representations guided by label distribution. Furthermore, we introduce a mini-batch strategy to randomly sample original and forged representations from the generator and send these representations into the discriminator for differentiation, strengthening the diversity of generated representations.
- 3.
- The proposed WL scheme names the generated representations based on the measurement between these representations and Wasserstein barycenter of gear reliability degrees. This scheme offsets the unlabeled ability of GAN and provides available labels for classifiers.
2. Background and Related Works
2.1. Transmission Gear Reliability
2.2. Generative Adversarial Networks
3. Materials and Methods
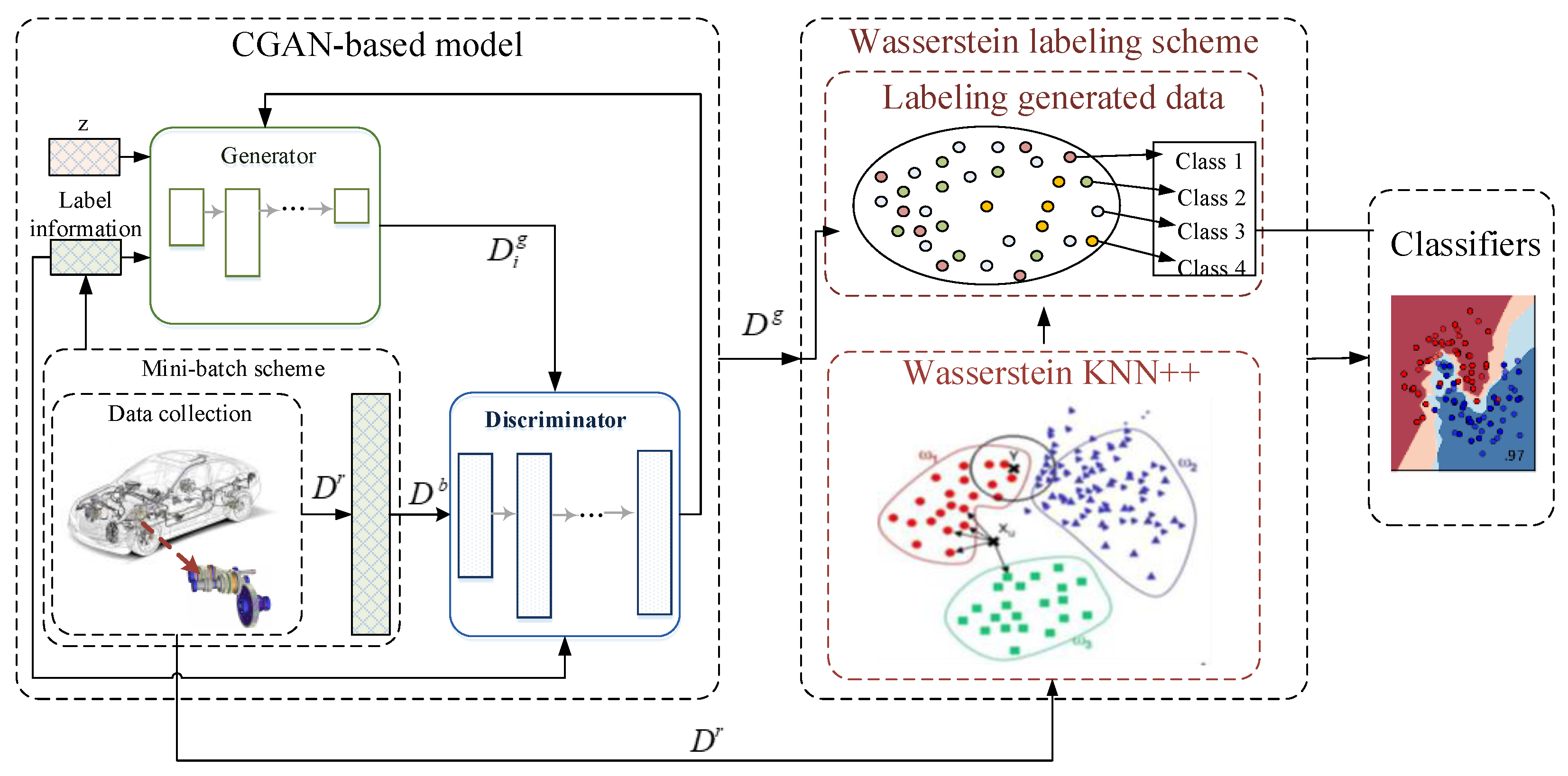
3.1. CGAN-Based Model
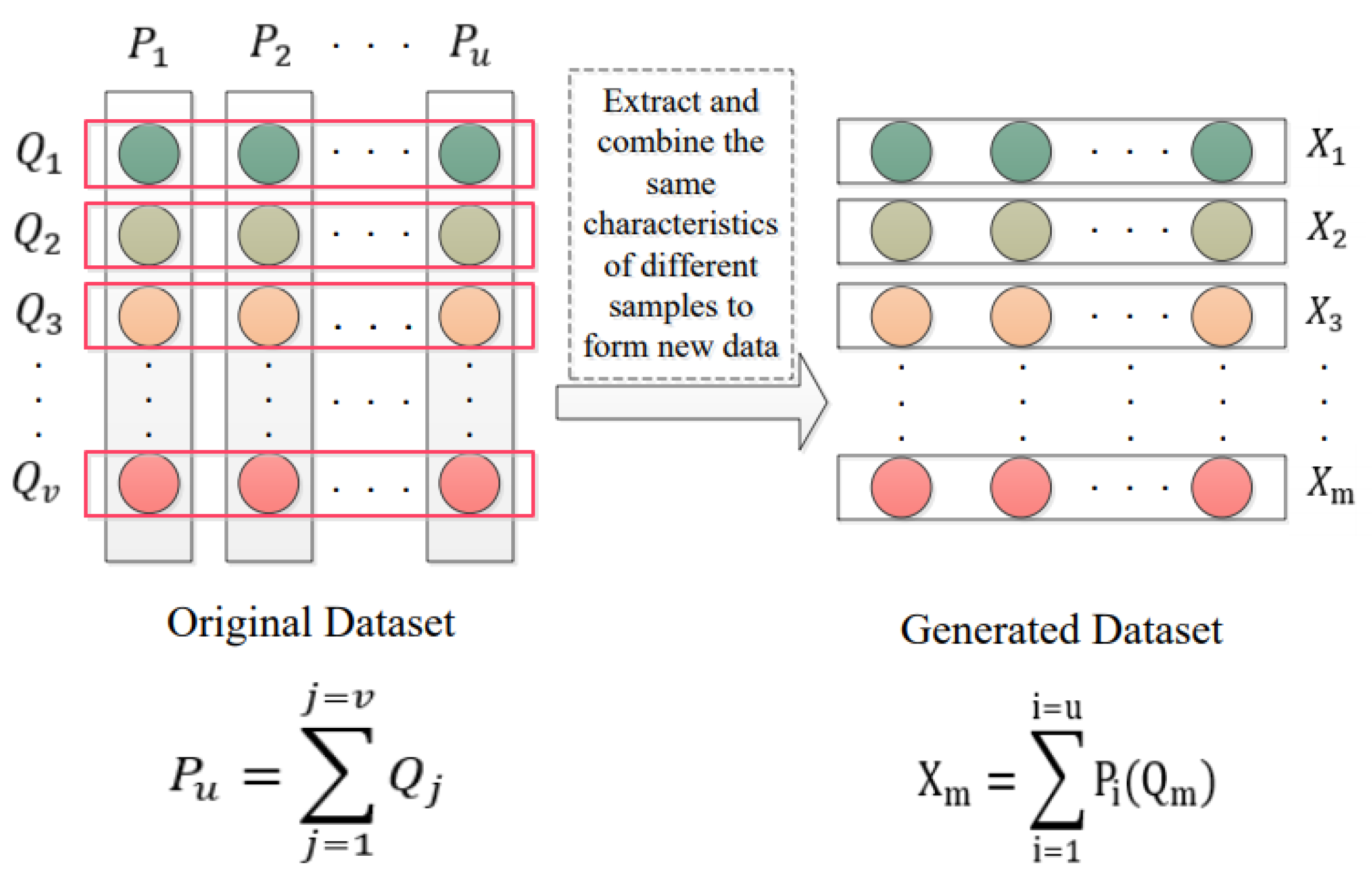
3.1.1. Data Processing
3.1.2. Model Structure
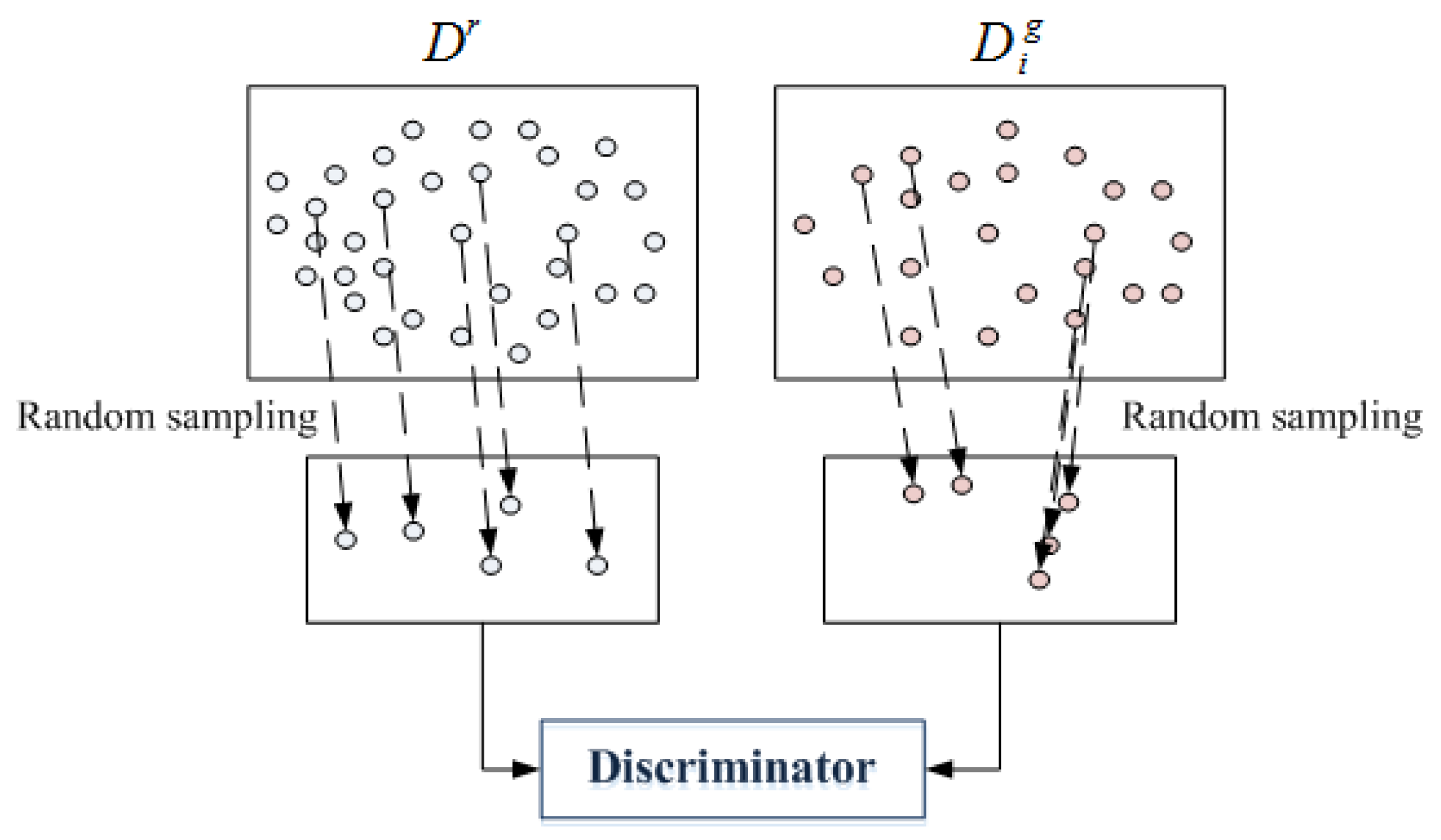
3.1.3. Mini-Batch Scheme
| Algorithm 1: CGAN-based model for extracting the generated representations without label information |
 |
3.1.4. Network Optimization
3.2. Wasserstein Labeling Scheme
3.2.1. Wasserstein Barycenter
| Algorithm 2: Wasserstein labeling scheme for assigning labels to the generated representations |
 |
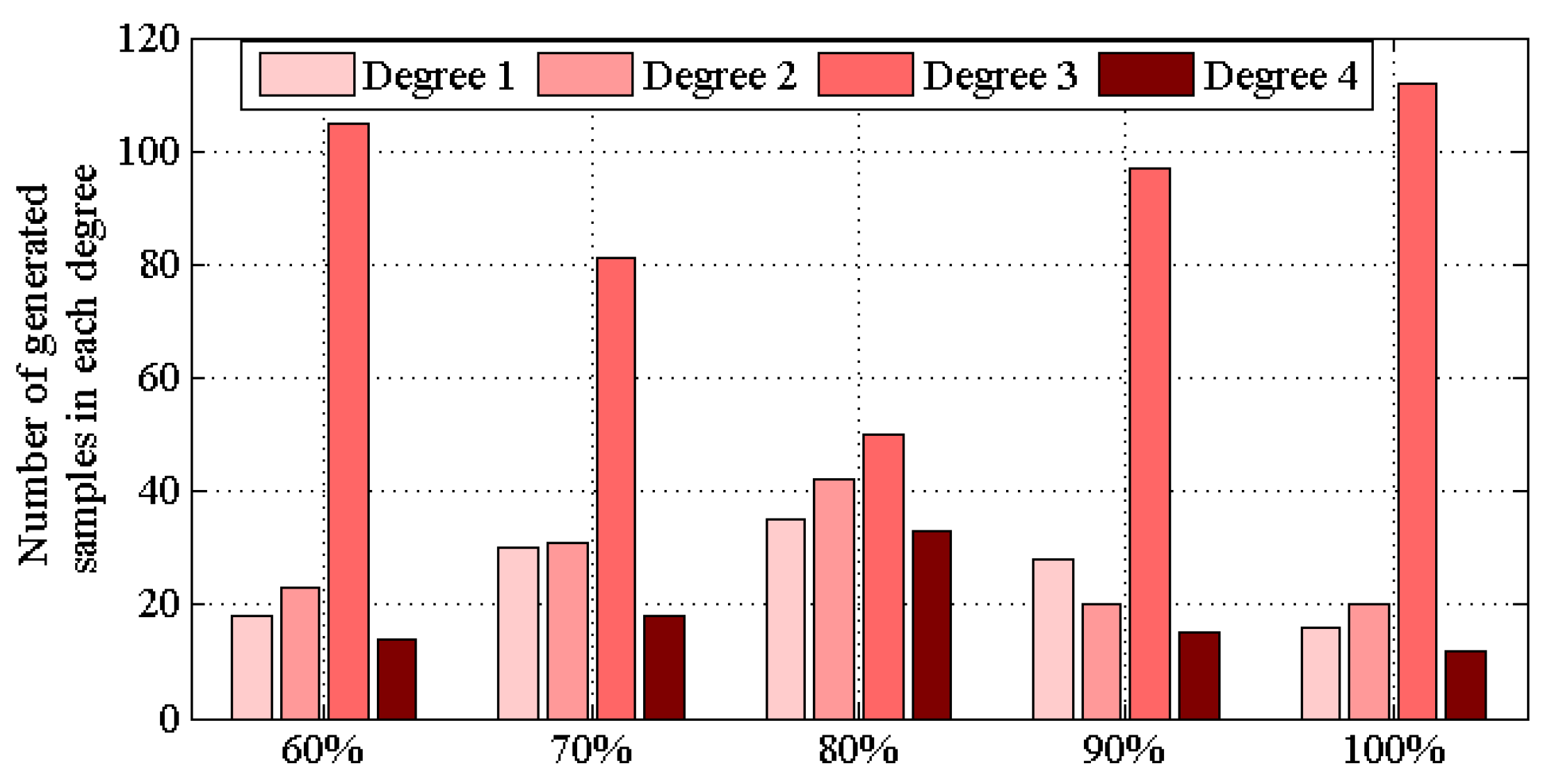
3.2.2. Labeling Generated Data
3.3. Discussion
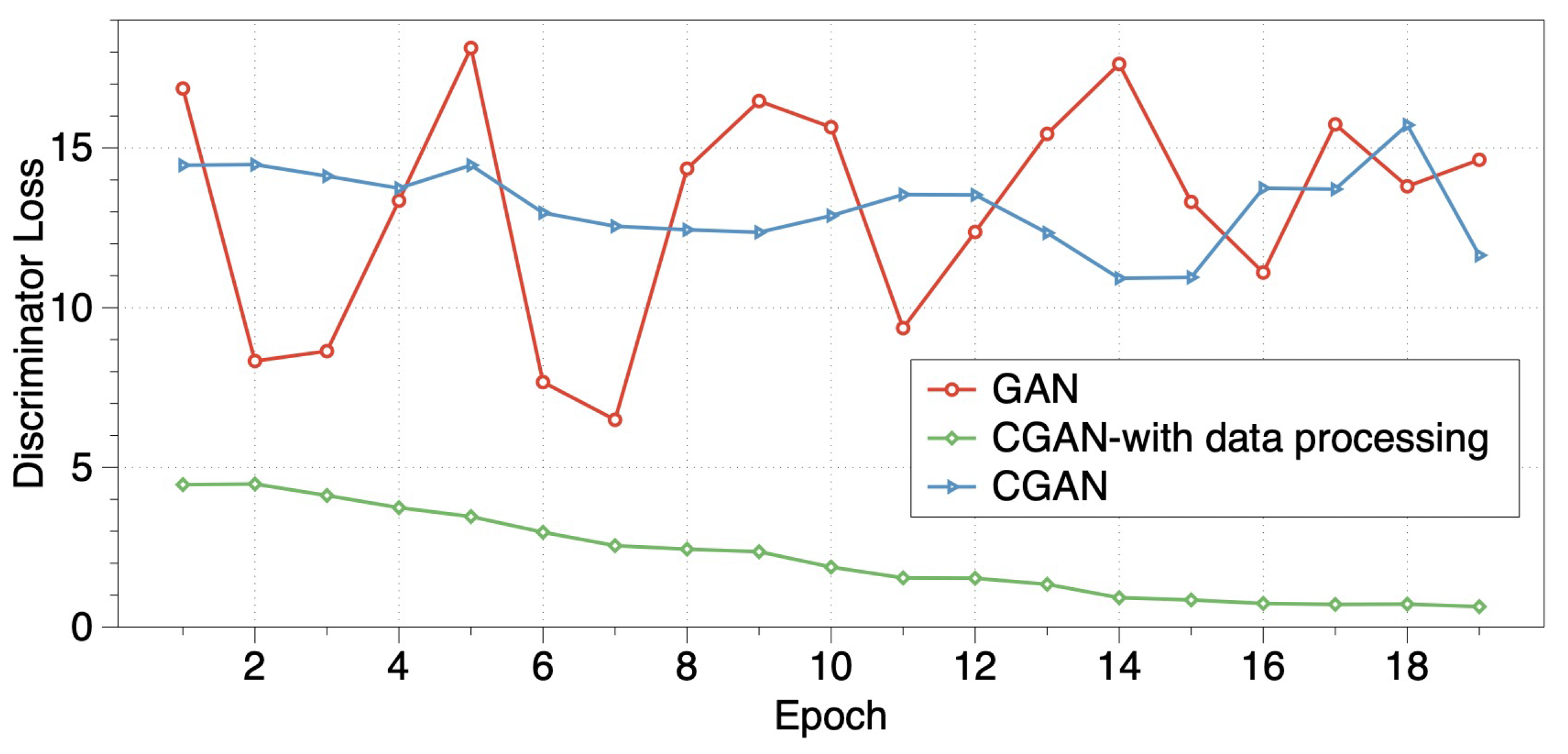
3.3.1. The Necessity of Data Processing
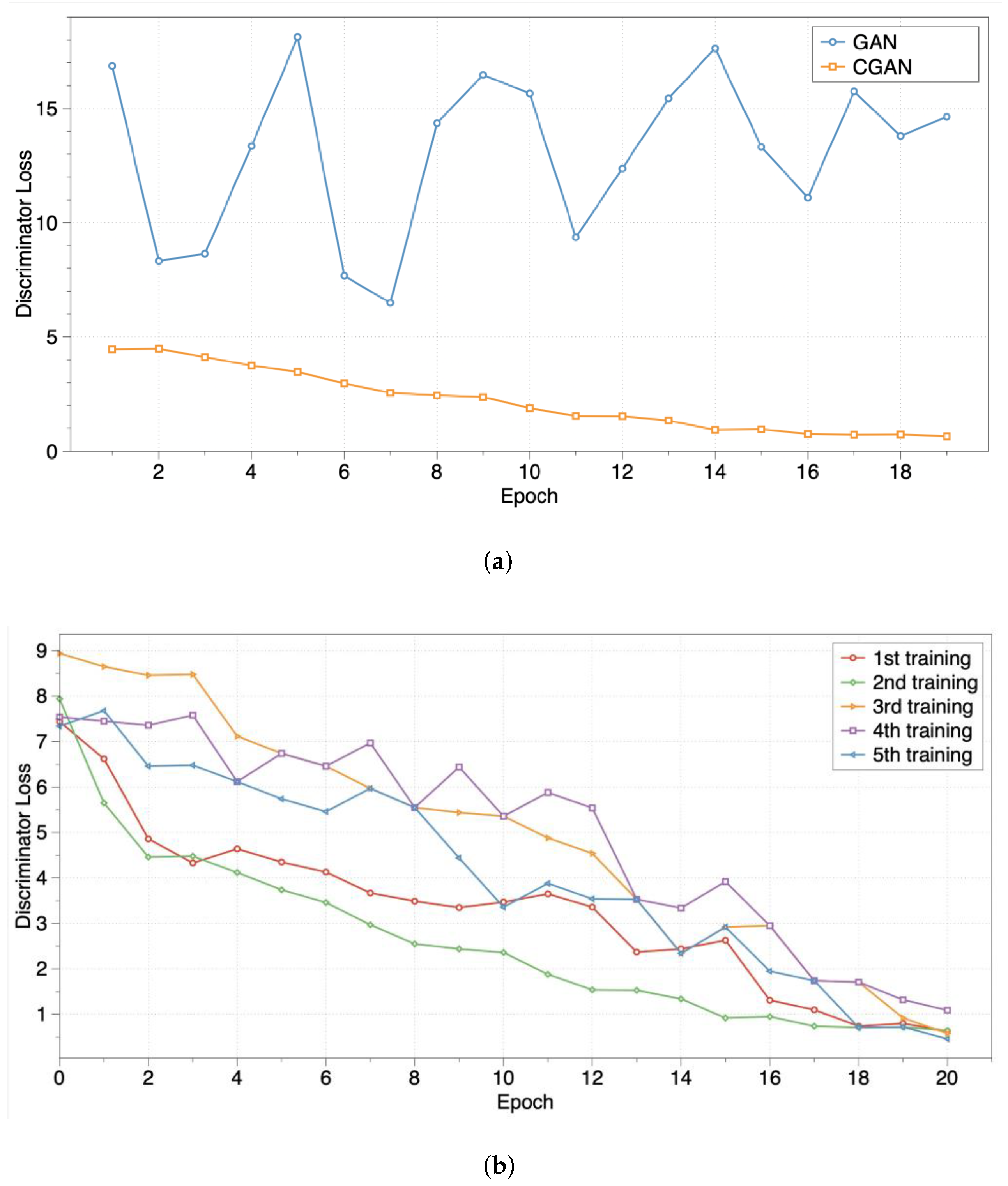
3.3.2. Algorithm Performance
4. Results
4.1. Simulation Settings
4.2. Model Parameter Analysis
4.3. Comparisons of Different Labeling Strategy
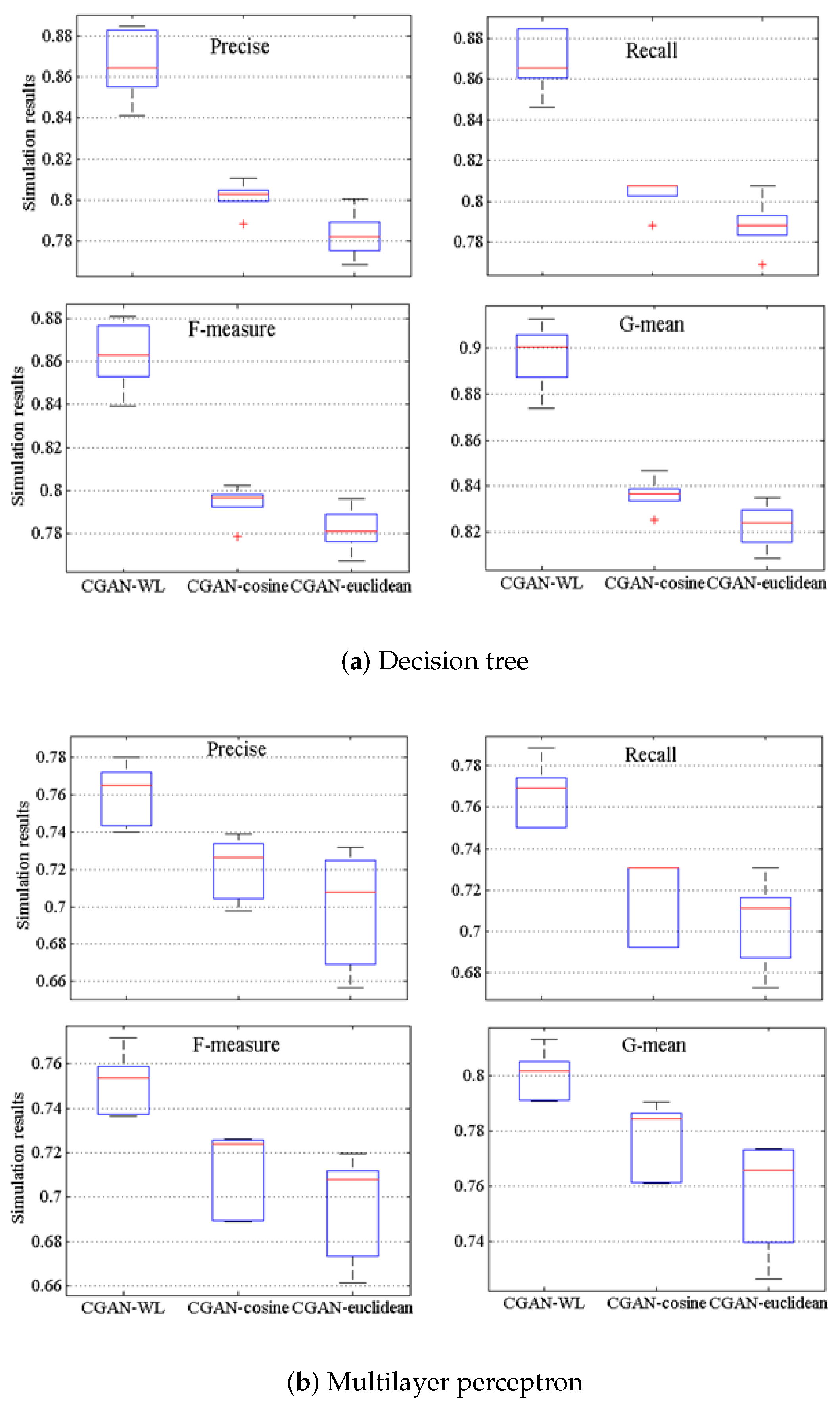
4.4. Comparisons of Different Generation Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Dong, L.; Li, Z.; Zhou, Q.; Zhang, Z. Research on Reliability Test Method of Product Formulation. Reliab. Environ. Test. Electron. Prod. 2021, 39, 7–11. [Google Scholar]
- Li, J.; He, H.; Li, L.; Chen, G. A Novel Generative Model with Bounded-GAN for Reliability Classification of Gear Safety. IEEE Trans. Ind. Electron. 2019, 66, 8772–8781. [Google Scholar] [CrossRef]
- Wang, Z.; Gao, J.M.; Wang, R.X.; Chen, K.; Gao, Z.Y.; Zheng, W. Failure mode and effects analysis by using the house of reliability-based rough VIKOR approach. IEEE Trans. Reliab. 2018, 67, 230–248. [Google Scholar] [CrossRef]
- Park, J.; Ha, J.M.; Oh, H.; Youn, B.D.; Choi, J.H.; Kim, N.H. Model-based fault diagnosis of a planetary gear: A novel approach using transmission error. IEEE Trans. Reliab. 2016, 65, 1830–1841. [Google Scholar] [CrossRef]
- Xu, S.; Li, S.E.; Bo, C.; Li, K. Instantaneous Feedback Control for a Fuel-Prioritized Vehicle Cruising System on Highways With a Varying Slope. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1210–1220. [Google Scholar] [CrossRef]
- Gao, B.; He, Y.; Woo, W.L.; Tian, G.Y.; Liu, J.; Hu, Y. Multidimensional tensor-based inductive thermography with multiple physical fields for offshore wind turbine gear inspection. IEEE Trans. Ind. Electron. 2016, 63, 6305–6315. [Google Scholar] [CrossRef] [Green Version]
- Tan, X.; Xie, L. Fatigue Reliability Evaluation Method of a Gear Transmission System Under Variable Amplitude Loading. IEEE Trans. Reliab. 2019, 68, 599–608. [Google Scholar] [CrossRef]
- Zhao, B.; Xie, L.; Li, H.; Zhang, S.; Wang, B.; Li, C. Reliability Analysis of Aero-Engine Compressor Rotor System Considering Cruise Characteristics. IEEE Trans. Reliab. 2019, 69, 245–259. [Google Scholar] [CrossRef]
- Gabdullin, N.; Madanzadeh, S.; Vilkin, A. Towards End-to-End Deep Learning Performance Analysis of Electric Motors. Actuators 2021, 10, 28. [Google Scholar] [CrossRef]
- Li, W.W.K. On a mixture autoregressive model. J. R. Stat. Soc. 2010, 62, 95–115. [Google Scholar]
- Zhu, Y.; Zhou, G. Technical analysis: An asset allocation perspective on the use of moving averages. J. Financ. Econ. 2009, 92, 519–544. [Google Scholar] [CrossRef]
- Abrahart, R.J.; See, L. Comparing neural network and autoregressive moving average techniques for the provision of continuous river flow forecasts in two contrasting catchments. Hydrol. Process. 2015, 14, 2157–2172. [Google Scholar] [CrossRef]
- Ouyang, T.; He, Y.; Huang, H. Monitoring Wind Turbines’ Unhealthy Status: A Data-Driven Approach. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 3, 163–172. [Google Scholar] [CrossRef]
- Jiang, G.; Xie, P.; He, H.; Yan, J. Wind turbine fault detection using a denoising autoencoder with temporal information. IEEE/ASME Trans. Mechatron. 2018, 23, 89–100. [Google Scholar] [CrossRef]
- Jiang, G.; He, H.; Xie, P.; Tang, Y. Stacked multilevel-denoising autoencoders: A new representation learning approach for wind turbine gearbox fault diagnosis. IEEE Trans. Instrum. Meas. 2017, 66, 2391–2402. [Google Scholar] [CrossRef]
- Lu, D.; Qiao, W.; Gong, X. Current-based gear fault detection for wind turbine gearboxes. IEEE Trans. Sustain. Energy 2017, 8, 1453–1462. [Google Scholar] [CrossRef]
- Preechayasomboon, P.; Rombokas, E. Sensuator: A Hybrid Sensor–Actuator Approach to Soft Robotic Proprioception Using Recurrent Neural Networks. Actuators 2021, 10, 30. [Google Scholar] [CrossRef]
- Lim, P.; Goh, C.K.; Tan, K.C. A Novel Time Series-Histogram of Features (TS-HoF) Method for Prognostic Applications. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 2, 204–213. [Google Scholar] [CrossRef]
- Xu, W.; Xu, J.X.; He, D.; Tan, K.C. An Evolutionary Constraint-Handling Technique for Parametric Optimization of a Cancer Immunotherapy Model. IEEE Trans. Emerg. Top. Comput. Intell. 2019, 3, 151–162. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Li, J.; Liu, S.; He, H.; Li, L. A Novel Framework for Gear Safety Factor Prediction. IEEE Trans. Ind. Inform. 2018, 15, 1998–2007. [Google Scholar] [CrossRef]
- Tang, L. Two-stage Robust Unit Commitment Considering Wind Power Uncertainty and Unit Failure and Outage Risk. Smart Power 2021, 49, 47–53. [Google Scholar]
- Sharghi, A.H.; Karami Mohammadi, R.; Farrokh, M.; Zolfagharysaravi, S. Feed-Forward Controlling of Servo-Hydraulic Actuators Utilizing a Least-Squares Support-Vector Machine. Actuators 2020, 9, 11. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Jean, P.A.; Mirza, M.; Xu, B.; David, W.F.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Yun, B. A manufacturing quality prediction model based on AdaBoost-LSTM with rough knowledge. Comput. Ind. Eng. 2021, 155, 107227. [Google Scholar]
- Wu, Y.; Zhang, Z.; Xiao, R.; Jiang, P.; Dong, Z.; Deng, J. Operation State Identification Method for Converter Transformers Based on Vibration Detection Technology and Deep Belief Network Optimization Algorithm. Actuators 2021, 10, 56. [Google Scholar] [CrossRef]
- Xuan, N.; Ding, H.; Qi, M.; Wang, Y.; Wongd, E.K. URCA-GAN: UpSample Residual Channel-wise Attention Generative Adversarial Network for image-to-image translation. Neurocomputing 2021, 443, 75–84. [Google Scholar]
- Liu, D.; Huang, X.; Zhan, W.; Ai, L.; Zheng, X.; Cheng, S. View synthesis-based light field image compression using a generative adversarial network. Inf. Sci. 2020, 545, 118–131. [Google Scholar] [CrossRef]
- Yi, X.; Walia, E.; Babyn, P. Generative adversarial network in medical imaging: A review. Med. Image Anal. 2019, 371, 58–67. [Google Scholar] [CrossRef] [Green Version]
- Fekri, M.N.; Ghosh, A.M.; Grolinger, K. Generating Energy Data for Machine Learning with Recurrent Generative Adversarial Networks. Energies 2019, 13, 130. [Google Scholar] [CrossRef] [Green Version]
- Tiantian, H.; Song, H.; Jiang, T.; Li, S. Learning Representations of Inorganic Materials from Generative Adversarial Networks. Symmetry 2020, 12, 1889. [Google Scholar]
- Yong, W.Z.; Ki, K.D. Experimental Analysis of Equilibrization in Binary Classification for Non-Image Imbalanced Data Using Wasserstein GAN. Int. J. Internet 2018, 11, 37–42. [Google Scholar]
- Fan, Y.; Liu, C. A Neural Network Weight Initialization Method Based on Transfer Learning. CN Patent CN111126599A, 8 May 2020. [Google Scholar]
- Lemaitre, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning. J. Mach. Learn. Res. 2017, 18, 1–5. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Tang, B.; He, H. GIR-based ensemble sampling approaches for imbalanced learning. Pattern Recognit. 2017, 71, 306–319. [Google Scholar] [CrossRef]
- Sawilowsky, S.S. Misconceptions Leading to Choosing the t Test over the Wilcoxon Mann Whitney Test for Shift in Location Parameter. J. Mod. Appl. Stat. Methods 2014, 4, 598–600. [Google Scholar] [CrossRef]
- He, H.; Yang, B.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: http://archive.ics.uci.edu/ml/datasets/Refractive+errors (accessed on 20 March 2021).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| samples in the real dataset | |
| feature dimensions of samples in the real dataset | |
| class of samples in the real dataset | |
| after data processing | |
| feature dimensions of | |
| class information of | |
| noise information into the generator | |
| classification result of the discriminator on | |
| discriminator’s classification result of the generated data | |
| frequency of samples | |
| loss function of the discriminator | |
| learning rate of the discriminator | |
| loss function of the discriminator |
| Metrics | P | R | F-M | G-M |
|---|---|---|---|---|
| Algorithm: DT [36] | ||||
| ROS [35] | 0.791 | 0.796 | 0.790 | 0.843 |
| SMOTE [21] | 0.769 | 0.762 | 0.762 | 0.813 |
| ADASYN [39] | 0.792 | 0.796 | 0.790 | 0.842 |
| SMOTETomek [35] | 0.767 | 0.777 | 0.763 | 0.816 |
| SMOTEENN [35] | 0.674 | 0.654 | 0.637 | 0.746 |
| GAN-WL | 0.802 | 0.804 | 0.799 | 0.832 |
| CGAN-WL(ours) | 0.854 | 0.858 | 0.852 | 0.889 |
| Algorithm: RF [40] | ||||
| ROS | 0.759 | 0.754 | 0.749 | 0.806 |
| SMOTE | 0.774 | 0.769 | 0.767 | 0.819 |
| ADASYN | 0.788 | 0.781 | 0.777 | 0.828 |
| SMOTETomek | 0.766 | 0.758 | 0.754 | 0.814 |
| SMOTEENN | 0.682 | 0.615 | 0.613 | 0.721 |
| GAN-WL | 0.744 | 0.740 | 0.735 | 0.800 |
| CGAN-WL(ours) | 0.815 | 0.815 | 0.810 | 0.848 |
| Algorithm: MLP [36] | ||||
| ROS | 0.701 | 0.683 | 0.678 | 0.751 |
| SMOTE | 0.686 | 0.671 | 0.670 | 0.741 |
| ADASYN | 0.709 | 0.696 | 0.694 | 0.760 |
| SMOTETomek | 0.698 | 0.675 | 0.677 | 0.758 |
| SMOTEENN | 0.625 | 0.539 | 0.503 | 0.652 |
| GAN-WL | 0.593 | 0.596 | 0.589 | 0.688 |
| CGAN-WL(ours) | 0.756 | 0.762 | 0.749 | 0.798 |
| Method | DT [36] | RF [40] | MLP [36] | |
|---|---|---|---|---|
| P | ROS [35] | |||
| SMOTE [21] | ||||
| ADASYN [39] | ||||
| SMOTETomek [35] | ||||
| SMOTEENN [35] | ||||
| CGAN-WL(ours) | ||||
| R | ROS | |||
| SMOTE | ||||
| ADASYN | ||||
| SMOTETomek | ||||
| SMOTEENN | ||||
| CGAN-WL(ours) | ||||
| F-M | ROS | |||
| SMOTE | ||||
| ADASYN | ||||
| SMOTETomek | ||||
| SMOTEENN | ||||
| CGAN-WL(ours) | ||||
| G-M | ROS | |||
| SMOTE | ||||
| ADASYN | ||||
| SMOTETomek | ||||
| SMOTEENN | ||||
| CGAN-WL(ours) |
| Metrics | P | R | F-M | G-M |
|---|---|---|---|---|
| Algorithm: DT [36] | ||||
| ROS [35] | 0.753 | 0.757 | 0.751 | 0.802 |
| SMOTE [21] | 0.725 | 0.727 | 0.729 | 0.776 |
| ADASYN [39] | 0.758 | 0.754 | 0.756 | 0.801 |
| SMOTETomek [35] | 0.725 | 0.727 | 0.720 | 0.771 |
| SMOTEENN [35] | 0.638 | 0.616 | 0.599 | 0.704 |
| GAN-WL | 0.766 | 0.760 | 0.759 | 0.801 |
| CGAN-WL(ours) | 0.811 | 0.817 | 0.817 | 0.846 |
| Algorithm: RF [40] | ||||
| ROS | 0.715 | 0.717 | 0.706 | 0.766 |
| SMOTE | 0.737 | 0.725 | 0.728 | 0.775 |
| ADASYN | 0.746 | 0.745 | 0.737 | 0.781 |
| SMOTETomek | 0.723 | 0.719 | 0.711 | 0.776 |
| SMOTEENN | 0.642 | 0.585 | 0.583 | 0.687 |
| GAN-WL | 0.703 | 0.701 | 0.705 | 0.760 |
| CGAN-WL(ours) | 0.776 | 0.775 | 0.779 | 0.808 |
| Algorithm: MLP [36] | ||||
| ROS | 0.681 | 0.679 | 0.679 | 0.711 |
| SMOTE | 0.641 | 0.636 | 0.631 | 0.702 |
| ADASYN | 0.667 | 0.656 | 0.654 | 0.727 |
| SMOTETomek | 0.651 | 0.637 | 0.646 | 0.719 |
| SMOTEENN | 0.585 | 0.508 | 0.501 | 0.617 |
| GAN-WL | 0.556 | 0.557 | 0.541 | 0.640 |
| CGAN-WL(ours) | 0.716 | 0.728 | 0.703 | 0.778 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Zhao, B.; Wu, K.; Dong, Z.; Zhang, X.; Zheng, Z. A Representation Generation Approach of Transmission Gear Based on Conditional Generative Adversarial Network. Actuators 2021, 10, 86. https://doi.org/10.3390/act10050086
Li J, Zhao B, Wu K, Dong Z, Zhang X, Zheng Z. A Representation Generation Approach of Transmission Gear Based on Conditional Generative Adversarial Network. Actuators. 2021; 10(5):86. https://doi.org/10.3390/act10050086
Chicago/Turabian StyleLi, Jie, Boyu Zhao, Kai Wu, Zhicheng Dong, Xuerui Zhang, and Zhihao Zheng. 2021. "A Representation Generation Approach of Transmission Gear Based on Conditional Generative Adversarial Network" Actuators 10, no. 5: 86. https://doi.org/10.3390/act10050086
APA StyleLi, J., Zhao, B., Wu, K., Dong, Z., Zhang, X., & Zheng, Z. (2021). A Representation Generation Approach of Transmission Gear Based on Conditional Generative Adversarial Network. Actuators, 10(5), 86. https://doi.org/10.3390/act10050086