Hierarchical Phoneme Classification for Improved Speech Recognition


Abstract
:Featured Application
Abstract
1. Introduction
2. Phoneme Clustering
2.1. Phonemes
2.2. Baseline Phoneme Recognition with TIMIT Dataset
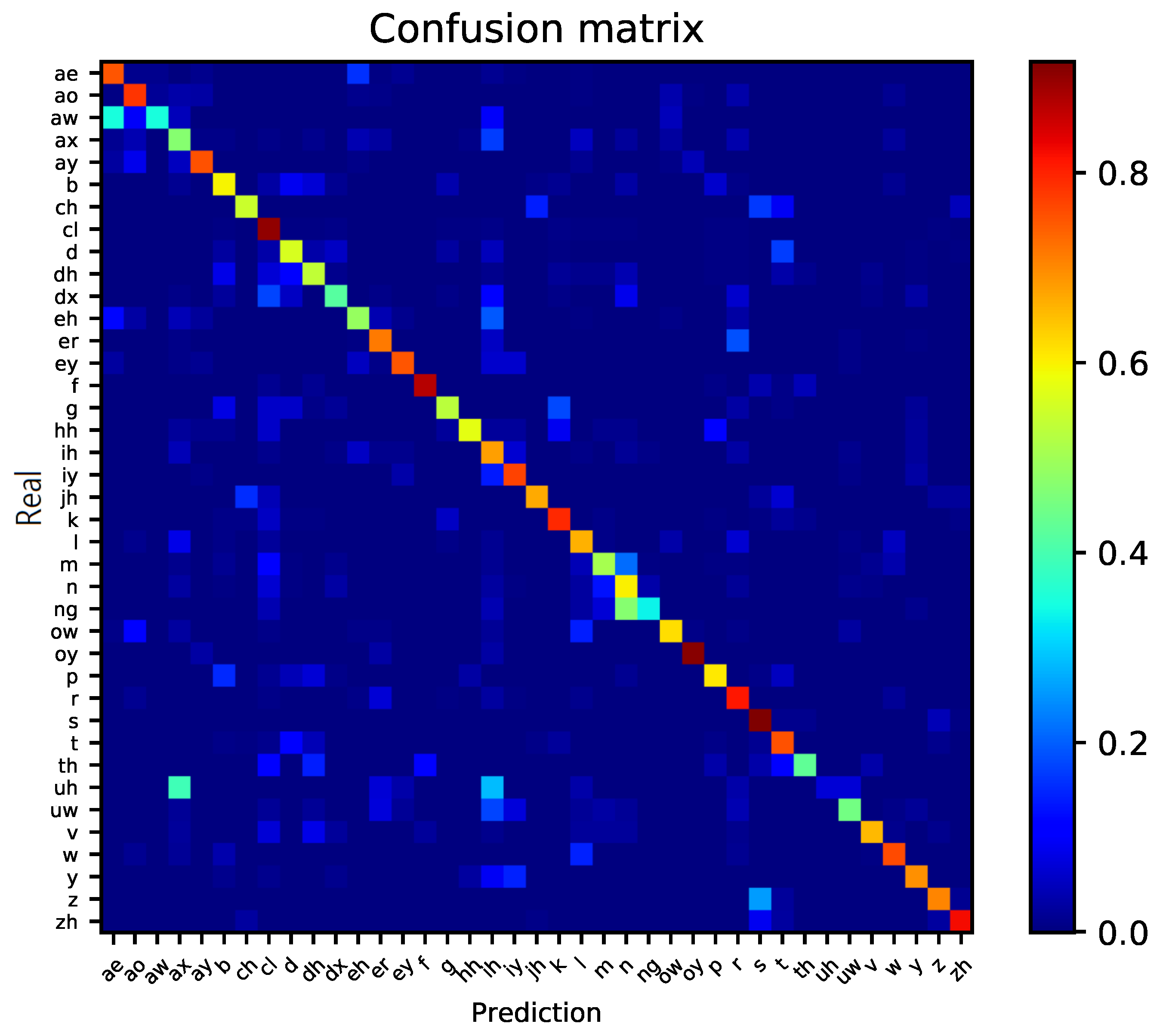
2.3. Confusion Matrix
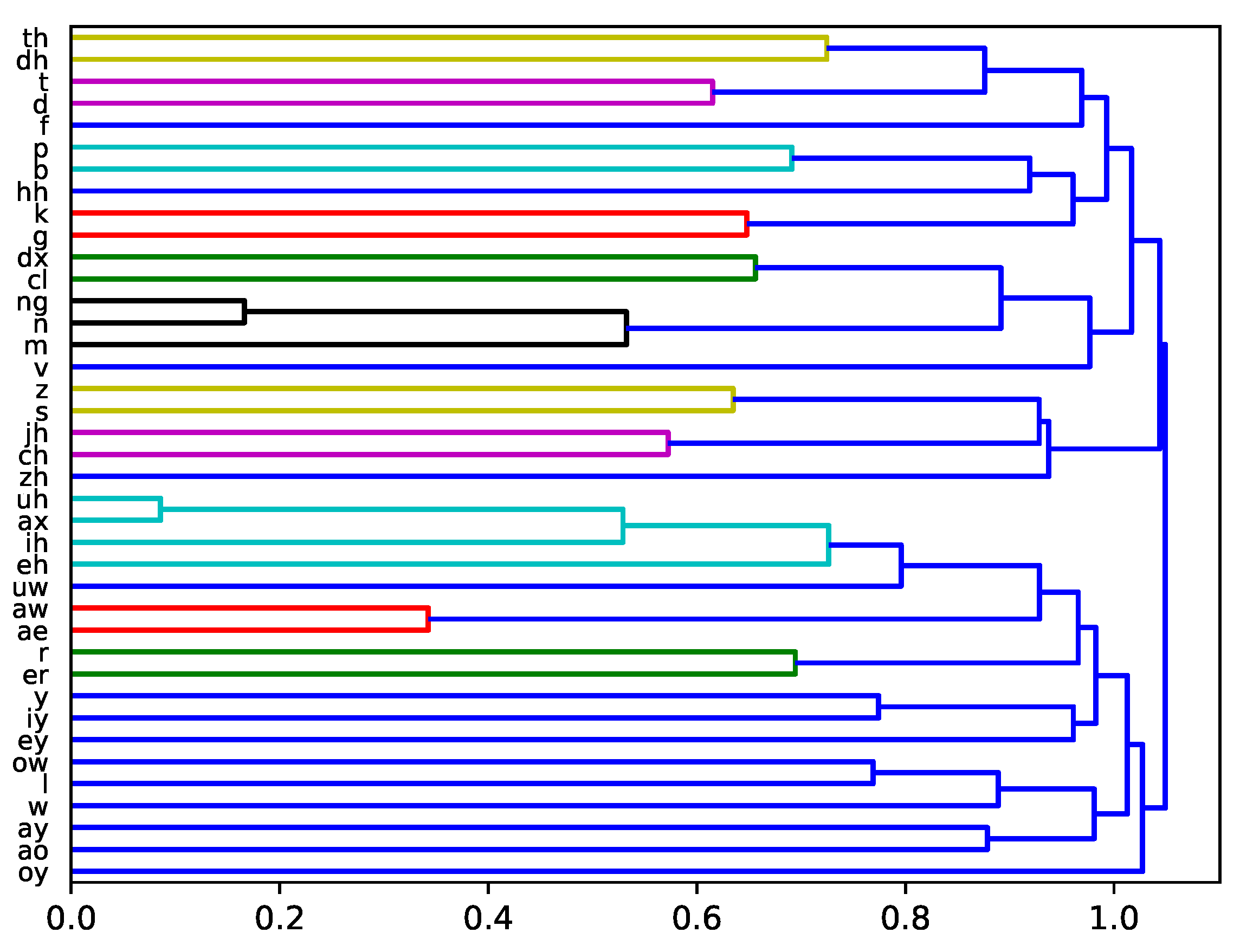
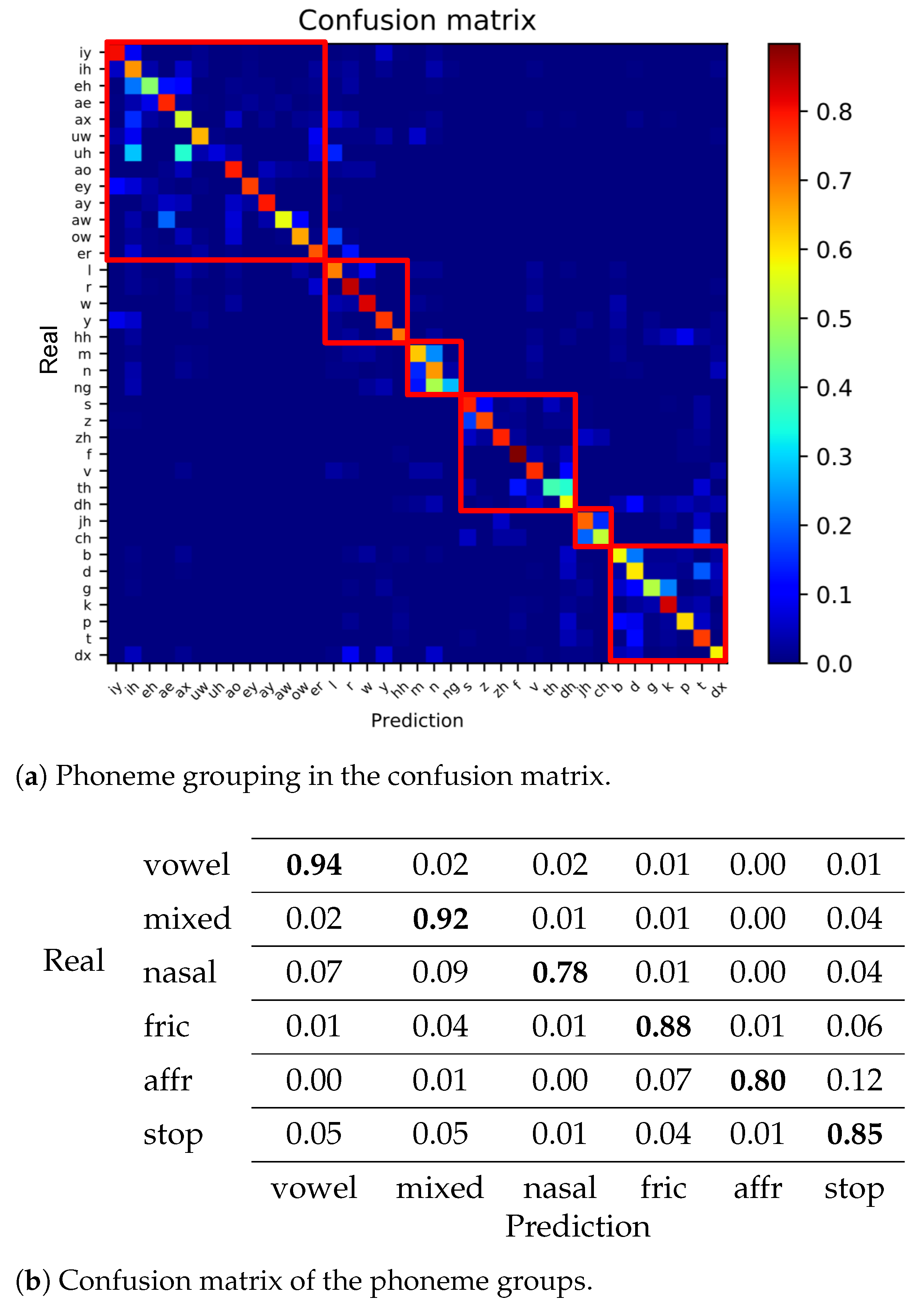
2.4. Phoneme Clustering Using Confusion Matrix
3. Hierarchical Phoneme Classification
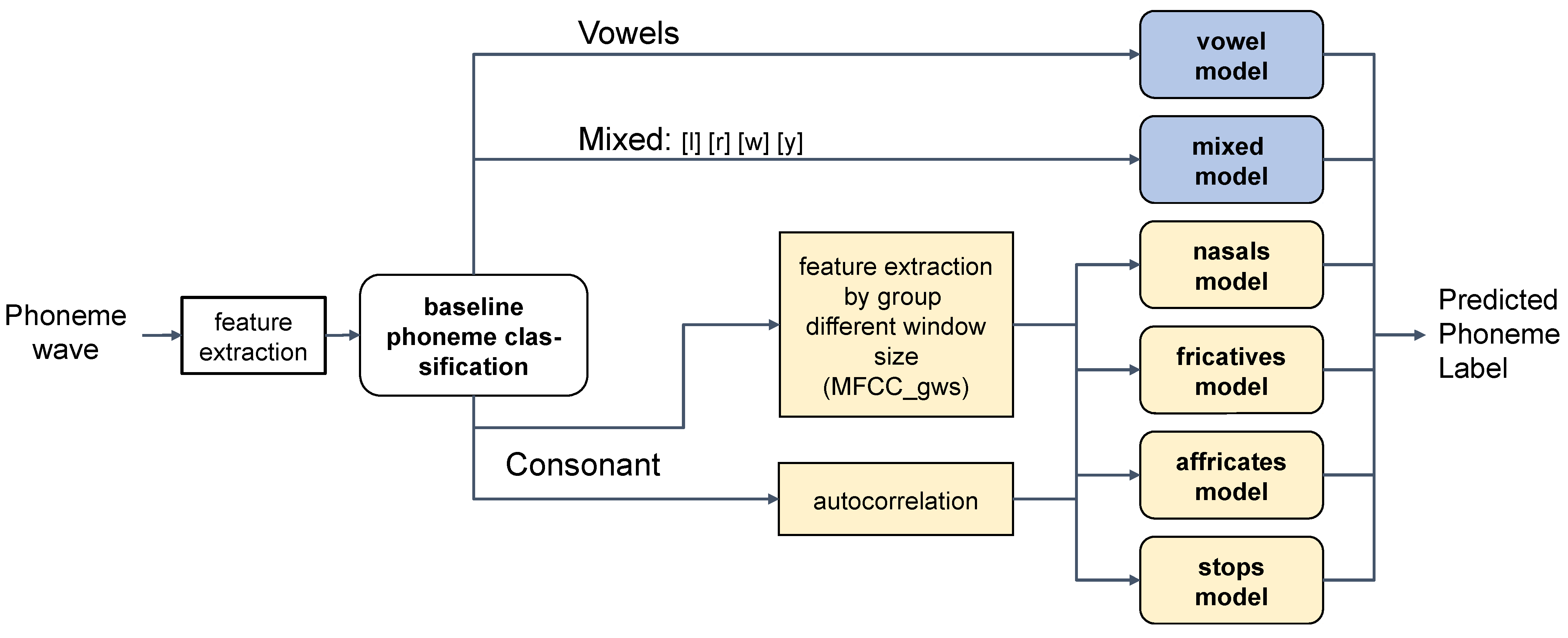
3.1. Overall Architecture
3.2. Vowels and Mixed Phoneme Classification
3.3. Varying Analysis Window Sizes for Consonants
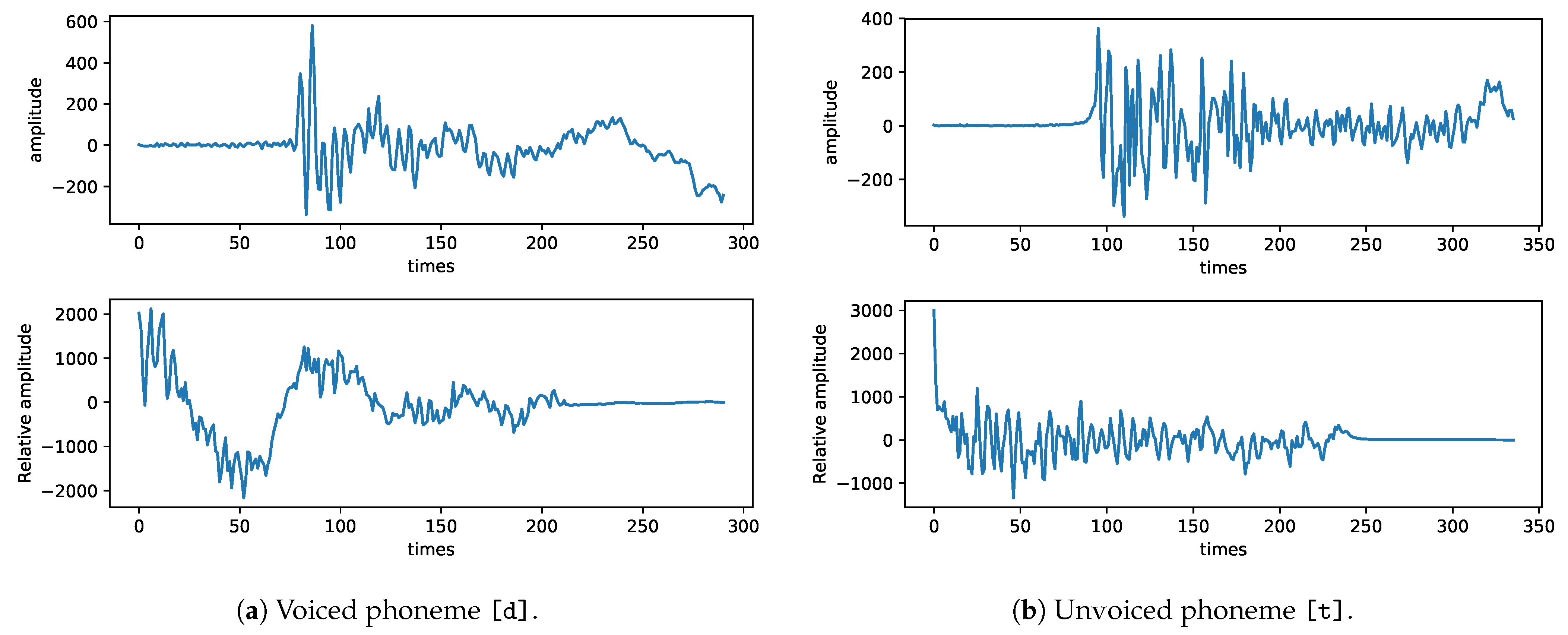
3.4. Voiced and Unvoiced Consonants Classification
| Algorithm 1 Autocorrelation |
| H] |
| N length of signal x |
| for to N do |
| for to do |
| end for |
| end for |
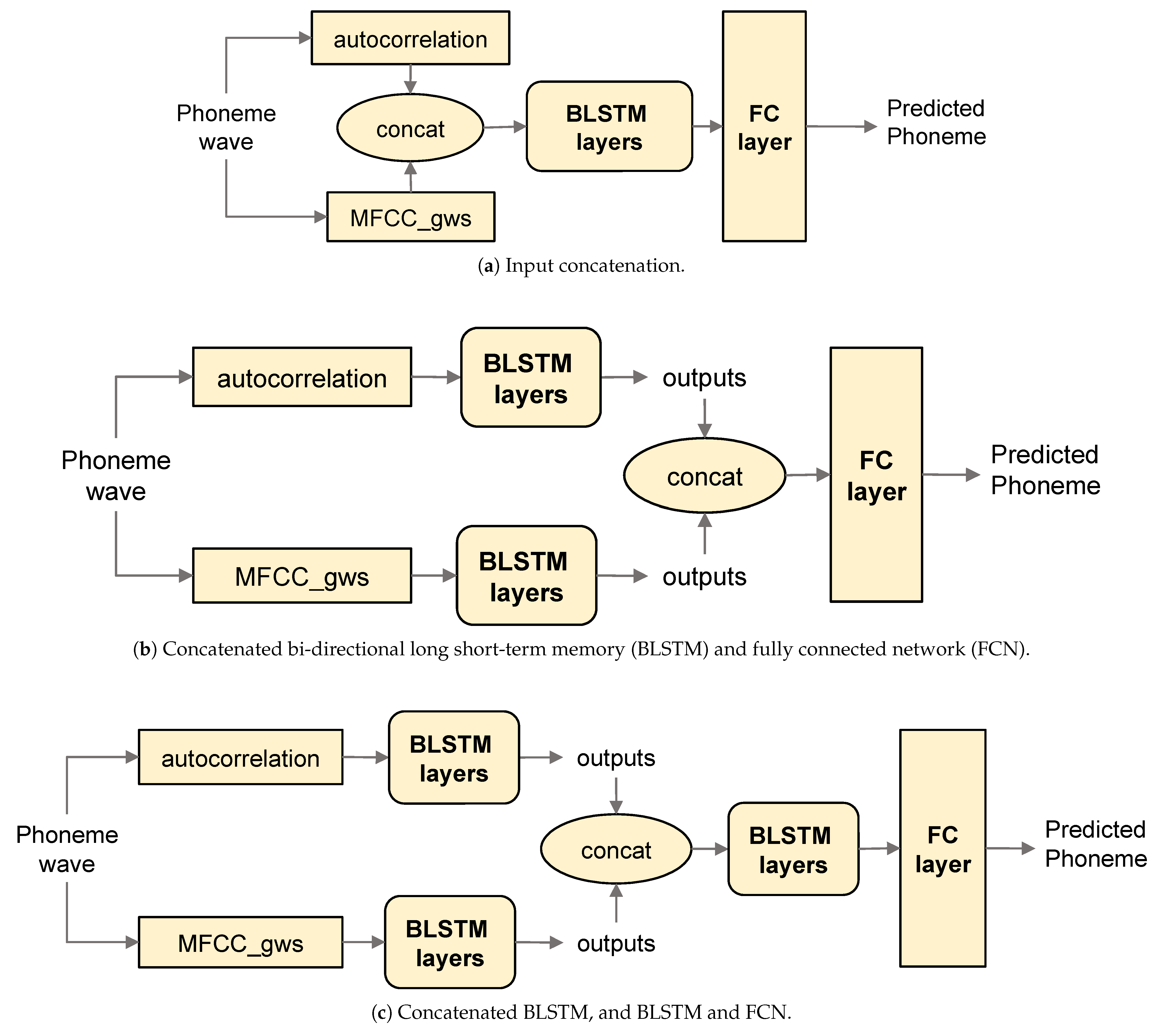
3.5. Consonant Group Model Architectures
4. Experimental Results
4.1. TIMIT Database
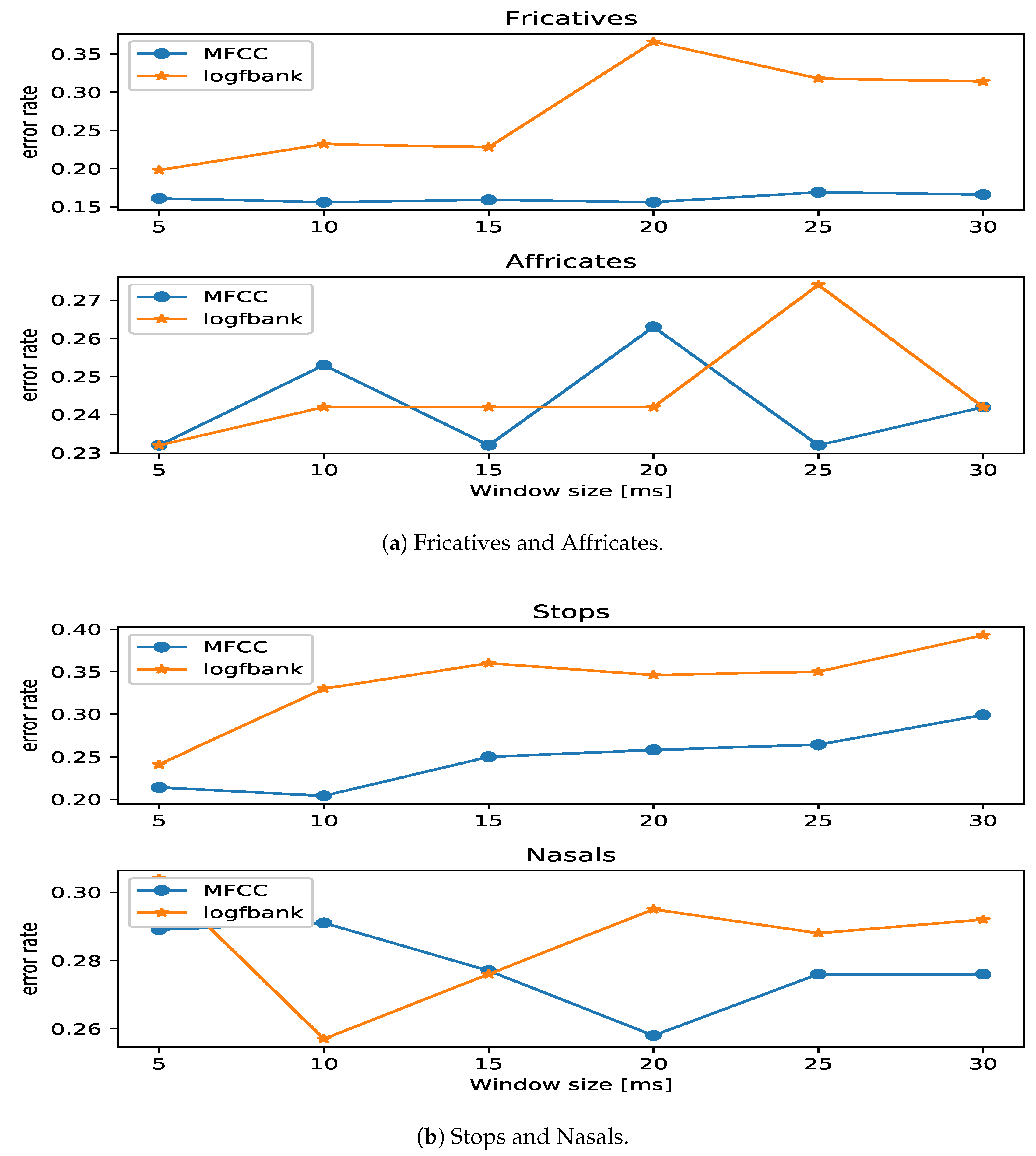
4.2. MFCC vs. Log Filter Bank Energy
4.3. Various Window Sizes
4.4. Phoneme Group Model Training
4.5. Performance of the Hierarchical Classification
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ARPA | Advanced Research Projects Agency |
| ASR | Automatic Speech Recognition |
| BLSTM | Bi-directional Long Short-Term Memory |
| CNN | Convolutional Neural Network |
| IPA | International Phonetic Alphabet |
| LSTM | Long Short-Term Memory |
| MFCC | Mel-Frequency Cepstral Coefficient |
| NIST | National Institute of Standards and Technology |
| RNN | Recurrent Neural Network |
References
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Yu, D.; Li, J. Recent progresses in deep learning based acoustic models. IEEE/CAA J. Autom. Sin. 2017, 4, 396–409. [Google Scholar] [CrossRef]
- Xiong, W.; Wu, L.; Alleva, F.; Droppo, J.; Huang, X.; Stolcke, A. The Microsoft 2017 conversational speech recognition system. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5934–5938. [Google Scholar]
- Caterini, A.L.; Chang, D.E. Deep Neural Networks in a Mathematical Framework; Springer: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Taylor, S.; Kim, T.; Yue, Y.; Mahler, M.; Krahe, J.; Rodriguez, A.G.; Hodgins, J.K.; Matthews, I.A. A deep learning approach for generalized speech animation. ACM Trans. Gr. 2017, 36, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Graves, A. Sequence Transduction with Recurrent Neural Networks. arXiv 2012, arXiv:1211.3711. [Google Scholar]
- Graves, A.; Mohamed, A.R.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Zeyer, A.; Doetsch, P.; Voigtlaender, P.; Schlüter, R.; Ney, H. A Comprehensive Study of Deep Bidirectional LSTM RNNs for Acoustic Modeling in Speech Recognition. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 May 2017; pp. 2462–2466. [Google Scholar]
- Abdel-Hamid, O.; Mohamed, A.R.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional neural networks for speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef] [Green Version]
- Tóth, L. Phone recognition with hierarchical convolutional deep maxout networks. EURASIP J. Audio Speech Music Process. 2015, 2015, 25. [Google Scholar] [CrossRef] [Green Version]
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. Deep speech: Scaling up end-to-end speech recognition. arXiv 2014, arXiv:1412.5567. [Google Scholar]
- Miao, Y.; Gowayyed, M.; Metze, F. EESEN: End-to-end speech recognition using deep RNN models and WFST-based decoding. In Proceedings of the 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Scottsdale, AZ, USA, 13–17 December 2015; pp. 167–174. [Google Scholar]
- Bahdanau, D.; Chorowski, J.; Serdyuk, D.; Brakel, P.; Bengio, Y. End-to-end attention-based large vocabulary speech recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4945–4949. [Google Scholar]
- Zhang, Y.; Pezeshki, M.; Brakel, P.; Zhang, S.; Bengio, C.L.Y.; Courville, A. Towards end-to-end speech recognition with deep convolutional neural networks. arXiv 2017, arXiv:1701.02720. [Google Scholar]
- Battenberg, E.; Chen, J.; Child, R.; Coates, A.; Gaur, Y.; Li, Y.; Liu, H.; Satheesh, S.; Seetapun, D.; Sriram, A.; et al. Exploring Neural Transducers for End-to-End Speech Recognition. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017. [Google Scholar]
- Chiu, C.C.; Sainath, T.N.; Wu, Y.; Prabhavalkar, R.; Nguyen, P.; Chen, Z.; Kannan, A.; Weiss, R.J.; Rao, K.; Gonina, E.; et al. State-of-the-art speech recognition with sequence-to-sequence models. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4774–4778. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Hayes, B. Introductory Phonology; Malden, M.A., Ed.; Wiley-Blackwell: Oxford, UK, 2009. [Google Scholar]
- Rabiner, L. On the use of autocorrelation analysis for pitch detection. IEEE Trans. Acoust. Speech Signal Process. 1977, 25, 24–33. [Google Scholar] [CrossRef] [Green Version]
- Hernández, M. A tutorial to extract the pitch in speech signals using autocorrelation. Open J. Technol. Eng. Discip. (OJTED) 2016, 2, 1–11. [Google Scholar]
- Klautau, A. ARPABET and the TIMIT Alphabet. 2001. [Google Scholar]
- International Youth Association TIP. Reproduction of The International Phonetic Alphabet; Cambridge University Press: London, UK, 2005. [Google Scholar]
- Gold, B.; Morgan, N.; Ellis, D. Speech and Audio Signal Processing: Processing and Perception of Speech and Music, 2nd ed.; Wiley: Hoboken, NJ, USA, 2011. [Google Scholar]
- Linguistic Data Consortium. Table of All the Phonemic and Phonetic Symbols Used in the Timit Lexicon; Linguistic Data Consortium: Philadelphia, PA, USA, 1990. [Google Scholar]
- Garofolo, J.; Lamel, L.; Fisher, W.; Fiscus, J.; Pallett, D. DARPA TIMIT acoustic-phonetic continous speech corpus CD-ROM. NIST speech disc 1-1.1. NASA STI/Recon Tech. Rep. N 1993, 93, 1–94. [Google Scholar]
- Ladefoged, P.; Disner, S.F. Vowels and Consonants; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Ades, A.E. Vowels, consonants, speech, and nonspeech. Psychol. Rev. 1977, 84, 524. [Google Scholar] [CrossRef]
- Stevens, K.N. Acoustic Phonetics; MIT Press: Cambridge, MA, USA, 2000; Volume 30. [Google Scholar]
- Miller, G.A.; Nicely, P.E. An analysis of perceptual confusions among some English consonants. J. Acoust. Soc. Am. 1955, 27, 338–352. [Google Scholar] [CrossRef]
- Halle, M.; Hughes, G.W.; Radley, J.P. Acoustic properties of stop consonants. J. Acoust. Soc. Am. 1957, 29, 107–116. [Google Scholar] [CrossRef]
- Shadle, C.H. The acoustics of fricative consonants. Tech. Rep. 1985, 1–200. [Google Scholar] [CrossRef]
- Fujimura, O. Analysis of nasal consonants. J. Acoust. Soc. Am. 1962, 34, 1865–1875. [Google Scholar] [CrossRef]
- Halberstadt, A.K. Heterogeneous Acoustic Measurements and Multiple Classifiers for Speech Recognition; Massachusetts Institute of Technology: Cambridge, MA, USA, 1999. [Google Scholar]
- Evangelopoulos, G.N. Efficient Hardware Mapping of Long Short-Term Memory Neural Networks for Automatic Speech Recognition. Master’s Thesis, KU Leuven, Leuven, Belgium, 2016. [Google Scholar]
- Ek, J.V.; Michálek, J.; Psutka, J. Recurrent DNNs and its Ensembles on the TIMIT Phone Recognition Task. arXiv 2018, arXiv:1806.07186. [Google Scholar]
- Michaálek, J.; Ek, J.V. A Survey of Recent DNN Architectures on the TIMIT Phone Recognition Task. arXiv 2018, arXiv:1806.07974. [Google Scholar]
- Han, W.; Chan, C.F.; Choy, C.S.; Pun, K.P. An efficient MFCC extraction method in speech recognition. In Proceedings of the 2006 IEEE International Symposium on Circuits and Systems, Island of Kos, Greece, 21–24 May 2006; p. 4. [Google Scholar]
- Muda, L.; Begam, M.; Elamvazuthi, I. Voice recognition algorithms using mel frequency cepstral coefficient (MFCC) and dynamic time warping (DTW) techniques. arXiv 2010, arXiv:1003.4083. [Google Scholar]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]
- Corpet, F. Multiple sequence alignment with hierarchical clustering. Nucl. Acids Res. 1988, 16, 10881–10890. [Google Scholar] [CrossRef] [PubMed]
- Wilks, D.S. Cluster analysis. In International Geophysics; Elsevier: Amsterdam, The Netherlands, 2011; Volume 100, pp. 603–616. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM networks. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; Volume 4, pp. 2047–2052. [Google Scholar]
- Hannun, A.Y.; Maas, A.L.; Jurafsky, D.; Ng, A.Y. First-pass large vocabulary continuous speech recognition using bi-directional recurrent DNNs. arXiv 2014, arXiv:1408.2873. [Google Scholar]
- Graves, A.; Fernández, S.; Schmidhuber, J. Bidirectional LSTM networks for improved phoneme classification and recognition. In International Conference on Artificial Neural Networks; Springer: New York, NY, USA, 2005; pp. 799–804. [Google Scholar]
- Caramazza, A.; Chialant, D.; Capasso, R.; Miceli, G. Separable processing of consonants and vowels. Nature 2000, 403, 428. [Google Scholar] [CrossRef] [PubMed]
- Rabiner, L.R.; Schafer, R.W. Digital Processing of Speech Signals; Pearson Publishing: NewYork, NY, USA, 1978; Volume 100. [Google Scholar]
- Chen, C.H. Signal Processing Handbook; CRC Press: Boca Raton, FL, USA, 1988; Volume 51. [Google Scholar]
- Furui, S.; Sondhi, M.M. Advances in Speech Signal Processing; Marcel Dekker, Inc.: New York, NY, 1991. [Google Scholar]
- Proakis, J.G. Digital Signal Processing: Principles Algorithms and Applications; Pearson Education India Services Pvt.: Chennai, India, 2001. [Google Scholar]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal deep learning. In Proceedings of the 28th International Conference On Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 689–696. [Google Scholar]
- Nadeu, C.; Hernando, J.; Gorricho, M. On the decorrelation of filter-bank energies in speech recognition. In Proceedings of the Fourth European Conference on Speech Communication and Technology, Madrid, Spain, 18–21 September 1995. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vowels (19) | Consonants (31) | TIMIT Extension (11 + 1) | |||||
|---|---|---|---|---|---|---|---|
| ARPAbet | IPA | ARPAbet | IPA | ARPAbet | IPA | Symbol | Description |
| aa | ɑ | b | b | q | ʔ | ax-h | Devoiced [ə] ([ə̥]) |
| ae | æ | ch | ʧ | r | ɹ | eng | Syllabic [ŋ] |
| ah | ʌ | d | d | s | s | hv | Voiced [h] |
| ao | ɔ | dh | ð | sh | ʃ | bcl | [b] closure |
| aw | aʊ | dx | ɾ | t | t | dcl | [d] closure |
| ax | ə | el | l̩ | th | θ | gcl | [g] closure |
| axr | ɚ | em | m̩ | v | v | kcl | [k] closure |
| ay | aɪ | en | n̩ | w | w | pcl | [p] closure |
| eh | ɛ | f | f | wh | ʍ | tcl | [t] closure |
| er | ɝ | g | g | y | j | pau | Pause |
| ey | eɪ | hh | h | z | z | epi | Epenthetic silence |
| ih | ɪ | jh | ʤ | zh | ʒ | h# | Begin/end marker |
| ix | ɨ | k | k | ||||
| iy | i | l | l | ||||
| ow | oʊ | m | m | ||||
| oy | ɔɪ | n | n | ||||
| uh | ʊ | ng | ŋ | ||||
| uw | u | nx | |||||
| ux | ʉ | p | p | ||||
| No | ARPAbet | No | ARPAbet | No | ARPAbet | No | ARPAbet |
|---|---|---|---|---|---|---|---|
| 1 | iy | 11 | oy | 21 | ng eng | 31 | b |
| 2 | ih ix | 12 | aw | 22 | v | 32 | p |
| 3 | eh | 13 | ow | 23 | f | 33 | d |
| 4 | ae | 14 | er axr | 24 | dh | 34 | dx |
| 5 | ax ah ax-h | 15 | l el | 25 | th | 35 | t |
| 6 | uw ux | 16 | r | 26 | z | 36 | g |
| 7 | uh | 17 | w | 27 | s | 37 | k |
| 8 | ao aa | 18 | y | 28 | zh sh | 38 | hh hv |
| 9 | ey | 19 | m em | 29 | jh | 39 | bcl pcl dcl tcl gcl |
| 10 | ay | 20 | n en nx | 30 | ch | kcl q epi pau h |
| Group | Phonemes of the Group (Written in ARPAbet) | |
|---|---|---|
| Vowels | iy ih eh ae ax uw uh ao ey ay oy aw ow er | |
| Mixed | l r w y | |
| Consonants | Nasals | m n ng |
| Fricatives | s z zh f v th dh hh | |
| Affricates | jh ch | |
| Stops | b d g k p t dx | |
| File | Begin | End | Text/Phoneme |
|---|---|---|---|
| sa.txt | 0 | 46797 | She had your dark suit in greasy wash water all year. |
| sa1.phn | 0 | 3050 | h# |
| 3050 | 4559 | sh | |
| 4559 | 5723 | ix | |
| 5723 | 6642 | hv | |
| 6642 | 8772 | eh | |
| 8772 | 9190 | dcl | |
| 9190 | 10,337 | jh | |
| … | … | … | |
| 40,313 | 42,059 | y | |
| 42,059 | 43,479 | ih | |
| 43,479 | 44,586 | axr | |
| 44,586 | 46,720 | h# |
| Phoneme Groups | Fricatives | Affricates | Stops | Nasals | Vowels/Mixed |
|---|---|---|---|---|---|
| Train set | 21,424 | 2031 | 22,281 | 14,157 | 75,257 |
| Core test set | 1114 | 95 | 1114 | 736 | 3955 |
| Baseline | Analysis Window Sizes | ||||||
|---|---|---|---|---|---|---|---|
| 5 ms | 10 ms | 15 ms | 20 ms | 25 ms | 30 ms | ||
| Vowels | 0.700 | - | - | - | - | - | - |
| Mixed | 0.919 | - | - | - | - | - | - |
| Nasals | 0.568 | 0.565 | 0.553 | 0.564 | 0.579 | 0.557 | 0.568 |
| Fricatives | 0.724 | 0.710 | 0.739 | 0.738 | 0.737 | 0.735 | 0.736 |
| Affcicates | 0.632 | 0.632 | 0.642 | 0.653 | 0.590 | 0.653 | 0.642 |
| Stops | 0.628 | 0.657 | 0.682 | 0.651 | 0.647 | 0.626 | 0.620 |
| Group avg | 0.695 | 0.697 | 0.706 | 0.704 | 0.695 | 0.698 | 0.698 |
| Integrated | 0.730 | 0.732 | 0.738 | 0.735 | 0.735 | 0.731 | 0.731 |
| MFCC/Autocorrelation Combinations | ||||
|---|---|---|---|---|
| Phoneme | Group Specific | Input Concat | Concat BLSTM | Concat BLSTM |
| Groups | Window Sizes | + FCN | + BLSTM + FCN | |
| Nasals | 0.742 | 0.757 | 0.742 | 0.757 |
| Fricatives | 0.844 | 0.847 | 0.834 | 0.827 |
| Affricates | 0.768 | 0.737 | 0.779 | 0.747 |
| Stops | 0.796 | 0.781 | 0.806 | 0.778 |
| Overall Model | |||
|---|---|---|---|
| Phoneme | Baseline | Group | MFCC |
| Groups | Phoneme | Specific | and Autocorrealation |
| Classification | Window Size | Combination Model | |
| Vowels | 0.700 | 0.700 | 0.700 |
| Mixed | 0.919 | 0.919 | 0.919 |
| Nasals | 0.568 | 0.579 | 0.590 |
| Fricatives | 0.724 | 0.739 | 0.754 |
| Affcicates | 0.632 | 0.653 | 0.653 |
| Stops | 0.628 | 0.682 | 0.688 |
| Group avg | 0.695 | 0.712 | 0.717 |
| Integrated | 0.730 | 0.740 | 0.743 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oh, D.; Park, J.-S.; Kim, J.-H.; Jang, G.-J. Hierarchical Phoneme Classification for Improved Speech Recognition. Appl. Sci. 2021, 11, 428. https://doi.org/10.3390/app11010428
Oh D, Park J-S, Kim J-H, Jang G-J. Hierarchical Phoneme Classification for Improved Speech Recognition. Applied Sciences. 2021; 11(1):428. https://doi.org/10.3390/app11010428
Chicago/Turabian StyleOh, Donghoon, Jeong-Sik Park, Ji-Hwan Kim, and Gil-Jin Jang. 2021. "Hierarchical Phoneme Classification for Improved Speech Recognition" Applied Sciences 11, no. 1: 428. https://doi.org/10.3390/app11010428
APA StyleOh, D., Park, J. -S., Kim, J. -H., & Jang, G. -J. (2021). Hierarchical Phoneme Classification for Improved Speech Recognition. Applied Sciences, 11(1), 428. https://doi.org/10.3390/app11010428