An Ontology-Based Framework for Publishing and Exploiting Linked Open Data: A Use Case on Water Resources Management

 , and
, and 
Abstract
:1. Introduction
- A water supply network oriented ontology is proposed, which allows for modelling, generating, integrating, publishing and exploiting a dataset, enabling general users to interact with the data. This ontology has been developed in OWL 2 and considers a large set of concepts, attributes and relationships to contextualize water management supply networks field.
- Our approach is tested on real-world data from a water management supply network in the Mediterranean region of Valencia (Valencian Community, Spain). It is a southeastern zone of Spain where autumn storm episodes are quite common, with flooding of urban areas, but with usual annual droughts. Different cities of the Valencian region such as Alicante or Valencia have developed an integral and sustainable water management plan, including flood prevention and supply network deep management among their priorities. Reported results allow us to support domain experts in the decision-making process.
- A semantic model has been implemented for materialization of all the involved concepts and measures from the data sources, as well as those processes and components required. The concepts are integrated according to the ontology scheme and integrated in the RDF repository. On top of this, a series of SPARQL queries have been formulated for federated querying.
- In this regard, the links to external repositories have been used to enrich the original data in order to facilitate data reuse and interoperability. Thus, in our use case, the links to GeoNames and Wikidata have allowed to add contextual information to original data.
2. Background and Related Work
2.1. Background Concepts
- Ontology. Ontologies offer a formal model of concepts of interest (classes), features and attributes of each concept (properties) and property restrictions, involving a specific knowledge domain in the real world [9,10]. Ontologies are a layer of the W3C standard stack (https://www.w3.org/standards/semanticweb/ (visited on 24 October 2019)). A knowledge base is made up of an ontology and its instances (set of class and property individuals). A knowledge base provides services to make heterogeneous systems and databases interoperability easier.
- OWL. The Ontology Web Language (OWL) is an extension of RDF and RFFS for defining machine understandable ontologies on the Web. From a formal point of view, an OWL ontology corresponds to a TBox in the context of a very expressive DL (description logic) [13]. Thanks to the equivalence of OWL with DL, OWL-DL provides maximum expressiveness while keeping computational completeness and decidability [14].
2.2. Related Work
3. Proposed Approach
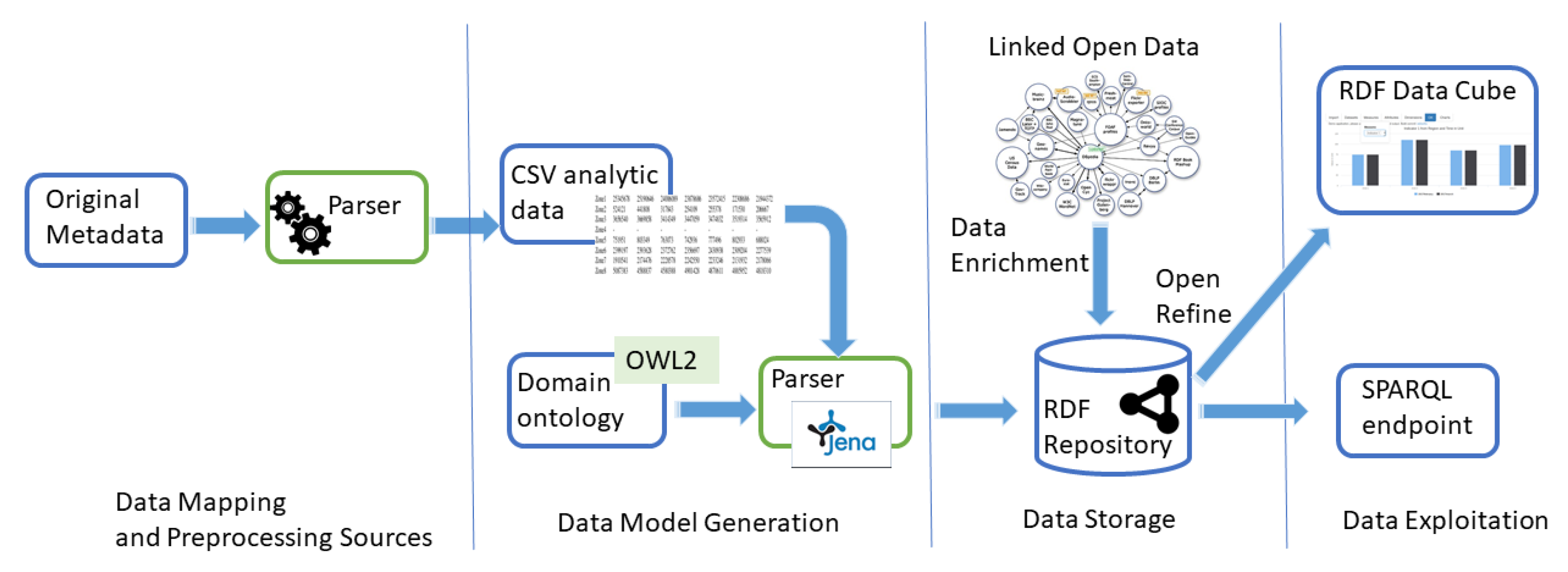
- Data mapping and pre-processing of sources: The way in which the dataset is published is vital to enhance its management, exploitation and reuse. The dataset format defines the structure of the published data which will be used by both human and machines. Different formats are used by institutions to publish their data: (1) CSV (Comma Separated Files) is the most used format due to its simplicity, it is highly reusable and machine-readable; (2) XLS allows the use of macros and formulas, which may be challenging to handle, to obtain advanced calculations in a readable format; (3) XML, RDF and JSON provide a more detailed information of source data including the semantics [33].However, due to the heterogeneity of data sources regarding data formats and vocabularies, a pre-processing step of the data is compulsory. This process allows data from different institutions and organizations to be processed in a similar way. The pre-processing consists of ETL (Extract-Transformation-Load) tools [34] and parsers in order to obtain normalized information from source data.
- Data model generation: The guide Best practices for publishing Linked Data proposed by the W3C Government Linked Data Working Group recommends the use of standardized vocabularies to improve the published Linked Data facilitating its usage and expansion [32]. However, in some cases, it is necessary to build an ontology reusing existing ontologies or from scratch. Lately, Protégé [35] have attracted strong interest from the research community to construct a large number of diverse intelligent systems, in particular ontologies covering different domains, such as biomedicine, e-commerce or organizational modeling.This step also includes the definition of a method to transform the source data into RDF, a machine readable language. RDF facilitates the interoperability and the definition of connections or links to other repositories. The process of conversion to RDF may be done either in batch mode or in an interactive way (for example using graphic applications). We can mention two representative tools: (1) Jena (https://jena.apache.org/documentation/rdf/index.html (visited on 4 February 2019)) is an open source Semantic Web framework for Java. It allows the definition and manipulation of RDF graphs. The graph is represented as an abstract “model” in which classes are used to represent resources, properties and literals. (2) OpenRefine (https://github.com/OpenRefine/OpenRefine (visited on 4 February 2019)) is an open source desktop application to transform raw data into a machine-readable format. The transformations (actions) to be made are defined by the user and stored in a project. Subsequently, a graphical mapping from the project to an RDF skeleton is carried out. Finally, it is exported in RDF format.
- Data storage: The Semantic Web is an extension of the Web through standards by the W3C. The standards promote common data formats and exchange protocols on the Web, most fundamentally the RDF. This has led to a considerable increase of RDF data on the web. Consequently, a set of techniques have been proposed for storing RDF data. Different works have previously studied the RDF data storage in an efficient way [36,37] allowing inference, update, scalability, distribution, or SPARQL endpoint.In addition, datasets can be enriched by means of external links in order to add information related to the context. In general, the connection process to external repositories consists of two stages: (i) automatic parsing of source information in order to unveil possible links to external sources; (ii) manual validation of the candidate links carried out by experts in data curation. In this stage, different tools (See, for example, https://tools.wmflabs.org/mix-n-match/ (visited on 4 February 2019)) can be used to facilitate data curation. The selected links will be defined through the owl:sameAs relationship.Nowadays, we can mention different representative repositories used as external source data: (1) GeoNames is a geographical database available and accessible through various web services; it allows the linking of source textual information to geographical locations and currently is one of the most used external repositories [38]. (2) DBpedia is a project aiming to extract structured content from the information created in various Wikimedia projects; it is a Knowledge Graph which stores knowledge in a machine-readable format. (3) Wikidata is a collaboratively edited knowledge base hosted by the Wikimedia Foundation and is also a Knowledge Graph; it is a document-oriented database, focused on items, which represent topics, concepts, or objects. (4) Many institutions rely on VIAF (http://viaf.org/ (visited on 4 February 2019)) to connect authority data.The tools to validate and check data integrity help to enhance its correctness and consistency. For example, constraints provide one method of implementing business rules. Other tools are based on test driven data-debugging frameworks that can run automatically generated (based on a schema) and manually generated test cases against an SPARQL endpoint [39].
- Data exploitation: The publication of data as LOD allows data reuse. The use of standard vocabularies based on RDF enhances the interoperability, the reuse and the exploitation by other institutions. SPARQL endpoints not only facilitate the access to the data, but also enable federated queries run on other SPARQL endpoints.Linked data also enhance the inference of new knowledge by discovering new relationships and automatically analyzing the content of the data, such as identifying possible inconsistencies [40]. Many experiments have been conducted regarding this area [41,42]. In general, inference takes into account the transitivity of predicates such as rdfs:subClassOf and rdfs:subPropertyOf.
4. Use Case
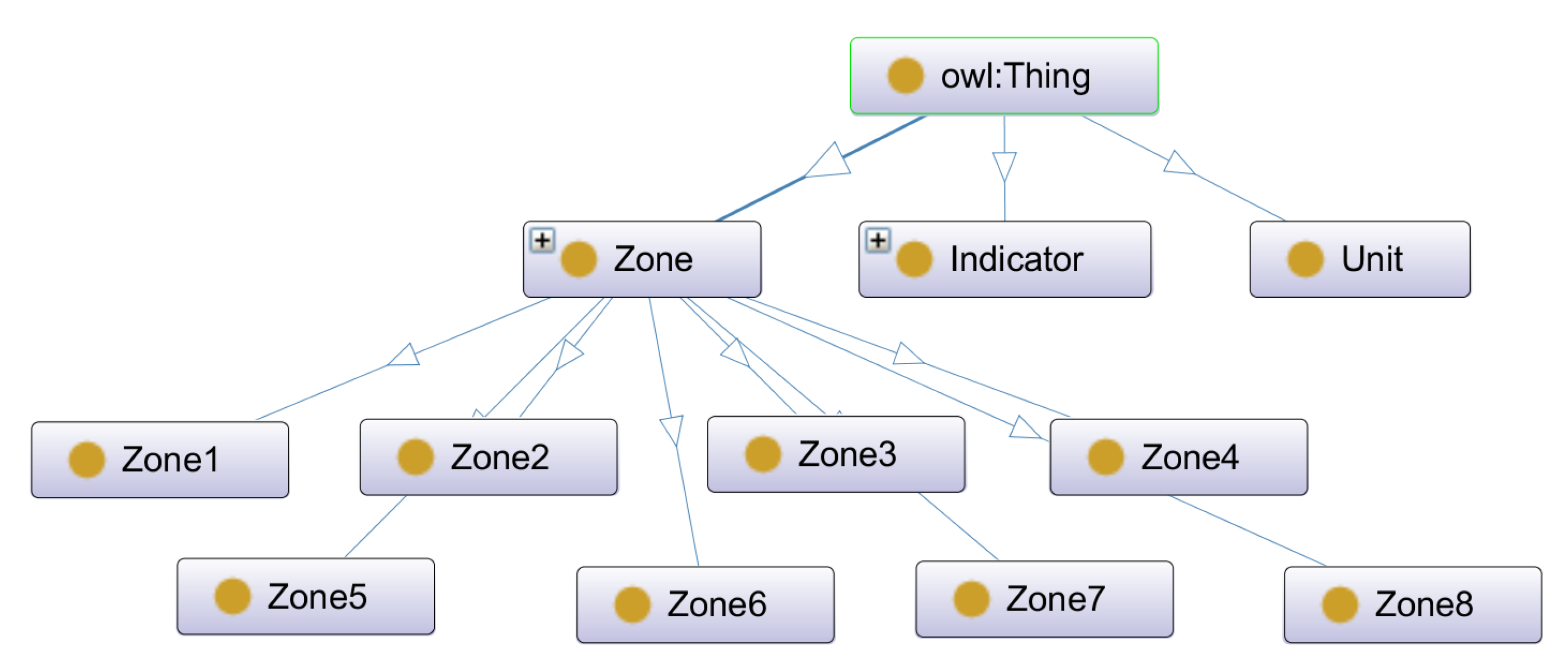
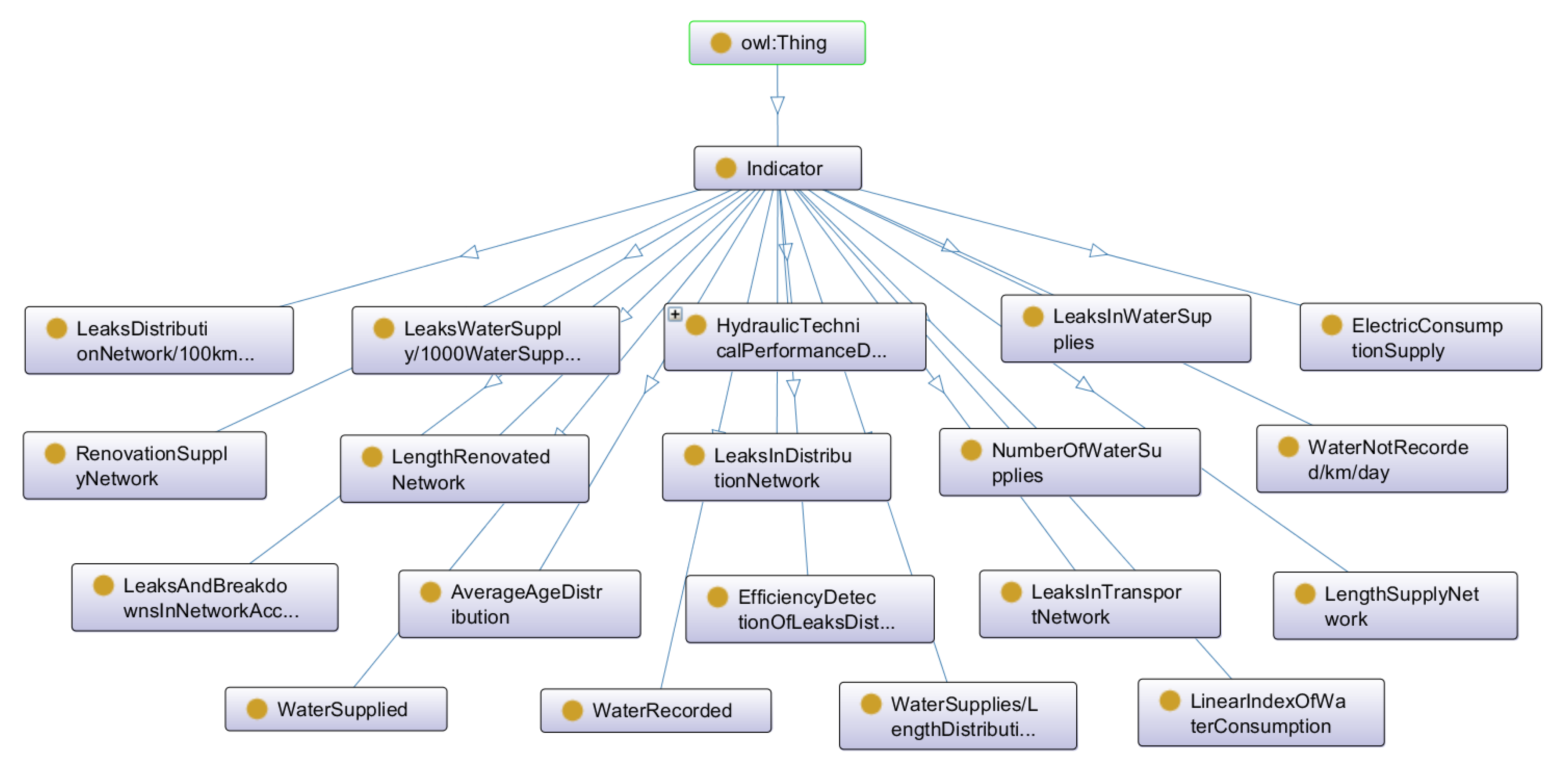
4.1. Water Supply Network Ontology
Technical Details of Water Ontology
4.2. Application to Water Supply Networks Management
water:zone1 owl:sameAs <http://www.wikidata.org/entity/Q935589>.
SELECT ?year ?value ?unit
WHERE {
water:zona6.3 water:hasLengthSupplyNetwork ?length .
?length water:inYear ?year .
?length water:unit ?unit .
?length water:value ?value}
ORDER BY ?year
}
SELECT waterSupplied ?population
WHERE {
water:Zone4.1 water:hasWaterSupplied ?waterSupplied .
water:Zone4.1 owl:sameas ?wikidataLink.
?waterSupplied water:inYear ?year .
BIND(concat("", ?year) as ?yearTr)
?waterSupplied water:value ?value-.
FILTER(regex(str(?wikidataLink), “wikidata”))
SERVICE <https://query.wikidata.org/sparql> {
?wikidataLink p:P1082 ?populationStatement.
?populationStatement ps:P1082 ?population;
pq:P585 ?date.
FILTER(xsd:integer(YEAR(?date)) = xsd:integer(?yearTr))
}
}
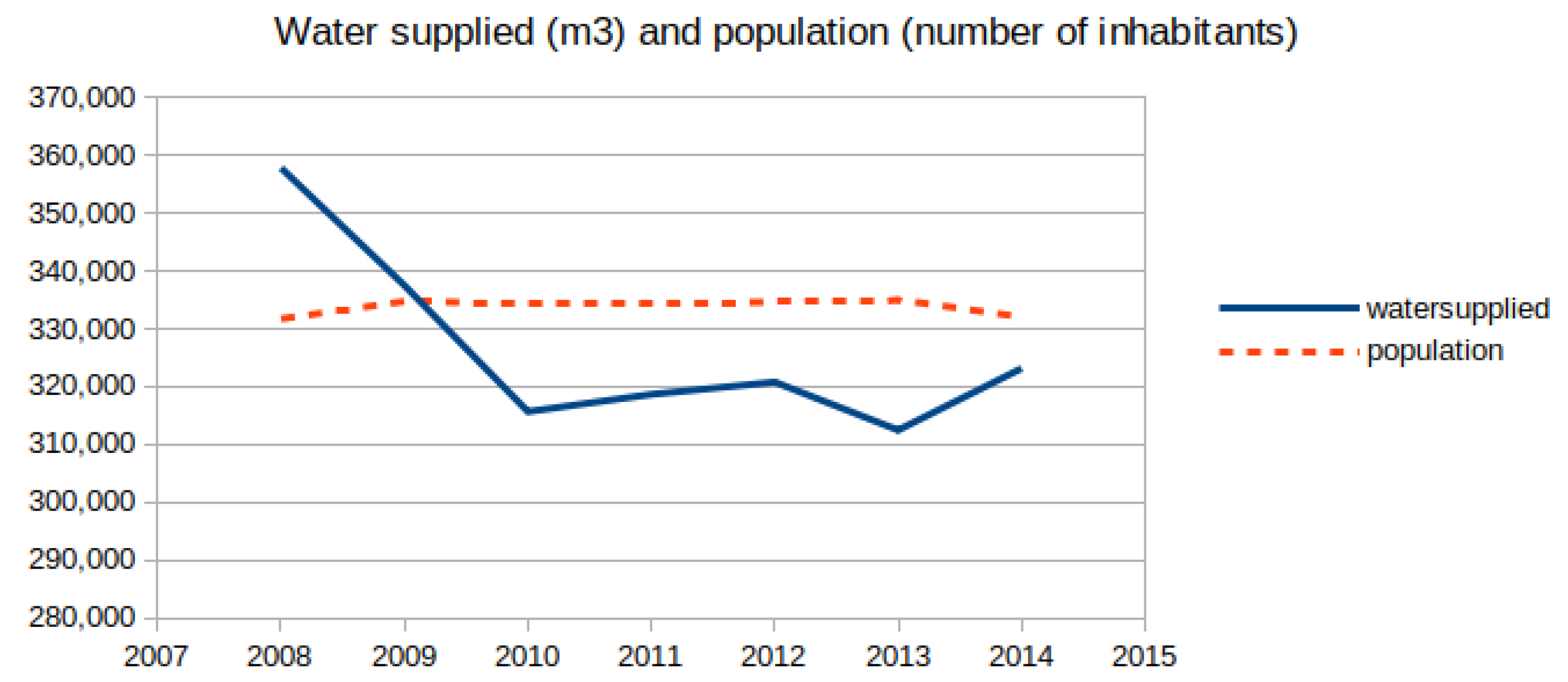
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Joshi, B. Novel Water Sustainability Technologies: Key Projects and Opportunities, Financing, and Venture Capital, Transactions and Trends; BCC Research Report, MST074A; BCC Research: Wellesley, MA, USA, 2019. [Google Scholar]
- Ponce Romero, J.M.; Hallett, S.H.; Jude, S. Leveraging Big Data Tools and Technologies: Addressing the Challenges of the Water Quality Sector. Sustainability 2017, 9, 2160. [Google Scholar] [CrossRef] [Green Version]
- Vázquez Loaiza, J.P.; Pérez-Torres, A.; Díaz Contreras, K.M. Semantic Icons: A Sentiment Analysis as a Contribution to Sustainable Tourism. Sustainability 2019, 11, 4655. [Google Scholar] [CrossRef] [Green Version]
- Gayoso-Cabada, J.; Goicoechea-de Jorge, M.; Gómez-Albarrán, M.; Sanz-Cabrerizo, A.; Sarasa-Cabezuelo, A.; Sierra, J.L. Ontology-Enhanced Educational Annotation Activities. Sustainability 2019, 11, 4455. [Google Scholar] [CrossRef] [Green Version]
- Konys, A. Green Supplier Selection Criteria: From a Literature Review to a Comprehensive Knowledge Base. Sustainability 2019, 11, 4208. [Google Scholar] [CrossRef] [Green Version]
- Curry, E.; Degeler, V.; Clifford, E.; Coakley, D. Linked Water Data For Water Information Management. In Proceedings of the 11th International Conference on Hydroinformatics (HIC 2014), New York, NY, USA, 17–21 August 2014. [Google Scholar]
- Gruber, T.R. Toward principles for the design of ontologies used for knowledge sharing? Int. J. Hum. Comput. Stud. 1995, 43, 907–928. [Google Scholar] [CrossRef]
- Barba-González, C.; García-Nieto, J.; del Mar Roldán-García, M.; Navas-Delgado, I.; Nebro, A.J.; Aldana-Montes, J.F. BIGOWL: Knowledge centered Big Data analytics. Expert Syst. Appl. 2019, 115, 543–556. [Google Scholar] [CrossRef]
- Noy, N.F.; McGuinness, D.L. Ontology Development 101: A Guide to Creating Your First, Ontology; Stanford University: Stanford, CA, USA, 2001. [Google Scholar]
- Guarino, N. Formal ontology and information systems. In Proceedings of the FOIS, Trento, Italy, 6–8 June 1998; Volume 98, pp. 81–97. [Google Scholar]
- McBride, B. The resource description framework (RDF) and its vocabulary description language RDFS. In Handbook on Ontologies; Springer: Berlin, Germany, 2004; pp. 51–65. [Google Scholar]
- Staab, S.; Studer, R. Handbook on Ontologies; Springer Science & Business Media: Berlin, Germany, 2013. [Google Scholar]
- Gruber, T.R. A translation approach to portable ontology specifications. Knowl. Acquis. 1993, 5, 199–220. [Google Scholar] [CrossRef]
- McGuinness, D.L.; Van Harmelen, F. OWL web ontology language overview. W3C Recomm. 2004, 10, 2004. [Google Scholar]
- Harris, S.; Seaborne, A.; Prud’hommeaux, E. SPARQL 1.1 query language. W3C Recomm. 2013, 21, 1–6. [Google Scholar]
- Prud, E.; Seaborne, A. SPARQL Query Language for RDF. Available online: https://www.w3.org/2001/sw/DataAccess/rq23/ (accessed on 3 December 2019).
- David, B.; Read, E.; Lucido, J.; Slawecki, T.; Young, T. An analysis of water data systems to inform the Open Water Data Initiative. J. Am. Water Resour. Assoc. 2016, 52, 845–858. [Google Scholar] [CrossRef] [Green Version]
- Bianchini, D.; Antonellis, V.D.; Garda, M.; Melchiori, M. Exploiting Smart City Ontology and Citizens’ Profiles for Urban Data Exploration. In On the Move to Meaningful Internet Systems, Proceedings of the OTM 2018 Conferences—Confederated International Conferences: CoopIS, C&TC, and ODBASE 2018, Valletta, Malta, 22–26 October 2018; Proceedings, Part I; Lecture Notes in Computer Science; Panetto, H., Debruyne, C., Proper, H.A., Ardagna, C.A., Roman, D., Meersman, R., Eds.; Springer: Berlin, Germany, 2018; Volume 11229, pp. 372–389. [Google Scholar] [CrossRef]
- Rani, M.; Alekh, S.; Bhardwaj, A.; Gupta, A.; Vyas, O.P. Ontology-based Classification and Analysis of non-emergency Smart-city Events. In Proceedings of the 2016 International Conference on Computational Techniques in Information and Communication Technologies (ICCTICT), New Delhi, India, 11–13 March 2016. [Google Scholar]
- Goel, D.; Chaudhury, S.; Ghosh, H. Smart Water Management: An Ontology-Driven Context-Aware IoT Application. In Pattern Recognition and Machine Intelligence, Proceedings of the 7th International Conference, PReMI 2017, Kolkata, India, 5–8 December 2017; Lecture Notes in Computer Science; Shankar, B.U., Ghosh, K., Mandal, D.P., Ray, S.S., Zhang, D., Pal, S.K., Eds.; Springer: Berlin, Germany, 2017; Volume 10597, pp. 639–646. [Google Scholar] [CrossRef]
- Ahmedi, L.; Jajaga, E.; Ahmedi, F. An Ontology Framework for Water Quality Management. In Proceedings of the 6th International Workshop on Semantic Sensor Networks co-located with the 12th International Semantic Web Conference (ISWC 2013), Sydney, Australia, 22 October 2013; Corcho, Ó., Henson, C.A., Barnaghi, P.M., Eds.; CEUR Workshop Proceedings. CEUR-WS: Aachen, Germany, 2013; Volume 1063, pp. 35–50. [Google Scholar]
- Katsiri, E.; Makropoulos, C. An ontology framework for decentralized water management and analytics using wireless sensor networks. Desalin. Water Treat. 2016, 57, 26355–26368. [Google Scholar] [CrossRef]
- de Rivera, D.S.; Robles, T.; López, J.A.; de Miguel, A.S.; de la Cruz, M.N.; Martínez, J.A.; Skarmeta, A.F.; Gómez, M.S.I. Adaptation of Ontology Sets for Water Related Scenarios Management with IoT Systems for a More Productive and Sustainable Agriculture Systems. In Proceedings of the SEMANTiCS 2017 Workshops co-Located with the 13th International Conference on Semantic Systems (SEMANTiCS 2017), Amsterdam, The Netherlands, 11–14 September 2017; Fensel, A., Daniele, L., Aroyo, L., de Boer, V., Darányi, S., Elloumi, O., García-Castro, R., Hollink, L., Inel, O., Kuys, G., et al., Eds.; CEUR Workshop Proceedings. CEUR-WS: Aachen, Germany, 2017; Volume 2063. [Google Scholar]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z.G. DBpedia: A Nucleus for a Web of Open Data. In The Semantic Web, 6th International Semantic Web Conference, Proceedings of the2nd Asian Semantic Web Conference, ISWC 2007 + ASWC 2007, Busan, Korea, 11–15 November 2007; Aberer, K., Choi, K., Noy, N.F., Allemang, D., Lee, K., Nixon, L.J.B., Golbeck, J., Mika, P., Maynard, D., Mizoguchi, R., et al., Eds.; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2007; Volume 4825, pp. 722–735. [Google Scholar] [CrossRef] [Green Version]
- Tanon, T.P.; Vrandecic, D.; Schaffert, S.; Steiner, T.; Pintscher, L. From Freebase to Wikidata: The Great Migration. In Proceedings of the 25th International Conference on World Wide Web, WWW 2016, Montreal, QC, Canada, 11–15 April 2016; pp. 1419–1428. [Google Scholar] [CrossRef] [Green Version]
- Rebele, T.; Suchanek, F.M.; Hoffart, J.; Biega, J.; Kuzey, E.; Weikum, G. YAGO: A Multilingual Knowledge Base from Wikipedia, Wordnet, and Geonames. In Proceedings of the Semantic Web—ISWC 2016—15th International Semantic Web Conference, Kobe, Japan, 17–21 October 2016; Proceedings, Part II Lecture Notes in Computer Science. Groth, P.T., Simperl, E., Gray, A.J.G., Sabou, M., Krötzsch, M., Lécué, F., Flöck, F., Gil, Y., Eds.; Springer: Berlin, Germany, 2016; Volume 9982, pp. 177–185. [Google Scholar] [CrossRef]
- Färber, M.; Bartscherer, F.; Menne, C.; Rettinger, A. Linked data quality of DBpedia, Freebase, OpenCyc, Wikidata, and YAGO. Semant. Web 2018, 9, 77–129. [Google Scholar] [CrossRef]
- European Data Portal. Re-Using Open Data. 2017. Available online: https://www.europeandataportal.eu/sites/default/files/re-using_open_data.pdf (accessed on 3 December 2019).
- Cyganiak, R.; Reynolds, D. The RDF Data Cube Vocabulary. 2014. Available online: https://www.w3.org/TR/vocab-data-cube/ (accessed on 8 April 2018).
- Bernadette Hyland, D.W. The Joy of Data—Cookbook for Publishing Linked Government Data on the Web. 2011. Available online: http://www.w3.org/2011/gld/wiki/Linked_Data_Cookbook (accessed on 3 December 2019).
- Villazón-Terrazas, B.; Vilches-Blázquez, L.M.; Corcho, O.; Gómez-Pérez, A. Methodological Guidelines for Publishing Government Linked Data. In Linking Government Data; Wood, D., Ed.; Springer: New York, NY, USA, 2011; pp. 27–49. [Google Scholar] [CrossRef]
- Hyland, B.; Atemezing, G.; Villazón-Terrazas, B. Best Practices for Publishing Linked Data. W3C Working Group Note. 9 January 2014. Available online: https://www.w3.org/TR/ld-bp/ (accessed on 20 May 2018).
- International, O.K. Open Data Handbook: File Formats. 2012. Available online: http://opendatahandbook.org/guide/en/appendices/file-formats/ (accessed on 7 April 2018).
- Bansal, S.K. Towards a Semantic Extract-Transform-Load (ETL) Framework for Big Data Integration. In Proceedings of the 2014 IEEE International Congress on Big Data, Anchorage, AK, USA, 27 June–2 July 2014; pp. 522–529. [Google Scholar] [CrossRef]
- Musen, M.A. The protégé project: A look back and a look forward. AI Matters 2015, 1, 4–12. [Google Scholar] [CrossRef] [PubMed]
- Pan, Z.; Zhu, T.; Liu, H.; Ning, H. A survey of RDF management technologies and benchmark datasets. J. Ambient Intell. Humaniz. Comput. 2018, 9, 1693–1704. [Google Scholar] [CrossRef]
- Faye, D.; Curé, O.; Blin, G. A survey of RDF storage approaches. ARIMA J. 2012, 15, 11–35. [Google Scholar]
- Acheson, E.; Sabbata, S.D.; Purves, R.S. A quantitative analysis of global gazetteers: Patterns of coverage for common feature types. Comput. Environ. Urban Syst. 2017, 64, 309–320. [Google Scholar] [CrossRef] [Green Version]
- Kontokostas, D.; Westphal, P.; Auer, S.; Hellmann, S.; Lehmann, J.; Cornelissen, R. Databugger: A test-driven framework for debugging the web of data. In Proceedings of the 23rd International World Wide Web Conference, WWW ’14, Seoul, Korea, 7–11 April 2014; Companion Volume. Chung, C., Broder, A.Z., Shim, K., Suel, T., Eds.; pp. 115–118. [Google Scholar] [CrossRef]
- W3C. Inference. Available online: https://www.w3.org/standards/semanticweb/inference (accessed on 20 November 2018).
- Ren, X.; Curé, O.; Ke, L.; Lhez, J.; Belabbess, B.; Randriamalala, T.; Zheng, Y.; Képéklian, G. Strider: An Adaptive, Inference-enabled Distributed RDF Stream Processing Engine. PVLDB 2017, 10, 1905–1908. [Google Scholar] [CrossRef]
- Colucci, S.; Donini, F.M.; Sciascio, E.D. Reasoning over RDF Knowledge Bases: Where We Are. In AI*IA 2017 Advances in Artificial Intelligence, Proceesdings of the XVIth International Conference of the Italian Association for Artificial Intelligence, Bari, Italy, 14–17 November 2017; Esposito, F., Basili, R., Ferilli, S., Lisi, F.A., Eds.; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2017; Volume 10640, pp. 243–255. [Google Scholar] [CrossRef]
- Thivet, G.; Fernandez, S. Water Demand Management: The Mediterranean Experience; Technical Focus Paper; Global Water Partnership (GWP): Stockholm, Sweden, 2012. [Google Scholar]
- INE. Estadística sobre el Suministro y Saneamiento del Agua, Año 2016. Notas de Prensa; Instituto Nacional de Estadística, 2018. Available online: https://www.ine.es/dyngs/INEbase/es/operacion.htm?c=Estadistica_C&cid=1254736176834&menu=ultiDatos&idp=1254735976602 (accessed on 3 December 2019).
- Dodds, L.; Davis, I. A Pattern Catalogue for Modelling, Publishing, and Consuming Linked Data. 2012. Available online: http://patterns.dataincubator.org (accessed on 6 November 2018).
- Pérez-Urbina, H.; Sirin, E.; Clark, K. Validating RDF with OWL Integrity Constraints. 2012. Available online: https://www.stardog.com/docs/4.1.3/icv/icv-specification (accessed on 29 October 2018).
- Maté, A.; Trujillo, J.; Mylopoulos, J. Key Performance Indicator Elicitation and Selection Through Conceptual Modelling. In Proceedings of the Conceptual Modeling—35th International Conference, ER 2016, Gifu, Japan, 14–17 November 2016; pp. 73–80. [Google Scholar] [CrossRef]
- Pearson, K. VII. Mathematical contributions to the theory of evolution.—III. Regression, heredity, and panmixia. Philos. Trans. R. Soc. Lond. Ser. A 1896, 187, 253–318. [Google Scholar]
- Spearman, C. The proof and measurement of association between two things. Am. J. Psychol. 1904, 72–101. [Google Scholar] [CrossRef]
- Hauke, J.; Kossowski, T. Comparison of values of Pearson’s and Spearman’s correlation coefficients on the same sets of data. Quaest. Geogr. 2011, 30, 87–93. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object Properties | Description Logic |
|---|---|
| unit | ∃ unit.Thing ⊑ Indicator |
| ⊤ ⊑ ∀ unit.Unit | |
| Data Properties | Description Logic |
| value | ∃ value.Datatype Literal ⊑ Indicator |
| ⊤ ⊑ ∀ value.Datatype double | |
| inYear | ∃ inYear.Datatype Literal ⊑ Indicator |
| ⊤ ⊑ ∀ inYear.Datatype integer |
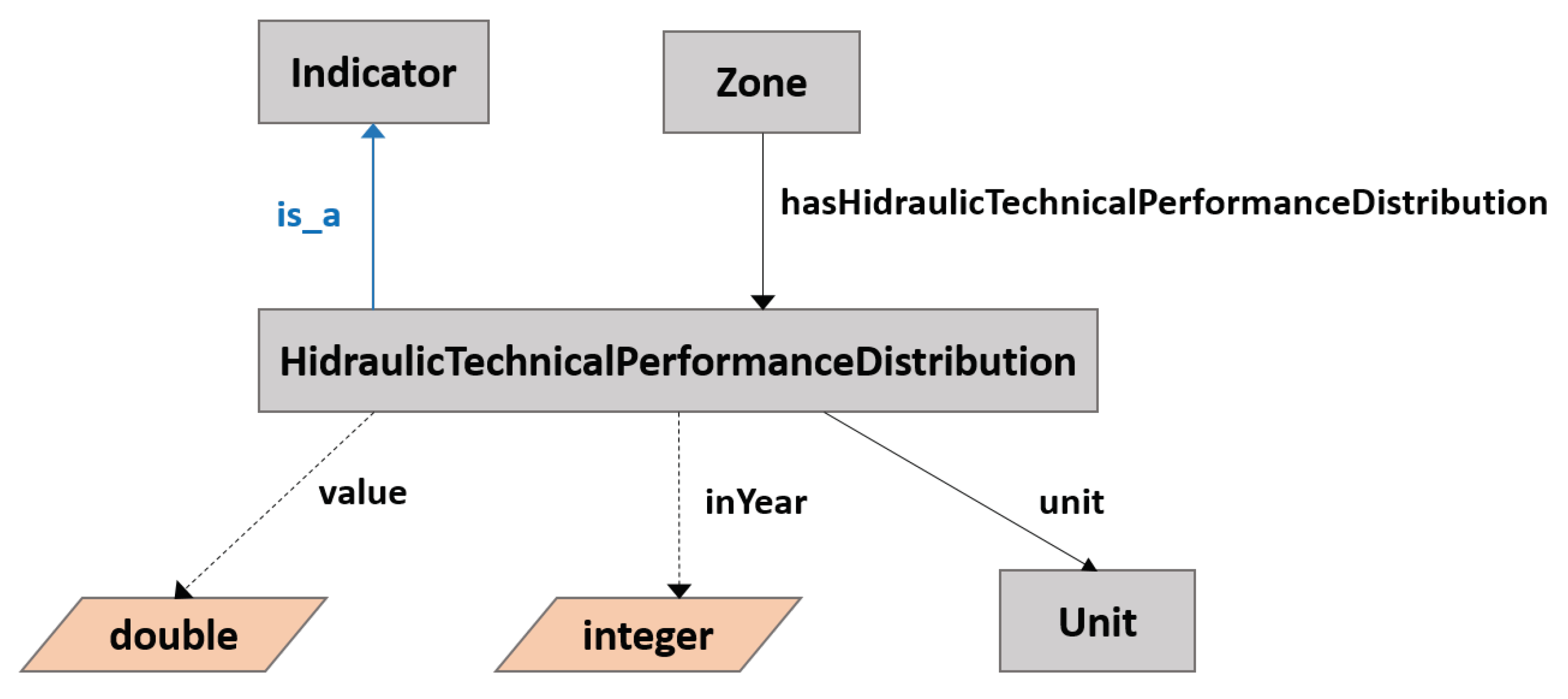
| Object Property | Description Logic |
|---|---|
| hasHydraulicTechnicalPerformanceDistribution | ⊑ hasIndicator |
| ∃ hasHydraulicTechnicalPerformanceDistribution.Thing | |
| ⊑ Zone | |
| ⊤ ⊑ ∀ hasHydraulicTechnicalPerformanceDistribution | |
| HydraulicTechnicalPerformanceDistribution | |
| classes | Description Logic |
| HydraulicTechnicalPerformanceDistribution | ⊑ Indicator |
| Zone | Measure1 | Measure2 | Measure3 | Measure4 | Measure5 | Measure6 | Measure7 |
|---|---|---|---|---|---|---|---|
| Zone1.1 | 25,345,678 | 25,190,646 | 24,006,089 | 23,878,686 | 23,572,415 | 22,308,686 | 21,944,372 |
| Zone1.2 | 524,121 | 441,808 | 317,843 | 254,109 | 255,378 | 171,530 | 206,667 |
| Zone1.3 | 3,656,540 | 3,669,858 | 3,414,349 | 3,447,059 | 3,474,832 | 3,519,314 | 3,565,912 |
| Zone1.4 | - | - | - | - | - | - | - |
| Zone1.5 | 751,951 | 803,349 | 763,073 | 742,936 | 777,496 | 802,933 | 688,024 |
| Zone1.6 | 2,399,197 | 2,393,628 | 2,372,762 | 2,356,697 | 2,430,938 | 2,309,204 | 2,277,539 |
| Zone1.7 | 1,910,541 | 2,174,476 | 2,228,578 | 2,242,550 | 2,233,246 | 2,131,932 | 2,178,066 |
| Zone1.8 | 5,087,383 | 4,588,837 | 4,580,388 | 4,901,428 | 4,870,611 | 4,885,952 | 4,818,310 |
| Entity | Pattern |
|---|---|
| Zone | …/zone/* |
| Water supply | …/hasNumberOfWaterSupplies/* |
| Water leaks | …/hasLeaksDistributionNetwork/* |
| Water not recorded | …/hasWaterNotRecorded/* |
| Length supply network | …/hasLengthSupplyNetwork/* |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Escobar, P.; Roldán-García, M.d.M.; Peral, J.; Candela, G.; García-Nieto, J. An Ontology-Based Framework for Publishing and Exploiting Linked Open Data: A Use Case on Water Resources Management. Appl. Sci. 2020, 10, 779. https://doi.org/10.3390/app10030779
Escobar P, Roldán-García MdM, Peral J, Candela G, García-Nieto J. An Ontology-Based Framework for Publishing and Exploiting Linked Open Data: A Use Case on Water Resources Management. Applied Sciences. 2020; 10(3):779. https://doi.org/10.3390/app10030779
Chicago/Turabian StyleEscobar, Pilar, María del Mar Roldán-García, Jesús Peral, Gustavo Candela, and José García-Nieto. 2020. "An Ontology-Based Framework for Publishing and Exploiting Linked Open Data: A Use Case on Water Resources Management" Applied Sciences 10, no. 3: 779. https://doi.org/10.3390/app10030779
APA StyleEscobar, P., Roldán-García, M. d. M., Peral, J., Candela, G., & García-Nieto, J. (2020). An Ontology-Based Framework for Publishing and Exploiting Linked Open Data: A Use Case on Water Resources Management. Applied Sciences, 10(3), 779. https://doi.org/10.3390/app10030779