Deep Fake Image Detection Based on Pairwise Learning


Abstract
:1. Introduction
- A fake face image detector based on the novel CFFN, consisting of an improved DenseNet backbone network and Siamese network architecture, is proposed.
- The cross-layer features are investigated by the proposed CFFN, which can be used to improve the performance.
- The pairwise learning approach is used to improve the generalization property of the proposed DeepFD.
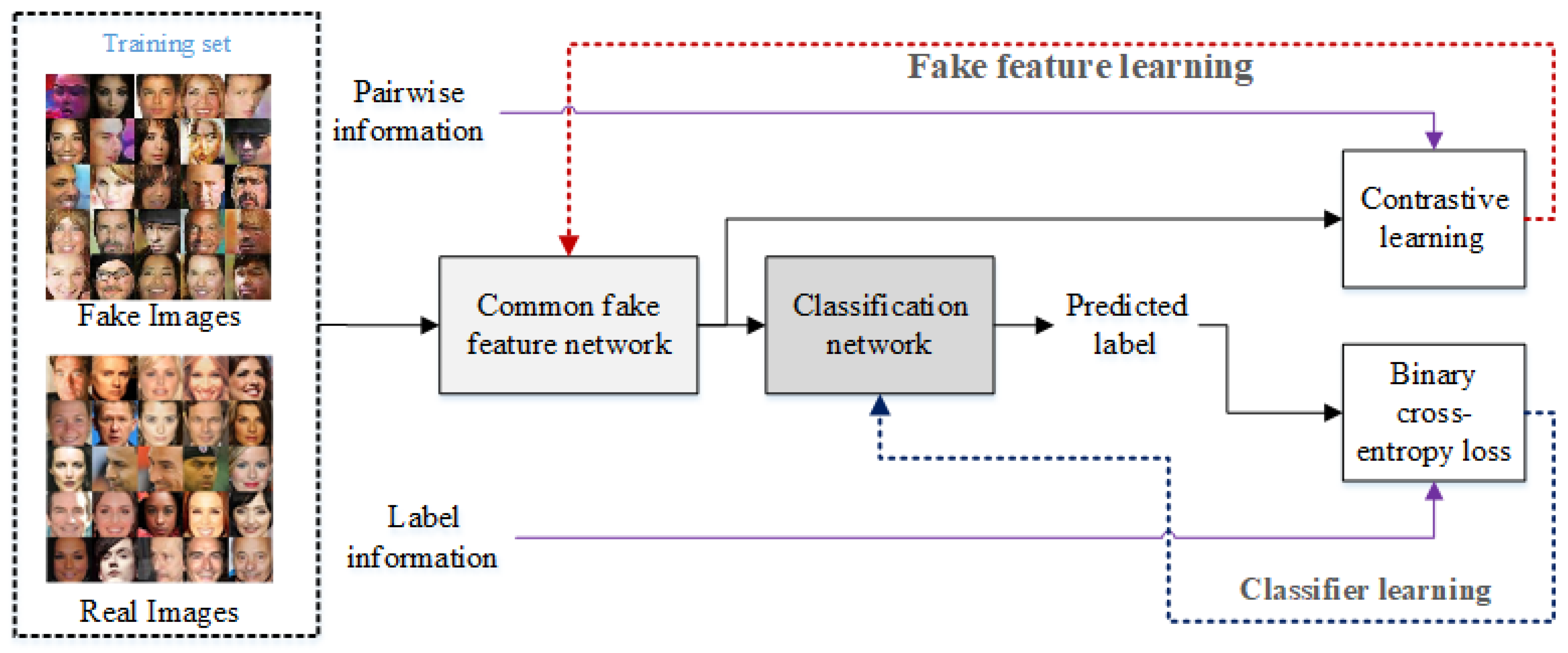
2. Fake Face Image Detection
2.1. Common Fake Feature Network
2.2. Discriminative Feature Learning
2.3. Classification Learning
2.4. Two-Step Learning Policy
3. Fake General Image Detection
4. Experimental Results
4.1. Fake Face Image Detection
4.1.1. Data Collection
4.1.2. Experimental Settings
4.1.3. Objective Performance Comparison
4.1.4. Visualized Result
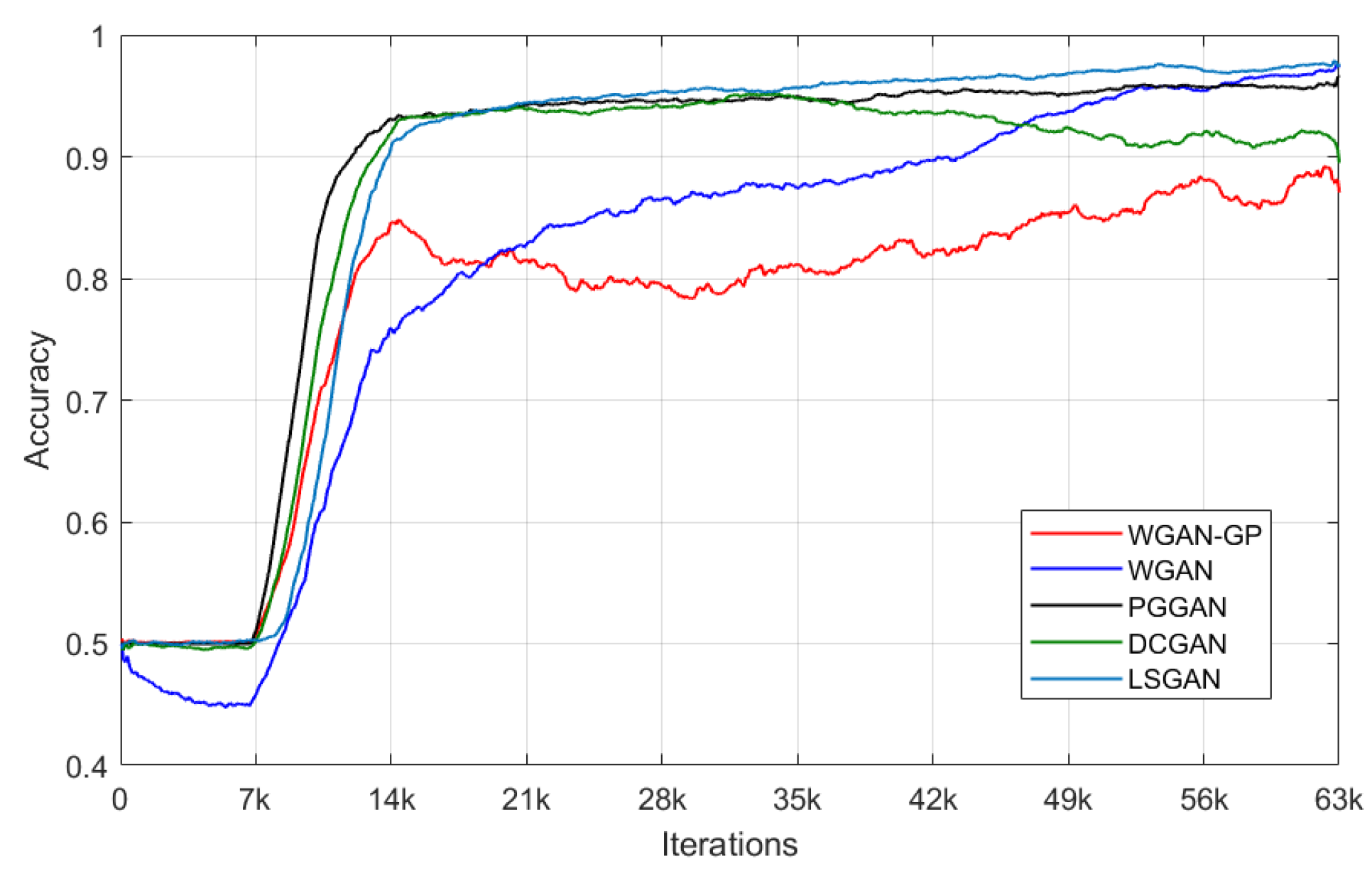
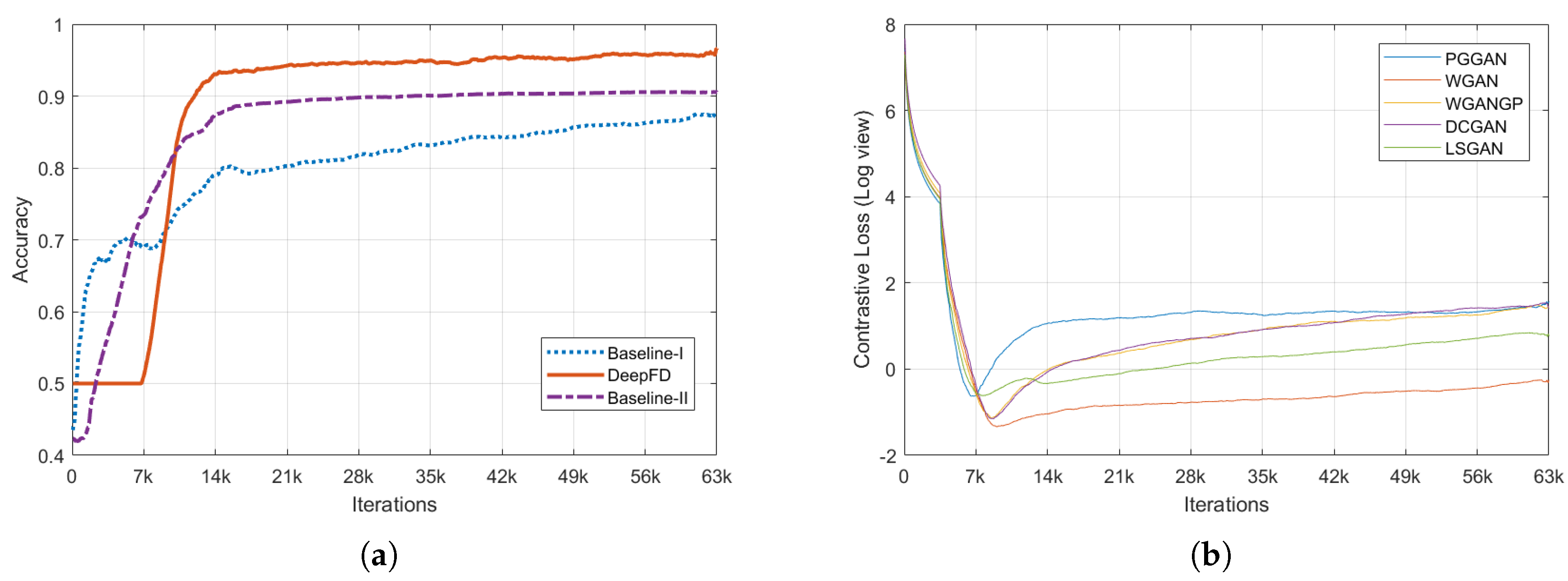
4.1.5. Training Convergence
4.2. Fake General Image Detection
4.3. Discussions and Limitations
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CNN | Convolution neural network |
| CFF | Common fake feature |
| CFFN | Common fake feature network |
| DeepFD | Deep fake image detector |
| GAN | Generative adversarial nets |
References
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of GANs for Improved Quality, Stability, and Variation. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large scale GAN training for high fidelity natural image synthesis. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef] [Green Version]
- AI Can Now Create Fake Porn, Making Revenge Porn Even More Complicated. 2018. Available online: https://theconversation.com/ai-can-now-create-fake-porn-making-revenge-porn-even-more-complicated-92267 (accessed on 30 March 2019).
- Hsu, C.; Lee, C.; Zhuang, Y. Learning to detect fake face images in the Wild. In Proceedings of the 2018 International Symposium on Computer, Consumer and Control (IS3C), Taichung, Taiwan, 6–8 December 2018; pp. 388–391. [Google Scholar] [CrossRef] [Green Version]
- Chang, H.T.; Hsu, C.C.; Yeh, C.H.; Shen, D.F. Image authentication with tampering localization based on watermark embedding in wavelet domain. Opt. Eng. 2009, 48, 057002. [Google Scholar]
- Hsu, C.C.; Hung, T.Y.; Lin, C.W.; Hsu, C.T. Video forgery detection using correlation of noise residue. In Proceedings of the IEEE Workshop on Multimedia Signal Processing, Cairns, Australia, 8–10 October 2008; pp. 170–174. [Google Scholar]
- Farid, H. Image forgery detection. IEEE Signal Process. Mag. 2009, 26, 16–25. [Google Scholar] [CrossRef]
- Huaxiao Mo, B.C.; Luo, W. Fake Faces Identification via Convolutional Neural Network. In Proceedings of the ACM Workshop on Information Hiding and Multimedia Security, Innsbruck, Austria, 20–22 June 2018; pp. 43–47. [Google Scholar]
- Dang, L.; Hassan, S.; Im, S.; Lee, J.; Lee, S.; Moon, H. Deep learning based computer generated face identification using convolutional neural network. Appl. Sci. 2018, 8, 2610. [Google Scholar] [CrossRef] [Green Version]
- Marra, F.; Gragnaniello, D.; Cozzolino, D.; Verdoliva, L. Detection of GAN-Generated Fake Images over Social Networks. In Proceedings of the IEEE Conference on Multimedia Information Processing and Retrieval, Miami, FL, USA, 10–12 April 2018; pp. 384–389. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1610–02357. [Google Scholar]
- Dang, L.M.; Hassan, S.I.; Im, S.; Moon, H. Face image manipulation detection based on a convolutional neural network. Expert Syst. Appl. 2019, 129, 156–168. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5767–5777. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Smolley, S.P. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2813–2821. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Chopra, S.; Hadsell, R.; LeCun, Y. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 539–546. [Google Scholar]
- LeCun, Y.; Boser, B.E.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.E.; Jackel, L.D. Handwritten digit recognition with a back-propagation network. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 26–29 November 1990; pp. 396–404. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1139–1147. [Google Scholar]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Is object localization for free?-weakly-supervised learning with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 685–694. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-Attention generative adversarial networks. In Proceedings of the 36th International Conference on Machine Learning; Chaudhuri, K., Salakhutdinov, R., Eds.; PMLR: Long Beach, CA, USA, 2019; Volume 97, pp. 7354–7363. [Google Scholar]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral normalization for generative adversarial networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Number | Feature Learning | Classification |
|---|---|---|
| 1 | conv. layer, kernel = 7 × 7, stride = 4, #channels = 48 | Conv. layer, kernel = 3 × 3, #channels = 2 |
| 2 | Dense block × 2, #channels = 48 | Global average pooling |
| 3 | Dense block × 3, #channels = 60 | Fully connected layer, neurons = 2 |
| 4 | Dense block × 4, #channels = 78 | |
| 5 | Dense block × 2, #channels = 126 | |
| 6 | Fully connected layer, neurons = 128 | SoftMax layer |
| Layer Number | Feature Learning | Classification |
|---|---|---|
| 1 | conv. layer, kernel = 7 × 7, stride = 4, #channels = 48 | Conv. layer, kernel = 3 × 3, #channels = 2 |
| 2 | Dense block × 3, #channels = 60 | Global average pooling |
| 3 | Dense block × 4, #channels = 78 | Fully connected layer, neurons = 2 |
| 4 | Dense block × 5, #channels = 99 | |
| 5 | Dense block × 3, #channels = 171 | |
| 6 | Fully connected layer, neurons = 128 | SoftMax layer |
| Method/Target | WGAN-GP | DCGAN | WGAN | LSGAN | PGGAN | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall | |
| Method in [8] | 0.322 | 0.373 | 0.334 | 0.349 | 0.371 | 0.391 | 0.350 | 0.396 | 0.345 | 0.378 |
| Method in [9] | 0.769 | 0.602 | 0.749 | 0.689 | 0.809 | 0.743 | 0.808 | 0.761 | 0.817 | 0.703 |
| Method in [11] | 0.792 | 0.684 | 0.820 | 0.811 | 0.864 | 0.881 | 0.848 | 0.869 | 0.868 | 0.853 |
| Method in [10] | 0.830 | 0.671 | 0.827 | 0.796 | 0.882 | 0.869 | 0.862 | 0.854 | 0.881 | 0.875 |
| Method in [5] | 0.832 | 0.690 | 0.871 | 0.847 | 0.885 | 0.920 | 0.866 | 0.898 | 0.922 | 0.909 |
| Baseline-I | 0.876 | 0.711 | 0.882 | 0.887 | 0.902 | 0.920 | 0.900 | 0.914 | 0.938 | 0.901 |
| Baseline-II | 0.901 | 0.728 | 0.822 | 0.838 | 0.864 | 0.881 | 0.920 | 0.919 | 0.917 | 0.887 |
| The proposed | 0.986 | 0.751 | 0.929 | 0.916 | 0.988 | 0.927 | 0.947 | 0.986 | 0.988 | 0.948 |
| Method/Target | BIGGAN | SA-GAN | SN-GAN | |||
|---|---|---|---|---|---|---|
| Precision | Recall | Precision | Recall | Precision | Recall | |
| Method in [8] | 0.358 | 0.409 | 0.430 | 0.509 | 0.354 | 0.424 |
| Method in [9] | 0.580 | 0.673 | 0.610 | 0.723 | 0.585 | 0.691 |
| Method in [11] | 0.650 | 0.737 | 0.682 | 0.762 | 0.653 | 0.691 |
| Method in [5] | 0.734 | 0.763 | 0.775 | 0.782 | 0.743 | 0.747 |
| Baseline-I | 0.769 | 0.789 | 0.787 | 0.811 | 0.798 | 0.791 |
| Baseline-II | 0.826 | 0.803 | 0.827 | 0.854 | 0.810 | 0.822 |
| The proposed | 0.909 | 0.865 | 0.930 | 0.936 | 0.934 | 0.900 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hsu, C.-C.; Zhuang, Y.-X.; Lee, C.-Y. Deep Fake Image Detection Based on Pairwise Learning. Appl. Sci. 2020, 10, 370. https://doi.org/10.3390/app10010370
Hsu C-C, Zhuang Y-X, Lee C-Y. Deep Fake Image Detection Based on Pairwise Learning. Applied Sciences. 2020; 10(1):370. https://doi.org/10.3390/app10010370
Chicago/Turabian StyleHsu, Chih-Chung, Yi-Xiu Zhuang, and Chia-Yen Lee. 2020. "Deep Fake Image Detection Based on Pairwise Learning" Applied Sciences 10, no. 1: 370. https://doi.org/10.3390/app10010370
APA StyleHsu, C. -C., Zhuang, Y. -X., & Lee, C. -Y. (2020). Deep Fake Image Detection Based on Pairwise Learning. Applied Sciences, 10(1), 370. https://doi.org/10.3390/app10010370