Diversity Balancing for Two-Stage Collaborative Filtering in Recommender Systems

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Works
2.1. Social-Based Recommender Systems
2.2. Improving RS Diversity
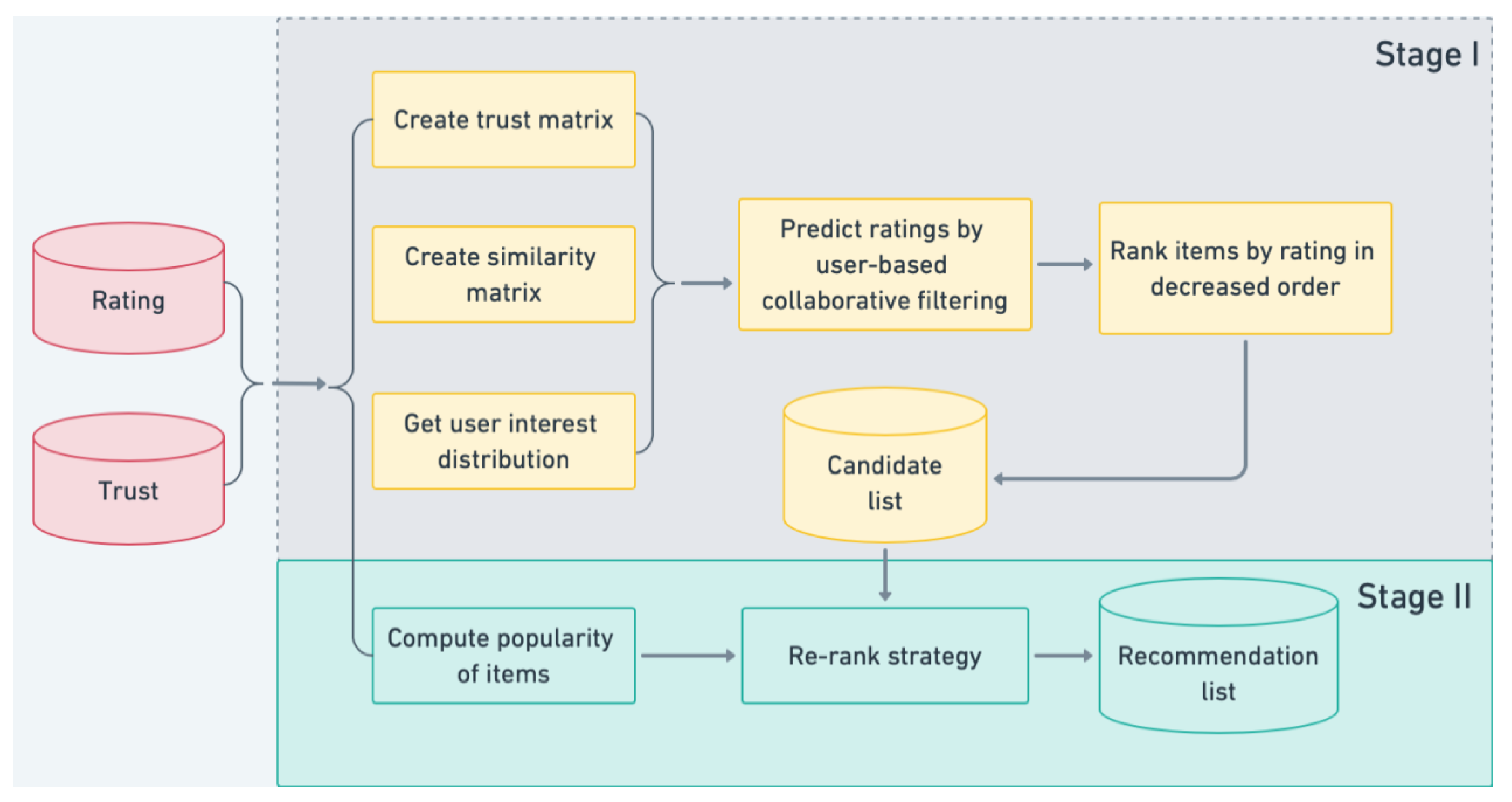
3. Diversity Balancing for Two-Stage Collaborative Filtering
3.1. Trust Ranking
3.2. User Interest Distribution
3.2.1. Acquisition of Item Category
3.2.2. User Interest Distributions
3.2.3. Trust and Interest Weight Aggregation
3.3. Rating Prediction and Top-N Re-Ranking
3.3.1. Rating Prediction
3.3.2. Top-N Re-Ranking
| Algorithm 1. Diversity Balancing for Two-Stage collaborative filtering (DBTS) |
| Input: rating matrix R, social trust matrix T, active user u, trust threshold θ, interest threshold γ, ranking strategy threshold β. Output: the top-N recommendation list. Begin //Stage I: calculate user similarities.
|
4. Experiments and Analysis of Results
4.1. Dataset
4.2. Evaluation Metrics
4.2.1. Accuracy Metrics
4.2.2. Diversity Metric
4.3. Sensitivity Analysis
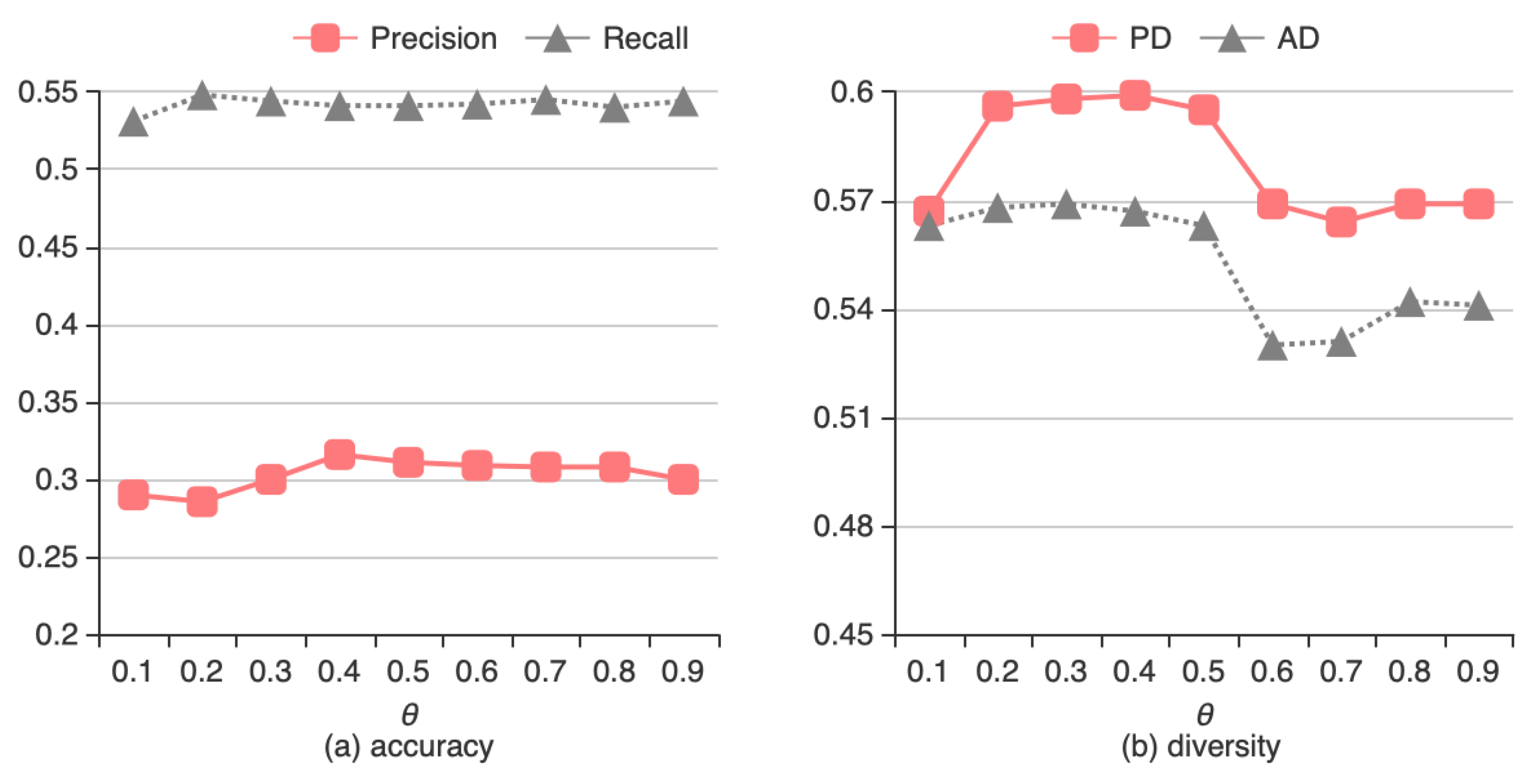
4.3.1. Effect of Trust Threshold θ
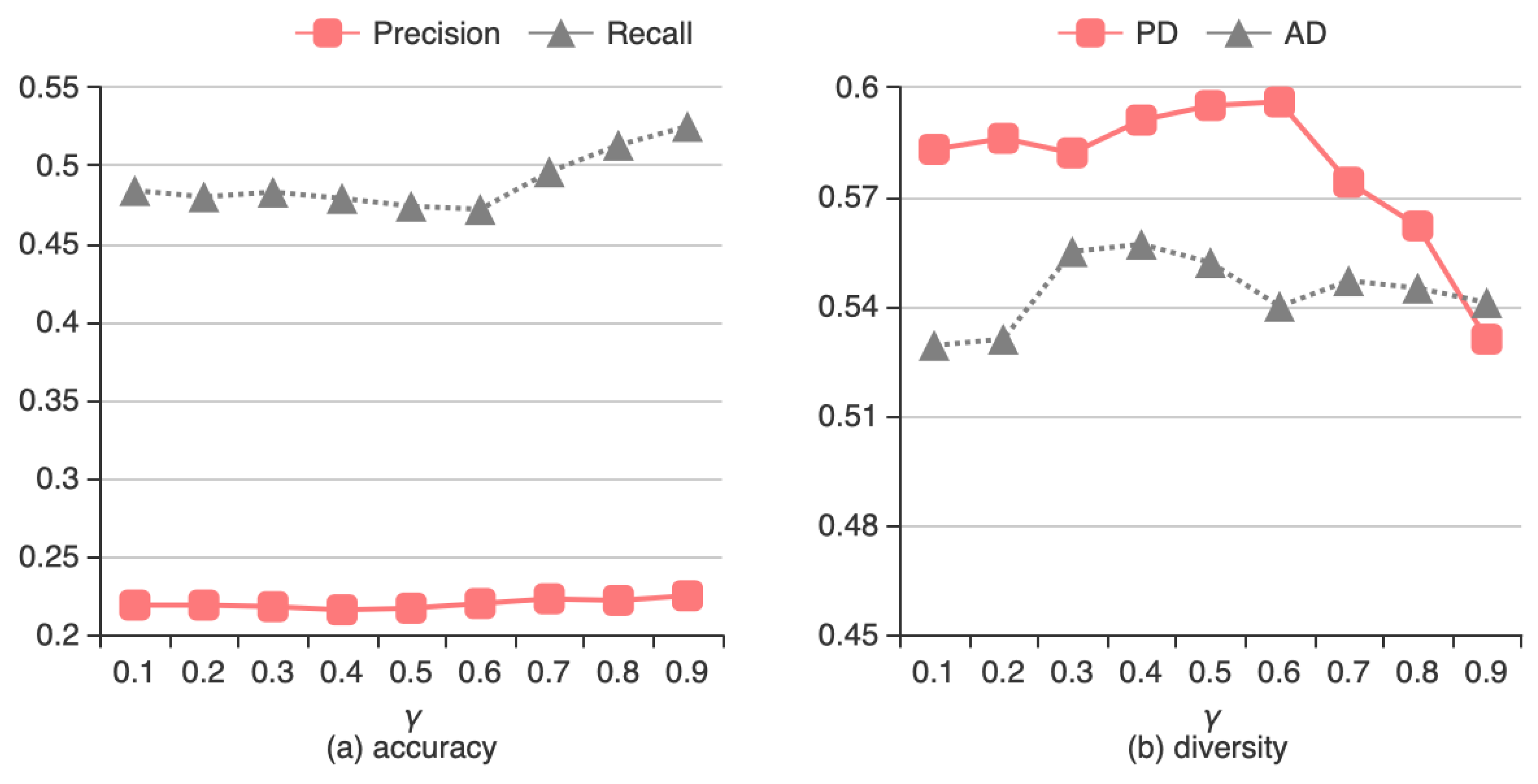
4.3.2. Effect of Interest Threshold γ
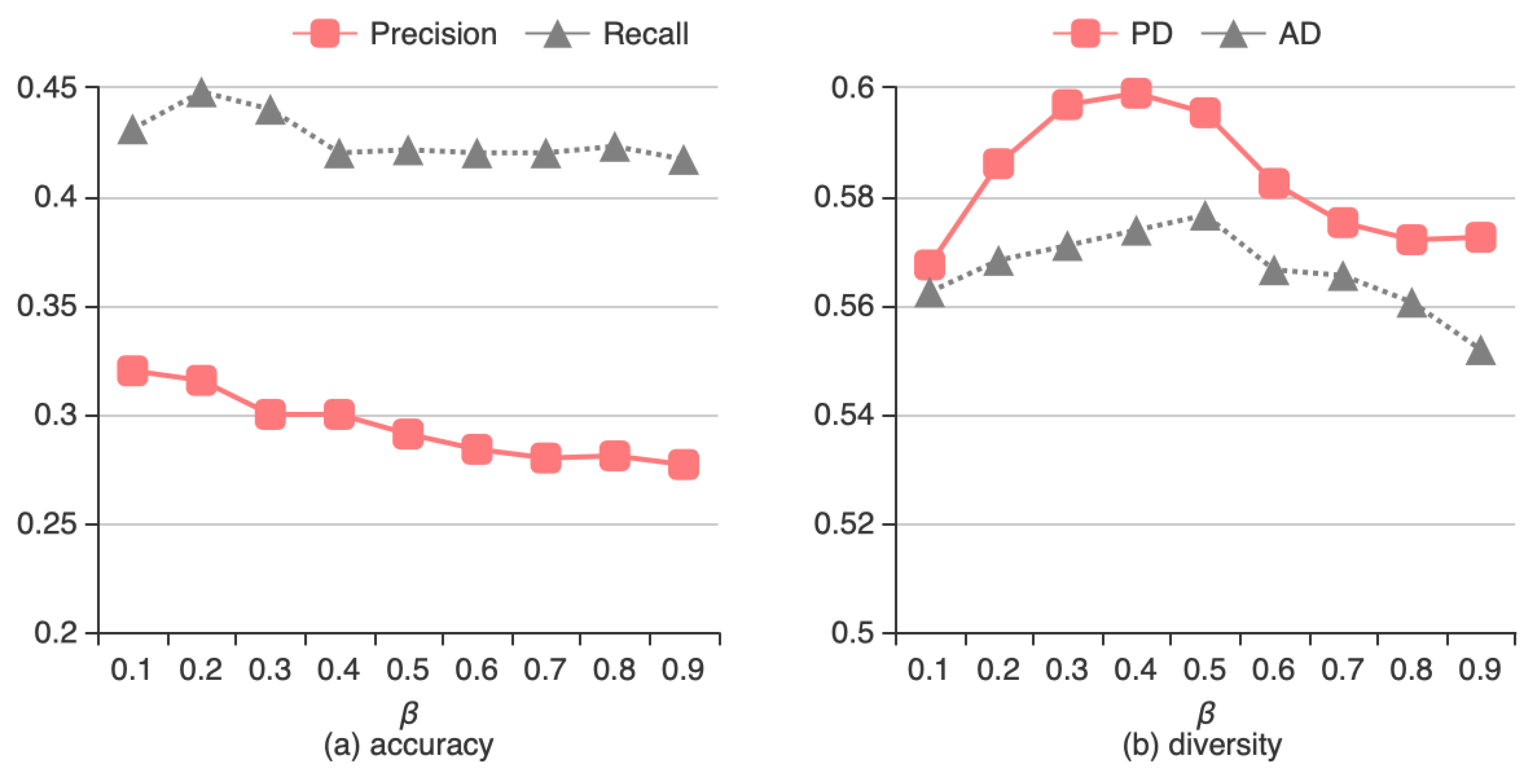
4.3.3. Effect of Weight Parameter β
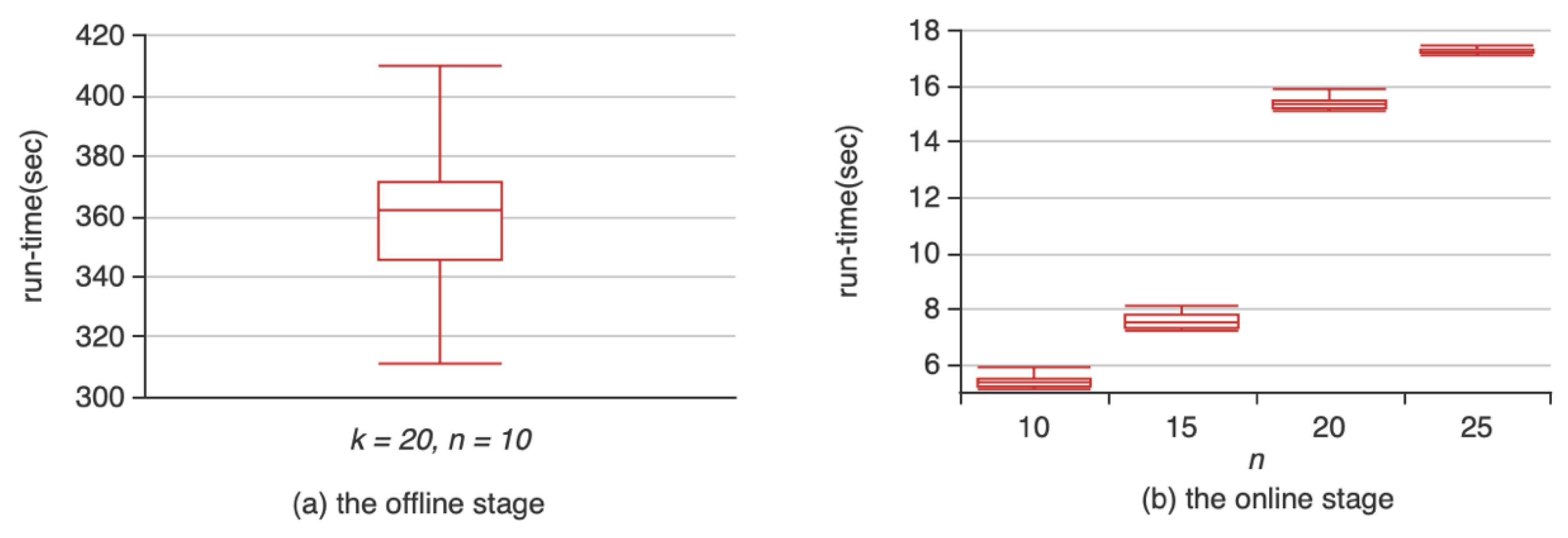
4.3.4. The Execution Time of DBTS
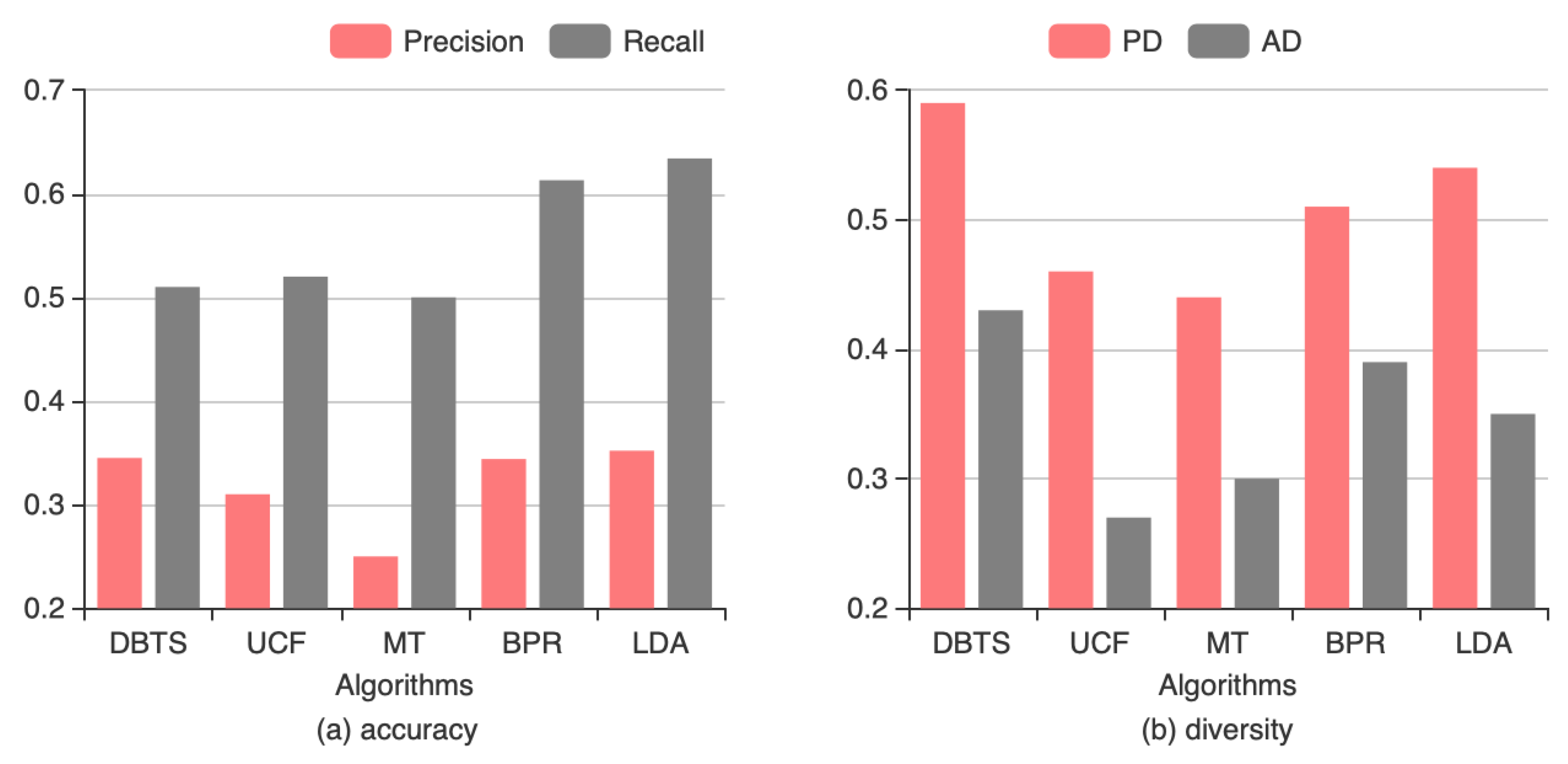
4.3.5. Discussion of Experimental Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Konstan, J.A.; Miller, B.N.; Maltz, D.; Herlocker, J.L.; Gordon, L.R.; Riedl, J. GroupLens: Applying collaborative filtering to Usenet news. Commun. ACM 2000, 40, 77–87. [Google Scholar] [CrossRef]
- Lu, J.; Wu, D.; Mao, M.; Wang, W.; Zhang, G. Recommender system application developments: A survey. Decis. Support Syst. 2015, 74, 12–32. [Google Scholar] [CrossRef]
- Cremonesi, P.; Koren, Y.; Turrin, R. Performance of recommender algorithms on top-N recommendation tasks. In Proceedings of the 2010 ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010. [Google Scholar]
- Balabanovic, M.; Shoham, Y. Content-based, collaborative recommendation. Commun. ACM 1997, 40, 66–72. [Google Scholar] [CrossRef]
- Wang, Z.; Sun, L.; Zhu, W.; Yang, S.; Li, H.; Wu, D. Joint social and content recommendation for user-generated videos in online social network. IEEE Trans. Multimed 2013, 15, 698–709. [Google Scholar] [CrossRef] [Green Version]
- Massa, P.; Avesani, P.; Tiella, R. A Trust-enhanced recommender system application: Moleskiing. In Proceedings of the 2005 ACM Symposium on Applied Computing, Santa Fe, New Mexico, 13–17 March 2005. [Google Scholar]
- Jamali, M.; Ester, M. A matrix factorization technique with trust propagation for recommendation in social networks. In Proceedings of the Fourth ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; pp. 135–142. [Google Scholar]
- Moradi, P.; Ahmadian, S.; Akhlaghian, F. An effective trust-based recommendation method using a novel graph clustering algorithm. Phys. A Stat. Mech. Its Appl. 2015, 436, 462–481. [Google Scholar] [CrossRef]
- Hernando, A.; Ortega, F. A probabilistic model for recommending to new cold-start non-registered users. Inf. Sci. 2017, 376, 216–232. [Google Scholar] [CrossRef]
- Lika, B.; Kolomvatsos, K.; Hadjiefthymiades, S. Facing the cold start problem in recommender systems. Expert Syst. Appl. 2014, 41, 2065–2073. [Google Scholar] [CrossRef]
- Afra, S.; Aksaç, A.; Õzyer, T.; Alhajj, R. Link prediction by network analysis. In Prediction and Inference from Social Networks and Social Media; Springer: Cham, Germany, 2017; pp. 97–114. [Google Scholar]
- Yang, B.; Lei, Y.; Liu, J.; Li, W. Social collaborative filtering by trust. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1633–1647. [Google Scholar] [CrossRef]
- Lu, Y.; Tsaparas, P.; Ntoulas, A.; Polanyi, L. Exploiting social context for review quality prediction. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 691–700. [Google Scholar]
- Ma, H.; Yang, H.; Lyu, M.R.; King, I. Sorec: Social recommendation using probabilistic matrix factorization. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; pp. 931–940. [Google Scholar]
- Ma, H.; King, I.; Lyu, M.R. Learning to recommend with social trust ensemble. In Proceedings of the 32nd International ACM SIGIR Conference on Research, Boston, MA, USA, 19–23 July 2009; pp. 203–210. [Google Scholar]
- Ma, H.; Zhou, D.; Liu, C.; Lyu, M.R.; King, I. Recommender systems with social regularization. In Proceedings of the fourth ACM International Conference on Web Search and Data Mining, Hong Kong, Chnia, 9–12 February 2011; pp. 287–296. [Google Scholar]
- Guo, G.; Zhang, J.; Smith, N.Y. TrustSVD: Collaborative filtering with both the explicit and implicit influence of user trust and of item ratings. In Proceedings of the AAAI, Hyatt Regency, Austin, TX, USA, 25–30 January 2015; pp. 123–129. [Google Scholar]
- Wang, J.C.; Chiu, C.C. Recommending trusted online auction sellers using social network analysis. Expert Syst. Appl. 2008, 34, 1666–1679. [Google Scholar] [CrossRef]
- Moradi, P.; Ahmadian, S. A reliability-based recommendation method to improve trust-aware recommender systems. Expert Syst. Appl. 2015, 42, 7386–7398. [Google Scholar] [CrossRef]
- Azadjalal, M.M.; Moradi, P.; Abdollahpouri, A.; Jalili, M. A trust-aware recommendation method based on Pareto dominance and confidence concepts. Knowl. Based Syst. 2016, 116, 130–143. [Google Scholar] [CrossRef]
- Koohi, H.; Kiani, K. A new method to find neighbor users that improves the performance of Collaborative Filtering. Expert Syst. Appl. 2017, 83, 30–39. [Google Scholar] [CrossRef]
- Kong, X.; Jiang, H.; Wang, W.; Bekele, T.M.; Xu, Z.; Wang, M. Exploring dynamic research interest and academic influence for scientific collaborator recommendation. Scientometrics 2017, 113, 369–385. [Google Scholar] [CrossRef]
- Davoodi, E.; Kianmehr, K.; Afsharchi, M. A semantic social network-based expert recommender system. Applied Intell. 2013, 39, 1–13. [Google Scholar] [CrossRef]
- Hamedani, E.M.; Kaedi, M. Recommending the long tail items through personalized diversification. Knowl. Based Syst. 2019, 125, 348–357. [Google Scholar] [CrossRef]
- Wang, S.F.; Gong, M.G.; Li, H.L.; Yang, J.W. Multi-objective optimization for long tail recommendation. Knowl. Based Syst. 2016, 104, 145–155. [Google Scholar] [CrossRef]
- Gogna, A.; Majumdar, A. DiABlO: Optimization based design for improving diversity in recommender system. Inf. Sci. 2017, 378, 59–74. [Google Scholar] [CrossRef]
- Gogna, A.; Majumdar, A. Balancing accuracy and diversity in recommendations using matrix completion framework. Knowl. Based Syst. 2017, 125, 83–95. [Google Scholar] [CrossRef] [Green Version]
- Hou, L.; Liu, K.; Liu, J.; Zhang, R.T. Solving the stability-accuracy-diversity dilemma of recommender systems. Phys. A Stat. Mech. Its Appl. 2016, 468, 415–424. [Google Scholar] [CrossRef] [Green Version]
- Hawalah, A.; Fasli, M. Utilizing contextual ontological user profiles for personalized recommendations. Expert Syst. Appl. 2014, 41, 4777–4797. [Google Scholar] [CrossRef]
- Shambour, Q.; Lu, J. An effective recommender system by unifying user and item trust information for B2B applications. J. Comput. Syst. Sci. 2015, 81, 1110–1126. [Google Scholar] [CrossRef]
- Yuan, W.W.; Guan, D.H.; Lee, Y.K.; Lee, S.U.; Hur, S.J. Improved trust-aware recommender system using small-worldness of trust networks. Knowl. Based Syst. 2010, 23, 232–238. [Google Scholar] [CrossRef]
- Guo, G.; Zhang, J.; Thalmann, D. Merging trust in collaborative filtering to alleviate data sparsity and cold start. Knowl. Based Syst. 2014, 57, 57–68. [Google Scholar] [CrossRef]
- Parvin, H.; Moradi, P.; Esmaeili, S. TCFACO: Trust-aware collaborative filtering method based on ant colony optimization. Expert Syst. Appl. 2019, 118, 152–168. [Google Scholar] [CrossRef]
- Lee, W.P.; Ma, C.Y. Enhancing collaborative recommendation performance by combining user preference and trust-distrust propagation in social networks. Knowl. Based Syst. 2016, 106, 125–134. [Google Scholar] [CrossRef]
- Pasquale, D.M.; Lidia, F.; Messina, F. Providing recommendations in social networks by integrating local and global reputation. Inf. Sci. 2018, 78, 58–67. [Google Scholar]
- Bedi, P.; Sharma, P. Trust based recommender system using ant colony for trust computation. Expert Syst. Appl. 2012, 39, 1183–1190. [Google Scholar] [CrossRef]
- Massa, P.; Avesani, P. Trust metrics on controversial users: Balancing between tyranny of the majority. Int. J. Semant. Web Inf. Syst. 2007, 3, 39–64. [Google Scholar] [CrossRef] [Green Version]
- Tommaso, D.N.; Rosati, J.; Tomeo, P.; Eugenio, D.S. Adaptive multi-attribute diversity for recommender systems. Inf. Sci. 2014, 328, 234–253. [Google Scholar]
- Vargas, S.; Castells, P. Improving sales diversity by recommending users to items. In Proceedings of the ACM Conference on Recommender Systems, ACM 2016, Boston, MA, USA, 15–19 September 2016; pp. 145–152. [Google Scholar]
- Pathak, A.; Patra, B.K. A knowledge reuse framework for improving novelty and diversity in recommendations. In Proceedings of the ACM Press the Second ACM IKDD Conference 2015, Bangalore, India, 18–21 March 2015; pp. 11–19. [Google Scholar]
- Adomavicius, G.; Kwon, Y.O. Improving aggregate recommendation diversity using ranking-based techniques. IEEE Trans. Knowl. Data Eng. 2012, 24, 896–911. [Google Scholar] [CrossRef]
- Wang, J.; Liu, Y.; Sun, J.; Jiang, Y.; Sun, C. Diversified recommendation incorporating item content information based on MOEA/D. In Proceedings of the 2016 49th Hawaii International Conference on System Sciences (HICSS), Koloa, HI, USA, 5–8 January 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Mingyang, W.; Chongchong, J.; Donghui, Y. Social friend recommendation mechanism based on three-degree influence. J. Comput. Appl. 2015, 35, 1984–1987. [Google Scholar]
- Steyvers, M.; Griffiths, T. Probabilistic topic models. Handb. Latent Semant. Anal. 2007, 427, 424–440. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian personalized ranking from implicit feedback. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, Vancouver, BC, Canada, 19–22 July 2009; AUAI Press: Barcelona, Spain, 2009; pp. 452–461. [Google Scholar]






© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Wei, Q.; Zhang, L.; Wang, B.; Ho, W.-H. Diversity Balancing for Two-Stage Collaborative Filtering in Recommender Systems. Appl. Sci. 2020, 10, 1257. https://doi.org/10.3390/app10041257
Zhang L, Wei Q, Zhang L, Wang B, Ho W-H. Diversity Balancing for Two-Stage Collaborative Filtering in Recommender Systems. Applied Sciences. 2020; 10(4):1257. https://doi.org/10.3390/app10041257
Chicago/Turabian StyleZhang, Liang, Quanshen Wei, Lei Zhang, Baojiao Wang, and Wen-Hsien Ho. 2020. "Diversity Balancing for Two-Stage Collaborative Filtering in Recommender Systems" Applied Sciences 10, no. 4: 1257. https://doi.org/10.3390/app10041257
APA StyleZhang, L., Wei, Q., Zhang, L., Wang, B., & Ho, W. -H. (2020). Diversity Balancing for Two-Stage Collaborative Filtering in Recommender Systems. Applied Sciences, 10(4), 1257. https://doi.org/10.3390/app10041257