Data-Efficient Domain Adaptation for Semantic Segmentation of Aerial Imagery Using Generative Adversarial Networks



Abstract
:1. Introduction
2. Related Works
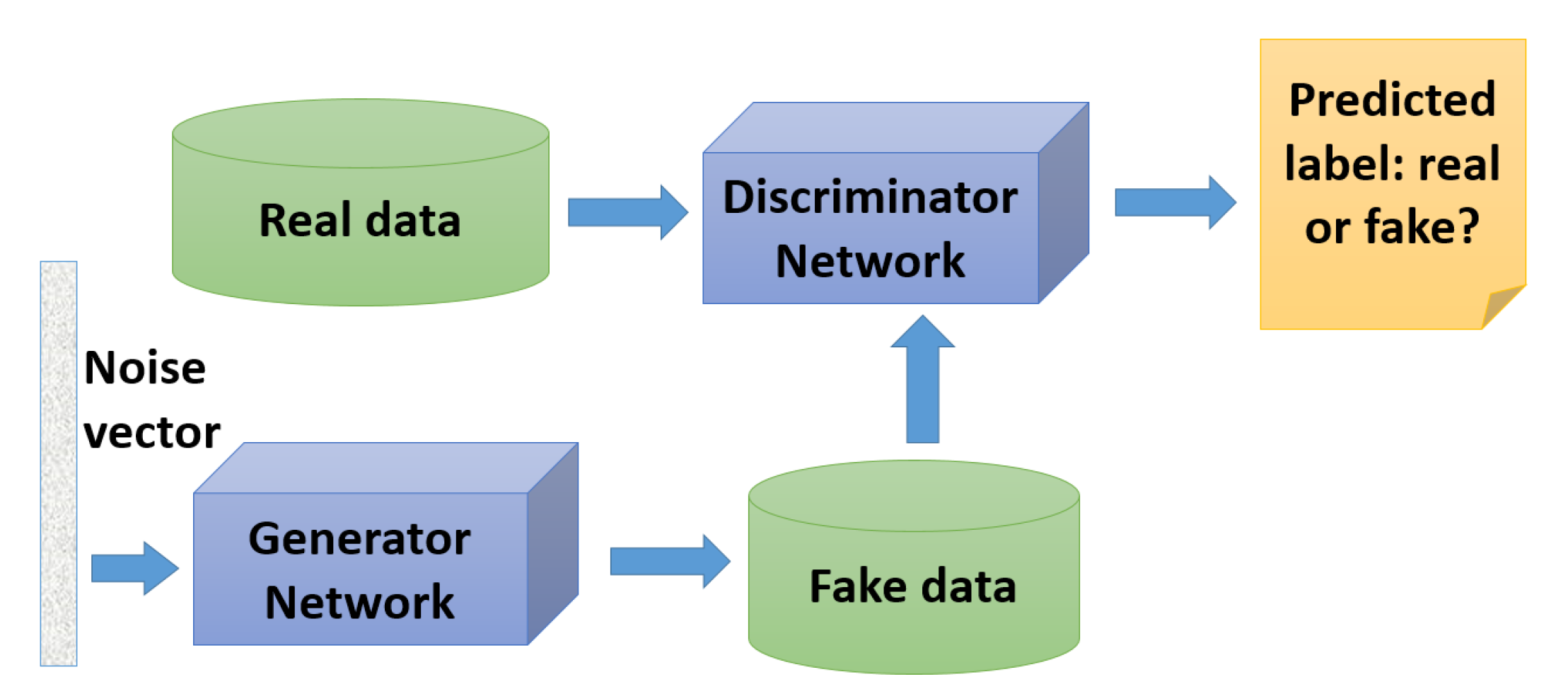
3. Generative Adversarial Networks (GANs)
3.1. The Generator and the Discriminator
3.2. translation from Image-to-Image using GANs
3.2.1. Paired Image-to-Image Translation
3.2.2. Unpaired Image Translation
4. Proposed Method
4.1. The GAN Architecture
4.2. The Description of the Algorithm
4.3. Problem Formulation
5. Experimental Results
5.1. The Datasets and the Evaluation Metrics
5.1.1. The Datasets
5.1.2. The Analysis of the Domain Shift Factors
5.1.3. Evaluation Metrics
5.2. Experimental Settings
5.2.1. Step 1: Training of the Semantic Segmentation Model
- Processor: Intel Core i9 (Coffee Lake architecture, 6 cores)
- GPU: Nvidia GTX 1080, 8GB dedicated
- Memory: 32 GB RAM
- Operating system: Windows 10 and Linux (Ubuntu 16.04)
5.2.2. Step 2: Label Significant Data Samples from the Target Domain
5.2.3. Step 3: Training the First GAN Network
5.2.4. Step 4: Training the Second GAN Network
5.2.5. Step 5: Segment Images from the Target Domain
5.2.6. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Alhichri, H.; Jdira, B.B.; Alajlan, N. Multiple Object Scene Description for the Visually Impaired Using Pre-trained Convolutional Neural Networks. In Proceedings of the International Conference on Image Analysis and Recognition, Póvoa de Varzim, Portugal, 13–15 July 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 290–295. [Google Scholar]
- Benjdira, B.; Khursheed, T.; Koubaa, A.; Ammar, A.; Ouni, K. Car Detection using Unmanned Aerial Vehicles: Comparison between Faster R-CNN and YOLOv3. In Proceedings of the 2019 1st International Conference on Unmanned Vehicle Systems-Oman (UVS), Muscat, Oman, 5–7 February 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Al Rahhal, M.M.; Bazi, Y.; Al Zuair, M.; Othman, E.; BenJdira, B. Convolutional neural networks for electrocardiogram classification. J. Med Biol. Eng. 2018, 38, 1014–1025. [Google Scholar] [CrossRef]
- Benjdira, B.; Bazi, Y.; Koubaa, A.; Ouni, K. Unsupervised Domain Adaptation Using Generative Adversarial Networks for Semantic Segmentation of Aerial Images. Remote. Sens. 2019, 11, 1369. [Google Scholar] [CrossRef] [Green Version]
- Ammour, N.; Alhichri, H.; Bazi, Y.; Benjdira, B.; Alajlan, N.; Zuair, M. Deep learning approach for car detection in UAV imagery. Remote. Sens. 2017, 9, 312. [Google Scholar] [CrossRef] [Green Version]
- Singh, V.K.; Rashwan, H.A.; Romani, S.; Akram, F.; Pandey, N.; Sarker, M.M.K.; Saleh, A.; Arenas, M.; Arquez, M.; Puig, D.; et al. Breast tumor segmentation and shape classification in mammograms using generative adversarial and convolutional neural network. Expert Syst. Appl. 2019, 139, 112855. [Google Scholar] [CrossRef]
- Ammar, A.; Koubaa, A.; Ahmed, M.; Saad, A. Aerial Images Processing for Car Detection using Convolutional Neural Networks: Comparison between Faster R-CNN and YoloV3. arXiv 2019, arXiv:1910.07234. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Dong, L.Y.; Sui, P.; Sun, P.; Li, Y.L. Novel naive Bayes classification algorithm based on semi-supervised learning. Jilin Daxue Xuebao (Gongxueban)/J. Jilin Univ. (Eng. Technol. Ed. 2016, 46, 884–889. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Sun, P.; Brown, C.; Beschastnikh, I.; Stolee, K.T. Mining Specifications from Documentation using a Crowd. In Proceedings of the 2019 IEEE 26th International Conference on Software Analysis, Evolution and Reengineering (SANER), Hangzhou, China, 24–27 February 2019; pp. 275–286. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Darrell, T.; Saenko, K. Simultaneous deep transfer across domains and tasks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4068–4076. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M.I. Learning transferable features with deep adaptation networks. arXiv 2015, arXiv:1502.02791. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial discriminative domain adaptation. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 1, p. 4. [Google Scholar]
- Luo, Z.; Zou, Y.; Hoffman, J.; Fei-Fei, L.F. Label efficient learning of transferable representations acrosss domains and tasks. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 165–177. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Patel, V.M.; Gopalan, R.; Li, R.; Chellappa, R. Visual Domain Adaptation: A survey of recent advances. IEEE Signal Process. Mag. 2015, 32, 53–69. [Google Scholar] [CrossRef]
- Saenko, K.; Kulis, B.; Fritz, M.; Darrell, T. Adapting visual category models to new domains. In Proceedings of the European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 213–226. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 2096–2030. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. arXiv 2014, arXiv:1409.7495. [Google Scholar]
- Bousmalis, K.; Silberman, N.; Dohan, D.; Erhan, D.; Krishnan, D. Unsupervised pixel-level domain adaptation with generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3722–3731. [Google Scholar]
- Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.Y.; Isola, P.; Saenko, K.; Efros, A.A.; Darrell, T. Cycada: Cycle-consistent adversarial domain adaptation. arXiv 2017, arXiv:1711.03213. [Google Scholar]
- Ros, G.; Sellart, L.; Materzynska, J.; Vazquez, D.; Lopez, A.M. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3234–3243. [Google Scholar]
- Vazquez, D.; Lopez, A.M.; Marin, J.; Ponsa, D.; Geronimo, D. Virtual and real world adaptation for pedestrian detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 797–809. [Google Scholar] [CrossRef] [PubMed]
- Peng, X.; Saenko, K. Synthetic to real adaptation with generative correlation alignment networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1982–1991. [Google Scholar]
- Shrivastava, A.; Pfister, T.; Tuzel, O.; Susskind, J.; Wang, W.; Webb, R. Learning from simulated and unsupervised images through adversarial training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2107–2116. [Google Scholar]
- Shafaei, A.; Little, J.J.; Schmidt, M. Play and learn: Using video games to train computer vision models. arXiv 2016, arXiv:1608.01745. [Google Scholar]
- Hoffman, J.; Wang, D.; Yu, F.; Darrell, T. Fcns in the wild: Pixel-level adversarial and constraint-based adaptation. arXiv 2016, arXiv:1612.02649. [Google Scholar]
- Zhang, Y.; David, P.; Gong, B. Curriculum domain adaptation for semantic segmentation of urban scenes. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2020–2030. [Google Scholar]
- Sankaranarayanan, S.; Balaji, Y.; Jain, A.; Lim, S.N.; Chellappa, R. Unsupervised domain adaptation for semantic segmentation with gans. arXiv 2017, arXiv:1711.06969. [Google Scholar]
- Tsai, Y.H.; Hung, W.C.; Schulter, S.; Sohn, K.; Yang, M.H.; Chandraker, M. Learning to adapt structured output space for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7472–7481. [Google Scholar]
- Huang, H.; Huang, Q.; Krahenbuhl, P. Domain transfer through deep activation matching. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 590–605. [Google Scholar]
- Tasar, O.; Happy, S.L.; Tarabalka, Y.; Alliez, P. ColorMapGAN: Unsupervised Domain Adaptation for Semantic Segmentation Using Color Mapping Generative Adversarial Networks. arXiv 2019, arXiv:1907.12859. [Google Scholar]
- Fang, B.; Kou, R.; Pan, L.; Chen, P. Category-Sensitive Domain Adaptation for Land Cover Mapping in Aerial Scenes. Remote. Sens. 2019, 11, 2631. [Google Scholar] [CrossRef] [Green Version]
- Gerke, M. Use of the Stair Vision Library Within the ISPRS 2D Semantic Labeling Benchmark (Vaihingen); University of Twente: Enschede, The Nerthands, 2014. [Google Scholar]
- Oliehoek, F.A.; Savani, R.; Gallego, J.; van der Pol, E.; Gross, R. Beyond Local Nash Equilibria for Adversarial Networks. arXiv 2018, arXiv:1806.07268. [Google Scholar]
- Goodfellow, I.J. NIPS 2016 Tutorial: Generative Adversarial Networks. arXiv 2016, arXiv:1701.00160. [Google Scholar]
- Liu, M.Y.; Breuel, T.; Kautz, J. Unsupervised Image-to-Image Translation Networks. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, NV, USA, 4–9 December 2017. [Google Scholar]
- Zhu, J.Y.; Zhang, R.; Pathak, D.; Darrell, T.; Efros, A.A.; Wang, O.; Shechtman, E. Toward Multimodal Image-to-Image Translation. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, NV, USA, 4–9 December 2017. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. DualGAN: Unsupervised Dual Learning for Image-to-Image Translation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2868–2876. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef] [Green Version]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical Evaluation of Rectified Activations in Convolutional Network. arXiv 2015, arXiv:1505.00853. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Srivastava, N.; Hinton, G.E.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral Segmentation Network for Real-Time Semantic Segmentation. In Proceedings of the European Conference on Computer Vision, Lecture Notes in Computer Science, Munich, Germany, 8–14 September 2018; pp. 334–349. [Google Scholar] [CrossRef] [Green Version]
- Real-Time Semantic Segmentation on Cityscapes. Available online: https://paperswithcode.com/sota/real-time-semantic-segmentation-cityscap (accessed on 28 March 2019).
- Semantic Segmentation Suite. Available online: https://github.com/GeorgeSeif/Semantic-Segmentation-Suite (accessed on 28 March 2019).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Potsdam | Vaihingen |
|---|---|---|
| Buildings | 28.2% | 26.9% |
| Impervious Surfaces | 29.9% | 29.3% |
| Low vegetation | 20.9% | 19.4% |
| Trees | 14.4% | 22.4% |
| Clutter | 4.8% | 0.7% |
| Cars | 1.7% | 1.3% |
| Domain Shift Factor | Resolution | Sensor | Class Representation |
|---|---|---|---|
| Trees | low | high | medium |
| Cars | low | low | low |
| Clutter | low | high | high |
| Impervious Surfaces | low | low | low |
| Buildings | low | high | low |
| Low vegetation | low | high | high |
| Number of Images from Target | Average Accuracy | Precision | Sensitivity | Dice Coef | IoU |
|---|---|---|---|---|---|
| 0 | 0.345 | 0.345 | 0.345 | 0.316 | 0.175 |
| 1 | 0.368 | 0.445 | 0.368 | 0.360 | 0.176 |
| 3 | 0.422 | 0.470 | 0.422 | 0.404 | 0.214 |
| 12 | 0.474 | 0.513 | 0.474 | 0.455 | 0.253 |
| 23 | 0.507 | 0.541 | 0.507 | 0.488 | 0.281 |
| 47 | 0.524 | 0.559 | 0.524 | 0.505 | 0.297 |
| 94 | 0.559 | 0.591 | 0.559 | 0.543 | 0.327 |
| 188 | 0.588 | 0.625 | 0.588 | 0.572 | 0.349 |
| Number of Images from Target | Average Accuracy | Precision | Sensitivity | Dice Coef | IoU |
|---|---|---|---|---|---|
| 0 | 0.334 | 0.335 | 0.334 | 0.288 | 0.169 |
| 192 | 0.363 | 0.365 | 0.363 | 0.318 | 0.179 |
| Method | Average Accuracy | Dice Coef | IoU |
|---|---|---|---|
| Without Domain Adaptation | 0.345 | 0.316 | 0.175 |
| FCNs in the wild | 0.486 | 0.413 | 0.309 |
| Unsupervised Method in [4] | 0.520 | 0.490 | 0.300 |
| Ours (188 images) | 0.588 | 0.572 | 0.349 |
| Nb of Images | Imp. Surf. | Building | Low Veget. | Tree | Car | Clutter Backgr. |
|---|---|---|---|---|---|---|
| 0 | 0.583 | 0.227 | 0.383 | 0.062 | 0.400 | 0.935 |
| 1 | 0.591 | 0.265 | 0.368 | 0.311 | 0.323 | 0.893 |
| 3 | 0.477 | 0.303 | 0.553 | 0.417 | 0.323 | 0.893 |
| 12 | 0.538 | 0.439 | 0.559 | 0.402 | 0.325 | 0.894 |
| 23 | 0.602 | 0.467 | 0.573 | 0.421 | 0.338 | 0.894 |
| 47 | 0.605 | 0.416 | 0.575 | 0.520 | 0.385 | 0.893 |
| 94 | 0.634 | 0.463 | 0.618 | 0.509 | 0.405 | 0.893 |
| 188 | 0.685 | 0.543 | 0.602 | 0.539 | 0.408 | 0.893 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benjdira, B.; Ammar, A.; Koubaa, A.; Ouni, K. Data-Efficient Domain Adaptation for Semantic Segmentation of Aerial Imagery Using Generative Adversarial Networks. Appl. Sci. 2020, 10, 1092. https://doi.org/10.3390/app10031092
Benjdira B, Ammar A, Koubaa A, Ouni K. Data-Efficient Domain Adaptation for Semantic Segmentation of Aerial Imagery Using Generative Adversarial Networks. Applied Sciences. 2020; 10(3):1092. https://doi.org/10.3390/app10031092
Chicago/Turabian StyleBenjdira, Bilel, Adel Ammar, Anis Koubaa, and Kais Ouni. 2020. "Data-Efficient Domain Adaptation for Semantic Segmentation of Aerial Imagery Using Generative Adversarial Networks" Applied Sciences 10, no. 3: 1092. https://doi.org/10.3390/app10031092
APA StyleBenjdira, B., Ammar, A., Koubaa, A., & Ouni, K. (2020). Data-Efficient Domain Adaptation for Semantic Segmentation of Aerial Imagery Using Generative Adversarial Networks. Applied Sciences, 10(3), 1092. https://doi.org/10.3390/app10031092