Electrocoagulation Based Chromium Removal Efficiency Classification Using Logistic Regression


Abstract
:Featured Application
Abstract
1. Introduction
Understanding Electrocoagulation
2. Related Works
3. Materials and Methods
3.1. Labeled Dataset Building
3.2. Building Logistic Regression Model
3.2.1. Model Overview
3.2.2. Logistic Model Building
3.2.3. Logistic Model Fitting
4. Result and Discussion
4.1. Confusion Matrix
4.2. Classification Report
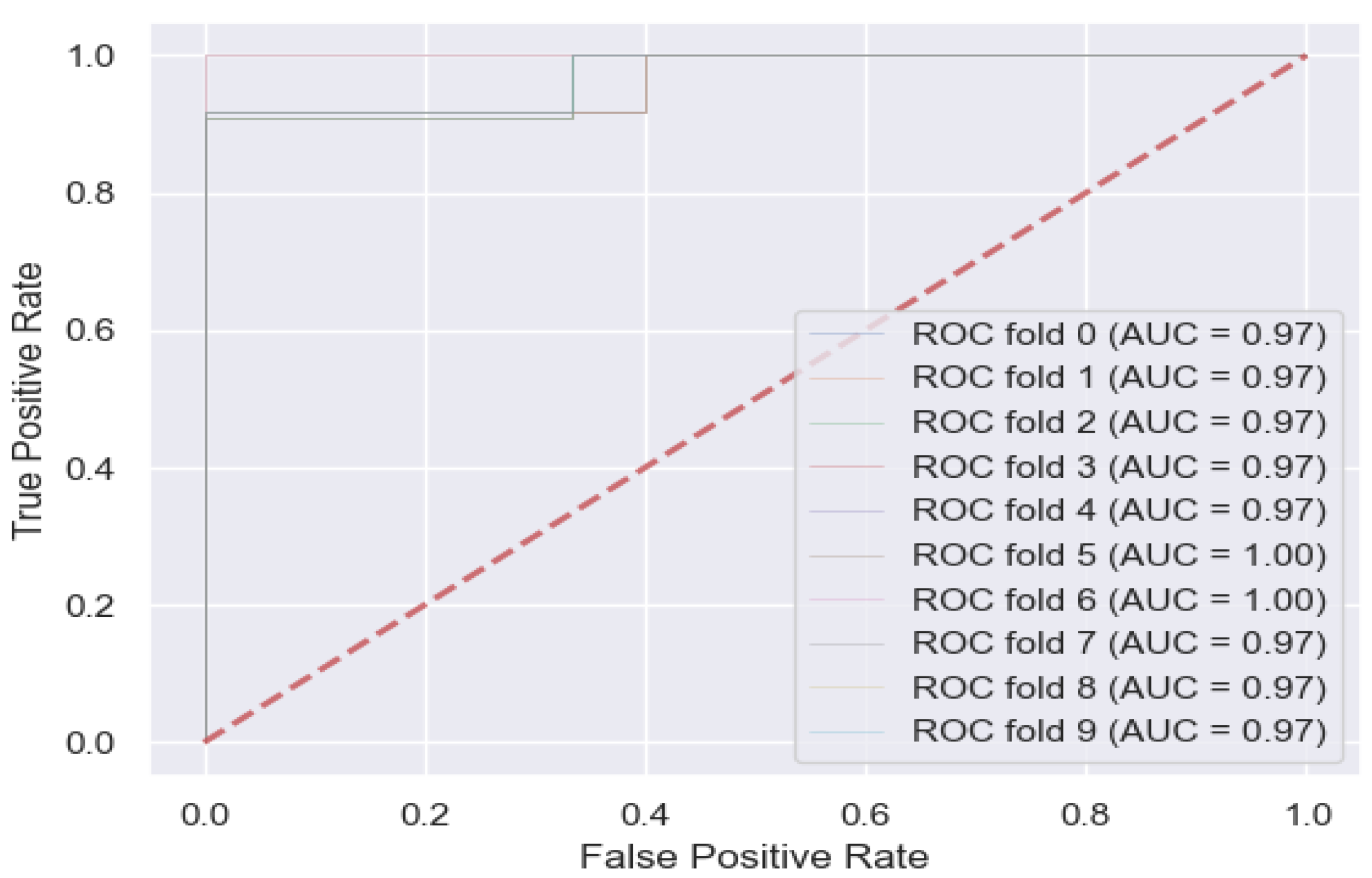
4.3. ROC Curve
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| EC | Electrocoagulation |
| Cr | Chromium |
| LR | Logistic Regression |
| SVC | Classification of Carrier Vectors |
| TAN | Total Ammonia Nitrogen |
| TIN | Total Inorganic Nitrogen |
| XWT | Cross-Wave Transformation |
References
- Lunk, H.J. Discovery, properties and applications of chromium and its compounds. ChemTexts 2015, 1, 1–7. [Google Scholar] [CrossRef] [Green Version]
- Ivy, M.; Nadia, M.; Chad, S.; Chad, M.T. Hexavalent Chromium in Drinking Water. J. AWWA 2018, 110, 22–35. [Google Scholar] [CrossRef]
- Shahid, M.; Shamshad, S.; Rafiq, M.; Khalid, S.; Bibi, I.; Niazi, N.K.; Dumat, C.; Rashid, M.I. Chromium speciation, bioavailability, uptake, toxicity and detoxification in soil plant system: A review. Chemosphere 2017, 178, 513–533. [Google Scholar] [CrossRef] [PubMed]
- Grégorio Crini, E.L. Advantages and disadvantages of techniques used for wastewater treatment. Environ. Chem. Lett. 2018, 17, 145–155. [Google Scholar] [CrossRef]
- Pokhrel, N. Removal of Heavy Metals from Wastewater Using Electrocoagulation. Ph.D. Thesis, Metropolia Ammattikorkeakoulu, Helsinki, Finland, 2017. [Google Scholar]
- Akoulih, M.; Tigani, S.; Chaibi, H.; Saadane, R.; Tazi, A. Principal Component Analysis based Approach for Understanding Electrocoagulation Setting Impact on Chromium Elimination: A Step Toward Smart Eco-Friendly City. In Proceedings of the 4th International Conference on Smart City Applications (SCA’19), Casablanca, Morocco, 2–4 October 2019; pp. 1–6. [Google Scholar]
- ALJaberi, F.Y. Operating cost analysis of a concentric aluminium tubes electrodes electrocoagulation reactor. Heliyon 2019, 5. [Google Scholar] [CrossRef] [PubMed]
- Mahdi, R.; Amirarsalan Mehrara Molanb, K.K. Analyzing injury severity of motorcycle at-fault crashes using decision tree and logistic regression methods. Int. J. Transp. Sci. Technol. 2019. [Google Scholar] [CrossRef]
- Robles-Velasco, A.; Cortés, P.; Muñuzuri, J.; Onieva, L. Prediction of pipe failures in water supply networks using logistic regression and support vector classification. J. Pre-Proof 2019. [Google Scholar] [CrossRef]
- Wan, C.M.; Nosedal-Sanchez, A.; Nosedal-Sanchez, J.; Asgary, A.; Pantin, B. Modeling provision of disaster mutual assistance by electricity utilities using logistic regression. Int. J. Disaster Risk Reduct. 2019, 36, 891–921. [Google Scholar] [CrossRef]
- Nhat-Duc Hoang, Q.L.N.; Xuan-Linh, T. Automatic Detection of Concrete Spalling Using Piecewise Linear Stochastic Gradient Descent Logistic Regression and Image Texture Analysis. Complexity 2019, 2019, 14. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Chen, G.; Reniers, G. Vulnerability assessment of atmospheric storage tanks to floods based on logistic regression. Reliab. Eng. Syst. Saf. 2020, 196. [Google Scholar] [CrossRef]
- Palmieri, F. Network anomaly detection based on logistic regression of non linear chaoticin variants. J. Netw. Comput. Appl. 2019, 148, 102460. [Google Scholar] [CrossRef]
- Chiri, H.; Abascal, A.J.; Castanedo, S.; Antolínez, J.A.; Liu, Y.; Weisberg, R.H.; Medina, R. Statistical simulation of ocean current patterns using autoregressive logistic regression models: A case study in the Gulf of Mexico. Ocean. Model. 2019, 136, 1–12. [Google Scholar] [CrossRef]
- Kakade, A.; Kumari, B.; Dholaniya, P.S. Feature selection using Logistic Regression in Case–Control DNA methylation data of Parkinson’s disease: A Comparative study. J. Theor. Biol. 2018, 136. [Google Scholar] [CrossRef] [PubMed]
- Bihu, S.; Balaji Rajagopalan, J.S. Investigating regime shifts and the factors controlling Total Inorganic Nitrogen concentrations in treated wastewater using non-homogeneoues Hidden Markov and multinominal logistic regression models. Sci. Total Environ. 2019, 646, 625–633. [Google Scholar] [CrossRef]
- Sun, Q.; Zhang, P.; Wei, H.; Liu, A.; You, S.; Sun, D. Improved mapping and understanding of desert vegetation-habitat complexes from intraannual series of spectral endmember space using crosswavelet transform and logistic regression. Remote. Sens. Environ. 2020, 236. [Google Scholar] [CrossRef]
- Martín-Domínguez, A.; Rivera-Huerta, M.D.; Pérez-Castrejón, S.; Garrido-Hoyos, S.E.; Villegas-Mendoza, I.E.; Gelover-Santiago, S.L.; Drogui, P.; Buelna, G. Chromium removal from drinking water by redox-assisted coagulation: Chemical versus electrocoagulation. Sep. Purif. Technol. 2018, 130. [Google Scholar] [CrossRef] [Green Version]
- Maitlo, H.A.; Kim, K.H.; Kumar, V.; Kim, S.; Park, J.W. Nanomaterials based treatment options for chromiumin aqueous environments. Environ. Int. 2019, 130. [Google Scholar] [CrossRef] [PubMed]
- Dos Santos, C.S.; Reis, M.H.; Cardoso, V.L.; de Resende, M.M. Electrodialysis for removal of chromium (VI) from effluent: Analysis of concentrated solution saturation. J. Environ. Chem. Eng. 2019, 7. [Google Scholar] [CrossRef]
- Genawi, N.M.; Ibrahim, M.H.; El-Naas, M.H.; Alshaik, A.E. Chromium Removal from Tannery Wastewater by Electrocoagulation: Optimization and Sludge Characterization. Water 2020, 12, 1374. [Google Scholar] [CrossRef]
- Byrd, R.H.; Lu, P.; Nocedal, J.; Zhu, C. A Limited Memory Algorithm for Bound Constrained Optimization. J. Sci. Comput. 1995, 16, 1190–1208. [Google Scholar] [CrossRef]


{kind=link}
| Run | CD (mA/cm2) | pH | Concentration (ppm) | Removal (%) | Class |
|---|---|---|---|---|---|
| 1 | 20.0 | 4.00 | 1000.00 | 71.40 | 0 |
| 2 | 20.0 | 9.0 | 1000.0 | 99.9 | 1 |
| 3 | 13.0 | 6.5 | 750.0 | 98.5 | 1 |
| 4 | 13.0 | 6.5 | 1170.45 | 84.6 | 0 |
| 5 | 6.0 | 4.0 | 500.0 | 24.5 | 0 |
| 6 | 20.0 | 9.0 | 500.0 | 95.0 | 1 |
| 7 | 13.0 | 6.5 | 750.0 | 94.8 | 1 |
| 8 | 13.0 | 6.5 | 750.0 | 94.6 | 1 |
| 9 | 13.0 | 10.7 | 750.0 | 100.0 | 1 |
| 10 | 13.0 | 6.5 | 750.0 | 94.6 | 1 |
| 11 | 13.0 | 6.5 | 750.0 | 94.5 | 1 |
| 12 | 1.22 | 6.5 | 750.0 | 23.3 | 0 |
| 13 | 24.77 | 6.5 | 750.0 | 93.0 | 1 |
| 14 | 6.0 | 4.0 | 1000.0 | 2.8 | 0 |
| 15 | 13.0 | 6.5 | 750.0 | 94.3 | 1 |
| 16 | 6.0 | 9.0 | 500.0 | 86.0 | 0 |
| 17 | 20.0 | 4.0 | 500.0 | 92.5 | 1 |
| 18 | 13.0 | 6.5 | 329.55 | 99.9 | 1 |
| 19 | 13.0 | 2.29 | 750.0 | 19.5 | 0 |
| 20 | 6.0 | 9.0 | 1000.0 | 90.0 | 1 |
| Class | Precision | Recall | F-Score |
|---|---|---|---|
| 0.0 | 0.83 | 0.83 | 0.83 |
| 1.0 | 0.92 | 0.92 | 0.92 |
| Average | 0.88 | 0.88 | 0.88 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Akoulih, M.; Tigani, S.; Saadane, R.; Tazi, A. Electrocoagulation Based Chromium Removal Efficiency Classification Using Logistic Regression. Appl. Sci. 2020, 10, 5179. https://doi.org/10.3390/app10155179
Akoulih M, Tigani S, Saadane R, Tazi A. Electrocoagulation Based Chromium Removal Efficiency Classification Using Logistic Regression. Applied Sciences. 2020; 10(15):5179. https://doi.org/10.3390/app10155179
Chicago/Turabian StyleAkoulih, Meryem, Smail Tigani, Rachid Saadane, and Amal Tazi. 2020. "Electrocoagulation Based Chromium Removal Efficiency Classification Using Logistic Regression" Applied Sciences 10, no. 15: 5179. https://doi.org/10.3390/app10155179
APA StyleAkoulih, M., Tigani, S., Saadane, R., & Tazi, A. (2020). Electrocoagulation Based Chromium Removal Efficiency Classification Using Logistic Regression. Applied Sciences, 10(15), 5179. https://doi.org/10.3390/app10155179