Named Entity Recognition for Sensitive Data Discovery in Portuguese




Abstract
:1. Introduction
2. Named Entity Recognition
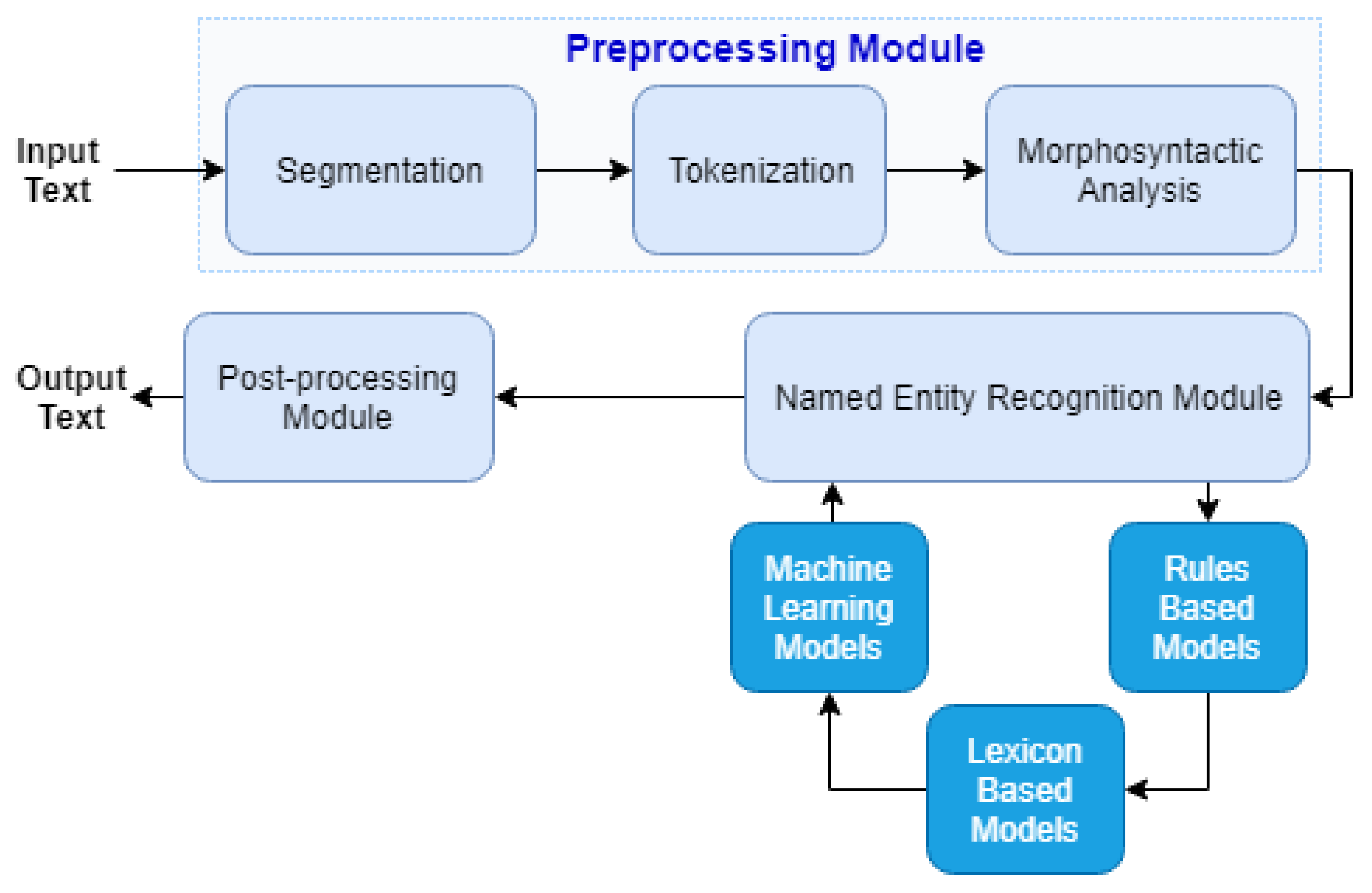
3. NER Component
3.1. Preprocessing Module
- Segmentation: So that each sentence is processed individually without depending on the context of the previous one. We start by dividing the entire text into sentences by the end of sentence punctuation marks: Period (.), question mark (?), exclamation (!), and suspension points (...).
- Tokenization: Is performed second on the module chain. This component divides the text in n-grams, words, or sets of words. The number of n-grams can also be parameterized, and this tokenization consists of representing the text as a vector of individual or sets of words. Regarding our approach, some decisions have been made in terms of punctuation, which consist of separating all the nonalphanumeric characters from the words. All punctuation marks except the hyphen (-), the at (@), and the slash (/) are separated by a blank space from all alphanumeric characters in the text. By default, the parameterization used in the processing chain consists of the division into unigrams.
- Morphosyntactic Analysis: After tokenization, we perform the morphosyntactic analysis of all separate text in unigrams. The text is analyzed and classified with Part-of-Speech Tagging using different techniques and tools. The task of Part-of-Speech (POS) Tagging consists of analyzing and tagging all the words in the text at the syntactic level. After studying the state-of-the-art, three different implementations were tested and analyzed to select the best to integrate into the NER Component. In the first and second experiments, we used the POS tagging model of the NLTK library. While in the first experiment the model was being applied directly, in the second one we retrained the model with Floresta Sintáctica Corpus [20]. In the third experiment, we used the SpaCy library POS model. After testing, we concluded that the model with the best behavior was the last one, which consists of an implementation based on statistical models and the use of multitask CNN [21]. It achieved an accuracy of 86.4% for the transformed Floresta Sintáctica corpus. Therefore, this is the default model used in the NER Component.
3.2. Named Entity Recognition Module
- Rule-Based Models: Several Information Extraction and Named Entity Recognition approaches are based on rules. This first component of the NER Module implements different rule-based models to discover some of the entity classes. The entity classes that are discovered at this stage of the component chain are all associated with sensitive data related to the Personal Identification Numbers category, including postal codes, email addresses, and some date formats. In addition to these rules there is, in some cases, an extra validation. This validation is performed on all personal numbers in which there is a control validation, check digit, or checksum. It allows us to disambiguate and have a greater certainty of cases such as the telephone number and the tax identification number, both containing nine digits. For the telephone number, for example, a set of rules and also a set of context words were created. The regex used for the extraction of this entity was: 9[1236][0-9]{7}|2[1-9]{1}[0-9]{7}|1[0-9]{2,3}, while the list of context words for it was: Contacto, contato, telemovel, telefonico, telefónico, contactar, fax. It consists of a set of Portuguese words that usually appear in documents related to telephone contacts. Another feature of this implementation is the context, which has been added to the model in order to solve errors in some of the data types, mainly those of the Personal Identification Number category. The context consists of a specific word or set of words for each class of entity that must exist in the text in order to confirm the result achieved with the rules.
- Lexicon-Based Models: Is the second component in the processing chain. This approach was chosen due to the lack of Portuguese corpus classified for the task of Named Entity Recognition and the good results often achieved with this type of approaches [23]. These lexicon-based models combine the results of morphological analysis, a set of lexicons, and techniques of stemming and lemmatization. The goal is the recognition of the entity classes: PESSOA, LOCAL, PROFISSAO, MED, VALOR, and TEMPO. For each entity, we used different lexicons with their own specific characteristics. This type of implementation consists of comparing the tokens present in the text with the lexicon, and understanding if they correspond to the same entity. The first entity class is PESSOA, which corresponds to the names of people. For this implementation two different lexicons were used in order to catch both female and male names, and these lexicons can be obtained from the Public Administration Data Portal (https://dados.gov.pt/pt/datasets/nomesfeminino). The LOCAL entity follows the same implementation used for the names above, as two lexicons were also used in this case, and each entry may correspond to more than one word, as is the case of ‘United Kingdom’. The first lexicon, with more than 18,000 entries corresponds to the set of all Portuguese cities, municipalities, and parishes, available in Gov Data (https://dados.gov.pt/pt/datasets). For the entities PROFISSAO and MED we have also used the comparison with lexicons, but using a different approach. The two lexicons are from Wikipedia (https://pt.wikipedia.org) information. The entity VALOR should extract all existing values from the text, which may correspond to the value of a contract, a fine, etc. In this type of entity, the value can be written both numerically and in full, and to cover both cases, we used Part-Of-Speech (POS) Tagging classification. For the words or symbols that come associated with the values, besides the use of the tag ‘SYM’ of POS Tagging, a lexicon has been created with the most relevant words that should be considered. This lexicon consists of words such as ‘dollar’, ‘euro’, ‘millions’, etc. The last entity implemented was TEMPO, and to be able to deal with it, a lexicon was created with all the months in Portuguese and English, as well as their abbreviated forms. Some of these entities were also implemented with Machine Learning models, with the goal of understanding how to achieve the best results for each class of sensitive data.
- Machine Learning Models: Is the last subcomponent on the chain of the NER module. We conclude from the current state-of-the-art analysis that for the most ambiguous entities and for those in which there are no well-defined rules, the best results are achieved through machine learning methods and, out of these, the most recent approaches are based on the study of neural networks. In the next section, we present the Machine Learning approaches for NER used in this work. These approaches were carried out for a smaller set of entities: PESSOA, LOCAL, TEMPO, VALOR, and ORGANIZACAO; For these entities and in this experiment, we had two different approaches:
- We implemented the two statistical models most commonly used in the tasks of Named Entity Recognition, Conditional Random Field, and Random Forest;
3.2.1. Statistical Models
- Parts of words through stemming;
- Simplified POS tags;
- Confirmation of capital letters, lower case letters, titles, and digits;
- Resources from nearby words.
3.2.2. Neural Network Model
- Character-level patterns are identified by a convolutional neural network;
- Word-level input from fastText embeddings;
- Casing input (whether words are lower case, upper case, etc.).
3.3. Postprocessing Module
4. Experiments and Results
4.1. Lexicon-Based Models Evaluation
4.2. Statistical Models Evaluation
4.3. Neural Network Model Evaluation
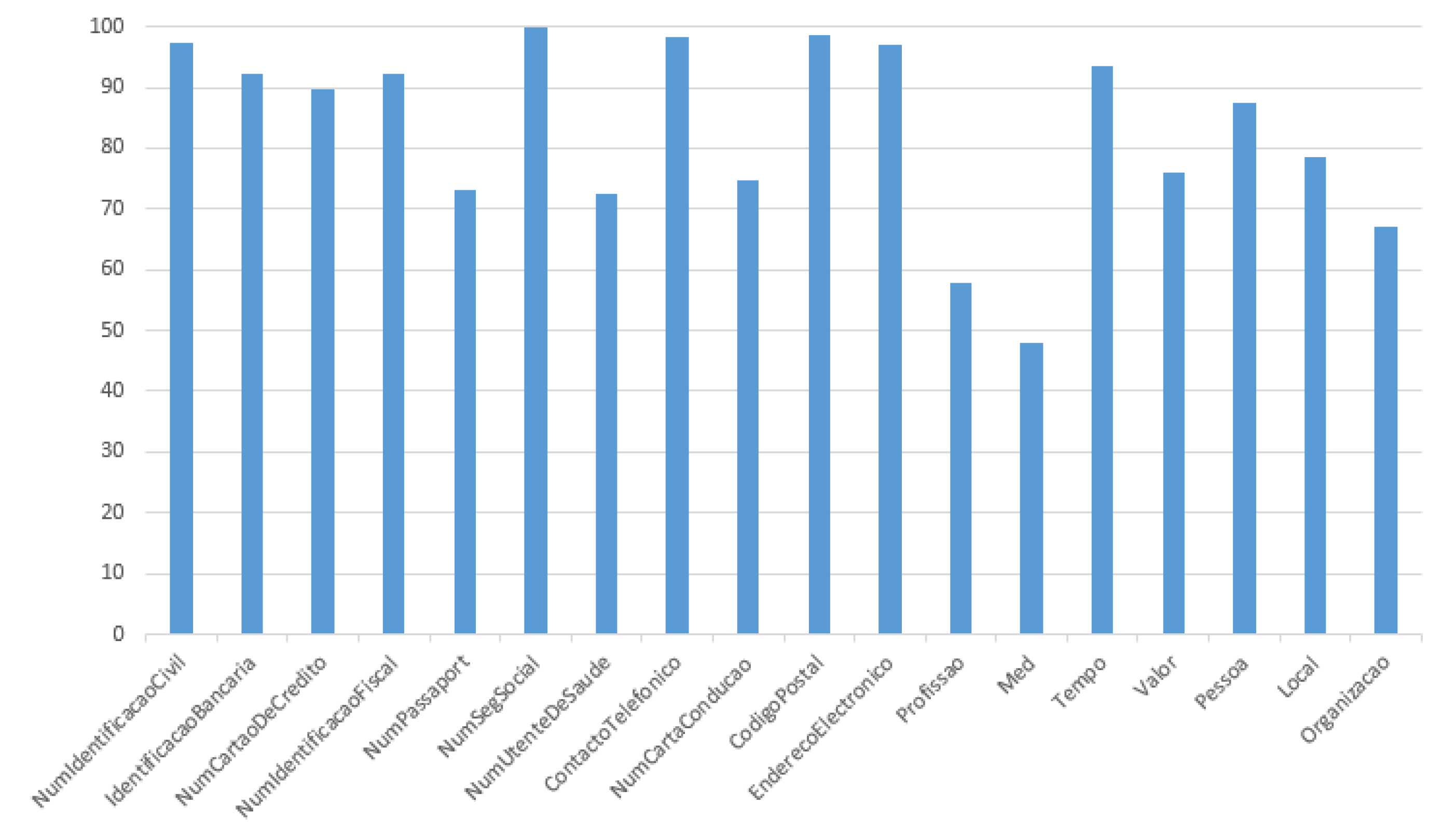
4.4. Named Entity Recognition Component Validation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Dale, R.; Moisl, H.; Somers, H. (Eds.) Handbook of Natural Language Processing; CRC Press: Boca Raton, FL, USA, 2000. [Google Scholar]
- Nadeau, D.; Sekine, S. A survey of named entity recognition and classification. Lingvist. Investig. 2007, 30, 3–26. [Google Scholar]
- Dias, M.; Maia, R.; Ferreira, J.; Ribeiro, R.; Martins, A. DataSense Platform. In Proceedings of the IASTEM—586th International Conference on Science Technology and Management (ICSTM), Bandar Seri Begawan, Brunei, 11–12 April 2019. [Google Scholar]
- Clough, P. Extracting metadata for spatially-aware information retrieval on the internet. In Proceedings of the 2005 Workshop on Geographic Information Retrieval, Bremen, Germany, 4 November 2005; pp. 25–30. [Google Scholar]
- Korba, L.; Wang, Y.; Geng, L.; Song, R.; Yee, G.; Patrick, A.S.; Buffett, S.; Liu, H.; You, Y. Private data discovery for privacy compliance in collaborative environments. In International Conference on Cooperative Design, Visualization and Engineering; Springer: Berlin/Heidelberg, Germany, 2008; pp. 142–150. [Google Scholar]
- Cardie, C. Empirical methods in information extraction. AI Mag. 1997, 18, 65. [Google Scholar]
- Ciravegna, F. 2, an adaptive algorithm for information extraction from web-related texts. In Proceedings of the IJCAI—2001 Workshop on Adaptive Text Extraction and Mining, Seattle, WA, USA, 4–10 August 2001. [Google Scholar]
- Grishman, R.; Sundheim, B. Design of the MUC-6 evaluation. In Proceedings of the 6th Conference on Message Understanding, Columbia, MD, USA, 6–8 November 1995; Association for Computational Linguistics: Stroudsburg, PA, USA, 1995; pp. 1–11. [Google Scholar]
- Brill, E.; Mooney, R.J. An overview of empirical natural language processing. AI Mag. 1997, 18, 13. [Google Scholar]
- Mikheev, A.; Moens, M.; Grover, C. Named entity recognition without gazetteers. In Proceedings of the Ninth Conference on European chapter of the Association for Computational Linguistics, Bergen, Norway, 8–12 June 1999; Association for Computational Linguistics: Stroudsburg, PA, USA, 1999; pp. 1–8. [Google Scholar]
- Gattani, A.; Lamba, D.S.; Garera, N.; Tiwari, M.; Chai, X.; Das, S.; Subramaniam, S.; Rajaraman, A.; Harinarayan, V.; Doan, A. Entity extraction, linking, classification, and tagging for social media: A wikipedia-based approach. Proc. VLDB Endow. 2013, 6, 1126–1137. [Google Scholar] [CrossRef] [Green Version]
- Torisawa, K. Inducing gazetteers for named entity recognition by large-scale clustering of dependency relations. In Proceedings of the ACL-08: HLT, Columbus, OH, USA, 15–20 June 2008; pp. 407–415. [Google Scholar]
- Zhou, G.; Su, J. Named entity recognition using an HMM-based chunk tagger. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; pp. 473–480. [Google Scholar]
- Finkel, J.R.; Grenager, T.; Manning, C. Incorporating non-local information into information extraction systems by gibbs sampling. In Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics, Ann Arbor, MI, USA, 25–30 June 2005; Association for Computational Linguistics: Stroudsburg, PA, USA, 2005; pp. 363–370. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. arXiv 2016, arXiv:1603.01360. [Google Scholar]
- De Castro, P.V.Q.; da Silva, N.F.F.; da Silva Soares, A. Portuguese Named Entity Recognition Using LSTM-CRF. In International Conference on Computational, Processing of the Portuguese Language; Springer: Cham, Switzerland, 2018; pp. 83–92. [Google Scholar]
- Chiu, J.P.; Nichols, E. Named entity recognition with bidirectional LSTM-CNNs. Trans. Assoc. Comput. Linguist. 2016, 4, 357–370. [Google Scholar] [CrossRef]
- Mota, C.; Santos, D.; Ranchhod, E. Avaliação de reconhecimento de entidades mencionadas: Princípio de AREM. In Proceedings of the Avaliação Conjunta: Um Novo Paradigma no Processamento Computacional da língua Portuguesa, Computational Processing of the Portuguese Language: 7th International Workshop. PROPOR, Itatiaia, Brazil, 13–17 May 2006; pp. 161–175. [Google Scholar]
- Kannan, S.; Gurusamy, V. Preprocessing Techniques for Text Mining. Int. J. Comput. Sci. Commun. Networks 2014, 5, 7–16. [Google Scholar]
- Afonso, S.; Bick, E.; Haber, R.; Santos, D. Florestasintá(c)tica: A treebank for Portuguese. In quot. In Manuel González Rodrigues, Proceedings of the Third International Conference on Language Resources and Evaluation (LREC 2002), Las Palmas de Gran Canaria, Spain, 29–31 May, 2002; Paz Suarez Araujo, C., Ed.; ELRA: Paris, France, 2002. [Google Scholar]
- Arnold, T. A tidy data model for natural language processing using cleannlp. arXiv 2017, arXiv:1703.09570. [Google Scholar] [CrossRef]
- Ramshaw, L.A.; Marcus, M.P. Text chunking using transformation-based learning. In Natural Language Processing Using Very Large Corpora; Springer: Dordrecht, The Netherlands, 1999; pp. 157–176. [Google Scholar]
- Ratinov, L.; Roth, D. Design challenges and misconceptions in named entity recognition. In Proceedings of the Thirteenth Conference on Computational Natural Language Learning, Boulder, CO, USA, 4 June 2009; Association for Computational Linguistics: Stroudsburg, PA, USA, 2009; pp. 147–155. [Google Scholar]
- Santos, D.; Cardoso, N. A golden resource for named entity recognition in Portuguese. In International Workshop on Computational, Processing of the Portuguese Language; Springer: Berlin/Heidelberg, Germany, 2006; pp. 69–79. [Google Scholar]
- Môro, D.K. Reconhecimento de Entidades Nomeadas em Documentos de Língua Portuguesa; TCC- Universidade Federal de Santa Catarina Araranguá, Tecnologias de Informação e Comunicação: Florianópolis, Brazil, 2018. [Google Scholar]
- Lin, D.; Wu, X. Phrase clustering for discriminative learning. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Suntec, Singapore, 2–7 August 2009; Association for Computational Linguistics: Stroudsburg, PA, USA, 2009; Volume 2, pp. 1030–1038. [Google Scholar]
- Nothman, J.; Ringland, N.; Radford, W.; Murphy, T.; Curran, J.R. Learning multilingual named entity recognition from Wikipedia. Artif. Intell. 2013, 194, 151–175. [Google Scholar] [CrossRef] [Green Version]
- Do Amaral, D.O.F.; Vieira, R. NERP-CRF: Uma ferramenta para o reconhecimento de entidades nomeadas por meio de Conditional Random Fields. Linguamática 2014, 6, 41–49. [Google Scholar]
- McCallum, A.; Li, W. Early results for named entity recognition with conditional random fields, feature induction and web-enhanced lexicons. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003; Association for Computational Linguistics: Stroudsburg, PA, USA, 2003; Volume 4, pp. 188–191. [Google Scholar]
- Sears, T.D.; Sunehag, P. Induced semantics for undirected graphs: Another look at the Hammersley-Clifford theorem. In AIP Conference Proceedings; American Institute of Physics: College Park, MD, USA, 2007; pp. 125–132. [Google Scholar]
- Jin, N. Ncsu-sas--Ning: Candidate generation and feature engineering for supervised lexical normalization. In Proceedings of the Workshop on Noisy User-Generated Text, Beijing, China, 31 July 2015; pp. 87–92. [Google Scholar]
- Jiang, P.; Wu, H.; Wang, W.; Ma, W.; Sun, X.; Lu, Z. MiPred: Classification of real and pseudo microRNA precursors using random forest prediction model with combined features. Nucleic Acids Res. 2007, 35 (Suppl. 2), W339–W344. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yadav, V.; Bethard, S. A survey on recent advances in named entity recognition from deep learning models. arXiv 2019, arXiv:1910.11470. [Google Scholar]
- Nie, Y.; Fan, Y. Arriving-on-time problem: Discrete algorithm that ensures convergence. Transp. Res. Rec. 2006, 1964, 193–200. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Athiwaratkun, B.; Wilson, A.G.; Anandkumar, A. Probabilistic FastText for multi-sense word embeddings. arXiv 2018, arXiv:1806.02901. [Google Scholar]
- Ferreira, L.; Teixeira, A.; Cunha, J.P.S. REMMA-Reconhecimento de entidades mencionadas do MedAlert. In Desafios na Avaliaçao Conjunta do Reconhecimento de Entidades Mencionadas: O Segundo HAREM; Linguateca: Aveiro, Portugal, 2008. [Google Scholar]
- Pires, A.R.O. Named Entity Extraction from Portuguese Web Text. Master’s Thesis, FEUP - Faculdade de Engenharia, Porto, Portugal, 2017. [Google Scholar]
- Amaral, D.O.F.D. Reconhecimento de Entidades Nomeadas na área da Geologia: Bacias Sedimentares Brasileiras; PUCRS: Porto Alegre, Brazil, 2017. [Google Scholar]
- Pirovani, J.P.C. CRF+ LG: Uma abordagem híbrida para o reconhecimento de entidades nomeadas em português. Ph.D. Thesis, Universidade Federal do Espírito Santo, Espírito Santo, Brazil, 2019. [Google Scholar]
- Li, P.H.; Fu, T.J.; Ma, W.Y. Remedying BiLSTM-CNN Deficiency in Modeling Cross-Context for NER. arXiv 2019, arXiv:1908.11046. [Google Scholar]



{kind=link}
{kind=link}
| Categories | Entities Classes | Sensitive Data Included |
|---|---|---|
| NumIdentificacaoCivil | Identification Number | |
| IdentificacaoBancaria | Bank Identification Number | |
| NumCartaoDeCredito | Credit Card Number | |
| Personal | NumIdentificacaoFiscal | Tax Identification Number |
| Identification | NumPassaport | Passport Number |
| Number | NumSegSocial | Social Security Number |
| NumUtenteDeSaude | National Health Number | |
| ContactoTelefonico | Telephone Number | |
| NumCartaConducao | Driving License Number | |
| Pessoa | Person Names | |
| Local | Addresses, Locals | |
| Socio-Economic | Organizacao | Organizations |
| Information | Tempo | Dates |
| Valor | Values, Ordered values | |
| Med | Medical data | |
| Profissao | Jobs, Professions | |
| Other | CodigoPostal | Postal Code |
| EnderecoEletronico | E-mail address |
| Model | Metrics | HAREM Golden Collection | SIGARRA News Corpus |
|---|---|---|---|
| Lexicon-Based | Precision | 71.00% | 51.32% |
| Recall | 55.60% | 74.10% | |
| F1-score | 62.36% | 60.64% | |
| Conditional Random Fields | Precision | 63.48% | 73.60% |
| Recall | 44.35% | 59.01% | |
| F1-score | 52.21% | 65.50% | |
| Random Forest | Precision | 49.87% | 65.8% |
| Recall | 36.12% | 50.1% | |
| F1-score | 41.89% | 56.89% | |
| Bidirectional LSTM | Precision | - | 81.13% |
| Recall | - | 75.61% | |
| F1-score | - | 78.27% |
| Entity Class | Lexicon-Based Model | CRF Model | RF Model | Bi-LSTM Model |
|---|---|---|---|---|
| TEMPO | 91.7% | 65.9% | 75.2% | 71.27% |
| VALOR | 62.8% | 34.6% | 18.6% | - |
| PESSOA | 39.5% | 69.4% | 60.2% | 80.78% |
| LOCAL | 51.9% | 77.5% | 58.4% | 80% |
| ORGANIZACAO | - | 47.1% | 34.1% | 80.5% |
| Entity Classes | Used Models |
|---|---|
| Personal Identifications Numbers | Rule-Based Models |
| CodigoPostal | |
| EnderecoElectronico | |
| Profissao | Lexicon-Based Models |
| Med | |
| Tempo | |
| Valor | |
| Pessoa | Machine Learning Models (Bi-LSTM) |
| Local | |
| Organizacao |
| Metrics | Results |
|---|---|
| Precision | 87.60% |
| Recall | 79.02% |
| F1-score | 83.01% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dias, M.; Boné, J.; Ferreira, J.C.; Ribeiro, R.; Maia, R. Named Entity Recognition for Sensitive Data Discovery in Portuguese. Appl. Sci. 2020, 10, 2303. https://doi.org/10.3390/app10072303
Dias M, Boné J, Ferreira JC, Ribeiro R, Maia R. Named Entity Recognition for Sensitive Data Discovery in Portuguese. Applied Sciences. 2020; 10(7):2303. https://doi.org/10.3390/app10072303
Chicago/Turabian StyleDias, Mariana, João Boné, João C. Ferreira, Ricardo Ribeiro, and Rui Maia. 2020. "Named Entity Recognition for Sensitive Data Discovery in Portuguese" Applied Sciences 10, no. 7: 2303. https://doi.org/10.3390/app10072303
APA StyleDias, M., Boné, J., Ferreira, J. C., Ribeiro, R., & Maia, R. (2020). Named Entity Recognition for Sensitive Data Discovery in Portuguese. Applied Sciences, 10(7), 2303. https://doi.org/10.3390/app10072303