Predictive Scheduling with Markov Chains and ARIMA Models



Abstract
:1. Introduction
- disruptions of resource availability (machine or robot failure)
- disruptions of orders (placement of new orders)
- disruptions of processes (material shortage, poor product quality)
- disruptions associated with misestimation of the ongoing process parameters (incorrect estimation of operation times)
- disruptions related to the change in the duration of the operation (employee absence or malaise, shorter or extended operation times)
2. Existing Work on Robust Production Scheduling
2.1. Essentials of Robust Scheduling
- Predictive scheduling-related to the planning stage.
- Reactive scheduling-related to the production stage.
- a nominal schedule-based on the current system parameters,
- a robust schedule-based on the assumption of uncertainty and variability of production.
2.2. Existing Literature on Robust Production Scheduling
2.3. Machine Failure as the Major Uncertainty Factor
3. Production Scheduling under Technological Machine Failure Constraint
3.1. Objectives
3.2. Basic Mathematical Notation of the Problem
- Set is a set of machines (workstations) processing jobs:
- Set is a set of jobs (tasks) to process
- —a matrix of columns and rows describing the technology (the job order):where —the order position of the operation of job , which is when the job is not processed on the machine; and , when it is.
- Matrix —a matrix describing processing times of operations:where —the processing time of operations of job ; for each , .
- Set of potential machine failure times:where —time to failure of the machine l; where is a natural number representing the z-th machine failure.
- Set of time buffers to include in the nominal schedule (for machine ) to obtain a robust schedule:where —the size of the time buffer in the schedule at the failure time ; where for , .
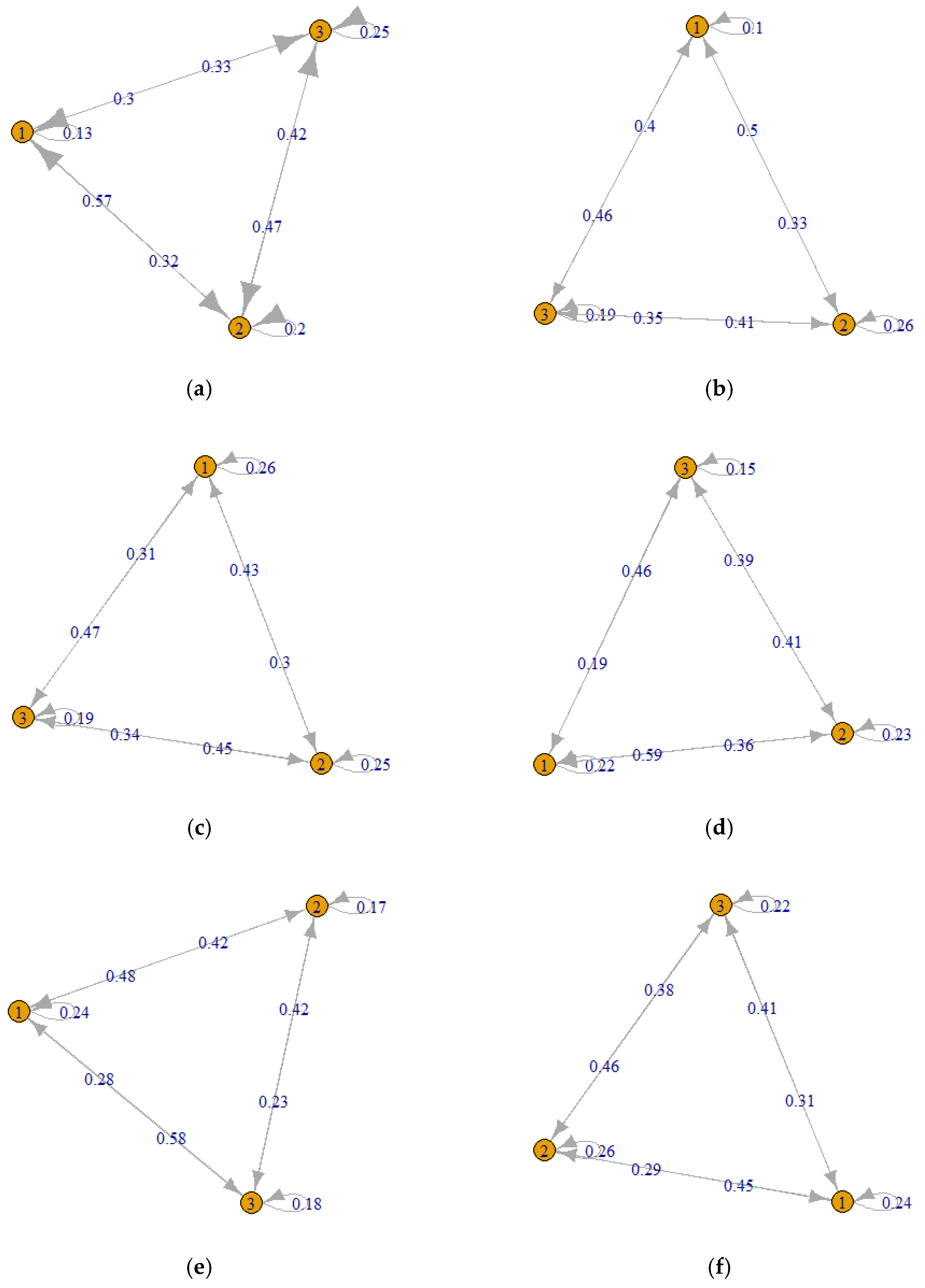
3.3. Prediction of Failure and Machine Repair Times
4. Experimental Verification of the Proposed Solution
4.1. Historical Data
- Machine M1—197 observations
- Machine M2—166 observations
- Machine M3—180 observations
- Machine M6—157 observations
- Machine M7—208 observations
- Machine M8—97 observations
4.2. Prediction of Machine Failure Parameters
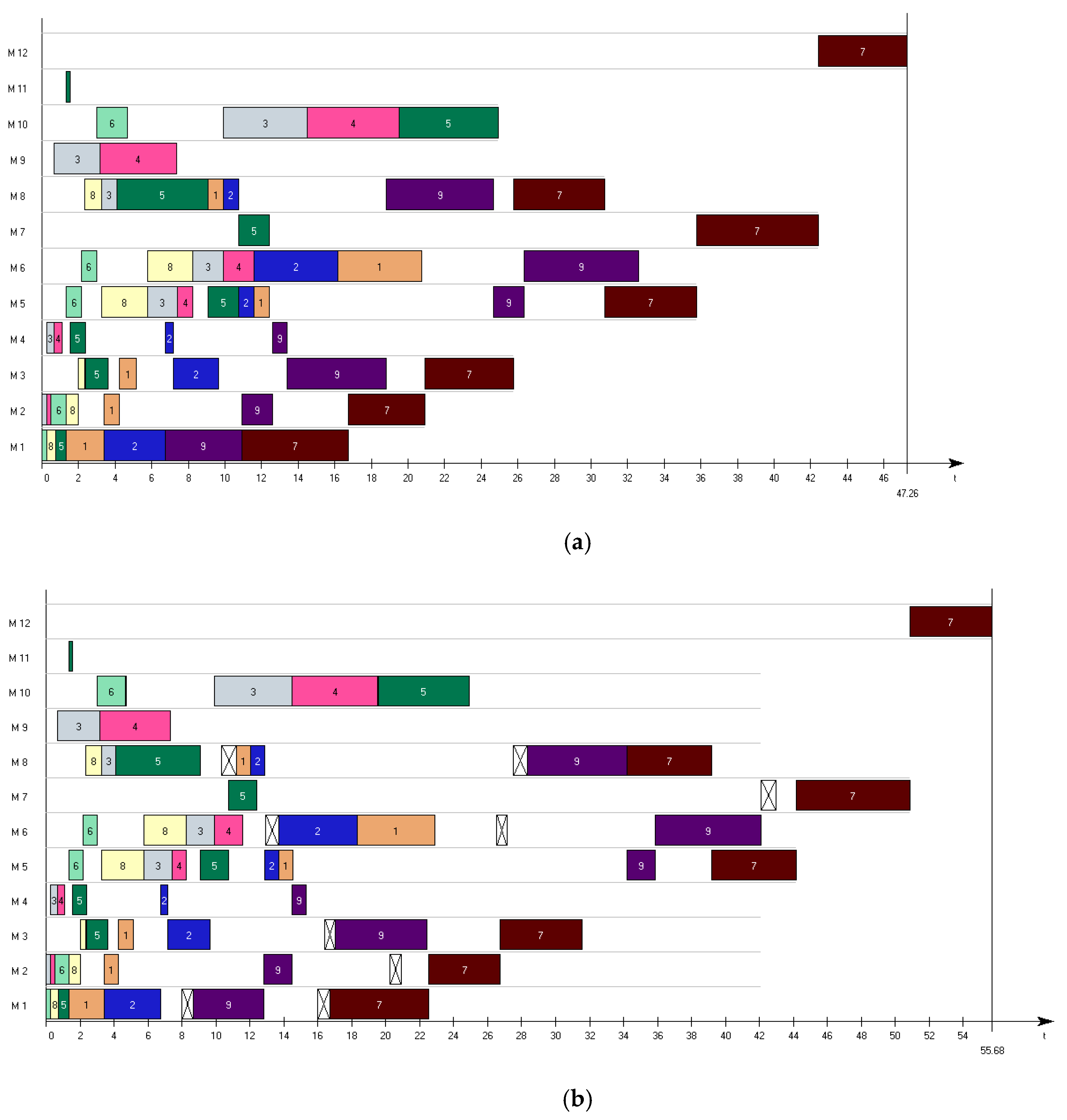
4.3. Production Process Modelling and Scheduling
- LPT (longest processing time)
- SPT (shortest processing time)
4.4. Evaluation Criteria
- makespan —total production time,
- mean completion time given by:where —the completion time of job i.
- mean flow time given by:where —the flow time of job i.
- the number of critical operations is derived from:where —the number of critical operations, —the completion time of operation oij (current), —the start time of operation oij + 1 (subsequent).
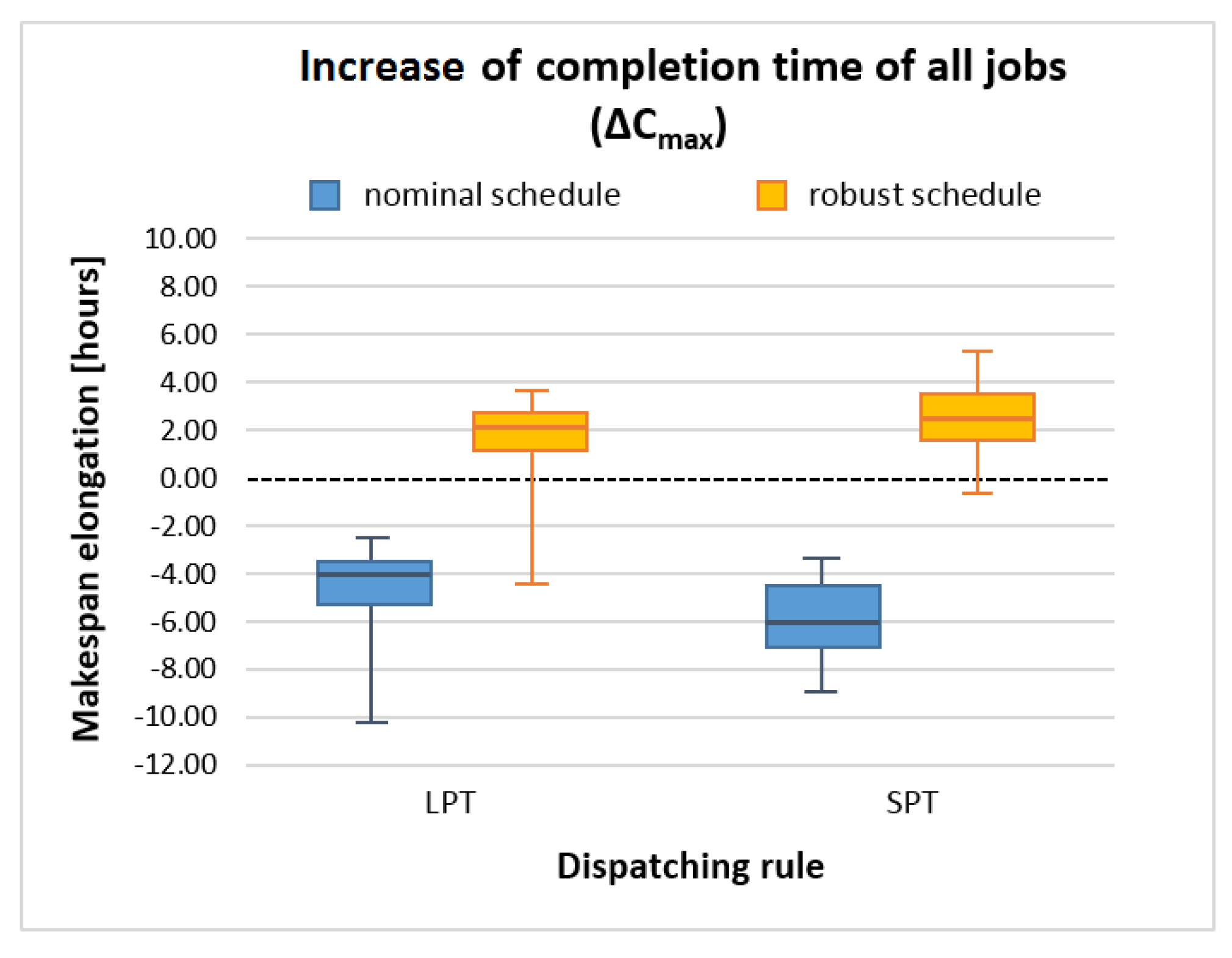
- Increase of completion time of all jobs given by:where —increase of completion time of all jobs, —nominal schedule makespan, —actual (executed) schedule makespan.
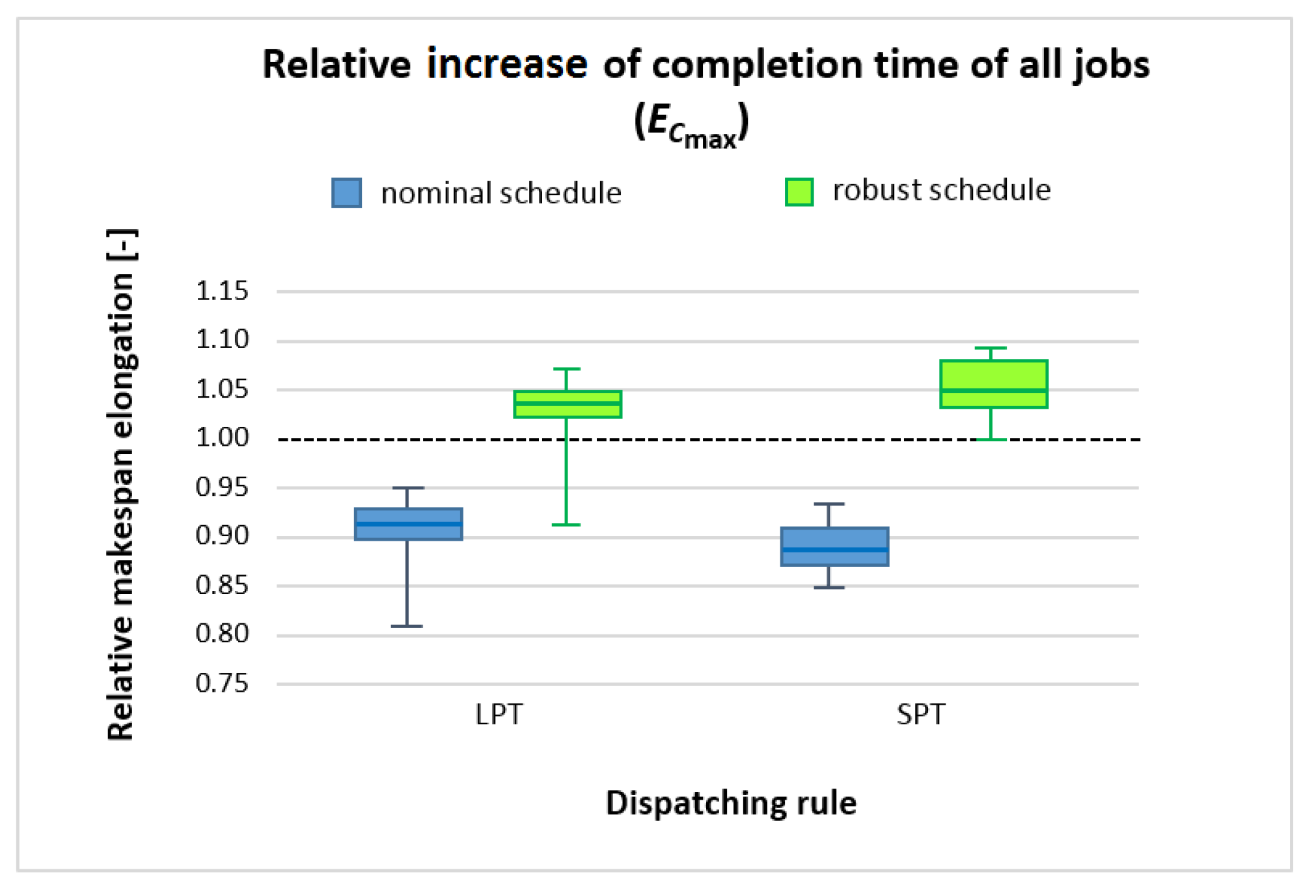
- Relative increase of makespan given by:where —relative increase of makespan, —nominal schedule makespan, —actual (executed) schedule makespan.
4.5. Experimental Results
5. Summary and Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Transition Rate Matrix | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Machine M1 | Machine M2 | Machine M3 | |||||||||
| shift | 1 | 2 | 3 | shift | 1 | 2 | 3 | shift | 1 | 2 | 3 |
| 1 | 0.132 | 0.566 | 0.302 | 1 | 0.100 | 0.500 | 0.400 | 1 | 0.262 | 0.426 | 0.311 |
| 2 | 0.324 | 0.203 | 0.473 | 2 | 0.328 | 0.262 | 0.410 | 2 | 0.300 | 0.250 | 0.450 |
| 3 | 0.333 | 0.420 | 0.246 | 3 | 0.463 | 0.352 | 0.185 | 3 | 0.466 | 0.345 | 0.190 |
| Machine M6 | Machine M7 | Machine M8 | |||||||||
| shift | 1 | 2 | 3 | shift | 1 | 2 | 3 | shift | 1 | 2 | 3 |
| 1 | 0.222 | 0.593 | 0.185 | 1 | 0.244 | 0.476 | 0.280 | 1 | 0.241 | 0.448 | 0.310 |
| 2 | 0.361 | 0.230 | 0.410 | 2 | 0.415 | 0.169 | 0.415 | 2 | 0.286 | 0.257 | 0.457 |
| 3 | 0.463 | 0.390 | 0.146 | 3 | 0.583 | 0.233 | 0.183 | 3 | 0.406 | 0.375 | 0.219 |
References
- Perłowski, R.; Antosz, K.; Zielecki, W. Optimization of the Medium-Term Production Planning in the Company—Case Study. Lect. Notes Electr. Eng. 2018, 505, 369–376. [Google Scholar]
- Burduk, A.; Musial, K.; Kochanska, J. Tabu Search and Genetic Algorithm for Production Process Scheduling Problem. LogForum 2019, 15, 181–189. [Google Scholar] [CrossRef]
- Sobaszek, Ł.; Gola, A.; Kozłowski, E. Application of survival function in robust scheduling of production jobs. In Proceedings of the 2018 Federated Conference on Computer Science and Information Systems (FEDCSIS), Prague, Czech Republic, 3–6 September 2017; Ganzha, M., Maciaszek, M., Paprzycki, M., Eds.; IEEE: New York, NY, USA, 2017; Volume 11, pp. 575–578. [Google Scholar]
- Gürel, S.; Körpeoḡlu, E.; Aktürk, M.S. An Anticipative Scheduling Approach with Controllable Processing Times. Comput. Oper. Res. 2010, 37, 1002–1013. [Google Scholar] [CrossRef] [Green Version]
- Gao, H. Building Robust Schedules using Temporal Potection—An Empirical Study of Constraint Based Scheduling Under Machine Failure Uncertainty. Ph.D. Thesis, Univeristy of Toronto, Toronto, ON, Canada, 1996. [Google Scholar]
- Sobaszek, Ł.; Gola, A.; Kozlowski, E. Job-shop scheduling with machine breakdown prediction under completion time constraint. Adv. Intell. Syst. Comput. 2018, 637, 358–367. [Google Scholar]
- Daniewski, K.; Kosicka, E.; Mazurkiewicz, D. Analysis of the correctness of determination of the effectiveness of maintenance service actions. Manag. Prod. Eng. Rev. 2018, 9, 20–25. [Google Scholar]
- Janardhanan, M.N.; Li, Z.; Bocewicz, G.; Banaszak, Z.; Nielsen, P. Metaheuristic algorithms for balancing robotic assembly lines with sequence-dependent robot setup times. Appl. Math. Model. 2019, 65, 256–270. [Google Scholar] [CrossRef] [Green Version]
- Deepu, P. Robust Schedules and Disruption Management for Job Shops. Ph.D. Thesis, Montana State Univeristy, Bozeman, MT, USA, 2008. [Google Scholar]
- Jasiulewicz-Kaczmarek, M.; Gola, A. Maintenance 4.0 Technologies for Sustainable Manufacturing—An Overview. IFAC PapersOnLine 2019, 52, 91–96. [Google Scholar] [CrossRef]
- Gola, A.; Kłosowski, G. Development of computer-controlled material handling model by means of fuzzy logic and genetic algorithms. Neurocomputing 2019, 338, 381–392. [Google Scholar] [CrossRef]
- Klimek, M. Techniques of Generating Schedules for the Problem of Financial Optimization of Multi-Stage Project. Appl. Comput. Sci. 2017, 15, 20–34. [Google Scholar]
- Rahman, H.F.; Sarker, R.; Essam, D. A Real-Time Order Acceptance and Scheduling Approach for Permutation Flow Shop Problems. Eur. J. Oper. Res. 2015, 247, 488–503. [Google Scholar] [CrossRef]
- Choi, S.H.; Wang, K. Flexible Flow Shop Scheduling with Stochastic Processing Times: A Decomposition-Based Approach. Comput. Ind. Eng. 2012, 63, 362–373. [Google Scholar] [CrossRef] [Green Version]
- Kianfar, K.; Fatemi, G.S.M.T.; Oroojlooy, J.A. Study of Stochastic Sequence-Dependent Flexible Flow Shop via Developing a Dispatching Rule and a Hybrid GA. Eng. Appl. Artif. Intell. 2012, 25, 494–506. [Google Scholar] [CrossRef]
- Almeder, C.; Hartl, R.F. A Metaheuristic Optimization Approach for a Real-World Stochastic Flexible Flow Shop Problem with Limited Buffer. Int. J. Prod. Econ. 2013, 145, 88–95. [Google Scholar] [CrossRef]
- Rahman, H.F.; Sarker, R.; Essam, D. A Genetic Algorithm for Permutation Flow Shop Scheduling Under Make to Stock Production System. Comput. Ind. Eng. 2015, 90, 12–24. [Google Scholar] [CrossRef]
- Chung-Cheng, L.; Kuo-Ching, Y.; Shih-Wei, L. Robust Single Machine Scheduling for Minimizing Total Flow Time in the Presence of Uncertain Processing Times. Comput. Ind. Eng. 2014, 74, 102–110. [Google Scholar]
- Bibo, Y.; Geunes, J. Predictive–reactive scheduling on a single resource with Uncertain Future Jobs. Eur. J. Oper. Res. 2008, 189, 1267–1283. [Google Scholar]
- Jian, X.; Li-Ning, X.; Ying-Wu, C. Robust Scheduling for Multi-Objective Flexible Job-Shop Problems with Random Machine Breakdowns. Int. J. Prod. Econ. 2013, 141, 112–126. [Google Scholar]
- Mehta, S.V.; Uzsoy, R.M. Predictable Scheduling of a Job Shop Subject to Breakdowns. IEEE Trans. Robot. Autom. 1998, 14, 365–378. [Google Scholar] [CrossRef]
- Bierwirth, C.; Mattfeld, D.C. Production Scheduling and Rescheduling with Genetic Algorithms. Evol. Comput. 1999, 7, 1–17. [Google Scholar] [CrossRef]
- Xingquan, Z.; Hongwei, M.; Jianping, W. A robust scheduling method based on a multi-objective immune algorithm. Inf. Sci. 2009, 179, 3359–3369. [Google Scholar]
- Jensen, M.T. Robust and Flexible Scheduling with Evolutionary Computation. Ph.D. Thesis, University of Aarhus, Aarhus, Denmark, 2001. [Google Scholar]
- Janak, S.L.; Lin, X.; Floudas, C.A. A New Robust Optimization Approach for Scheduling Under Uncertainty—II. Uncertainty with Known Probability Distribution. Comput. Chem. Eng. 2007, 31, 171–195. [Google Scholar] [CrossRef]
- Henning, G.P.; Cerda, J. Knowledge-based predictive and reactive scheduling in industrial environments. Comput. Chem. Eng. 2000, 24, 2315–2338. [Google Scholar] [CrossRef]
- Jensen, M.T. Improving robustness and flexibility of tardiness and total flow-time job shops using robustness measures. Appl. Soft Comput. 2001, 1, 35–52. [Google Scholar] [CrossRef] [Green Version]
- Al-Hinai, N.; ElMekkawy, T.Y. Robust and Stable Flexible Job Shop Scheduling with Random Machine Breakdowns Using a Hybrid Genetic Algorithm. Int. J. Prod. Econ. 2011, 132, 279–291. [Google Scholar] [CrossRef]
- Davenport, A.; Gefflot, C.; Beck, C. Slack-based Techniques for Robust Schedules. In Proceedings of the Sixth European Conference on Planning, Toledo, Spain, 12–14 September 2001. [Google Scholar]
- Kempa, W.; Paprocka, I.; Kalinowski, K.; Grabowik, C. Estimation of reliability characteristics in a production scheduling model with failures and time-changing parameters described by Gamma and exponential distributions. Adv. Mater. Res. 2014, 837, 116–121. [Google Scholar] [CrossRef]
- Kempa, W.; Wosik, I.; Skołud, B. Estimation of Reliability Characteristics in a Production Scheduling Model with Time-Changing Parameters—First Part, Theory. Manag. Control Manuf. Process. 2011, 1, 7–18. [Google Scholar]
- Rosmaini, A.; Shahrul, K. An overview of time-based and condition-based maintenance in industrial application. Comput. Ind. Eng. 2012, 63, 135–149. [Google Scholar]
- Rawat, M.; Lad, B.K. Novel approach for machine tool maintenance modelling and optimization using fleet system architecture. Comput. Ind. Eng. 2018, 126, 47–62. [Google Scholar] [CrossRef]
- Baptista, M.; Sankararaman, S.; De Medeiros, I.P.; Nascimento, C.; Prendinger, H.; Henriques, E.M.P. Forecasting fault events for predictive maintenance using data-driven techniques and ARMA modeling. Comput. Ind. Eng. 2018, 115, 41–53. [Google Scholar] [CrossRef]
- Kalinowski, K.; Krenczyk, D.; Grabowik, C. Predictive-reactive strategy for real time scheduling of manufacturing systems. Appl. Mech. Mater. 2013, 307, 470–473. [Google Scholar] [CrossRef]
- Sobaszek, Ł.; Gola, A.; Kozłowski, E. Module for prediction of technological operation times in an intelligent job scheduling system. In Intelligent Systems in Production Engineering and Maintenance—ISPEM 2018: International Conference on Intelligent Systems in Production Engineering and Maintenance; Burduk, A., Chlebus, E., Nowakowski, T., Tubis, A., Eds.; Springer: Cham, Switzerland, 2018; pp. 234–243. [Google Scholar]
- Knopik, L.; Migawa, K. Semi-Markov system model for minimal repair maintenance. Eksploat. I Niezawodn. Maint. Reliab. 2019, 21, 256–260. [Google Scholar] [CrossRef]
- Stewart, W.J. Probability, Markov Chains, Queues, and Simulation; Princeton University Press: Princeton, NJ, USA, 2009. [Google Scholar]
- Ross, S. Introduction to Probability Models, 6th ed.; Academic Press: San Diego, CA, USA, 1997. [Google Scholar]
- Kozłowski, E.; Borucka, A.; Świderski, A. Application of the logistic regression for determining transition probability matrix of operating states in the transport systems. Eksploat. I Niezawodn. Maint. Reliab. 2020, 22, 192–200. [Google Scholar] [CrossRef]
- Chow, G.C. Ekonometria; PWN: Warszawa, Poland, 1995. [Google Scholar]
- Kozłowski, E. Analiza i Identyfikacja Szeregów Czasowych; Politechnika Lubelska: Lublin, Poland, 2015. [Google Scholar]
- Box, G.E.P.; Jenkins, G.M. Time Series Analysis: Forecasting and Control. Holden-Day; Wiley: San Francisco, CA, USA, 1970. [Google Scholar]
- Rymarczyk, T. Characterizations of the shape of unknown objects by inverse numerical methods. Prz. Elektrotechniczny 2020, 88, 138–140. [Google Scholar]
- Kozłowski, E.; Mazurkiewicz, D.; Żabiński, T.; Prucnal, S.; Sęp, J. Machining sensor data management for operation-level predictive model. Expert Syst. Appl. 2020, 159, 113600. [Google Scholar] [CrossRef]
- Shumway, R.H.; Stoffer, D.S. Time Series Analysis and Its Applications with R Examples; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Kosicka, E.; Kozłowski, E.; Mazurkiewicz, D. The use of stationary tests for analysis of monitored residual processes. Eksploat. I Niezawodn. Maint. Reliab. 2015, 17, 604–609. [Google Scholar] [CrossRef]
- RStudio Team. RStudio: Integrated Development for R; PBC: Boston, MA, USA, 2020; Available online: http://www.rstudio.com (accessed on 10 July 2020).
- Bräsel, H.; Dornheim, L.; Kutz, S.; Mörig, M.; Rössling, I. LiSA—A Library of Scheduling Algorithms; Magdeburg University: Magdeburg, Germany, 2001. [Google Scholar]
- Chiang, T.C.; Fu, L.C. Using Dispatching Rules for Job Shop Scheduling with Due Date-Based Objectives. Int. J. Prod. Res. 2007, 45, 1–28. [Google Scholar] [CrossRef]




| Job | Operation | Machine | Type of Operation | tsij * [min] | tsij * [h] | toij * [min] | toij * [h] | |
|---|---|---|---|---|---|---|---|---|
| 2 | 10 | M1 | Laser1 | Laser-cutting sheets | 22 | 0.367 | 4 | 0.067 |
| 20 | M4 | CNC saw | Band-saw cutting | 6 | 0.100 | 0.5 | 0.008 | |
| 30 | M3 | CNC press | Edge bending | 16 | 0.267 | 3 | 0.050 | |
| 40 | M8 | Drill | Drilling holes and threading | 12 | 0.200 | 1 | 0.017 | |
| 50 | M5 | Metalworking | Metalworking | 5 | 0.083 | 1 | 0.017 | |
| 60 | M6 | MIG welder | MIG welding | 8 | 0.133 | 5.5 | 0.092 | |
| 6 | 10 | M1 | Laser1 | Laser-cutting sheets | 12 | 0.200 | 0.3 | 0.005 |
| 20 | M2 | Laser2 | Laser-cutting profiles | 14 | 0.233 | 1 | 0.017 | |
| 30 | M5 | Metalworking | Metalworking | 5 | 0.083 | 1 | 0.017 | |
| 40 | M6 | MIG welder | MIG welding | 8 | 0.133 | 1 | 0.017 | |
| 50 | M10 | Turning lathe | Turning | 11 | 0.183 | 2 | 0.033 | |
| 9 | 10 | M1 | Laser1 | Laser-cutting sheets | 20 | 0.333 | 5 | 0.083 |
| 20 | M2 | Laser2 | Laser-cutting pipes and profiles | 12 | 0.200 | 2 | 0.033 | |
| 30 | M4 | CNC saw | Band-saw cutting | 6 | 0.100 | 1 | 0.017 | |
| 40 | M3 | CNC press | Edge bending | 25 | 0.471 | 6.5 | 0.108 | |
| 50 | M8 | Drill | Drilling holes and threading | 12 | 0.200 | 7 | 0.117 | |
| 60 | M5 | Metalworking | Metalworking | 5 | 0.083 | 2 | 0.033 | |
| 70 | M6 | MIG welder | MIG welding | 8 | 0.133 | 7.5 | 0.125 | |
| Machine M1 | Machine M2 | Machine M3 | Machine M6 | Machine M7 | Machine M8 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Failure–Shift [–] | Repair Time [min] | Failure –Shift [–] | Repair Time [min] | Failure–Shift [–] | Repair Time [min] | Failure–Shift [–] | Repair Time [min] | Failure–Shift [–] | Repair Time [min] | Failure–Shift [–] | Repair Time [min] |
| 3 | 230 | 2 | 50 | 3 | 70 | 1 | 10 | 2 | 20 | 2 | 235 |
| 2 | 120 | 1 | 15 | 3 | 30 | 1 | 50 | 1 | 20 | 1 | 30 |
| 1 | 15 | 2 | 20 | 1 | 35 | 1 | 15 | 1 | 40 | 1 | 15 |
| 2 | 95 | 2 | 20 | 3 | 190 | 3 | 110 | 1 | 20 | 2 | 215 |
| 1 | 80 | 1 | 15 | 2 | 125 | 1 | 120 | 2 | 20 | 2 | 100 |
| 2 | 30 | 3 | 250 | 2 | 30 | 2 | 130 | 3 | 80 | 2 | 10 |
| 3 | 130 | 2 | 15 | 3 | 15 | 1 | 30 | 2 | 10 | 1 | 40 |
| Machine No. | p-Value [–] |
|---|---|
| M1 | 0.8922 |
| M2 | 0.9051 |
| M3 | 0.9510 |
| M6 | 0.7361 |
| M7 | 0.9684 |
| M8 | 0.5618 |
| Machine No. | ARIMA Model | Predicted Repair Times [min] | ||||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| M1 | ARIMA(1,0,0) | 38.77 | 42.11 | 41.90 | 41.91 | 41.91 |
| M2 | ARIMA(0,0,0) | 39.79 | 39.79 | 39.79 | 39.79 | 39.79 |
| M3 | ARIMA(1,1,2) | 36.78 | 40.80 | 40.02 | 40.16 | 40.14 |
| M6 | ARIMA(2,0,1) | 48.12 | 37.57 | 43.20 | 37.78 | 42.13 |
| M7 | ARIMA(1,0,1) | 54.80 | 54.20 | 53.72 | 53.35 | 53.06 |
| M8 | ARIMA(0,0,1) | 51.83 | 49.85 | 49.85 | 49.85 | 49.85 |
| Machine No. | Elements of Set FTMl [h] | Elements of Set TBMl [h] |
|---|---|---|
| M1 | FTM1 = {8} | TBM1 = {0.646, 0.702, 0.698, 0.699, 0.699} |
| M2 | FTM2 = {8} | TBM2 = {0.663, 0.663, 0.663, 0.663, 0.663} |
| M3 | FTM3 = {8} | TBM3 = {0.613, 0.680, 0.667, 0.669, 0.669} |
| M6 | FTM6 = {8} | TBM6 = {0.802, 0.626, 0.720, 0.630, 0.702} |
| M7 | FTM7 = {8} | TBM7 = {0.913, 0.903, 0.895, 0.889, 0.884} |
| M8 | FTM8 = {8} | TBM8 = {0.864, 0.831, 0.831, 0.831, 0.831} |
| Machine No. (Technology) | MTTF * | MTTR * |
|---|---|---|
| M1 | Uniform(0, 16.763) | Weibull(0.88, 1.28) |
| M2 | Uniform(0, 8.673) | Weibull(0.75, 1.51) |
| M3 | Uniform(0, 15.247) | Weibull(0.679, 1.72) |
| M6 | Uniform(0, 22.083) | Weibull(0.769, 1.43) |
| M7 | Uniform(0, 8.34) | Weibull(0.973, 1.58) |
| M8 | Uniform(0, 19.24) | Weibull(0.877, 1.45) |
| Dispatching Rule | Evaluation Criterion [h] | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Nominal Sched | Robust Sched | Elong. [%] | Nominal Sched | Robust Sched | Elong. [%] | Nominal Sched | Robust Sched | Elong. [%] | |
| LPT | 23.34 | 23.86 | 2.3% | 31.94 | 36.49 | 14.2% | 46.93 | 53.14 | 13.2% |
| SPT | 18.33 | 19.94 | 8.8% | 20.95 | 23.42 | 11.8% | 47.26 | 55.68 | 17.8% |
| Dispatching Rule | Number of Critical Operations [–] | |||||
|---|---|---|---|---|---|---|
| Nominal Sched. | Robust Sched. | Reduction [%] | Nominal Schedule | Robust Sched. | Reduction [%] | |
| LPT | 30 | 24 | −20.0% | 26 | 21 | −19.2% |
| SPT | 32 | 27 | −15.6% | 25 | 21 | −16.0% |
| Sim. No. | Executed Schedule (Simulation) C′max [h] | Increase of Makespan and Relative Increase of Makespan | |||||
|---|---|---|---|---|---|---|---|
| Nominal Schedule | Robust Schedule | ||||||
| Cmax [h] | ΔCmax [h] | ECmax [–] | Cmax [h] | ΔCmax [h] | ECmax [–] | ||
| 1 | 52.15 | −5.22 | 0.90 | 0.99 | 1.02 | ||
| 2 | 49.75 | −2.82 | 0.94 | 3.39 | 1.07 | ||
| 3 | 50.93 | −4.00 | 0.92 | 2.21 | 1.04 | ||
| 4 | 57.57 | −10.64 | 0.82 | −4.43 | 0.92 | ||
| 5 | 52.79 | −5.86 | 0.89 | 0.35 | 1.01 | ||
| 6 | 52.62 | −5.69 | 0.89 | 0.52 | 1.01 | ||
| 7 | 50.01 | −3.08 | 0.94 | 3.13 | 1.06 | ||
| 8 | 55.23 | −8.30 | 0.85 | −2.09 | 0.96 | ||
| 9 | 50.69 | −3.76 | 0.93 | 2.45 | 1.05 | ||
| 10 | 53.73 | −6.80 | 0.87 | −0.59 | 0.99 | ||
| 11 | 50.62 | −3.69 | 0.93 | 2.52 | 1.05 | ||
| 12 | 49.26 | 46.93 | −2.33 | 0.95 | 53.14 | 3.88 | 1.08 |
| 13 | 51.98 | −5.05 | 0.90 | 1.16 | 1.02 | ||
| 14 | 51.73 | −4.80 | 0.91 | 1.41 | 1.03 | ||
| 15 | 50.20 | −3.27 | 0.93 | 2.94 | 1.06 | ||
| 16 | 52.17 | −5.24 | 0.90 | 0.97 | 1.02 | ||
| 17 | 50.71 | −3.78 | 0.93 | 2.43 | 1.05 | ||
| 18 | 51.01 | −4.08 | 0.92 | 2.13 | 1.04 | ||
| 19 | 50.61 | −3.68 | 0.93 | 2.53 | 1.05 | ||
| 20 | 50.65 | −3.72 | 0.93 | 2.49 | 1.05 | ||
| 21 | 49.95 | −3.02 | 0.94 | 3.19 | 1.06 | ||
| 22 | 50.22 | −3.29 | 0.93 | 2.92 | 1.06 | ||
| 23 | 51.83 | −4.90 | 0.91 | 1.31 | 1.03 | ||
| 24 | 52.21 | −5.28 | 0.90 | 0.93 | 1.02 | ||
| 25 | 50.79 | −3.86 | 0.92 | 2.35 | 1.05 | ||
| Sim. No. | Executed Schedule (Simulation) C′max [h] | Increase of Makespan and Relative Increase of Makespan | |||||
|---|---|---|---|---|---|---|---|
| Nominal Schedule | Nominal Schedule | ||||||
| Cmax [h] | ΔCmax [h] | ECmax [–] | Cmax [h] | ΔCmax [h] | ECmax [–] | ||
| 1 | 51.86 | −4.60 | 0.91 | 3.82 | 1.07 | ||
| 2 | 53.32 | −6.06 | 0.89 | 2.36 | 1.04 | ||
| 3 | 52.11 | −4.85 | 0.91 | 3.57 | 1.07 | ||
| 4 | 55.09 | −7.83 | 0.86 | 0.59 | 1.01 | ||
| 5 | 54.27 | −7.01 | 0.87 | 1.41 | 1.03 | ||
| 6 | 55.36 | −8.10 | 0.85 | 0.32 | 1.01 | ||
| 7 | 52.55 | −5.29 | 0.90 | 3.13 | 1.06 | ||
| 8 | 52.65 | −5.39 | 0.90 | 3.03 | 1.06 | ||
| 9 | 51.60 | −4.34 | 0.92 | 4.08 | 1.08 | ||
| 10 | 53.19 | −5.93 | 0.89 | 2.49 | 1.05 | ||
| 11 | 53.99 | −6.73 | 0.88 | 1.69 | 1.03 | ||
| 12 | 51.07 | 47.26 | −3.81 | 0.93 | 55.68 | 4.61 | 1.09 |
| 13 | 53.76 | −6.50 | 0.88 | 1.92 | 1.04 | ||
| 14 | 51.54 | −4.28 | 0.92 | 4.14 | 1.08 | ||
| 15 | 55.85 | −8.59 | 0.85 | −0.17 | 1.00 | ||
| 16 | 54.55 | −7.29 | 0.87 | 1.13 | 1.02 | ||
| 17 | 53.95 | −6.69 | 0.88 | 1.73 | 1.03 | ||
| 18 | 51.47 | −4.21 | 0.92 | 4.21 | 1.08 | ||
| 19 | 51.69 | −4.43 | 0.91 | 3.99 | 1.08 | ||
| 20 | 50.71 | −3.45 | 0.93 | 4.97 | 1.10 | ||
| 21 | 51.75 | −4.49 | 0.91 | 3.93 | 1.08 | ||
| 22 | 53.29 | −6.03 | 0.89 | 2.39 | 1.04 | ||
| 23 | 54.03 | −6.77 | 0.87 | 1.65 | 1.03 | ||
| 24 | 53.47 | −6.21 | 0.88 | 2.21 | 1.04 | ||
| 25 | 52.11 | −4.85 | 0.91 | 3.57 | 1.07 | ||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sobaszek, Ł.; Gola, A.; Kozłowski, E. Predictive Scheduling with Markov Chains and ARIMA Models. Appl. Sci. 2020, 10, 6121. https://doi.org/10.3390/app10176121
Sobaszek Ł, Gola A, Kozłowski E. Predictive Scheduling with Markov Chains and ARIMA Models. Applied Sciences. 2020; 10(17):6121. https://doi.org/10.3390/app10176121
Chicago/Turabian StyleSobaszek, Łukasz, Arkadiusz Gola, and Edward Kozłowski. 2020. "Predictive Scheduling with Markov Chains and ARIMA Models" Applied Sciences 10, no. 17: 6121. https://doi.org/10.3390/app10176121
APA StyleSobaszek, Ł., Gola, A., & Kozłowski, E. (2020). Predictive Scheduling with Markov Chains and ARIMA Models. Applied Sciences, 10(17), 6121. https://doi.org/10.3390/app10176121