1. Introduction
The development of the Internet, automation, intelligent decision support, and other technologies has driven the manufacturing industry to transform towards digitalization, networking, and intelligence [
1,
2,
3]. The manufacturing environment of enterprises has gradually expanded from the traditional workshop to large-scale, highly dynamic networked version [
4,
5,
6,
7], such as the CMfg (Cloud Manufacturing), where the cloud platform has pooled massive virtualized manufacturing resources from geographically distributed providers [
8,
9], including hardware resources (such as machining center, lathe, assembly line, materials, etc.), software resources (such as CAD/CAE, simulation, computing capabilities), human resources, knowledge resources, and so on. Therefore, how to schedule these manufacturing resources to serve emerging manufacturing tasks in real-time is not only an urgent requirement in the CMfg environment but also a common problem of the generalized networked manufacturing models, such as Smart Manufacturing and Industrial 4.0 [
10,
11]. Compared with the traditional workshop environment, real-time scheduling in the CMfg is more complicated because logistics factors need to be considered when using distributed massive heterogeneous manufacturing resources [
12], and complex manufacturing projects bring precedence constraints at the same time. In addition, the provider needs to take into account its internal processing plan while coordinating with the demander, and the considerations of differences in management, specifications, and protocols among the enterprises are also needed [
13,
14]. Although there have been many studies focused on modeling, solving, and optimization of the scheduling problem in the workshop environment, their research results cannot be directly applied to the networked manufacturing environment because the scale of the problem is dramatically increased.
In the academic consensus, the main kinds of users in the CMfg platform can be described by a so-called “tri-group” model [
4,
15,
16], which is summarized as:
- Demander
Users who publish manufacturing tasks to the platform, and request to purchase the manufacturing resource services provided by the platform.
- Provider
Users who register manufacturing resources on the platform, providing virtualized manufacturing resources, such as software, equipment, materials, and labor.
- Operator
Users who operate and manage the platform; they (1) decompose the demands into manufacturing tasks, (2) encapsulate the registered manufacturing resources through virtualization technology, and (3) match the manufacturing services and provide decision support applications.
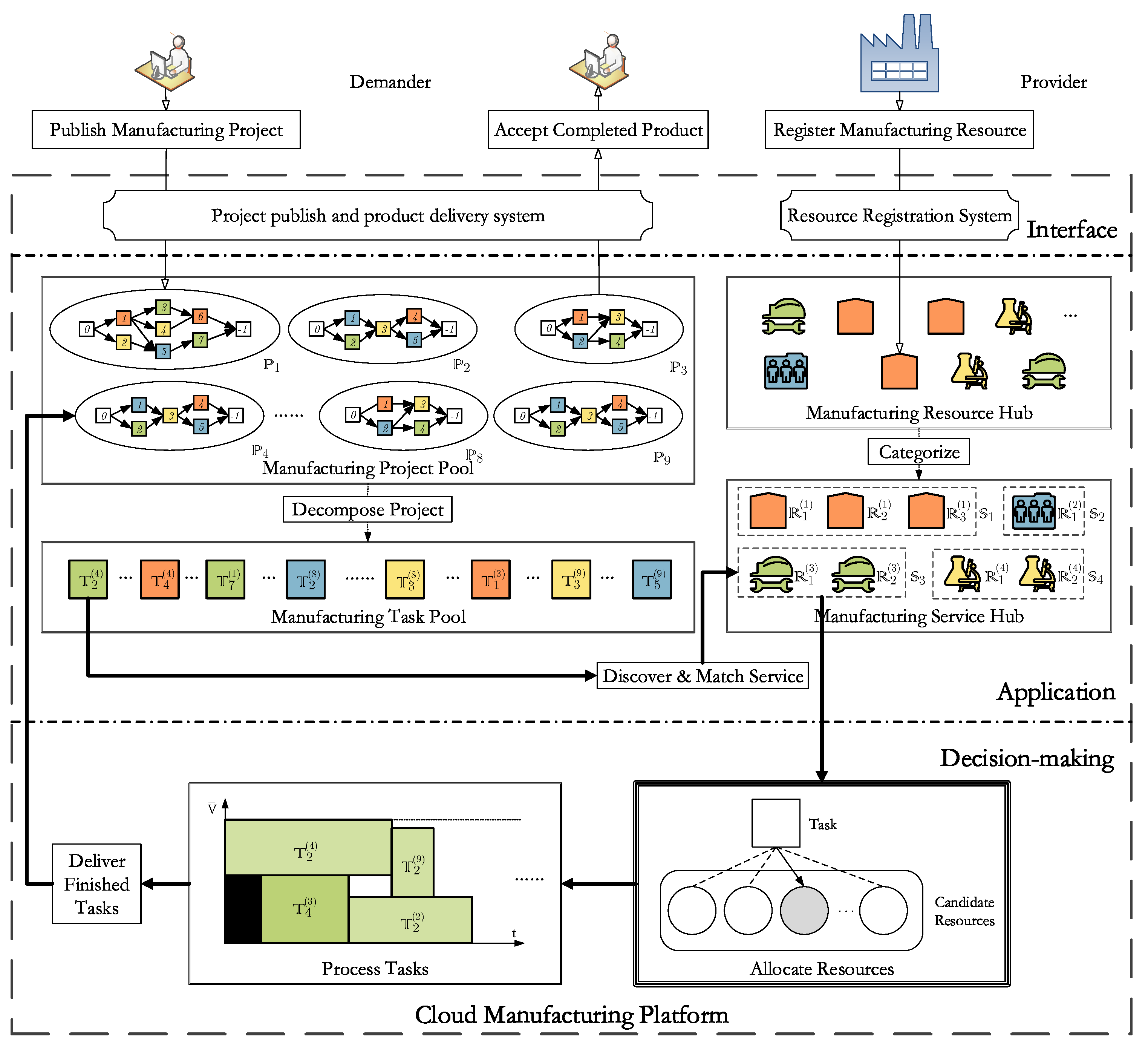
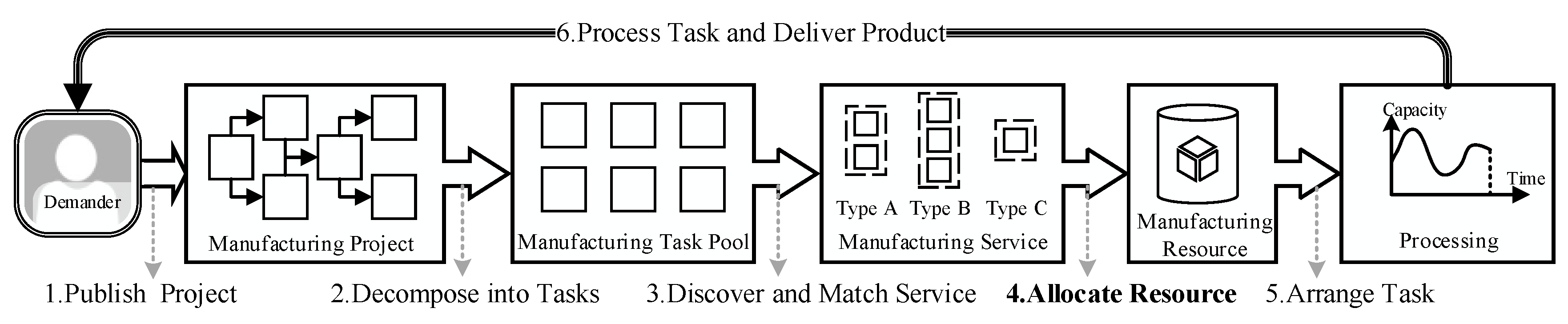
The CMfg environment within the research scope of this article can be briefly described, as shown in
Figure 1, and the meaning of the symbols is described in
Table 1.
This architecture is mainly composed of three layers of functions, namely interface, application, and decision-making. The real-time scheduling problem comes from the decision-making layer. Accordingly, the process of the demander using the services provided by the platform can be described as follows:
Demanders publish MP (Manufacturing Project) to the platform;
Platform decomposes MP into MTs (Manufacturing Tasks);
Platform discovers and matches MR (Manufacturing Resource) in type-matched MS (Manufacturing Service) for these MTs;
Platform allocates MR for the processing of MT.
Providers arrange MTs using professional software and deliver the completed MTs to demanders.
Therefore, the scheduling problem in the CMfg environment is as follows: how to reasonably allocate the emerging MTs to the type-matched MRs in real-time under the constraints of task precedence, resource occupation, and logistics duration while reducing the service costs, improving the service quality, and shortening the make-span for each MP?
Since the scheduling environment of CMfg is larger and more dynamic than that of the traditional workshop [
17,
18], it is much more difficult to find the optimal solution. As a consequence, the focus of related research turns to find the approximate optimal solution. As a major branch of approximation methods, a search-based heuristic scheduling approach expands the current schedule with well-designed strategies. The keys to designing such an approach are the neighborhood structure and the search direction, such as Simulated Annealing, Tabu-search, Discrete Search, Genetic Algorithm, and so on [
19,
20,
21,
22,
23]. However, these algorithms cannot be directly applied to the scheduling problem in the CMfg environment because they will take a long time for the solution searching.
In order to solve the real-time scheduling problem, researchers have proposed and developed numerous approaches and algorithms that can be divided into two categories: generative and adaptive. Generative scheduling adopts the idea of integrating partial-schedules, and the key lies in the design of priority rules. However, the priority rules for the determined manufacturing environment are not suitable for dynamic random situations [
24]. Hence, adaptive methods have attracted more researchers. Adaptive scheduling, which is also called rescheduling, modifies the existing schedule dynamically according to the decision environment. Proactive and reactive are the two main modes of rescheduling [
25]. Due to the uncertain factors, such as task delay, unit failure, and order insertion, the disturbances become difficult to predict, which means that the proactive rescheduling cannot be used in the real-time environments [
26]. As a result, more and more researchers have begun to focus on reactive or hybrid rescheduling methods [
27]. One group studied the random resource constrained project scheduling problem. They transformed the problem into a multi-stage decision problem, and made dynamic decisions by designing rescheduling strategies [
28]. Another group studied the rescheduling problem with new operation insertion in a single machine environment. They set up an event-triggered rescheduling model with the goal of minimizing the absolute deviation of the maximum delay compared with the baseline [
29]. For the dynamic manufacturing environment where tasks arrive randomly, a dynamic event-driven task rescheduling method is designed to avoid service rearrangement, and the constructed parallel processing strategy takes service time, logistics time, the earliest available time, and other factors into consideration at the same time for optimal service selection [
30]. Researchers have also proposed two reactive scheduling strategies based on the selection and buffering to solve the random resource constrained project scheduling problem. They found that the buffer-based reaction rules combined with the baseline scheduling turned out to be an effective solution [
31].
The above reviews indicate that it is difficult to efficiently allocate massive manufacturing resources in the CMfg environment for the real-time scheduling. Research on the real-time scheduling in the CMfg is scarce, and the proposed scheduling methods are based on reactive scheduling strategy, the baseline of which is set in advance and needs to be modified as the environment changes. For the dynamic CMfg environment, such scheduling methods will consume numerous computing resources. Changing schedules often results in the re-allocation of resources, which will lead to additional logistics costs. Generally, real-time scheduling using these approaches requires a trade-off between the solution quality and decision efficiency. With the development of artificial intelligence, more and more teams are trying to apply related technologies to the manufacturing scope [
32]. In order to solve the scheduling problem in the manufacturing environment, many neural networks are used to determine the key parameters to improve the performance of the genetic algorithm [
33,
34].
In this paper, we convert the aforementioned scheduling problem into the form of estimating the optimal objective value, and an ANN-based model is established to predict the task completion status for each candidate resource as the principle for allocating manufacturing tasks. The trained ANN model has high prediction accuracy, and the proposed ANN-based approach performs well in terms of the optimization objectives, including cost, satisfaction, and make-span. The high responsiveness of the ANN-based approach makes it suitable for the real-time scheduling in the CMfg environment.
The structure of the paper is as follows. First, we establish a mathematical model of the real-time scheduling problem in the CMfg environment in
Section 2. Then, the solution framework of this problem is defined in
Section 3. As the key issue in this framework, the decision of task allocation is made using a trained ANN model.
Section 4 conducts comparison experiments for scheduling methods in terms of objectives and responsiveness. The application design for the proposed ANN-based approach is depicted in
Section 5.
Section 6 presents the conclusion.
2. Mathematical Modeling for the CMfg Scheduling Problem
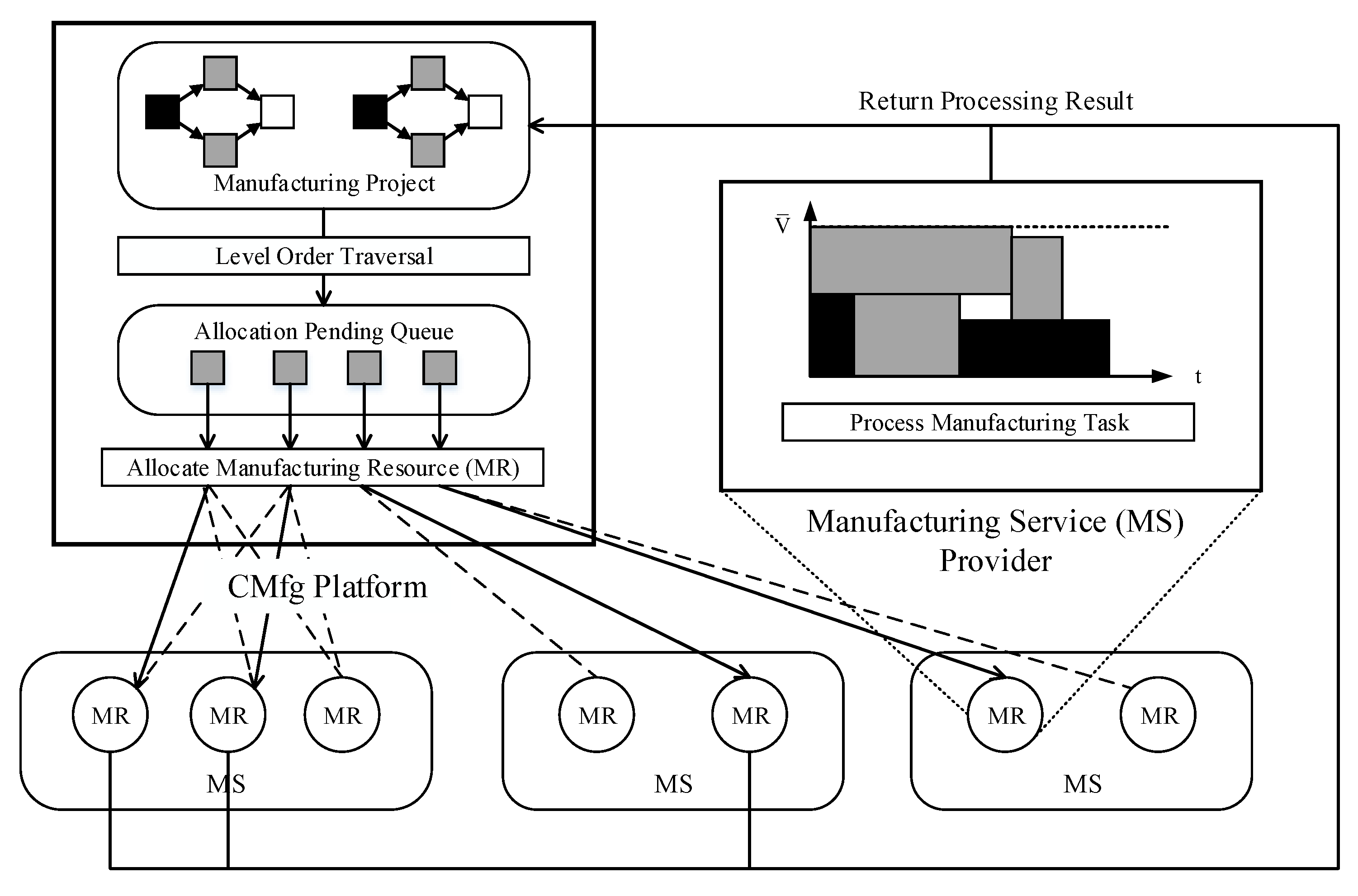
According to the CMfg platform architecture (
Figure 1), the real-time scheduling can be described as the procedure shown in
Figure 2.
The MPs in the CMfg platform consist of MTs with precedence sequence, the waiting ones for allocation are in white, and the ones in allocating are filled in gray, while the completed ones are filled in black. By using level-order traversal, the operator can allocate MTs to the type-matched MRs without precedence constraints, and these tasks will be manufactured by the corresponding providers.
Basic assumptions, as follows, are needed to focus on our research scope before mathematical modeling:
The set-up time for MT is already included in the processing time;
No interruption is considered in the processing of MTs;
The capacity of MR occupied by task processing will be released when the processing is completed;
Transportation logistics need to be considered before and after the processing of MT.
2.1. Formal Expression of the Main Components
The main components of the CMfg environment are MT and MR. Due to the consideration of management granularity, these two components are not directly presented to the scheduling problem.
Providers distributed in different locations register their encapsulated and virtualized MR capabilities to the CMfg platform. Then, the platform operator classifies these MRs according to their capability types and abstracts them into MS, which is an integrated form of MRs for the demander to use. Specifically, MS of type
k can be expressed by a tuple, as shown in Equation (
1).
where
represents the label set of MR in the same type, and
denotes the allocation pending queue of MTs at time
t.
For MR labeled
i in
, its attributes are expressed as Equation (
2).
where
and
represent unit cost and service quality, respectively.
is the maximum available capacity at time
t, and
is its upper bound.
and
denote the processing pending queue of MTs and the active MT set defined in Equation (
3) at time
t, respectively.
where
is the label mark of MT,
and
, respectively, represent the start time and finish time of processing this MT. Symbol
is a 0–1 decision variable defined as Equation (
4).
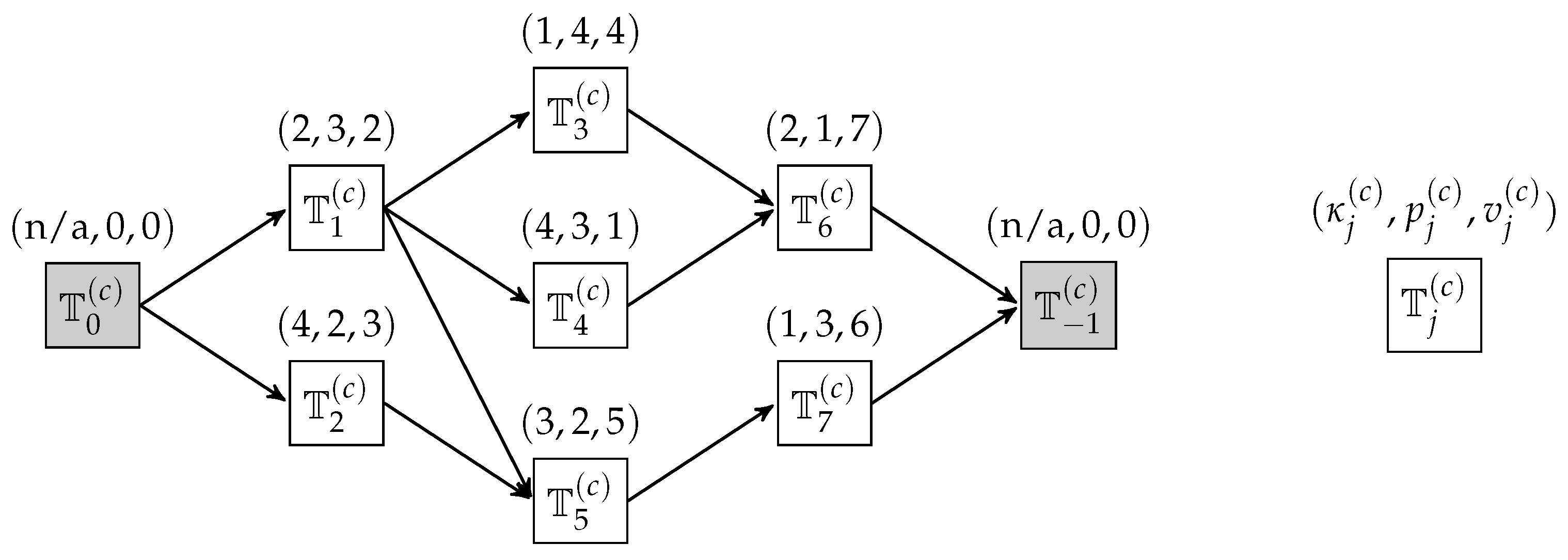
In the cloud platform, MP that is published by the demander will be pooled, and the precedence relationship of the contained MTs can be described as the activity-on-vertex network, as shown in
Figure 3.
Where
and
are dummy MTs to help stylize the MP into a single-input-single-output graph. Specifically, an MP labelled
c can be expressed by a tuple shown in Equation (
5).
where
represents the label set of MT included in
,
denotes the publish time, and
is the logistics duration vector defined as Equation (
6).
where
is the logistics duration between
and
.
For MT labelled
j in
, its attributes can be represented as Equation (
7).
where
,
, and
represent required service capacity, service capability type, and processing time, respectively.
and
, respectively, denote the immediate predecessor and the successor set.
In this way, the mathematical model of real-time scheduling in the CMfg environment can be expressed as Equations (8)–(16), and it is a multi-objectives optimization problem.
where
denotes the set of arrived MPs during time interval
, and the objective function of Equation (
8) is the accumulated mean value of objective vector
defined as Equation (
9). The composition of the objectives and the Constraints (10)–(16) will be described in detail in the rest of this section.
2.2. Optimization Objectives for Real-Time Scheduling
For each MP, the scheduling optimization objectives include three aspects, namely cost, make-span, and service quality. Without loss of generality, we proceed from the perspective of .
First of all, the service usage cost for any MP is incurred when the demander requests and uses specific MRs included in the type-matched MSs, it is equal to the sum of the usage costs of MTs inside the MP. The service usage cost for MT is determined by the unit cost of the allocated MR and the requirement for task processing. Specifically, if
is allocated to
for processing, the service usage cost is determined by Equation (
17).
Then, the service usage cost for
will be Equation (
18)
Secondly, the make-span of MP refers to the overall processing time to complete all its MTs. It needs to consider the logistics duration for all the MTs inside the MP. According to the activity-on-vertex of
as shown in
Figure 3, its make-span can be expressed as Equation (
19), where
belongs to dummy
.
Thirdly, the quality of the product refers to the satisfaction of manufacturing
, and it is determined by the intrinsic service quality of specific MRs. Since the satisfaction of processing
can be expressed as Equation (
20), the quality of the product for processing
can be defined as Equation (
21), which is the lowest satisfaction obtained by processing MTs included in
.
2.3. Constraints for Real-Time Scheduling
Constraints for real-time scheduling problems in the CMfg environment include task precedence, resources occupation, logistics duration, and so on.
Specifically, Constraints (10) and (11) indicate the logical limitation of allocation, which means that for type-matched MRs, any MT can only be assigned to one of them for processing, and each of the MT can only be processed once. As formulated in Equation (12), the processing time of any MT needs to be guaranteed, that is, the time span between the start time and the finish time of processing is at least equal to the required processing time .
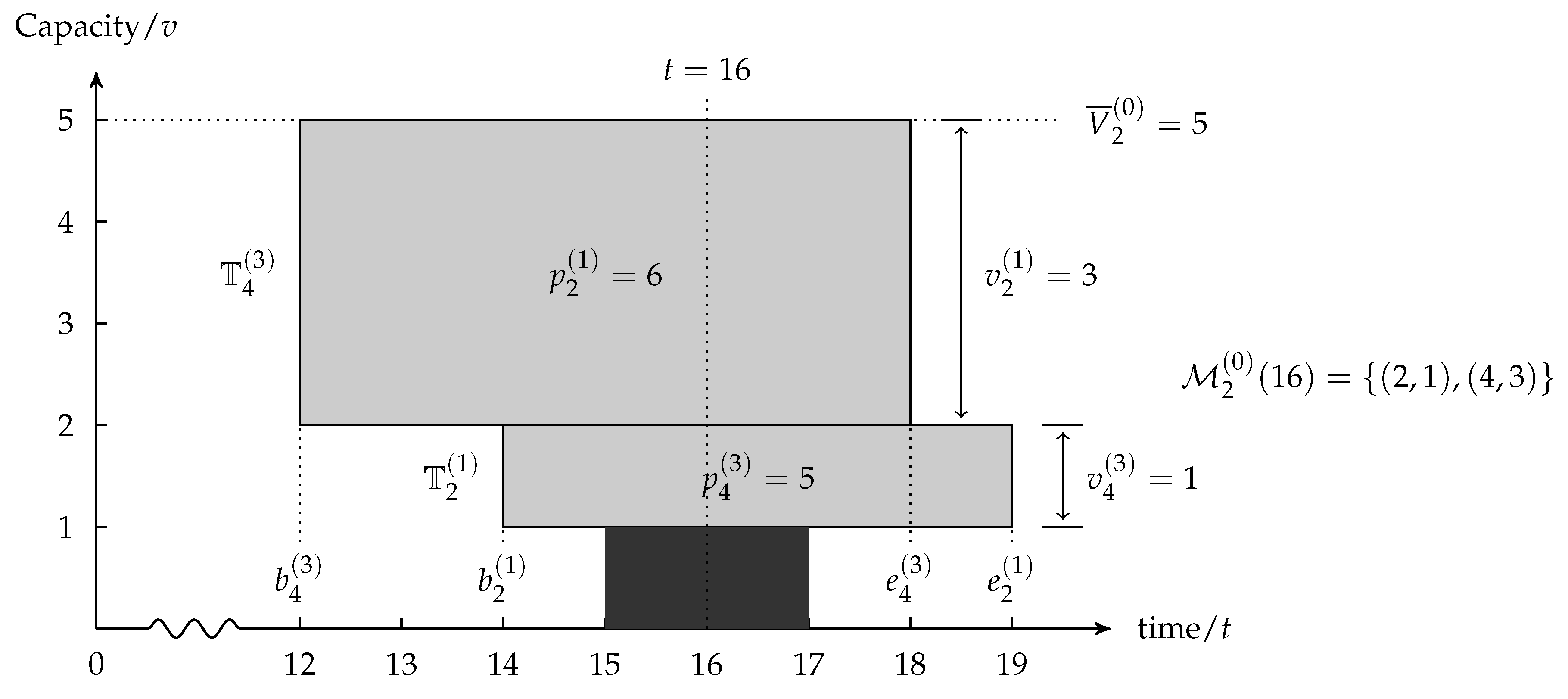
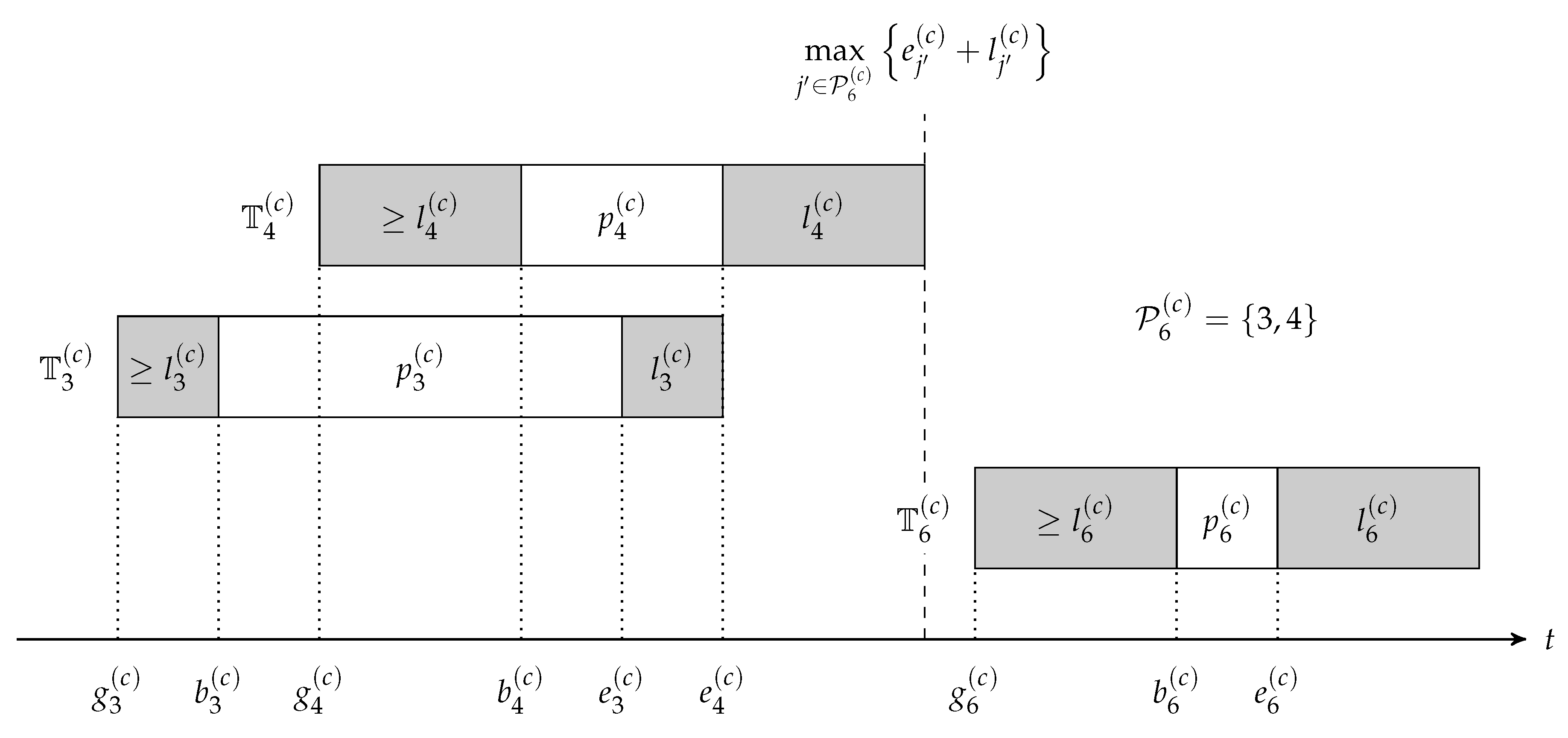
During the processing of MT, Equation (13) means the available capacity of MR needs to be no less than the capacity required by the MT, and Equation (14) indicates the sum of occupied capacity by active MTs does not exceed the maximum resource capacity at time
t. Take
, for example, as shown in
Figure 4, the capacity upper bound is
, and the rectangle in black indicates the resource occupation of the provider’s internal planning task. At time
, the maximum available capacity of
becomes
, so it is reasonable to manufacture
(
) and
(
) at this time slot since the sum of occupied capacity does not exceed (
); hence, we get the active MT set as
.
Figure 5 depicts the precedence constraints in MP that contain Equations (15) and (16), which, respectively, mean the ready time of any MT is no earlier than the complete time of its predecessors and the start time of any MT is no earlier than its ready time plus its logistics duration.
Where the auxiliary variable
is defined as Equation (
22).
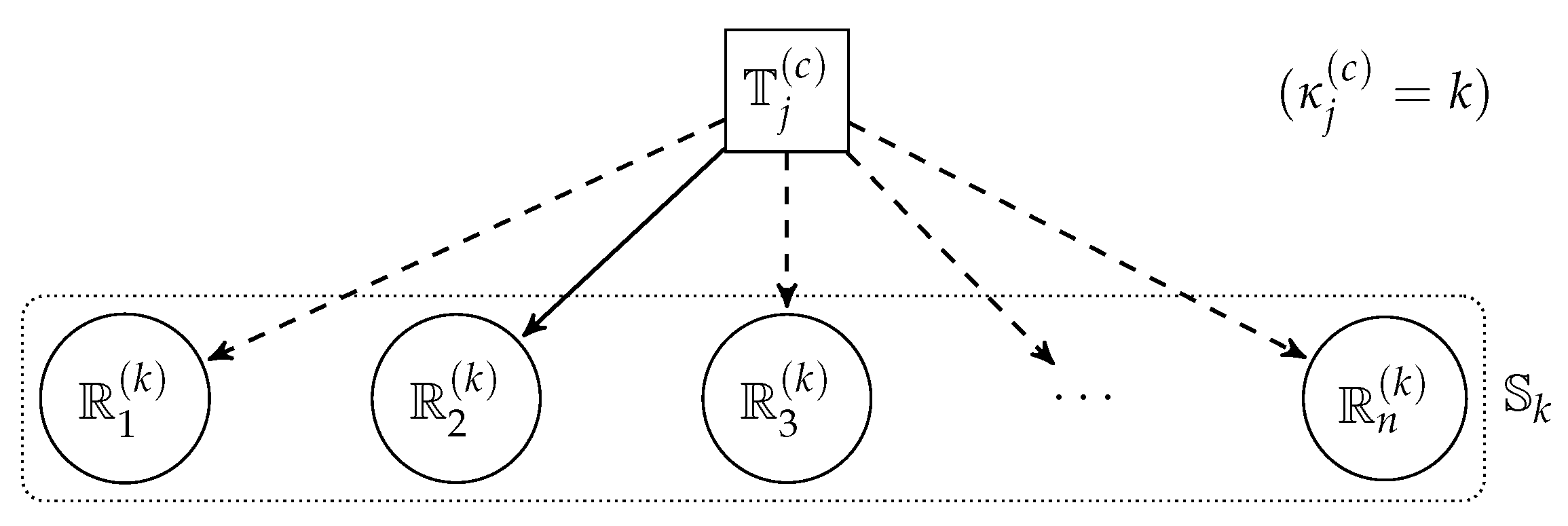
3. Artificial Neural Network based Resource Allocation Methodology
The main purpose of the real-time scheduling problem is to allocate MSs for every MT, and the allocation of
can be depicted as
Figure 6. The candidate MRs are determined by their capability type and the upper bound of available capacity as formulated in Equation (
23).
However, since the number of candidate MRs is large and the processing statuses of these MRs are changing over time, the conventional search algorithms are no longer applicable because they will spend a long time checking all of the possible time intervals in every candidate MR. Therefore, we adopt an ANN that is based on the multi-layer perceptron architecture to speed up the searching procedure by estimating the objective values of each candidate MR.
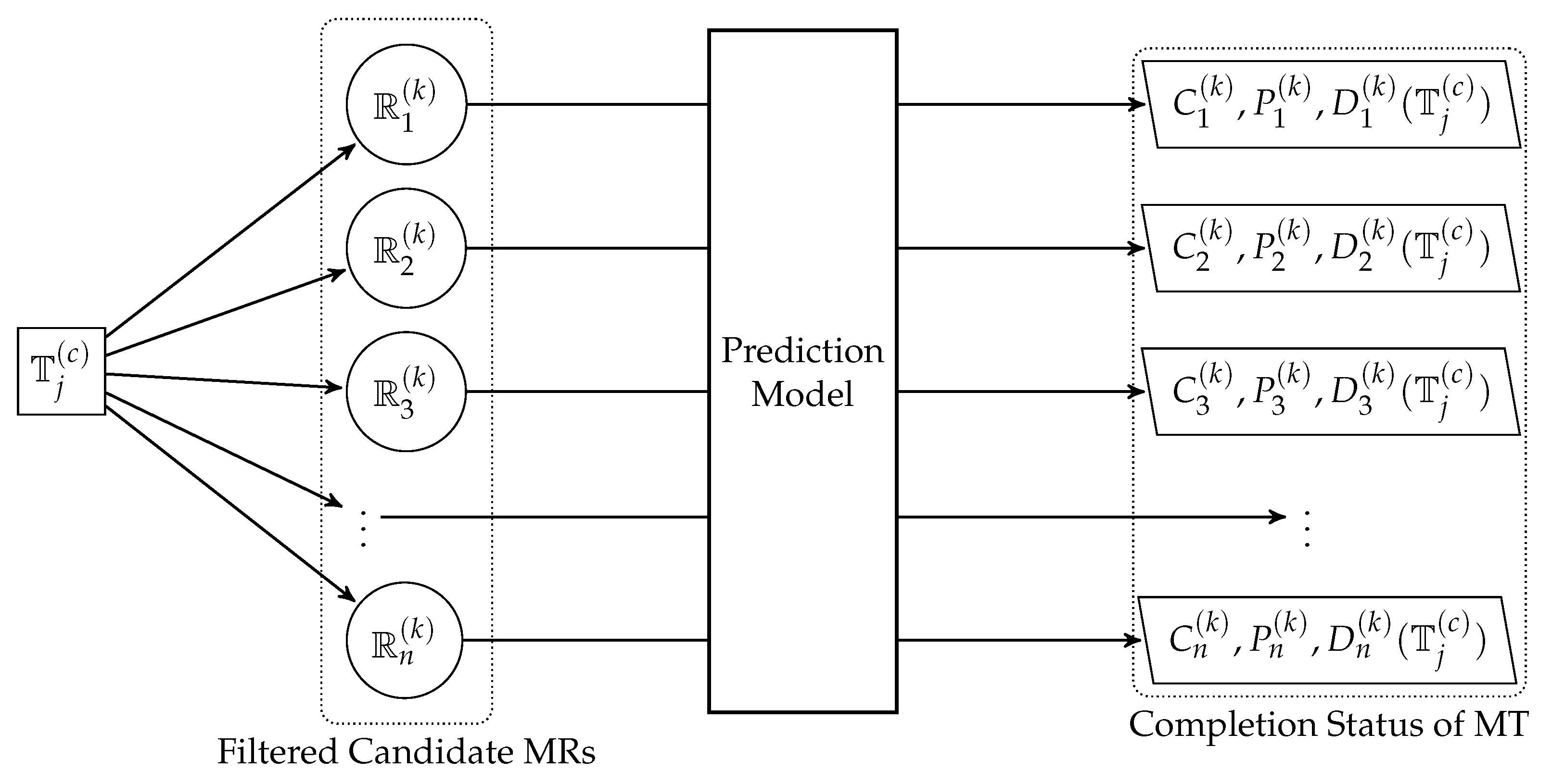
Specifically, take
as an example, after filtering out candidate MRs according to (
23), the objective values projected on MT can be estimated by the completion status prediction model as shown in
Figure 7.
Since both
and
are intrinsic values of
, the key of this prediction model is to predict the completion time
of
. It can be known from the activity-on-vertex structure of one MP (
Figure 3), that is, one MT will affect the make-span of its MP only if it is on the critical path, otherwise it has a flexible interval for completion time. Using the level-order traversal algorithm, the upper and lower bounds of the ideal completion time of
that may not affect the make-span of its MP can be obtained. Then, the upper and lower bounds can divide the time axis into three adjacent sections, and their probabilities are Equations (
24)–(
26).
where
means the probability of completion time
lies in time interval “Completion status
n”. Since the completion status of
can only belong to one of these three statuses, we have
. Then the allocation preference for MR candidates of
can be defined as Equation (
27), which motivates the allocation of MR to process
as early as possible.
As shown in
Figure 8, the ANN predicts the completion status of MT.
Where
,
,
represent
,
,
, respectively. The expression of actual completion status of
processed on
is defined as Equation (
28).
The inputs of this ANN are written in Input (
29), which means all the possible features from the decision condition.
The decision condition for
allocated to
consists of intrinsic attributes of
(
,
,
,
,
) and dynamic features of
defined in Equation (
30).
where
and
are the mean value and standard deviation value of the processing pending queue
at time
t, respectively.
The outputs of the ANN are formulated in Output (
31), which means the possibilities of completion status as Equations (
24)–(
26).
Since the real completion status obtained by sampling is a discrete value as Equation (
32), we convert the outputs into the style of one-hot encoding, which is in the same style of Equation (
28).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}