Data Enhancement for Plant Disease Classification Using Generated Lesions


Abstract
:1. Introduction
- (i)
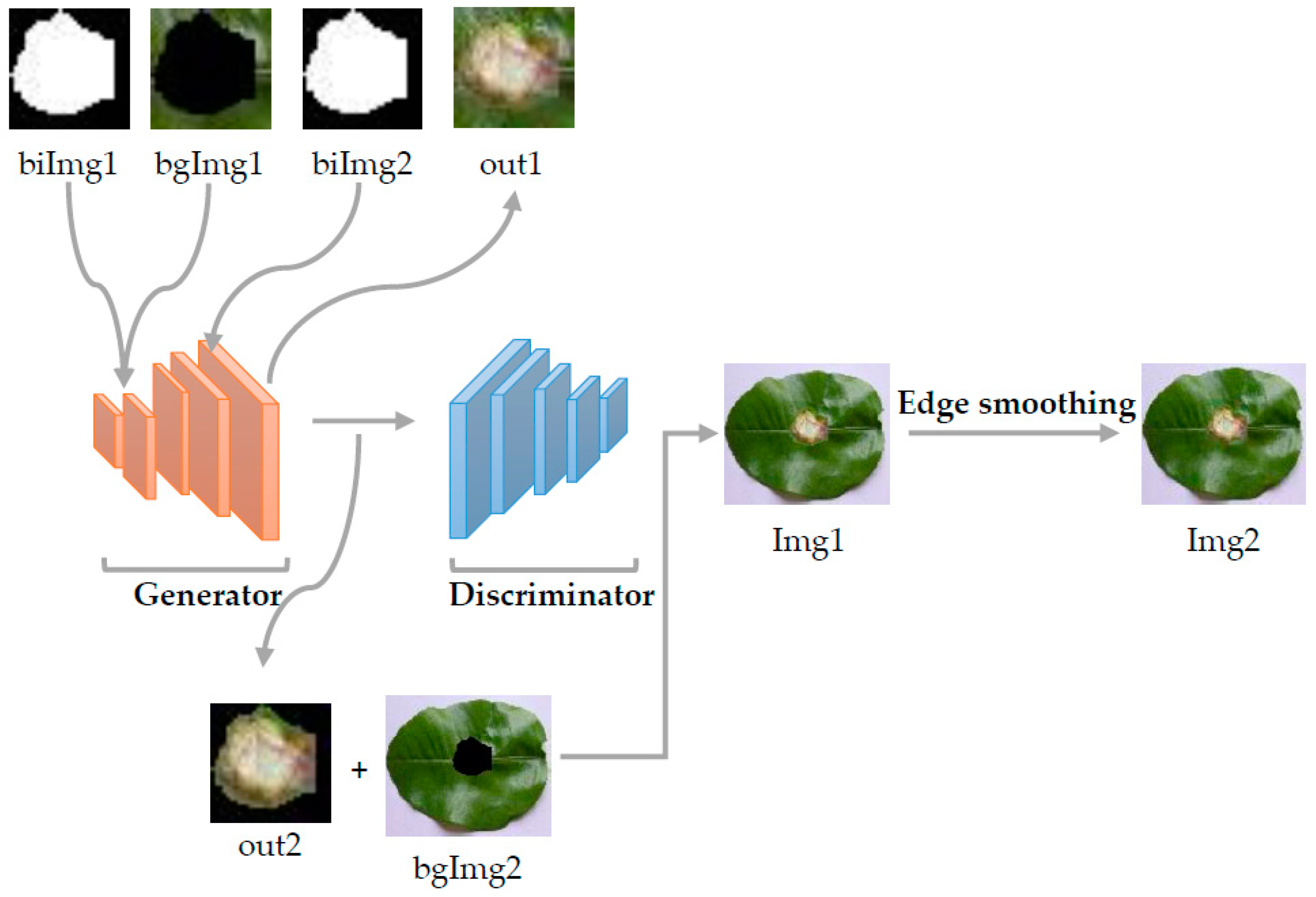
- We first input the binarized image and cropped lesion images into a GAN to generate plant lesions with a specific shape. Meanwhile, we also introduced the dropout layer of the network [6] to solve the problem of image overfitting and improve the training speed.
- (ii)
2. Related Work
3. Methods
3.1. Network Architecture
3.2. ES-BGNet
3.3. Image Marker Layer
3.4. Image Edge Weighted Smoothing
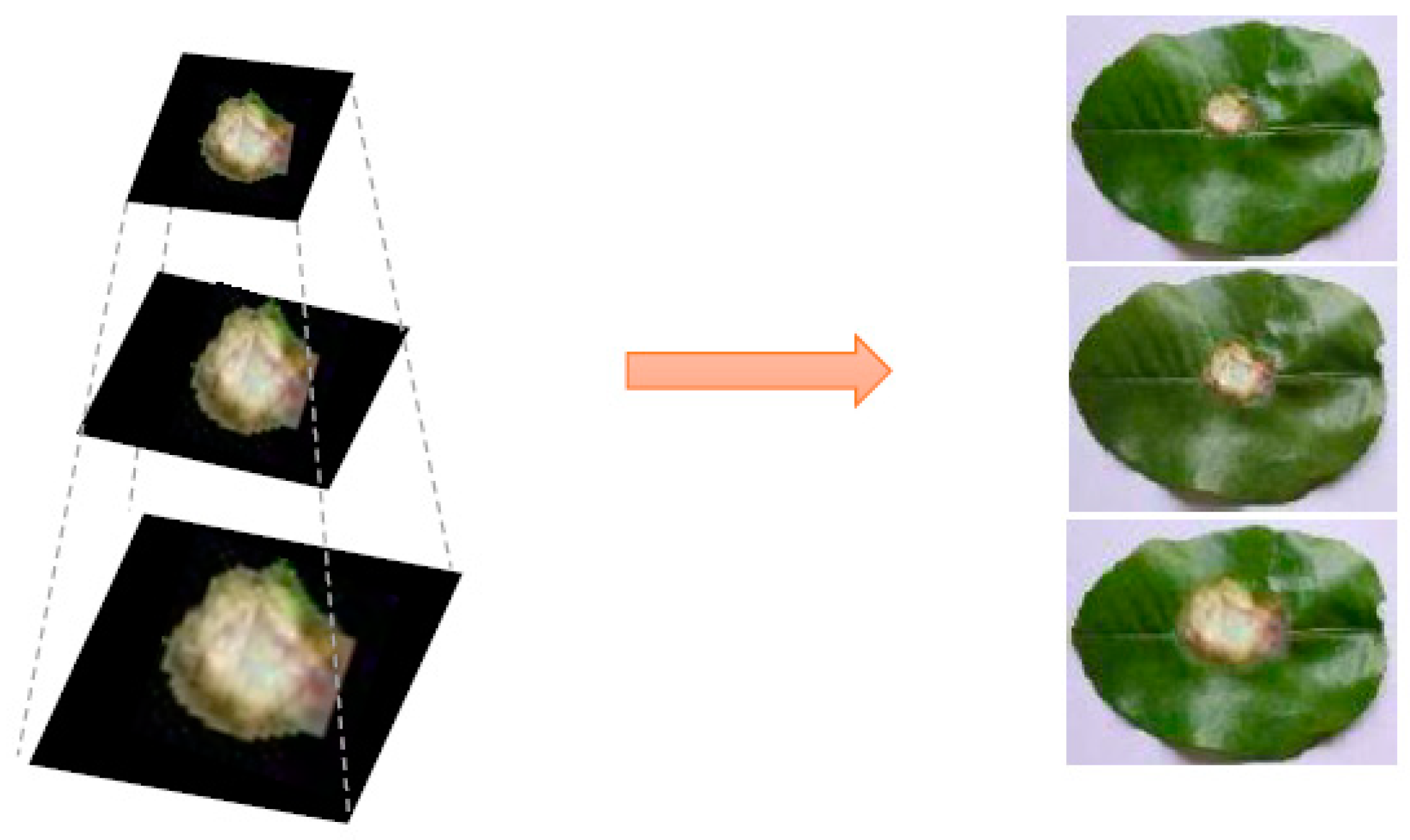
3.5. Bilinear Interpolation Image Pyramid
4. Experiments
4.1. Dataset
4.2. The Generated Image from ES-BGNet
4.3. Quality Assessment of Generated Images
4.4. Compare Accuracy to Determine Whether to Use Synthetic Data in AlexNet
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Network | Average IS | Average FID |
|---|---|---|---|
| Citrus canker | DCGAN | 2.79 ± 0.11 | 124.29 ± 1.41 |
| WGAN-GP | 2.93 ± 0.19 | 118.03 ± 0.61 | |
| Self-Supervised GAN | 2.88 ± 0.22 | 121.93 ± 1.87 | |
| Improved Self-supervised GAN | 2.96 ± 0.15 | 116.12 ± 0.99 |
| Data Type | Average Accuracy |
|---|---|
| No leaf information | 0.721 ± 0.039 |
| Has leaf information | 0.982 ± 0.005 |
| DataSet | Algorithm Type | Average Accuracy |
|---|---|---|
| SVM | 0.917 ± 0.011 | |
| Citrus canker | KNN | 0.922 ± 0.010 |
| AlexNet | 0.955 ± 0.003 |
| Algorithm Type | Average IS | Average FID |
|---|---|---|
| ISODATA | 5.62 ± 0.08 | 33.89 ± 1.80 |
| Histogram-based threshold | 6.01 ± 0.14 | 25.35 ± 1.72 |
| Image filtering and histograms | 5.94 ± 0.15 | 27.66 ± 1.56 |
| Algorithm Type | ISODATA | Histogram-Based Threshold | Image Filtering and Histograms |
|---|---|---|---|
| ISODATA | 1 | −0.42 | −0.57 |
| Histogram-based threshold | −0.42 | 1 | −0.51 |
| Image filtering and histograms | −0.57 | −0.51 | 1 |
| Algorithm Type | ISODATA | Histogram-Based Threshold | Image Filtering and Histograms |
|---|---|---|---|
| ISODATA | 1 | −0.33 | −0.48 |
| Histogram-based threshold | −0.33 | 1 | −0.44 |
| Image filtering and histograms | −0.48 | −0.44 | 1 |
| Algorithm Type | Average IS | Average FID |
|---|---|---|
| Mean and median filtering | 6.12 ± 0.08 | 20.02 ± 1.04 |
| Gaussian filtering | 5.45 ± 0.14 | 37.35 ± 1.71 |
| Gradient-based image filtering | 5.99 ± 0.15 | 23.73 ± 1.36 |
| Algorithm Type | Mean and Median Filtering | Gaussian Filtering | Gradient-Based Image Filtering |
|---|---|---|---|
| Mean and median filtering | 1 | −0.65 | −0.40 |
| Gaussian filtering | −0.65 | 1 | −0.42 |
| Gradient-based image filtering | −0.40 | −0.42 | 1 |
| Algorithm Type | Mean and Median Filtering | Gaussian Filtering | Gradient-Based Image Filtering |
|---|---|---|---|
| Mean and median filtering | 1 | −0.46 | −0.51 |
| Gaussian filtering | −0.46 | 1 | −0.62 |
| Gradient-based image filtering | −0.51 | −0.62 | 1 |
| Average IS | Average FID | |
|---|---|---|
| 0.1 | 5.89 ± 0.12 | 26.35 ± 1.33 |
| 0.2 | 6.12 ± 0.08 | 20.02 ± 1.04 |
| 0.3 | 5.92 ± 0.16 | 25.71 ± 2.51 |
| 0.19 | 6.09 ± 0.10 | 20.88 ± 1.33 |
| 0.21 | 6.11 ± 0.08 | 20.25 ± 1.16 |
| λ | 0.1 | 0.2 | 0.3 | 0.19 | 0.21 |
|---|---|---|---|---|---|
| 0.1 | 1 | −0.52 | −0.57 | −0.39 | −0.66 |
| 0.2 | −0.52 | 1 | −0.51 | −0.23 | −0.41 |
| 0.3 | −0.57 | −0.51 | 1 | −0.75 | −0.53 |
| 0.19 | −0.39 | −0.23 | −0.75 | 1 | −0.47 |
| 0.21 | −0.66 | −0.41 | −0.53 | −0.47 | 1 |
| λ | 0.1 | 0.2 | 0.3 | 0.19 | 0.21 |
|---|---|---|---|---|---|
| 0.1 | 1 | −0.37 | −0.56 | −0.72 | −0.48 |
| 0.2 | −0.37 | 1 | −0.48 | −0.21 | −0.41 |
| 0.3 | −0.56 | −0.48 | 1 | −0.41 | −0.29 |
| 0.19 | −0.72 | −0.21 | −0.41 | 1 | −0.50 |
| 0.21 | −0.48 | −0.41 | −0.29 | −0.50 | 1 |
| Method Type | Average IS | Average FID |
|---|---|---|
| Bilinear interpolation | 6.12 ± 0.08 | 20.02 ± 1.04 |
| Nearest-neighbor interpolation | 6.09 ± 0.07 | 22.52 ± 1.22 |
| Bicubic interpolation | 6.01 ± 0.11 | 27.32 ± 1.61 |
| Algorithm Type | Mean and Median Filtering | Gaussian Filtering | Gradient-Based Image Filtering |
|---|---|---|---|
| Bilinear interpolation | 1 | −0.51 | −0.60 |
| Nearest-neighbor interpolation | −0.51 | 1 | −0.38 |
| Bicubic interpolation | −0.60 | −0.38 | 1 |
| Algorithm Type | Mean and Median Filtering | Gaussian Filtering | Gradient-Based Image Filtering |
|---|---|---|---|
| Bilinear interpolation | 1 | −0.38 | −0.61 |
| Nearest-neighbor Interpolation | −0.38 | 1 | −0.37 |
| Bicubic interpolation | −0.61 | −0.37 | 1 |
References
- Weizheng, S.; Yachun, W.; Zhanliang, C.; Hongda, W. Grading method of leaf spot disease based on image processing. In Proceedings of the 2008 IEEE International Conference on Computer Science and Software Engineering, Wuhan, China, 12–14 December 2008; Volume 6, pp. 491–494. [Google Scholar]
- Das, A.K. Citrus canker—A review. J. Appl. Hortic. 2003, 5, 52–60. [Google Scholar]
- Butler, D. Fungus threatens top banana. Nat. News 2013, 504, 195. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Chuang, M.F.; Ni, H.F.; Yang, H.R.; Shu, S.L.; Lai, S.Y.; Jiang, Y.L. First report of stem canker disease of pitaya (Hylocereus undatus and H. polyrhizus) caused by Neoscytalidium dimidiatum in Taiwan. Plant Dis. 2012, 96, 906. [Google Scholar] [CrossRef] [PubMed]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Adelson, E.H.; Anderson, C.H.; Bergen, J.R.; Burt, P.J.; Ogden, M.J. Pyramid methods in image processing. RCA Eng. 1984, 29, 33–41. [Google Scholar]
- Bunker, W.M.; Merz, D.M.; Fadden, R.G. Method of Edge Smoothing for a Computer Image Generation System. U.S. Patent 4,811,245, 7 March 1989. [Google Scholar]
- Zhang, M.; Meng, Q. Automatic citrus canker detection from leaf images captured in field. Pattern Recognit. Lett. 2011, 32, 2036–2046. [Google Scholar] [CrossRef] [Green Version]
- Zhongliang, H.; Zhengjun, Q. Rape lesion feature parameter extraction based on image processing. In Proceedings of the 2011 IEEE International Conference on New Technology of Agricultural, Zibo, China, 27–29 May 2011; pp. 1–4. [Google Scholar]
- Al-Tarawneh, M.S. An empirical investigation of olive leave spot disease using auto-cropping segmentation and fuzzy C-means classification. World Appl. Sci. J. 2013, 23, 1207–1211. [Google Scholar]
- Sunny, S.; Gandhi, M.P.I. An efficient citrus canker detection method based on contrast limited adaptive histogram equalization enhancement. Int. J. Appl. Eng. Res. 2018, 13, 809–815. [Google Scholar]
- Singh, K.; Kumar, S.; Kaur, P. Support vector machine classifier based detection of fungal rust disease in Pea Plant (Pisam sativam). Int. J. Inf. Technol. 2019, 11, 485–492. [Google Scholar] [CrossRef]
- Reyes, A.K.; Caicedo, J.C.; Camargo, J.E. Fine-tuning Deep Convolutional Networks for Plant Recognition. CLEF (Work. Notes) 2015, 1391, 1391. [Google Scholar]
- Tan, W.; Zhao, C.; Wu, H. Intelligent alerting for fruit-melon lesion image based on momentum deep learning. Multimed. Tools Appl. 2016, 75, 16741–16761. [Google Scholar] [CrossRef]
- Sladojevic, S.; Arsenovic, M.; Anderla, A.; Culibrk, D.; Stefanovic, D. Deep neural networks based recognition of plant diseases by leaf image classification. Comput. Intell. Neurosci. 2016, 2016, 3289801. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Toda, Y.; Okura, F. How Convolutional Neural Networks Diagnose Plant Disease. Plant Phenomics 2019, 2019, 9237136. [Google Scholar] [CrossRef]
- Bera, T.; Das, A.; Sil, J.; Das, A.K. A Survey on Rice Plant Disease Identification Using Image Processing and Data Mining Techniques. In Emerging Technologies in Data Mining and Information Security; Springer: Singapore, 2019; pp. 365–376. [Google Scholar]
- Minaee, S.; Abdolrashidi, A.; Su, H.; Bennamoun, M.; Zhang, D. Biometric Recognition Using Deep Learning: A Survey. arXiv 2019, arXiv:1912.00271. [Google Scholar]
- Brahimi, M.; Mahmoudi, S.; Boukhalfa, K.; Moussaoui, A. Deep interpretable architecture for plant diseases classification. arXiv 2019, arXiv:1905.13523. [Google Scholar]
- Francis, M.; Deisy, C. Disease Detection and Classification in Agricultural Plants Using Convolutional Neural Networks—A Visual Understanding. In Proceedings of the IEEE 2019 6th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 7–8 March 2019; pp. 1063–1068. [Google Scholar]
- Nestsiarenia, I. Disease Detection on the Plant Leaves by Deep Learning. In Proceedings of the Advances in Neural Computation, Machine Learning, and Cognitive Research II: Selected Papers from the XX International Conference on Neuroinformatics, Moscow, Russia, 8–12 October 2018; Springer: Moscow, Russia, 2019; Volume 799, p. 151. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein Gan. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5767–5777. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.K.; Wang, Z.; Smolley, S.P. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of Gans for Improved Quality, Stability, and Variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Burt, P.; Adelson, E. The Laplacian pyramid as a compact image code. IEEE Trans. Commun. 1983, 31, 532–540. [Google Scholar] [CrossRef]
- Valerio Giuffrida, M.; Scharr, H.; Tsaftaris, S.A. ARIGAN: Synthetic Arabidopsis plants using generative adversarial network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2064–2071. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. Unlabeled samples generated by gan improve the person re-identification baseline in vitro. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3754–3762. [Google Scholar]
- Miyato, T.; Koyama, M. cGANs with Projection Discriminator. arXiv 2018, arXiv:1802.05637. [Google Scholar]
- Wu, E.; Wu, K.; Cox, D.; Lotter, W. Conditional infilling GANs for data augmentation in mammogram classification. In Image Analysis for Moving Organ, Breast, and Thoracic Images; Springer: Cham, Switzerland, 2018; pp. 98–106. [Google Scholar]
- Zhu, Y.; Aoun, M.; Krijn, M.; Vanschoren, J. Data Augmentation using Conditional Generative Adversarial Networks for Leaf Counting in Arabidopsis Plants. In Proceedings of the British Machine Vision Conference: Workshop on Computer Vision Problems in Plant Phenotyping, Newcastle, UK, 3–6 September 2018; p. 324. [Google Scholar]
- Purbaya, M.E.; Setiawan, N.A.; Adji, T.B. Leaves image synthesis using generative adversarial networks with regularization improvement. In Proceedings of the 2018 IEEE International Conference on Information and Communications Technology (ICOIACT), Yogyakarta, Indonesia, 6–7 March 2018; pp. 360–365. [Google Scholar]
- Ward, D.; Moghadam, P.; Hudson, N. Deep leaf segmentation using synthetic data. arXiv 2018, arXiv:1807.10931. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.N.; Odena, A. Self-Attention Generative Adversarial Networks. Machine Learning. arXiv 2018, arXiv:1805.08318. [Google Scholar]
- Dong, H.W.; Yang, Y.H. Training Generative Adversarial Networks with Binary Neurons by End-to-end Backpropagation. arXiv 2018, arXiv:1810.04714. [Google Scholar]
- Song, J.; He, T.; Gao, L.; Xu, X.; Hanjalic, A.; Shen, H.T. Binary generative adversarial networks for image retrieval. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Chen, X.; Xu, C.; Yang, X.; Tao, D. Attention-GAN for object transfiguration in wild images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 164–180. [Google Scholar]
- Minaee, S.; Abdolrashidi, A. Deep-Emotion: Facial Expression Recognition Using Attentional Convolutional Network. Computer Vision and Pattern Recognition. arXiv 2019, arXiv:1902.01019. [Google Scholar]
- Sapoukhina, N.; Samiei, S.; Rasti, P.; Rousseau, D. Data Augmentation from RGB to Chlorophyll Fluorescence Imaging Application to Leaf Segmentation of Arabidopsis thaliana From Top View Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Kuznichov, D.; Zvirin, A.; Honen, Y.; Kimmel, R. Data Augmentation for Leaf Segmentation and Counting Tasks in Rosette Plants. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13 September 2019. [Google Scholar]
- Zhang, M.; Liu, S.; Yang, F.; Liu, J. Classification of Canker on Small Datasets Using Improved Deep Convolutional Generative Adversarial Networks. IEEE Access 2019, 7, 49680–49690. [Google Scholar] [CrossRef]
- Lucic, M.; Tschannen, M.; Ritter, M.; Zhai, X.; Bachem, O.; Gelly, S. High-fidelity image generation with fewer labels. arXiv 2019, arXiv:1903.02271. [Google Scholar]
- Chen, T.; Zhai, X.; Ritter, M.; Lucic, M.; Houlsaby, N. Self-Supervised GANs via Auxiliary Rotation Loss. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–21 June 2019; pp. 12154–12163. [Google Scholar]
- Tran, N.T.; Tran, V.H.; Nguyen, N.B.; Cheung, N.M. An Improved Self-supervised GAN via Adversarial Training. arXiv 2019, arXiv:1905.05469. [Google Scholar]
- Lin, C.H.; Chang, C.C.; Chen, Y.S.; Juan, D.C.; Wei, W.; Chen, H.T. COCO-GAN: Generation by Parts via Conditional Coordinating. arXiv 2019, arXiv:1904.00284. [Google Scholar]
- Takano, N.; Alaghband, G. SRGAN: Training Dataset Matters. arXiv 2019, arXiv:1903.09922. [Google Scholar]
- Zhang, D.; Khoreva, A. PA-GAN: Improving GAN Training by Progressive Augmentation. arXiv 2019, arXiv:1901.10422. [Google Scholar]
- Lucic, M.; Kurach, K.; Michalski, M.; Gelly, S.; Bousquet, O. Are gans created equal? A large-scale study. In Proceedings of the Advances in neural information processing systems, Montréal, QC, Canada, 3–8 December 2018; pp. 700–709. [Google Scholar]
- Ridler, T.W.; Calvard, S. Picture thresholding using an iterative selection method. IEEE Trans. Syst. Man Cybern. 1978, 8, 630–632. [Google Scholar]
- Glasbey, C.A. An analysis of histogram-based thresholding algorithms. CVGIP Graph. Models Image Process. 1993, 55, 532–537. [Google Scholar] [CrossRef]
- Mohan, V.M.; Durga, R.K.; Devathi, S.; Raju, S.K. Image processing representation using binary image; grayscale, color image, and histogram. In Proceedings of the Second International Conference on Computer and Communication Technologies, Hyderabad, India, 24–26 July 2015; Springer: New Delhi, India, 2016; pp. 353–361. [Google Scholar]
- Schroeder, J.; Chitre, M. Adaptive mean/median filtering. In Proceedings of the IEEE Conference Record of the Thirtieth Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 3–6 November 1996; Volume 1, pp. 13–16. [Google Scholar]
- Law, T.; Itoh, H.; Seki, H. Image filtering, edge detection, and edge tracing using fuzzy reasoning. IEEE Trans. Pattern Anal. Mach. Intell. 1996, 18, 481–491. [Google Scholar] [CrossRef]
- Kou, F.; Chen, W.; Wen, C.; Li, Z. Gradient domain guided image filtering. IEEE Trans. Image Process. 2015, 24, 4528–4539. [Google Scholar] [CrossRef]
- Späth, H. Two Dimensional Spline Interpolation Algorithms; AK Peters: Wellesley, MA, USA, 1995. [Google Scholar]
- Olivier, R.; Hanqiang, C. Nearest neighbor value interpolation. arXiv 2012, arXiv:1211.1768. [Google Scholar] [CrossRef] [Green Version]
- Carlson, R.E.; Fritsch, F.N. An algorithm for monotone piecewise bicubic interpolation. SIAM J. Numer. Anal. 1989, 26, 230–238. [Google Scholar] [CrossRef]








| Method | Precision | Recall | F1 Score | Accuracy |
|---|---|---|---|---|
| Human Experts Classifier | 0.472 ± 0.091 | 0.380 ± 0.094 | 0.421 ± 0.088 | 0.593 ± 0.129 |
| 0.677 ± 0.054 | 0.666 ± 0.068 | 0.671 ± 0.080 | 0.701 ± 0.050 |
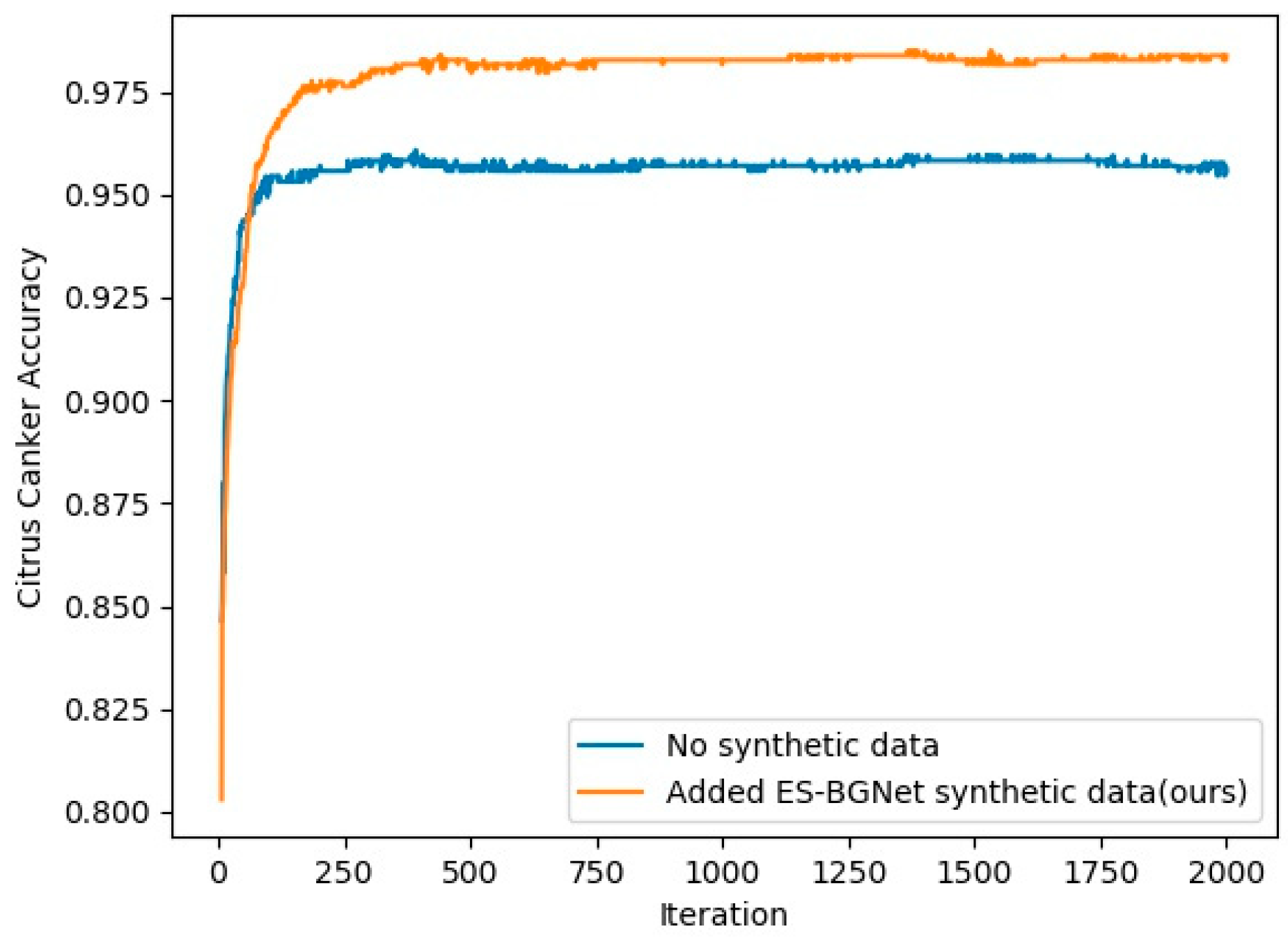
| Dataset | Network | Average Accuracy |
|---|---|---|
| Citrus canker | No synthetic data | 0.955 ± 0.003 |
| Added ES-BGNet synthetic data (ours) | 0.978 ± 0.007 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, R.; Zhang, M.; Yang, K.; Liu, J. Data Enhancement for Plant Disease Classification Using Generated Lesions. Appl. Sci. 2020, 10, 466. https://doi.org/10.3390/app10020466
Sun R, Zhang M, Yang K, Liu J. Data Enhancement for Plant Disease Classification Using Generated Lesions. Applied Sciences. 2020; 10(2):466. https://doi.org/10.3390/app10020466
Chicago/Turabian StyleSun, Rongcheng, Min Zhang, Kun Yang, and Ji Liu. 2020. "Data Enhancement for Plant Disease Classification Using Generated Lesions" Applied Sciences 10, no. 2: 466. https://doi.org/10.3390/app10020466
APA StyleSun, R., Zhang, M., Yang, K., & Liu, J. (2020). Data Enhancement for Plant Disease Classification Using Generated Lesions. Applied Sciences, 10(2), 466. https://doi.org/10.3390/app10020466