



Reinforcement Learning for the Face Support Pressure of Tunnel Boring Machines



Abstract
:1. Introduction
2. Methods
2.1. Analytical Training Environment
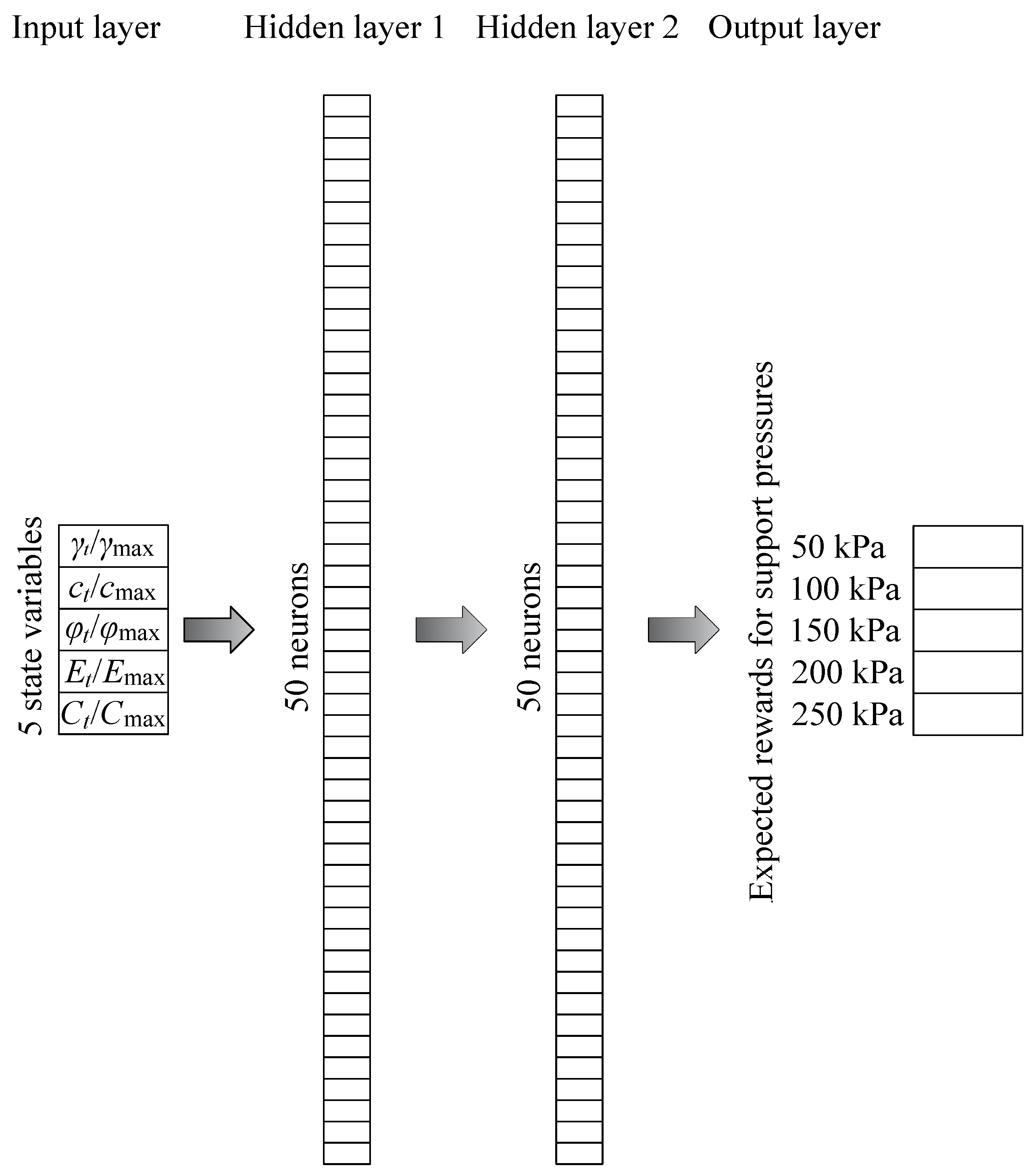
2.2. State Representation
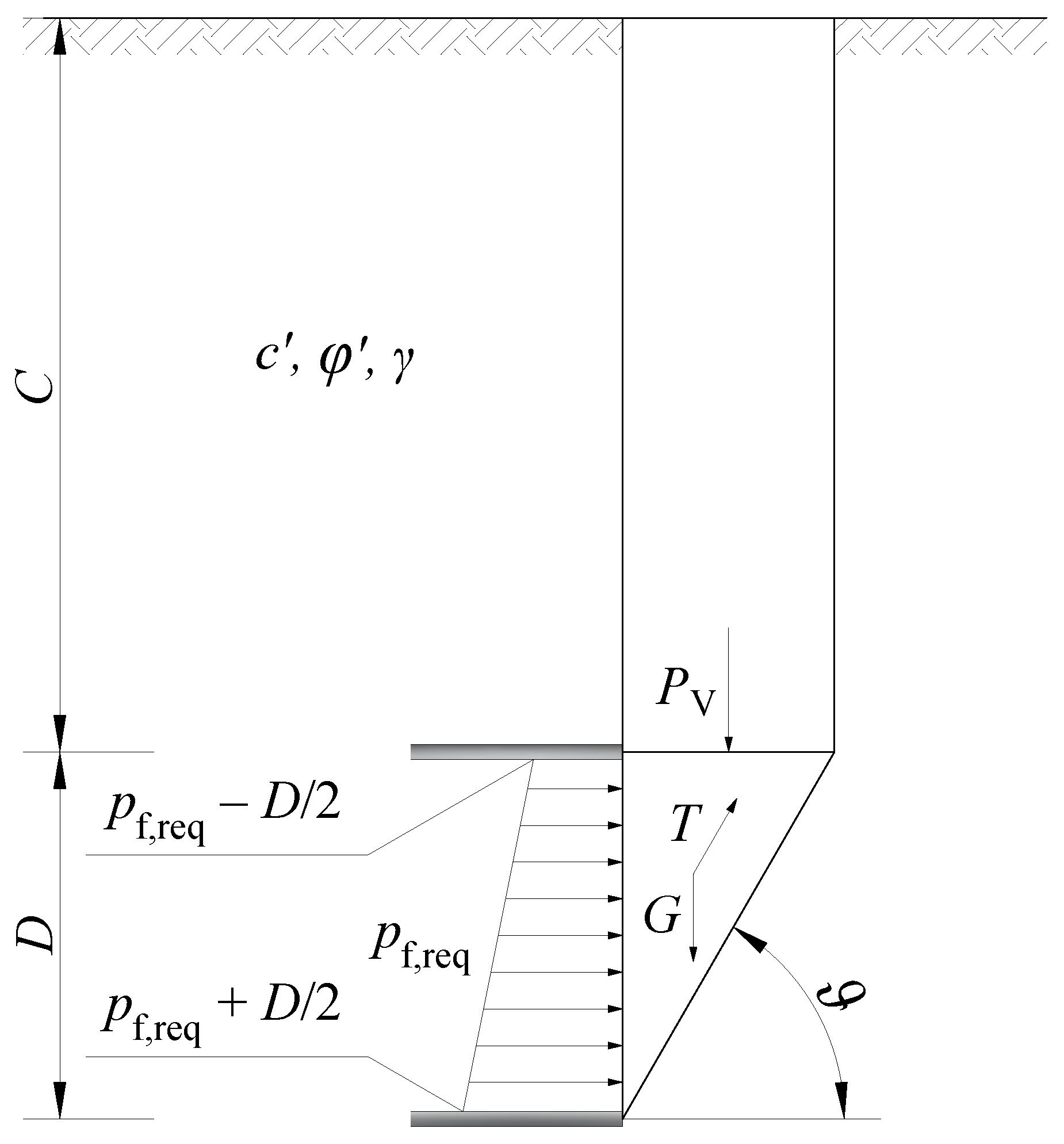
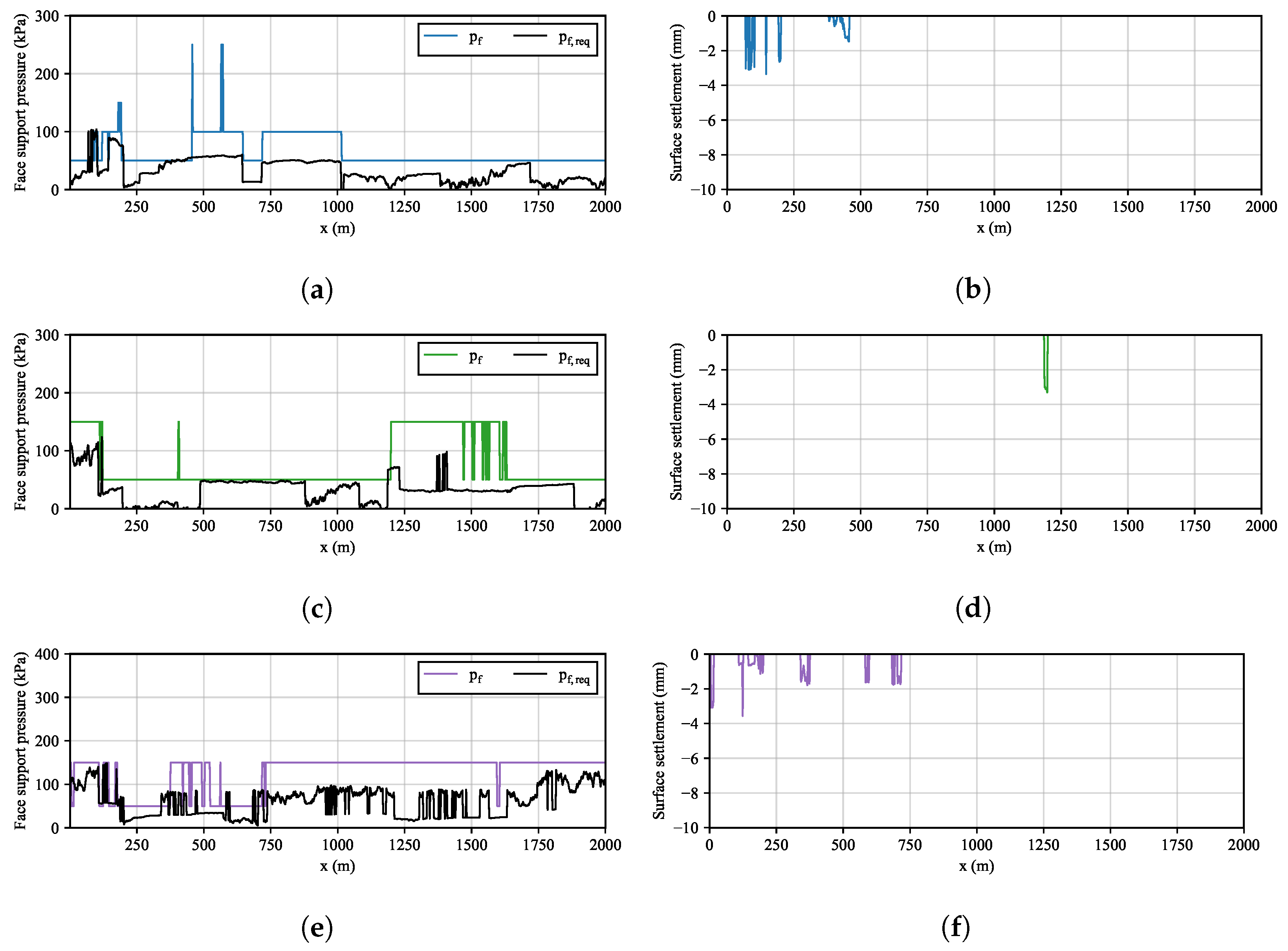
2.3. Face Support Pressure and Settlement
2.4. Deep Q-Network
2.4.1. Experience Replay
2.4.2. Target Memory
3. Results of the Analytical Environment
3.1. Sensitivity Analysis
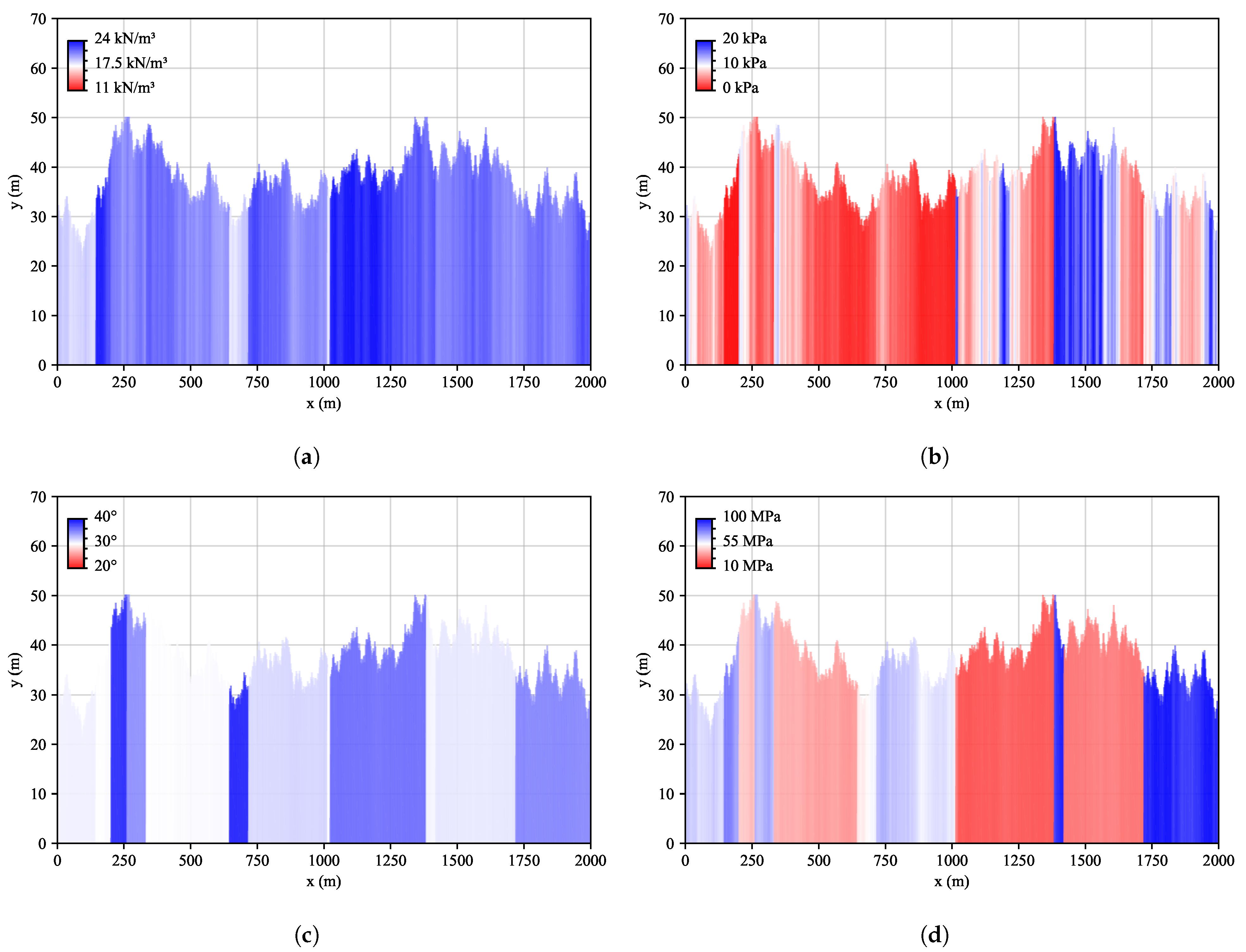
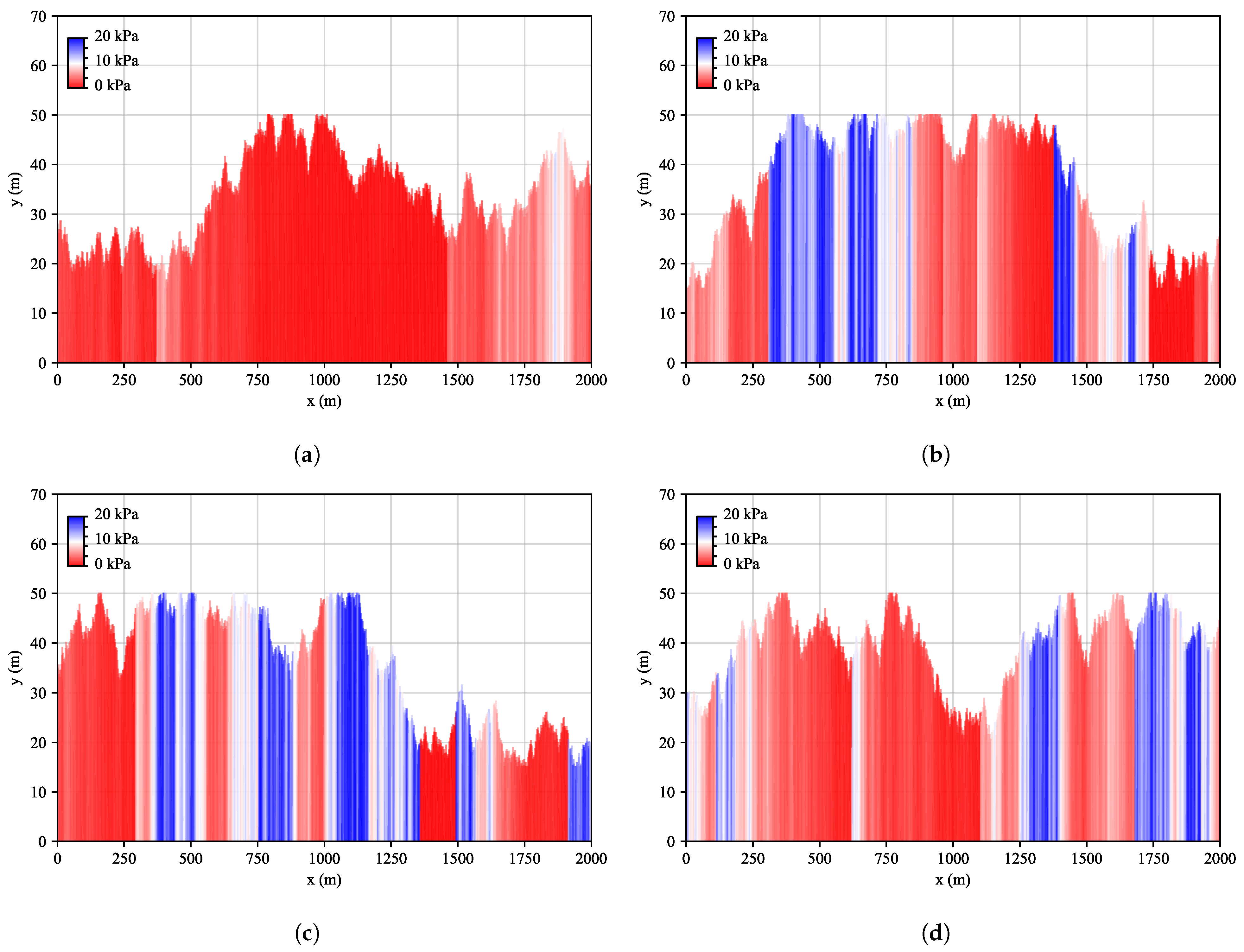
3.2. Random Geologies
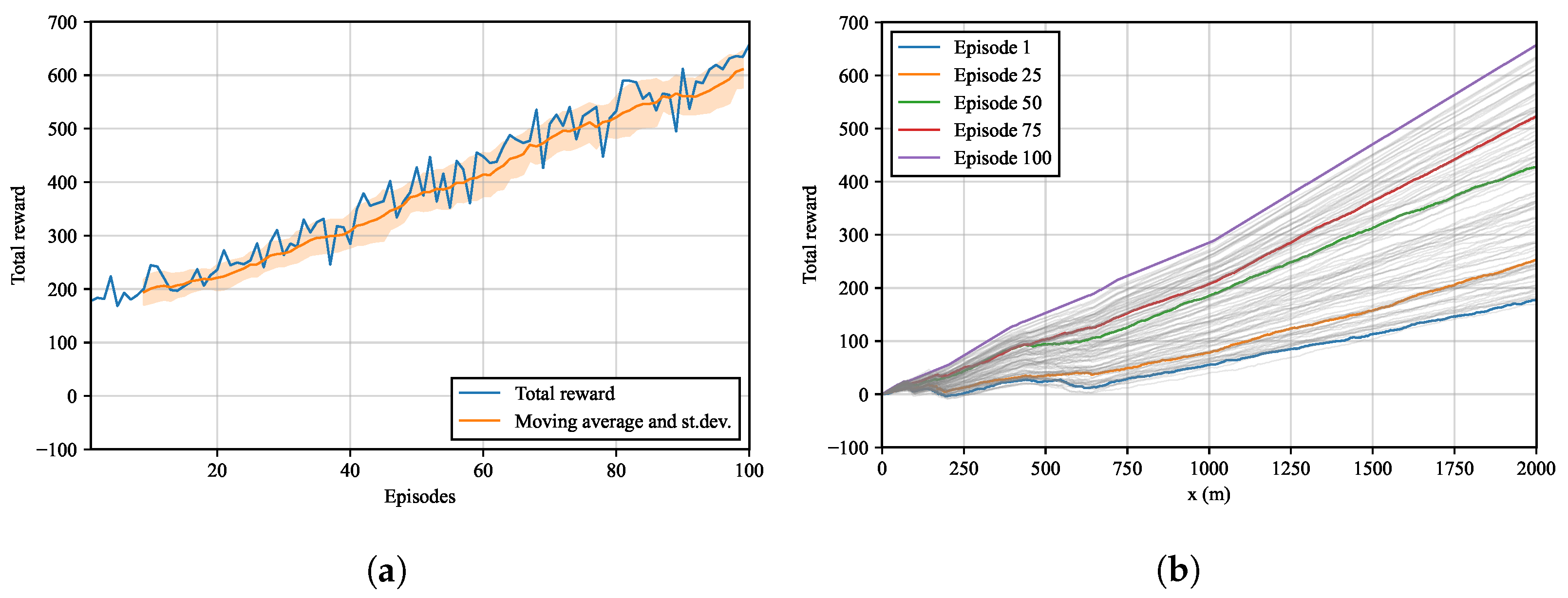
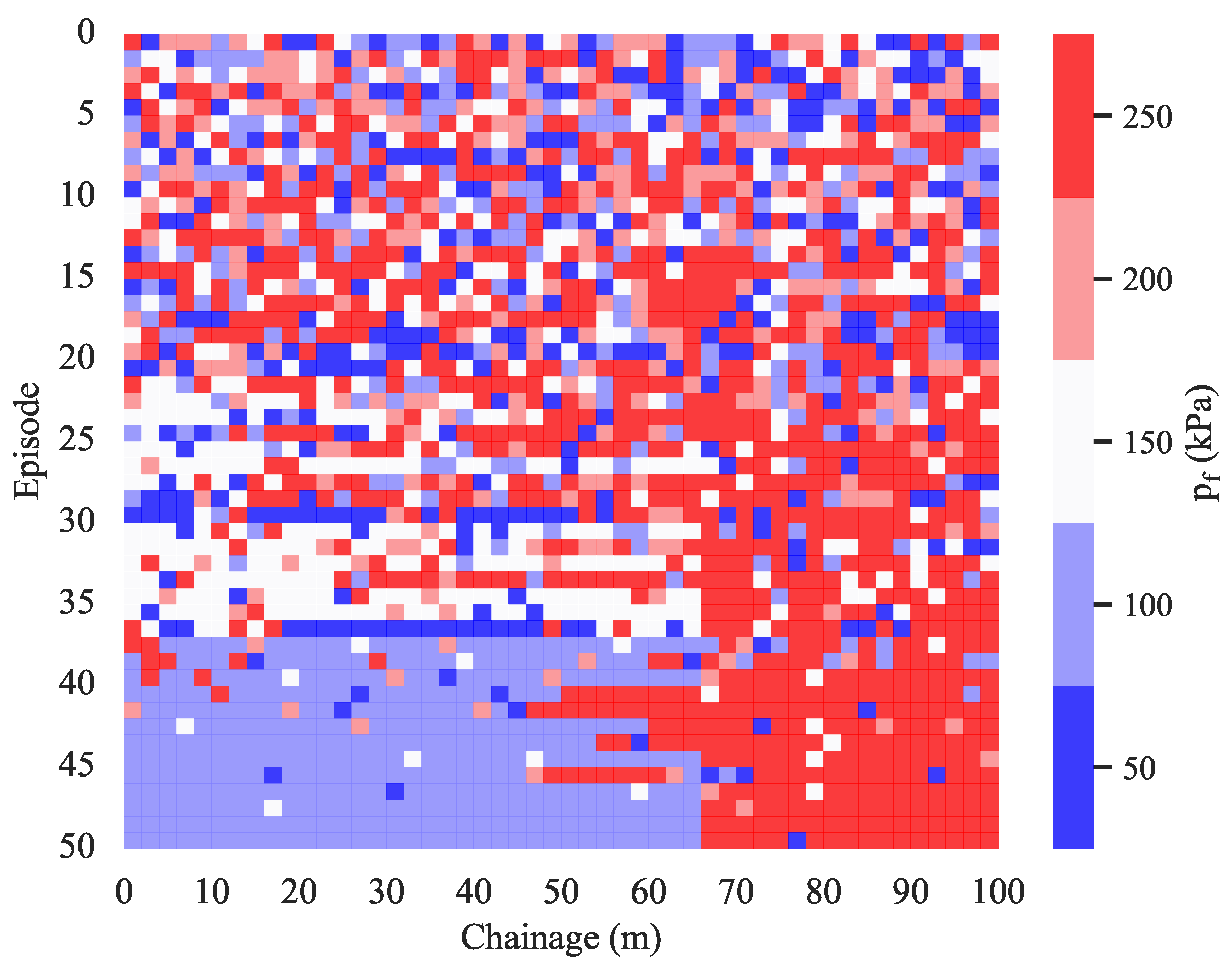
3.3. Effect of the Number of Episodes
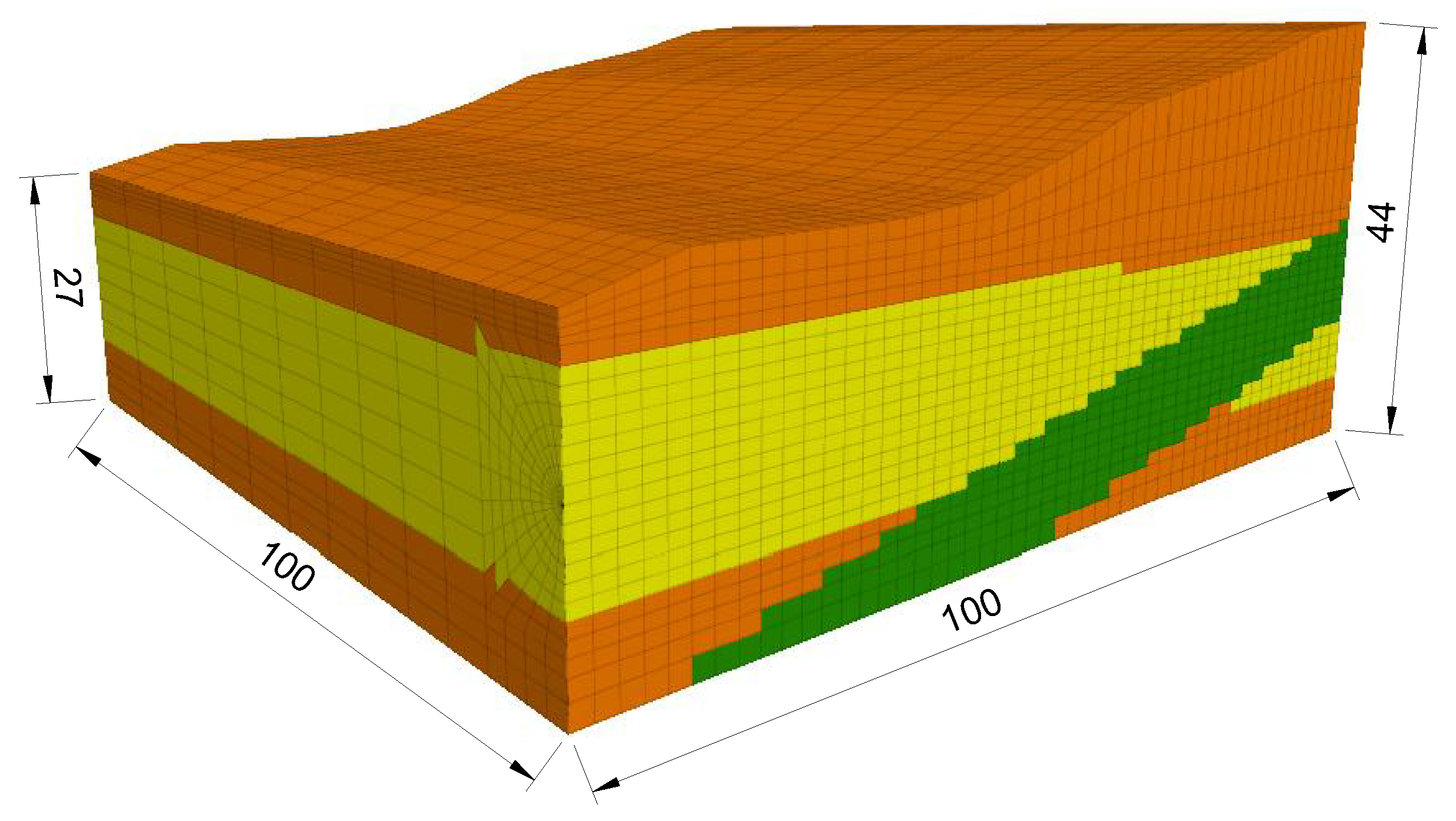
3.4. Finite Difference Environment
4. Discussion
- The adoption of more advanced constitutive models, the simulation of the lining with shell elements, and the simulation of the ring gap and mortar [93,94]. It is perhaps worth noting that different types of segments (in terms of concrete class and reinforcement) and ring gap mortar pressures are chosen in practice. Hence, two additional agents could be implemented to predict the segment types and mortar pressures.
- The consideration of the spatial variability of soil properties with random fields, by varying the soil properties according to certain statistical distributions and correlation lengths [95]. Since random fields further complicate the environment, more advanced reinforcement learning algorithms might be adopted, such as the 51-atom agent (C51) [96]. Moreover, the definition of the state variables can be improved, e.g., by considering the soil properties at more than one point at each epoch.
5. Conclusions
- The algorithm is capable of predicting the tunnel face support pressure that ensures stability and minimise settlements among a prescribed range of pressures. The algorithm can adapt to geological (soil properties) or geometrical (overburden) changes.
- An analytical environment is used to optimise the algorithm. The optimal hyperparameters are found as (discount factor), (learning rate), (synchronisation frequency), (memory size) and (batch size). These hyperparameter values are effective also in the numerical environment.
- Although the algorithm is trained in a static environment with constant geology, it is also effective with random geological settings. In particular, it is found that using the algorithm trained with constant geology can be used for random geologies without retraining.
- The maximum cumulative reward plateaus after 400 training episodes and about 90% of the peak performance is reached after 50 episodes.
- The algorithm proves effective both in the analytical and in the more realistic numerical environment. Training is more computationally costly in the numerical environment. However, the hyperparameter values optimised in the analytical environment can be efficiently adopted.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | artificial intelligence | |
| DQN | deep Q-network | |
| EPB | Earth pressure balance shield | |
| FDM | finite difference method | |
| NATM | New Austrian Tunnelling Method | |
| SPB | slurry pressure balance shield | |
| TBM | tunnel boring machine | |
| List of symbols | ||
| A | Cross-sectional area of the tunnel | (m²) |
| Action taken at state i | ||
| C | Soil cover | (m) |
| D | Tunnel diameter | (m) |
| E | Soil Young’s modulus | (MPa) |
| Maximum value of the soil Young’s modulus | (MPa) | |
| G | Self weight of the sliding wedge | (kN) |
| K | Experience factor | |
| N | Number of episodes | |
| Vertical load from the soil prism | (kN) | |
| Value function | ||
| Target value function | ||
| Maximum reward in state for actions a | ||
| Reward at state i | ||
| State of the environment | ||
| T | Shear force on the vertical slip surface | (kN) |
| a | Action vector | |
| c | Soil cohesion | (kPa) |
| Maximum value of the soil cohesion | (kPa) | |
| f | Synchronisation frequency | |
| j | Episode counter | |
| Random action | ||
| Tunnel face support pressure | (kPa) | |
| Tunnel face support pressure required for stability | (kPa) | |
| r | Rewards vector | |
| s | State vector | |
| Batch size | ||
| Memory size | ||
| t | State counter | |
| u | Soil settlement above the tunnel | (mm) |
| x | Tunnel chainage | (m) |
| Discount factor | ||
| Settlement difference between excavation steps | (mm) | |
| Probability of a random action | ||
| Initial probability of a random action | ||
| Soil unit weight | (kN/m³) | |
| Maximum value of the soil unit weight | (kN/m³) | |
| Unit weight of the support medium | (kN/m³) | |
| Stress release due to tunnel construction | ||
| Learning rate | ||
| Soil friction angle | (°) | |
| Maximum value of the soil friction angle | (°) | |
| Parameters of the value function | ||
| Parameters of the target value function | ||
| Sliding angle | (°) | |
References
- Davis, E.H.; Gunn, M.J.; Mair, R.J.; Seneviratine, H.N. The stability of shallow tunnels and underground openings in cohesive material. Géotechnique 1980, 30, 397–416. [Google Scholar] [CrossRef]
- Leca, E.; Dormieux, L. Upper and lower bound solutions for the face stability of shallow circular tunnels in frictional material. Géotechnique 1990, 40, 581–606. [Google Scholar] [CrossRef] [Green Version]
- Anagnostou, G.; Kovári, K. The face stability of slurry-shield-driven tunnels. Tunn. Undergr. Space Technol. 1994, 9, 165–174. [Google Scholar] [CrossRef]
- Anagnostou, G.; Kovári, K. Face stability conditions with earth-pressure-balanced shields. Tunn. Undergr. Space Technol. 1996, 11, 165–173. [Google Scholar] [CrossRef]
- Horn, N. Horizontal ground pressure on vertical faces of tunnel tubes. In Proceedings of the Landeskonferenz der Ungarischen Tiefbauindustrie, Budapest, Hungary, 18–21 June 1961. [Google Scholar]
- DAUB. Recommendations for face support pressure calculations for shield tunnelling in soft ground. Guidelines, Deutscher Ausschuss für unterirdisches Bauen, Cologne, Germany, 2016. Available online: bit.ly/3YEMGm2 (accessed on 11 March 2023).
- Alagha, A.S.; Chapman, D.N. Numerical modelling of tunnel face stability in homogeneous and layered soft ground. Tunn. Undergr. Space Technol. 2019, 94, 103096. [Google Scholar] [CrossRef]
- Sterpi, D.; Cividini, A. A Physical and Numerical Investigation on the Stability of Shallow Tunnels in Strain Softening Media. Rock Mech. Rock Eng. 2004, 37, 277–298. [Google Scholar] [CrossRef]
- Vermeer, P.; Ruse, N.; Dolatimehr, A. Tunnel Heading Stability in Drained Ground. Felsbau 2002, 20, 8–18. [Google Scholar]
- Augarde, C.E.; Lyamin, A.V.; Sloan, S.W. Stability of an undrained plane strain heading revisited. Comput. Geotech. 2003, 30, 419–430. [Google Scholar] [CrossRef]
- Ahmed, M.; Iskander, M. Evaluation of tunnel face stability by transparent soil models. Tunn. Undergr. Space Technol. 2012, 27, 101–110. [Google Scholar] [CrossRef]
- Chen, R.P.; Li, J.; Kong, L.G.; Tang, L.J. Experimental study on face instability of shield tunnel in sand. Tunn. Undergr. Space Technol. 2013, 33, 12–21. [Google Scholar] [CrossRef]
- Kirsch, A. Experimental investigation of the face stability of shallow tunnels in sand. Acta Geotech. 2010, 5, 43–62. [Google Scholar] [CrossRef] [Green Version]
- Lü, X.; Zeng, S.; Zhao, Y.; Huang, M.; Ma, S.; Zhang, Z. Physical model tests and discrete element simulation of shield tunnel face stability in anisotropic granular media. Acta Geotech. 2020, 15, 3017–3026. [Google Scholar] [CrossRef]
- Lü, X.; Zhou, Y.; Huang, M.; Zeng, S. Experimental study of the face stability of shield tunnel in sands under seepage condition. Tunn. Undergr. Space Technol. 2018, 74, 195–205. [Google Scholar] [CrossRef]
- Chambon, P.; Corté, J. Shallow Tunnels in Cohesionless Soil: Stability of Tunnel Face. J. Geotech. Eng. 1994, 120, 1148–1165. [Google Scholar] [CrossRef]
- Mair, R. Centrifugal Modelling of Tunnel Construction in Soft Clay. Ph.D. Thesis, University of Cambridge, Cambridge, UK, 1979. [Google Scholar]
- Soranzo, E.; Wu, W. Centrifuge Test of Face Stability of Shallow Tunnels in Unsaturated Soil. In Poromechanics V; American Society of Civil Engineers: Reston, VA, USA, 2013; pp. 1326–1335. [Google Scholar] [CrossRef]
- Jong, S.; Ong, D.; Oh, E. State-of-the-art review of geotechnical-driven artificial intelligence techniques in underground soil-structure interaction. Tunn. Undergr. Space Technol. 2021, 113, 103946. [Google Scholar] [CrossRef]
- Ebid, A. 35 Years of (AI) in Geotechnical Engineering: State of the Art. Geotech. Geol. Eng. 2021, 39, 637–690. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, R.; Wu, C.; Goh, A.T.C.; Lacasse, S.; Liu, Z.; Liu, H. State-of-the-art review of soft computing applications in underground excavations. Geosci. Front. 2020, 11, 1095–1106. [Google Scholar] [CrossRef]
- Marcher, T.; Erharter, G.; Winkler, M. Machine Learning in tunnelling—Capabilities and challenges. Geomech. Tunn. 2020, 13, 191–198. [Google Scholar] [CrossRef]
- Shahrour, I.; Zhang, W. Use of soft computing techniques for tunneling optimization of tunnel boring machines. Undergr. Space 2021, 6, 233–239. [Google Scholar] [CrossRef]
- Soranzo, E.; Guardiani, C.; Wu, W. A soft computing approach to tunnel face stability in a probabilistic framework. Acta Geotech. 2022, 17, 1219–1238. [Google Scholar] [CrossRef]
- Soranzo, E.; Guardiani, C.; Wu, W. The application of reinforcement learning to NATM tunnel design. Undergr. Space, 2022; in press. [Google Scholar] [CrossRef]
- Qin, S.; Xu, T.; Zhou, W.H. Predicting Pore-Water Pressure in Front of a TBM Using a Deep Learning Approach. Int. J. Geomech. 2021, 21, 04021140. [Google Scholar] [CrossRef]
- Kim, D.; Pham, K.; Oh, J.Y.; Lee, S.J.; Choi, H. Classification of surface settlement levels induced by TBM driving in urban areas using random forest with data-driven feature selection. Autom. Constr. 2022, 135, 104109. [Google Scholar] [CrossRef]
- Kim, D.; Kwon, K.; Pham, K.; Oh, J.Y.; Choi, H. Surface settlement prediction for urban tunneling using machine learning algorithms with Bayesian optimization. Autom. Constr. 2022, 140, 104331. [Google Scholar] [CrossRef]
- Lee, H.K.; Song, M.K.; Lee, S.S. Prediction of Subsidence during TBM Operation in Mixed-Face Ground Conditions from Realtime Monitoring Data. Appl. Sci. 2021, 11, 12130. [Google Scholar] [CrossRef]
- Erharter, G.H.; Hansen, T.F. Towards optimized TBM cutter changing policies with reinforcement learning. Geomech. Tunn. 2022, 15, 665–670. [Google Scholar] [CrossRef]
- Liu, Y.; Huang, S.; Wang, D.; Zhu, G.; Zhang, D. Prediction Model of Tunnel Boring Machine Disc Cutter Replacement Using Kernel Support Vector Machine. Appl. Sci. 2022, 12, 2267. [Google Scholar] [CrossRef]
- Mahmoodzadeh, A.; Mohammadi, M.; Hashim Ibrahim, H.; Nariman Abdulhamid, S.; Farid Hama Ali, H.; Mohammed Hasan, A.; Khishe, M.; Mahmud, H. Machine learning forecasting models of disc cutters life of tunnel boring machine. Autom. Constr. 2021, 128, 103779. [Google Scholar] [CrossRef]
- Hou, S.; Liu, Y.; Zhuang, W.; Zhang, K.; Zhang, R.; Yang, Q. Prediction of shield jamming risk for double-shield TBM tunnels based on numerical samples and random forest classifier. Acta Geotech. 2022, 18, 495–517. [Google Scholar] [CrossRef]
- Lin, P.; Xiong, Y.; Xu, Z.; Wang, W.; Shao, R. Risk assessment of TBM jamming based on Bayesian networks. Bull. Eng. Geol. Environ. 2021, 81, 47. [Google Scholar] [CrossRef]
- Liu, M.; Liao, S.; Yang, Y.; Men, Y.; He, J.; Huang, Y. Tunnel boring machine vibration-based deep learning for the ground identification of working faces. J. Rock Mech. Geotech. Eng. 2021, 13, 1340–1357. [Google Scholar] [CrossRef]
- Wellmann, F.; Amann, F.; de la Varga, M.; Chudalla, N. Automated geological model updates during TBM operation—An approach based on probabilistic machine learning concepts. Geomech. Tunn. 2022, 15, 635–641. [Google Scholar] [CrossRef]
- Erharter, G.H.; Marcher, T. On the pointlessness of machine learning based time delayed prediction of TBM operational data. Autom. Constr. 2021, 121, 103443. [Google Scholar] [CrossRef]
- Sheil, B. Discussion of “on the pointlessness of machine learning based time delayed prediction of TBM operational data” by Georg H. Erharter and Thomas Marcher. Autom. Constr. 2021, 124, 103559. [Google Scholar] [CrossRef]
- Bai, X.D.; Cheng, W.C.; Li, G. A comparative study of different machine learning algorithms in predicting EPB shield behaviour: A case study at the Xi’an metro, China. Acta Geotech. 2021, 16, 4061–4080. [Google Scholar] [CrossRef]
- Guo, D.; Li, J.; Jiang, S.H.; Li, X.; Chen, Z. Intelligent assistant driving method for tunnel boring machine based on big data. Acta Geotech. 2022, 17, 1019–1030. [Google Scholar] [CrossRef]
- Zhang, N.; Zhang, N.; Zheng, Q.; Xu, Y.S. Real-time prediction of shield moving trajectory during tunnelling using GRU deep neural network. Acta Geotech. 2022, 17, 1167–1182. [Google Scholar] [CrossRef]
- Benardos, A.; Kaliampakos, D. Modelling TBM performance with artificial neural networks. Tunn. Undergr. Space Technol. 2004, 19, 597–605. [Google Scholar] [CrossRef]
- Feng, S.; Chen, Z.; Luo, H.; Wang, S.; Zhao, Y.; Liu, L.; Ling, D.; Jing, L. Tunnel boring machines (TBM) performance prediction: A case study using big data and deep learning. Tunn. Undergr. Space Technol. 2021, 110, 103636. [Google Scholar] [CrossRef]
- Gao, B.; Wang, R.; Lin, C.; Guo, X.; Liu, B.; Zhang, W. TBM penetration rate prediction based on the long short-term memory neural network. Undergr. Space 2021, 6, 718–731. [Google Scholar] [CrossRef]
- Xu, H.; Zhou, J.; Asteris, P.G.; Jahed Armaghani, D.; Tahir, M.M. Supervised Machine Learning Techniques to the Prediction of Tunnel Boring Machine Penetration Rate. Appl. Sci. 2019, 9, 3715. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Li, P.; Guo, D.; Li, X.; Chen, Z. Advanced prediction of tunnel boring machine performance based on big data. Geosci. Front. 2021, 12, 331–338. [Google Scholar] [CrossRef]
- Mahmoodzadeh, A.; Nejati, H.R.; Mohammadi, M.; Hashim Ibrahim, H.; Rashidi, S.; Ahmed Rashid, T. Forecasting tunnel boring machine penetration rate using LSTM deep neural network optimized by grey wolf optimization algorithm. Expert Syst. Appl. 2022, 209, 118303. [Google Scholar] [CrossRef]
- International Business Machines. Supervised Learning, 2020. Available online: https://www.ibm.com/cloud/learn/supervised-learning (accessed on 11 March 2023).
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Schrittwieser, J.; Antonoglou, I.; Hubert, T.; Simonyan, K.; Sifre, L.; Schmitt, S.; Guez, A.; Lockhart, E.; Hassabis, D. Graepel, T.; Lillicrap, T.; et al. Mastering Atari, Go, chess and shogi by planning with a learned model. Nature 2020, 588, 604–612. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Huang, A.; Maddison, C.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–503. [Google Scholar] [CrossRef]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.L.; Lai, M.; Bolton, A.; et al. Mastering the game of Go without human knowledge. Nature 2017, 550, 354–370. [Google Scholar] [CrossRef] [Green Version]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shahrabi, J.; Adibi, M.; Mahootchi, M. Computers and Industrial Engineering. Nature 2017, 110, 75–82. [Google Scholar] [CrossRef]
- Ipek, E.; Mutlu, O.; Martínez, J.F.; Caruana, R. Self-Optimizing Memory Controllers: A Reinforcement Learning Approach. In Proceedings of the 2008 International Symposium on Computer Architecture, Virtual, 21–25 June 2008; pp. 39–50. [Google Scholar] [CrossRef] [Green Version]
- Martinez, J.F.; Ipek, E. Dynamic Multicore Resource Management: A Machine Learning Approach. IEEE Micro 2009, 29, 8–17. [Google Scholar] [CrossRef]
- Li, L.; Chu, W.; Langford, J.; Schapire, R.E. A Contextual-Bandit Approach to Personalized News Article Recommendation. arXiv 2010, arXiv:1003.0146. [Google Scholar]
- Theocharous, G.; Thomas, P.S.; Ghavamzadeh, M. Personalized Ad Recommendation Systems for Life-Time Value Optimization with Guarantees. In Proceedings of the 24th International Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 1806–1812. [Google Scholar]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Sallab, A.A.A.; Yogamani, S.K.; Pérez, P. Deep Reinforcement Learning for Autonomous Driving: A Survey. arXiv 2020, arXiv:2002.00444. [Google Scholar] [CrossRef]
- Gao, X. Deep reinforcement learning for time series: Playing idealized trading games. arXiv 2018, arXiv:1803.03916. [Google Scholar]
- Paulus, R.; Xiong, C.; Socher, R. A Deep Reinforced Model for Abstractive Summarization. arXiv 2017, arXiv:1705.04304. [Google Scholar]
- Yu, C.; Liu, J.; Nemati, S. Reinforcement Learning in Healthcare: A Survey. arXiv 2019, arXiv:1908.08796. [Google Scholar] [CrossRef]
- Mousavi, S.; Schukat, M.; Howley, E. Deep Reinforcement Learning: An Overview. In Proceedings of the SAI Intelligent Systems Conference (IntelliSys) 2016, London, UK, 21–22 September 2016; pp. 426–440. [Google Scholar] [CrossRef] [Green Version]
- Erharter, G.; Marcher, T.; Hansen, T.; Liu, Z. Reinforcement learning based process optimization and strategy development in conventional tunnelling. Autom. Constr. 2021, 127, 103701. [Google Scholar] [CrossRef]
- Zhang, P.; Li, H.; Ha, Q.; Yin, Z.Y.; Chen, R.P. Reinforcement learning based optimizer for improvement of predicting tunneling-induced ground responses. Adv. Eng. Informatics 2020, 45, 101097. [Google Scholar] [CrossRef]
- Van Rossum, G.; Drake, F.L. Python 3 Reference Manual; CreateSpace: Scotts Valley, CA, USA, 2009. [Google Scholar]
- Andrew, A. Reinforcement Learning: An Introduction. Kybernetes 1998, 27, 1093–1096. [Google Scholar] [CrossRef]
- Bowyer, C. Characteristics of Rewards in Reinforcement Learning, 2022. Available online: https://medium.com/mlearning-ai/characteristics-of-rewards-in-reinforcement-learning-f5722079aef5 (accessed on 11 March 2023).
- Singh, N. A Comprehensive Guide to Reinforcement Learning. Available online: https://www.analyticsvidhya.com/blog/2021/10/a-comprehensive-guide-to-reinforcement-learning (accessed on 18 May 2022).
- Gütter, W.; Jäger, M.; Rudigier, G.; Weber, W. TBM versus NATM from the contractor’s point of view. Geomech. Tunn. 2011, 4, 327–336. [Google Scholar] [CrossRef]
- Schuck, N.W.; Wilson, R.; Niv, Y. Chapter 12 - A State Representation for Reinforcement Learning and Decision-Making in the Orbitofrontal Cortex. In Goal-Directed Decision Making; Morris, R., Bornstein, A., Shenhav, A., Eds.; Academic Press: New York, NY, USA, 2018; pp. 259–278. [Google Scholar] [CrossRef] [Green Version]
- Kit Machine. Is Domain Knowledge Important for Machine Learning? 2022. Available online: https://www.kit-machines.com/domain-knowledge-machine-learning/ (accessed on 11 March 2023).
- Chen, R.; Tang, L.; Ling, D.; Chen, Y. Face stability analysis of shallow shield tunnels in dry sandy ground using the discrete element method. Comput. Geotech. 2011, 38, 187–195. [Google Scholar] [CrossRef]
- Leca, E.; New, B. Settlements induced by tunneling in Soft Ground. Tunn. Undergr. Space Technol. 2007, 22, 119–149. [Google Scholar] [CrossRef]
- ITAtech Activity Group Investigation. Geophysical Ahead Investigation Methods Seismic Methods; Technical Report ITAtech Report No. 10; International Tunnelling Association: Salt Lake City, UT, USA, 2018. [Google Scholar]
- Shirlaw, N. Setting operating pressures for TBM tunnelling. In Proceedings of the HKIE Geotechnical Division Annual Seminar, 2012: Geotechnical Aspects of Tunnelling for Infrastructure, Hong Kong, China, 13 May 2022; The Hong Kong Institution of Engineers: Hong Kong, China, 2012; pp. 7–28. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y. Deep Reinforcement Learning: An Overview. arXiv 2017, arXiv:1701.07274. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems; Curran Associates: San Diego, CA, USA, 2019; Volume 32, pp. 8024–8035. [Google Scholar]
- Zai, A.; Brown, B. Deep Reinforcement Learning in Action; Manning: New York, NY, USA, 2020. [Google Scholar]
- Bengio, Y. Practical Recommendations for Gradient-Based Training of Deep Architectures. In Neural Networks: Tricks of the Trade: Second Edition; Springer: Berlin/Heidelberg, Germany, 2012; pp. 437–478. [Google Scholar] [CrossRef] [Green Version]
- Soranzo, E.; Guardiani, C.; Saif, A.; Wu, W. A Reinforcement Learning approach to the location of the non-circular critical slip surface of slopes. Comput. Geosci. 2022, 166, 105182. [Google Scholar] [CrossRef]
- Lin, L. Self-improving reactive agents based on reinforcement learning, planning and teaching. Mach. Learn. 1992, 8, 293–321. [Google Scholar] [CrossRef]
- McCloskey, M.; Cohen, N.J. Catastrophic Interference in Connectionist Networks: The Sequential Learning Problem. In Psychology of Learning and Motivation; Bower, G.H., Ed.; Academic Press: Cambridge, MA, USA, 1989; Volume 24, pp. 109–165. [Google Scholar] [CrossRef]
- Alsahly, A.; Stascheit, J.; Meschke, G. Advanced finite element modeling of excavation and advancement processes in mechanized tunneling. Adv. Eng. Softw. 2016, 100, 198–214. [Google Scholar] [CrossRef]
- Demagh, R.; Emeriault, F. 3D Modelling of Tunnel Excavation Using Pressurized Tunnel Boring Machine in Overconsolidated Soils. Stud. Geotech. Mech. 2014, 35, 3–17. [Google Scholar] [CrossRef]
- Hasanpour, R. Advance numerical simulation of tunneling by using a double shield TBM. Comput. Geotech. 2014, 57, 37–52. [Google Scholar] [CrossRef]
- Hasanpour, R.; Rostami, J.; Ünver, B. 3D finite difference model for simulation of double shield TBM tunneling in squeezing grounds. Tunn. Undergr. Space Technol. 2014, 40, 109–126. [Google Scholar] [CrossRef]
- Itasca Consulting Group. FLAC3D (Fast Lagrangian Analysis of Continua); Itasca Consulting Group: Minneapolis, MN, USA, 2009. [Google Scholar]
- Dias, T.G.S.; Bezuijen, A. TBM Pressure Models—Observations, Theory and Practice. In Proceedings of the Volume 5: Geotechnical Synergy in Buenos Aires 2015, Buenos Aires, Argentina, 5–18 November 2015; Sfriso, A.O., Ed.; IOS Press: Clifton, NJ, USA, 2015; pp. 347–375. [Google Scholar] [CrossRef]
- Vilalta, R.; Giraud-Carrier, C.; Brazdil, P.; Soares, C. Inductive Transfer. In Encyclopedia of Machine Learning; Springer: Boston, MA, USA, 2010; pp. 545–548. [Google Scholar] [CrossRef]
- Kasper, T.; Meschke, G. A 3D finite element simulation model for TBM tunnelling in soft ground. Int. J. Numer. Anal. Methods Geomech. 2004, 28, 1441–1460. [Google Scholar] [CrossRef]
- Kasper, T.; Meschke, G. On the influence of face pressure, grouting pressure and TBM design in soft ground tunnelling. Tunn. Undergr. Space Technol. 2006, 21, 160–171. [Google Scholar] [CrossRef]
- Fenton, G.; Griffiths, D. Risk Assessment in Geotechnical Engineering; John Wiley and Sonds: Hoboken, NJ, USA, 2008. [Google Scholar] [CrossRef]
- Bellemare, M.G.; Dabney, W.; Munos, R. A Distributional Perspective on Reinforcement Learning. arXiv 2017, arXiv:1707.06887. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | Outcome | Reward | Episode Termination |
|---|---|---|---|
| Excavation | Round completed | No | |
| Tunnel excavation completed | No | ||
| Support pressure | Choice of the support pressure | No | |
| Settlement | Additional settlement | No | |
| Surface settlement > 10 cm | −100 | Yes | |
| Numerical stability | Divergence of the calculation | −100 | Yes |
| Soil Parameter | Symbol | Unit | Minimum Value | Maximum Value | % Variation/m |
|---|---|---|---|---|---|
| Unit weight | (kN/m³) | 11 | 24 | ||
| Cohesion | c | (kPa) | 0 | 20 | |
| Friction angle | () | 20 | 40 | ||
| Young’s modulus | E | (MPa) | 10 | 100 |
| Hyperparameter | Values | Max. Reward |
|---|---|---|
| Discount factor | 0.01 | 621.0 |
| 0.15 | 657.2 | |
| 0.2 | 622.2 | |
| Learning rate | 637.1 | |
| 657.2 | ||
| 536.3 | ||
| Synchronisation frequency f | 5 | 657.2 |
| 10 | 644.2 | |
| 15 | 652.1 | |
| Memory size | 5 | 647.3 |
| 10 | 657.2 | |
| 15 | 562.8 | |
| Batch size | 5 | 630.0 |
| 2 | 657.2 | |
| 1 | 609.3 |
| Mean Reward | Standard Deviation | |
|---|---|---|
| 0.00 | 458.1 | 124.9 |
| 0.25 | 453.6 | 130.1 |
| 0.50 | 315.8 | 138.4 |
| 0.75 | 326.2 | 169.5 |
| 1.00 | 221.2 | 212.0 |
| Soil Parameter | Symbol | Unit | Layer 1 | Layer 2 | Layer 3 |
|---|---|---|---|---|---|
| Unit weight | (kN/m³) | 23.0 | 13.7 | 15.9 | |
| Cohesion | c | (kPa) | 14 | 1 | 11 |
| Friction angle | () | 25 | 23 | 34 | |
| Young’s modulus | E | (MPa) | 11 | 32 | 13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Soranzo, E.; Guardiani, C.; Wu, W. Reinforcement Learning for the Face Support Pressure of Tunnel Boring Machines. Geosciences 2023, 13, 82. https://doi.org/10.3390/geosciences13030082
Soranzo E, Guardiani C, Wu W. Reinforcement Learning for the Face Support Pressure of Tunnel Boring Machines. Geosciences. 2023; 13(3):82. https://doi.org/10.3390/geosciences13030082
Chicago/Turabian StyleSoranzo, Enrico, Carlotta Guardiani, and Wei Wu. 2023. "Reinforcement Learning for the Face Support Pressure of Tunnel Boring Machines" Geosciences 13, no. 3: 82. https://doi.org/10.3390/geosciences13030082
APA StyleSoranzo, E., Guardiani, C., & Wu, W. (2023). Reinforcement Learning for the Face Support Pressure of Tunnel Boring Machines. Geosciences, 13(3), 82. https://doi.org/10.3390/geosciences13030082