A Deep Learning-Based Perception Algorithm Using 3D LiDAR for Autonomous Driving: Simultaneous Segmentation and Detection Network (SSADNet)


Abstract
:1. Introduction
2. Simultaneous Segmentation and Detection Network (SSADNet)
2.1. Input Data Preprocessing
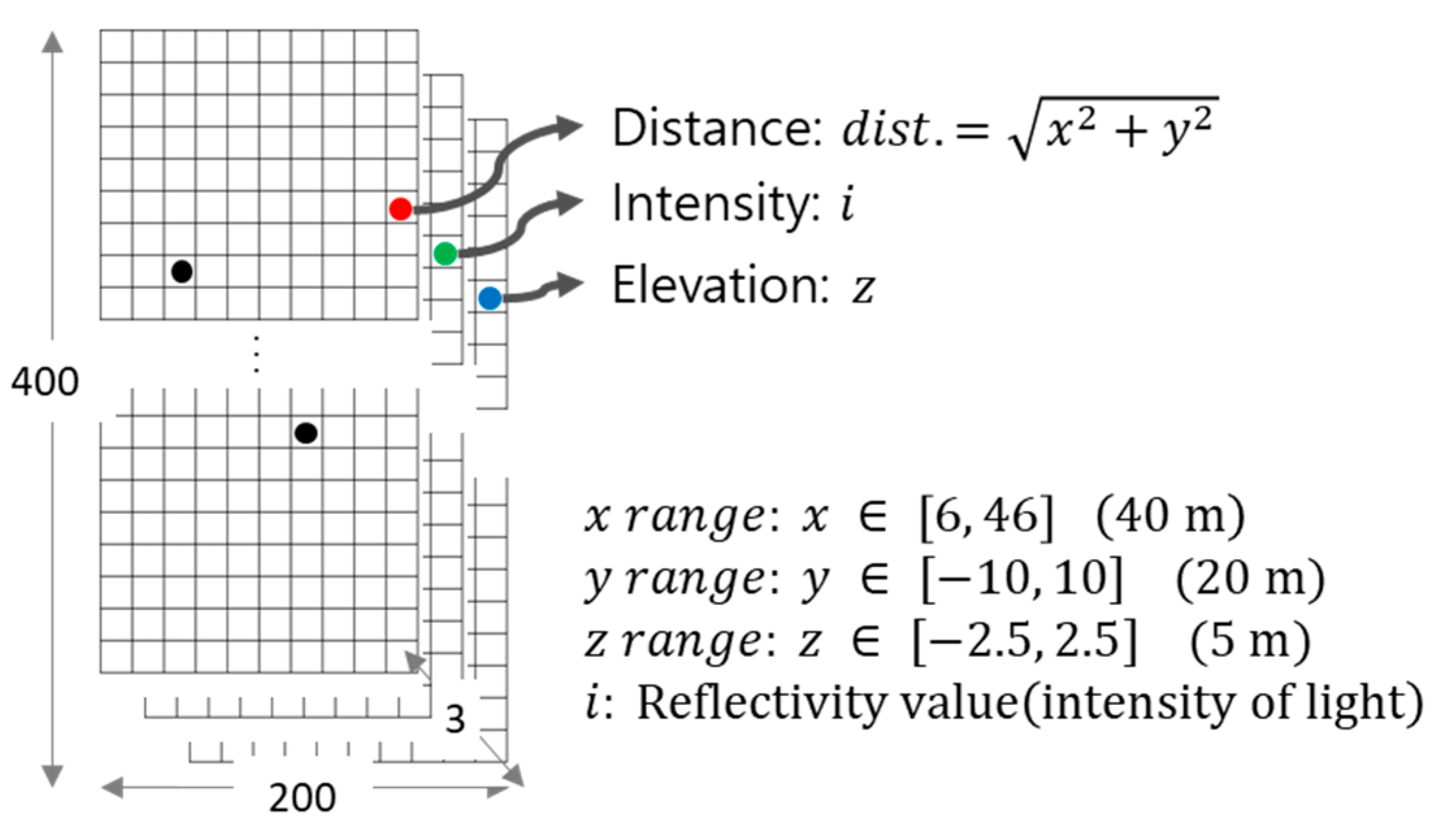
2.1.1. Point Cloud Data Representation
2.1.2. Point Cloud Top View Image
2.2. Simultaneous Segmentation and Detection Network (SSADNet)
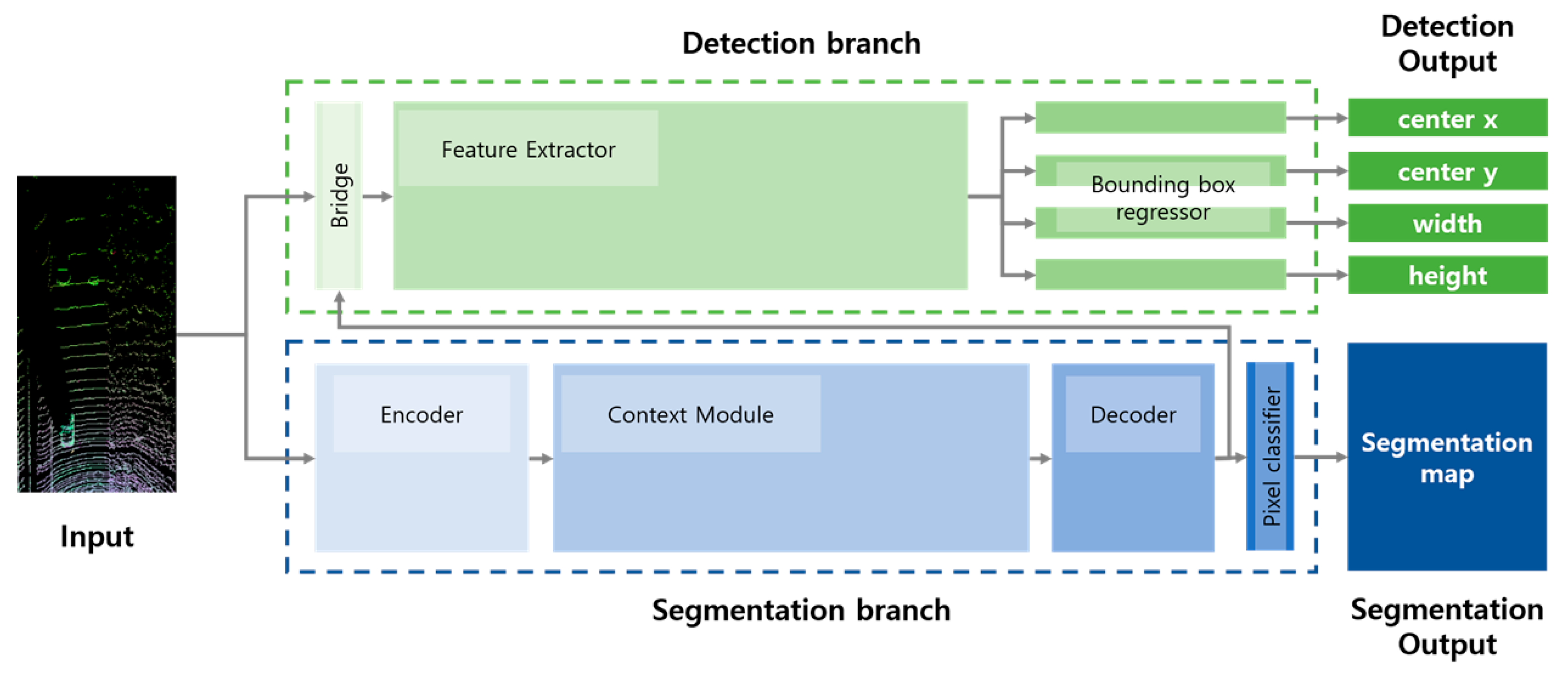
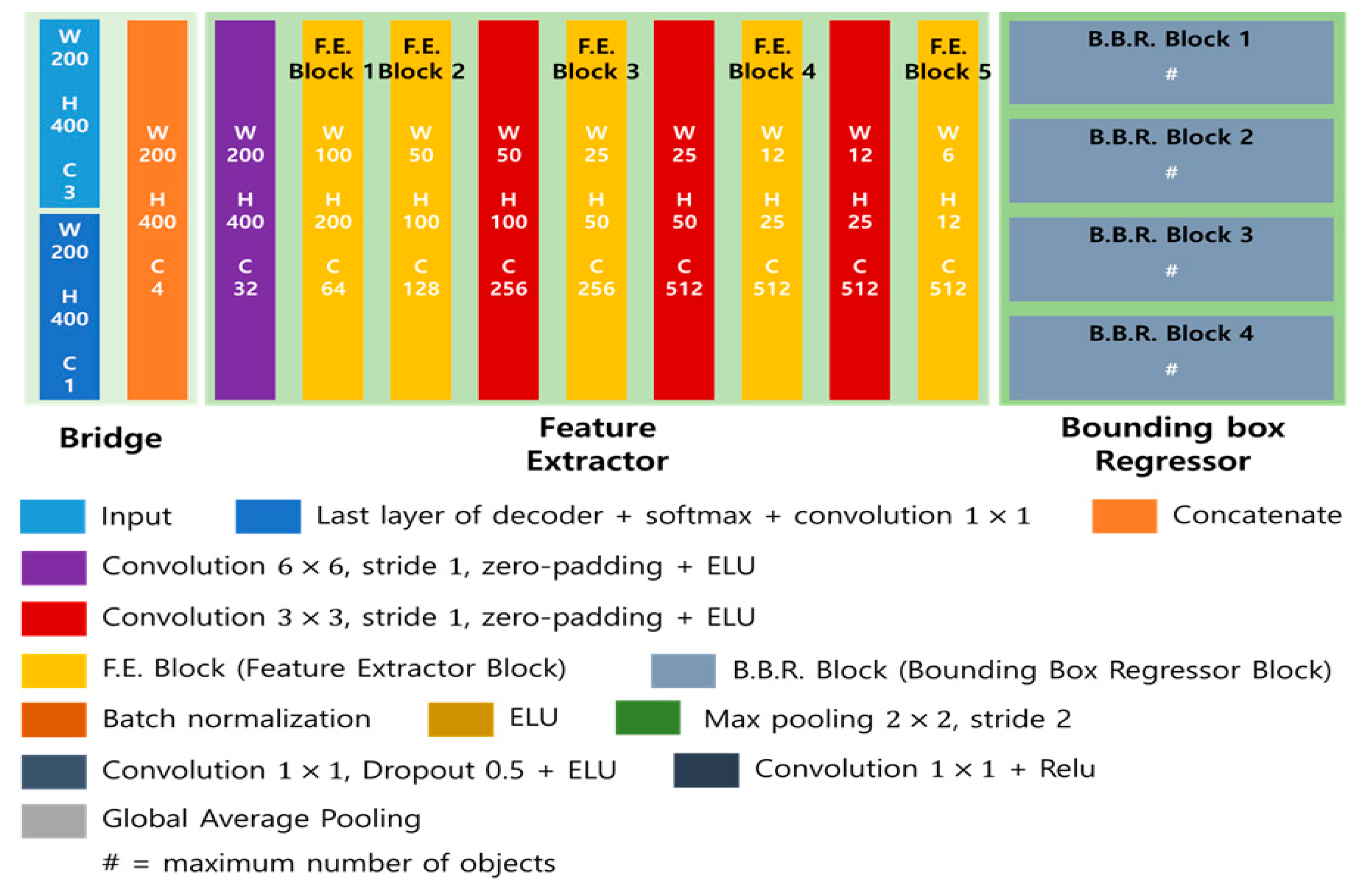
2.2.1. Architecture of SSADNet
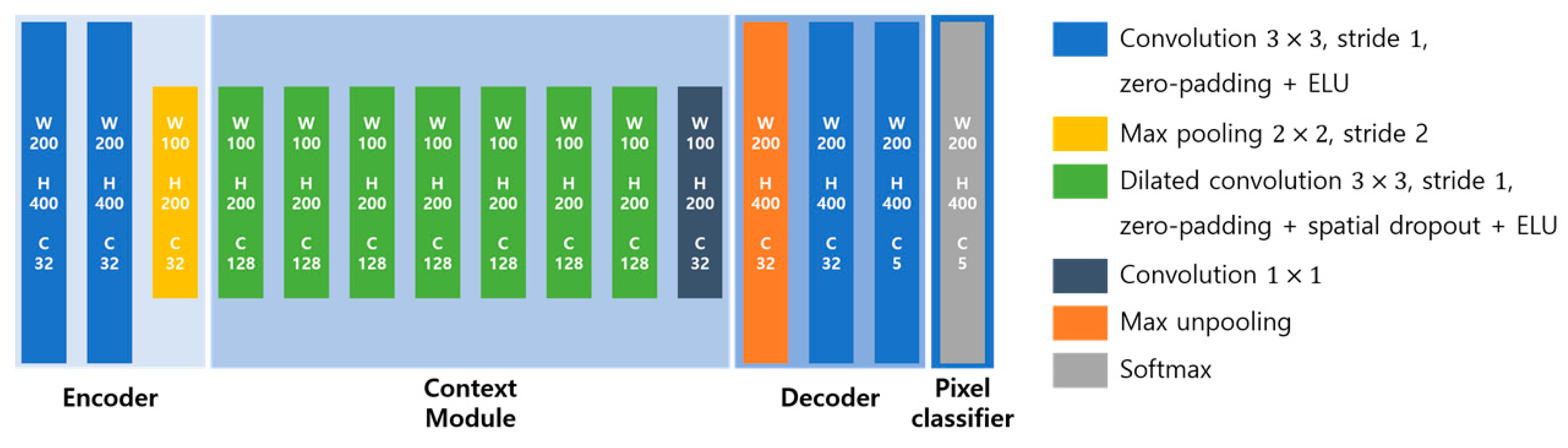
A. Segmentation Branch
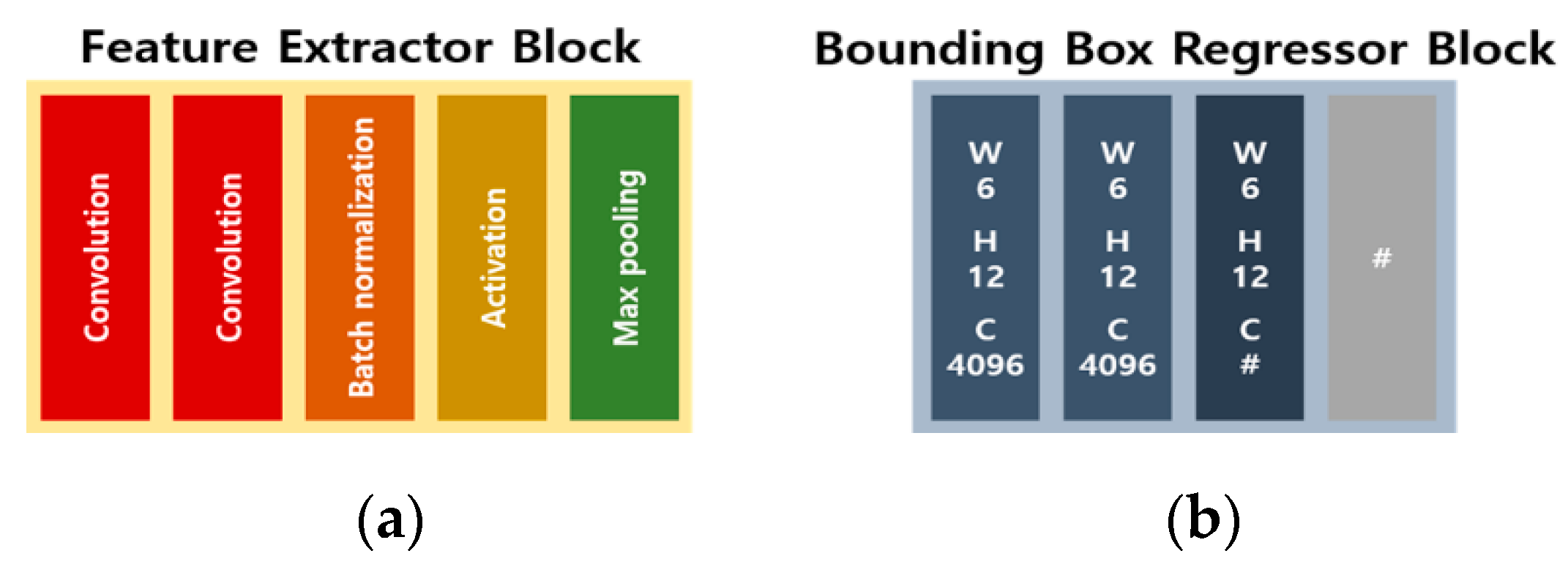
B. Detection Branch
2.2.2. Object Function
3. Experiment Results and Discussion
3.1. Dataset
3.1.1. Bounding Box Label
3.1.2. Segmentation Ground Truth
3.2. Implementation Details
3.3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

References
- Yi, U.K.; Lee, J.W. Extraction of lane-related information and a real time image processing onboard system. Int. J. Automot. Technol. 2005, 6, 171–181. [Google Scholar]
- Lee, K.B.; Kim, Y.J.; Ahn, O.S.; Kim, Y.B. Lateral control of autonomous vehicle using Levenberg-Marquardt neural network algorithm. Int. J. Automot. Technol. 2002, 3, 71–77. [Google Scholar]
- Noh, S.-W.; Kim, T.-G.; Ko, N.Y.; Bae, Y.-C. Particle filter for correction of GPS location data of a mobile robot. J. Korea Inst. Electron. Commun. Sci. 2012, 7, 381–389. [Google Scholar]
- Wang, K.; Yan, F.; Zou, B.; Tang, L.; Yuan, Q.; Lv, C. Occlusion-free road segmentation leveraging semantics for autonomous vehicles. Sensors 2019, 19, 4711. [Google Scholar] [CrossRef] [Green Version]
- Sharma, S.; Ball, J.; Tang, B.; Carruth, D.W.; Doude, M.; Islam, M.A. Semantic segmentation with transfer learning for off-road autonomous driving. Sensors 2019, 19, 2577. [Google Scholar] [CrossRef] [Green Version]
- Vaquero, V.; Repiso, E.; Sanfeliu, A. Robust and real-time detection and tracking of moving objects with minimum 2D LiDAR information to advance autonomous cargo handling in ports. Sensors 2018, 19, 107. [Google Scholar] [CrossRef] [Green Version]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martínez, V.; Garcia-Rodriguez, J. A Review on Deep Learning Techniques Applied to Semantic Segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Zou, N.; Xiang, Z.; Chen, Y.; Chen, S.; Qiao, C. Chen simultaneous semantic segmentation and depth completion with constraint of boundary. Sensors 2020, 20, 635. [Google Scholar] [CrossRef] [Green Version]
- Cai, G.; Jiang, Z.; Wang, Z.; Huang, S.; Chen, K.; Ge, X.; Wu, Y. Spatial aggregation net: Point cloud semantic segmentation based on multi-directional convolution. Sensors 2019, 19, 4329. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Chang, S.; Zhang, Y.; Zhao, X.; Huang, S.; Feng, Z.; Wei, Z.; Zhang, F. Spatial attention fusion for obstacle detection using MmWave radar and vision sensor. Sensors 2020, 20, 956. [Google Scholar] [CrossRef] [Green Version]
- Kuang, H.; Wang, B.; An, J.; Zhang, M.; Zhang, Z. Voxel-FPN: Multi-scale voxel feature aggregation for 3D object detection from LIDAR point clouds. Sensors 2020, 20, 704. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. arXiv 2015, arXiv:1411.4038. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Intelligent Tutoring Systems; Springer Science and Business Media LLC: Berlin, Germany, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. RangeNet ++: Fast and Accurate LiDAR Semantic Segmentation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Venetian, Macao, 3–8 November 2019; pp. 4213–4220. [Google Scholar]
- Wang, Y.; Shi, T.; Yun, P.; Tai, L.; Liu, M. PointSeg: Real-time semantic segmentation based on 3D LiDAR point cloud. arXiv 2018, arXiv:1807.06288. [Google Scholar]
- Yang, B.; Luo, W.; Urtasun, R. PIXOR: Real-time 3D object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7652–7660. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6526–6534. [Google Scholar]
- Fabio, A.; Pau, G.; Collotta, M. A survey on driverless vehicles: From their diffusion to security. J. Internet Serv. Inf. Secur. 2018, 8, 1–19. [Google Scholar]
- Arena, F.; Ticali, D. The development of autonomous driving vehicles in tomorrow’s smart cities mobility. AIP Conf. Proc. 2018, 2040, 140007. [Google Scholar] [CrossRef]
- Caltagirone, L.; Scheidegger, S.; Svensson, L.; Wahde, M. Fast LIDAR-based road detection using fully convolutional neural networks. IEEE Intell. Veh. Symp. 2017, 1019–1024. [Google Scholar] [CrossRef] [Green Version]
- Fisher, Y.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Tompson, J.; Goroshin, R.; Jain, A.; LeCun, Y.; Bregler, C. Efficient object localization using convolutional networks. arXiv 2015, arXiv:1411.4280. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Nitish, S.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Min, L.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- De Boer, P.-T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A tutorial on the cross-entropy method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Context Module | Dilation Rate (Width, Height) | Receptive Field |
|---|---|---|
| 1 | (1, 1) | 3 × 3 |
| 2 | (1, 2) | 5 × 7 |
| 3 | (2, 4) | 9 ×15 |
| 4 | (4, 8) | 17 × 31 |
| 5 | (8, 16) | 33 × 63 |
| 6 | (16, 32) | 65 × 127 |
| 7 | (32, 64) | 129 × 255 |
| 8 | - | 129 × 255 |
| Total Loss | |
|---|---|
| Segmentation loss (Cross-entropy) | |
| Detection loss | |
| Loss about center x coordinate of bounding box (MSE) | |
| Loss about center y coordinate of bounding box (MSE) | |
| Loss about width coordinate of bounding box (MSE) | |
| Loss about height coordinate of bounding box (MSE) | |
| Segmentation loss weight (=1.0) | |
| Detection loss weight (=0.1) | |
| Batch size | |
| Width of the Segmentation map | |
| Height of the Segmentation map |
| mAP | Weighted Average of the Number of Data Belonging to the Class for the Precision of Each Class |
|---|---|
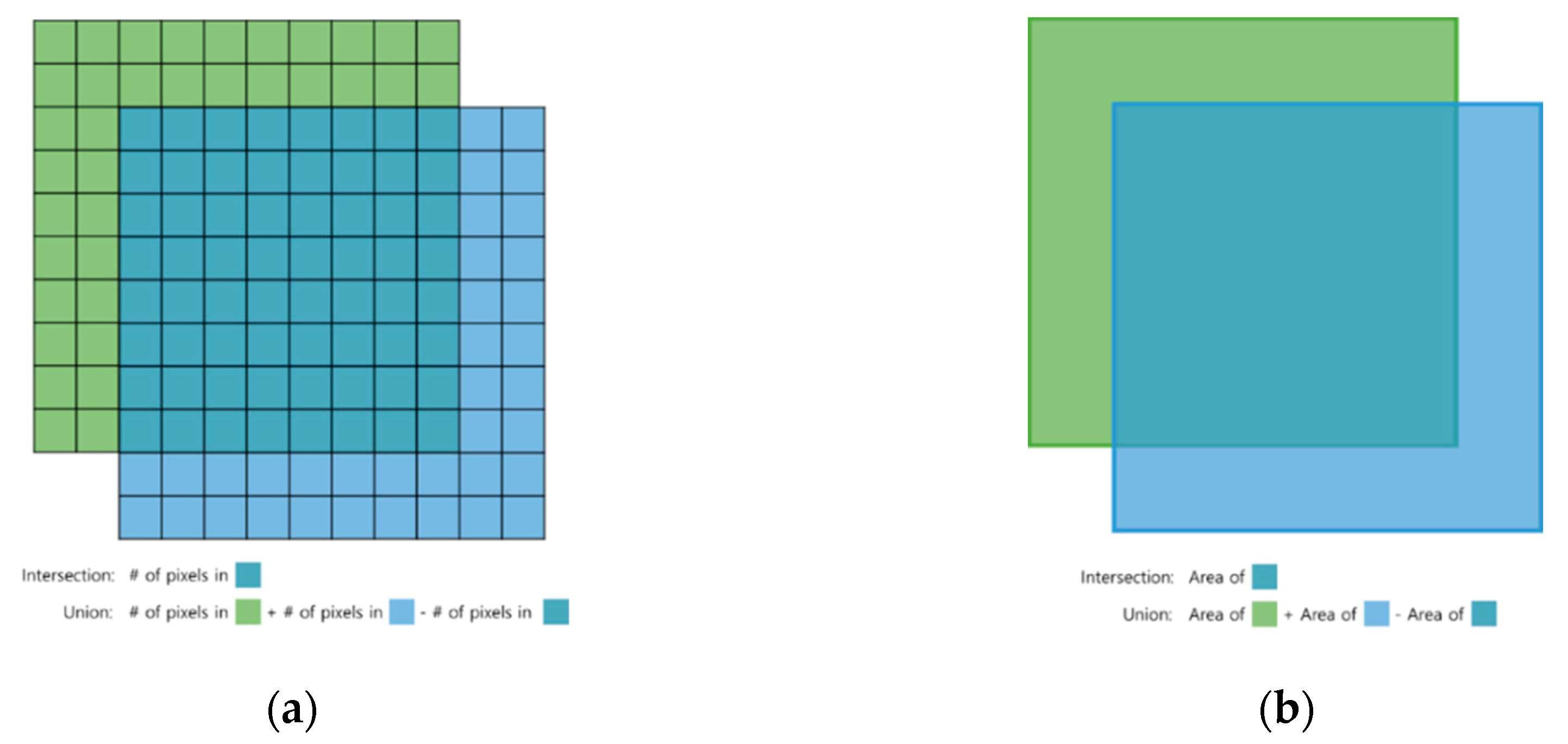
| mIoU | Average of the ratio of overlapping areas to the sum of the real and predicted areas in the bounding box |
| FPS | The number of inference frames per second |
| ACC [%] | mAP [%] | mIoU [%] |
|---|---|---|
| 96.9% | 96.9% | 83.57% |
| mAP50 [%] | mIoU [%] | |
|---|---|---|
| @0.5 | @0.7 | |
| 85.02% | 70.48% | 79.03% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, Y.; Park, S. A Deep Learning-Based Perception Algorithm Using 3D LiDAR for Autonomous Driving: Simultaneous Segmentation and Detection Network (SSADNet). Appl. Sci. 2020, 10, 4486. https://doi.org/10.3390/app10134486
Lee Y, Park S. A Deep Learning-Based Perception Algorithm Using 3D LiDAR for Autonomous Driving: Simultaneous Segmentation and Detection Network (SSADNet). Applied Sciences. 2020; 10(13):4486. https://doi.org/10.3390/app10134486
Chicago/Turabian StyleLee, Yongbeom, and Seongkeun Park. 2020. "A Deep Learning-Based Perception Algorithm Using 3D LiDAR for Autonomous Driving: Simultaneous Segmentation and Detection Network (SSADNet)" Applied Sciences 10, no. 13: 4486. https://doi.org/10.3390/app10134486
APA StyleLee, Y., & Park, S. (2020). A Deep Learning-Based Perception Algorithm Using 3D LiDAR for Autonomous Driving: Simultaneous Segmentation and Detection Network (SSADNet). Applied Sciences, 10(13), 4486. https://doi.org/10.3390/app10134486