Improvement of Learning Stability of Generative Adversarial Network Using Variational Learning

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Preliminary Works
2.1. Generative Adversarial Networks
2.2. Variational Autoencoder
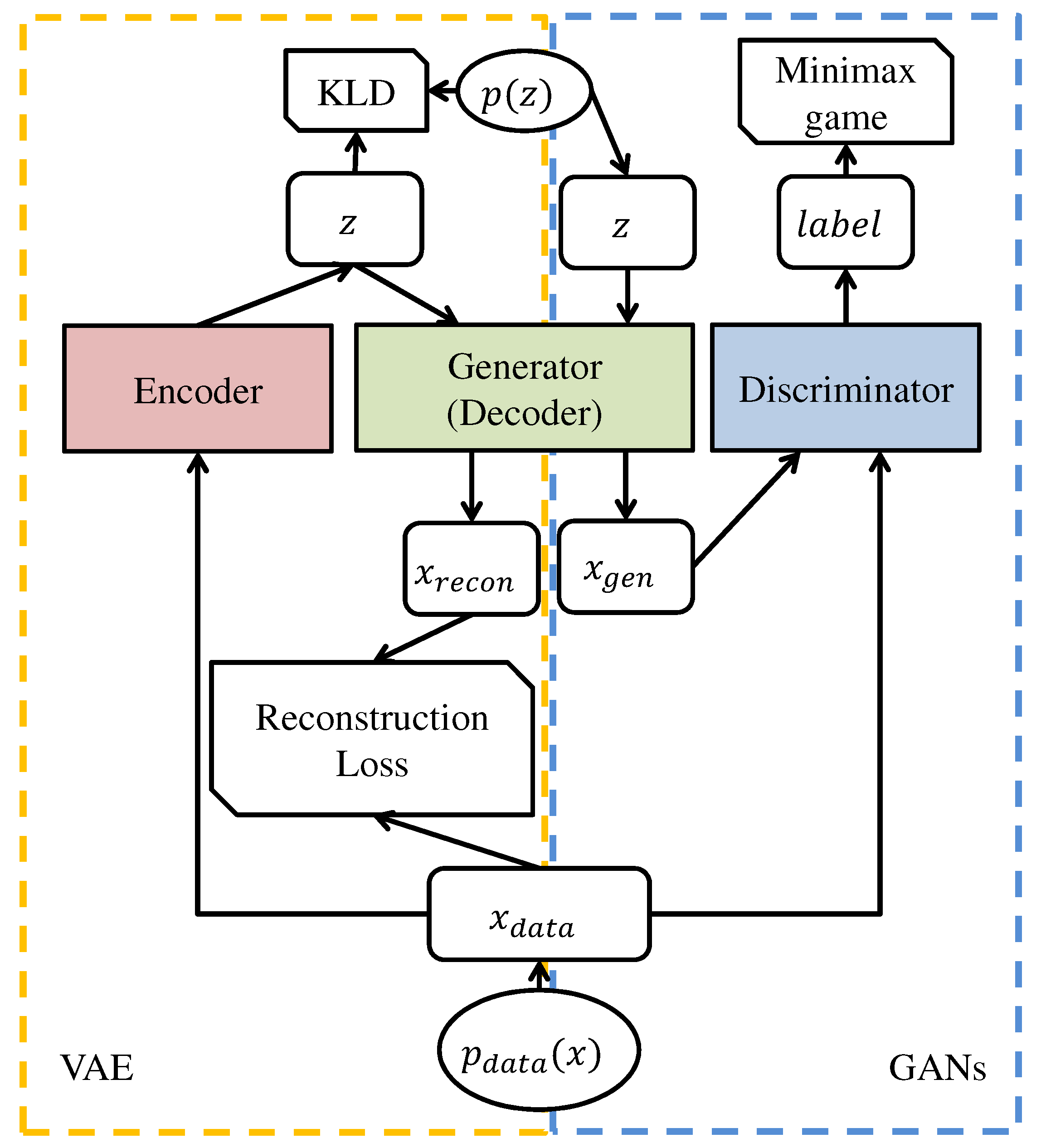
3. Improving the Learning Stability of Generative Adversarial Networks Using Variational Learning
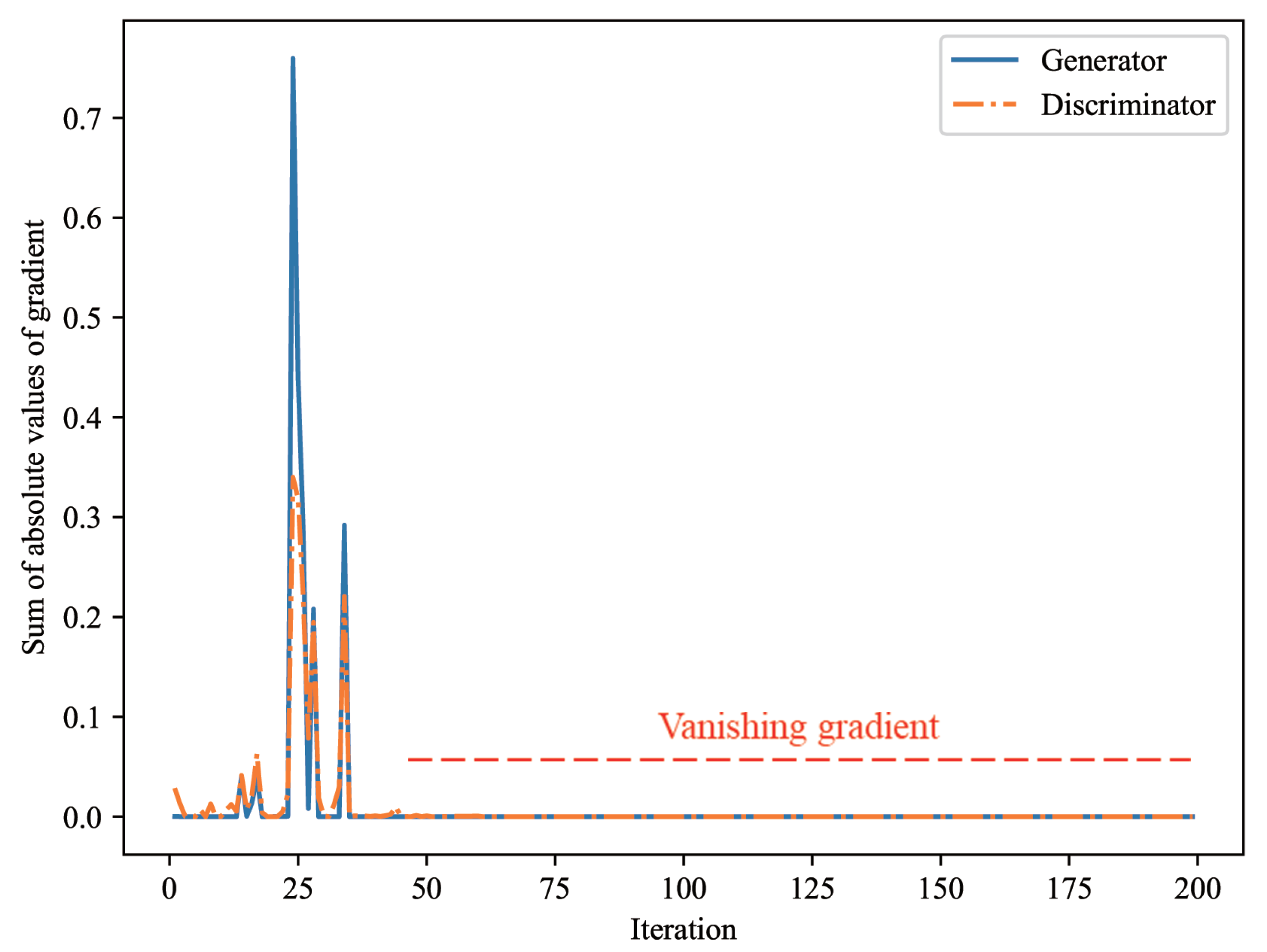
3.1. Problem Statement
3.2. Hybrid Generative Adversarial Networks for Solving Vanishing Gradient Problem
| Algorithm 1 The number of steps to apply to the discriminator, k, is a hyperparameter. We used , the least expensive option, in our experiments. is a hyperparameter. M is the batch size. ,, are parameters for generator, encoder, and discriminator, respectively. is 0 or 1. |
|
4. Experimental Results and Discussions
4.1. Dataset and Model Configuration
4.2. Improving Learning Stability Using the Proposed Method
4.3. Quality of Data Generated by the Proposed Method
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; Van Der Laak, J.A.; Van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Zhang, C.; Xue, T.; Freeman, B.; Tenenbaum, J. Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling. In Proceedings of the Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 82–90. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Lucic, M.; Kurach, K.; Michalski, M.; Gelly, S.; Bousquet, O. Are gans created equal? A large-scale study. In Proceedings of the Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 700–709. [Google Scholar]
- Goodfellow, I. NIPS 2016 tutorial: Generative adversarial networks. arXiv 2016, arXiv:1701.00160. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5767–5777. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Nowozin, S.; Cseke, B.; Tomioka, R. f-gan: Training generative neural samplers using variational divergence minimization. In Proceedings of the Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 271–279. [Google Scholar]
- Kodali, N.; Abernethy, J.; Hays, J.; Kira, Z. On convergence and stability of gans. arXiv 2017, arXiv:1705.07215. [Google Scholar]
- Zhao, J.; Mathieu, M.; LeCun, Y. Energy-based generative adversarial network. arXiv 2016, arXiv:1609.03126. [Google Scholar]
- Berthelot, D.; Schumm, T.; Metz, L. Began: Boundary equilibrium generative adversarial networks. arXiv 2017, arXiv:1703.10717. [Google Scholar]
- Bang, D.; Shim, H. Improved training of generative adversarial networks using representative features. arXiv 2018, arXiv:1801.09195. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Proceedings of the Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2234–2242. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Wu, Y.; Burda, Y.; Salakhutdinov, R.; Grosse, R. On the quantitative analysis of decoder-based generative models. arXiv 2016, arXiv:1611.04273. [Google Scholar]
- Makhzani, A.; Shlens, J.; Jaitly, N.; Goodfellow, I.; Frey, B. Adversarial autoencoders. arXiv 2015, arXiv:1511.05644. [Google Scholar]
- Mescheder, L.; Nowozin, S.; Geiger, A. Adversarial variational bayes: Unifying variational autoencoders and generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, Sydney, Australia, 6–11 August 2017; pp. 2391–2400. [Google Scholar]
- Nguyen, A.; Clune, J.; Bengio, Y.; Dosovitskiy, A.; Yosinski, J. Plug & play generative networks: Conditional iterative generation of images in latent space. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4467–4477. [Google Scholar]
- Hou, X.; Sun, K.; Shen, L.; Qiu, G. Improving variational autoencoder with deep feature consistent and generative adversarial training. Neurocomputing 2019, 341, 183–194. [Google Scholar] [CrossRef] [Green Version]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Dumoulin, V.; Belghazi, I.; Poole, B.; Mastropietro, O.; Lamb, A.; Arjovsky, M.; Courville, A. Adversarially learned inference. arXiv 2016, arXiv:1606.00704. [Google Scholar]
- Donahue, J.; Krähenbühl, P.; Darrell, T. Adversarial feature learning. arXiv 2016, arXiv:1605.09782. [Google Scholar]
- Pu, Y.; Wang, W.; Henao, R.; Chen, L.; Gan, Z.; Li, C.; Carin, L. Adversarial symmetric variational autoencoder. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4330–4339. [Google Scholar]
- Hu, Z.; Yang, Z.; Salakhutdinov, R.; Xing, E.P. On unifying deep generative models. arXiv 2017, arXiv:1706.00550. [Google Scholar]
- Rosca, M.; Lakshminarayanan, B.; Warde-Farley, D.; Mohamed, S. Variational approaches for auto-encoding generative adversarial networks. arXiv 2017, arXiv:1706.04987. [Google Scholar]
- Dosovitskiy, A.; Brox, T. Generating images with perceptual similarity metrics based on deep networks. In Proceedings of the Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 658–666. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Deng, L. The MNIST database of handwritten digit images for machine learning research [best of the web]. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Large-scale celebfaces attributes (celeba) dataset. Retrieved August 2018, 15, 2018. [Google Scholar]
- Fuglede, B.; Topsoe, F. Jensen-Shannon divergence and Hilbert space embedding. In Proceedings of the IEEE International Symposium on Information Theory (ISIT 2004), Chicago, IL, USA, 27 June–2 July 2004; p. 30. [Google Scholar]
- Kullback, S. Information Theory and Statistics; Courier Corporation Dover Publications: Mineola, New York, USA, 1997. [Google Scholar]
- Moon, T.K. The expectation-maximization algorithm. IEEE Signal Process. Mag. 1996, 13, 47–60. [Google Scholar] [CrossRef]
- Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.; Glorot, X.; Botvinick, M.; Mohamed, S.; Lerchner, A. Beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–22. [Google Scholar]
- Arjovsky, M.; Bottou, L. Towards principled methods for training generative adversarial networks. arXiv 2017, arXiv:1701.04862. [Google Scholar]
- Robert, C.; Casella, G. Monte Carlo Statistical Methods; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the IEEE Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; Volume 2, pp. 1398–1402. [Google Scholar]







© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.-Y.; Choi , S.-I. Improvement of Learning Stability of Generative Adversarial Network Using Variational Learning. Appl. Sci. 2020, 10, 4528. https://doi.org/10.3390/app10134528
Lee J-Y, Choi S-I. Improvement of Learning Stability of Generative Adversarial Network Using Variational Learning. Applied Sciences. 2020; 10(13):4528. https://doi.org/10.3390/app10134528
Chicago/Turabian StyleLee, Je-Yeol, and Sang-Il Choi . 2020. "Improvement of Learning Stability of Generative Adversarial Network Using Variational Learning" Applied Sciences 10, no. 13: 4528. https://doi.org/10.3390/app10134528
APA StyleLee, J. -Y., & Choi , S. -I. (2020). Improvement of Learning Stability of Generative Adversarial Network Using Variational Learning. Applied Sciences, 10(13), 4528. https://doi.org/10.3390/app10134528