1. Introduction
At present, many different subjective and objective methods and criteria for quality evaluation of synthetic speech produced by text-to-speech (TTS) systems are used. For the subjective assessment of synthesis quality, listening tests are generally acknowledged. The conventional listening tests usually involve a comparison category rating on a scale from “much better” to “much worse” than high-quality reference speech [
1]. Perceptual characteristics may be divided into five basic dimensions—(1) naturalness of voice, and its pleasantness, (2) prosodic quality including accentuation, rhythm, and intonation, (3) fluency and intelligibility, (4) absence of disturbances, (5) calmness—with the first three being the best for capturing the integral quality [
2]. Apart from the naturalness and understandability of contents, listening tests can also measure the distinguishability of characters or the degree of entertainment [
3]. The subjective scales for rating the synthesized speech may include only a few scored parameters, such as an overall impression by a mean opinion score (MOS) describing the perceived speech quality from poor to excellent, a valence from negative to positive, and an arousal from unexcited to excited [
4]. The MOS scale can be used not only for naturalness, but for different dimensions, such as affect (from negative to positive) or speaking style (from irritated to calm) as well [
5]. The comparison of a pair of utterances synthesized by different methods or originating from different speech inventories is often carried out by a preference listening test [
6]. For objective speech quality estimation of the TTS voice, various speech features extracted from the natural and synthetic speech are evaluated. In [
7] the mel frequency cepstral coefficients (MFCC) and the modified group delay function were used as a dynamic time warping (DTW)-based fusion of magnitude and phase features. The DTW alignment of reference and synthesized spectral sequences was also carried out in combination with the average spectral distortion [
8]. In addition to the MFCC distance, pitch frequency (F0) related features can be used to compare a reference natural signal with a copy-synthesis: voicing accuracy, a gross pitch error, and a fine pitch error [
9]. The synthetic speech quality may be predicted by a mix of several prosodic properties (slope of F0, F0 range, jitter, shimmer, vocalic durations, intervocalic durations) and articulation-associated properties (discrete-cosine-transform coefficients of the mel-cepstrum, their delta, and delta-delta values) [
2].
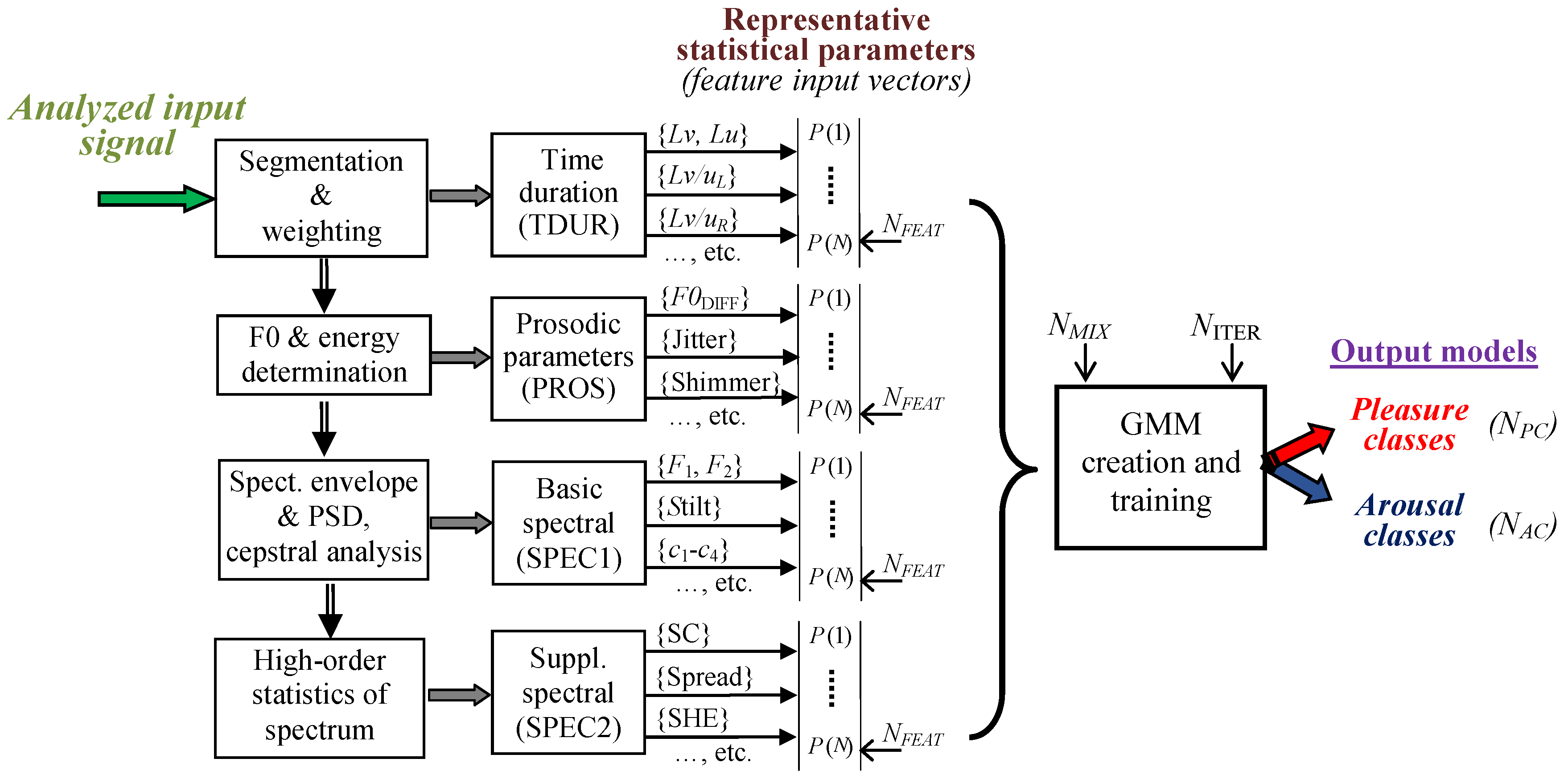
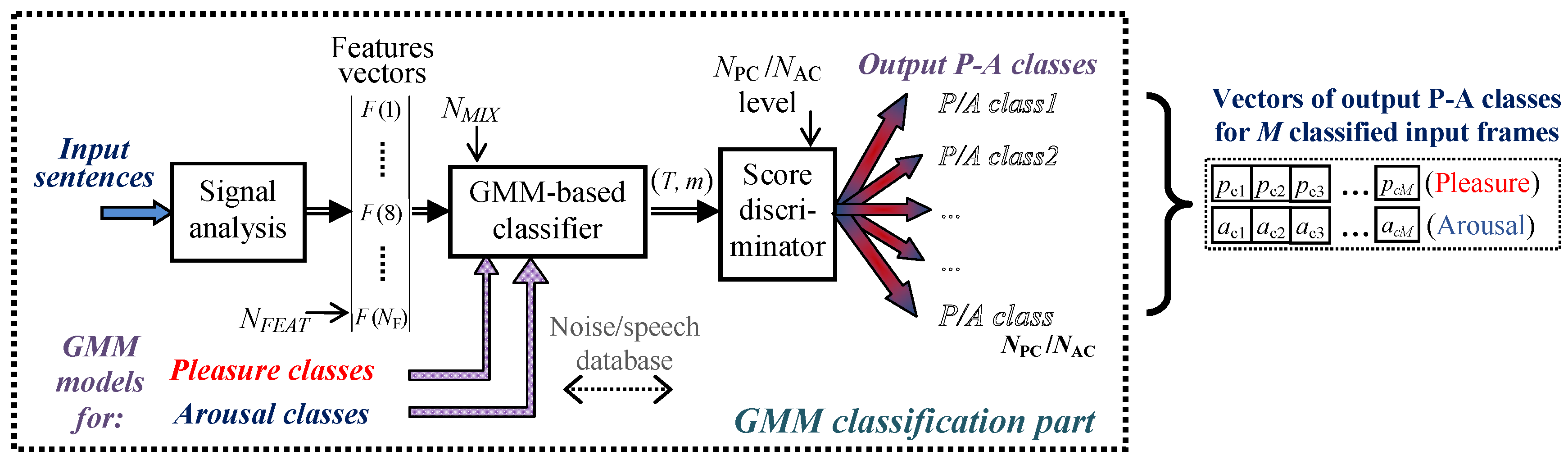
Our current research focuses on the development of an automatic system for the quality evaluation of synthetic speech in the Czech language using different synthesis methods. It was motivated by our assumption of the successful application of a 2D emotional model with a Pleasure-Arousal (P-A) scale [
10] for automatic evaluation of synthetic speech quality based on the Gaussian mixture model (GMM) classification. In such a manner, the subjectivity of human assessment and considerable time consumption during the standard listening tests can be eliminated. The proposed system is based on the principle of determination of similarities/differences between the original sentences uttered by a speaker and the sentences synthesized using the speech material of the same speaker. The final evaluation result based on Euclidean distances in the P-A space expresses the order of synthesis proximity between different speech syntheses and the original speech. The audio material used for the GMM creation and training originated from the sound/speech databases that were directly labeled in the P-A scale so that the subsequent GMM classification process yielded a combination of Pleasure and Arousal classes corresponding to the speech stimuli tested.
Within the framework of the work presented, two basic evaluation experiments with the Czech speech synthesizer of male and female voices were performed. The first was aimed at the evaluation of sentences generated by the TTS system using two methods of prosody manipulation—a rule-based method and a modification reflecting the final syllable status [
11]. The second compared the differences between the tested sentences produced by the TTS system using three different synthesis methods (standard and deep learning [
12,
13]) in combination with rule-based prosody generation.
In the first of these experiments, only the corpus-based unit selection (USEL) speech synthesis method [
14,
15] was evaluated. Different approaches to prosody modification bring about differences in time duration, phrasing, and time structuring within the synthetic sentences analyzed. Therefore, special types of speech features must be used to enable the detection of these differences in utterance speed, phrase creation, and prosody production by changes in the time domain instead of the standard spectral features. These special supra-segmental features were derived from time durations of voiced and unvoiced parts and were included in the feature set used in this first automatic evaluation experiments. The objective evaluation results of the first experiment were compared with the subjective ratings of human evaluators using the standard listening test.
In the second basic evaluation experiment, the three tested types of speech synthesis were the following: (1) the basic USEL synthesis, (2) the synthesis using a deep neural network (DNN) with a long short-term memory (LSTM) and a conventional WORLD vocoder [
16], (3) the synthesis using a recurrent neural network with the LSTM and a WaveRNN [
17] vocoder. The speech synthesized by the methods using the neural networks is typologically different from that produced by the USEL synthesizer. The USEL artifacts can be found mainly at the points of concatenation of speech units [
18], while the neural network synthesis is characterized by problems manifesting perceptually as a certain type of acoustic noise. Thus, the automatic evaluation system developed must satisfy the requirements for the comparison of speech synthesis approaches with essentially different acoustic realizations. In this experiment, the objective results were compared with the subjective ones based on the subjective assessment called MUltiple Stimuli with Hidden Reference and Anchor (MUSHRA) listening test [
19] for the comparison of speech stimuli using hidden original speech, as well as anchors with different impairments.
An auxiliary analysis was carried out to reveal a possible influence of the number of mixture components, the number of synthetic sentences tested, the types of speech features, the types of audio databases for GMM creation, and the dispersion of positions of original utterances in the P-A space on the partial results of the continual GMM P-A classification, as well as on the stability and the accuracy of the final evaluation results. In addition, the influence of the number of mixtures used for GMM creation and training together with 2D classification in the P-A space on the computational complexity (CPU processing time) was investigated. The experiments realized confirm the suitability of the method for this type of task as well as the principal functionality of the system developed.
4. Discussion of the Obtained Results
The detailed comparison of computational complexity demonstrates a great increase in CPU time for GMM creation and training using higher number of mixtures
NMIX. To obtain GMMs for seven Pleasure or five Arousal classes using the sound database (IADS-2), the necessary CPU time was 43 s for eight mixture components and about 1890 s for
NMIX = 512 (see first two rows in
Table 5) representing a 44-fold increase. With the speech database (MSP-IMPROV), separate models for male and female voices were created, hence the differences in the CPU times are halved: about 19 s for
NMIX = 8 and 900 s for the maximum of 512 mixtures, (approx. 47-fold increase). The situation is similar for both voices—male and female ones. For 2D GMM classification of original sentences of real speakers (a set of 50 in total) with these models, the CPU times are about 7 times lower, however, 250 s for the maximum
NMIX = 512 is still too high—beyond the possibility of real-time processing. For the results obtained in the classification phase, the CPU times are affected neither by the voice (male/female) nor by the database (DB
1/DB
2), as documented in
Table 6.
The analysis of the effect of the number of Gaussian mixtures on the obtained dispersion of the originals’ centers expressed by the
stdPO and
stdAO values has shown their monotonous decrease—see the graphs in
Figure 8. The falling trend is the same for the male (M1) as well as the female (F1) voices, greater differences are observed for the DB
2 used. For maximum accuracy of the evaluation results, low
stdPO and
stdAO values are necessary. It is practically fulfilled for the sound database in the case of
NMIX = 128 and for the DB
2 using
NMIX = 512. With respect to the CPU times, we have finally chosen
NMIX = 128 to be used as a compromise value in further experiments (with CPU times for GMM classification being about 0.5 s per one sentence tested).
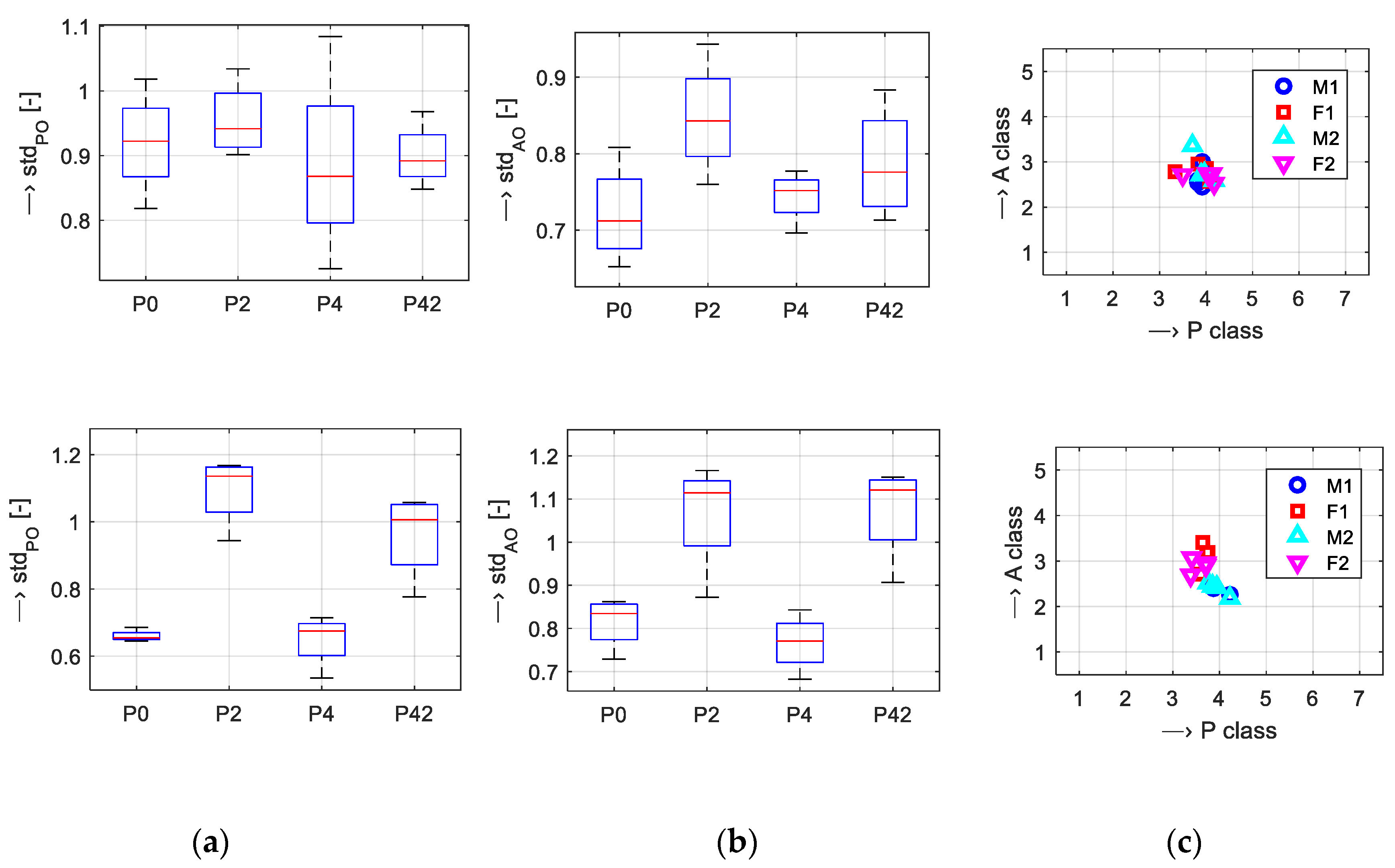
The next auxiliary analysis of dispersion of the originals around the centers dealt with different feature sets used for GMM classification. As can be seen in a box-plot comparison in
Figure 9, lower mean values of
stdPO and
stdAO parameters are achieved with P0 and P4 sets for both databases (DB
1, DB
2). Considering the structure of the feature sets in
Table 3, we finally decided to use the set P4 with a more balanced distribution of speech features (prosodic, spectral, and temporal types).
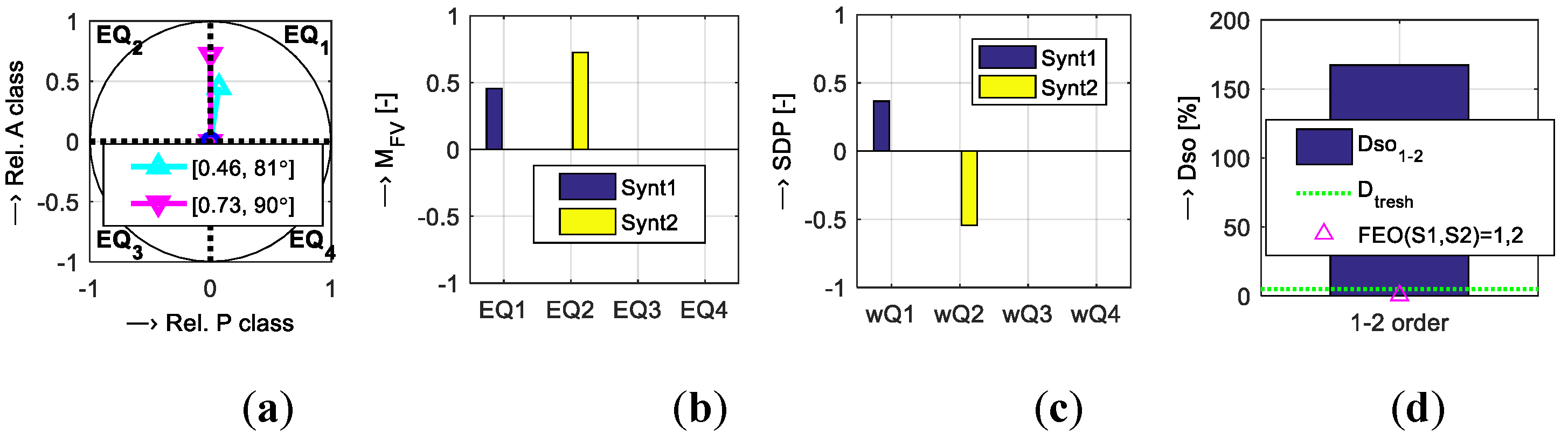
For practical testing of the functionality of the evaluation system we calculated and compared partial results comprising centers of originals,
MFV and
ϕFV of sum vectors, summary distribution parameters, differences
DsoX–Y and FEO decisions for M1 and F1 voices depending on the sound/speech database used (see
Table 7 and
Table 8). The
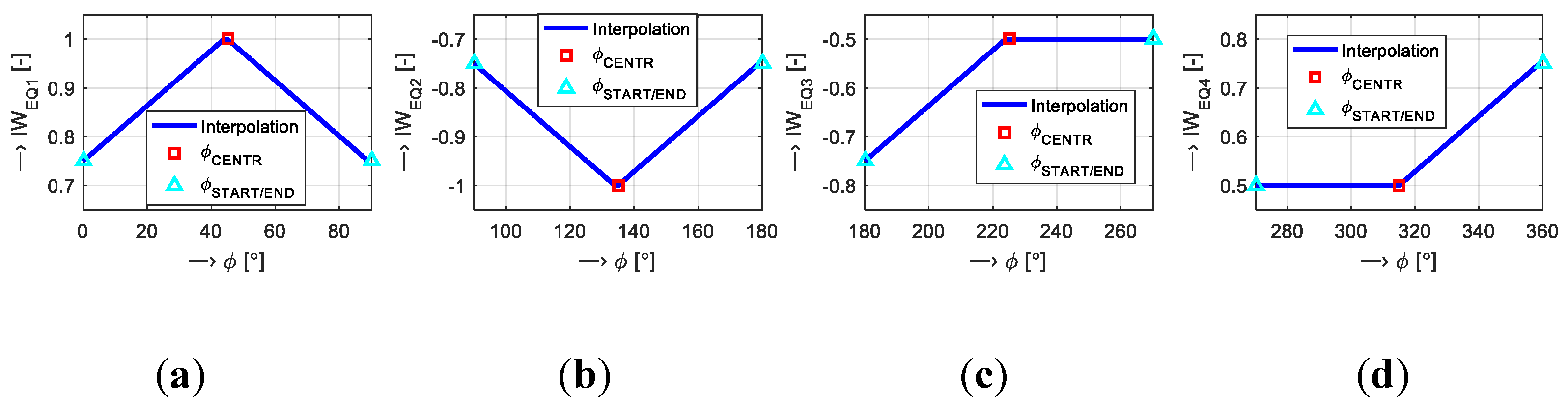
MFV parameters in the second columns of both tables show similar values for both types of prosody manipulation. For better discrimination between them, the emotional quadrant importance weights are applied. In principle, it increases the complexity of the whole evaluation algorithm. On the other hand, consideration of the location in emotional quadrants
EQ1–4 is justified in a psychological perception of the synthetic speech by human listeners. This is the main criterion for evaluation of the synthetic speech quality primarily for the listening test methods however, the objective evaluation approaches must respect this influence, too. The importance weights
nw0,1,2 chosen for the transformation functions
IWEQ1–4 (see
Table 4) and subsequent scaling of the
MFV values provide the required effect—greater separation of these parameters. It is well documented in the case of the DB
2 with the M1 voice (see the last two rows in
Table 7) where a simple difference between the
MFV values of TTS
1 and TTS
2 is about 0.03, but the sum vectors lie in the opposite quadrants (EQ
1/EQ
3), so the SDP values have opposite signs and the value of 193% is finally assigned to the parameter
Dso. The same effect is shown also for the female voice F1—in this case the
Dso values are smaller, but still safely over the chosen 5% similarity threshold as documented by the results in the last but one column of
Table 8.
From the last auxiliary investigation follows that a minimum number of 25 sentences (one half of a full set) must be processed to achieve proper partial as well as final evaluation parameters. The values in
Table 9 demonstrate that for a lower number of sentences the final decision would not be stable giving either the wrong evaluation order (for
NTS = 10) or no useful information because of the similarity of the category “1/2” (for
NTS = 25). For compatibility between the evaluations using both testing synthetic speech corpora (SC1 a SC2) only the full sets consisting of 50 sentences for each voice were applied in further analysis.
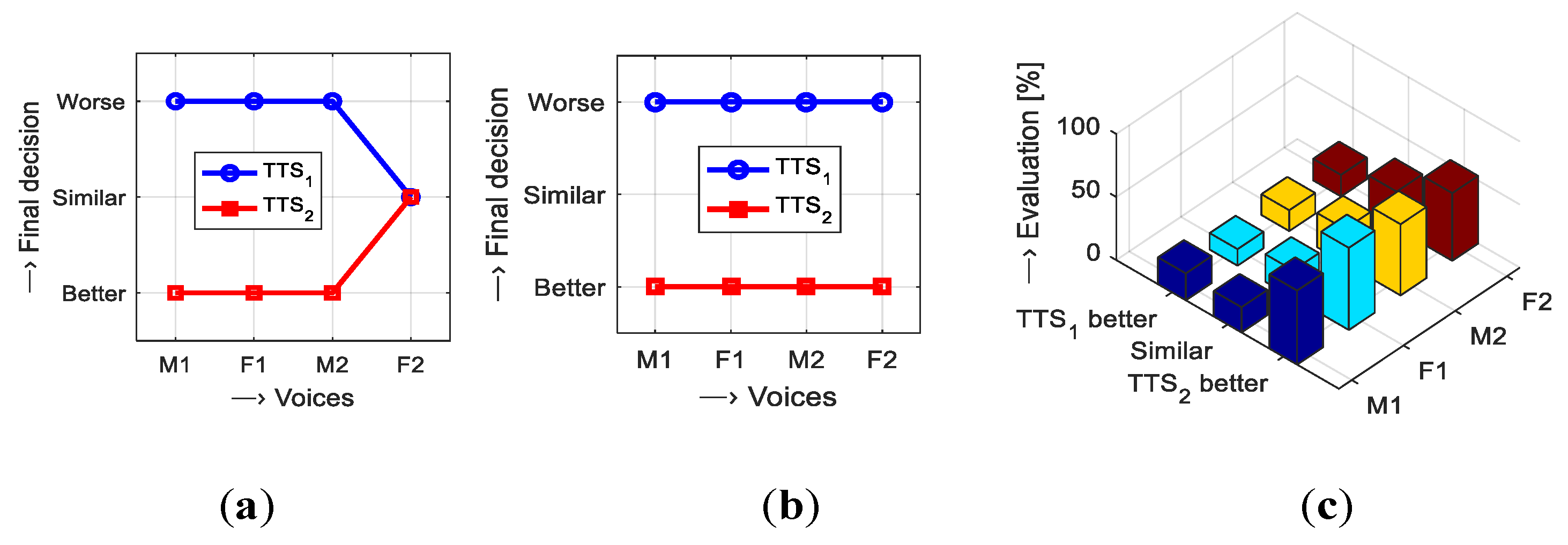
The final comparison of the evaluation experiment using sentences of the speech corpus SC1 with the results obtained by the standard listening test method described in more detail in [
11] shows principal correspondence as documented by the graphs in
Figure 11. While the results for the M1, F1, and M2 voices are stable and prefer the TTS
2 method for both databases, for the F2 voice the results are classified as similar in the TTS
1 as well as the TTS
2. As follows from the comparison of center positions of originals and their dispersions in the P-A scale presented in
Figure 10, for the F2 voice the
stdPO and
stdAO parameters achieve the greatest values. This voice has also the smallest evaluation percentage by the listening test (about 53% vs. the best evaluated voice F1 with 65%) as shown in
Figure 11c.
The final objective results of the second evaluation based on testing sentences of the speech corpus SC2 show some differences when compared with the MUSHRA listening test. The graphs in
Figure 12a,b document that our GMM-based automatic system marks the synthesis
Synt2 (LSTM with the WORLD vocoder) as the worst one in all cases, the synthesis
Synt1 (USEL) as the best (excluding the F2 voice), and the
Synt3 (WaveRNN) of a medium quality. For the female voice F2, the results are different depending on the training database used for GMMs. For the sound database DB
1, the quality order is exchanged for
Synt1 and
Synt3 types (
Synt3 is the best and
Synt1 is medium). Using the speech database DB
2 generates the result of similarity between
Synt1 and
Synt3 synthesis types. Generally, it can be said that using the speech database DB
2 generates smaller dispersion of localized positions and hence it brings better evaluation results of
Dso parameters and stable FEO decisions.
Contrary to it, the listening tests rated the
Synt3 as the best, then the
Synt1 as medium, and the
Synt2 as the worst—see the 3D bar-graph in
Figure 12c. It also indicates similarity between
Synt1 and
Synt2 types for the female voice F2 (MUSHRA scores are 48.5% vs. 48.9% [
17]). Our speech features used for GMM-based evaluation apparently reflect better naturalness of the USEL synthesis using units of original speech recordings, although it causes undesirable artifacts due to concatenation of these units [
19]. From this point of view, the DNN is less natural as it uses a model to generate the synthetic speech, but the WaveRNN based on a DNN vocoder is more natural as it uses a complex network for direct mapping between the parametric representation and the speech samples. This is probably a reason for a simpler LSTM with the WORLD vocoder being more averaged smoothed and less natural. The result of the
Synt3 being better than the
Synt2 was expected, too. The listening test comparison of the WaveRNN and the USEL is generally more subjective.
5. Conclusions
The task of the synthetic speech quality determination by objective measures has been successfully fulfilled by the designed automatic system with continual evaluation on the 2D P-A scale and practical verification on two corpora of the synthetic speech generated by the Czech TTS system. We have theoretical knowledge about a better type of the synthesis (prosody manipulation in the TTS system), but the subjective evaluation performed can show a different opinion of listeners, even though the results of the objective evaluation by this proposed system are generally in correspondence with the theory. The benefit of the proposed method is that the sound/speech material used to create and train the GMMs for P-A classification can be totally unrelated to the synthetic speech tested. The sentences from the original speaker also need not be syntactically or semantically related to the sentences of the TTS system evaluated.
The currently developed automatic evaluation system uses a statistical approach and its kernel is practically based on the GMM classifier. The GMM can describe a distribution of given data using a simple k-means method for data clustering implemented in the Netlab toolbox [
30]. We automatically expect that all components have Gaussian distributions but their linear combination can approximate non-Gaussian probability distributions for each of the processed P-A classes. In addition, we use a fixed number of mixtures for GMMs without discrimination between the Pleasure/Arousal types of classes and the gender of a speaker (male/female). At present, we are not able to confirm assumption about real distribution of the processed data, so statistical parameters of the training data represented by values in the feature vectors must be investigated in detail. The newer, more complex and more precise method based on spectral clustering [
26] can solve this potential problem, so we will try to implement this approach into the GMM creation and training algorithm. Last, but not least, we would like to test adaptive setting of the training procedure (
NMIX,
NITER, and
NFEAT parameters) depending on the currently used training data reflecting also the language characteristics (differences in time-duration as well as prosodic parameters).
The limitation of the present work lies in the fact that the size of both synthetic speech databases evaluated was relatively small and more sentences must be tested to evaluate the real performance of the proposed automatic system. The second problem is the practical impossibility of direct comparison of our final results with the other subjective evaluation approaches due to incompatible expression of results (in the case of the MUSHRA test) or absence of percentage values (for comparison with the listening test in the form of a confusion matrix). The output of our automatic evaluation system in the form of FEO decisions representing symbolical distances in the 2D P-A space between originals (from a speaker) with the added aspect of subjective emotional meaning by the location in four emotional quadrants. Next, the parameters Dso1–2,2–3 determining differences between the first and the second rank and the second and the third rank in the order are expressed in percentage but, due to the application of emotion quadrant weights, they can reach up to 200%.
From the practical point of view, it would be useful to provide an evaluation of the overall computational complexity of the method used in our evaluation process, together with its real-time capabilities, as well as the performance testing of the whole automatic evaluation system. The current realization in the Matlab environment is not very suitable for the building of the application running under Windows or others platforms. If the critical points were found, the whole evaluation algorithm would be implemented in one of the higher programming languages such as C++, C#, Java, etc.
Considering the limitation of the current work and its potential for practical use by other researchers we plan to build larger speech corpora and perform next evaluation experiments with the aim to find any fusion method how to enable comparison with the results obtained from the evaluation of the listening test. The Czech TTS system tested is also able to produce synthetic speech in the Slovak language (similar to Czech) [
16,
31]; therefore, we also suppose the application of Slovak in this proposed automatic evaluation system. Finally, we will attempt to collect speech databases directly in the Czech (Slovak) languages with sentences labeled on the P-A scale for the subsequent creation of GMM models used in the continuous P-A classification.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}