Comparison of Instance Selection and Construction Methods with Various Classifiers



Abstract
:1. Introduction
- using specially tailored algorithms which are designed to face those challenge
- limiting the size of the training data
- exporting the training process from the device to the cloud or other high performance environment
2. Research Background
2.1. Problem Statement
2.2. Instance Selection and Construction Methods Overview
- search direction
- −
- −
- −
- −
- type of selection
- −
- condensation, when the algorithm tries to remove samples, which are located far from the decision boundary, as in the case of IB2, CNN, Drop1 and Drop2, MSS.
- −
- edition, when the algorithm is designed for noise removal, such as ENN, RENN, All-kNN, HMN-E.
- −
- hybrid, when the algorithm performs both steps—condensation and edition. Usually these methods starts from noise removal, and then perform condensation. This group includes: Drop3, Drop5, ICF, HMN-EI.
- the evaluation method
- −
- filters, where the method uses internal heuristic independent to the final classifier.
- −
- wrappers, when external dedicated classifier is used to identify important samples.
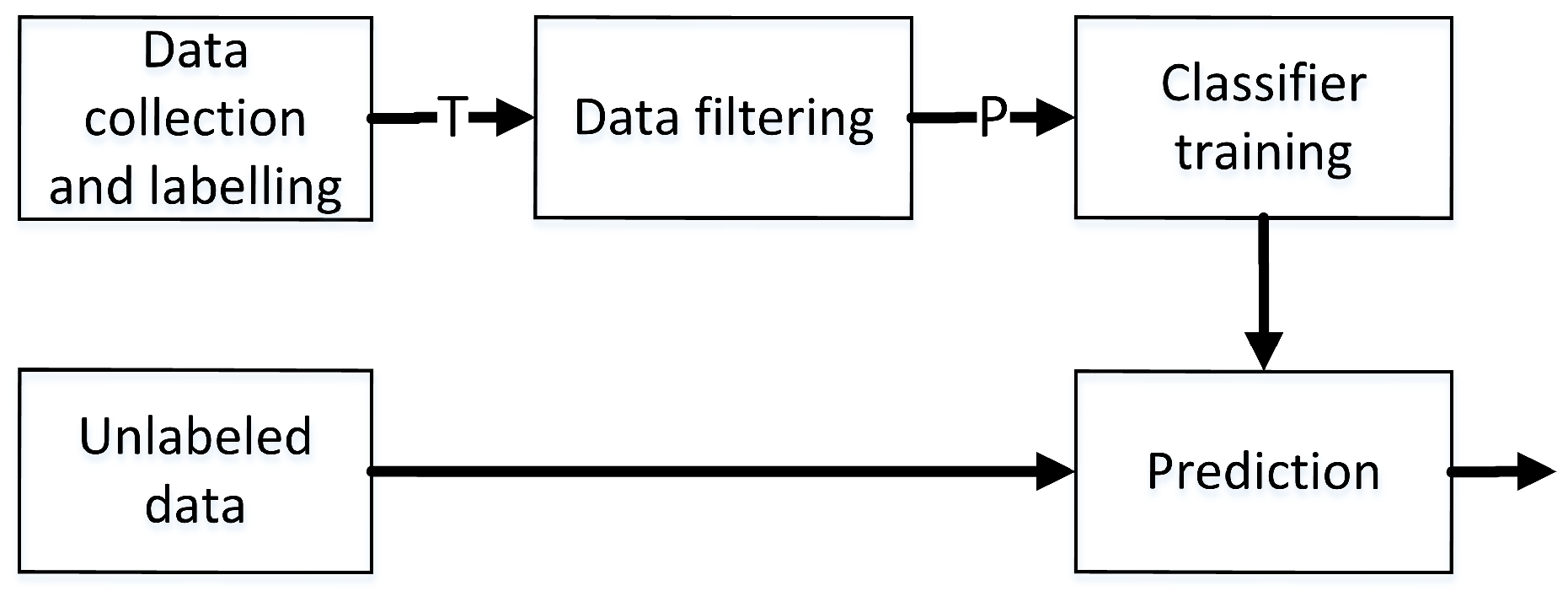
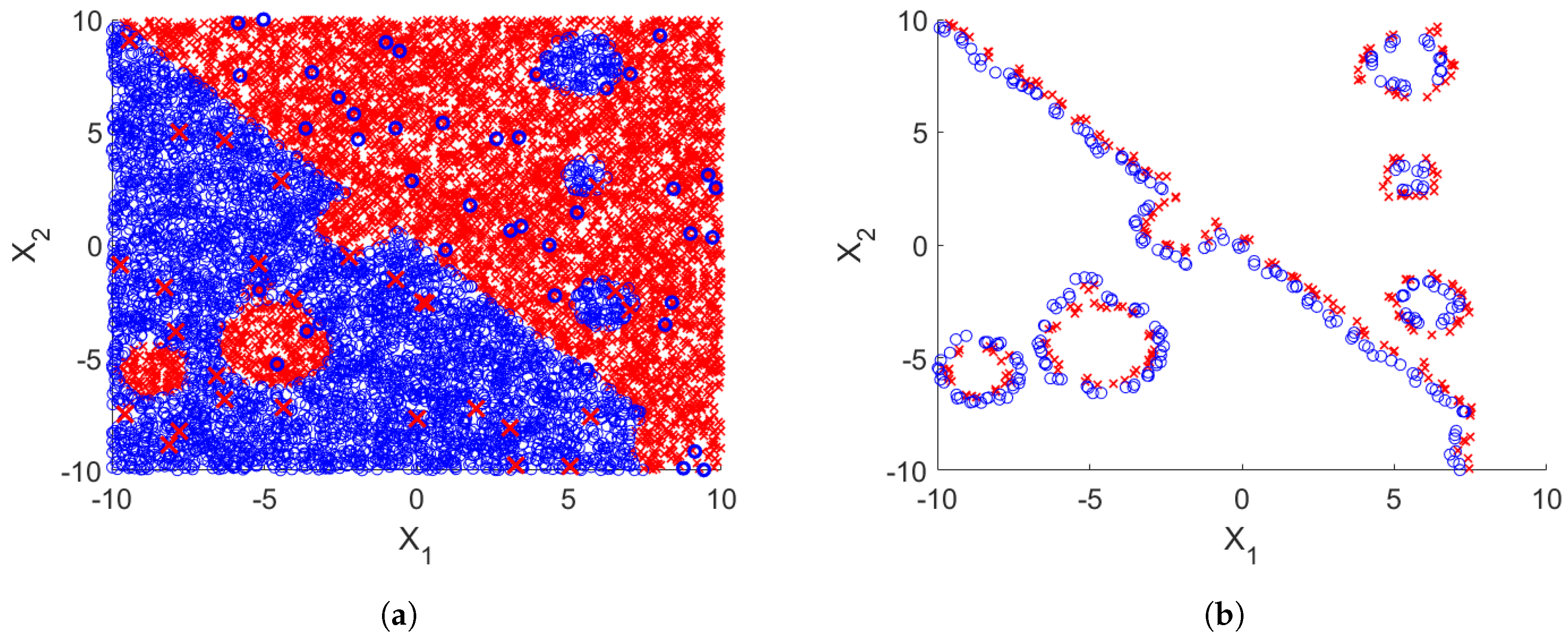
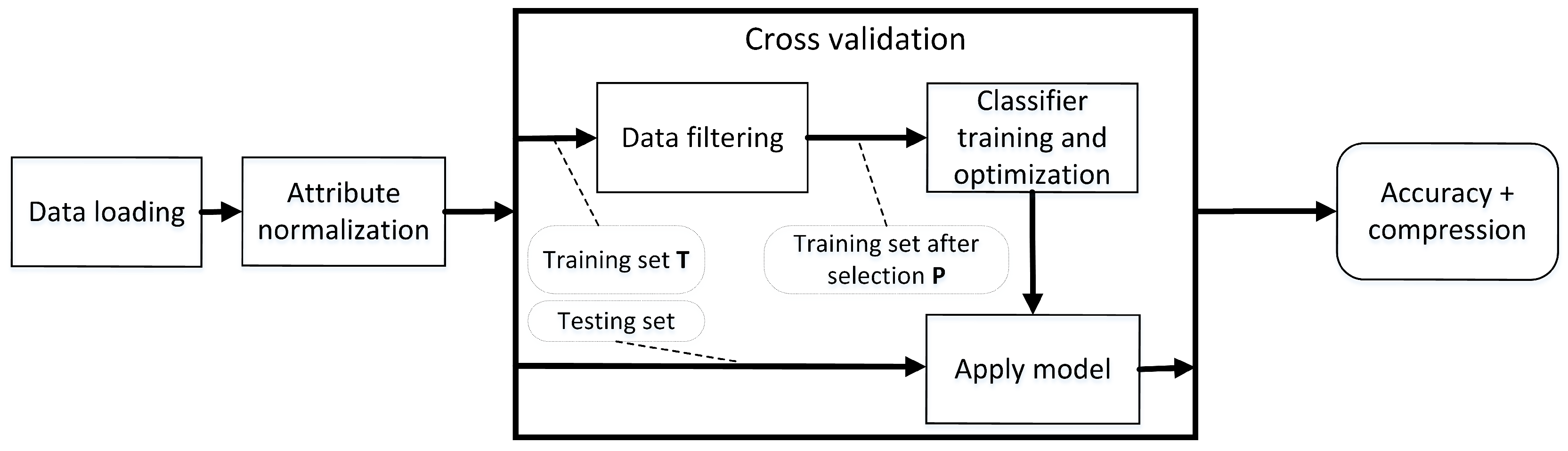
3. Experimental Design
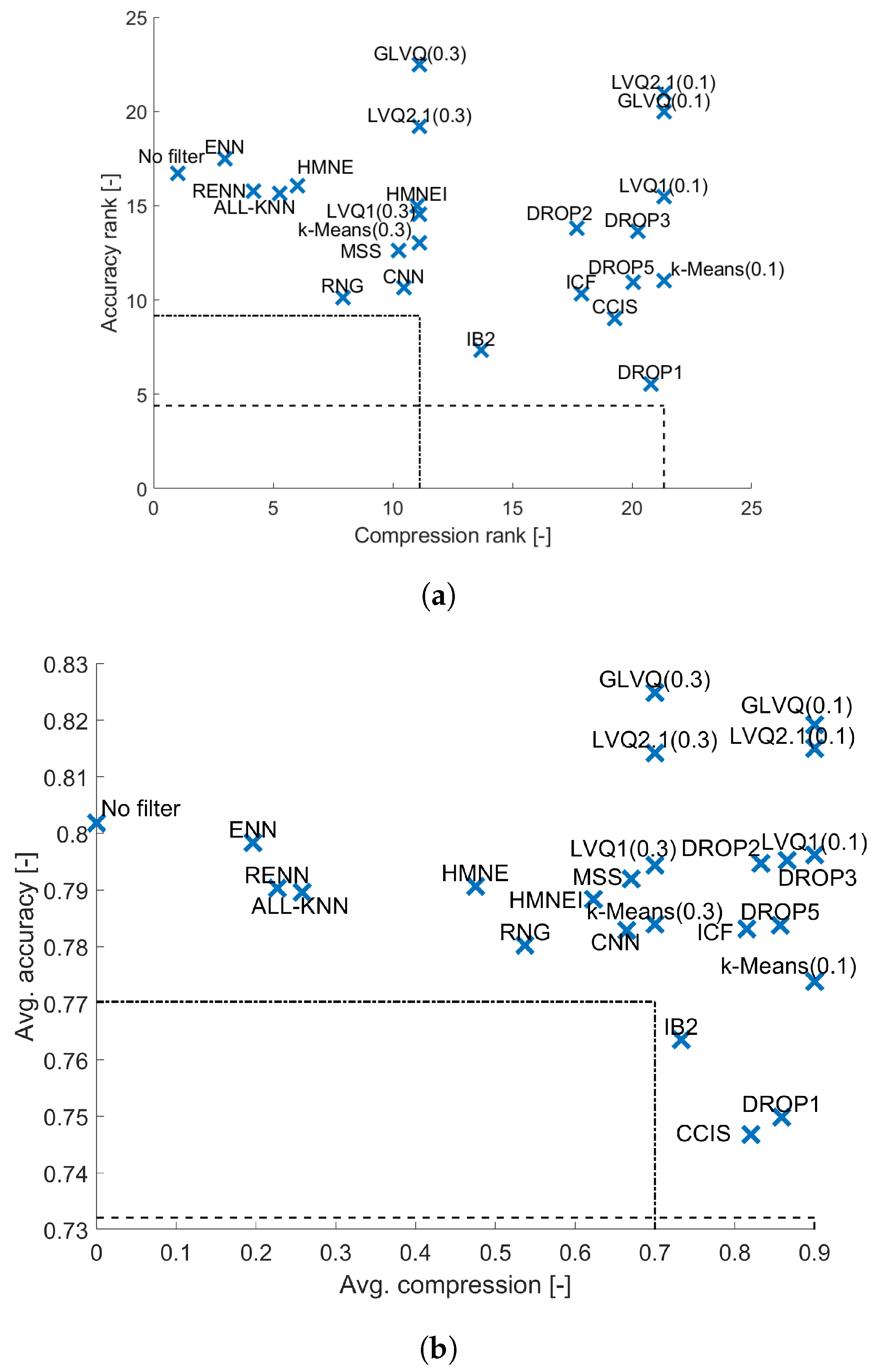
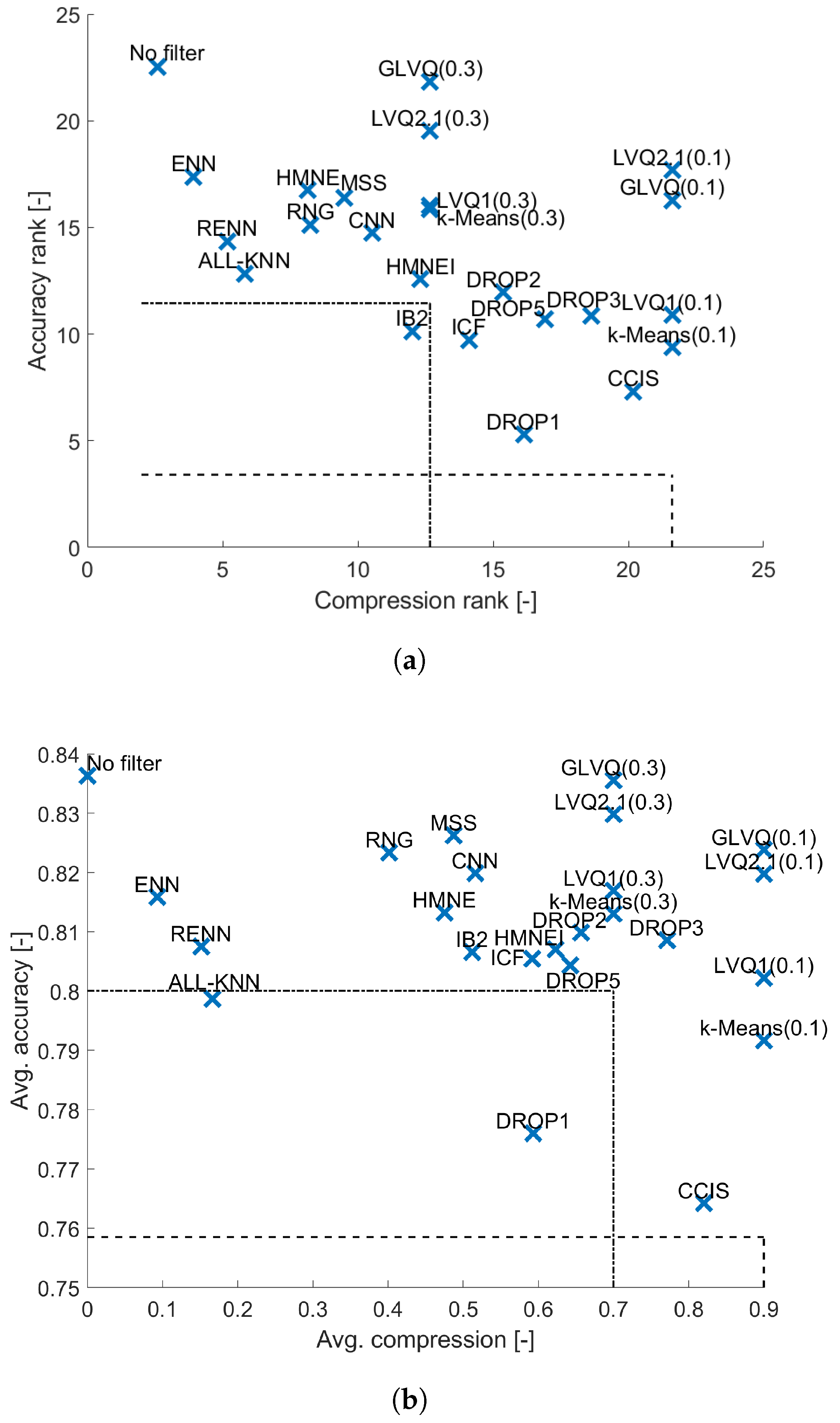
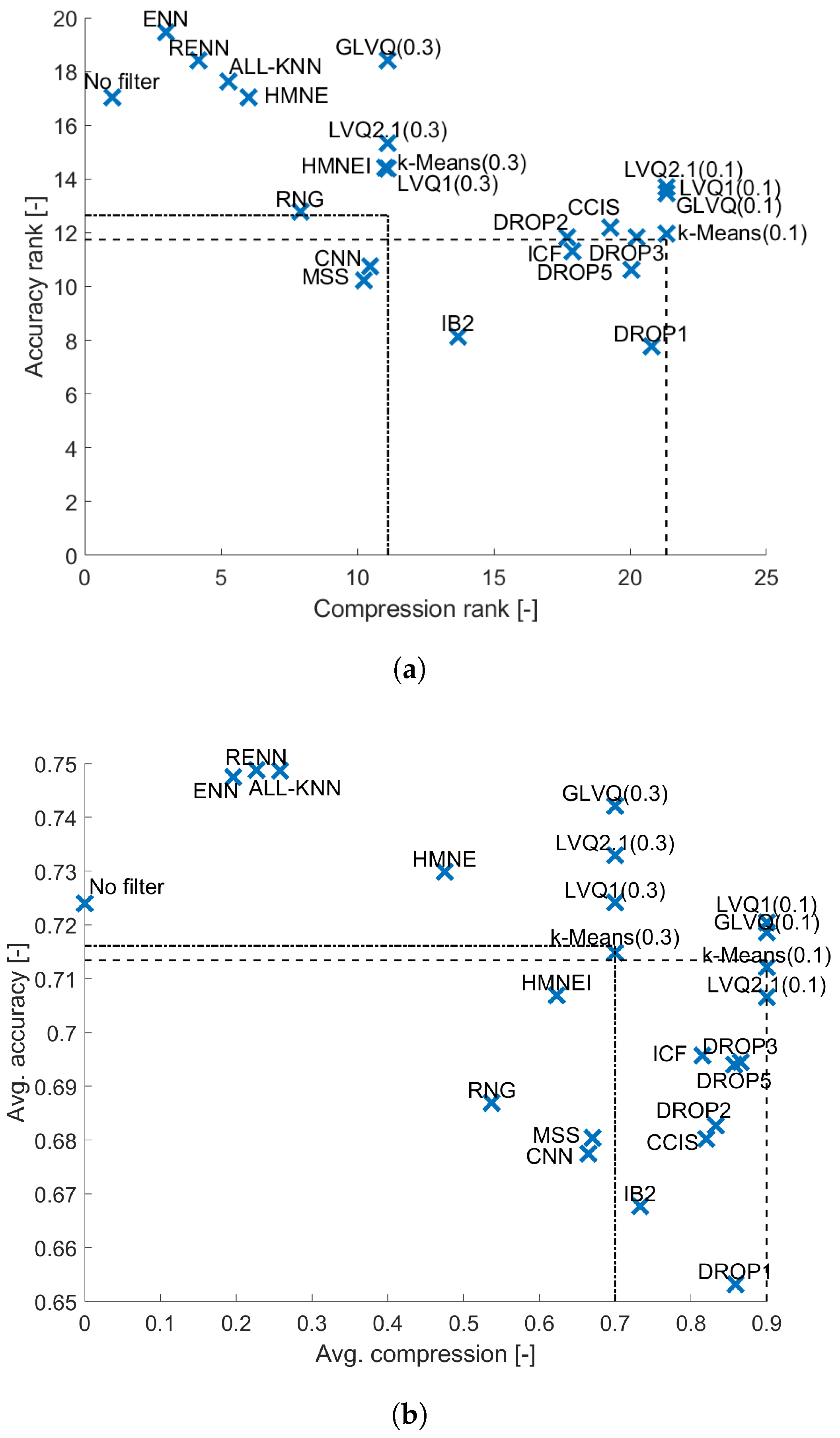
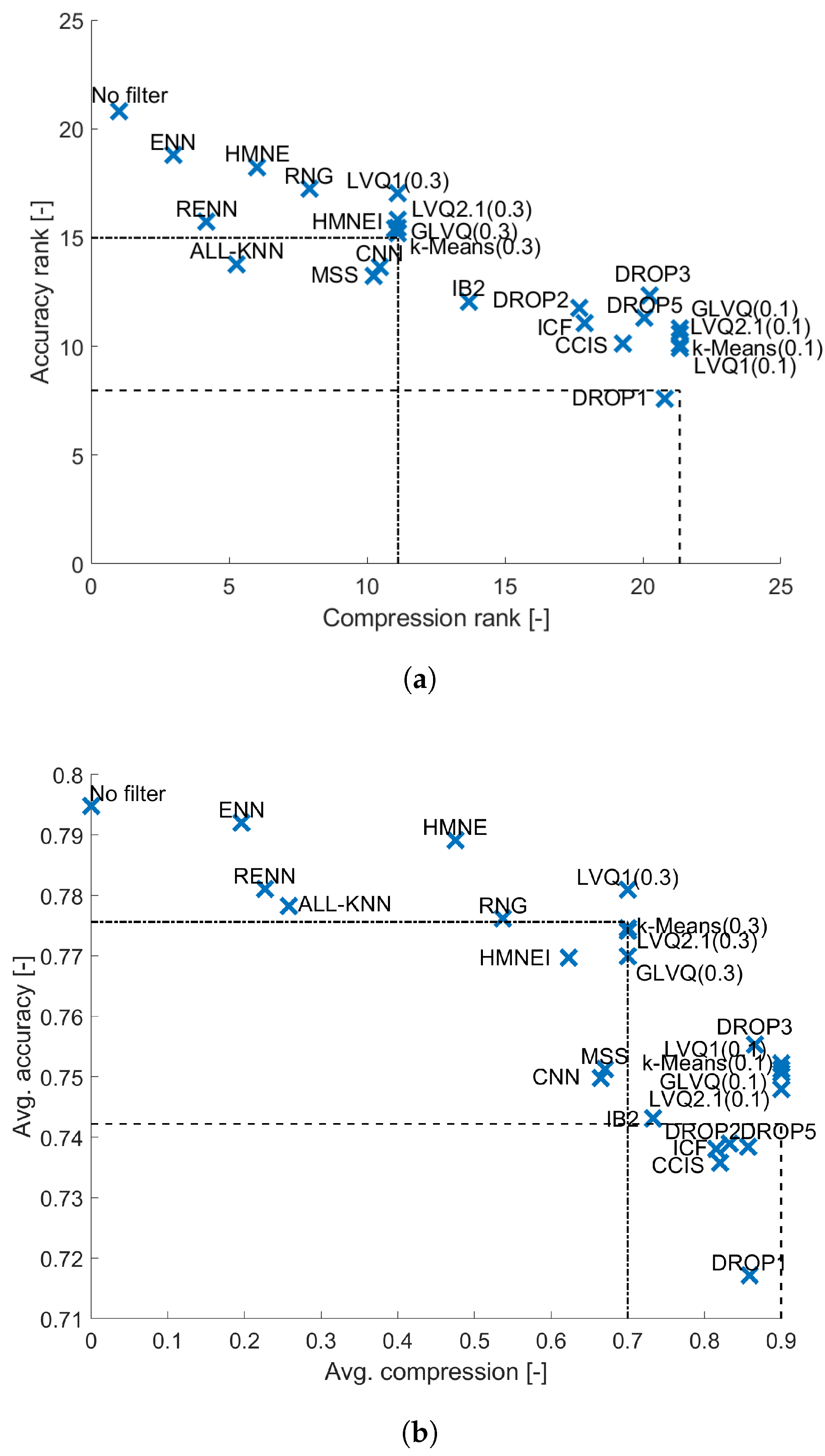
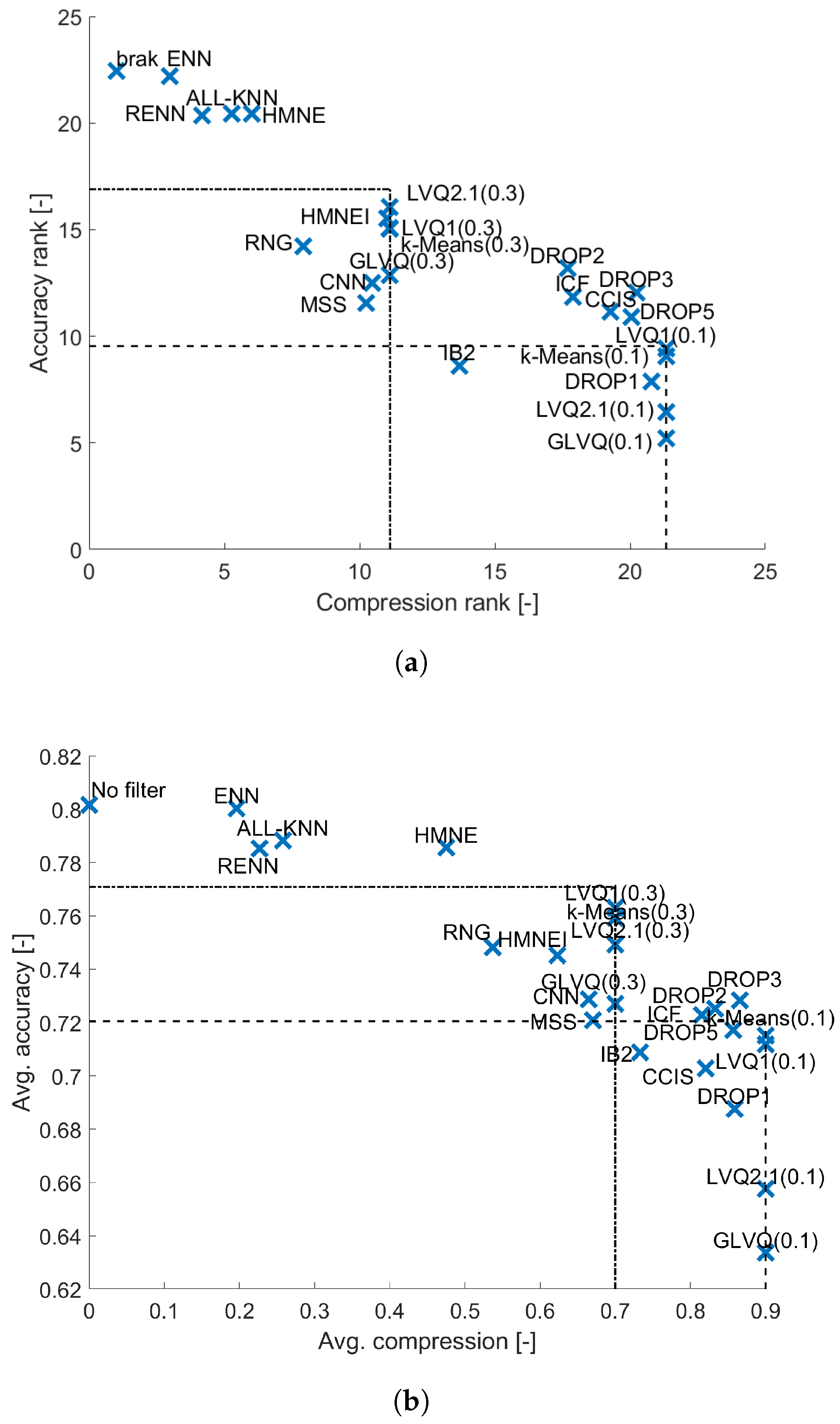
4. Results and Analysis
4.1. 1-NN
4.2. kNN
4.3. Naive Bayes
4.4. GLM
4.5. C4.5 Decision Tree
4.6. Random Forest
4.7. SVM
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| SVM | Support Vector Machine |
| Random Forest | Random Forest |
| kNN | k-Nearest Neighbor |
| 1-NN | 1-Nearest Neighbor |
| C4.5 | C4.5 decision tree |
| GLM | Generalized Linear Model |
| Naive Bayes | Naive Bayes |
| MLP | Multi Layer Perceptron |
| Linear Regression | Linear Regression |
| ENN | Edited Nearest Neighbor Rule |
| CNN | Condenced Nearest Neighbor Rule |
| RENN | Repeated ENN |
| ICF | Iterative Case Filtering |
| IB3 | Instance Based Learining version 3 |
| IB2 | Instance Based Learining version 2 |
| GGE | Gabriel Graph Editing |
| RNGE | Relative Neighbor Graph Editing |
| MSS | Modified Selective Subset Selection |
| LVQ | Learning Vector Quantization |
| LVQ1 | Learning Vector Quantization version 1 |
| LVQ2 | Learning Vector Quantization version 2 |
| LVQ2.1 | Learning Vector Quantization version 2.1 |
| LVQ3 | Learning Vector Quantization version 3 |
| OLVQ1 | Optimized Learning Vector Quantization |
| GLVQ | Generalized Learning Vector Quantization |
| SNG | Suppervised Neural Gas |
| CCIS | Class Conditional Instance Selection |
| HMN | Hit Miss Network |
| HMN-C | Hit Miss Network Condensation |
| HMN-E | Hit Miss Network Editing |
| HMN-EI | Hit Miss Network Iterative Editing |
| RNN | Reduced Nearest Neighbor Rule |
References
- Blachnik, M. Reducing Time Complexity of SVM Model by LVQ Data Compression. In Artificial Intelligence and Soft Computing; LNCS 9119; Springer: Berlin, Germany, 2015; pp. 687–695. [Google Scholar]
- Duch, W.; Grudziński, K. Prototype based rules—New way to understand the data. In Proceedings of the IEEE International Joint Conference on Neural Networks, Washington, DC, USA, 15 July 2001; pp. 1858–1863. [Google Scholar]
- Blachnik, M.; Duch, W. LVQ algorithm with instance weighting for generation of prototype-based rules. Neural Networks 2011, 24, 824–830. [Google Scholar] [CrossRef]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [Green Version]
- García, S.; Luengo, J.; Herrera, F. Tutorial on practical tips of the most influential data preprocessing algorithms in data mining. Knowl. Based Syst. 2016, 98, 1–29. [Google Scholar] [CrossRef]
- Blachnik, M.; Kordos, M.; Wieczorek, T.; Golak, S. Selecting Representative Prototypes for Prediction the Oxygen Activity in Electric Arc Furnace. LNCS 2012, 7268, 539–547. [Google Scholar]
- Kordos, M.; Blachnik, M.; Białka, S. Instance Selection in Logical Rule Extraction for Regression Problems. LNAI 2013, 7895, 167–175. [Google Scholar]
- Abdulali, A.; Hassan, W.; Jeon, S. Stimuli-magnitude-adaptive sample selection for data-driven haptic modeling. Entropy 2016, 18, 222. [Google Scholar] [CrossRef] [Green Version]
- Blachnik, M. Instance Selection for Classifier Performance Estimation in Meta Learning. Entropy 2017, 19, 583. [Google Scholar] [CrossRef] [Green Version]
- Grochowski, M.; Jankowski, N. Comparison of Instance Selection Algorithms. II. Results and Comments. LNCS 2004, 3070, 580–585. [Google Scholar]
- Borovicka, T.; Jirina, M., Jr.; Kordik, P.; Jirina, M. Selecting representative data sets. In Advances in Data Mining Knowledge Discovery and Applications; IntechOpen: London, UK, 2012. [Google Scholar]
- Blachnik, M.; Duch, W. Prototype-based threshold rules. Lect. Notes Comput. Sci. 2006, 4234, 1028–1037. [Google Scholar]
- García, S.; Derrac, J.; Cano, J.R.; Herrera, F. Prototype selection for nearest neighbor classification: Taxonomy and empirical study. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 417–435. [Google Scholar] [CrossRef]
- Triguero, I.; Derrac, J.; Garcia, S.; Herrera, F. A taxonomy and experimental study on prototype generation for nearest neighbor classification. IEEE Trans. Syst. Man, Cybern. 2012, 42, 86–100. [Google Scholar] [CrossRef]
- Hart, P. The condensed nearest neighbor rule. IEEE Trans. Inf. Theory 1968, 16, 515–516. [Google Scholar] [CrossRef]
- Aha, D.; Kibler, D.; Albert, M. Instance-Based Learning Algorithms. Mach. Learn. 1991, 6, 37–66. [Google Scholar] [CrossRef] [Green Version]
- Marchiori, E. Hit miss networks with applications to instance selection. J. Mach. Learn. Res. 2008, 9, 997–1017. [Google Scholar]
- Barandela, R.; Ferri, F.J.; Sánchez, J.S. Decision boundary preserving prototype selection for nearest neighbor classification. Int. J. Pattern Recognit. Artif. Intell. 2005, 19, 787–806. [Google Scholar] [CrossRef] [Green Version]
- Wilson, D.; Martinez, T. Reduction techniques for instance-based learning algorithms. Mach. Learn. 2000, 38, 257–268. [Google Scholar] [CrossRef]
- Tomek, I. An experiment with the edited nearest-neighbor rule. IEEE Trans. Syst. Man Cybern. 1976, 6, 448–452. [Google Scholar]
- Wilson, D. Assymptotic properties of nearest neighbour rules using edited data. IEEE Trans. Syst. Man Cybern. 1972, SMC-2, 408–421. [Google Scholar] [CrossRef] [Green Version]
- Sánchez, J.S.; Pla, F.; Ferri, F.J. Prototype selection for the nearest neighbour rule through proximity graphs. Pattern Recognit. Lett. 1997, 18, 507–513. [Google Scholar] [CrossRef]
- Brighton, H.; Mellish, C. Advances in instance selection for instance-based learning algorithms. Data Min. Knowl. Discov. 2002, 6, 153–172. [Google Scholar] [CrossRef]
- Marchiori, E. Class conditional nearest neighbor for large margin instance selection. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 364–370. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nova, D.; Estévez, P.A. A review of learning vector quantization classifiers. Neural Comput. Appl. 2014, 25, 511–524. [Google Scholar] [CrossRef] [Green Version]
- Blachnik, M.; Kordos, M. Simplifying SVM with Weighted LVQ Algorithm. LNCS 2011, 6936, 212–219. [Google Scholar]
- Kordos, M.; Blachnik, M. Instance Selection with Neural Networks for Regression Problems. LNCS 2012, 7553, 263–270. [Google Scholar]
- Arnaiz-González, Á.; Díez-Pastor, J.F.; Rodríguez, J.J.; García-Osorio, C. Instance selection of linear complexity for big data. Knowl.-Based Syst. 2016, 107, 83–95. [Google Scholar] [CrossRef] [Green Version]
- De Haro-García, A.; Cerruela-García, G.; García-Pedrajas, N. Instance selection based on boosting for instance-based learners. Pattern Recognit. 2019, 96, 106959. [Google Scholar] [CrossRef]
- Arnaiz-González, Á.; González-Rogel, A.; Díez-Pastor, J.F.; López-Nozal, C. MR-DIS: Democratic instance selection for big data by MapReduce. Prog. Artif. Intell. 2017, 6, 211–219. [Google Scholar] [CrossRef]
- Blachnik, M.; Duch, W.; Wieczorek, T. Selection of prototypes rules – context searching via clustering. LNCS 2006, 4029, 573–582. [Google Scholar]
- Kuncheva, L.; Bezdek, J. Presupervised and postsupervised prototype classifier design. IEEE Trans. Neural Networks 1999, 10, 1142–1152. [Google Scholar] [CrossRef]
- Herrera, F. KEEL, Knowledge Extraction based on Evolutionary Learning. Spanish National Projects TIC2002-04036-C05, TIN2005-08386-C05 and TIN2008-06681-C06. 2005. Available online: http://www.keel.es (accessed on 1 May 2020).
- Blachnik, M.; Kordos, M. Information Selection and Data Compression RapidMiner Library. In Machine Intelligence and Big Data in Industry; Springer: Berlin, Germany, 2016; pp. 135–145. [Google Scholar]
- Alcalá-Fdez, J.; Fernández, A.; Luengo, J.; Derrac, J.; García, S.; Sanchez, L.; Herrera, F. KEEL data-mining software tool: Data set repository, integration of algorithms and experimental analysis framework. J. Mult. Valued Log. Soft Comput. 2011, 17, 255–287. [Google Scholar]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Nalepa, J.; Kawulok, M. Adaptive memetic algorithm enhanced with data geometry analysis to select training data for SVMs. Neurocomputing 2016, 185, 113–132. [Google Scholar] [CrossRef]
- Kawulok, M.; Nalepa, J. Support vector machines training data selection using a genetic algorithm. In Joint IAPR International Workshops on Statistical Techniques in Pattern Recognition (SPR) and Structural and Syntactic Pattern Recognition (SSPR); Springer: Berlin, Germany, 2012; pp. 557–565. [Google Scholar]
- De Mello, A.R.; Stemmer, M.R.; Barbosa, F.G.O. Support vector candidates selection via Delaunay graph and convex-hull for large and high-dimensional datasets. Pattern Recognit. Lett. 2018, 116, 43–49. [Google Scholar] [CrossRef]
- Devi, D.; Purkayastha, B. Redundancy-driven modified Tomek-link based undersampling: A solution to class imbalance. Pattern Recognit. Lett. 2017, 93, 3–12. [Google Scholar] [CrossRef]
- Arnaiz-González, Á.; Díez-Pastor, J.; Rodríguez, J.J.; García-Osorio, C.I. Instance selection for regression by discretization. Expert Syst. Appl. 2016, 54, 340–350. [Google Scholar] [CrossRef]
- Kordos, M.; Arnaiz-González, Á.; García-Osorio, C. Evolutionary prototype selection for multi-output regression. Neurocomputing 2019, 358, 309–320. [Google Scholar] [CrossRef]
- Gunn, I.A.; Arnaiz-González, Á.; Kuncheva, L.I. A Taxonomic Look at Instance-based Stream Classifiers. Neurocomputing 2018, 286, 167–178. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
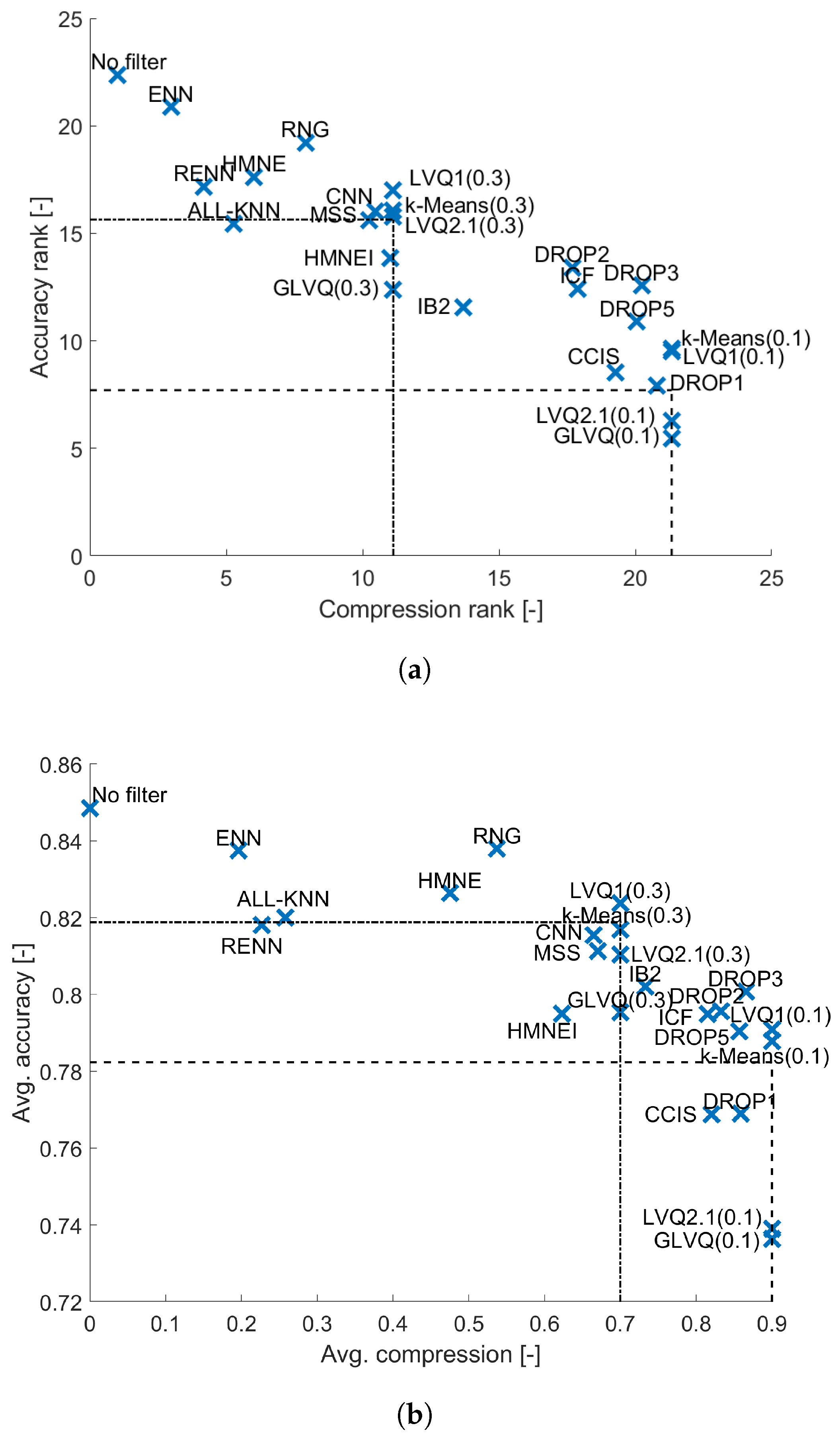{kind=link}
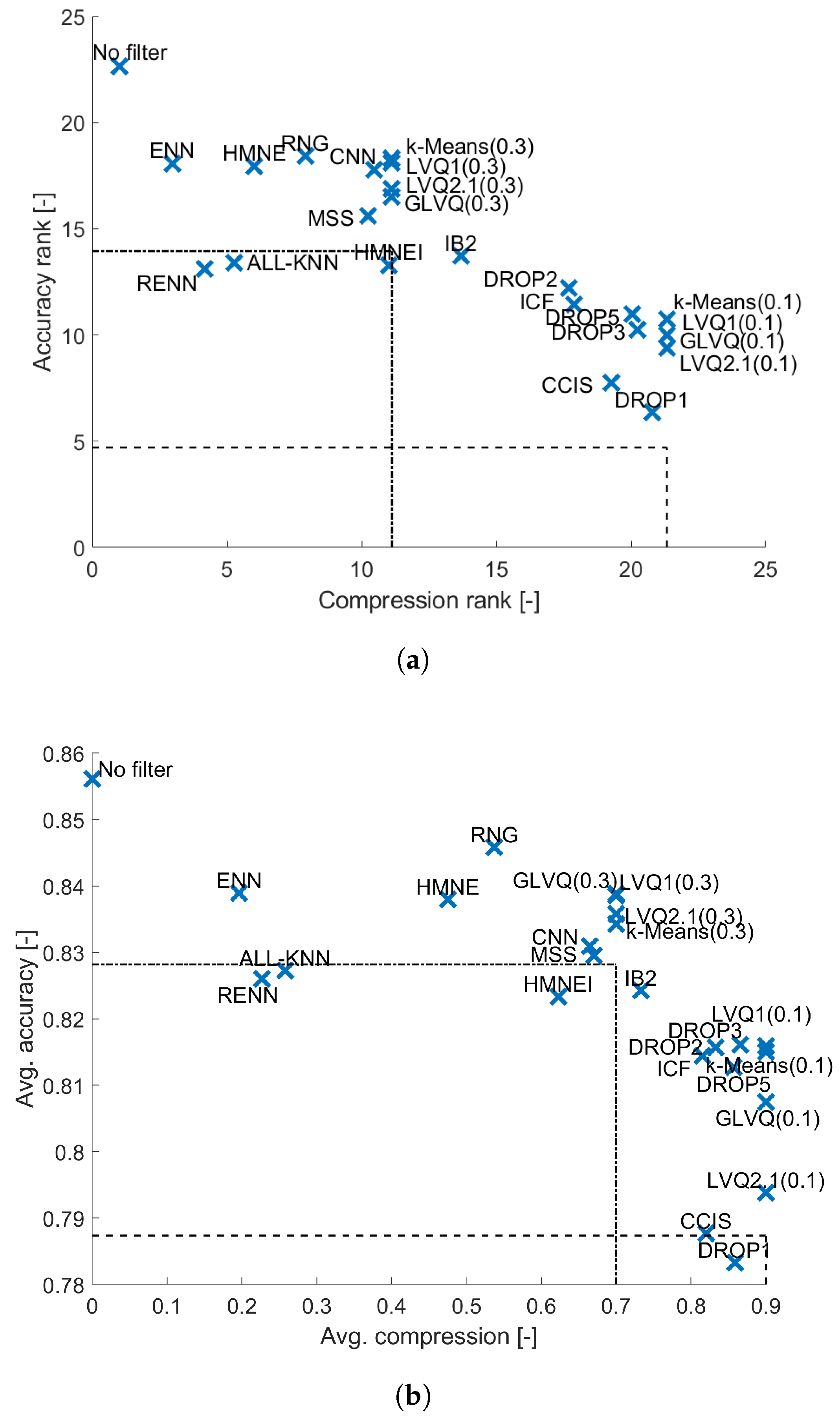{kind=link}
{kind=link}
| Classifier | Parameter | Values | Implementation |
|---|---|---|---|
| 1-NN | - | - | RapidMiner |
| kNN | k | 1:2:40 | RapidMiner |
| Naive Bayes | - | - | RapidMiner |
| GLM | - | - | HO |
| C4.5 | - | - | Weka |
| Random Forest | # trees | Weka | |
| SVM | C | LibSVM | |
| Id. | Name | s / a / c | Id. | Name | s / a / c |
|---|---|---|---|---|---|
| 1 | appendicitis | 106 / 7 / 2 | 21 | page-blocks | 5472 / 10 / 5 |
| 2 | balance | 625 / 4 / 3 | 22 | phoneme | 5404 / 5 / 2 |
| 3 | banana | 5300 / 2 / 2 | 23 | pima | 768 / 8 / 2 |
| 4 | bands | 365 / 19 / 2 | 24 | ring | 7400 / 20 / 2 |
| 5 | bupa | 345 / 6 / 2 | 25 | satimage | 6435 / 36 / 6 |
| 6 | cleveland | 297 / 13 / 5 | 26 | segment | 2310 / 19 / 7 |
| 7 | glass | 214 / 9 / 6 | 27 | sonar | 208 / 60 / 2 |
| 8 | haberman | 306 / 3 / 2 | 28 | spambase | 4597 / 57 / 2 |
| 9 | hayes-roth | 160 / 4 / 3 | 29 | spectfheart | 267 / 44 / 2 |
| 10 | heart | 270 / 13 / 2 | 30 | tae | 151 / 5 / 3 |
| 11 | hepatitis | 80 / 19 / 2 | 31 | texture | 5500 / 40 / 11 |
| 12 | ionosphere | 351 / 33 / 2 | 32 | thyroid | 7200 / 21 / 3 |
| 13 | iris | 150 / 4 / 3 | 33 | titanic | 2201 / 3 / 2 |
| 14 | led7digit | 500 / 7 / 10 | 34 | twonorm | 7400 / 20 / 2 |
| 15 | mammographic | 830 / 5 / 2 | 35 | vehicle | 846 / 18 / 4 |
| 16 | marketing | 6876 / 13 / 9 | 36 | vowel | 990 / 13 / 11 |
| 17 | monk-2 | 432 / 6 / 2 | 37 | wdbc | 569 / 30 / 2 |
| 18 | movement_libras | 360 / 90 / 15 | 38 | wine | 178 / 13 / 3 |
| 19 | newthyroid | 215 / 5 / 3 | 39 | wisconsin | 683 / 9 / 2 |
| 20 | optdigits | 5620 / 64 / 10 | 40 | yeast | 1484 / 8 / 10 |
| Random | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Compression | Compression | 1-NN | kNN | Naive Bayes | GLM | C4.5 | Forest | SVM | |||||||||||||
| Method | Rnk | Cmp | Rnk | Acc | Rnk | Acc | Rnk | Acc | Rnk | Acc | Rnk | Acc | Rnk | Acc | Rnk | Acc | |||||
| [-] | [%] | [-] | [%] | [-] | [%] | [-] | [%] | [-] | [%] | [-] | [%] | [-] | [%] | [-] | [%] | ||||||
| ENN | 2.97 | 19.66 | 17.50 | 79.74 | = | 17.37 | 81.44 | 19.46 | 74.43 | + | 18.79 | 78.72 | 22.18 | 79.61 | = | 20.87 | 83.46 | 18.08 | 83.70 | ||
| RENN | 4.18 | 22.74 | 15.76 | 78.75 | = | 14.36 | 80.43 | 18.41 | 74.51 | + | 15.73 | 77.57 | 20.37 | 78.05 | 17.18 | 81.46 | 13.13 | 82.24 | |||
| ALL-KNN | 5.28 | 26.02 | 15.64 | 78.66 | = | 12.85 | 79.55 | 17.62 | 74.46 | = | 13.78 | 77.29 | 20.45 | 78.17 | = | 15.45 | 81.59 | 13.41 | 82.28 | ||
| HMNE | 6.03 | 46.45 | 16.05 | 79.22 | = | 16.74 | 81.42 | 17.04 | 72.71 | = | 18.24 | 78.52 | 20.42 | 78.22 | 17.63 | 82.67 | 17.96 | 83.90 | |||
| RNG | 7.91 | 53.25 | 10.14 | 78.18 | 15.13 | 82.38 | 12.78 | 68.46 | 17.23 | 77.09 | 14.23 | 74.34 | 19.22 | 83.72 | 18.42 | 84.53 | |||||
| HMNEI | 11.00 | 60.86 | 15.01 | 79.00 | = | 12.58 | 80.82 | 14.42 | 70.48 | = | 15.41 | 76.61 | 15.53 | 74.30 | 13.86 | 79.57 | 13.28 | 82.47 | |||
| CNN | 10.46 | 66.38 | 10.65 | 78.42 | 14.74 | 82.03 | 10.74 | 67.53 | 13.65 | 74.28 | 12.51 | 72.13 | 16.03 | 81.28 | 17.77 | 82.96 | |||||
| MSS | 10.23 | 66.88 | 12.63 | 79.35 | 16.40 | 82.70 | 10.24 | 67.68 | 13.24 | 74.37 | 11.58 | 71.45 | 15.63 | 80.87 | 15.60 | 82.75 | |||||
| IB2 | 13.69 | 73.11 | 7.33 | 76.49 | 10.13 | 80.69 | 8.14 | 66.55 | 12.05 | 73.58 | 8.63 | 70.13 | 11.58 | 79.90 | 13.72 | 82.20 | |||||
| ICF | 17.87 | 80.84 | 10.33 | 78.22 | 9.72 | 80.40 | 11.31 | 69.22 | 11.08 | 73.41 | 11.85 | 71.72 | 12.42 | 79.18 | 11.42 | 81.11 | |||||
| CCIS | 19.28 | 80.91 | 9.03 | 74.78 | 7.31 | 76.48 | 12.18 | 67.85 | 10.12 | 73.25 | 11.14 | 69.96 | 8.55 | 76.81 | 7.77 | 78.74 | |||||
| DROP2 | 17.69 | 82.94 | 13.82 | 79.44 | = | 11.96 | 80.92 | 11.82 | 68.07 | 11.74 | 73.47 | 13.18 | 71.94 | 13.41 | 79.32 | 12.23 | 81.32 | ||||
| DROP5 | 20.06 | 85.28 | 10.94 | 78.37 | 10.68 | 80.38 | 10.62 | 69.14 | 11.29 | 73.42 | 10.90 | 71.07 | 10.90 | 78.84 | 10.99 | 81.12 | |||||
| DROP1 | 20.78 | 85.47 | 5.55 | 74.83 | 5.29 | 77.38 | 7.77 | 64.97 | 7.59 | 71.22 | 7.88 | 68.18 | 7.91 | 76.47 | 6.35 | 77.88 | |||||
| DROP3 | 20.23 | 85.99 | 13.64 | 79.30 | = | 10.87 | 80.60 | 11.85 | 69.15 | 12.35 | 75.10 | = | 12.06 | 72.15 | 12.58 | 79.71 | 10.27 | 81.28 | |||
| GLVQ(0.1) | 21.33 | 90.00 | 19.97 | 81.70 | + | 16.27 | 82.15 | 13.47 | 70.56 | = | 10.82 | 74.51 | 5.21 | 62.46 | 5.47 | 72.96 | 9.41 | 80.58 | |||
| GLVQ(0.3) | 11.13 | 70.00 | 22.47 | 82.49 | + | 21.85 | 83.53 | = | 18.42 | 73.77 | = | 15.45 | 76.60 | 12.87 | 71.93 | 12.38 | 79.22 | 16.50 | 83.68 | ||
| LVQ1(0.1) | 21.33 | 90.00 | 15.47 | 79.19 | = | 10.90 | 79.78 | 13.47 | 70.69 | = | 9.94 | 74.62 | 9.44 | 70.04 | 9.51 | 78.27 | 9.99 | 81.10 | |||
| LVQ1(0.3) | 11.13 | 70.00 | 14.53 | 79.42 | = | 15.85 | 81.62 | 14.38 | 72.01 | 17.03 | 77.60 | 15.09 | 75.54 | 17.00 | 82.04 | 18.09 | 83.68 | ||||
| LVQ2.1(0.1) | 21.33 | 90.00 | 20.96 | 81.33 | + | 17.69 | 81.79 | 13.71 | 69.29 | = | 10.56 | 74.17 | 6.45 | 64.71 | 6.27 | 73.20 | 9.41 | 79.26 | |||
| LVQ2.1(0.3) | 11.13 | 70.00 | 19.21 | 81.45 | + | 19.53 | 82.97 | = | 15.35 | 72.82 | = | 15.82 | 76.95 | 16.06 | 74.13 | 15.77 | 80.72 | 16.90 | 83.40 | ||
| k-Means(0.1) | 21.33 | 90.00 | 11.04 | 77.09 | 9.37 | 78.83 | 11.96 | 69.81 | = | 10.10 | 74.76 | 9.08 | 70.60 | 9.63 | 78.06 | 10.73 | 81.12 | ||||
| k-Means(0.3) | 11.13 | 70.00 | 13.04 | 78.41 | 16.04 | 81.24 | 14.38 | 71.05 | = | 15.19 | 76.97 | 15.04 | 75.15 | 16.05 | 81.21 | 18.29 | 83.24 | ||||
| Rnd(0.1) | 21.33 | 90.00 | 4.40 | 72.49 | 3.41 | 75.07 | 11.74 | 69.94 | 7.97 | 73.50 | 9.54 | 70.95 | 7.71 | 77.25 | 4.71 | 77.89 | |||||
| Rnd(0.3) | 11.13 | 70.00 | 9.17 | 76.77 | 11.45 | 79.67 | 12.65 | 71.14 | 14.99 | 77.11 | 16.90 | 76.30 | 15.64 | 81.43 | 13.95 | 82.31 | |||||
| No filter | 1.01 | 0.00 | 16.72 | 80.33 | 22.53 | 83.70 | 17.05 | 72.16 | 20.82 | 79.00 | 22.42 | 79.86 | 22.36 | 84.79 | 22.63 | 85.65 | |||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Blachnik, M.; Kordos, M. Comparison of Instance Selection and Construction Methods with Various Classifiers. Appl. Sci. 2020, 10, 3933. https://doi.org/10.3390/app10113933
Blachnik M, Kordos M. Comparison of Instance Selection and Construction Methods with Various Classifiers. Applied Sciences. 2020; 10(11):3933. https://doi.org/10.3390/app10113933
Chicago/Turabian StyleBlachnik, Marcin, and Mirosław Kordos. 2020. "Comparison of Instance Selection and Construction Methods with Various Classifiers" Applied Sciences 10, no. 11: 3933. https://doi.org/10.3390/app10113933
APA StyleBlachnik, M., & Kordos, M. (2020). Comparison of Instance Selection and Construction Methods with Various Classifiers. Applied Sciences, 10(11), 3933. https://doi.org/10.3390/app10113933