Development and Assessment of a Sensor-Based Orientation and Positioning Approach for Decreasing Variation in Camera Viewpoints and Image Transformations at Construction Sites


Abstract
:Featured Application
Abstract
1. Introduction
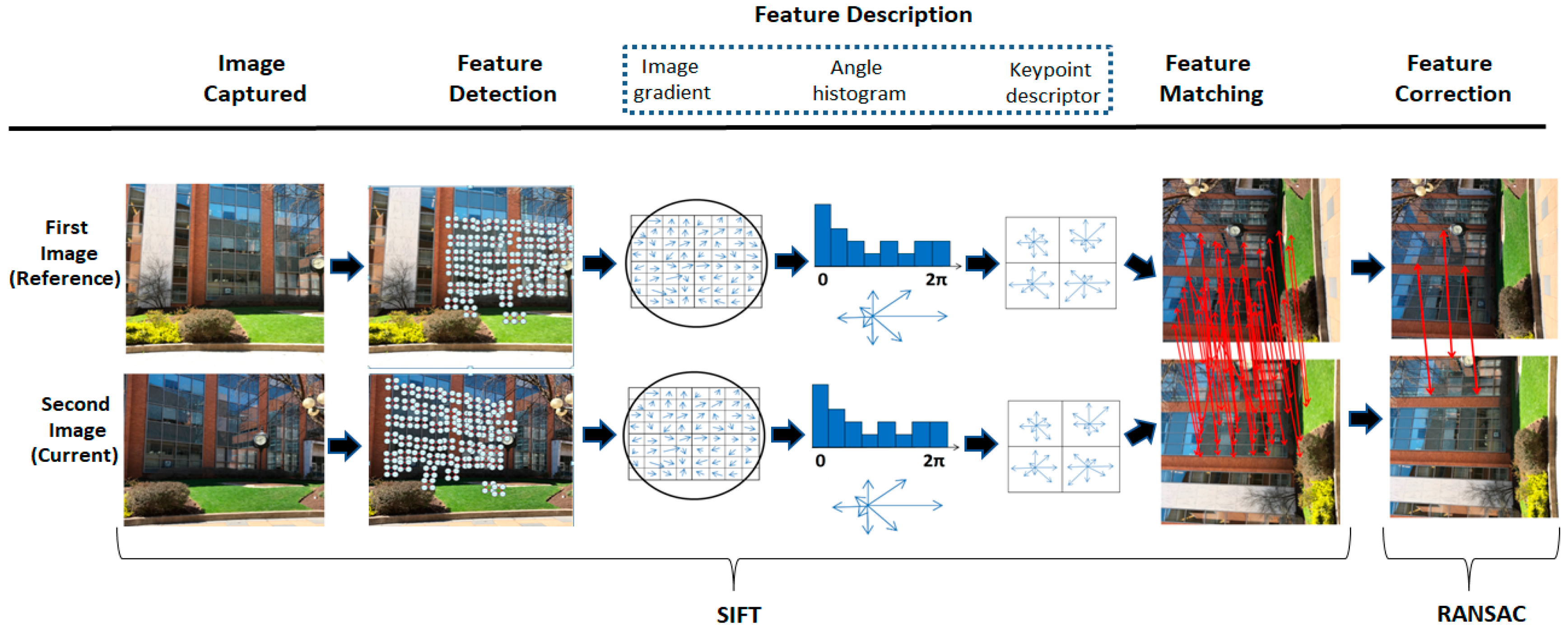
1.1. Image Matching Applications in the Construction Industry
1.2. Problem Statement
1.3. Ways to Control the Image Capture Process (Process Management)
1.4. Research Objectives
1.5. Research Methodology
2. Background Information for Method Development
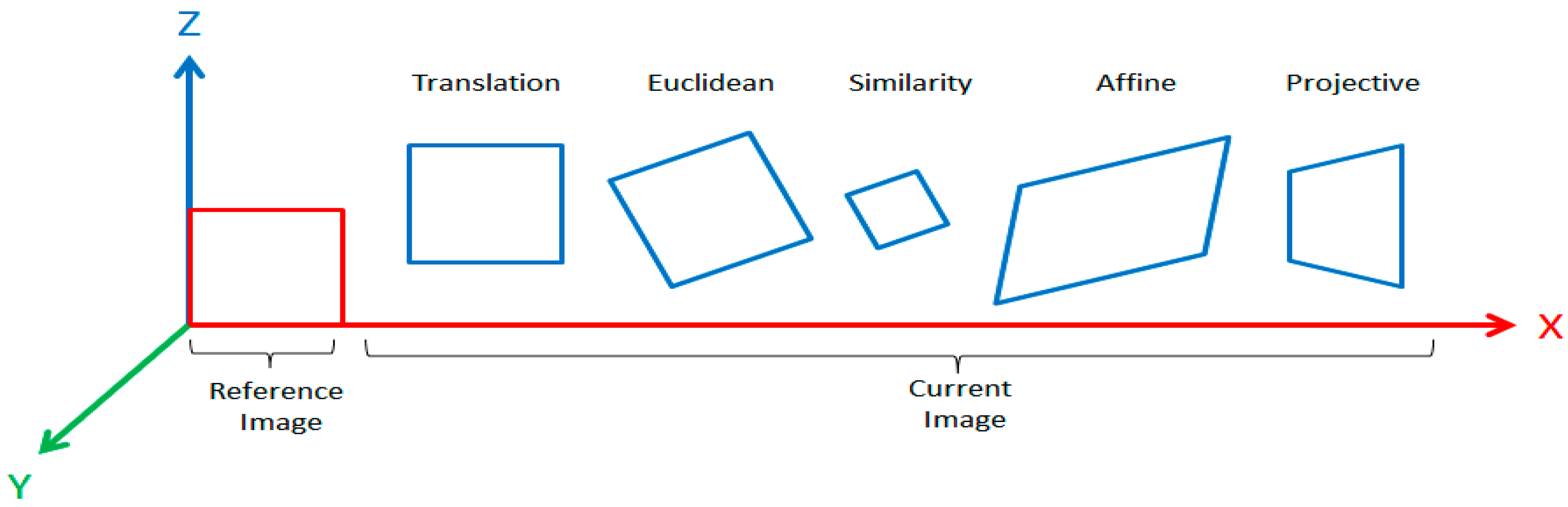
2.1. Image Transformation
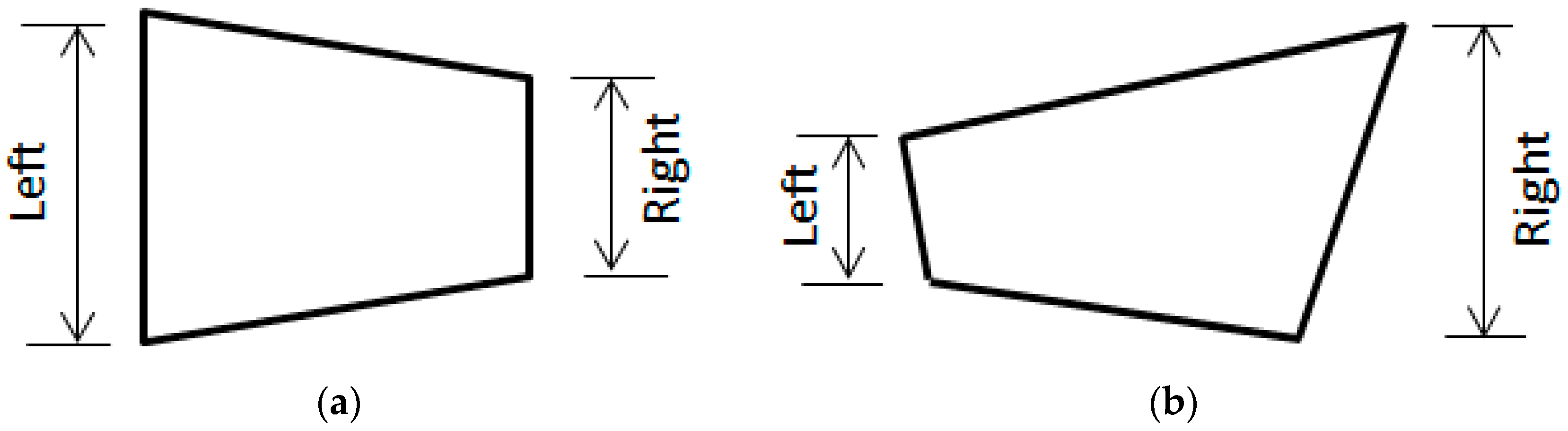
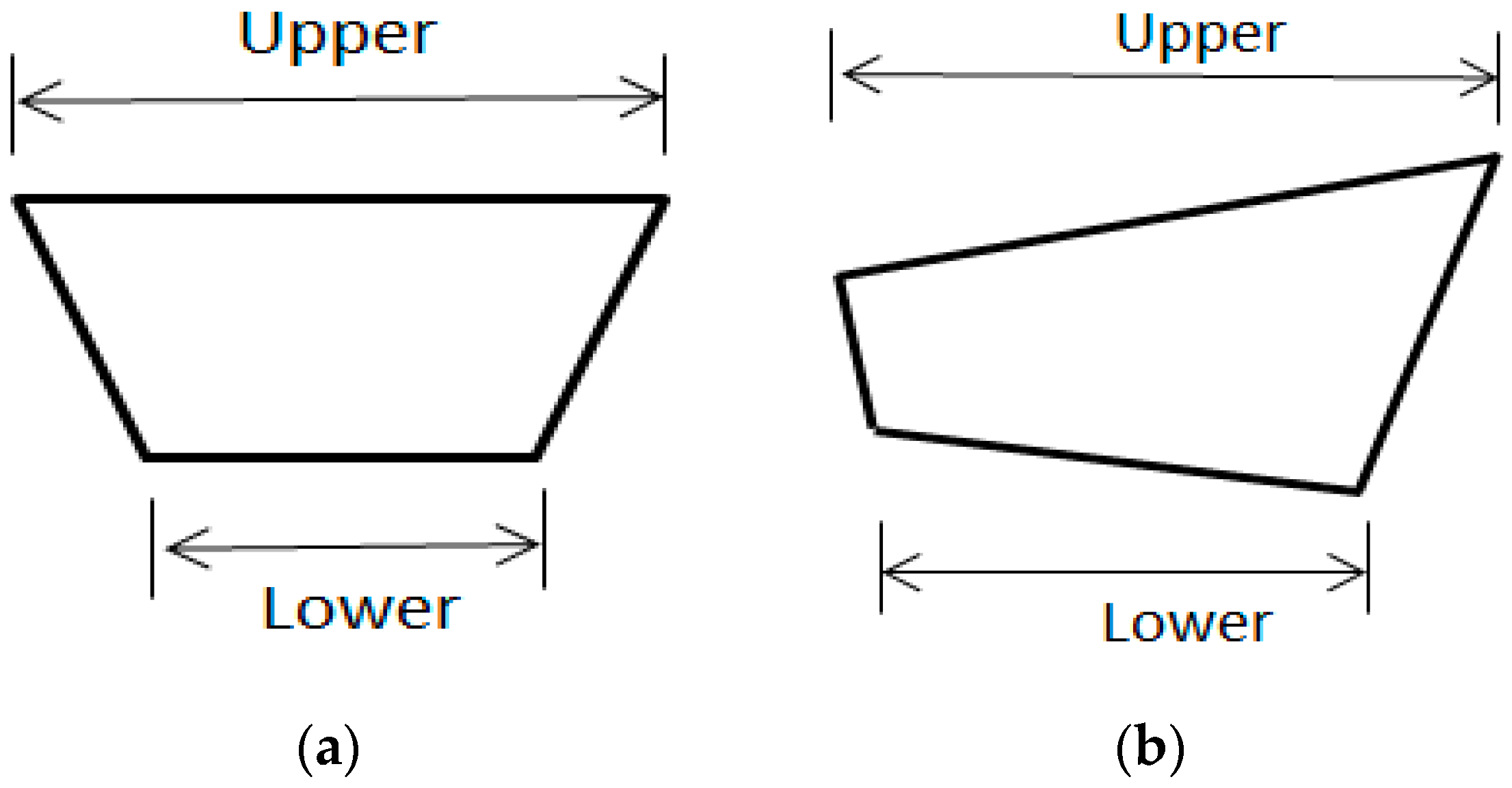
2.2. Image Transformation Scenarios: Illustrative Case Study (i.e., Examples of Image-Based Scene Transformations)
Advanced Transformations
2.3. Propose an Approach Based on Localization Systems to Remotely Repeat and Retrieve the Camera’s Position and Orientation to Decrease Image Transformation (Sensor-Based Tracking Systems)
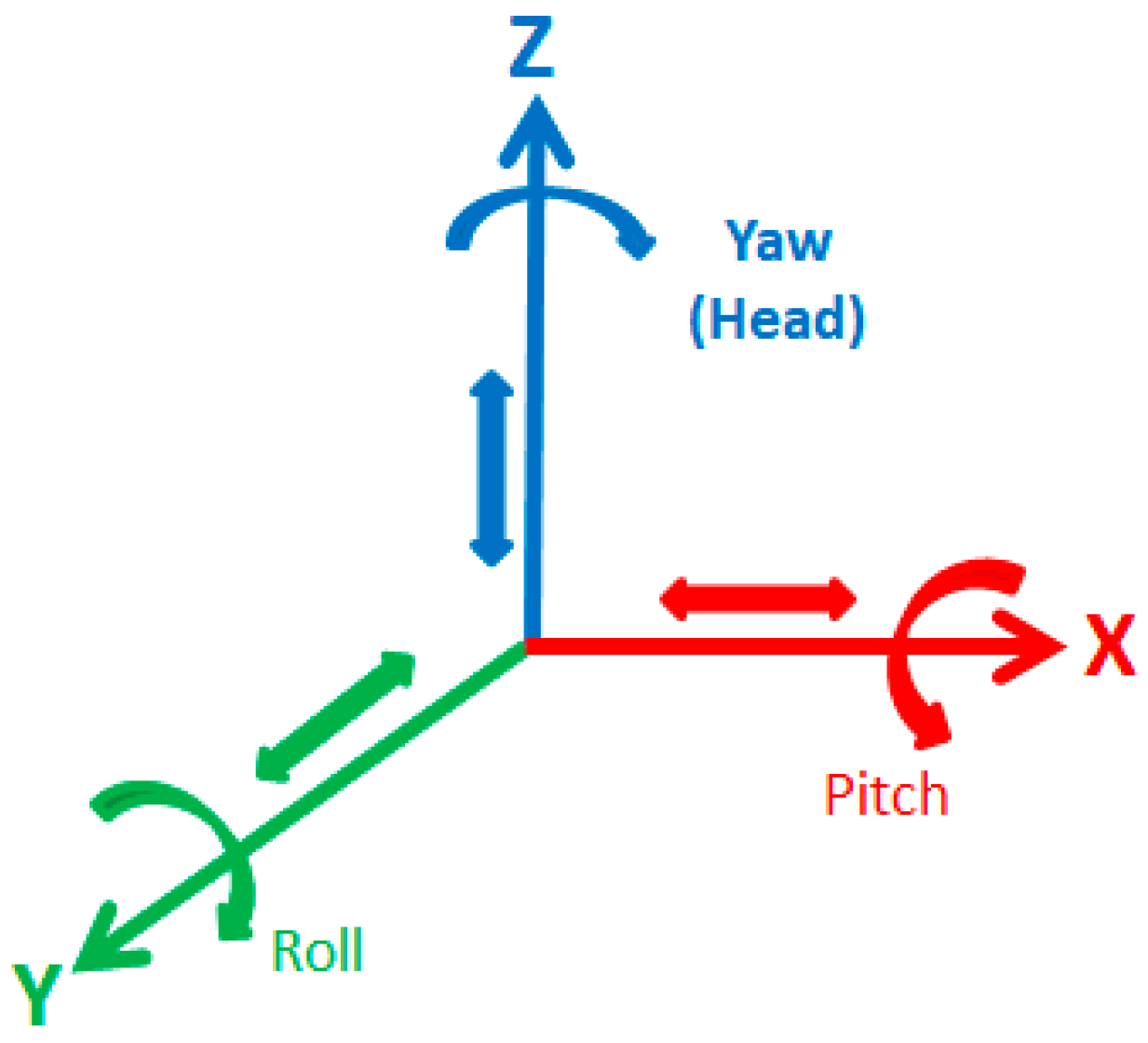
Required Position and Orientation Sensors
- Distance = time of flight × speed of light
- Speed of light = 299,792,458 m/s
3. Methods
3.1. System Architecture: Positioning and Orientation
3.2. Prototype Development
3.3. Experimental Testing of the Prototype System
3.3.1. Experimental Design
3.3.2. Experiment Tasks
- Position → XY = [0], Z = [0]
- Orientation → Head = [0], Pitch = [0], Roll = [0].
4. Results and Discussion
4.1. Limitations
4.2. Measuring Changes in Camera’s Position and Orientation
4.3. Results of Camera’s Positioning Accuracy and Precision in the X and Y Directions
- Accuracy in the X direction The results of the experiment regarding accuracy (i.e., producing pictures resembling the reference picture) showed that when the images were captured with the assistance of positioning sensors, they more accurately resembled the reference picture. In other words, when the participants did not use the sensors during the first task, the average error, in terms of accuracy in the X direction, was (30 cm), but when they used the sensors during the second task, the average error decreased to (0.3 cm).
- Accuracy in the Y direction The same situation occurred in the Y direction. In the Y direction, which reflected scaling, the average accuracy error decreased from (33 cm) to (6.8 cm) when the participants used a positioning sensor during the second task.
- Precision in the X direction The results regarding precision (i.e., producing pictures resembling each other) in the X direction showed an exciting result. In this direction, precision decreased when the participants used the sensor-based approach. In other words, the pictures captured during the first task without sensors had less standard deviation (15.5 cm) as compared with those that were captured during the second task (21 cm). This result indicates that when the participants wanted to take pictures from the scene without sensors, based on their common sense, they selected locations in the X direction that better resembled the reference image (the X direction was parallel to the scene). Therefore, the degree of repeatability increased. In contrast, since the sensors inherently generated error, the participants were navigated to the locations in the X direction that were less close to each other. The results are shown in Table 1.
- Precision in the Y direction The results of the experiment regarding precision determined when the images were captured with the assistance of positioning sensors showed that they were more precise in the Y direction. In other words, when participants used the sensors during the second task, the standard deviation in the Y direction decreased (from 112 cm to 13.3 cm). This result showed that in the Y direction, the positioning sensor during the second task could navigate the participants to distances that resembled the reference image more than the first task when they used their common sense.
4.4. Results of Camera’s Orientation, Accuracy, and Precision around the X, Y, and Z Directions
- Accuracy around the X-axis (pitch) The results of the experiment regarding accuracy (i.e., producing pictures resembling the reference picture) showed that the results in both approaches are very similar. While the orientation of the camera around the X-axis for the reference image was measured as 7 degrees, the average reference was 5 degrees for the first group of pictures and 2 degrees for the second group of pictures. Thus, the average accuracy error for pictures captured without using a sensor is slightly less (2 degrees vs. 5 degrees) than when the images were captured with the assistance of orientation sensors. This result shows that using the sensor did not improve the accuracy for rotation around the X-axis (pitch).
- Accuracy around the Y-axis (roll) The results showed that the average accuracy around the Y-axis for both approaches is the same. While the orientation of the camera for the reference image around the Y-axis measured 0, the average orientation for Groups 1 and 2 (with and without sensors) measured the same (1 degree). This result showed that when participants wanted to take pictures from a scene using their common sense, they could hold the tablet camera almost in the same orientation as when they used the orientation sensors (Table 2). However, as was indicated in the limitation section, two of the pictures captured by participants had 90 degrees rotation around the Y-axis of the tablet. Although these two exceptional pictures were discarded because of the high statistical skews that could affect the calculations, this could occur in real situations if crews are not warned in advance.
- Accuracy around the Z-axis (yaw) The results showed the average accuracy around the Z-axis for the sensor-based approach is slightly better than the non-sensor-based approach. While the orientation of the camera around the Z-axis for the reference image measured 10 degrees, the average for the non-sensor-based approach was 17 degrees and the sensor-based approach was 15 degrees. Therefore, the orientation accuracy error for the sensor-based approach (5 degrees) was slightly less than the non-sensor-based approach (7 degrees). This result indicates that the participants, using their common sense, can generate results closer to the reference than when they use sensors.
- Precision around the X-axis (pitch) The result regarding the standard deviation for the sensor-based approach was less than the non-sensor-based approach (7 degrees vs. 2 degrees). Therefore, precision (i.e., producing pictures that resemble each other) around the X-axis improved when the participants used the sensor-based approach. While the precision error for the non-sensor-based approach was 7 degrees, this value decreased to 2 degrees when they used the sensor-based approach. Therefore, the degree of repeatability of the camera’s orientation and picture resemblance for pitch increased.
- Precision around the Y-axis (roll) The standard deviation for both sensor-based and non-sensor-based approaches was almost the same (1.5 degrees vs. 1.2 degrees). Therefore, the results regarding the average precision error around the Y-axis (roll) were almost the same.
- Precision around the Z-axis (yaw) The standard deviation around the Z-axis reduced from 20 degrees to 7 degrees when participants used the sensor-based approach. This means the precision error for the sensor-based approach is less, as the participants could repeat the orientation of the camera regarding (yaw) with less error when using the sensor-based approach.
5. Summary and Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

- Marker-based AR (feature-based, artificial markers) In this approach, an artificial marker needs to be located in the scene or environment as a reference. Then, information about the marker is interpreted by a handheld computing device (smartphone/tablet) application. Artificial markers are printed and attached to the locations [1]. Some examples of artificial markers are dot-based markers [61], QR code markers [62,63], circular markers [64], square markers [65], and alphabetic combination markers [65]. Due to fiducial marker use in the environment, and the fact that these markers are distinguishable in the environment (physical world), the marker-based tracking approach is very robust with high accuracy [66,67,68].
- Markerless AR (feature-based, natural features) This type of AR system uses the natural features of the environment as references [24]. Depending on the algorithm used for this system, these features could be edges, corners, segments, or points [23]. In this online approach, features extracted from current video frames taken from the scene are compared with features extracted from an initial key frame. Then, correspondence between feature pairs is created. This loop continues until the best match between features has been computed [1]. If enough numbers of matches are identified, the virtual data stored in repository is queried and appears on the screen of the computing device, such as a smartphone or tablet.
Appendix B
B.1. First Group of Samples

B.2. Second Group of Samples

References
- Szeliski, R. Computer Vision: Algorithms and Applications. Computer (Long. Beach. Calif.) 2010, 5, 832. [Google Scholar]
- Forsyth, D.A.; Ponce, J. Computer Vision, A Modern Approach; Printice Hall: Upper Saddle River, NJ, USA, 2003. [Google Scholar]
- Shapiro, L.G.; Stockman, G.C. Computer Vision: Theory and Applications; Prentice Hall: Upper Saddle River, NJ, USA, 2001. [Google Scholar]
- Horn, B.; Klaus, B.; Horn, P. Robot Vision; MIT Press: Cambridge, NY, USA, 1986; ISBN 0262081598. [Google Scholar]
- Chen, M.; Shao, Z.; Li, D.; Liu, J. Invariant matching method for different viewpoint angle images. Appl. Opt. 2013, 52, 96–104. [Google Scholar] [CrossRef]
- Dai, X.L.; Lu, J. An object-based approach to automated image matching. In Proceedings of the IEEE 1999 International Geoscience and Remote Sensing Symposium. IGARSS’99 (Cat. No. 99CH36293), Hamburg, Germany, 28 June–2 July 1999; Volume 2, pp. 1189–1191. [Google Scholar]
- Karami, E.; Prasad, S.; Shehata, M. Image Matching Using SIFT, SURF, BRIEF and ORB: Performance Comparison for Distorted Images. In Proceedings of the 2015 Newfoundland Electrical and Computer Engineering Conference, St. John’s, NL, Canada, 14–15 April 2015; p. 4. [Google Scholar]
- Sinha, S.N.; Frahm, J.M.; Pollefeys, M.; Genc, Y. Feature tracking and matching in video using programmable graphics hardware. Mach. Vis. Appl. 2011, 22, 207–217. [Google Scholar] [CrossRef]
- Brown, M.; Lowe, D.G. Automatic panoramic image stitching using invariant features. Int. J. Comput. Vis. 2007, 74, 59–73. [Google Scholar] [CrossRef] [Green Version]
- Szeliski, R.; Shum, H.-Y. Creating full view panoramic image mosaics and environment maps. In Proceedings of the 24th Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 3–8 August 1997; pp. 251–258. [Google Scholar]
- Kratochvil, B.E.; Dong, L.X.; Zhang, L.; Nelson, B.J. Image-based 3D reconstruction using helical nanobelts for localized rotations. J. Microsc. 2010, 237, 122–135. [Google Scholar] [CrossRef]
- Lu, Q.; Lee, S. Image-based technologies for constructing as-is building information models for existing buildings. J. Comput. Civ. Eng. 2017, 31, 4017005. [Google Scholar] [CrossRef]
- Moghaddam, B.; Pentland, A. Probabilistic visual learning for object representation. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 696–710. [Google Scholar] [CrossRef] [Green Version]
- Rowley, H.A.; Baluja, S.; Kanade, T. Neural network-based face detection. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 23–38. [Google Scholar] [CrossRef]
- Pérez-Lorenzo, J.; Vázquez-Martín, R.; Marfil, R.; Bandera, A.; Sandoval, F. Image Matching Based on Curvilinear Regions; IntechOpen: London, UK, 2007. [Google Scholar]
- Takacs, G.; Chandrasekhar, V.; Tsai, S.; Chen, D.; Grzeszczuk, R.; Girod, B. Rotation-invariant fast features for large-scale recognition and real-time tracking. Signal Process. Image Commun. 2013, 28, 334–344. [Google Scholar] [CrossRef]
- Tang, S.; Andriluka, M.; Schiele, B. Detection and tracking of occluded people. Int. J. Comput. Vis. 2014, 110, 58–69. [Google Scholar] [CrossRef]
- Kang, H.; Efros, A.A.; Hebert, M.; Kanade, T. Image matching in large scale indoor environment. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, CVPR 2009, Miami, FL, USA, 20–25 June 2009; pp. 33–40. [Google Scholar]
- Kim, H.; Kano, N. Comparison of construction photograph and VR image in construction progress. Autom. Constr. 2008, 17, 137–143. [Google Scholar] [CrossRef]
- Jabari, S.; Zhang, Y. Building Change Detection Using Multi-Sensor and Multi-View- Angle Imagery; IOP Conference Series: Earth and Environmental Science; IOP Publishing: Halifax, NS, Canada, 2016; Volume 34. [Google Scholar]
- Gheisari, M.; Foroughi Sabzevar, M.; Chen, P.; Irizzary, J. Integrating BIM and Panorama to Create a Semi-Augmented-Reality Experience of a Construction Site. Int. J. Constr. Educ. Res. 2016, 12, 303–316. [Google Scholar] [CrossRef]
- Foroughi Sabzevar, M.; Gheisari, M.; Lo, L.J. Improving Access to Design Information of Paper-Based Floor Plans Using Augmented Reality. Int. J. Constr. Educ. Res. 2020, 1–21. [Google Scholar] [CrossRef]
- Belghit, H.; Zenati-Henda, N.; Bellabi, A.; Benbelkacem, S.; Belhocine, M. Tracking color marker using projective transformation for augmented reality application. In Proceedings of the 2012 International Conference on Multimedia Computing and Systems, Tangier, Morocco, 10–12 May 2012; pp. 372–377. [Google Scholar]
- Yuan, M.L.; Ong, S.-K.; Nee, A.Y.C. Registration using natural features for augmented reality systems. IEEE Trans. Vis. Comput. Graph. 2006, 12, 569–580. [Google Scholar] [CrossRef]
- Moravec, H.P. Techniques towards Automatic Visual Obstacle Avoidance. In Proceedings of the International Joint Conference on Artificial Intelligence, Cambridge, MA, USA, 22–25 August 1977; p. 584. [Google Scholar]
- Harris, C.G.; Stephens, M. A combined corner and edge detector. In Proceedings of the Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988; pp. 147–151. [Google Scholar]
- Smith, S.M.; Brady, J.M. SUSAN—A new approach to low level image processing. Int. J. Comput. Vis. 1997, 23, 45–78. [Google Scholar] [CrossRef]
- Rosten, E.; Drummond, T. Fusing points and lines for high performance tracking. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05) Volume 1, Washington, DC, USA, 17–21 October 2005; Volume 2, pp. 1508–1515. [Google Scholar]
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 430–443. [Google Scholar]
- Beaudet, P.R. Rotationally invariant image operators. In Proceedings of the 4th International Joint Conference on Pattern Recognition, Tokyo, Japan, 7–10 November 1978. [Google Scholar]
- Lakemond, R.; Sridharan, S.; Fookes, C. Hessian-based affine adaptation of salient local image features. J. Math. Imaging Vis. 2012, 44, 150–167. [Google Scholar] [CrossRef] [Green Version]
- Lindeberg, T. Scale selection properties of generalized scale-space interest point detectors. J. Math. Imaging Vis. 2013, 46, 177–210. [Google Scholar] [CrossRef] [Green Version]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Mikolajczyk, K.; Schmid, C. Scale & affine invariant interest point detectors. Int. J. Comput. Vis. 2004, 60, 63–86. [Google Scholar]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Yussof, W.N.J.H.W.; Hitam, M.S. Invariant Gabor-based interest points detector under geometric transformation. Digit. Signal Process. 2014, 25, 190–197. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Morel, J.-M.; Yu, G. ASIFT: A new framework for fully affine invariant image comparison. SIAM J. Imaging Sci. 2009, 2, 438–469. [Google Scholar] [CrossRef]
- Yu, G.; Morel, J.-M. A fully affine invariant image comparison method. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 1597–1600. [Google Scholar]
- Yu, Y.; Huang, K.; Chen, W.; Tan, T. A novel algorithm for view and illumination invariant image matching. IEEE Trans. Image Process. 2011, 21, 229–240. [Google Scholar]
- Wu, J.; Cui, Z.; Sheng, V.S.; Zhao, P.; Su, D.; Gong, S. A comparative study of SIFT and its variants. Meas. Sci. Rev. 2013, 13, 122–131. [Google Scholar] [CrossRef] [Green Version]
- Dellinger, F.; Delon, J.; Gousseau, Y.; Michel, J.; Tupin, F. Change detection for high resolution satellite images, based on SIFT descriptors and an a contrario approach. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 1281–1284. [Google Scholar]
- Höllerer, T.; Feiner, S. Mobile augmented reality. In Telegeoinformatics: Location-Based Computing and Services; Karimi, H.A., Hammad, A., Eds.; CRC Press: Boca Raton, FL, USA, 2004; ISBN 0-4153-6976-2. [Google Scholar]
- Sebastian Richard Hitting the Spot. Available online: http://spie.org/x26572.xml (accessed on 8 August 2019).
- LaMarca, A.; Chawathe, Y.; Consolvo, S.; Hightower, J.; Smith, I.; Scott, J.; Sohn, T.; Howard, J.; Hughes, J.; Potter, F. Place lab: Device positioning using radio beacons in the wild. In Proceedings of the International Conference on Pervasive Computing, Munich, Germany, 8–13 May 2005; pp. 116–133. [Google Scholar]
- Khoury, H.M.; Kamat, V.R. Evaluation of position tracking technologies for user localization in indoor construction environments. Autom. Constr. 2009, 18, 444–457. [Google Scholar] [CrossRef]
- Rolland, J.P.; Davis, L.D.; Baillot, Y. A survey of tracking technologies for virtual environments. In Fundamentals of Wearable Computers and Augmented Reality; CRC Press: Boca Raton, FL, USA, 2001; pp. 67–112. [Google Scholar]
- Bargh, M.S.; de Groote, R. Indoor localization based on response rate of bluetooth inquiries. In Proceedings of the First ACM International Workshop on Mobile Entity Localization and Tracking in GPS-Less Environments, San Francisco, CA, USA, 19 September 2008; pp. 49–54. [Google Scholar]
- Want, R.; Hopper, A.; Falcao, V.; Gibbons, J. The active badge location system. ACM Trans. Inf. Syst. 1997, 4, 42–47. [Google Scholar] [CrossRef]
- Bahl, P.; Padmanabhan, V.N. RADAR: An in-building RF-based user location and tracking system. In Proceedings of the Proceedings IEEE INFOCOM 2000. Conference on Computer Communications. Nineteenth Annual Joint Conference of the IEEE Computer and Communications Societies (Cat. No. 00CH37064), Tel Aviv, Israel, 26–30 March 2000; Volume 2, pp. 775–784. [Google Scholar]
- Karlekar, J.; Zhou, S.Z.Y.; Nakayama, Y.; Lu, W.; Chang Loh, Z.; Hii, D. Model-based localization and drift-free user tracking for outdoor augmented reality. In Proceedings of the 2010 IEEE International Conference on Multimedia and Expo, ICME 2010, Singapore, 19–23 July 2010; pp. 1178–1183. [Google Scholar]
- Deak, G.; Curran, K.; Condell, J. A survey of active and passive indoor localisation systems. Comput. Commun. 2012, 35, 1939–1954. [Google Scholar] [CrossRef]
- Gezici, S.; Tian, Z.; Giannakis, G.B.; Kobayashi, H.; Molisch, A.F.; Poor, H.V.; Sahinoglu, Z. Localization via ultra-wideband radios: A look at positioning aspects for future sensor networks. IEEE Signal Process. Mag. 2005, 22, 70–84. [Google Scholar] [CrossRef]
- Pozyx. Available online: https://www.pozyx.io/ (accessed on 8 August 2017).
- Popa, M.; Ansari, J.; Riihijarvi, J.; Mahonen, P. Combining cricket system and inertial navigation for indoor human tracking. In Proceedings of the 2008 IEEE Wireless Communications and Networking Conference, Las Vegas, NV, USA, 31 March–3 April 2008; pp. 3063–3068. [Google Scholar]
- Microsoft. Available online: https://www.microsoft.com/en-us/surface (accessed on 10 December 2017).
- Distance to Objects Using Single Vision Camera. Available online: https://www.youtube.com/watch?v=Z3KX0N56ZoA (accessed on 1 March 2020).
- Soanes, C. Oxford Dictionary of English; Oxford University Press: New York, NY, USA, 2003; ISBN 0198613474. [Google Scholar]
- Milgram, P.; Kishino, F. A taxonomy of mixed reality visual displays. IEICE Trans. Inf. Syst. 1994, 77, 1321–1329. [Google Scholar]
- Azuma, R.T. A survey of augmented reality. Presence Teleoperators Virtual Environ. 1997, 6, 355–385. [Google Scholar] [CrossRef]
- Bergamasco, F.; Albarelli, A.; Rodola, E.; Torsello, A. Rune-tag: A high accuracy fiducial marker with strong occlusion resilience. In Proceedings of the CVPR 2011, Providence, RI, USA, 20–25 June 2011; pp. 113–120. [Google Scholar]
- Kan, T.-W.; Teng, C.-H.; Chou, W.-S. Applying QR code in augmented reality applications. In Proceedings of the 8th International Conference on Virtual Reality Continuum and its Applications in Industry, Yokohama, Japan, 14–15 December 2009; pp. 253–257. [Google Scholar]
- Ruan, K.; Jeong, H. An augmented reality system using Qr code as marker in android smartphone. In Proceedings of the 2012 Spring Congress on Engineering and Technology, Xi’an, China, 27–30 May 2012; pp. 1–3. [Google Scholar]
- Naimark, L.; Foxlin, E. Circular data matrix fiducial system and robust image processing for a wearable vision-inertial self-tracker. In Proceedings of the Proceedings. International Symposium on Mixed and Augmented Reality, Darmstadt, Germany, 1 October 2002; pp. 27–36. [Google Scholar]
- Han, S.; Rhee, E.J.; Choi, J.; Park, J.-I. User-created marker based on character recognition for intuitive augmented reality interacion. In Proceedings of the 10th International Conference on Virtual Reality Continuum and Its Applications in Industry, Hong Kong, China, 11–12 December 2011; pp. 439–440. [Google Scholar]
- Pucihar, K.Č.; Coulton, P. Exploring the Evolution of Mobile Augmented Reality for Future Entertainment Systems. Comput. Entertain. 2015, 11, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Tateno, K.; Kitahara, I.; Ohta, Y. A nested marker for augmented reality. In Proceedings of the 2007 IEEE Virtual Reality Conference, Charlotte, NC, USA, 10–14 March 2007; pp. 259–262. [Google Scholar]
- Yan, Y. Registration Issues in Augmented Reality; University of Birmingham: Edgbaston, Birmingham, UK, 2015. Available online: https://pdfs.semanticscholar.org/ded9/2aa404e29e9cc43a08958ca7363053972224.pdf (accessed on 1 February 2020).



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Image | The Distance between the Center of Lens and Center of the Fixed Point on Scene | In the X Direction (cm) | In the Y Direction (cm) | In the Z Direction (cm) |
|---|---|---|---|---|
| Reference image | 44.71 | 330.5 | N/A | |
| Group 1 (without sensor) | Avg. | 14.7 | 297 | N/A |
| Min. | 0 | 154 | N/A | |
| Max. | 77 | 582 | N/A | |
| Precision Error (SD) | 15.5 | 112 | N/A | |
| Accuracy Error | 30 | 33 | N/A | |
| Range | 77 | 428 | N/A | |
| Group 2 (with sensor) | Avg. | 45 | 337 | N/A |
| Min. | 11 | 312 | N/A | |
| Max. | 101 | 366 | N/A | |
| Precision Error (SD) | 21 | 13.3 | N/A | |
| Accuracy Error | 0.3 | 6.8 | N/A | |
| Range | 90 | 54 | N/A |
| Type of Image | Rotation | Pitch (Ratio), Degree | Roll Degree | Yaw or Head (Ratio), Degree |
|---|---|---|---|---|
| Reference image | (0.97), 7 | 0 | (0.96), 10 | |
| Group 1 (without sensor) | Avg. | (0.98), 5 | 1 | (0.93), 17 |
| Min. | (1), 0 | 0 | (1), 0 | |
| Max. | (0.85), 38 | 6.5 [90 *] | (0.69), 80 | |
| Precision Error (SD) | (0.03), 7 | 1.5 | (0.08), 20 | |
| Accuracy Error | (0.01), 2 | 1 | (0.03), 7 | |
| Range | 38 | 6.5 [90 *] | 80 | |
| Group 2 (with sensor) | Avg. | (0.99), 2 | 1 | (0.94), 15 |
| Min. | (1), 0 | 0 | (0.99), 2 | |
| Max. | (0.96), 10 | 4.5 | (0.85), 38 | |
| Precision Error (SD) | (0.01), 2 | 1.2 | (0.03), 7 | |
| Accuracy Error | (0.02), 5 | 1 | (0.02), 5 | |
| Range | 10 | 4.5 | 36 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Foroughi Sabzevar, M.; Gheisari, M.; Lo, J. Development and Assessment of a Sensor-Based Orientation and Positioning Approach for Decreasing Variation in Camera Viewpoints and Image Transformations at Construction Sites. Appl. Sci. 2020, 10, 2305. https://doi.org/10.3390/app10072305
Foroughi Sabzevar M, Gheisari M, Lo J. Development and Assessment of a Sensor-Based Orientation and Positioning Approach for Decreasing Variation in Camera Viewpoints and Image Transformations at Construction Sites. Applied Sciences. 2020; 10(7):2305. https://doi.org/10.3390/app10072305
Chicago/Turabian StyleForoughi Sabzevar, Mohsen, Masoud Gheisari, and James Lo. 2020. "Development and Assessment of a Sensor-Based Orientation and Positioning Approach for Decreasing Variation in Camera Viewpoints and Image Transformations at Construction Sites" Applied Sciences 10, no. 7: 2305. https://doi.org/10.3390/app10072305
APA StyleForoughi Sabzevar, M., Gheisari, M., & Lo, J. (2020). Development and Assessment of a Sensor-Based Orientation and Positioning Approach for Decreasing Variation in Camera Viewpoints and Image Transformations at Construction Sites. Applied Sciences, 10(7), 2305. https://doi.org/10.3390/app10072305