Comprehensive Document Summarization with Refined Self-Matching Mechanism


Abstract
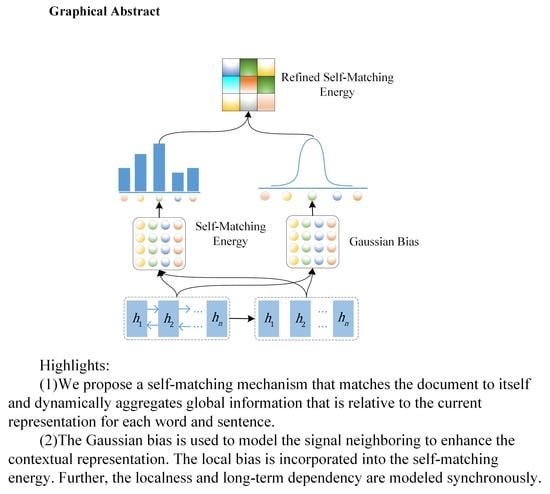
:
1. Introduction
- (1)
- We propose a refined self-matching mechanism and apply it to the extractive summarization, that dynamically aggregate relative information at the local and global level for each sentence in the document, the localness and long-term dependency are modeled comprehensively.
- (2)
- The Bidirectional Encoder Representation from Transformers (BERT) is incorporated into RSME flexibly. A hierarchical encoder is developed to effectively extracted the information at sentence-level and document-level, which helps capture the hierarchical property of the document.
- (3)
- The pointer network is utilized to select salient sentences based on current extraction state and relative importance gain of previous selections.
- (4)
- Extensive experiments are conducted on the CNN/Daily Mail dataset, and the experimental results showed that the proposed RSME significantly improves the ROUGE score compared with the state-of-art baseline methods.
2. Related Works
3. Method
3.1. Problem Description of Extractive Summarizer
3.2. Hierarchical Neural Network Based Encoder
3.3. Self-Matching Mechanism
3.4. Localness Modeling
3.5. Sentence Selection Based on Pointer Network
4. Experiments
4.1. Dataset
4.2. Evaluation Metric
4.3. Settings
4.4. Comparison Baselines
5. Results
5.1. Experimental Results Analysis
5.2. Ablation Test
5.3. Discussion
5.4. Case Study
6. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Zhou, Q.; Yang, N.; Wei, F.; Zhou, M. Selective encoding for abstractive sentence summarization. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1: Long Papers, pp. 1095–1104. [Google Scholar]
- Gehrmann, S.; Deng, Y.; Rush, A. Bottom-up abstractive summarization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4098–4109. [Google Scholar]
- Zhang, Y.; Li, D.; Wang, Y.; Xiao, W. Abstract text summarization with a convolutional Seq2seq model. J. Appl. Sci. 2019, 9, 1665. [Google Scholar] [CrossRef] [Green Version]
- Berend, G. Opinion expression mining by exploiting keyphrase extraction. In Proceedings of the 5th International Joint Conference on Natural Language Processing, Chiang Mai, Thailand, 8–13 November 2011; pp. 1162–1170. [Google Scholar]
- Jadhav, A.; Rajan, V. Extractive summarization with swap-net: Sentences and words from alternating pointer networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 1: Long Papers, pp. 142–151. [Google Scholar]
- Eduard, H.; Lin, C.Y. Automated text summarization and the SUMMARIST system. In Proceedings of the 1998 Workshop on Held at Baltimore, Baltimore, MD, USA, 13–15 October 1998. [Google Scholar]
- Erkan, G.; Radev, D.R. Lexrank: Graph-based lexical centrality as salience in text summarization. J. Artif. Intell. Res. 2004, 22, 457–479. [Google Scholar] [CrossRef]
- Mihalcea, R.; Tarau, P. Textrank: Bringing order into text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–24 July 2004; pp. 404–411. [Google Scholar]
- Zhou, Q.; Yang, N.; Wei, F.; Huang, S.; Zhou, M.; Zhao, T. Neural document summarization by jointly learning to score and select sentences. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, VI, Australia, 15–20 July 2018; Volume 1: Long Papers, pp. 654–663. [Google Scholar]
- Nallapati, R.; Zhai, F.; Zhou, B. Summarunner: A recurrent neural network based sequence model for extractive summarization of documents. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Wu, Y.; Hu, B. Learning to extract coherent summary via deep reinforcement learning. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Dong, Y.; Shen, Y.; Crawford, E.; van Hoof, H.; Cheung, J.C.K. Banditsum: Extractive summarization as a contextual bandit. arXiv 2018, arXiv:1809.09672. [Google Scholar]
- Cheng, J.; Lapata, M. Neural summarization by extracting sentences and words. arXiv 2016, arXiv:1603.07252. [Google Scholar]
- Rush, A.M.; Chopra, S.; Weston, J. A neural attention model for abstractive sentence summarization. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 379–389. [Google Scholar]
- See, A.; Liu, P.J.; Manning, C.D. Get to the point: Summarization with pointer-generator networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1: Long Papers, pp. 1073–1083. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the 2015 International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Vinyals, O.; Fortunato, M.; Jaitly, N. Pointer networks. In In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2692–2700. [Google Scholar]
- Al-Sabahi, K.; Zuping, Z.; Nadher, M. A hierarchical structured self-attentive model for extractive document summarization (HSSAS). arXiv 2018, arXiv:1805.07799. [Google Scholar] [CrossRef]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, Sydney, NSW, Australia, 6–11 August 2017; pp. 1243–1252. [Google Scholar]
- Narayan, S.; Cohen, S.B.; Lapata, M. Ranking sentences for extractive summarization with reinforcement Learning. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1: Long Papers, pp. 1747–1759. [Google Scholar]
- Yin, W.; Pei, Y. Optimizing sentence modeling and selection for document summarization. In Proceedings of the 24th International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Gu, J.; Lu, Z.; Li, H.; Li, V.O. Incorporating copying mechanism in sequence-to-sequence learning. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1: Long Papers, pp. 1631–1640. [Google Scholar]
- Chen, Y.C.; Bansal, M. Fast abstractive summarization with reinforce-selected sentence rewriting. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, VI, Australia, 15–20 July 2018; Volume 1: Long Papers, pp. 675–686. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv arXiv:1301.3781, 2013.
- Wang, S.; Jiang, J. Learning natural language inference with LSTM. In Proceedings of the 2016 NAACL-HLT, San Diego, CA, USA, 12–17 June 2016; pp. 1442–1451. [Google Scholar]
- Wang, W.; Yang, N.; Wei, F.; Chang, B.; Zhou, M. Gated self-matching networks for reading comprehension and question answering. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1: Long Papers, pp. 189–198. [Google Scholar]
- Tan, J.; Wan, X.; Xiao, J. From neural sentence summarization to headline generation: A coarse-to-fine approach. In Proceedings of the 26th International Joint Conference on Artificial Intelligence; AAAI Press: Palo Alto, CA, USA, 2017; pp. 4109–4115. [Google Scholar]
- Zeng, B.; Yang, H.; Xu, R.; Zhou, W.; Han, X. LCF: A local context focus mechanism for aspect-based sentiment classification. Appl. Sci. 2019, 9, 3389. [Google Scholar] [CrossRef] [Green Version]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-attention with relative position representations. arXiv 2018, arXiv:1803.02155. [Google Scholar]
- You, Y.; Jia, W.; Liu, T.; Yang, W. Improving abstractive document summarization with salient information modeling. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2132–2141. [Google Scholar]
- Vinyals, O.; Bengio, S.; Kudlur, M. Order matters: Sequence to sequence for sets. In Proceedings of the 2016 International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Hermann, K.M.; Kocisky, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching machines to read and comprehend. In Proceedings of the 28th International Conference on Neural Information Processing Systems-Volume 1, Montreal, QC, Canada, 11–12 December 2015; pp. 1693–1701. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
Sample Availability: Samples of the compounds are not available from the authors. |



{kind=link}
{kind=link}
{kind=link}
| Categories | Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|---|
| Abstractive | ConvS2S | 39.8 | 17.3 | 36.5 |
| PGN + Cov | 39.5 | 17.3 | 36.4 | |
| Fastabs | 41.4 | 18.7 | 37.7 | |
| Extractive | LEAD-3 | 40.3 | 17.7 | 36.6 |
| HSSAS # | 42.3 | 17.8 | 37.6 | |
| Refresh | 40.0 | 18.2 | 36.6 | |
| BanditSum | 41.5 | 18.7 | 37.6 | |
| SWAP-NET # | 41.6 | 18.3 | 37.7 | |
| Extractive (ours) | RSME | 41.5 | 18.8 | 37.7 |
| BERT-RSME | 42.4 * | 19.8 * | 38.9* |
| Models | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| RSME | 41.5 | 18.8 | 37.7 |
| -Gaussian bias | 41.1 | 18.6 | 37.7 |
| -Self Matching | 40.4 | 18.2 | 37.0 |
| -Pointer Network | 40.2 | 18.0 | 36.5 |
| Models | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| UniLSTM + Classifier | 39.8 | 17.9 | 36.4 |
| BiLSTM + Classifier | 40.2 | 18.0 | 36.5 |
| BiLSTM + Self Matching | 40.9 | 18.3 | 37.6 |
| Models | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| RSME | 41.5 | 18.8 | 37.7 |
| GloVe-basic | 40.4 | 18.1 | 36.7 |
| GloVe-RSME | 41.4 | 18.7 | 37.8 |
| BERT-basic | 42.0 | 19.3 | 38.5 |
| BERT-RSME | 42.4 | 19.8 | 38.9 |
| Reference Summary: |
|---|
| creature can . local people in narnaul are to the calf, called , is thought to have . |
| Basic model: |
| in India’s Hindu culture, cows are revered as a symbol of life. Nandi is attracting of visitors wanting to celebrate him. of them kneel before him to . baby teeth: one of Nandi’s mouths is clearly bigger than the others, which hang around his face. |
| ConvS2S: |
| Sukhbir said Nandi was in good health despite health. However, Nandi could only see the side of its body, not the front. Two years ago, an American farm revealed that it had a calf with two heads On everyone’s lips: this baby |
| RSME: |
| talk about gobby ! this little fellow has been born with - believed to be the the strange-looking baby opens all ten lips when he is sucking at his mother’s udders. but he can only of them |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, B.; Xu, R.; Yang, H.; Gan, Z.; Zhou, W. Comprehensive Document Summarization with Refined Self-Matching Mechanism. Appl. Sci. 2020, 10, 1864. https://doi.org/10.3390/app10051864
Zeng B, Xu R, Yang H, Gan Z, Zhou W. Comprehensive Document Summarization with Refined Self-Matching Mechanism. Applied Sciences. 2020; 10(5):1864. https://doi.org/10.3390/app10051864
Chicago/Turabian StyleZeng, Biqing, Ruyang Xu, Heng Yang, Zibang Gan, and Wu Zhou. 2020. "Comprehensive Document Summarization with Refined Self-Matching Mechanism" Applied Sciences 10, no. 5: 1864. https://doi.org/10.3390/app10051864
APA StyleZeng, B., Xu, R., Yang, H., Gan, Z., & Zhou, W. (2020). Comprehensive Document Summarization with Refined Self-Matching Mechanism. Applied Sciences, 10(5), 1864. https://doi.org/10.3390/app10051864