Comparative Study on Supervised Learning Models for Productivity Forecasting of Shale Reservoirs Based on a Data-Driven Approach


Abstract
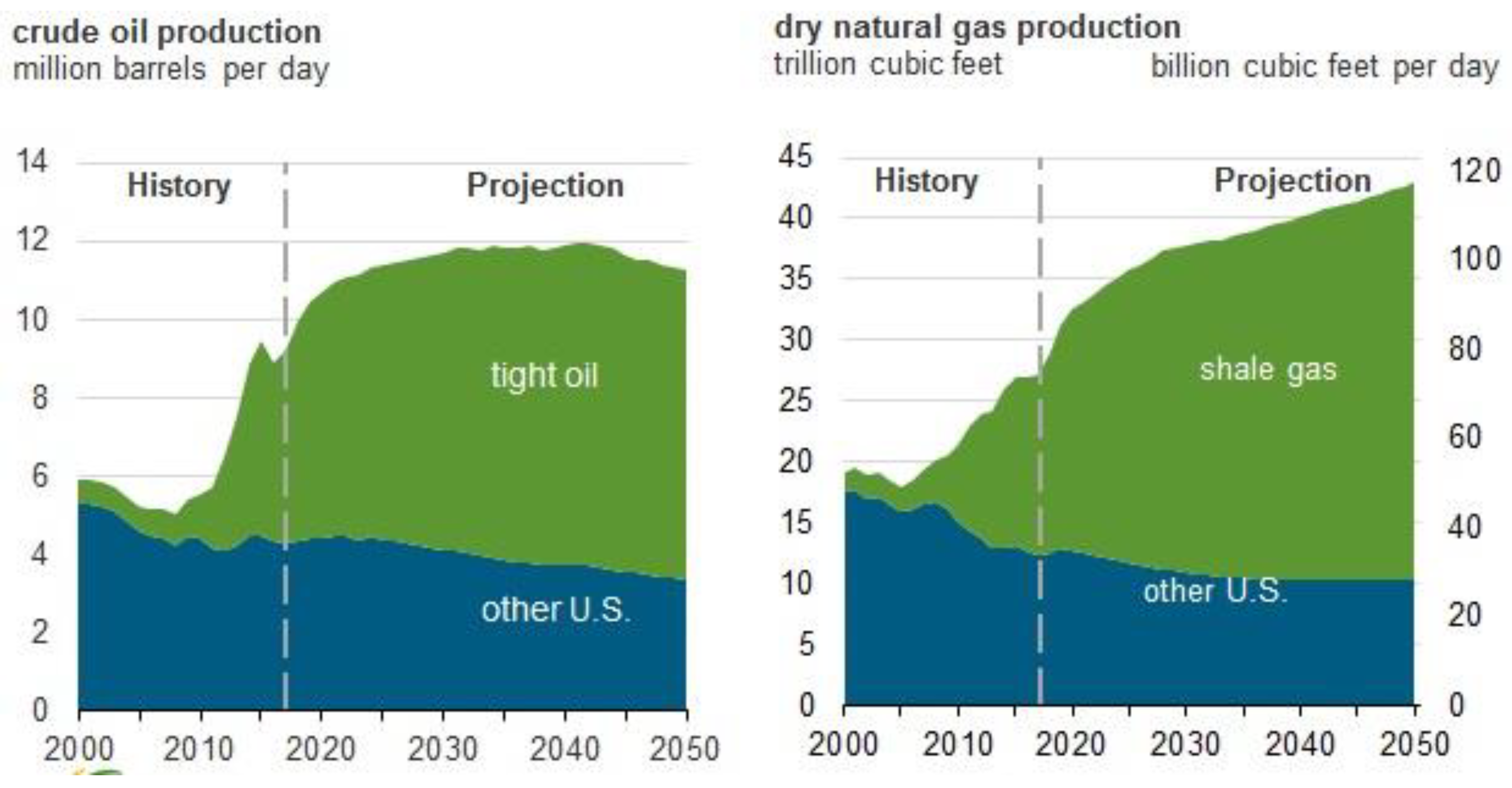
:1. Introduction
- First, our work considers the overfitting problem caused by unnecessary input features of prediction models. To further enhance the predictive performance of our machine learning model, we performed an RF-based variables importance method and statistical analysis to eliminate unnecessary input features.
- Second, after removing input features using VIM, general supervised learning models, including random forest, gradient boosting tree, and support vector machine were evaluated, and we selected the best model to predict productivity in Eagle Ford shale reservoirs.
- Third, to enhance the prediction model performance, clustering analysis was used, and the supervised learning model for each cluster was re-trained and compared with the results.
2. Materials and Methods
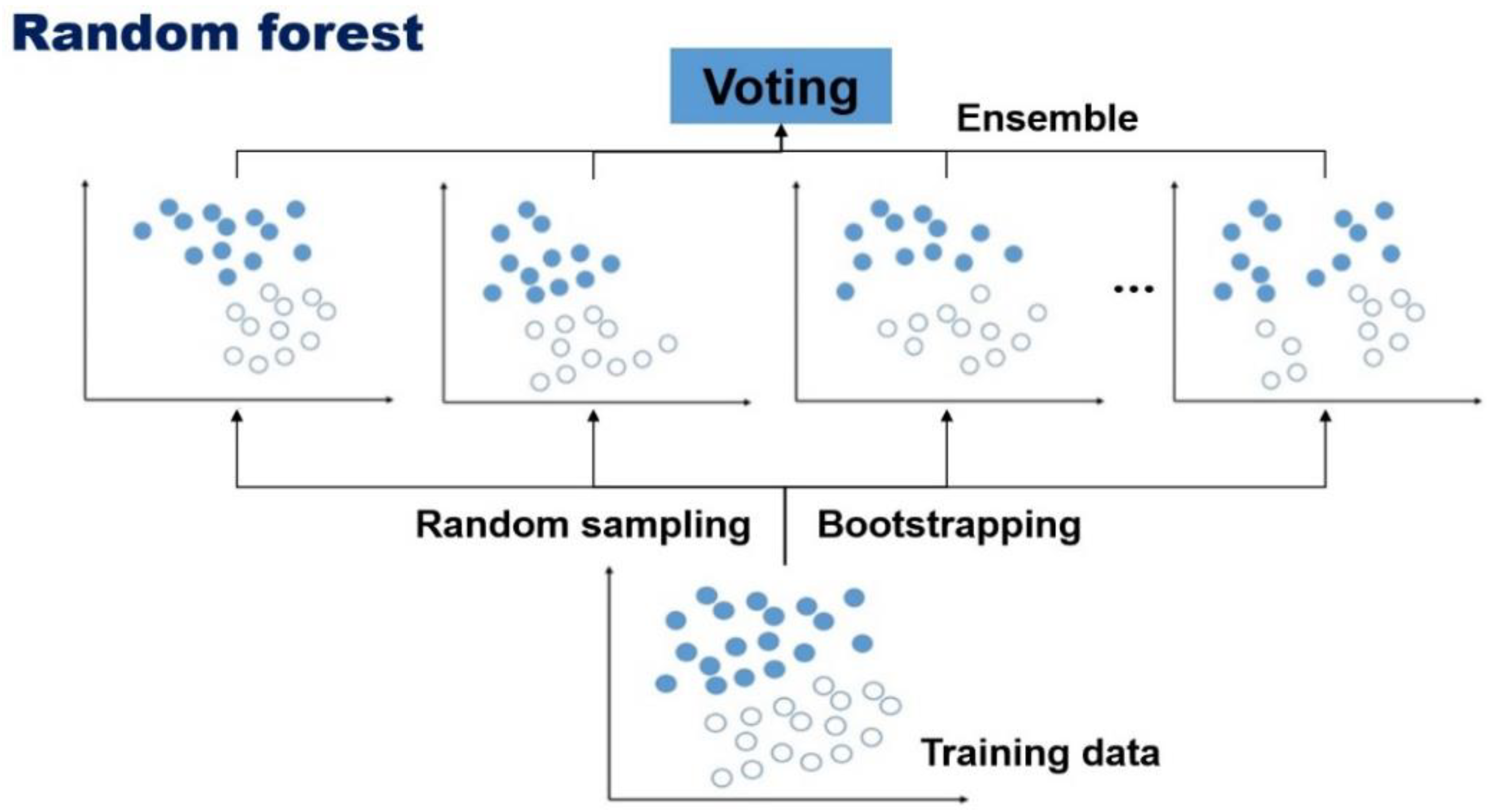
2.1. Random Forest
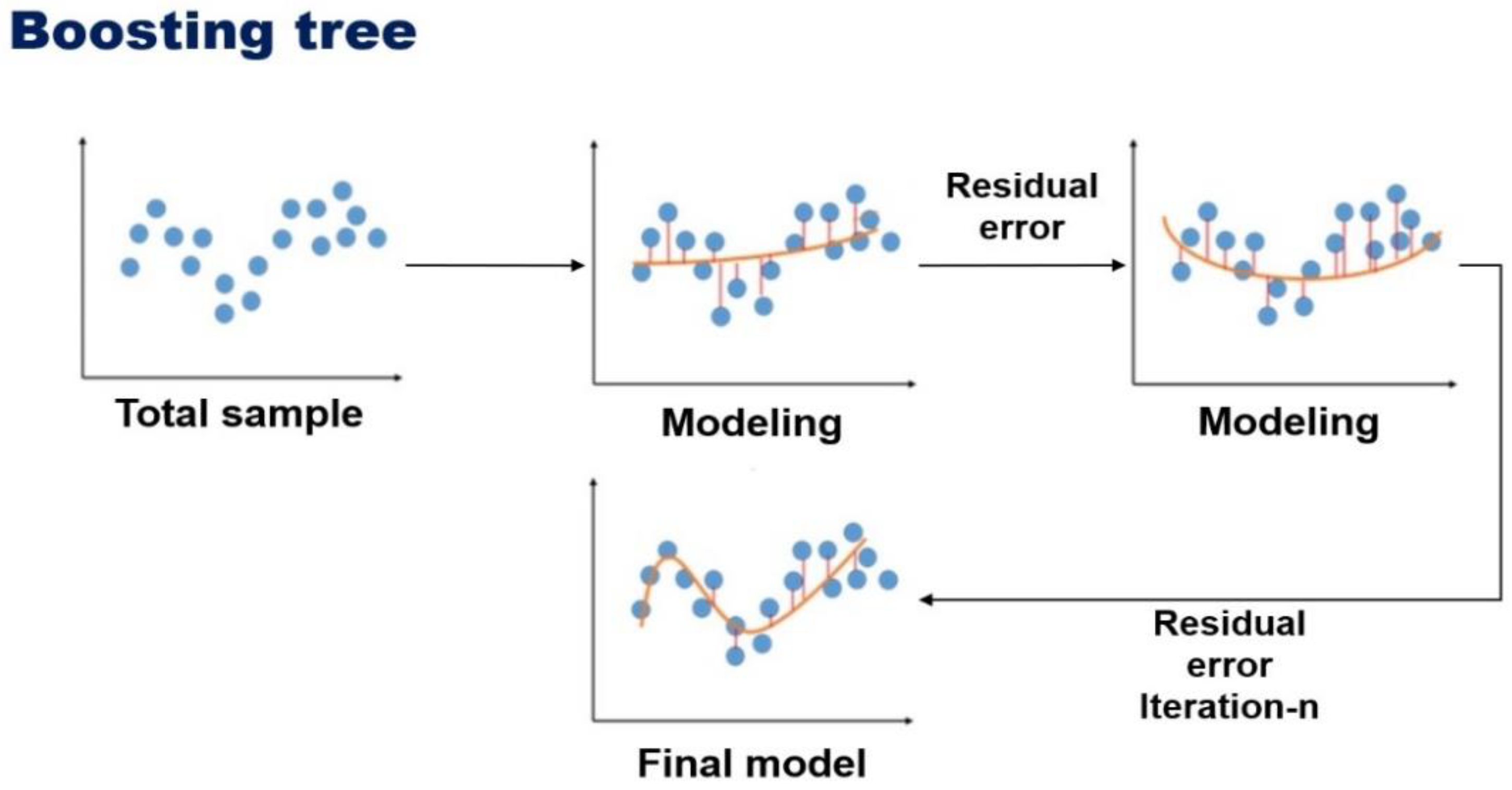
2.2. Gradient Boosting Tree
2.3. Support Vector Machine
2.4. Clustering Analysis
2.4.1. K-means Clustering
2.4.2. Partitioning Around Medoids Clustering
2.4.3. Hierarchical Clustering
2.5. Evaluating Prediction Models
2.6. Evaluating Clustering Analysis
2.6.1. Connectivity
2.6.2. Dunn Index
2.6.3. Silhouette Coefficient
3. Data Preparation and Description
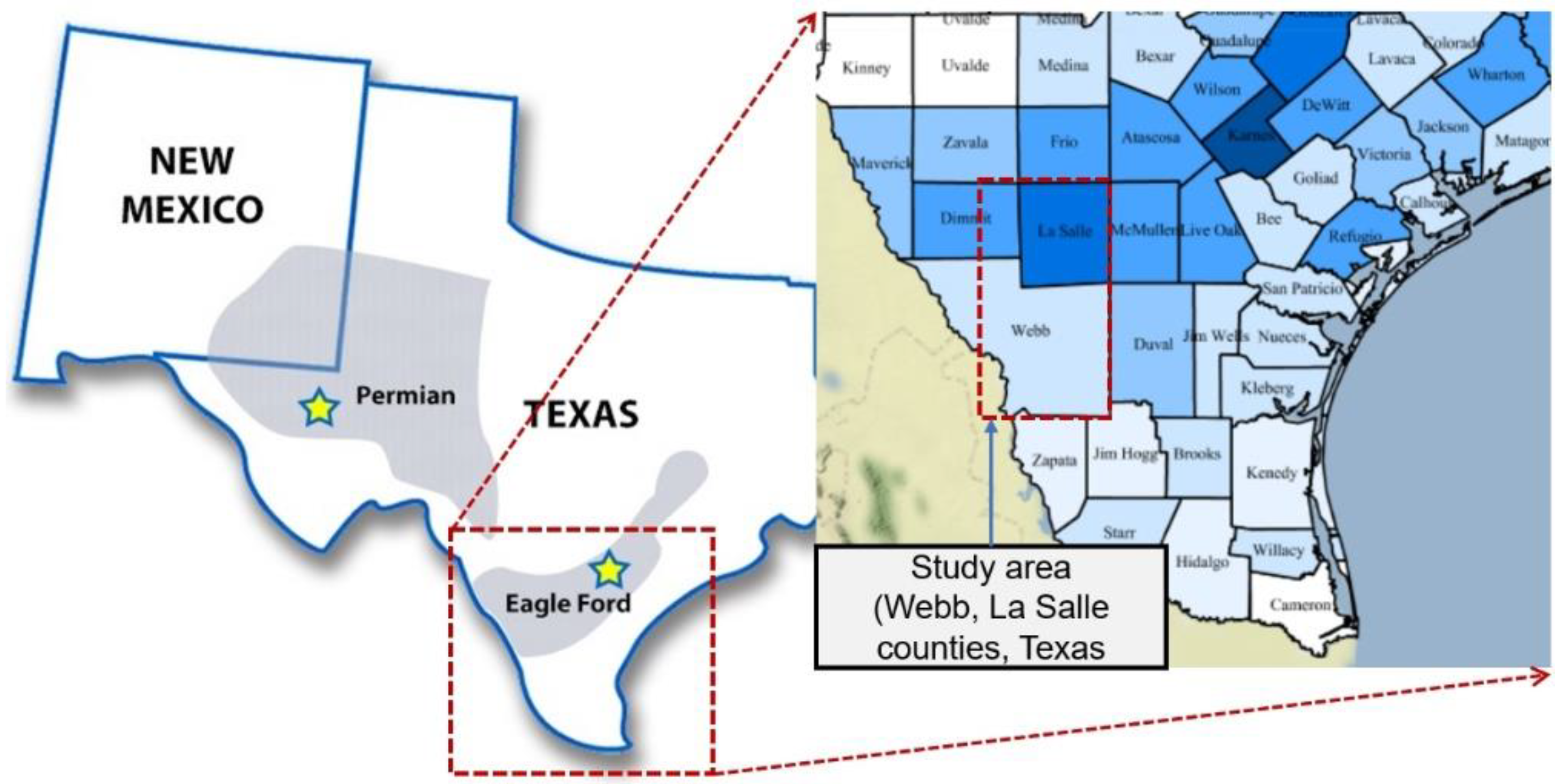
3.1. Field Data for Developed Model
3.2. Correlation Analysis
3.3. Workflow for Developed Model
4. Model Performance Analysis
4.1. Variables Importance Analysis
4.2. Model Validation
4.3. Clustering Analysis for Datasets
5. Results and Discussions
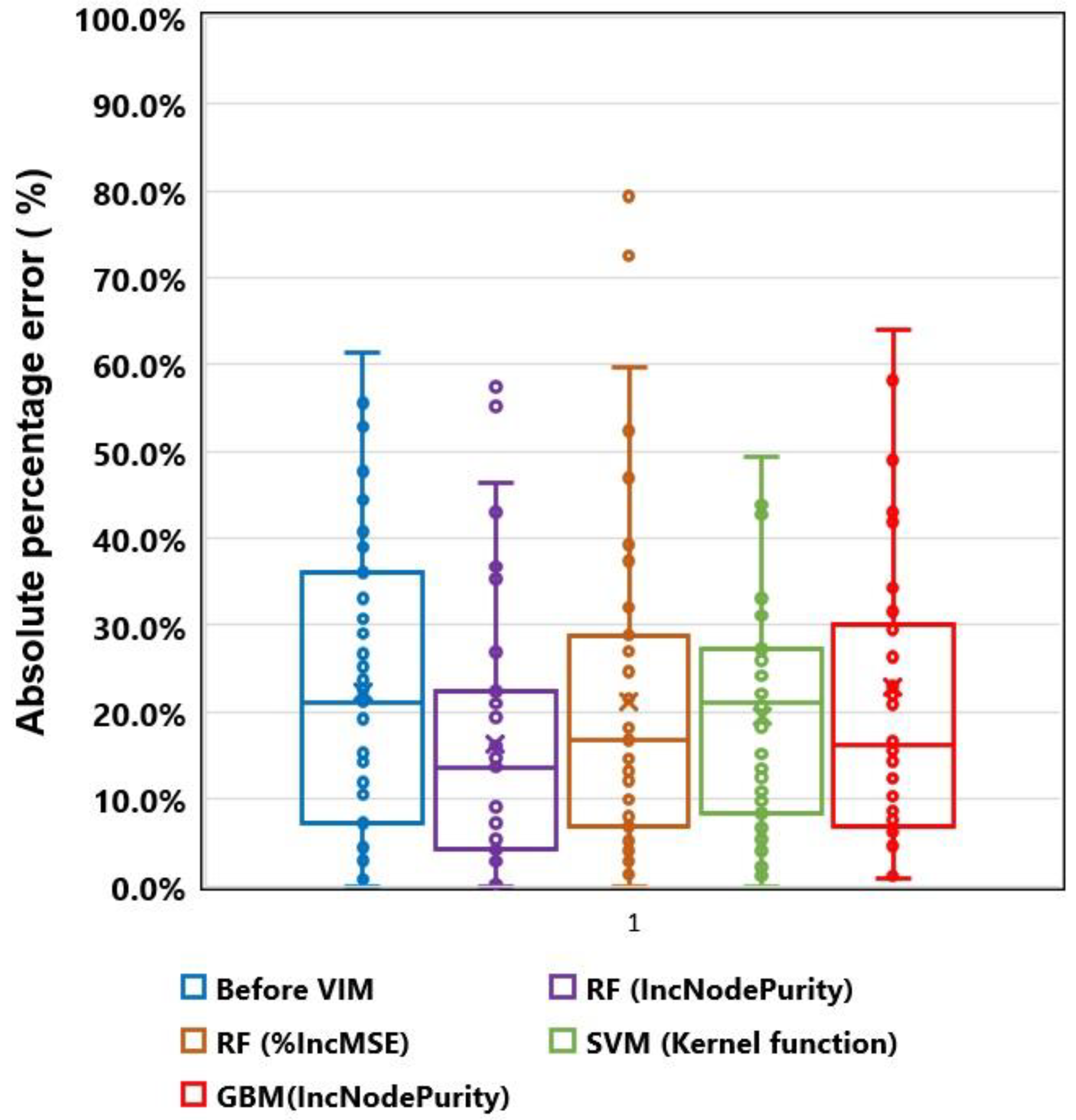
5.1. Comparative Analysis of Variables Importance Method
5.2. Comparative Analysis of Re-Training Using Clustering Analysis
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- U.S. Energy Information Administration. Shale Gas Production Includes Associated Natural Gas from Tight Oil Plays 2018. 2018. Available online: https://www.eia.gov/outlooks/aeo/pdf/AEO2018.pdf (accessed on 1 January 2020).
- Wilson, K.C.; Durlofsky, L.J. Optimization of shale gas field development using direct search techniques and reduced-physics models. J. Pet. Sci. Eng. 2013, 108, 304–315. [Google Scholar] [CrossRef]
- Ibrahim, M.; Wattenbarger, R.A. Analysis of rate dependence in transient linear flow in tight gas wells. In Proceedings of the 2006 Abu Dhabi International Petroleum Exhibition and Conference, Abu Dhabi, UAE, 5–8 November 2006. [Google Scholar] [CrossRef]
- Nobakht, M.; Clarkson, C.R. A new analytical method for analyzing production data from tight/shale gas reservoirs exhibiting linear flow: Constant pressure boundary-condition. SPE Res. Eval. Eng. 2012, 15, 370–384. [Google Scholar] [CrossRef] [Green Version]
- Clarkson, C.R.; Qanbari, F. An approximate semi-analytical multiphase forecasting method for multifractured tight light-oil wells with complex fracture geometry. J. Can. Pet. Technol. 2015, 54, 489–508. [Google Scholar] [CrossRef]
- Behmanesh, H.; Hamdi, H.; Clarkson, C.R. Production data analysis of liquid rich shale gas condensate reservoirs. J. Nat. Gas Sci. Eng. 2015, 22, 22–34. [Google Scholar] [CrossRef]
- Clarkson, C.R.; Haghshenas, B.; Ghanizadeh, A.; Qanbari, F.; Williams-Kovacs, J.D.; Riazi, N.; Debuhr, C.; Deglint, H.J. Nanopores to megafractures: Current challenges and methods for shale gas reservoir and hydraulic fracture characterization. J. Nat. Gas Sci. Eng. 2016, 31, 612–657. [Google Scholar] [CrossRef]
- Anderson, D.M.; Nobakht, M.; Mohadam, S.; Mattar, L. Analysis of Production Data from Fractured Shale Gas Wells. In Proceedings of the SPE Unconventional Gas Conference, Pittsburgh, PA, USA, 23–25 February 2010. [Google Scholar]
- Arps, J.J. Analysis of Decline Curves. Trans. AIME 1945, 160, 228–247. [Google Scholar] [CrossRef]
- Ilk, D.; Rushing, J.A.; Perego, A.D.; Blasingame, T.A. Exponential vs. Hyperbolic decline in tight gas sands: Understanding the origin and implications for reserve estimates using arps decline curves. In Proceedings of the SPE Annual Technical Conference and Exhibition, Denver, CO, USA, 21–24 September 2008. [Google Scholar]
- Kupchnenko, C.L.; Gault, B.W.; Mattar, L. Tight Gas Production Performance Using Decline Curves. In Proceedings of the CIPC/SPE Gas Technology Symposium Joint Conference, Calgary, AB, Canada, 16–19 June 2008. [Google Scholar]
- Valkó, P.P.; Lee, J.W. A better way to forecast production from unconventional gas wells. In Proceedings of the SPE Annual Technical Conference and Exhibition, Florence, Italy, 19–22 September 2010. [Google Scholar]
- Duong, A.N. Rate-decline analysis for fracture-dominated shale reservoirs. SPE Reserv. Eval. Eng. 2011, 14, 377–387. [Google Scholar] [CrossRef] [Green Version]
- Clark, A.J.; Lake, L.W.; Patzek, T.W. Production forecasting with logistic growth models. In Proceedings of the SPE Annual Technical Conference and Exhibition, Denver, CO, USA, 30 October–2 November 2011. [Google Scholar]
- Han, D.; Kwon, S. Selection of decline curve analysis method using the cumulative production in cline rate for transient production data obtained from a multi-stage hydraulic fractured horizontal well in unconventional gas fields. Int. J. Oil Gas Coal Technol. 2018, 18, 384–401. [Google Scholar] [CrossRef]
- Mohaghegh, S.D. Reservoir Modeling of Shale Formations. J. Nat. Gas Sci. Eng. 2013, 12, 22–33. [Google Scholar] [CrossRef]
- Zhong, M.; Schuetter, J.; Mishra, S.; Lafollette, R.F. Do data mining methods matter? A Wolfcamp Shale case study. In Proceedings of the SPE Hydraulic Fracturing Technology Conference and Exhibition, The Woodlands, TX, USA, 3–5 February 2015. [Google Scholar]
- Sfidari, E.; Kadkhodaie-Ilkhchi, A.; Najjari, S. Comparison of intelligent and statistical clustering approaches to predicting total organic carbon using intelligent systems. J. Pet. Sci. Eng. 2012, 86–87, 190–205. [Google Scholar] [CrossRef]
- Jung, H.; Jo, H.; Kim, S.; Lee, K.; Choe, J. Geological model sampling using PCA-assisted support vector machine for reliable channel reservoir characterization. J. Pet. Sci. Eng. 2018, 167, 396–405. [Google Scholar] [CrossRef]
- Bansal, Y.; Ertekin, T.; Karpyn, Z.; Ayala, L.; Nejad, A.; Suleen, F.; Balogun, O.; Sun, Q. Forecasting well performance in a discontinuous tight oil reservoirs using artificial neural networks. In Proceedings of the SPE Unconventional Resources Conference, The Woodlands, TX, USA, 10–12 April 2013. [Google Scholar]
- Lolon, E.; Hamidieh, K.; Weijers, L.; Mayerhofer, M.; Melcher, H.; Oduba, O. Evaluating the Relationship Between Well Parameters and Production Using Multivariate Statistical Models: A Middle Bakken and Three Forks Case History. In Proceedings of the SPE Hydraulic Fracturing Technology Conference, The Woodlands, TX, USA, 9–11 February 2016. [Google Scholar]
- Alabboodi, M.J.; Mohaghegh, S.D. Conditioning the Estimating Ultimate Recovery of Shale Wells to Reservoir and Completion Parameters. In Proceedings of the SPE Eastern Regional Meeting, Canton, OH, USA, 13–15 September 2016. [Google Scholar]
- Mohaghegh, S.D.; Gaskari, R.; Maysami, M. Shale Analytics: Making Production and Operational Decisions Based on Facts: A Case Study in Marcellus Shale. In Proceedings of the SPE Hydraulic Fracturing Technology Conference, The Woodlands, TX, USA, 24–26 January 2017. [Google Scholar]
- Li, Y.; Han, Y. Decline Curve Analysis for Production Forecasting Based on Machine Learning. In Proceedings of the SPE Symposium: Production Enhancement and Cost Optimization, Kuala Lumpur, Malaysia, 7–8 November 2017. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.; Hastie, T.; Tibshirani, R. Additive logistic regression: A statistical view of boosting (With discussion and a rejoinder by the authors). Ann. Stat. 2000, 28, 337–407. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support vector machine. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Jiang, S.; Mokhtari, M. Characterization of marl and interbedded limestone layers in the Eagle Ford Formation, DeWitt county, Texas. J. Pet. Sci. Eng. 2019, 172, 502–510. [Google Scholar] [CrossRef]
- Wang, M.; Wang, L.; Zhou, W.; Yu, W. Lean gas Huff and Puff process for Eagle Ford Shale: Methane adsorption and gas trapping effects on EOR. Fuel 2019, 248, 143–151. [Google Scholar] [CrossRef]
- Min, B.H.; Min, B.H.; Park, C.H.; Kang, J.M.; Park, H.J.; Jang, I.S. Optimal Well Placement Based on Artificial Neural Network Incorporating the Productivity Potential. Energy Source. Part A 2011, 33, 1726–1738. [Google Scholar] [CrossRef]
- Nguyen, H.; Bui, X.N.; Nguyen-Thoi, T.; Ragam, P.; Moayedi, H. Toward a State-of-the Art of Fly Rock Prediction Technology in Open-Pit Mines Using EANNs Model. Appl. Sci. 2019, 9, 4554. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, T.T.; Yoon, S. A Novel Approach to Short-Term Stock Price Movement Prediction using Transfer Learning. Appl. Sci. 2019, 9, 4745. [Google Scholar] [CrossRef] [Green Version]
- Arora, P.; Deepali; Varshney, S. Analysis of K-Means and K-Medoids Algorithm for Big Data. Procedia Comput. Sci. 2016, 78, 507–512. [Google Scholar] [CrossRef] [Green Version]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters Type | Parameters | Unit | Abbreviation |
|---|---|---|---|
| Input variables | Proppant volume | MMlb | Prop. |
| Slick water volume | Mgal | Slick water | |
| Cluster | - | Cluster | |
| Lateral length | ft | Laterallength | |
| Net pay | ft | Netpay | |
| Tubing head pressure | psia | THP | |
| Wellhead shut in pressure | psia | WHSP | |
| Gas gravity | - | Gasgravity | |
| Well test gas rate | Mscf | Testq | |
| Initial production rate (3 month) | MMscf | Qi_3M | |
| Easting | - | East. | |
| Northing | - | North. | |
| Measured depth | ft | MD | |
| True vertical depth | ft | TVD | |
| Peak for barrel of oil equivalent | mbo | Peak BOE | |
| Gas oil ratio | - | GOR | |
| Gas liquid ratio | - | GLR | |
| Initial water rate (3 month) | Mbbl | Wi | |
| Target variables | Cumulative gas production (36 month) | Bcf | Qp_36M |
| Parameters Type | Parameters | Range (Min-Max) | 1st Quartile | Mean | 3rd Quartile |
|---|---|---|---|---|---|
| Input variables | Prop. | 2.02–7.45 | 3.02 | 4.16 | 4.99 |
| Slick water | 25.2–230.2 | 69.9 | 96.5 | 117.9 | |
| Cluster | 36–81 | 48 | 52 | 57 | |
| Laterallength | 3579–8066 | 4718 | 5189 | 5641 | |
| Netpay | 7.0–562.0 | 58.0 | 140.1 | 201.0 | |
| THP | 1380–7330 | 2980 | 3838 | 4666 | |
| WHSP | 200–6448 | 700 | 2004 | 3064 | |
| Gasgravity | 0.592–0.852 | 0.683 | 0.710 | 0.737 | |
| Testq | 0.4–30.8 | 8.0 | 12.6 | 16.6 | |
| Qi_3M | 0.026–0.612 | 0.189 | 0.275 | 0.352 | |
| East. | 1,558,855–2,061,324 | 1,601,894 | 1,756,328 | 1,951,825 | |
| North. | 119,813–919,229 | 154,413 | 556,278 | 888,760 | |
| MD | 9724–18326 | 14,328 | 15,192 | 16,257 | |
| TVD | 5404–12944 | 8461 | 9516 | 10,926 | |
| Peak BOE | 8.6–61.2 | 19.4 | 24.4 | 30.9 | |
| GOR | 0–5,196,333 | 14,870 | 1,714,477 | 86,480 | |
| GLR | 0–662,275 | 10,339 | 76,090 | 73,995 | |
| Wi | 0.7–214.9 | 17.2 | 45.0 | 63.5 | |
| Target variables | Qp_36M | 0.28–4.48 | 1.00 | 1.46 | 1.60 |
| Supervised Learning Models | Parameters | Range of Values | Selection Values |
|---|---|---|---|
| RF | mtry | 1–5 | 5 |
| ntree | 10–500 | 300 | |
| GBM | mtry | 1–5 | 5 |
| ntree | 10–500 | 20 | |
| SVM | penalty function | 10–1000 | 600 |
| kernel parameter (RBF) | 10–100 | 20 |
| Machine Learning Algorithm | Performance Indicators | ||||
|---|---|---|---|---|---|
| R2 | MAD (Bcf) | MSE | RMSE | MAPE (%) | |
| RF (Before VIM -All datasets) | 0.40 | 0.297 | 0.408 | 0.639 | 22.94 |
| RF (VIM %IncMSE) | 0.69 | 0.274 | 0.126 | 0.354 | 22.29 |
| RF (VIM IncNodePurity) | 0.73 | 0.194 | 0.069 | 0.262 | 16.80 |
| GBM (VIM IncNodePurity) | 0.69 | 0.264 | 0.123 | 0.350 | 22.87 |
| SVM (Kernel function) | 0.63 | 0.242 | 0.089 | 0.297 | 20.03 |
| Machine Learning Algorithm | Performance Indicators | ||||
|---|---|---|---|---|---|
| R2 | MAD (Bcf) | MSE | RMSE | MAPE (%) | |
| RF (All datasets) | 0.40 | 0.297 | 0.408 | 0.639 | 22.94 |
| RF (Cluster 1) | 0.74 | 0.180 | 0.050 | 0.224 | 14.94 |
| RF (Cluster 2) | 0.88 | 0.154 | 0.043 | 0.209 | 12.05 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, D.; Jung, J.; Kwon, S. Comparative Study on Supervised Learning Models for Productivity Forecasting of Shale Reservoirs Based on a Data-Driven Approach. Appl. Sci. 2020, 10, 1267. https://doi.org/10.3390/app10041267
Han D, Jung J, Kwon S. Comparative Study on Supervised Learning Models for Productivity Forecasting of Shale Reservoirs Based on a Data-Driven Approach. Applied Sciences. 2020; 10(4):1267. https://doi.org/10.3390/app10041267
Chicago/Turabian StyleHan, Dongkwon, Jihun Jung, and Sunil Kwon. 2020. "Comparative Study on Supervised Learning Models for Productivity Forecasting of Shale Reservoirs Based on a Data-Driven Approach" Applied Sciences 10, no. 4: 1267. https://doi.org/10.3390/app10041267
APA StyleHan, D., Jung, J., & Kwon, S. (2020). Comparative Study on Supervised Learning Models for Productivity Forecasting of Shale Reservoirs Based on a Data-Driven Approach. Applied Sciences, 10(4), 1267. https://doi.org/10.3390/app10041267