VES: A Mixed-Reality System to Assist Multisensory Spatial Perception and Cognition for Blind and Visually Impaired People



Abstract
:Featured Application
Abstract

1. Introduction
2. Related Work
3. Materials and Methods
3.1. The Virtually Enhanced Senses System
3.1.1. User Requirements
- “The presence, location, and preferably the nature of obstacles immediately ahead of the traveler.” This relates to obstacle avoidance support;
- Data on the “path or surface on which the traveler is walking, such as texture, gradient, upcoming steps,” etc.;
- “The position and nature of objects to the sides of the travel path,” i.e., hedges, fences, doorways, etc.;
- Information that helps users to “maintain a straight course, notably the presence of some type of aiming point in the distance,” e.g., distant traffic sounds;
- “Landmark location and identification,” including those previously seen, particularly in (3);
- Information that “allows the traveler to build up a mental map, image, or schema for the chosen route to be followed.” (see “Cognitive Mapping” in [29]).
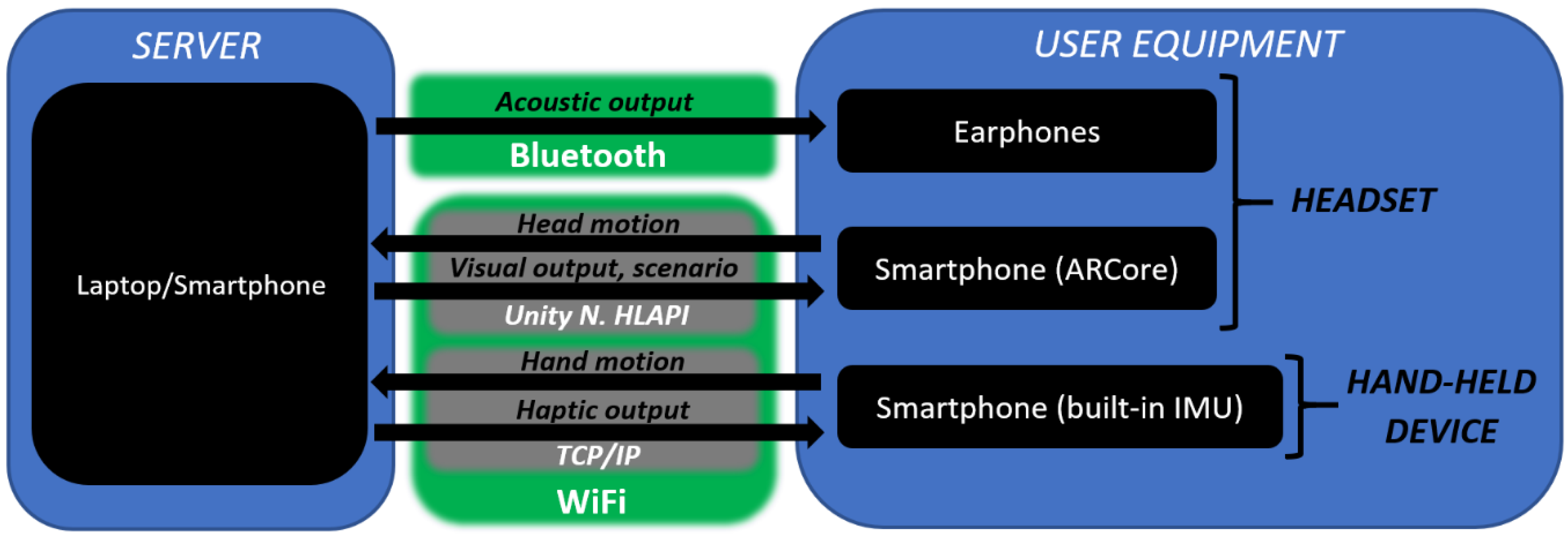
3.1.2. System Architecture
- Geometry-based Virtual Acoustic Space (GbVAS): This includes three novel main modes of stimulation based on the Virtual Acoustic Space project, and a speech synthesis module. It provides information concerning points 1, 3, 5 and 6 of Section 3.1.1. Further details will be described in the next sub-section;
- Acoustic Compass: This provides the user with a fixed orientation cue through spatialized audio. Therefore, it directly addresses point 4;
- Wall-tracking assistance: This novel mode, which was specifically requested by the end users, is meant to help them move parallel to a wall (points 3, 4). Once the user distances from a reference wall, a haptic warning will be triggered in the hand-held device, and a virtual sound source will be spawned in the closest point of the closest wall. The position of this sound source will be periodically updated according to the user’s movement. When the user reaches a threshold distance, the virtual sound source will be turned off.
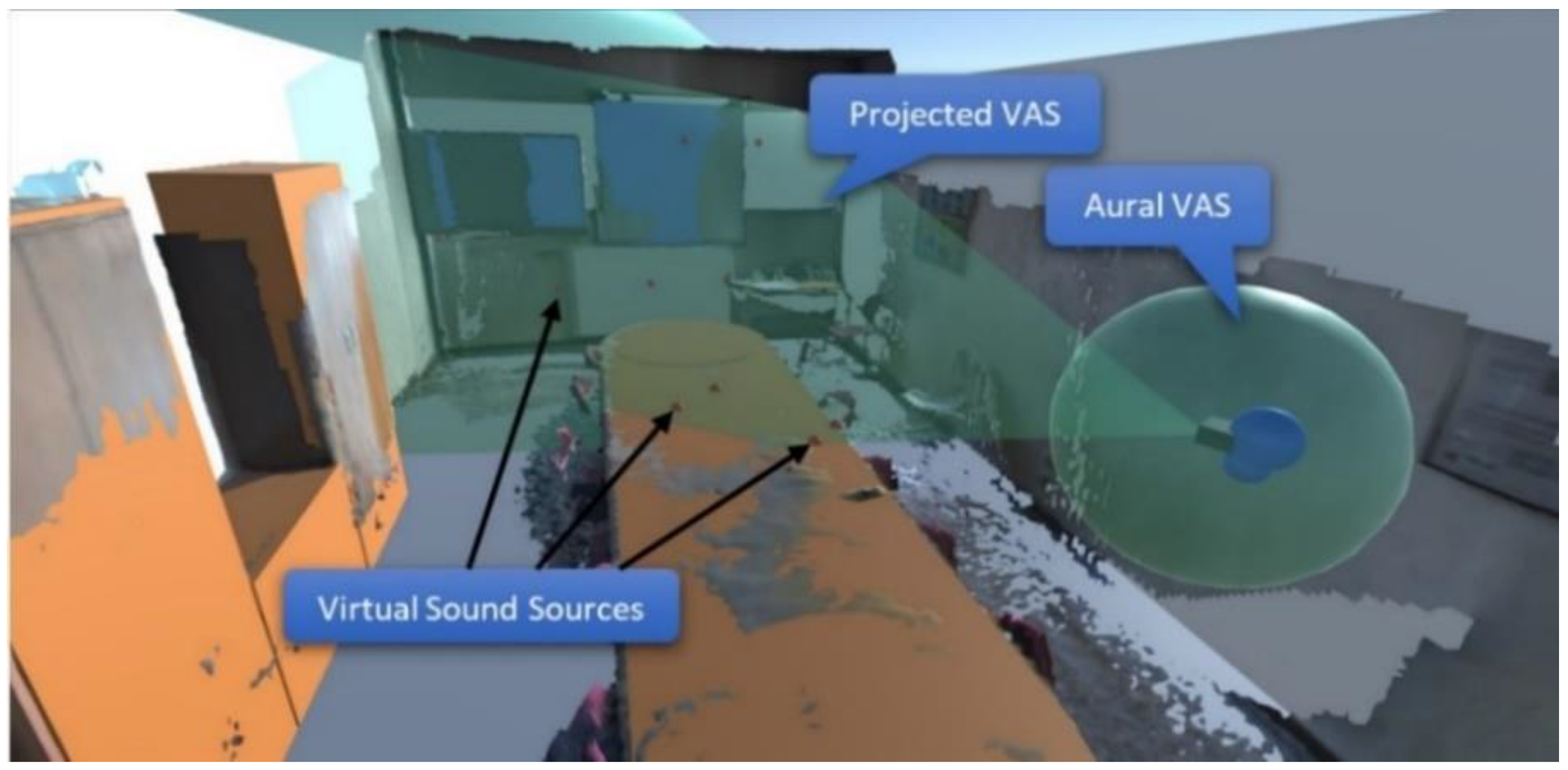
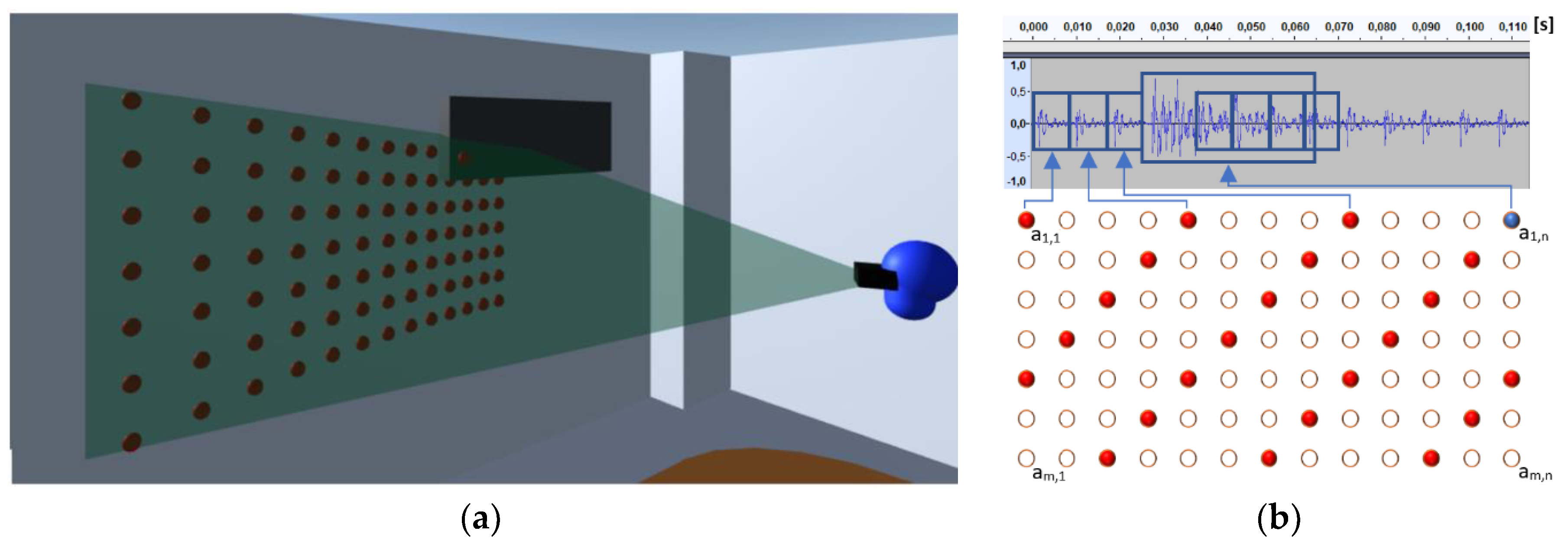
3.1.3. Geometry-Based Virtual Acoustic Space
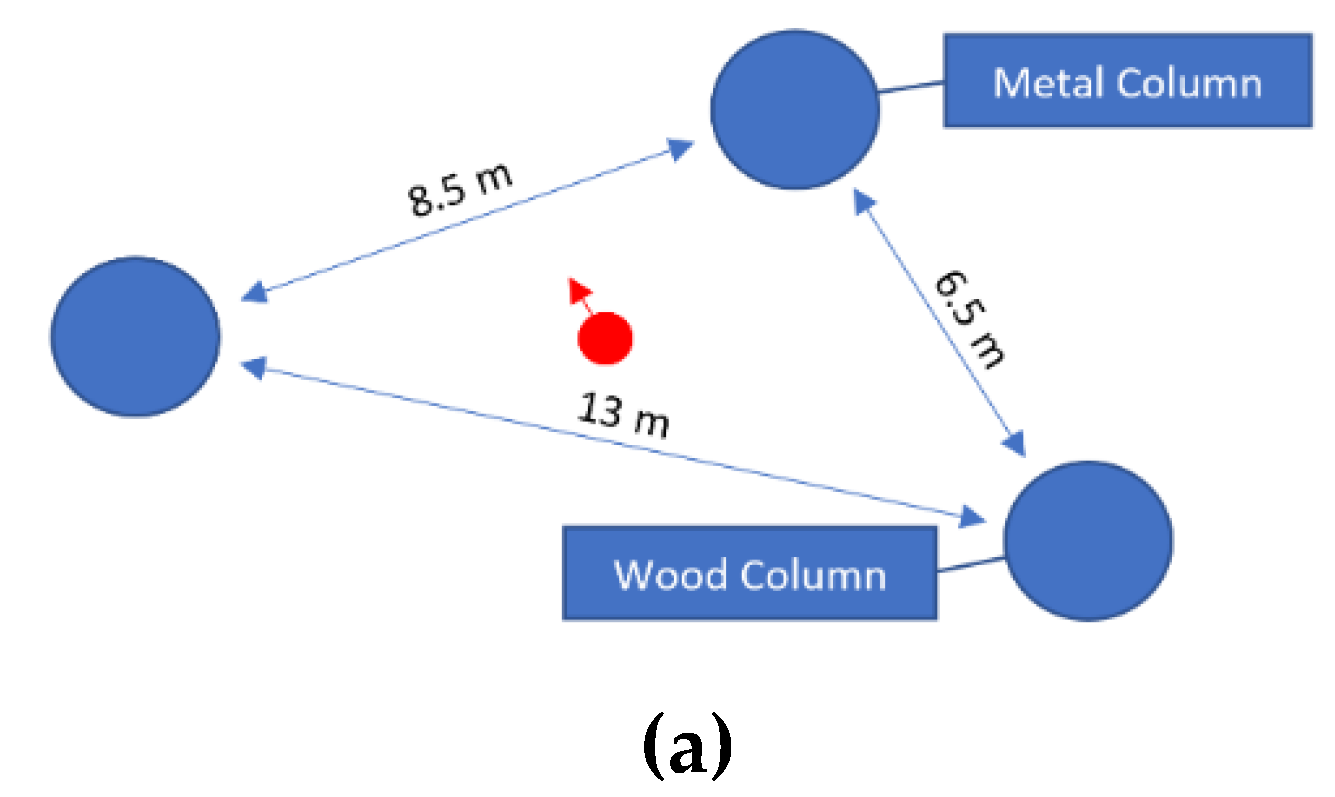
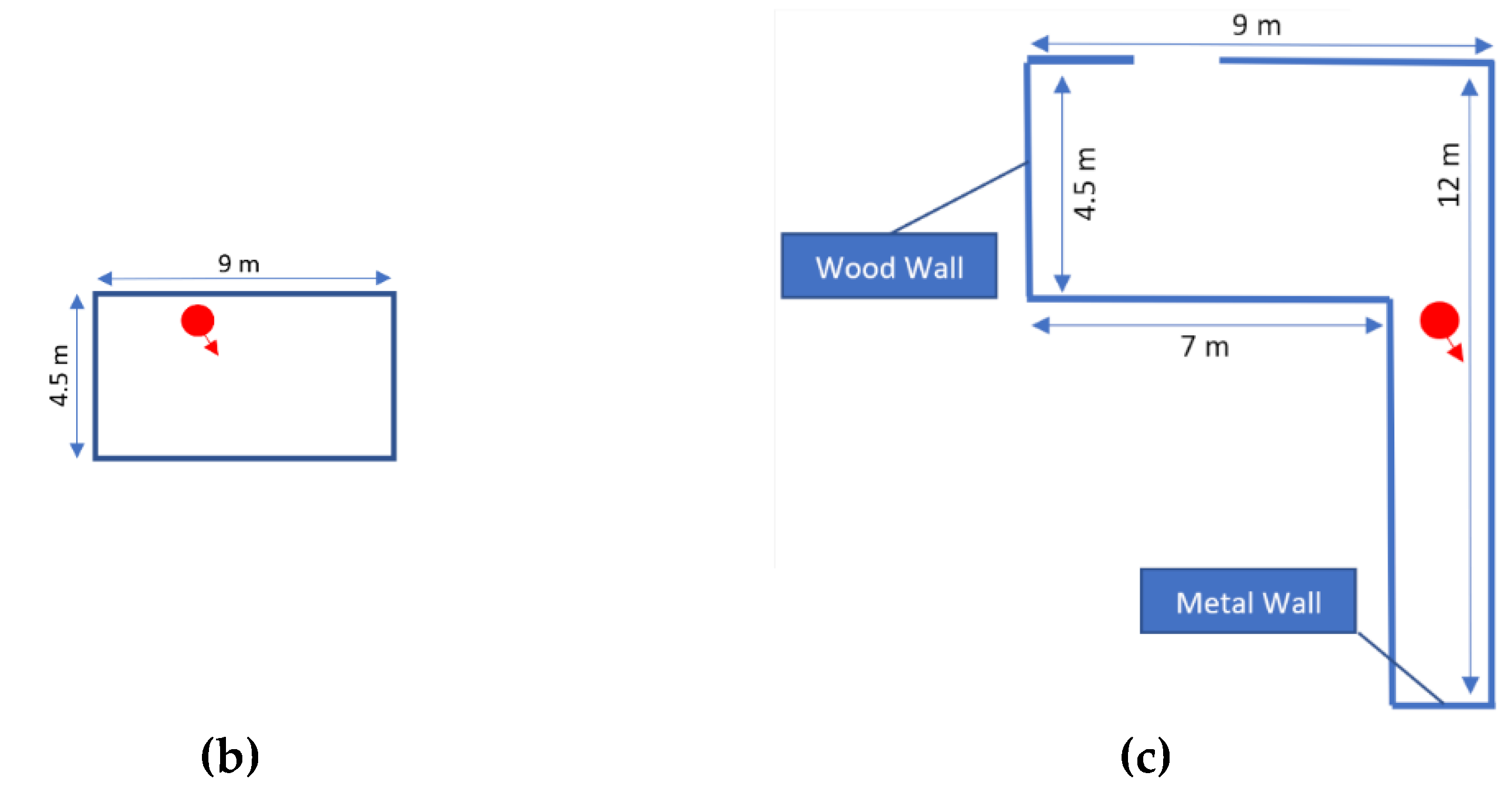
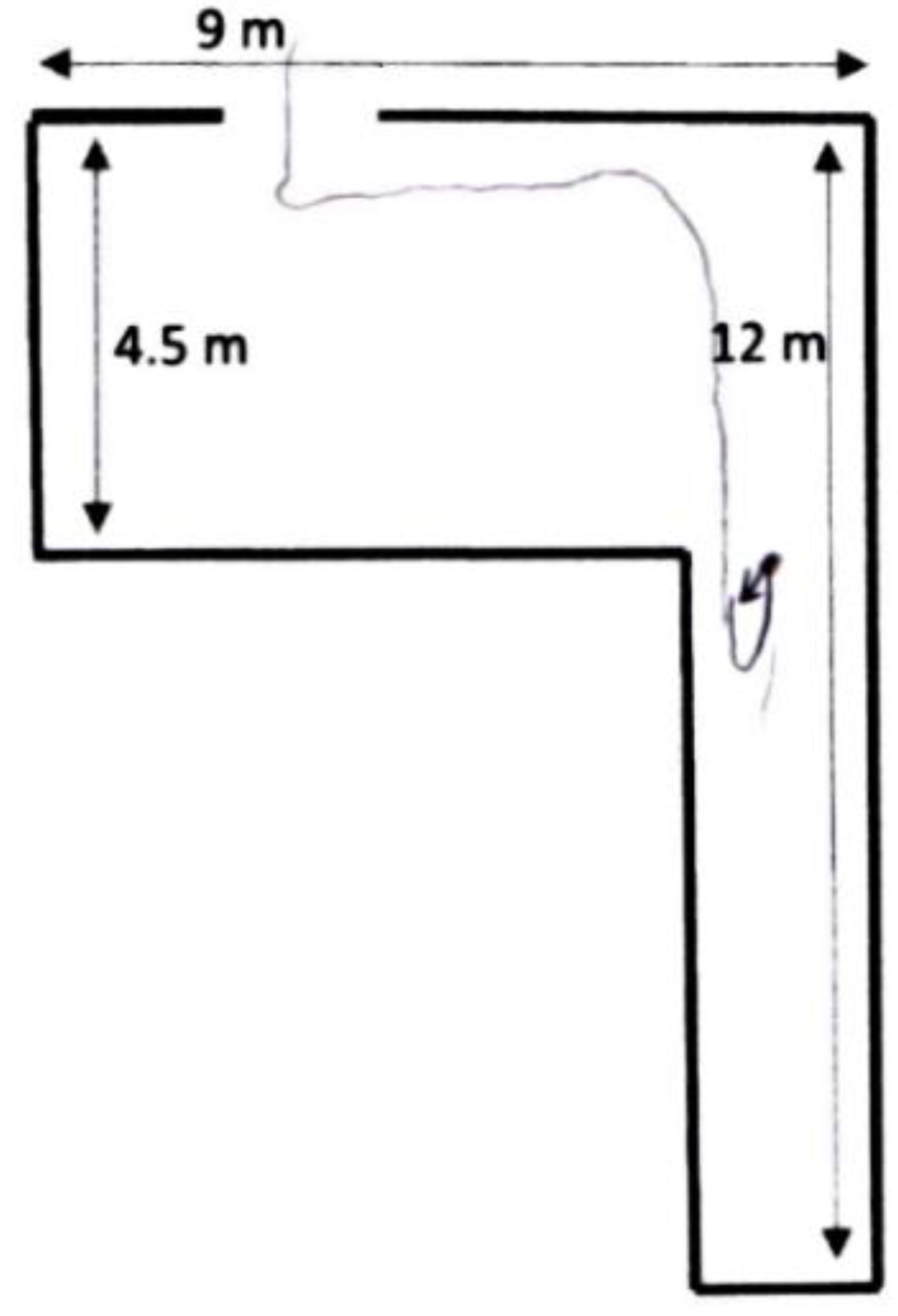
3.2. Experimental Procedures
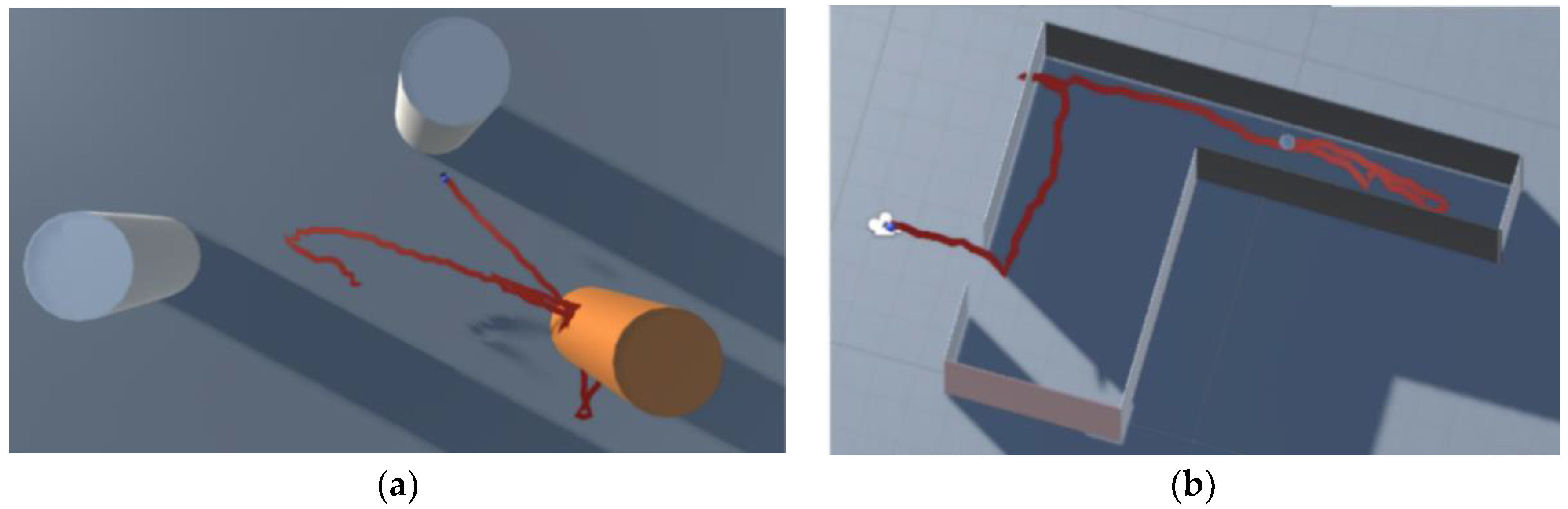
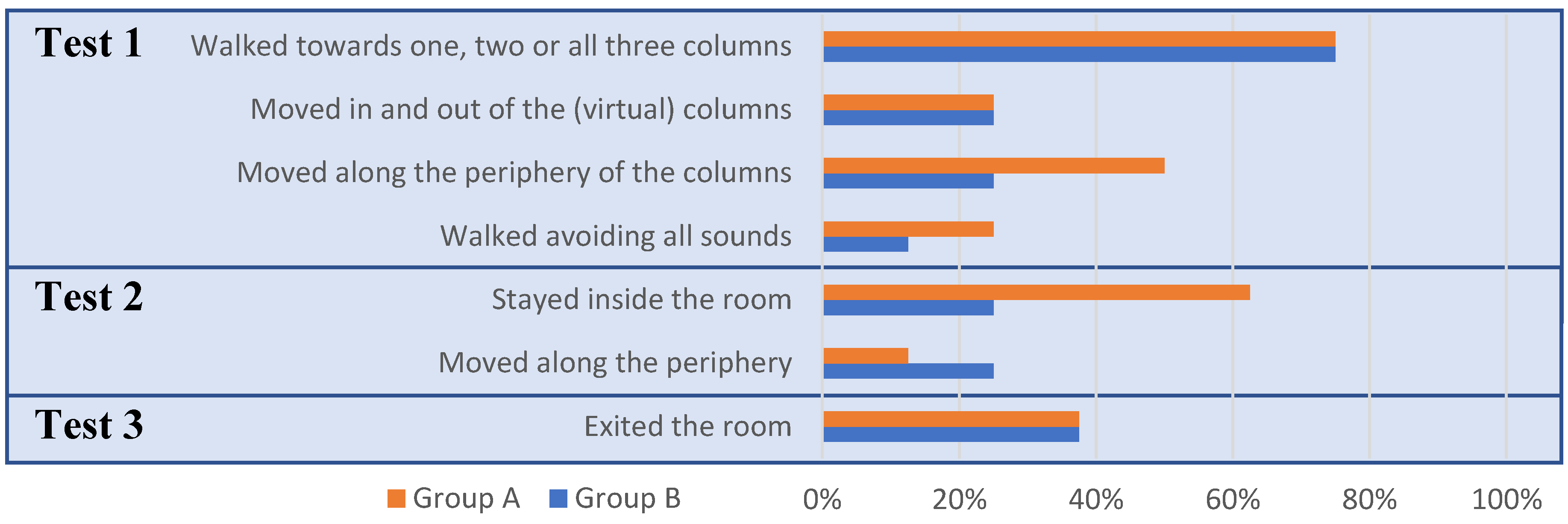
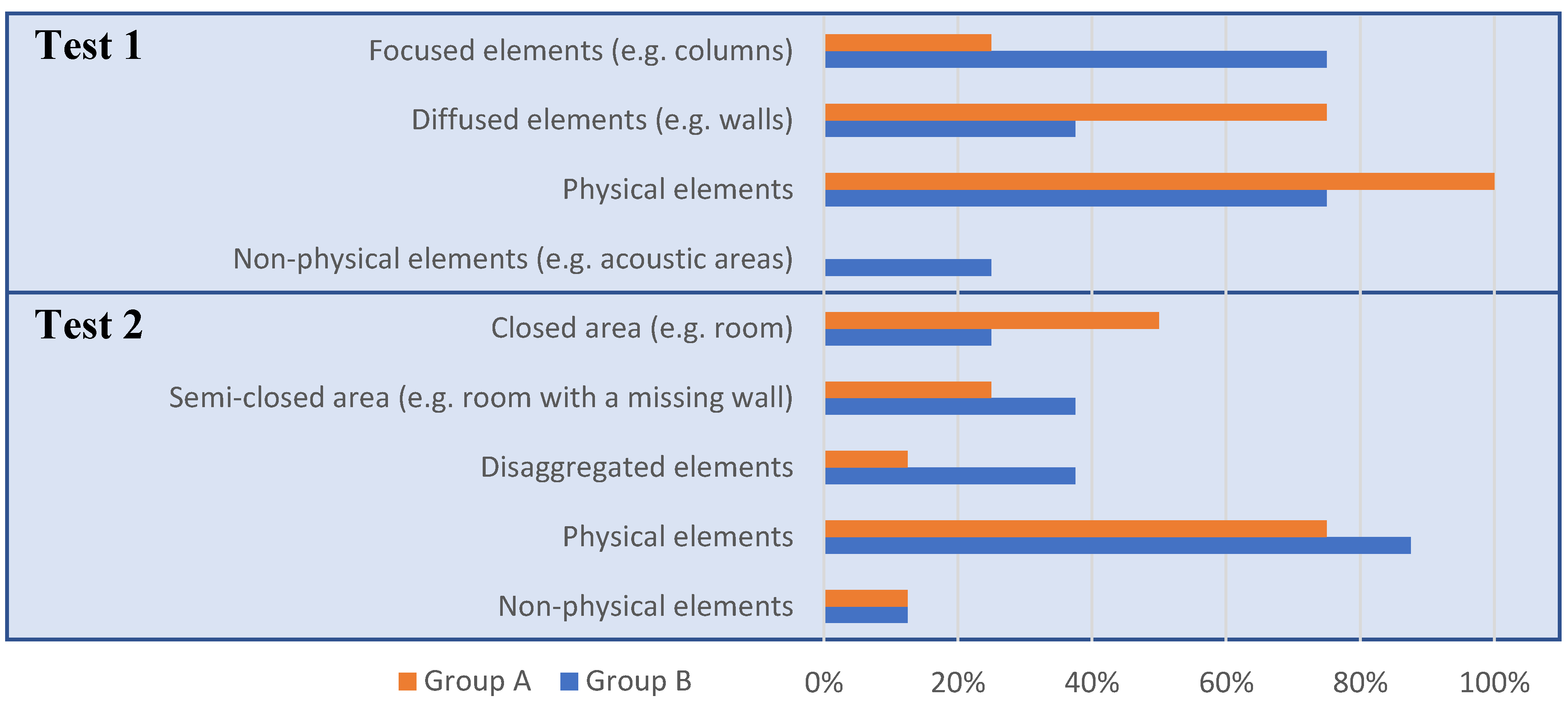
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ahmetovic, D.; Gleason, C.; Ruan, C.; Kitani, K. NavCog: A Navigational Cognitive Assistant for the Blind. In Proceedings of the 18th International Conference on Human-Computer Interaction with Mobile Devices and Services (MobileHCI ’16), Florence, Italy, 6–9 September 2016; pp. 90–99. [Google Scholar]
- Seeing, A.I. Talking Camera App for Those with a Visual Impairment. Available online: https://www.microsoft.com/en-us/seeing-ai/ (accessed on 9 January 2020).
- Real, S.; Araujo, A. Navigation Systems for the Blind and Visually Impaired: Past Work, Challenges, and Open Problems. Sensors 2019, 19, 3404. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Montello, D.; Giudice, N.A. Navigating without vision: Principles of blind spatial cognition. In Handbook of Behavioral and Cognitive Geography; Edward Elgar Publishing: Cheltenham, UK; Northampton, MA, USA, 2018; pp. 260–288. [Google Scholar]
- Schinazi, V.R.; Thrash, T.; Chebat, D.R. Spatial navigation by congenitally blind individuals. Wiley Interdiscip. Rev. Cogn. Sci. 2016, 7, 37–58. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- WayFindr. Available online: https://www.wayfindr.net/ (accessed on 9 January 2020).
- NaviLens-Smartphone Application. Available online: https://www.navilens.com/ (accessed on 9 January 2020).
- Loomis, J.M.; Golledge, R.G.; Klatzky, R.L.; Marston, J.R. Assisting wayfinding in visually impaired travelers. In Applied Spatial Cognition: From Research to Cognitive Technology; Lawrence Erlbaum Associates, Inc.: Mahwah, NJ, USA, 2007; pp. 179–203. [Google Scholar]
- Carrasco, E.; Loyo, E.; Otaegui, O.; Fösleitner, C.; Dubielzig, M.; Olmedo, R.; Wasserburger, W.; Spiller, J. ARGUS Autonomous Navigation System for People with Visual Impairments. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2014; Volume 8548, pp. 100–107. [Google Scholar]
- Lazzus. Available online: http://www.lazzus.com/en/ (accessed on 29 July 2019).
- Hub, A. Precise Indoor and Outdoor Navigation for the Blind and Visually Impaired Using Augmented Maps and the TANIA System. In Proceedings of the 9th International Conference on Low Vision, Vision 2008, Montreal, QC, Canada, 7–11 July 2008; pp. 2–5. [Google Scholar]
- Spiers, A.J.; Dollar, A.M. Design and evaluation of shape-changing haptic interfaces for pedestrian navigation assistance. IEEE Trans. Haptics 2017, 10, 17–28. [Google Scholar] [CrossRef] [PubMed]
- Kaczmarek, K.; Bach-y-Rita, P.; Tompkins, W.J.; Webster, J.G. A tactile vision-substitution system for the blind: Computer-controlled partial image sequencing. IEEE Trans. Biomed. Eng. 1985, 32, 602–608. [Google Scholar] [CrossRef] [PubMed]
- Meijer, P.B.L. An Experimental System for Auditory Image Representations. IEEE Trans. Biomed. Eng. 1992, 39, 112–121. [Google Scholar] [CrossRef] [PubMed]
- Grant, P.; Spencer, L.; Arnoldussen, A.; Hogle, R.; Nau, A.; Szlyk, J.; Nussdorf, J.; Fletcher, D.C.; Gordon, K.; Seiple, W. The Functional Performance of the BrainPort V100 Device in Persons Who Are Profoundly Blind. J. Vis. Impair. Blind. 2016, 110, 77–89. [Google Scholar] [CrossRef] [Green Version]
- Ward, J.; Meijer, P. Visual experiences in the blind induced by an auditory sensory substitution device. Conscious. Cogn. 2010, 19, 492–500. [Google Scholar] [CrossRef] [PubMed]
- Loomis, J.M.; Klatzky, R.L.; Giudice, N.A. Sensory substitution of vision: Importance of perceptual and cognitive processing. In Assistive Technology for Blindness and Low Vision; CRC Press: Boca Ratón, FL, USA, 2012; pp. 162–191. [Google Scholar]
- Gonzalez-Mora, J.L.; Rodriguez-Hernaindez, A.F.; Burunat, E.; Martin, F.; Castellano, M.A. Seeing the world by hearing: Virtual Acoustic Space (VAS) a new space perception system for blind people. In Proceedings of the 2006 2nd International Conference on Information & Communication Technologies, Damascus, Syria, 24–28 April 2006; Volume 1, pp. 837–842. [Google Scholar]
- González-Mora, J.L.; R Odríguez-Hernández, A.; Rodríguez-Ramos, L.F.; Dfaz-Saco, L.; Sosa, N. Development of a new space perception system for blind people, based on the creation of a virtual acoustic space. In Engineering Applications of Bio-Inspired Artificial Neural Networks, Proceedings of the International Work-Conference on Artificial Neural Networks, Alicante, Spain, 2–4 June 1999; Lecture Notes Computer Science; Springer: Berlin/Heidelberg, Germany, 1999; Volume 1607, pp. 321–330. [Google Scholar]
- Cassinelli, A.; Reynolds, C.; Ishikawa, M. Augmenting spatial awareness with haptic radar. In Proceedings of the 2006 10th IEEE International Symposium on Wearable Computers, Montreux, Switzerland, 11–14 October 2006; pp. 61–64. [Google Scholar]
- Meers, S.; Ward, K. A vision system for providing 3D perception of the environment via transcutaneous electro-neural stimulation. In Proceedings of the Eighth International Conference on Information Visualisation 2004 (IV 2004), London, UK, 16 July 2004. [Google Scholar]
- Lahav, O.; Gedalevitz, H.; Battersby, S.; Brown, D.; Evett, L.; Merritt, P. Virtual environment navigation with look-around mode to explore new real spaces by people who are blind. Disabil. Rehabil. 2018, 40, 1072–1084. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cobo, A.; Guerrón, N.E.; Martín, C.; del Pozo, F.; Serrano, J.J. Differences between blind people’s cognitive maps after proximity and distant exploration of virtual environments. Comput. Hum. Behav. 2017, 77, 294–308. [Google Scholar] [CrossRef]
- Zerroug, A.; Cassinelli, A.; Ishikawa, M. Virtual Haptic Radar. In Proceedings of the ACM SIGGRAPH ASIA 2009 Sketches, Yokohama, Japan, 16–19 December 2009. [Google Scholar]
- Massiceti, D.; Hicks, S.L.; van Rheede, J.J. Stereosonic Vision: Exploring Visual-to-Auditory Sensory Substitution Mappings in an Immersive Virtual Reality Navigation Paradigm. PLoS ONE 2018, 13, e0199389. [Google Scholar] [CrossRef] [PubMed]
- Jafri, R.; Campos, R.L.; Ali, S.A.; Arabnia, H.R. Visual and Infrared Sensor Data-Based Obstacle Detection for the Visually Impaired Using the Google Project Tango Tablet Development Kit and the Unity Engine. IEEE Access 2017, 6, 443–454. [Google Scholar] [CrossRef]
- Zhang, X.; Yao, X.; Zhu, Y.; Hu, F. An ARCore based user centric assistive navigation system for visually impaired people. Appl. Sci. 2019, 9, 989. [Google Scholar] [CrossRef] [Green Version]
- Electronic Travel Aids: New Directions for Research; National Academies Press: Washington, DC, USA, 1986; ISBN 978-0-309-07791-0.
- Schinazi, V. Representing Space: The Development Content and Accuracy of Mental Representations by the Blind and Visually Impaired; University College London: London, UK, 2008. [Google Scholar]
- Maidenbaum, S.; Abboud, S.; Amedi, A. Sensory substitution: Closing the gap between basic research and widespread practical visual rehabilitation. Neurosci. Biobehav. Rev. 2014, 41, 3–15. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haigh, A.; Brown, D.J.; Meijer, P.; Proulx, M.J. How well do you see what you hear? The acuity of visual-to-auditory sensory substitution. Front. Psychol. 2013, 4, 330. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sampaio, E.; Maris, S.; Bach-y-Rita, P. Brain plasticity: Visual acuity of blind persons via the tongue. Brain Res. 2001, 908, 204–207. [Google Scholar] [CrossRef]
- Thinus-Blanc, C.; Gaunet, F. Representation of space in blind persons: Vision as a spatial sense? Psychol. Bull. 1997, 121, 20–42. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PVAS Configuration (Groups A, B) | AVAS Configuration (Group B) | |||
|---|---|---|---|---|
| M | 13 | Mode | Non-modulated periodic pulses | |
| N | 7 | |||
| K | 36 | Radius (m) | 1,2 | |
| Angle of view (°) | αH | 50 | ||
| αV | 30 | |||
| Ts (ms) | 20 | |||
| Detection distance (m) | 20 | |||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Real, S.; Araujo, A. VES: A Mixed-Reality System to Assist Multisensory Spatial Perception and Cognition for Blind and Visually Impaired People. Appl. Sci. 2020, 10, 523. https://doi.org/10.3390/app10020523
Real S, Araujo A. VES: A Mixed-Reality System to Assist Multisensory Spatial Perception and Cognition for Blind and Visually Impaired People. Applied Sciences. 2020; 10(2):523. https://doi.org/10.3390/app10020523
Chicago/Turabian StyleReal, Santiago, and Alvaro Araujo. 2020. "VES: A Mixed-Reality System to Assist Multisensory Spatial Perception and Cognition for Blind and Visually Impaired People" Applied Sciences 10, no. 2: 523. https://doi.org/10.3390/app10020523
APA StyleReal, S., & Araujo, A. (2020). VES: A Mixed-Reality System to Assist Multisensory Spatial Perception and Cognition for Blind and Visually Impaired People. Applied Sciences, 10(2), 523. https://doi.org/10.3390/app10020523