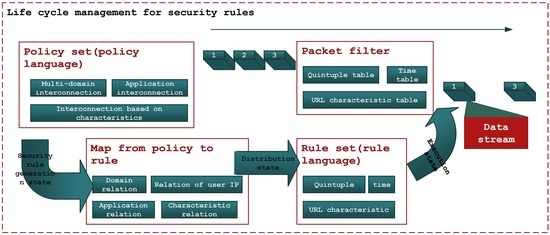
In this section, we will use Backus–Naur Form (BNF) paradigm to give a normalized policy/rule language definition and define a map method from policy language to rule language. As a formal description of policies and rules, subsequent security proofs depend on their structure.
3.3. Map Policies to Rules
As a map, this section transforms the conforming policy language into the corresponding rule language. In combination with the actual situation, IP addresses among users are different, and IP addresses domains are also different. Therefore, we can further conclude that the relation has the following properties:
Definition 1. ,
Definition 2. ,
Definition 3. ,
Definition 4. ,
Definition 5. ,
Definition 6. ,
where
is a projection operation on a relationship. The parameters between them are the terms to be projected. The function
represents a collection of strings that a node of grammar tree matches. The function
is a set of strings represented by a regular expression. Now, we describe the steps of the algorithm by means of the following examples:
From Formulas (
6) and (
16), we can know that
, where
is empty string. We specify that, when the policy is
, the corresponding rule image is
. Using the same policy, we transform
statement from the policy to rule.
Transform a statement into a statement. We divide the into three cases: when the is , the rule action is translated as ; when the policy is the , it is translated as , and, in the last case, it is translated as the default statement of the opposite action.
First, merge every
bar in the whitelist into a tree (white list tree). Traversal from root to leaf: if the two nodes currently being compared are the same, merge them into one node; otherwise, the remaining subtrees are merged under the parent node.
Figure 2 is the algorithm of
in
to merge into white list tree.
Next, merge each
of the blacklist into the white list tree in turn and conflict checking is performed for each merge. The specific process is that, if the exact same subtree appears, the system will prompt for a “detected conflict” message.
Figure 3 and
Figure 4 show an example of a conflict detected.
Next, each scope list is merged into the whitelist tree, as opposed to the default operation, which merges the list (if the default action is accepted, it merges with the blacklist; otherwise, it merges with the whitelist).
Figure 5 shows that the scope list is merged into the whitelist tree.
Through this algorithm, a new tree can be merged into the existing tree, and the original principle can be maintained. The operation to merge the subtree into the original tree is represented by plus sign +.
If the
is
, translate
as follows (all other parts of the signed
are the same). When there is only one configuration, from Formula (
12), we have:
From script (
34), we get the domain set
and the application set
. For example, the domain of
A corresponds to IP interval [10.0.0.1-10.0.0.3 10.0.0.5, 10.0.0.7]. Similarly, the IP interval of the domain
B is [6,8-9]. For the language element
of the security policy script, it can be translated into the source IP interval, and the destination IP interval of the language element in the security rules script respectively. It can be written as [1-3,5,7,10],[6,8-9]. Similarly,
can be translated into [1-3,5,7,10],[10,12].
Ignoring the control characters
and
, we consider the second half of the formula
. We mark these
s as
. By Definition 3, for each
, it can obtain the protocol type, destination port, time, and characteristics via relational operation expression
. The source port is used for its own side to receive messages and is randomly assigned with no restrictions. Covert this relational structure into a tree structure in order. The application element is translated into protocol type interval, source port interval, destination port interval and time interval characteristics in security rules. By searching for application name in scripts, we can get a security rule subtree with an application from the multi-domain network. For example,
uses TCP, UDP and ICMP protocols. Among them, TCP uses port 80 as the destination port, and UDP uses port 90 as the destination port. The usage time of app1 is limited to 5:00 a.m.–11:00 a.m. per day. The algorithm is illustrated by the following
Figure 6:
In steps 3 and 4, multiple tree merges are involved. Our approach is the same merge, different splits. Combining the whitelist tree of step 2, the security policy language is finally translated into the security rules script. In this process, the subtrees of the step 2 are connected, and the corresponding actions are added to the final rule part in combination with the black and white list action of the whitelist tree.
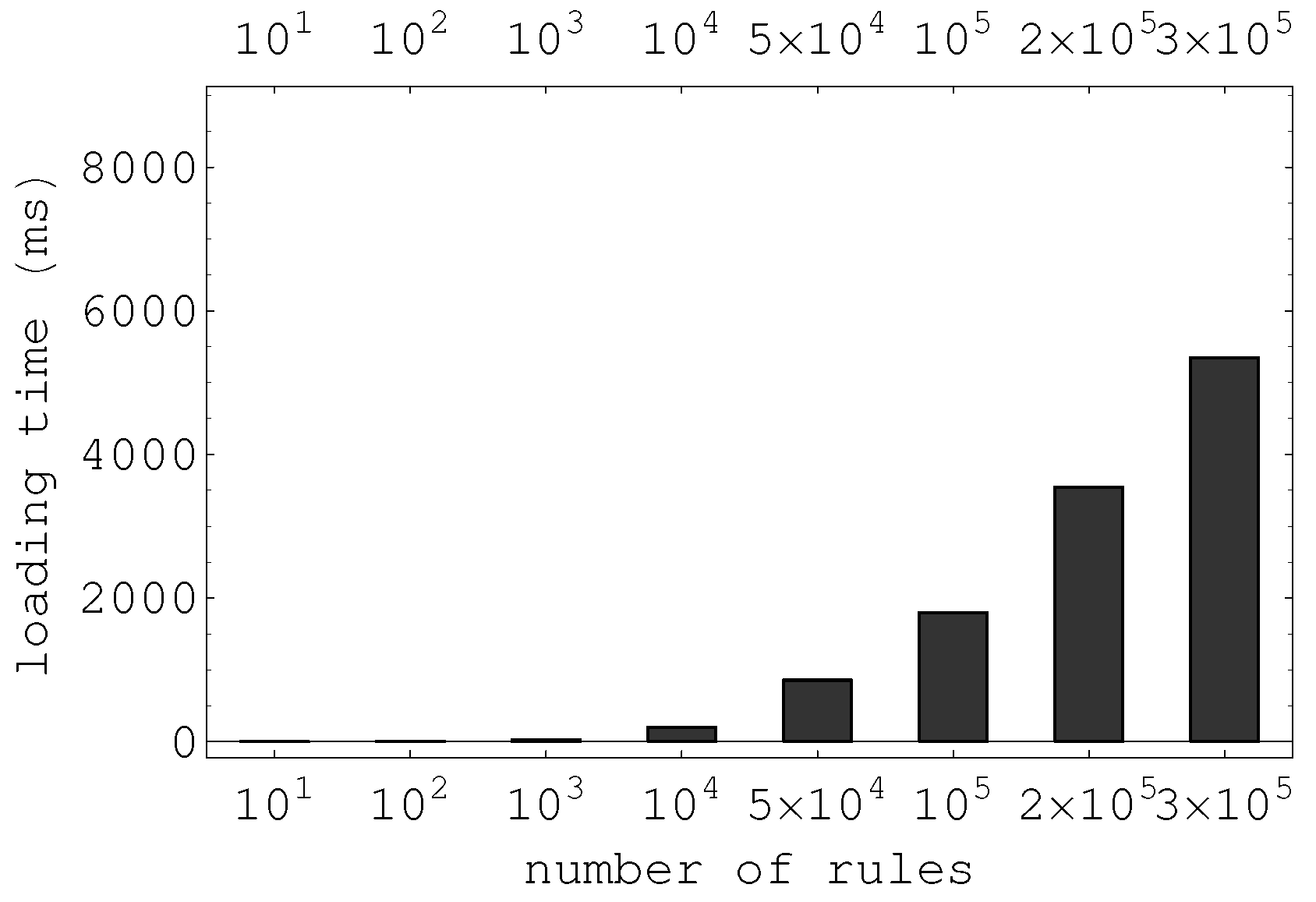
In the implementation, the packet filter module will call the mutual exclusion of the two operations through the synchronization variable
when loading the forest rules or filtering the packet. Algorithm 1 is described precisely as follows:
| Algorithm 1: Fine-grained packet filter |
![Applsci 10 00409 i001]() |
We define a type named
whose type can be seen in Formula (
35):
where
is the parent of this level, and
is its children.
is the data of the node.
There are four levels of the forest which has been built. They are the source of the domain, the destination of the domain, the application, and the action of the forest policy, respectively. Corresponding to
, we also define
. There are eight levels that are the source of IP, the destination of IP, the source of the port, the destination of the port, the protocol type, the time, the characteristic, and the action. See Formula (
36):
The policies can be mapped to the rules by Algorithm 3. The initialization of it also needs to be finished by Algorithm 2. It merges each policy tree in the policy file into the forest policy. In the process, the algorithm simultaneously merges the policies and detects conflicts.
| Algorithm 2: Merge trees into forest |
![Applsci 10 00409 i002]() |
Each policy p in the list is regarded as a tree, so policies f can be considered as a forest. Both forest and trees are three-layer structures. The layers represent source domain, destination domain, and app, respectively. As for app nodes, they all contain an action field (//). The function of Algorithm 2 is to merge trees into a forest.
Algorithm 2 is described precisely as follows:
Travel through every tree in the forest and try to merge policy p into the tree. If it fails to merge policy p into any tree in the forest, just add policy p into . The method of merging trees is as follows. First, compare the root node of policy p with that of the i-th tree in the forest, which are denoted as t and , respectively. If they are different, policy p cannot be merged into the i-th tree. Try to merge it into another tree. If they are the same, compare their child nodes which are denoted as and .
If a child node of denoted as is the same as , compare their child nodes which are denoted as and , or add to .
For each , if there is no like it, add it to . If there is an denoted as which is the same as , compare their actions. If one is and the other is or , then = or . If they are different and neither is , throw “conflict detection!”.
Algorithm 3 is described precisely as follows:
In Algorithm 3, it maps forest policies
f,
p into forest rules
r,
t. For each tree in the forest
f,
p, use the following method to turn it into a rule tree. As mentioned above, the trees of policy forest are three-layer structure, representing source domain, destination domain and app, respectively. Thus, given the root of the
i-th tree, we can get the source domain, and further obtain the source IP address
by searching the set of relationships
. The destination IP address
can be obtained similarly. Then, add it to
. From the app, we can get the information of protocol, source port, destination port, time, reg and action. Add them to the
of their previous element respectively and make
the leaf node of the rule tree. Leaf nodes of rule trees contain an action field which is the same as the app node of the original policy tree.
| Algorithm 3: Map policies to rules |
![Applsci 10 00409 i003]() |
Time coding is divided into absolute time and relative time. Time elements such as year, month, day, week, hour, minute and second are used to encode relative time. Absolute time is encoded in seconds that have elapsed since 1 January 1970. The relative time of the base structure from low to high is 60, 60, 24, 7, 31, and 12. Of these, number 7 means that the week is unlimited. Number 31 means days are unlimited. Number 12 means month is unlimited. For the time format “
”,
where the week
w can be calculated using the library function provided by “time.h”. For example, from 9:00 a.m. to 10:00 a.m. every day, the code of relative time is Formulas (
38) and (
39):
If it’s 0:00 a.m. to 0:00 a.m. per day, this means that there’s no limit about time. For “”, we first reverse calculate , obtain the current absolute time via “”, then assign the rest to the absolute time structure, and finally calculate the absolute time value through the library function “”.
Algorithm 4 is described precisely as follows.
In Algorithm 4, given the relative time interval which begins with and ends with , the corresponding absolute time interval can be obtained. Time stamp is an integer and can be converted into relative time or absolute time through function “” or “”. Using function “” for and , we can get six pairs of numbers representing the restrictions on month, date, day of week, hour, minute, and second. Placing restrictions on month means the period from one month to one month every year and no restriction implies January to December. Similarly, for date, day of week, hour, minute, and second, whether to make restrictions or not is optional.
| Algorithm 4: Convert relative time into absolute Time |
![Applsci 10 00409 i004]() |
Using function intToAb() for update, the time stamp of current time, we can get the current month, date, day of week, hour, minute, and second. If current time meets the limits to month, date, and day of week, there are two cases to consider. One case is that there are no limits to hour, minute, and second, and the other is that hour, minute, and second are limited. For the former, the absolute time interval converted is from 0:0:0 a.m. that day to 0:0:0 a.m. the next day. For the latter, it is the limited time interval that day. If current time does not meet any limit to month, date or day of week, the absolute time interval converted is from 1 January 1970, 0:0:0 a.m. to 1 January 1970, 0:0:0 a.m..
Algorithm 5 is described precisely as follows:
Since absolute time interval are converted from relative time interval according to current time, the absolute time interval converted should change as current time changes. Thus, it is necessary to invoke Algorithm 5 to update absolute time interval to ensure accuracy. The update input is the time stamp of the last time calling Algorithm 4. If the time stamp of packet is bigger than , invoke Algorithm 4 and update ensuring that the next update will be completed before the time constrained.
| Algorithm 5: Update time interval |
![Applsci 10 00409 i005]() |


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}