Probabilistic Substrate Classification with Multispectral Acoustic Backscatter: A Comparison of Discriminative and Generative Models


Abstract
:1. Introduction
2. Methods
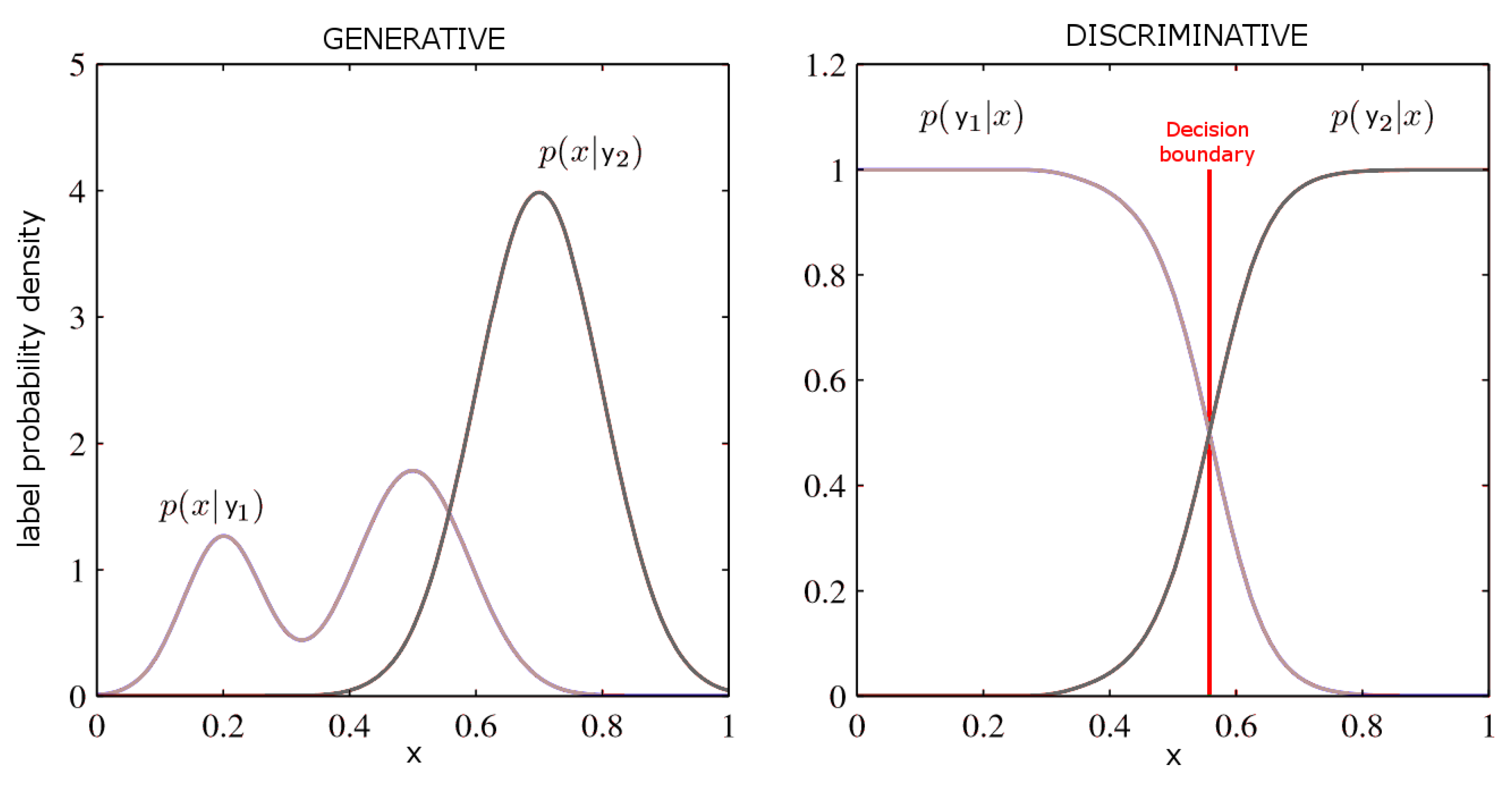
2.1. Discriminative Probabilistic Substrate Classification
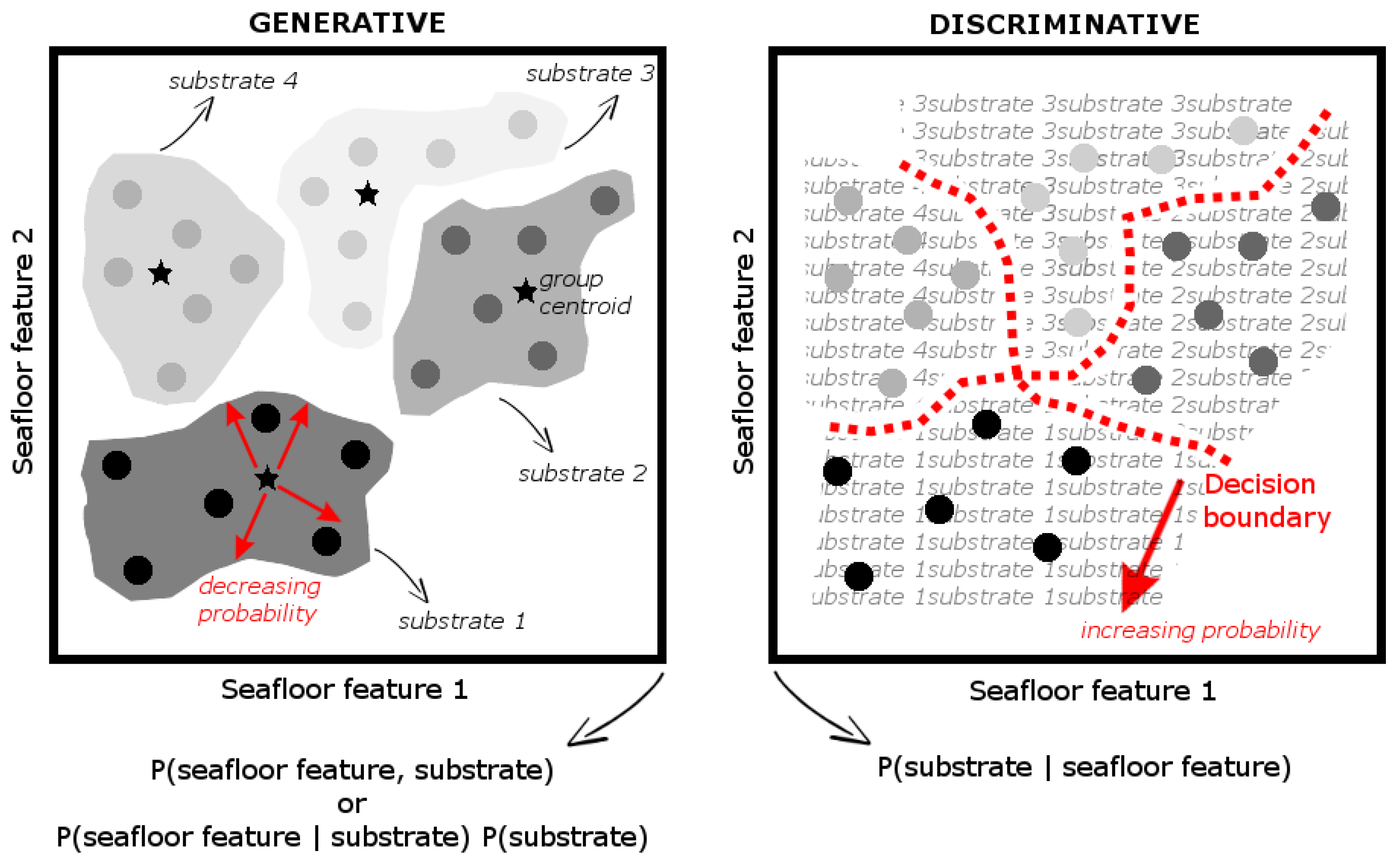
2.1.1. Graphical Models
2.1.2. Conditional Random Field
2.1.3. Fully Connected Conditional Random Field
2.2. Generative Model
2.2.1. Naïve Bayes Model
2.2.2. Gaussian Mixture Model
3. Data and Model Implementation
3.1. Backscatter
3.2. Bed Observations
3.2.1. GMM Model Implementation Details
3.2.2. CRF Model Implementation Details
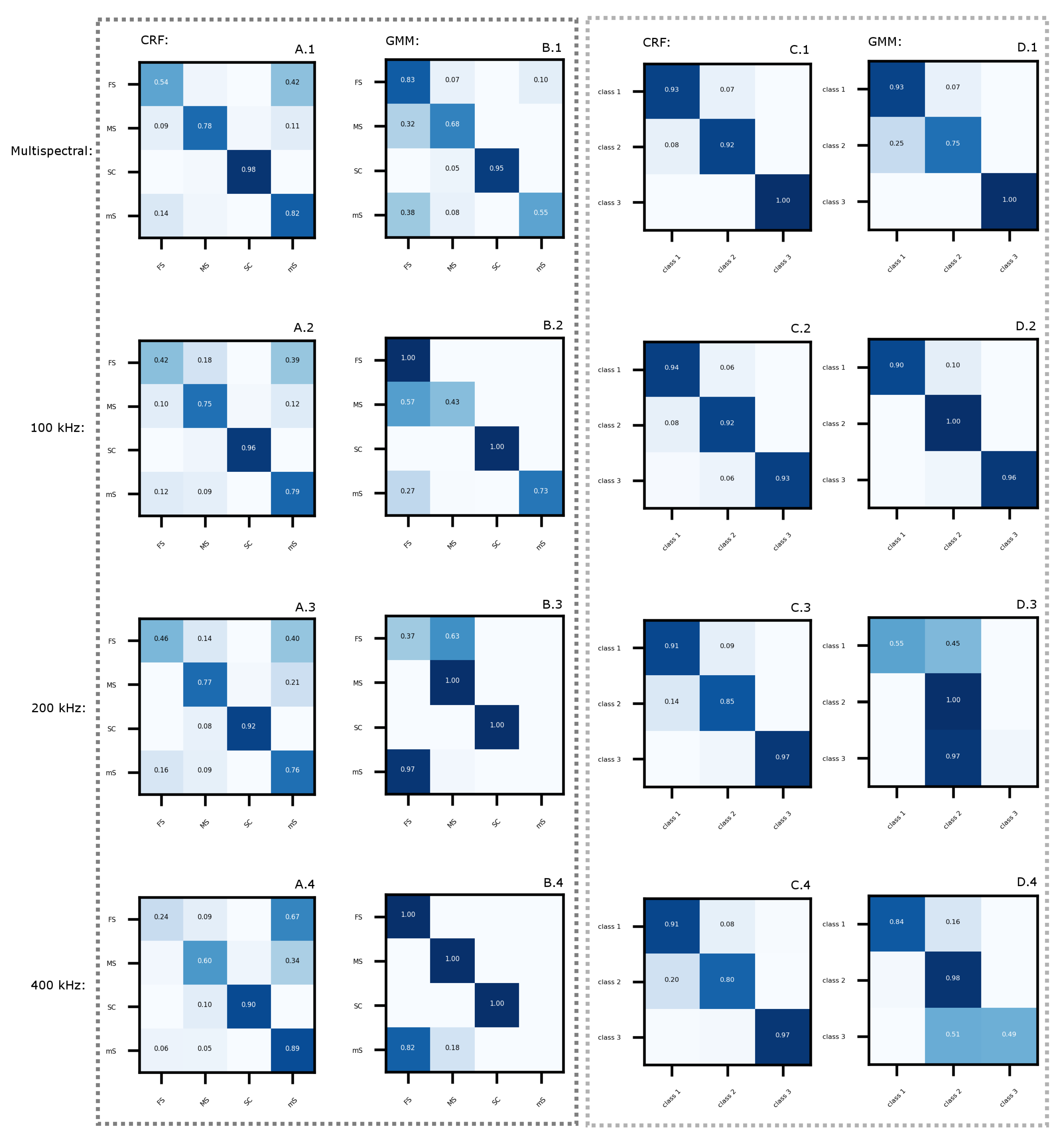
3.2.3. Model Evaluation
4. Results
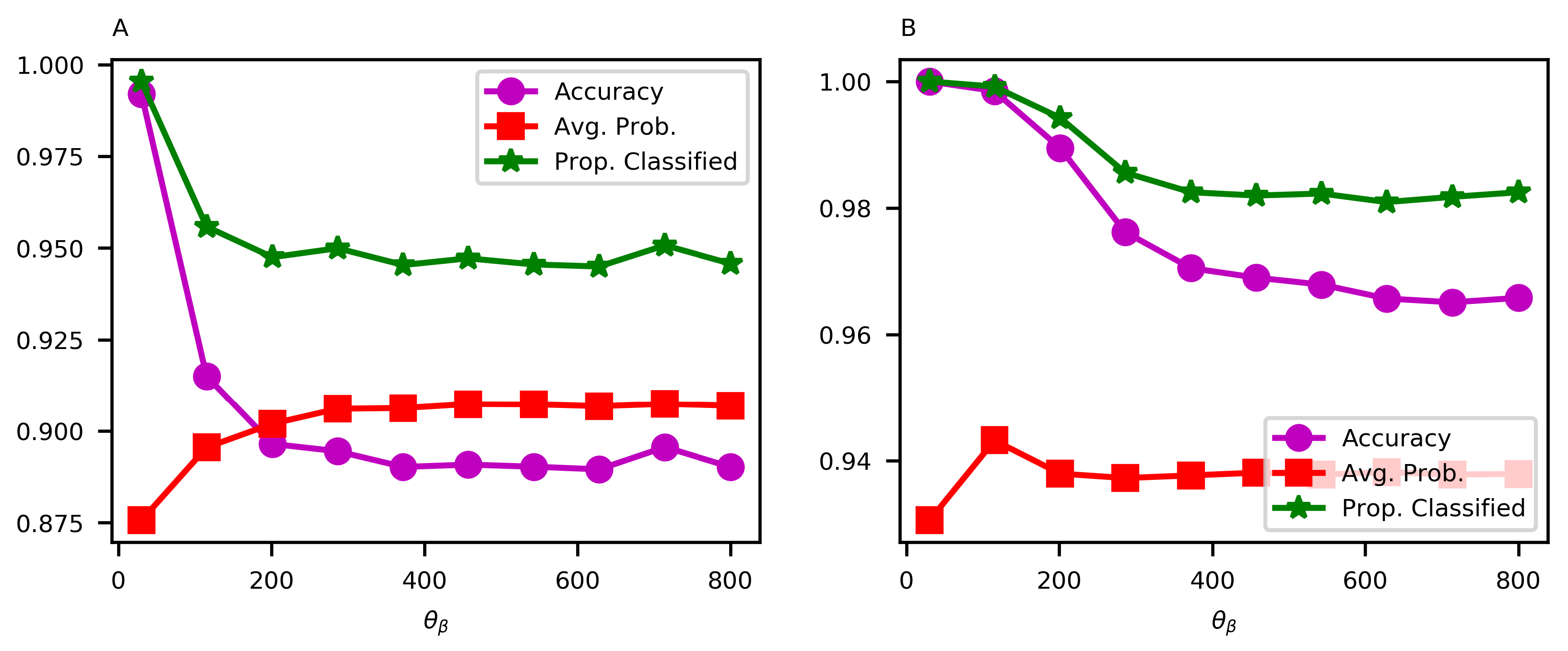
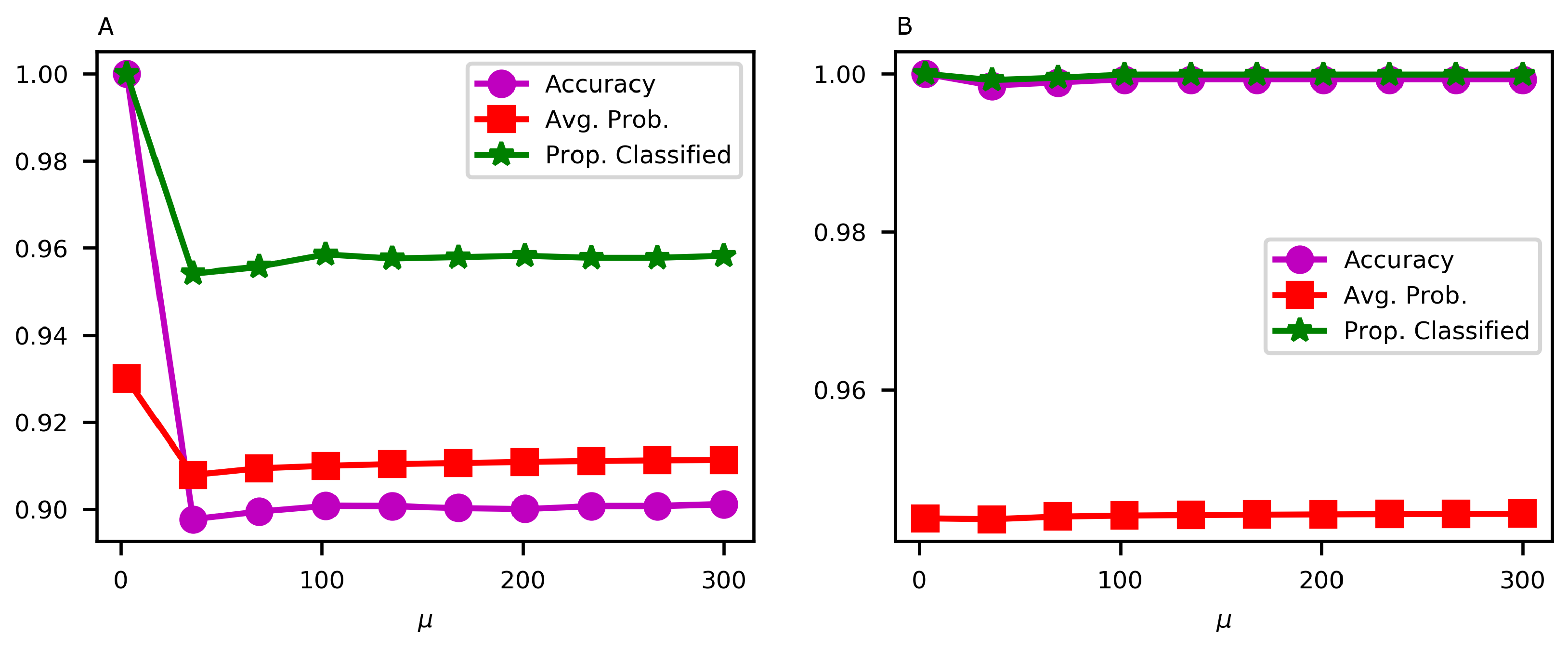
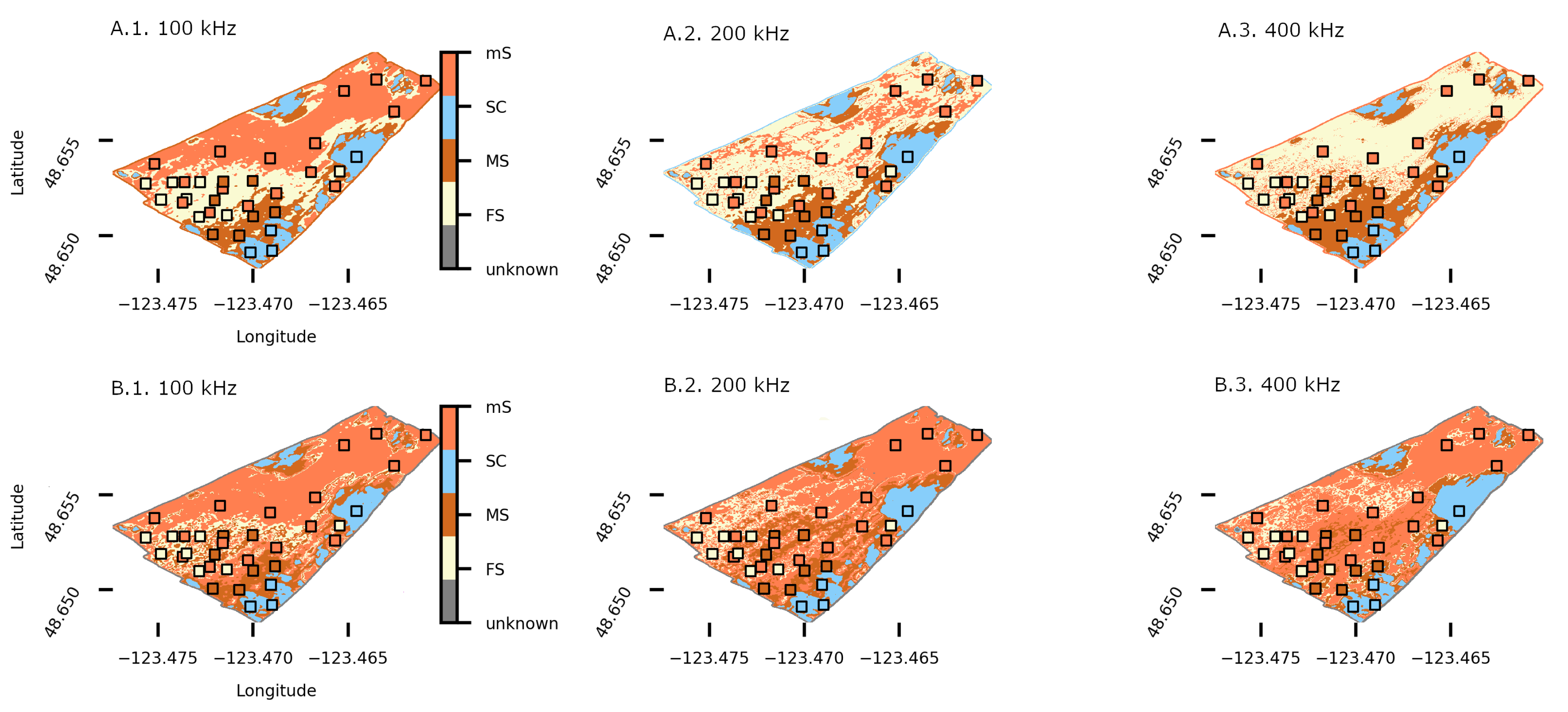
4.1. Conditional Random Field (CRF) Model: Sensitivity to and
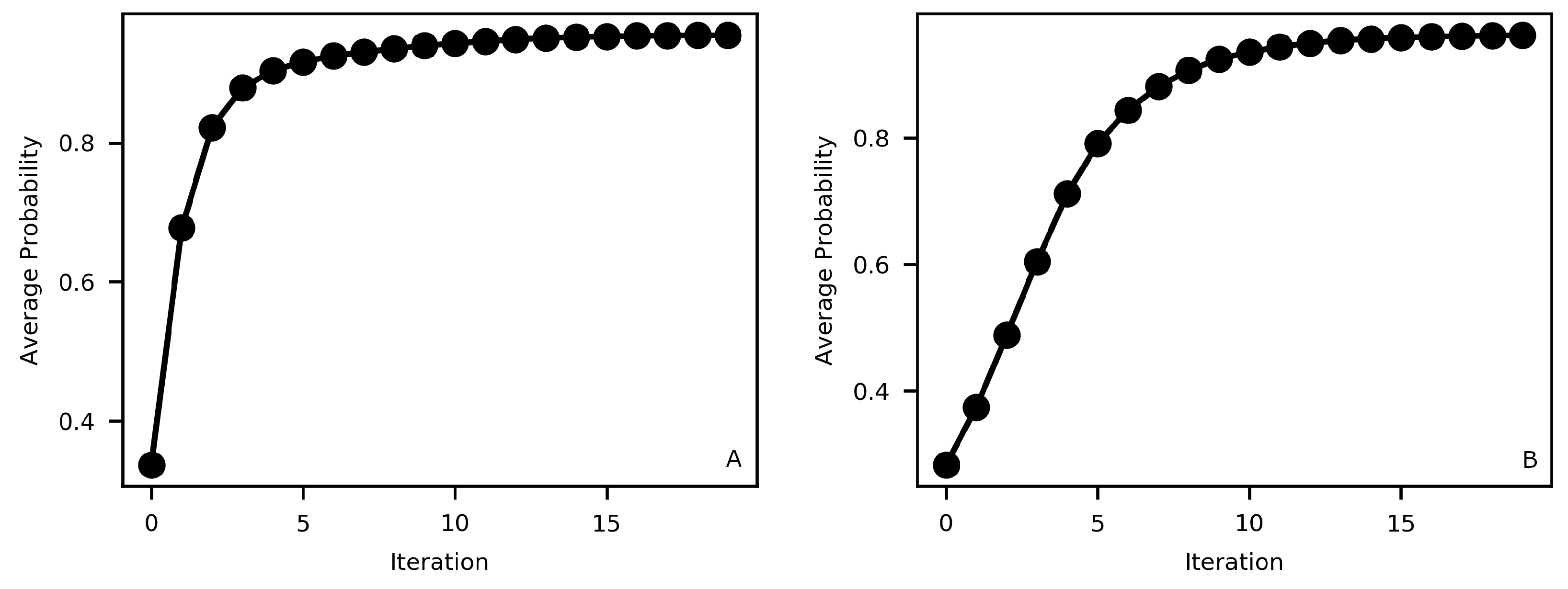
4.2. CRF: Number of Iterations
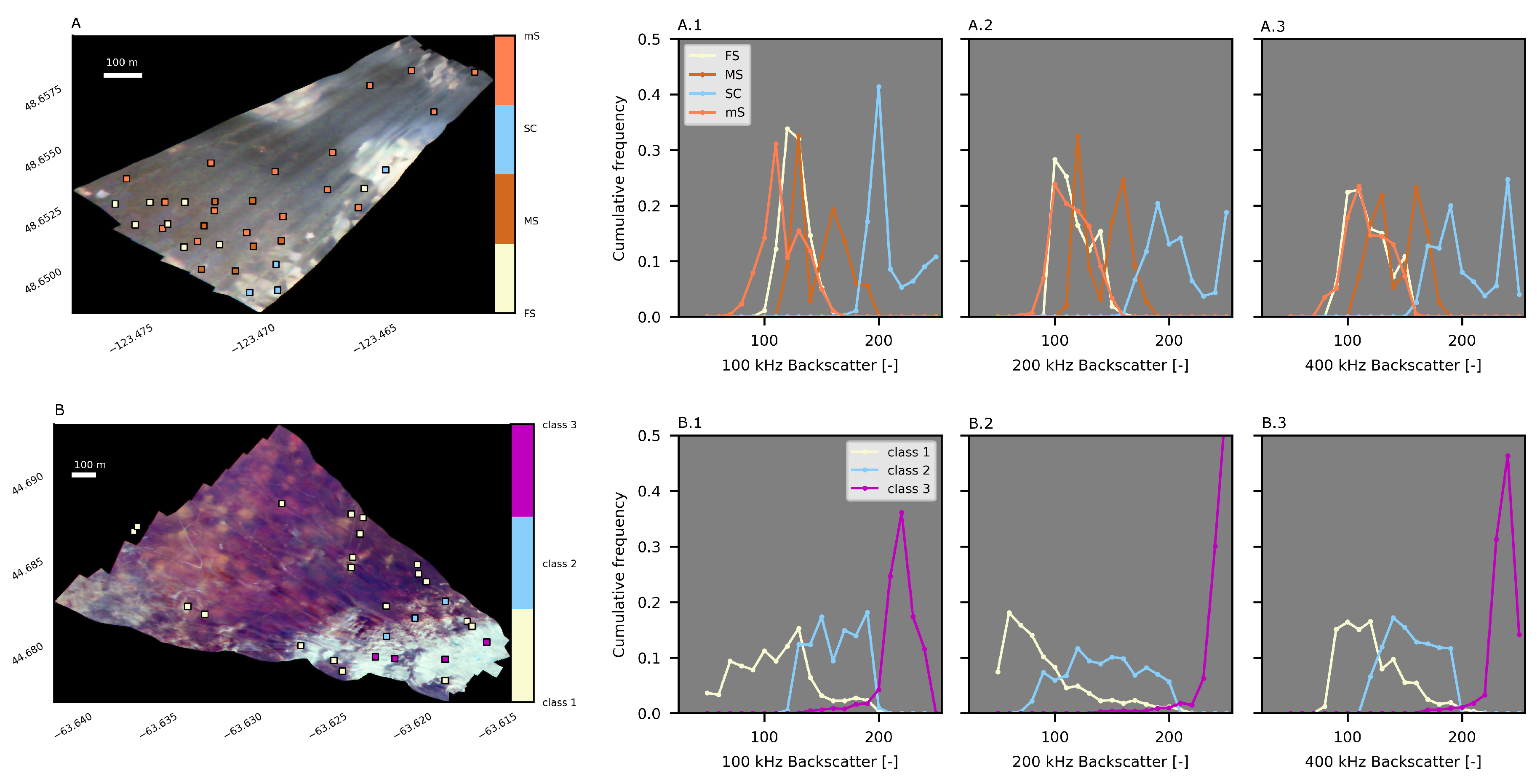
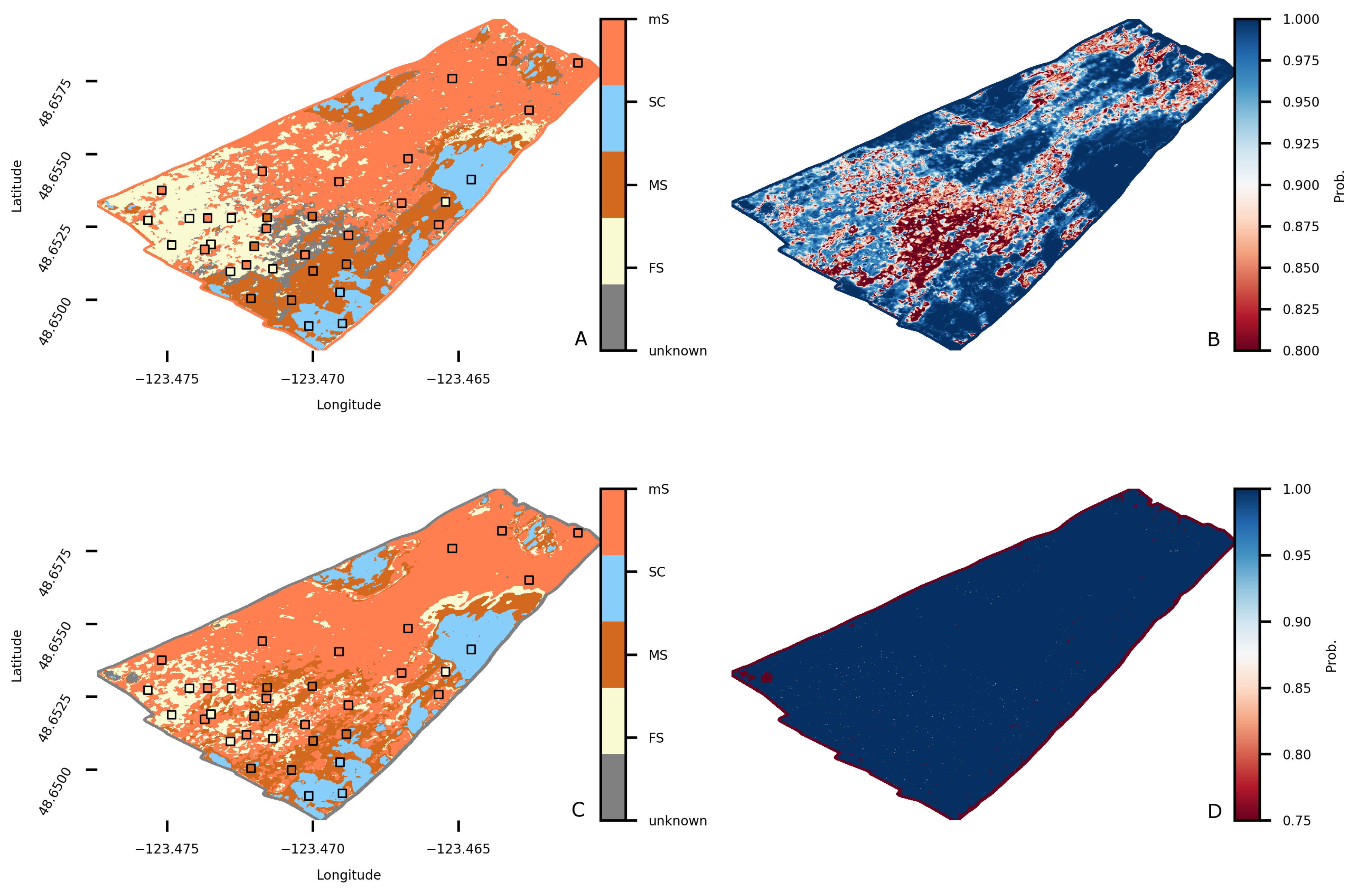
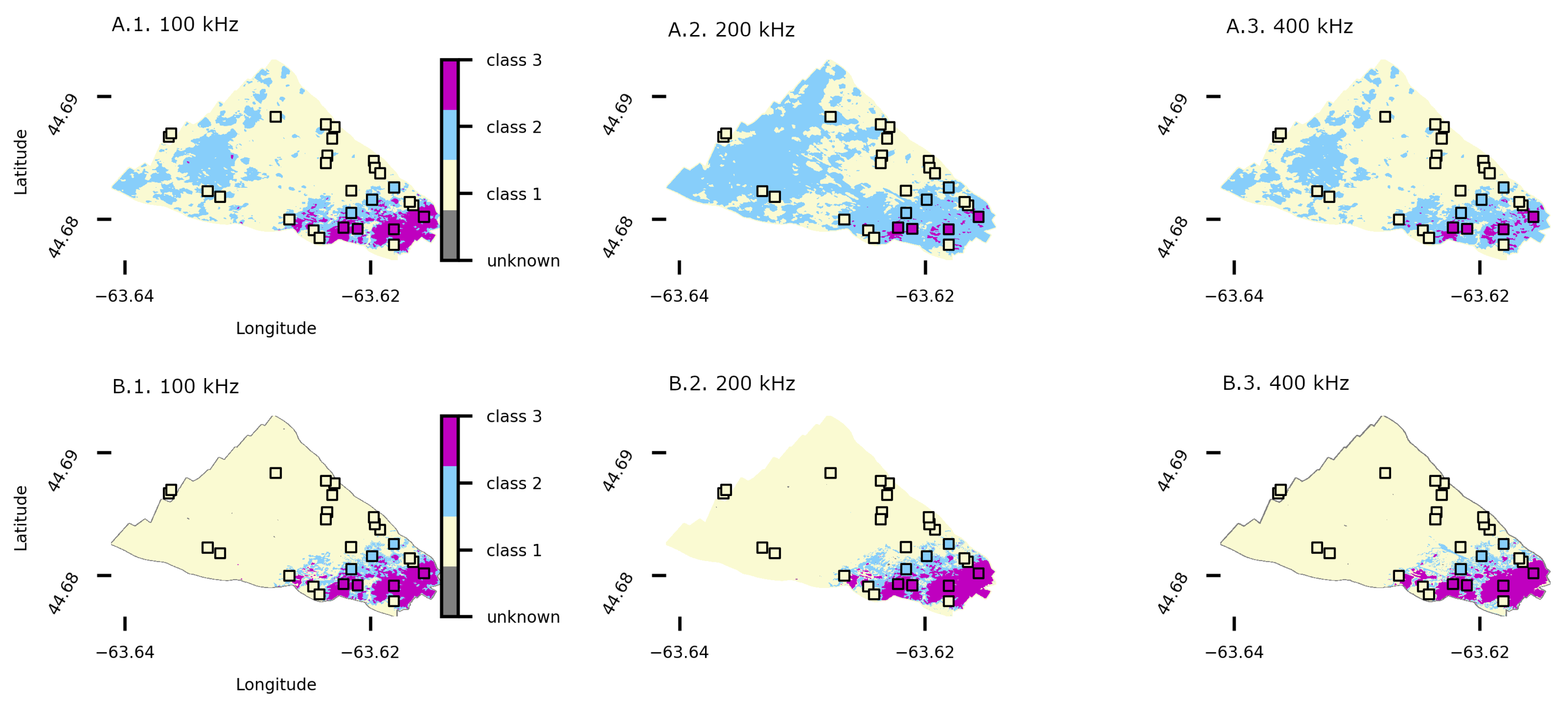
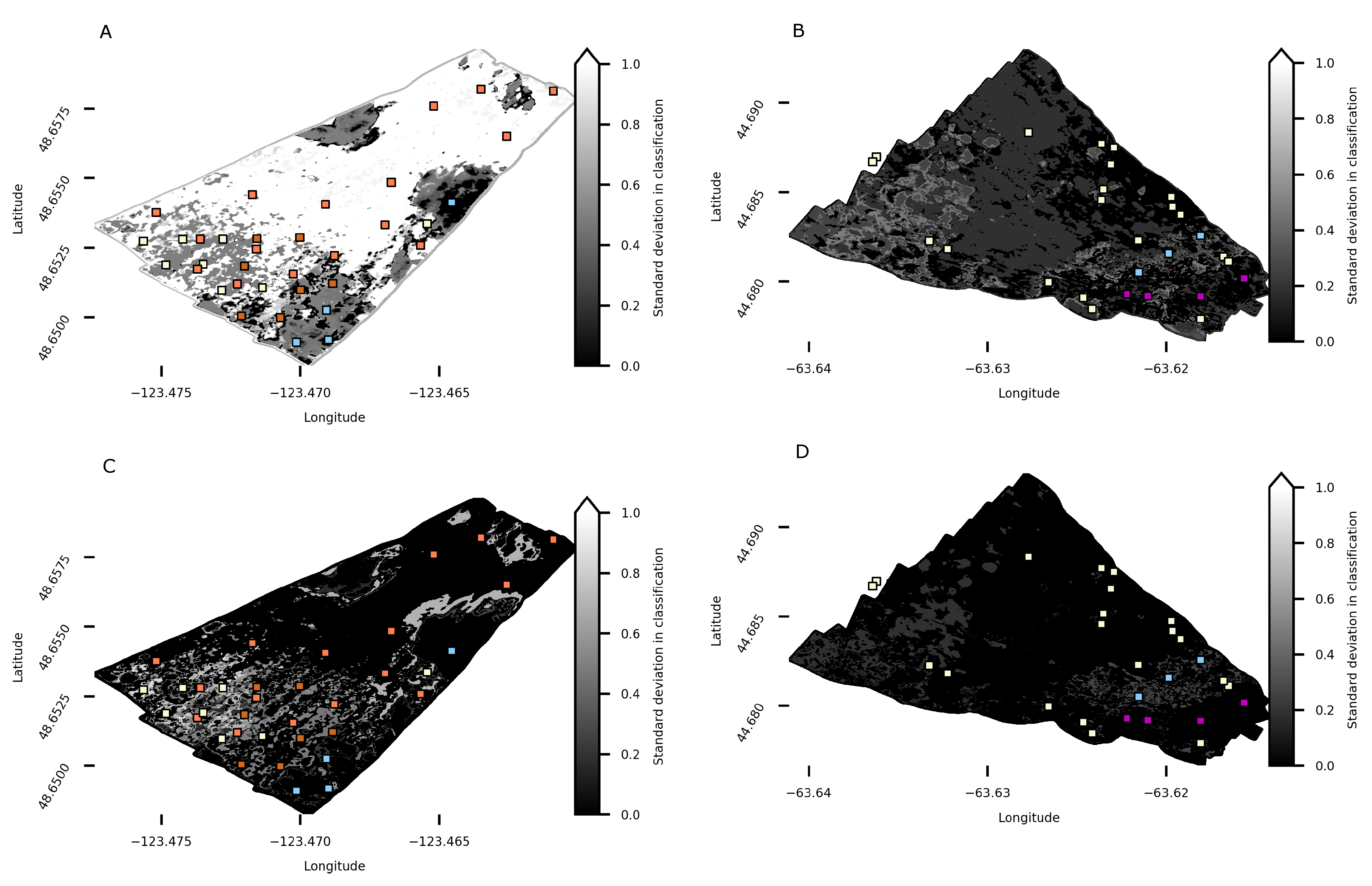
4.3. Patricia Bay Substrate Classification
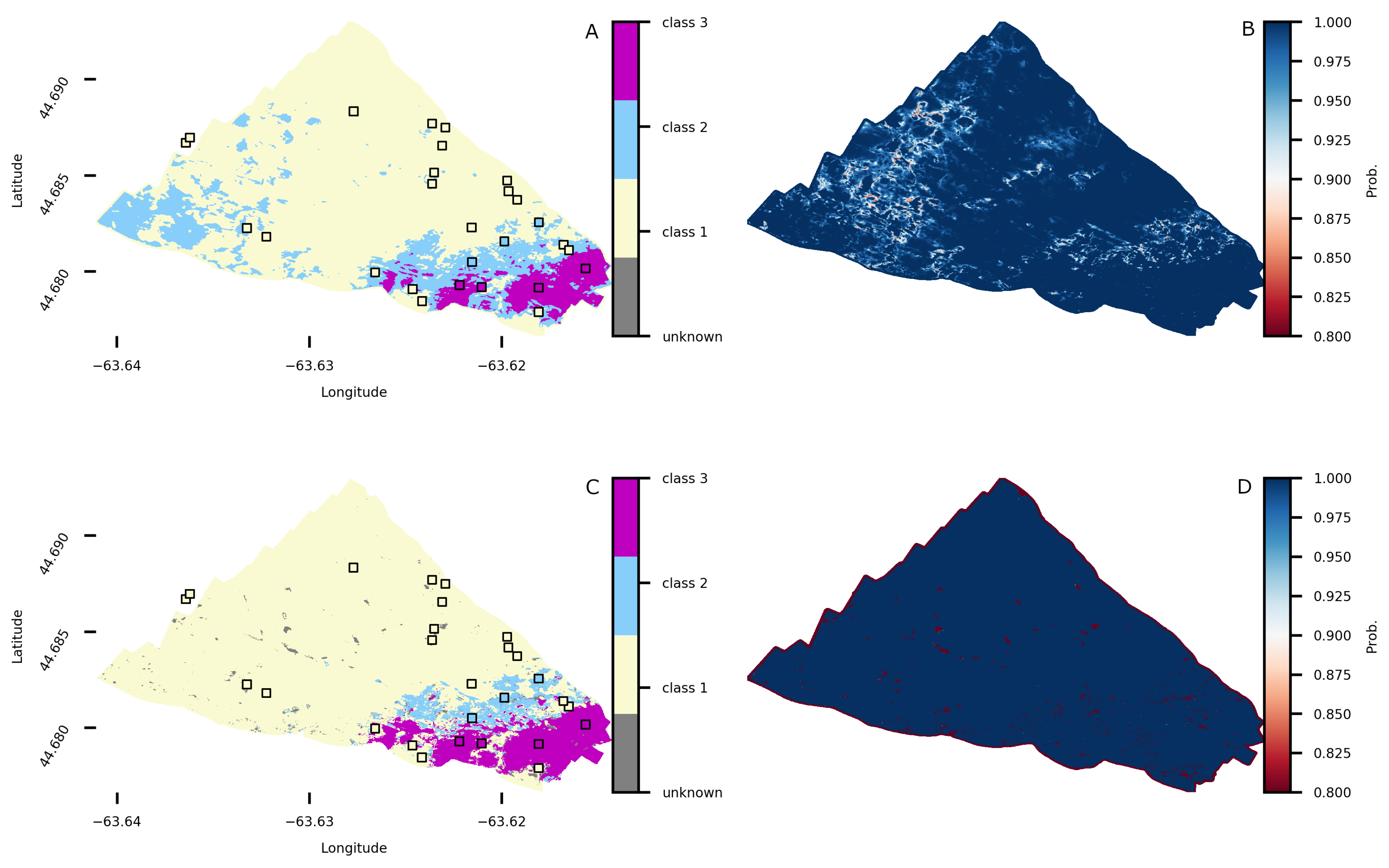
4.4. Bedford Basin Substrate Classification
4.5. Synthesis of All Model Results
5. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kenny, A.; Cato, I.; Desprez, M.; Fader, G.; Schuttenhelm, R.; Side, J. An overview of seabed-mapping technologies in the context of marine habitat classification. ICES J. Mar. Sci. 2003, 60, 411–418. [Google Scholar] [CrossRef] [Green Version]
- Brown, C.; Smith, S.; Lawton, P.; Anderson, J. Benthic habitat mapping: A review of progress towards improved understanding of the spatial ecology of the substrate using acoustic techniques. Estuar. Coast. Shelf Sci. 2011, 92, 502–520. [Google Scholar] [CrossRef]
- Mayer, L.; Jakobsson, M.; Allen, G.; Dorschel, B.; Falconer, R.; Ferrini, V.; Lamarche, G.; Snaith, H.; Weatherall, P. The Nippon Foundation–GEBCO Seabed 2030 Project: The Quest to See the World’s Oceans Completely Mapped by 2030. Geosciences 2018, 8, 2. [Google Scholar] [CrossRef]
- Ierodiaconou, D.; Monk, J.; Rattray, A.; Laurenson, L.; Versace, V. Comparison of automated classification techniques for predicting benthic biological communities using hydroacoustics and video observations. Cont. Shelf Res. 2011, 31, S28–S38. [Google Scholar] [CrossRef]
- Harris, P.; Baker, E. Why map benthic habitats. In Substrate Geomorphology as Benthic Habitat; Elsevier: London, UK, 2012; pp. 3–22. [Google Scholar]
- Amiri-Simkooei, A.; Snellen, M.; Simons, D. Riverbed sediment classification using multi-beam echo-sounder backscatter data. J. Acoust. Soc. Am. 2009, 126, 1724–1738. [Google Scholar] [CrossRef] [PubMed]
- Buscombe, D.; Grams, P.; Kaplinski, M. Compositional signatures in acoustic backscatter over vegetated and unvegetated mixed sand-gravel riverbeds. J. Geophys. Res. Earth Surf. 2017, 122, 1771–1793. [Google Scholar] [CrossRef]
- Lamarche, G.; Lurton, X. Recommendations for improved and coherent acquisition and processing of backscatter data from substrate-mapping sonars. Mar. Geophys. Res. 2018, 39, 5–22. [Google Scholar] [CrossRef]
- Schimel, A.; Beaudoin, J.; Parnum, I.; le Bas, T.; Schmidt, V.; Keith, G.; Ierodiaconou, D. Multibeam sonar backscatter data processing. Mar. Geophys. Res. 2018, 39, 121–137. [Google Scholar] [CrossRef]
- Malik, M.; Lurton, X.; Mayer, L. A framework to quantify uncertainties of substrate backscatter from swath mapping echosounders. Mar. Geophys. Res. 2018, 39, 1–18. [Google Scholar] [CrossRef]
- Roche, M.; Degrendele, K.; Vrignaud, C.; Loyer, S.; le Bas, T.; Augustin, J.; Lurton, X. Control of the repeatability of high frequency multibeam echosounder backscatter by using natural reference areas. Mar. Geophys. Res. 2018, 39, 89–104. [Google Scholar] [CrossRef]
- Lecours, V.; Dolan, M.; Micallef, A.; Lucieer, V.L. A review of marine geomorphometry, the quantitative study of the substrate. Hydrol. Earth Syst. Sci. 2016, 20, 3207–3244. [Google Scholar] [CrossRef]
- Diesing, M.; Mitchell, P.; Stephens, D. Image-based seabed classification: What can we learn from terrestrial remote sensing? ICES J. Mar. Sci. 2016, 73, 2425–2441. [Google Scholar] [CrossRef]
- Jackson, D.; Winebrenner, D.; Ishmaru, A. Application of the composite roughness model to high frequency bottom backscattering. J. Acoust. Soc. Am. 1986, 79, 1410–1422. [Google Scholar] [CrossRef]
- Jackson, D.; Richardson, M. High-Frequency Substrate Acoustics, 1st ed.; Springer Science & Business Media: New York, NY, USA, 2007; p. 616. [Google Scholar]
- Kloser, R.; Penrose, J.; Butler, A. Multi-beam backscatter measurements used to infer seabed habitats. Cont. Shelf Res. 2010, 30, 1772–1782. [Google Scholar] [CrossRef]
- Jackson, D.; Briggs, K.; Williams, K.; Richardson, M. Tests of models for high-frequency substrate backscatter. IEEE J. Ocean. Eng. 1996, 21, 458–470. [Google Scholar] [CrossRef]
- Diesing, M.; Stephens, D. A multi-model ensemble approach to seabed mapping. J. Sea Res. 2015, 100, 62–69. [Google Scholar] [CrossRef]
- Stephens, D.; Diesing, M. A comparison of supervised classification methods for the prediction of substrate type using multibeam acoustic and legacy grain-size data. PLoS ONE 2014, 9, e93950. [Google Scholar] [CrossRef] [PubMed]
- Dartnell, P.; Gardner, J. Predicting substrate facies from multibeam bathymetry and backscatter data. Photogramm. Eng. Remote. Sens. 2004, 70, 1081–1091. [Google Scholar] [CrossRef]
- Huvenne, V.; Robert, K.; Marsh, L.; Iacono, C.; le Bas, T.; Wynn, R. ROVs and AUVs. In Submarine Geomorphology; Springer: Berlin/Heidelberg, Germany, 2018; pp. 93–108. [Google Scholar]
- Buscombe, D.; Grams, P.; Kaplinski, M. Characterizing riverbed sediments using high-frequency acoustics 1: Spectral properties of scattering. J. Geophys. Res. Earth Surf. 2014, 119, 2674–2691. [Google Scholar] [CrossRef]
- Murphy, K. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, UK, 2012. [Google Scholar]
- Simons, D.; Snellen, M. A Bayesian approach to substrate classification using multi-beam echo-sounder backscatter data. Appl. Acoust. 2009, 70, 1258–1268. [Google Scholar] [CrossRef]
- Marsh, I.; Brown, C. Neural network classification of multibeam backscatter and bathymetry data from Stanton Bank (Area IV). Appl. Acoust. 2009, 70, 1269–1276. [Google Scholar] [CrossRef]
- Buscombe, D.; Grams, P.; Kaplinski, M. Characterizing riverbed sediments using high-frequency acoustics 2: Scattering signatures of Colorado River bed sediments in Marble and Grand Canyons. J. Geophys. Res. Earth Surf. 2014, 119, 2692–2710. [Google Scholar] [CrossRef]
- Lucieer, V.; Hill, N.; Barrett, N.; Nichol, S. Do marine substrates ‘look’ and ‘sound’ the same? Supervised classification of multibeam acoustic data using autonomous underwater vehicle images. Estuar. Coast. Shelf Sci. 2013, 117, 94–106. [Google Scholar] [CrossRef]
- Beaudoin, J.; Clarke, J.H.; Doucet, M.; Brown, C.; Brissette, M.; Gazzola, V. Setting the Stage for Multispectral Acoustic Backscatter Research; GeoHab: Winchester, UK, 2016. [Google Scholar]
- Feldens, P.; Schulze, I.; Papenmeier, S.; Schönke, M.; von Deimling, J.S. Improved Interpretation of Marine Sedimentary Environments Using Multi-Frequency Multibeam Backscatter Data. Geosciences 2018, 8, 214. [Google Scholar] [CrossRef]
- Koller, D.; Friedman, N. Probabilistic Graphical Models: Principles and Techniques; MIT Press: Cambridge, UK, 2009; pp. 104–109. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. Int. Conf. Mach. Learn. (ICML) 2001, 282–289. [Google Scholar]
- Zhu, H.; Meng, F.; Cai, J.; Lu, S. Beyond pixels: A comprehensive survey from bottom-up to semantic image segmentation and cosegmentation. J. Vis. Commun. Image Represent. 2016, 34, 12–27. [Google Scholar] [CrossRef] [Green Version]
- Buscombe, D.; Ritchie, A.C. Landscape Classification with Deep Neural Networks. Geosciences 2018, 8, 244. [Google Scholar] [CrossRef]
- Kumar, S.; Hebert, M. Discriminative random fields. Int. J. Comput. Vision 2006, 68, 179–201. [Google Scholar] [CrossRef]
- Krähenbühl, P.; Koltu, V.N. Efficient inference in fully connected CRFs with Gaussian edge potentials. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: Granada, Spain, 2011; pp. 109–117. [Google Scholar]
- Tappen, M.; Liu, C.; Adelson, E.; Freeman, W. Learning Gaussian conditional random fields for low-level vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Parameter learning and convergent inference for dense random fields. In Proceedings of the International Conference on Machine Learning, Atlanta, CA, USA, 16–21 June 2013; pp. 513–521. [Google Scholar]
- Hamill, D.; Buscombe, D.; Wheaton, J.M. Alluvial substrate mapping by automated texture segmentation of recreational-grade side scan sonar imagery. PLoS ONE 2018, 13, e0194373. [Google Scholar] [CrossRef] [PubMed]
- Bishop, C. Pattern Recognition and Machine Learning; Springer Science and Business Media: New York, NY, USA, 2006. [Google Scholar]
- Ainslie, M.; McColm, J. A simplified formula for viscous and chemical absorption in sea water. J. Acoust. Soc. Am. 1998, 103, 1671–1672. [Google Scholar] [CrossRef]
- Fader, G.B.J.; Miller, R.O. Surficial geology, Halifax Harbour, Nova Scotia. Bull. Geol. Surv. Can. 2008, 590, 163. [Google Scholar]
- Biffard, B. Seabed Remote Sensing by Single-Beam Echosounder: Models, Methods and Applications. Ph.D. Thesis, University of Victoria, Victoria, BC, Canada, 2011. [Google Scholar]
- Brown, C.; Varma, H.; Multispectral Seafloor Classification: Applying a Multidimensional Hypercube Approach to Unsupervised Seafloor Segmentation. R2Sonic Multispectral Backscatter Competition Entry. Available online: https://www.r2sonic.com/geohab2018/ (accessed on 10 January 2018).
- Gavrilov, A.; Parnum, I. Fluctuations of substrate backscatter data from multibeam sonar systems. IEEE J. Ocean. Eng. 2010, 35, 209–219. [Google Scholar] [CrossRef]
- Lasserre, J.; Bishop, C.; Minka, T. Principled hybrids of generative and discriminative models. IEEE. Conf. Comp. Vision (CVPR) 2006, 1, 87–94. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neur. Inf. Process. Syst. 2014, 2672–2680. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Patricia Bay | Bedford | |
|---|---|---|
| absorption @ 100 kHz [dB/km] | 28.9 | 23.1 |
| absorption @ 200 kHz [dB/km] | 48.4 | 39.3 |
| absorption @ 400 kHz [dB/km] | 89.1 | 91.7 |
| response @ 100 kHz [dB] | 25.6 | 23.6 |
| response @ 200 kHz [dB] | 12.9 | 12.9 |
| response @ 400 kHz [dB] | 4.8 | 4.8 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Buscombe, D.; Grams, P.E. Probabilistic Substrate Classification with Multispectral Acoustic Backscatter: A Comparison of Discriminative and Generative Models. Geosciences 2018, 8, 395. https://doi.org/10.3390/geosciences8110395
Buscombe D, Grams PE. Probabilistic Substrate Classification with Multispectral Acoustic Backscatter: A Comparison of Discriminative and Generative Models. Geosciences. 2018; 8(11):395. https://doi.org/10.3390/geosciences8110395
Chicago/Turabian StyleBuscombe, Daniel, and Paul E. Grams. 2018. "Probabilistic Substrate Classification with Multispectral Acoustic Backscatter: A Comparison of Discriminative and Generative Models" Geosciences 8, no. 11: 395. https://doi.org/10.3390/geosciences8110395
APA StyleBuscombe, D., & Grams, P. E. (2018). Probabilistic Substrate Classification with Multispectral Acoustic Backscatter: A Comparison of Discriminative and Generative Models. Geosciences, 8(11), 395. https://doi.org/10.3390/geosciences8110395