Performance Analysis of Thread Block Schedulers in GPGPU and Its Implications



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
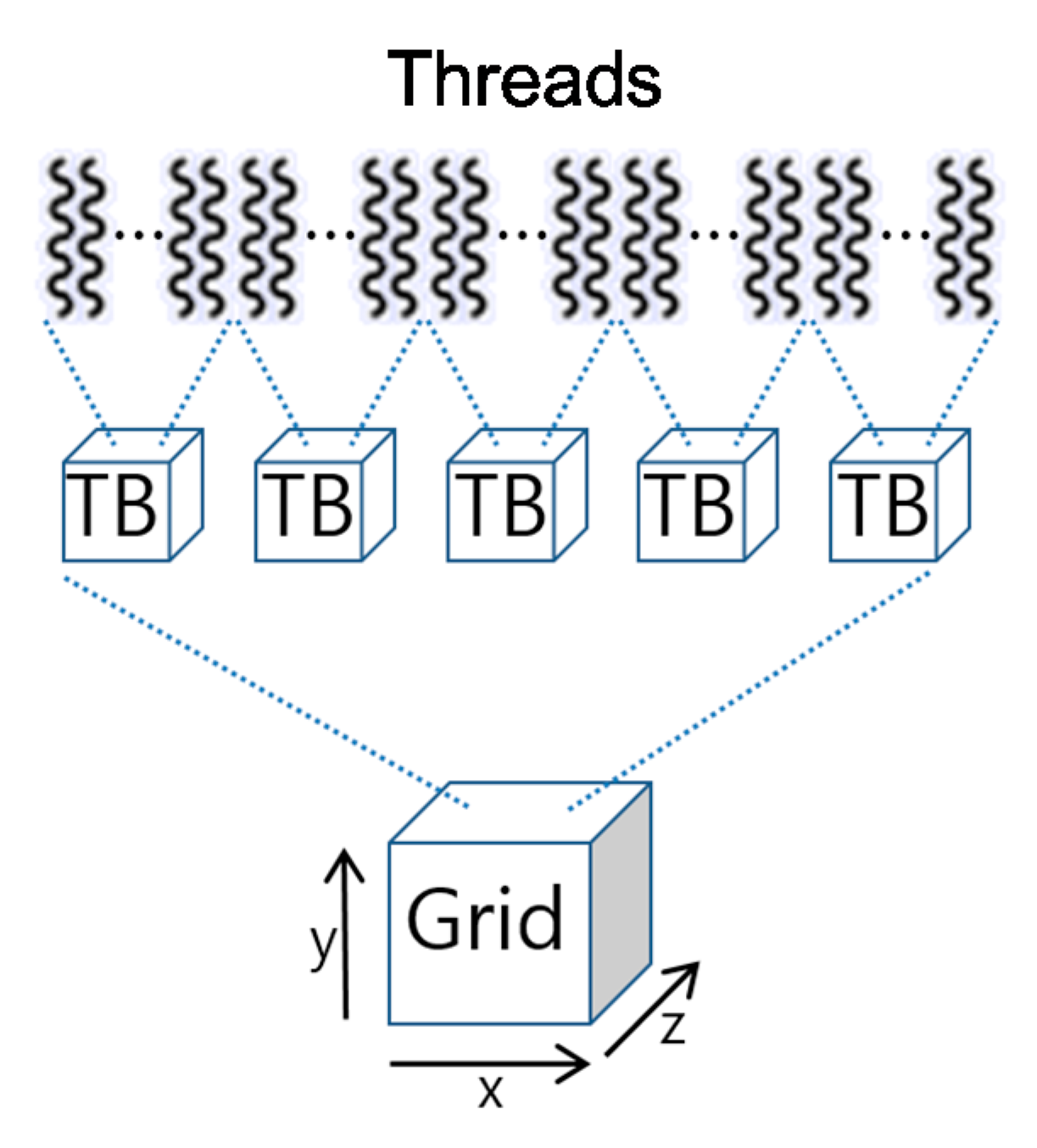
2. GPGPU and Thread Block Model
- −
- Registers and shared memory
- −
- Threads and thread block Information
- −
- Hardware Warp information
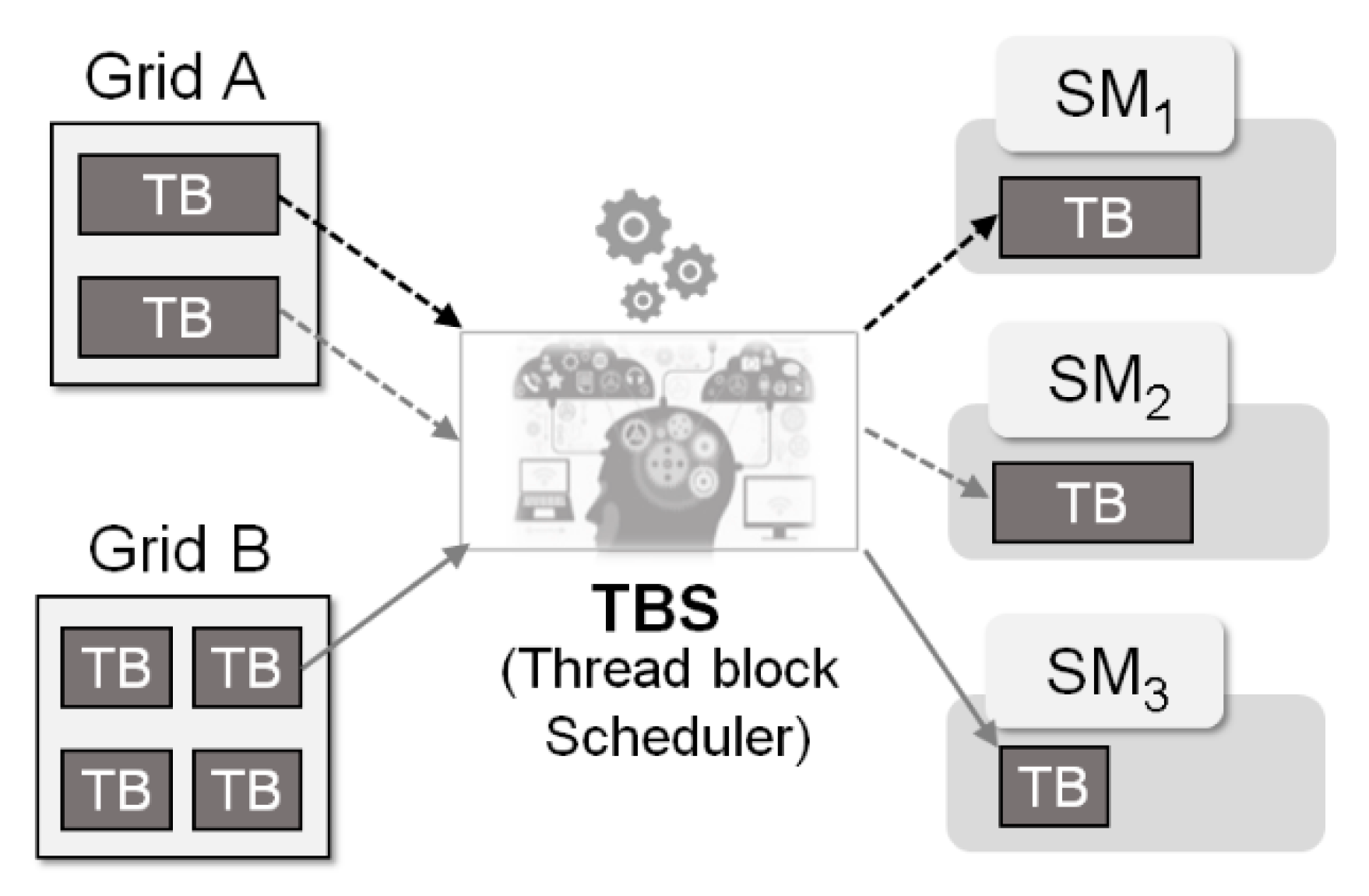
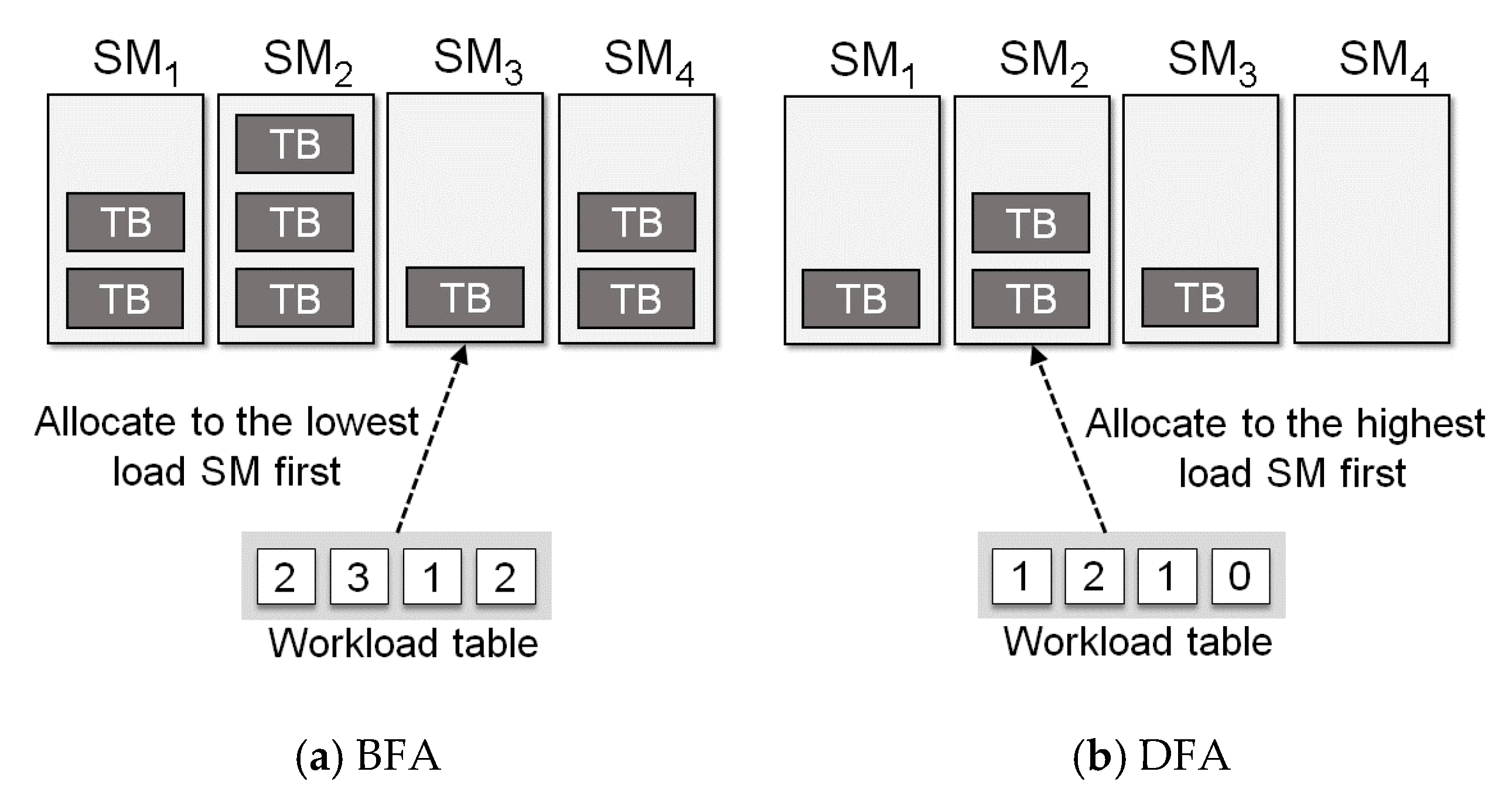
3. A GPGPU Simulator Based on the Thread Block Scheduling Model
- −
- Arrival time of the task
- −
- Number of mTBs corresponding to the total number of threads
- −
- Computing resource demands per mTB
- −
- Memory resource demands per mTB
- −
- Basic execution time of mTB
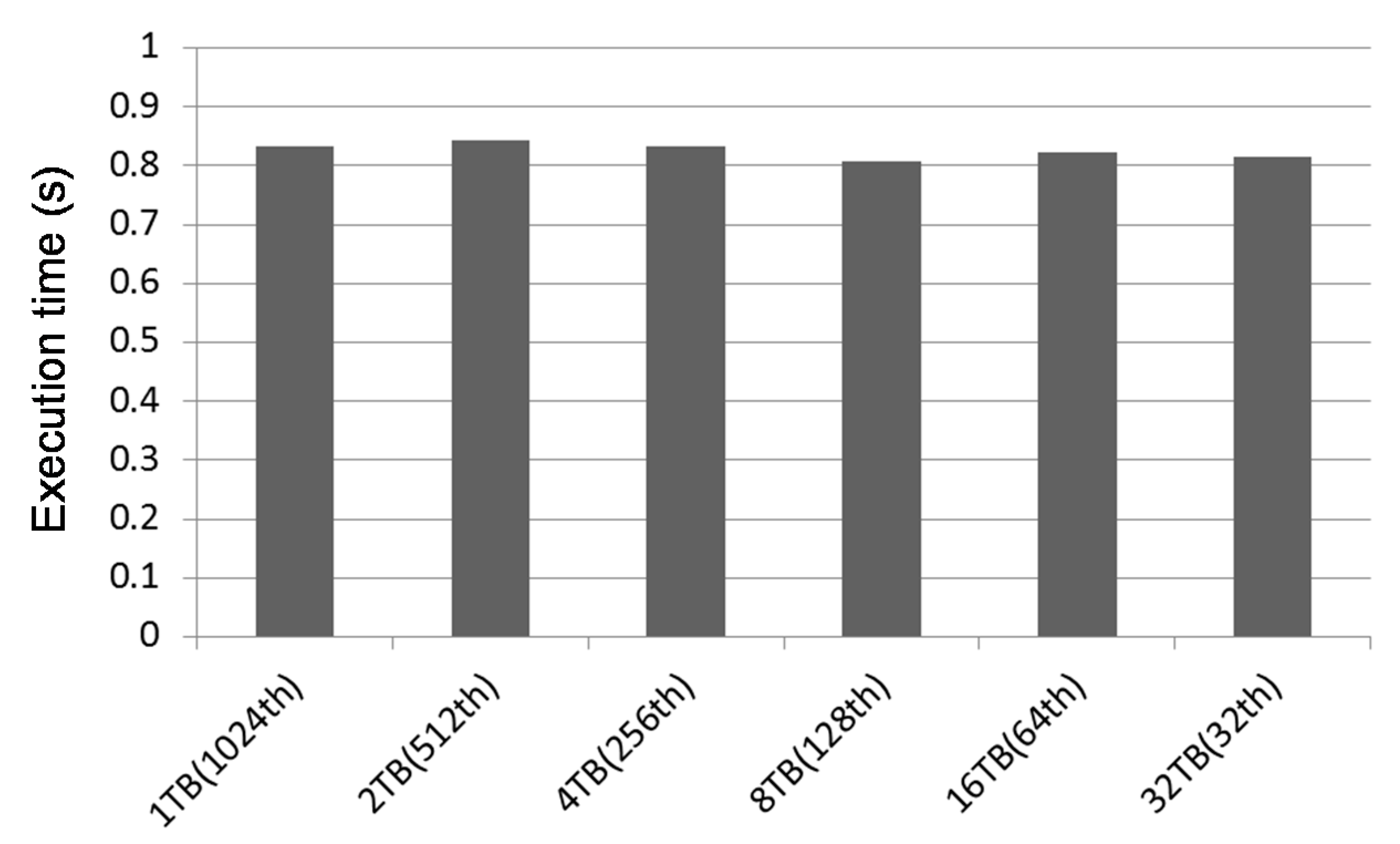
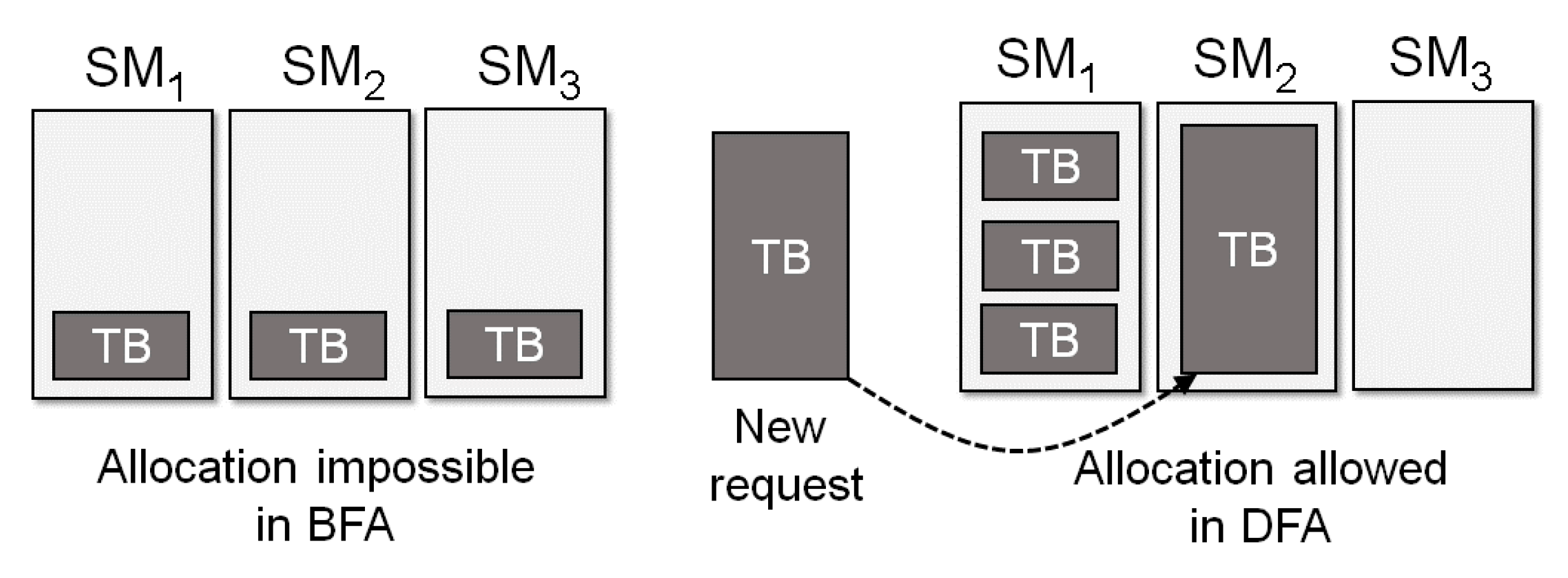
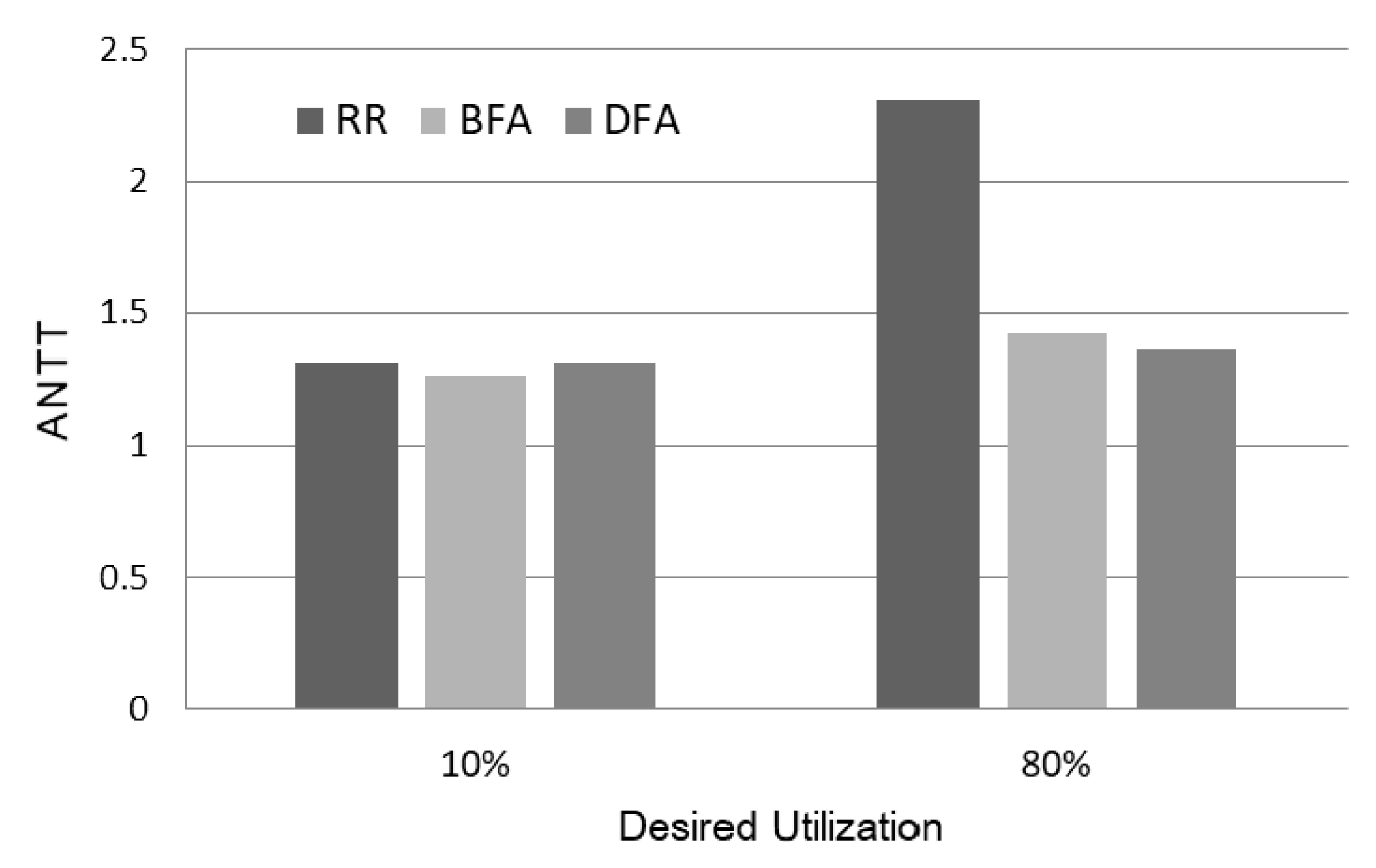
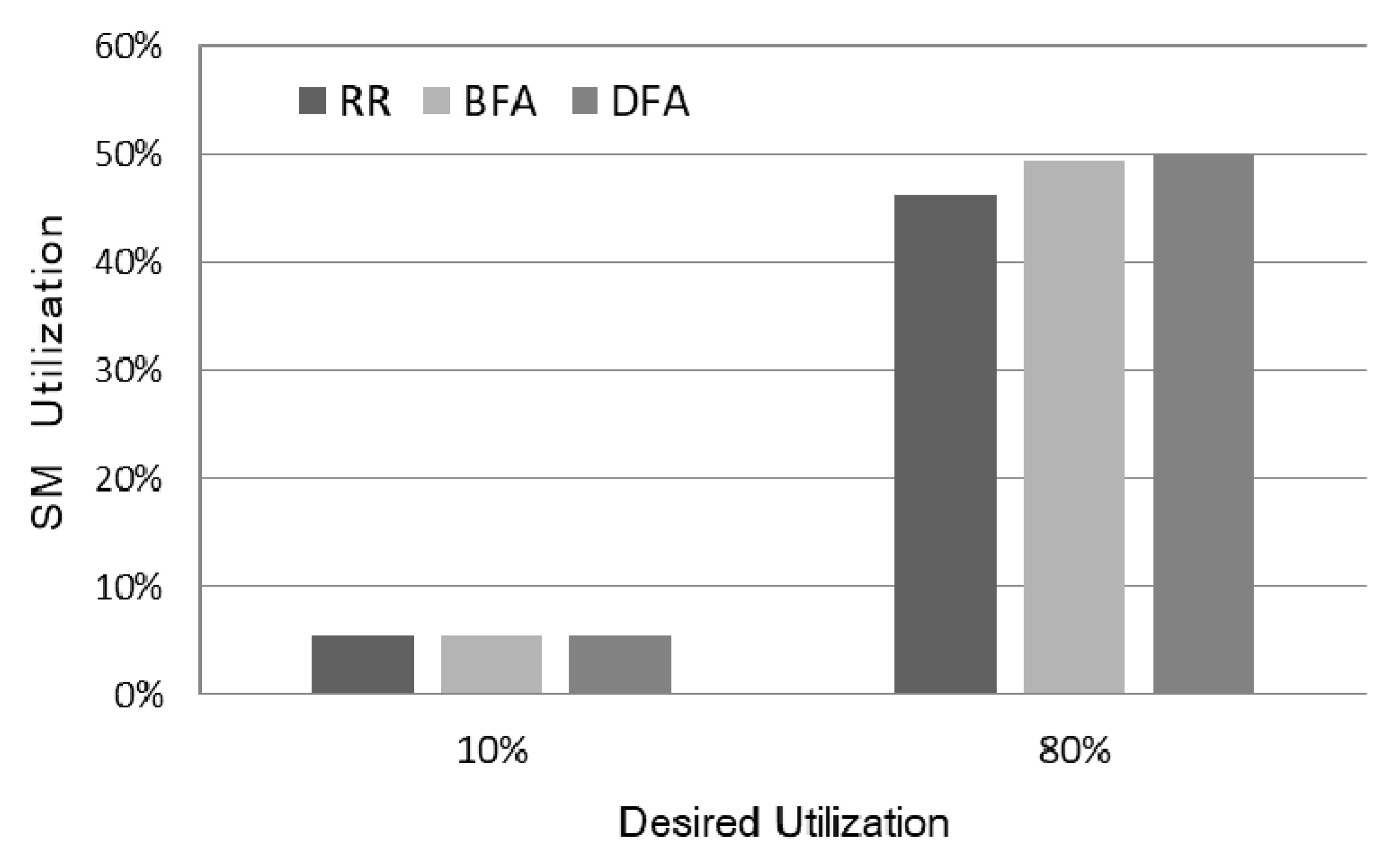
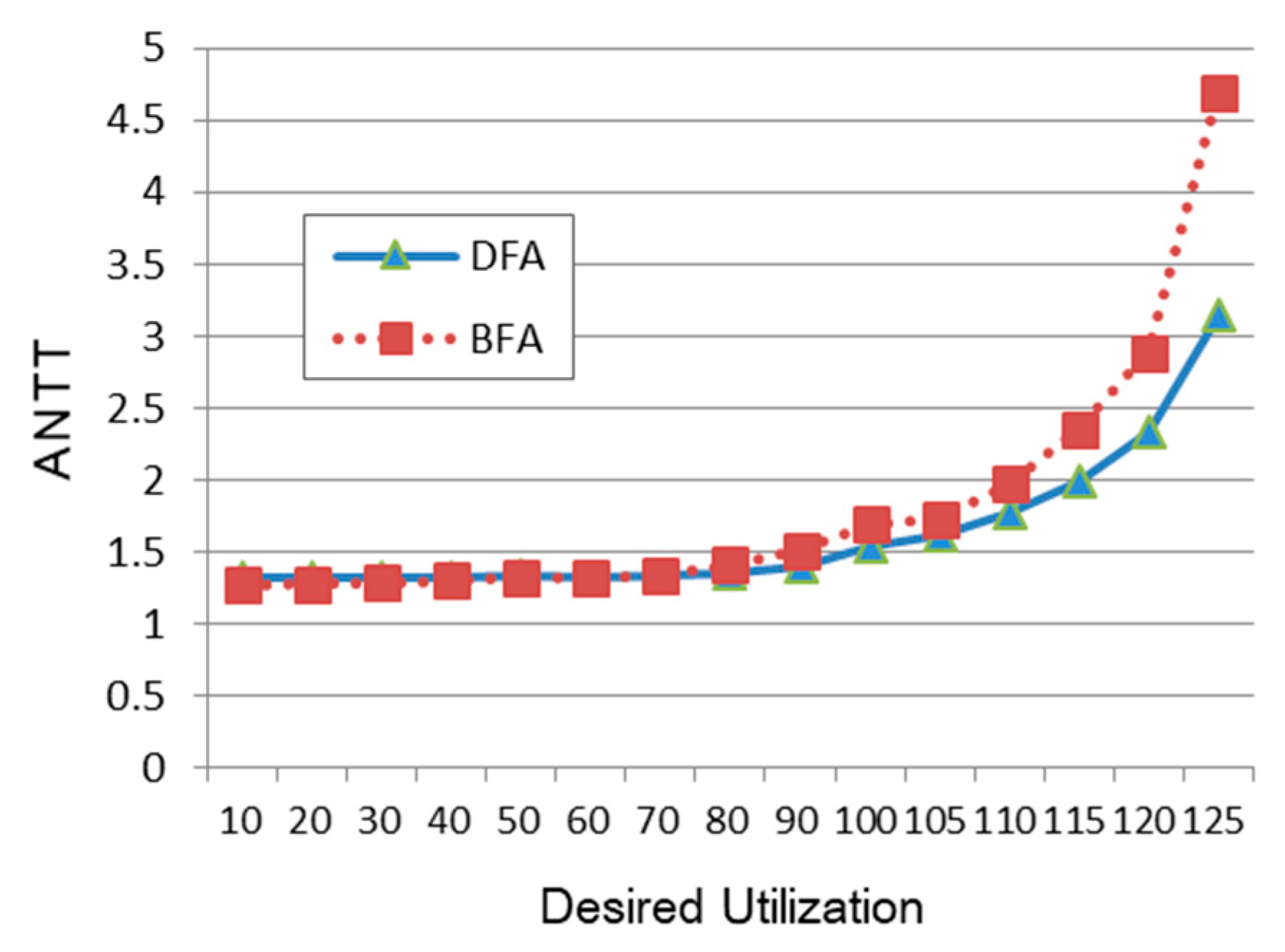
4. Performance Evaluation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Nickolls, J.; Dally, W.J. The GPU Computing Era. IEEE Micro 2010, 30, 56–69. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Maitre, O.; Lachiche, N.; Clauss, P.; Baumes, L.; Corma, A.; Collet, P. Efficient parallel implementation of evolutionary algorithms on GPGPU cards. In European Conference on Parallel Processing; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar] [CrossRef]
- Garland, M. Parallel computing with CUDA. In Proceedings of the IEEE International Symposium on Parallel & Distributed Processing (IPDPS), IEEE Computer Society, Atlanta, GA, USA, 19–23 April 2010. [Google Scholar] [CrossRef]
- CUDA Toolkit Documentation. Available online: https://docs.nvidia.com/cuda/ (accessed on 19 December 2020).
- Lee, S.; Arunkumar, A.; Wu, C. CAWA: Coordinated warp scheduling and cache prioritization for critical warp acceleration of GPGPU workloads. In Proceedings of the 2015 ACM/IEEE 42nd Annual International Symposium on Computer Architecture (ISCA), Portland, OR, USA, 13–17 June 2015; Volume 43, pp. 515–527. [Google Scholar]
- Ryoo, S.; Rodrigues, C.; Baghsorkhi, S.; Stone, S.; Kirk, D.; Hwu, W. Optimization principles and application performance evaluation of a multithreaded GPU using CUDA. In Proceedings of the 13th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, Salt Lake City, UT, USA, 20–23 February 2008. [Google Scholar]
- Galvin, P.; Gagne, G.; Silberschatz, A. Operating System Concepts; John Wiley & Sons: Hoboken, NJ, USA, 2003. [Google Scholar]
- Mostafa, S.; Rida, S.Z.; Hamad, H.S. Finding time quantum of round robin CPU scheduling algorithm in general computing systems using integer programming. Int. J. Res. Rev. Appl. Sci. 2010, 5, 64–71. [Google Scholar]
- Shreedhar, M.; Varghese, G. Efficient fair queuing using deficit round-robin. In Proceedings of the ACM SIGCOMM Computer Communication Review, New York, NY, USA, 3 July 1996; Volume 4, pp. 375–385. [Google Scholar] [CrossRef] [Green Version]
- Nieh, J.; Vaill, C.; Zhong, H. Virtual-Time Round-Robin: An O(1) Proportional Share Scheduler. In Proceedings of the 2001 USENIX AnnualTechnical Conference, Boston, MA, USA, 25–30 June 2001. [Google Scholar] [CrossRef]
- TBS Simulator. Available online: https://github.com/oslab-ewha/simtbs (accessed on 19 December 2020).
- Lee, J.; Lakshminarayana, N.B.; Kim, H.; Vuduc, R. Many-thread aware prefetching mechanisms for GPGPU applications. In Proceedings of the 2010 43rd Annual IEEE/ACM International Symposium on Microarchitecture, Atlanta, GA, USA, 4–8 December 2010. [Google Scholar]
- Yunjoo, P.; Donghee, S.; Kyungwoon, C.; Hyokyung, B. Analyzing Fine-Grained Resource Utilization for Efficient GPU Workload Allocation. J. Inst. Internet Broadcasting Commun. 2019, 19, 111–116. [Google Scholar] [CrossRef]
- Su, C.-L.; Chen, P.Y.; Lan, C.-C.; Huang, L.-S.; Wu, K.H. Overview and comparison of OpenCL and CUDA technology for GPGPU. In Proceedings of the 2012 IEEE Asia Pacific Conference on Circuits and Systems, Kaohsiung, Taiwan, 2–5 December 2012. [Google Scholar]
- Jia, Z.; Maggioni, M.; Smith, J.; Scarpazza, D.P. Dissecting the NVidia Turing T4 GPU via Microbenchmarking. arXiv Preprint 2019, arXiv:1903.07486. [Google Scholar]
- Wang, Q.; Xiaowen, C. GPGPU performance estimation with core and memory frequency scaling. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 2865–2881. [Google Scholar] [CrossRef]
- Andersch, M. Analyzing GPGPU pipeline latency. In Proceedings of the International Summer School on Advanced Computer Architecture and Compilation for High-Performance and Embedded Systems (ACACES), Fiuggi, Italy, 13–19 July 2014. [Google Scholar]
- Orzechowski, P.; Boryczko, K. Effective biclustering on GPU-capabilities and constraints. Prz Elektrotechniczn 2015, 1, 133–136. [Google Scholar] [CrossRef]
- López-Fernández, A.; Rodriguez-Baena, D.; Gomez-Vela, F.; Divina, F.; Garcia-Torres, M. A multi-GPU biclustering algorithm for binary datasets. J. Parallel Distrib. Comput. 2021, 147, 209–219. [Google Scholar] [CrossRef]
- Collange, S.; Daumas, M.; Defour, D.; Parello, D. Barra: A parallel functional simulator for GPGPU. In Proceedings of the 2010 IEEE International Symposium on Modeling, Analysis and Simulation of Computer and Telecommunication Systems, Miami Beach, FL, USA, 17–19 August 2010. [Google Scholar]
- Wang, Z.; Yang, J.; Melhem, R.; Childers, B.; Zhang, Y.; Guo, M. Simultaneous multikernel GPU: Multi-tasking throughput processors via fine-grained sharing. In Proceedings of the 2016 IEEE International Symposium on High Performance Computer Architecture (HPCA), Barcelona, Spain, 12–16 March 2016. [Google Scholar]
- Xu, Q.; Jeon, H.; Kim, K.; Ro, W.W.; Annavaram, M. Warped-slicer: Efficient intra-SM slicing through dynamic resource partitioning for GPU multiprogramming. In Proceedings of the 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), Seoul, Korea, 18–22 June 2016. [Google Scholar]
- Park, J.J.K.; Park, Y.; Mahlke, S. Dynamic resource management for efficient utilization of multitasking GPUs. In Proceedings of the 22nd International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Xi’an, China, 8–10 April 2017. [Google Scholar] [CrossRef] [Green Version]
- Pai, S.; Thazhuthaveetil, M.J.; Govindarajan, R. Improving GPGPU concurrency with elastic kernels. In Proceedings of the ACM SIGARCH Computer Architecture News, Bangalore, India, 16 March 2013; Volume 41, pp. 407–418. [Google Scholar]
- Badawi, A.A.; Veeravalli, B.; Lin, J.; Xiao, N.; Kazuaki, M.; Mi, A.K.M. Multi-GPU Design and Performance Evaluation of Homomorphic Encryption on GPU Clusters. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 379–391. [Google Scholar] [CrossRef]
- Yeh, T.T.; Sabne, A.; Sakdhnagool, P.; Eigenmann, R.; Rogers, T.G. Pagoda: Fine-grained GPU resource virtualization for narrow tasks. In Proceedings of the 22nd ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, Austin, TX, USA, 4–8 February 2017; Volume 52, pp. 221–234. [Google Scholar] [CrossRef]
- Aaron, A.; Fung, W.W.L.; Turner, A.E.; Aamodt, T.M. Visualizing complex dynamics in many-core accelerator architectures. In Proceedings of the 2010 IEEE International Symposium on Performance Analysis of Systems & Software (ISPASS), White Plains, NY, USA, 28–30 March 2010. [Google Scholar] [CrossRef]
- Hughes, C.; Green, R.; Voskuilen, G.R.; Zhang, M.; Rogers, T. GPGPU-Sim Overview. In Technical Report, No. SAND2019-13453C; Sandia National Lab: Albuquerque, NM, USA, 2019. [Google Scholar]









Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cho, K.; Bahn, H. Performance Analysis of Thread Block Schedulers in GPGPU and Its Implications. Appl. Sci. 2020, 10, 9121. https://doi.org/10.3390/app10249121
Cho K, Bahn H. Performance Analysis of Thread Block Schedulers in GPGPU and Its Implications. Applied Sciences. 2020; 10(24):9121. https://doi.org/10.3390/app10249121
Chicago/Turabian StyleCho, KyungWoon, and Hyokyung Bahn. 2020. "Performance Analysis of Thread Block Schedulers in GPGPU and Its Implications" Applied Sciences 10, no. 24: 9121. https://doi.org/10.3390/app10249121
APA StyleCho, K., & Bahn, H. (2020). Performance Analysis of Thread Block Schedulers in GPGPU and Its Implications. Applied Sciences, 10(24), 9121. https://doi.org/10.3390/app10249121