Single-Shot Object Detection with Split and Combine Blocks


Abstract
:1. Introduction
2. Related Work
2.1. Two-Stage Object Detectors
2.2. One-Stage Object Detectors
2.3. Objects as Points
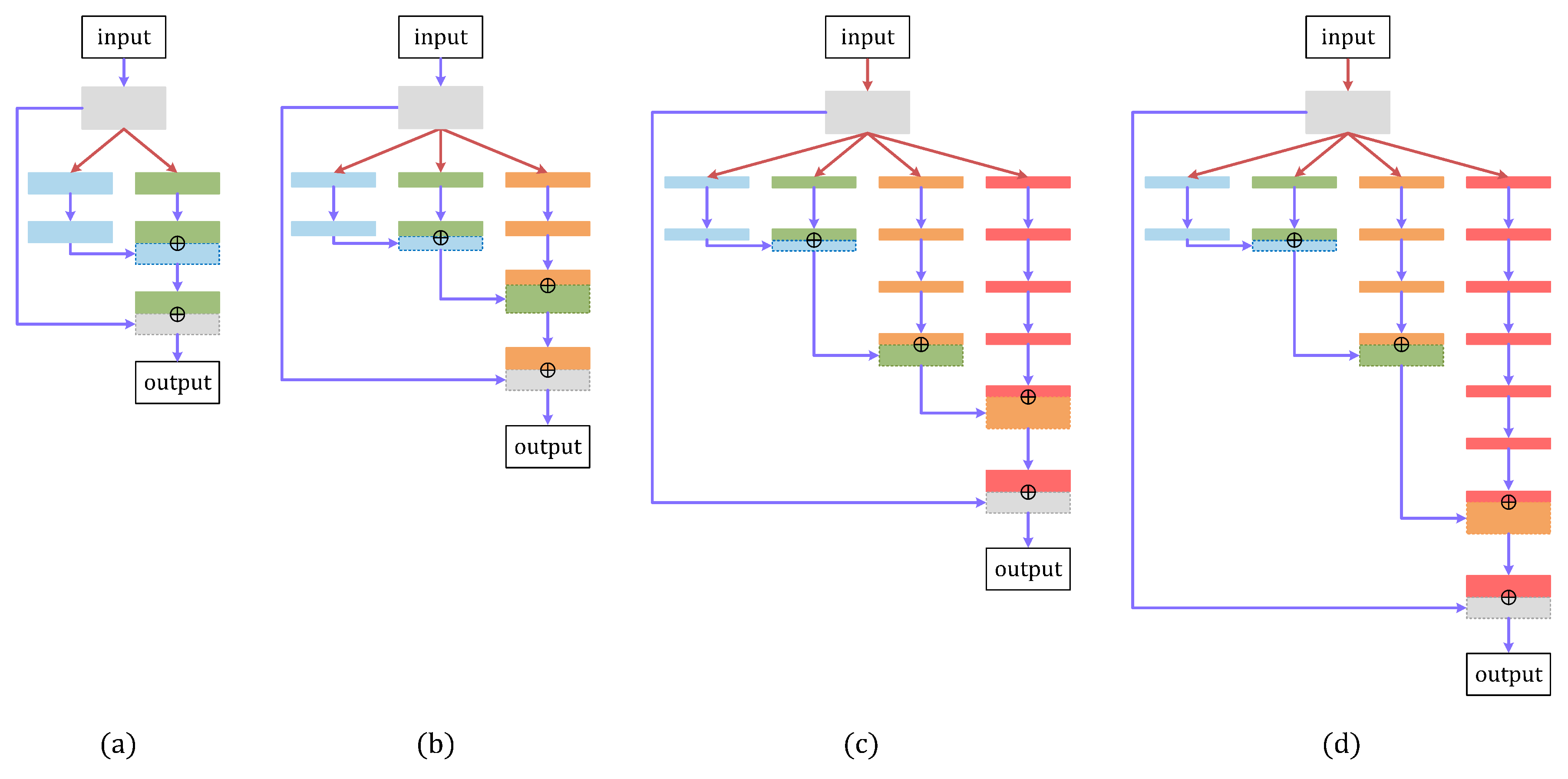
3. Method
3.1. Split and Combine Block
3.2. Backbone and FPN
3.3. Dense Predictions
3.4. Training and Testing
4. Experiments
4.1. Ablation Study
4.2. Visual Analysis
4.3. Comparison to Other Detectors
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.Y.; Mark Liao, H.Y.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Tan, M.; Le, Q.V. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Pleiss, G.; Van Der Maaten, L.; Weinberger, K. Convolutional networks with dense connectivity. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, F.; Wang, D.; Shelhamer, E.; Darrell, T. Deep layer aggregation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2403–2412. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In European Conference on Computer Vision; Springer: Amsterdam, The Netherlands, 2016; pp. 483–499. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9259–9266. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9308–9316. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Zurich, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Amsterdam, The Netherlands, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Li, B.; Liu, Y.; Wang, X. Gradient harmonized single-stage detector. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8577–8584. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Zhou, X.; Zhuo, J.; Krahenbuhl, P. Bottom-up object detection by grouping extreme and center points. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 850–859. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Wang, J.; Chen, K.; Yang, S.; Loy, C.C.; Lin, D. Region proposal by guided anchoring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 5–20 June 2019; pp. 2965–2974. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9759–9768. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 658–666. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhang, Z.; He, T.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of freebies for training object detection neural networks. arXiv 2019, arXiv:1902.04103. [Google Scholar]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of tricks for image classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 558–567. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Yao, Z.; Cao, Y.; Zheng, S.; Huang, G.; Lin, S. Cross-iteration batch normalization. arXiv 2020, arXiv:2002.05712. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic neural activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Dropblock: A regularization method for convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 10727–10737. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Baseline | SCNet | |||||||
|---|---|---|---|---|---|---|---|---|
| CmBN | √ | √ | √ | √ | √ | √ | √ | |
| Mish | √ | √ | √ | √ | √ | √ | ||
| Admix | √ | √ | √ | √ | √ | |||
| warmup+cosine | √ | √ | √ | √ | ||||
| multi-scale training | √ | √ | √ | |||||
| GA | √ | √ | ||||||
| DropBlock+SPP | √ | |||||||
| COCO val AP | 32.1 | 33.3 | 34.1 | 35.2 | 35.9 | 36.8 | 37.7 | 38.8 |
| FPS | 46 | 46 | 46 | 46 | 46 | 46 | 44 | 40 |
| Backbone | FPS | Input Size | AP | ||||||
|---|---|---|---|---|---|---|---|---|---|
| SCNet | SC-32 | 67.0 | 416 × 416 | 27.6 | 46.3 | 29.4 | 8.7 | 31.5 | 41.0 |
| SCNet | SC-32 | 65.8 | 608 × 608 | 29.3 | 48.0 | 33.3 | 10.3 | 32.5 | 42.8 |
| SCNet | SC-47 | 60.5 | 416 × 416 | 32.6 | 50.5 | 34.9 | 15.4 | 36.9 | 46.4 |
| SCNet | SC-47 | 54.7 | 608 × 608 | 34.7 | 52.8 | 37.4 | 16.9 | 39.3 | 48.4 |
| SCNet | SC-59 | 51.0 | 416 × 416 | 37.1 | 55.0 | 40.3 | 18.5 | 40.9 | 48.9 |
| SCNet | SC-59 | 40.0 | 608 × 608 | 38.8 | 56.7 | 42.5 | 19.6 | 42.7 | 51.0 |
| AP | ||||||
|---|---|---|---|---|---|---|
| control detector | 34.2 | 53.0 | 37.4 | 18.0 | 38.8 | 46.4 |
| SCNet | 38.8 | 56.7 | 42.5 | 19.6 | 42.7 | 51.0 |
| Backbone | FPS | Input Size | AP | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Two-stage detectors | |||||||||
| Faster R-CNN +++ | ResNet-101 | – | 1000 × 600 | 34.9 | 55.7 | 37.4 | 15.6 | 38.7 | 50.9 |
| Faster R-CNN w FPN | ResNet-101-FPN | – | 1000 × 600 | 36.2 | 59.1 | 39.0 | 18.2 | 39.0 | 48.2 |
| Mask R-CNN | ResNeXt-101 | 9.0 | 1333 × 800 | 39.8 | 62.3 | 43.4 | 22.1 | 43.2 | 51.2 |
| One-stage detectors | |||||||||
| SSD | VGG | 40.9 | 300 × 300 | 25.1 | 43.1 | 25.8 | – | – | – |
| SSD | VGG | 20.9 | 512 × 512 | 28.8 | 48.5 | 30.3 | – | – | – |
| YOLOv2 | DarkNet-19 | 40.0 | 544 × 544 | 21.6 | 44.0 | 19.2 | 5.0 | 22.4 | 35.5 |
| YOLOv3 | darknet-53 | 19.0 | 608 × 608 | 33.0 | 57.9 | 34.4 | 18.3 | 35.4 | 41.9 |
| RefineDet | VGG | 36.8 | 320 × 320 | 29.4 | 49.2 | 31.3 | 10.0 | 32.0 | 44.4 |
| RefineDet | VGG | 21.2 | 512 × 512 | 33.0 | 54.5 | 35.5 | 16.3 | 36.3 | 44.3 |
| CenterNet-DLA | DLA-34 | 26.9 | 512 × 512 | 39.2 | 57.1 | 42.8 | 19.9 | 43.0 | 51.4 |
| CenterNet-HG | Hourglass-104 | 7.4 | 512 × 512 | 42.1 | 61.1 | 45.9 | 24.1 | 45.5 | 52.8 |
| RetinaNet | ResNet-101-FPN | 5.0 | 800 × 800 | 39.1 | 59.1 | 42.3 | 21.8 | 42.7 | 50.2 |
| ATSS | ResNet-101 | 14.9 | 800 × 800 | 43.6 | 62.1 | 47.4 | 26.1 | 47.0 | 53.6 |
| ATSS | ResNet-101-DCN | 11.7 | 800 × 800 | 46.3 | 64.7 | 50.4 | 27.7 | 49.8 | 58.4 |
| SCNet(ours) | SC-59 | 51.0 | 416 × 416 | 37.1 | 54.9 | 40.4 | 18.5 | 40.9 | 48.9 |
| SCNet(ours) | SC-59 | 40.0 | 608 × 608 | 38.9 | 56.8 | 42.6 | 19.7 | 42.7 | 51.1 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Li, D.; Song, Y.; Gao, Q.; Wang, Z.; Liu, C. Single-Shot Object Detection with Split and Combine Blocks. Appl. Sci. 2020, 10, 6382. https://doi.org/10.3390/app10186382
Wang H, Li D, Song Y, Gao Q, Wang Z, Liu C. Single-Shot Object Detection with Split and Combine Blocks. Applied Sciences. 2020; 10(18):6382. https://doi.org/10.3390/app10186382
Chicago/Turabian StyleWang, Hongwei, Dahua Li, Yu Song, Qiang Gao, Zhaoyang Wang, and Chunping Liu. 2020. "Single-Shot Object Detection with Split and Combine Blocks" Applied Sciences 10, no. 18: 6382. https://doi.org/10.3390/app10186382
APA StyleWang, H., Li, D., Song, Y., Gao, Q., Wang, Z., & Liu, C. (2020). Single-Shot Object Detection with Split and Combine Blocks. Applied Sciences, 10(18), 6382. https://doi.org/10.3390/app10186382