1. Introduction
Optical Character Recognition (OCR) is the mechanical or electrical conversion of pictures of handwritten or printed typed text into machine-encoded texts from either a scanned document or an image of the document [
1]. It is widely practiced to recognize the texts in number plates of vehicles, passports, historical documents, business cards, printed materials, bank checks, etc. In this research, we focused on handwritten character recognition as it is more complex to recognize handwritten characters with various writing fashions than typed characters with one specific writing fashion. The main barrier to handwritten character recognition is the variation of literature worldwide. As of 2020, there are nearly 7117 languages in the world [
2]. Each of these languages has its own alphabet or letters. Hence, language-specific character recognition has been an area of interest for a long time now. Beforehand, while some of the languages have received many contributions in the area of handwritten character recognition, others did not receive any significant contributions. In this study, we focused on Bengali handwritten character recognition. The reason for choosing Bengali literature and the challenges of character recognition for the Bengali language have been presented in the following two paragraphs.
Bengali, an Indo-Aryan language, is the seventh most-spoken language worldwide and fifth most-spoken native language globally with nearly 228 million native speakers and approximately 37 million second-language speakers [
3,
4,
5]. Bengali is the most widely spoken language in Bangladesh, with 98% of Bangladeshis being fluent in Bengali as their primary language and for this reason, Modern Standard Bengali is the national language of Bangladesh [
6]. Moreover, Bengali is the second most-spoken language among the 22 scheduled languages of India just behind Hindi and the official language of West Bengal, Tripura, and the Barak Valley of Assam states of India. Moreover, it is the most-spoken language in the Andaman and Nicobar Islands located at the Bay of Bengal [
7] and is practiced by notable speakers in Uttarakhand, Nagaland, Mizoram, Meghalaya, Jharkhand, Chhattisgarh, Delhi, and Arunachal Pradesh states of India [
7]. Bengali is the only language in the world for which people sacrificed their lives on 21 February 1952 and after the independence of Bangladesh in 1971, UNESCO recognized 21 February as the International Mother Language Day in 1999 [
8]. As it is one of the most-spoken, popular, and precious languages of the world, Bengali handwritten character recognition has been an area of interest for researchers for decades now.
The phenomenon which turned Bengali handwritten character recognition into a complex problem is none other than the number of characters in Bengali literature. Unlike other popular languages, Bengali has not only 50 basic characters but also has many compound characters which makes the total number of characters in Bengali literature approximately 400 [
9]. Although the recent development in the domains of Transfer Learning and Deep Learning, 1000 classes can be taken care of by using complex neural networks, still Bengali character recognition is a tough task as Bengali characters are more complex and cursive in shape, especially the compound characters. Moreover, because it has a huge number of characters, some of the characters are extremely similar and some characters have multiple writing fashions which makes the recognition process more complex. Therefore, it is a profound domain of interest.
In this research, first, we chose publicly available and one of the most popular benchmark datasets, the CMATERdb Bengali handwritten character dataset for the training phase which contains 50 basic characters, 7 modifiers, 171 unique compound characters with 199 different writing styles, and 10 numerals of Bengali literature. After choosing the datasets, we applied some necessary preprocessing steps on the datasets and prepared different formations of the datasets as per the previous studies and conveniences. After that, we applied our proposed low-cost novel deep convolutional architecture, BengaliNet, along with hyperparameters tuning. Then, we measured the performance of the classifiers in terms of class-wise and overall precision, recall, f1-score, and accuracy. Finally, we compared the results with the previous studies and investigations. Experimental and comparative findings proved that our proposed architecture outperformed previously achieved highest performance and therefore, can recognize the Bengali handwritten characters more accurately. Additionally, our proposed architecture achieved decent overall accuracies while testing our trained models on other available Bengali datasets i.e., Ekush, BanglaLekha, and NumtaDB. Contributions of our research have been more precisely described in the “Our Contributions” section.
2. Literature Review
Previously, various studies have been conducted for the accurate recognition of the handwritten characters of some popular languages, for example, English handwritten characters [
10,
11], Chinese handwritten characters [
12,
13], Spanish handwritten characters [
14,
15], Hindi handwritten characters [
16,
17] and so on. However, not a significant amount of studies have been conducted on the Bengali handwritten characters. Moreover, very few contributions are notable in the recognition process of Bengali compound characters. Similar and popular non-Latin languages such as Arabic [
18], Chinese [
12,
13], Farsi [
19], Greek [
20], Hindi [
16,
17], Japanese [
21], Korean [
22], Nepali [
23], Russian [
24], Thai [
25], Urdu [
26], etc. have received contributions in the domain of handwritten character recognition. Compound characters are the common property of Indian scripts among which Devanagari and Bengali have a huge set of compound characters [
27]. Sometimes the shape of the compound character is so complex that it becomes difficult to identify the constituent consonants [
27]. Languages that use the Devanagari script such as Hindi [
27] suppress the vowel most of the time to bypass the use of compound characters [
28] and as a result, few significant works have been conducted regarding Devanagari handwritten compound character recognition previously. However, compound characters are frequently used in Bengali scripts. Therefore, it is important to design a model that can recognize this huge number of compound characters which are highly stylized and morphologically complex. In this section, we have mentioned only the noteworthy studies which paved away the path of the recognition process.
Researchers started to implement Bengali basic character recognition long before. Early research on Bengali 50 basic character recognition suggested a Multilayer Perceptron (MLP) technique on stroke features and achieved the highest overall accuracy of 84.33% [
29]. The number of samples used for training and testing was 350 and 90 for each of the 50 classes. In another research, the authors applied a Multilayer Perceptron (MLP) classifier on the 76 extracted features (36 longest-run features, 16 centroid features, and 24 shadow features) and achieved an overall accuracy of 75.05% [
30]. A total of 10,000 images of size
of 50 classes were used in this research and the train-test ratio was 80:20. Later, the study of chain code histogram features suggested an overall accuracy of 92.14% by applying a Multilayer Perceptron (MLP) classifier [
31]. In this research, the authors used 200 samples for each of the 50 classes for training and 10,187 samples for testing where each of the test classes had at least 60 samples per class. The images were scanned at 300 dpi resolution.
After that, CMATERdb datasets were introduced [
32,
33] which not only contained Bengali basic characters but also contained compound characters, numerals, and modifiers. Since then, a notable number of studies have been conducted on different CMATERdb datasets. One research suggested a deep convolutional neural network with a learning rate of 0.001 and the train-validation ratio of 80:20 for the recognition of 50 basic Bengali handwritten characters [
34]. Later, MobileNetV1 architecture was used for recognizing the basic Bengali handwritten characters [
35]. Sharif et al. applied a Hybrid-HOG-based Convolutional Neural Network approach and achieved 92.57% and 92.77% accuracy for 171 and 199 Bengali compound characters respectively [
36]. Ashiquzzaman et al. suggested a deep convolutional network-based approach with ELU and dropout to achieve an overall accuracy of 93.68% although they considered 8,000 test images and 34,000 train images [
37]. Although a significant amount of research has not been conducted on Bengali basic and compound characters, a significant amount of works has been conducted on the Bengali numerals recognition. A recent study suggested a Deep Convolutional Neural Network on point-light source-based shadow features and histogram of oriented pixel positions features [
38]. Ensemble learning was used in one of the studies as well [
39]. Another recent work suggested a Convolutional Neural Network-based architecture considering a lesser number of trainable parameters, applied their proposed model on Bengali numerals, basic characters, compound characters, modifiers, and the dataset of all 256 characters and outperformed previous studies [
40]. Another research that worked with the class-wise performance of 256 classes previously, achieved an overall accuracy of 87.26% using a soft computing paradigm embedded in a two-pass approach, and this work was suggested by the original authors of the CMATERdb datasets [
41]. In this research, we worked with the CMATERdb datasets and outperformed all these previous studies.
Moreover, there have been some studies where the authors have focused on developing cost-effective Bengali character recognition architectures. One study suggested a multiobjective approach towards cost-effective Bengali handwritten characters recognition [
42]. Another research suggested multiobjective optimization for recognition of handwritten Indic scripts [
43]. Furthermore, transfer learning has been used by applying various architectures i.e., AlexNet, VGG-16, ResNet-50, etc. beforehand [
44,
45]. Our proposed architecture has not only outperformed all these studies in terms of overall accuracy but also in terms of the number of parameters as well. Details on experimental results and comparative analysis can be discovered in the “Experimental Analysis” section.
3. Our Contributions
In this research, we have proposed a low-cost novel deep convolutional neural network architecture, BengaliNet, for Bengali handwritten character recognition. The architecture uses 2.24 million to 2.43 million parameters only, based on the number of output classes (7, 10, 50, 171, 199, and 256). The reason for focusing on a fewer number of parameters is that Bengali handwritten character recognition is supposed to be an application for mobile devices. Hence, low-cost models are suitable for such applications. The existing architectures in previous research used more parameters than ours. For example, VGG-16, Alex Net, and ResNet-50 have been implemented in previous research and used almost 138 million, 61 million, and 23 million parameters [
44,
45]. MobileNetV1 architecture uses the least number of parameters that is a total of 4.2 million parameters, but this architecture traded off low-cost implementation with accuracy, hence, produced a lower accuracy [
35].
However, the latest work in the domain of Bengali handwritten character recognition used 4.75 million parameters for training by not trading off the overall accuracy [
40]. This work outperformed all previous studies and the authors compared their architecture with AlexNet, VGGNet, and GoogLeNet as well. They used
size input images for their research. In our research, we used a novel deep convolutional neural network with an input size of
. As the main focus of this research is to design a low-cost high-performance network for mobile devices, the input size was kept as small as possible to minimize the overall number of parameters without sacrificing the performance. We not only used only 2.24 to 2.43 million parameters (almost half parameters of the latest research) but also outperformed the latest work by a fine margin as well. Details on our architecture can be found in the “Materials and Methods” section and comments on why our proposed architecture is novel and works better can be discovered in the “Experimental Analysis” section.
Further inspection of misclassifications revealed that almost all the misclassifications were occurring due to some common issues. Some of the classes had highly similar samples, some of the classes had multiple writing fashions and some of the classes had some noisy samples that are even difficult to recognize by human eyes. With proper examples and figures, misclassifications have been discussed in the “Experimental Analysis” section. We believe commenting on misclassifications will further showcase the efficiency of our proposed architecture and significantly justify our contributions. To measure the efficiency and impact of the proposed architecture in developing Bengali handwritten character recognition tools, other Bengali datasets of different distributions were used for testing i.e., Ekush, BanglaLekha, and NumtaDB. These datasets were not used while training, hence, the samples are unknown to the classifier. Despite coming from different distributions, our architecture achieved an overall accuracy of 98.36%, 99.13%, 96.09%, 98.11%, and 97.50% for Ekush basic and numerals, BanglaLekha basic and numerals, and NumtaDB numerals respectively. Thus, we believe our contributions will be significant in the domain of Bengali handwritten character recognition.
4. Materials and Methods
This section contains explanations on dataset description, augmentation, dataset preparation, deep convolutional neural network, and the proposed BengaliNet architecture.
4.1. Dataset Description
In this research, we considered the CMATERdb datasets [
41] for training. The datasets considered in this research are Bengali Numerals (CMATERdb 3.1.1), Bengali basic characters (CMATERdb 3.1.2), Bengali compound characters of 2 versions (CMATERdb 3.1.3.1 and CMATERdb 3.1.3.3), and Bengali modifiers (CMATERdb 3.1.4). For all the datasets, the training set and the test set were provided separately. Only the training set was split into the train and validation set. The test set was independent and had no impact on training whatsoever. CMATERdb 3.1.1 has 10 classes of Bengali numerals. CMATERdb 3.1.2 has 50 classes of Bengali basic characters. CMATERdb 3.1.3.1, and 3.1.3.3 have 171 classes of Bengali compound characters. However, among these 171 characters, some characters have multiple writing fashions. A total of 199 distinct classes are present in these datasets in terms of writing fashions. Lastly, CMATERdb 3.1.4 has 7 classes of Bengali modifiers. Moreover, Ekush [
46], BanglaLekha [
47] and NumtaDB [
48] datasets were used to test the classification accuracy of the architecture as well.
4.2. Augmentation
In deep learning, lack of adequate data has been a remarkable dilemma from the very beginning. The reason behind this is that if a model learns from fewer samples for a specific class, that class will have less probability to be predicted correctly, as the model does not know the pattern well compared to other patterns with enough samples. As a result, misclassifications are bound to happen. With more data, deep models can generalize the learning procedure. Augmentation allows the architectures to explore additional learning which can further enhance the classification outcome. For example, suppose a cat picture is provided to the architecture but the picture is rotated 45 degrees to the left or 45 degrees to the right. Despite being rotated to left or right, the picture is still a cat picture. Moreover, if the picture is translated, zoomed or if noise is added with the picture, still the picture is a cat picture. Augmentation procedure computationally produces these sorts of images by processes such as rotating, translating, shearing, flipping, etc. These processes produce artificial samples that not only increase the training size but also increase the learning outcome of the classifier. In addition, data augmentation can be used to make equal samples for training classes to solve the imbalance issue. In this research, we have applied augmentation on the train data and then split the train data into training sets and validation sets. No augmentation was applied on the test set. Moreover, the test set was provided separately with the considered datasets.
Augmentation was implemented with the compensation of the Augmentor Library [
49]. When using the method of augmentation, the max left rotation, the max right rotation, and the probability of rotation of the rotation function was anchored to 3, 3, and 0.4 respectively. The values of grid width, grid height, probability, and magnitude of the random distortion function were adjusted to 4, 4, 0.4, and 4 respectively. Moreover, the percentage ranges and the probability of the zoom random function were adjusted to 0.9 and 0.2 respectively.
4.3. Data Preparation
We took the CMATERdb datasets under consideration, augmented the training datasets to generate 500 samples per class, and after some preprocessing steps, prepared 8 different formations of datasets as works on one or more datasets have been conducted in the previous research [
34,
35,
36,
37,
38,
40,
41]. We considered the CMATERdb datasets and augmented the training datasets to generate 500 samples per class. After the augmentation procedure, the dilemma of imbalanced training data was resolved. After that, some preprocessing steps were employed and 8 different formations of datasets were prepared as works on one or more such formations have been conducted in the previous research [
34,
35,
36,
37,
38,
40,
41]. The details of preprocessing steps can be discovered in the “Experimental Analysis” section.
Table 1 illustrates the dataset formation, number of classes, number of samples in train, validation and test sets, and whether the datasets are balanced or imbalanced.
Figure 1,
Figure 2 and
Figure 3 illustrate samples of Bengali numerals, Bengali basic characters, and Bengali modifiers. The list of 171 compound characters can be located in the primary research work [
41].
4.4. Deep Convolutional Neural Network
Deep learning [
50,
51] is being used in the domain of computer vision for a long time now. The convolutional neural network, also recognized as CNN, is one of the most common forms of deep neural networks which is generally exercised for interpreting optical images of various research domains [
52]. Convolutional neural networks are employed for object or person identification in images and videos, image classification, recommender systems, natural language processing, medical image processing, and financial investigation [
53,
54,
55]. CNNs were motivated by the connectivity among neurons which can be observed in the animal cortex and are usually functioned for image recognition or identification in various domains of research.
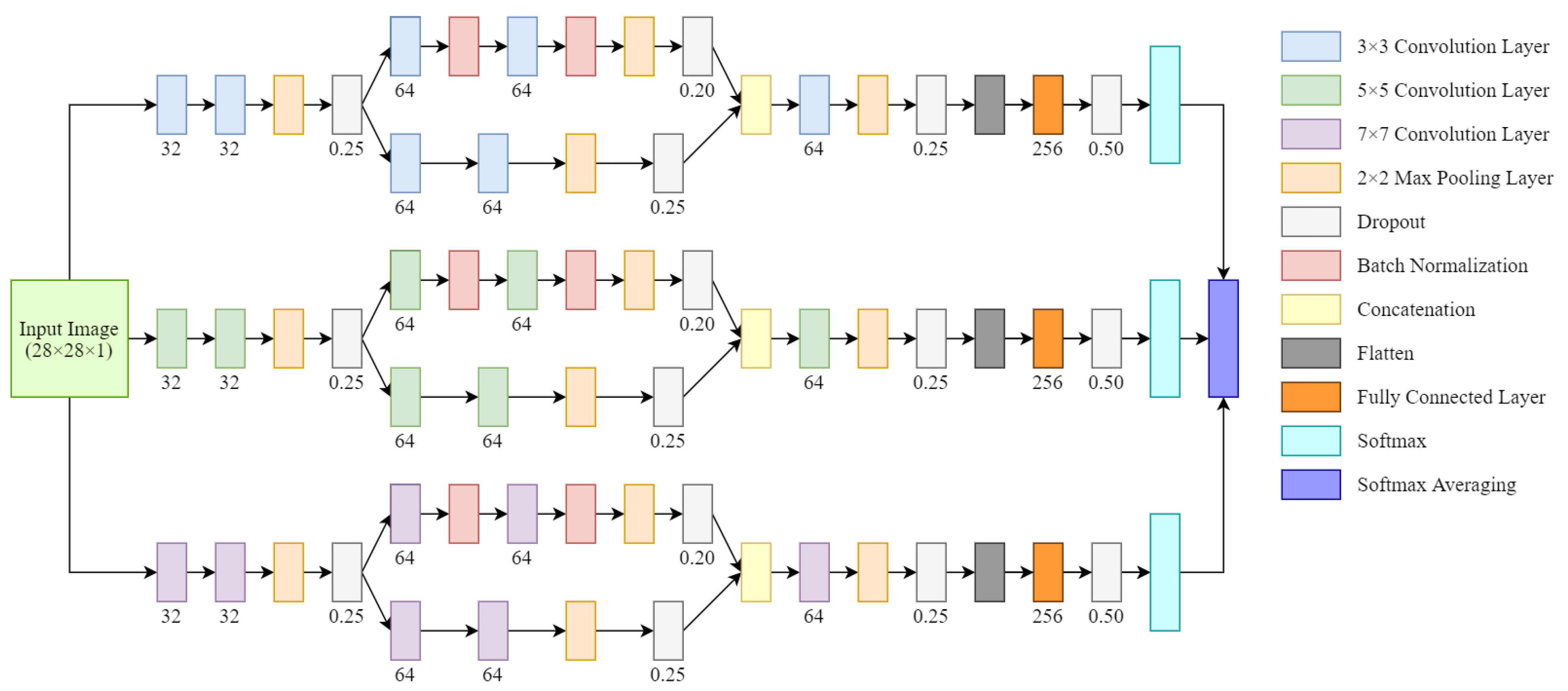
4.5. Proposed BengaliNet Architecture
The purpose of this research was to design a low-cost deep convolutional architecture that can accurately predict the Bengali handwritten characters. That is why BengaliNet was chosen as the name of the architecture. The size of the input image was set to
for BengaliNet architecture. The input image was then passed to three different paths. All these three paths have essentially the same combination of layers, but the filter size of convolution is different.
,
, and
filters were used for the three paths. It turned out because of having both simple and complex shaped characters, any one of the
,
, and
filters could not produce better learning but in combination, the classification can be enhanced dramatically. This phenomenon is also referred to as multicolumn CNN design as the end network consists of multiple convolutional neural networks or columns [
39]. More about the intuition behind classification enhancement can be discovered in the “Experimental Analysis” section with proper experimental results.
Each of the paths started with two convolutional layers of depth 32 followed by a max-pooling layer and a dropout of 25%. After that, the output was provided to two branches. The first branch had one convolutional layer followed by a batch normalization layer and another convolutional layer followed by another batch normalization layer. Then, max-pooling was added followed by a dropout of 20%. The second branch started with two convolutional layers followed by a max-pooling layer and a dropout of 25%. For both branches, the depth of the convolutional layers was set to 64. Outputs of the two branches were then concatenated and fed to a convolutional layer of depth 64 followed by a max-pooling layer and a dropout of 25%. Next, a fully connected layer of size 256 was added after flattening followed by a dropout of 50%. Finally, an output layer was connected with the SoftMax activation function with a size of 7, 10, 50, 171, 199, or 256 based on the number of classes. For all the convolutional layers, the ReLU activation function was used and for all max-pooling layers, the max-pooling filter size was .
Each of the three paths generated a prediction but despite applying a voting process to predict the outcome, we applied the SoftMax averaging technique here. The average of three SoftMax outputs was considered to be the final SoftMax output and was used to predict the outcome. More intuitions about this idea can be discovered in the “Experimental Analysis” section.
Figure 4 illustrates the architecture of BengaliNet. Our architecture has 2.24–2.43 million parameters based on the number of classes in consideration.
Table 2 illustrates the number of parameters for each layer considering 256 classes as 256 is the maximum number of classes in our experimental datasets.
5. Experimental Analysis
In this section, preprocessing, experimental settings, results analysis, individual vs. BengaliNet architecture, reason of better performance, comparison with previous works, and comments of misclassification have been described and illustrated.
5.1. Preprocessing
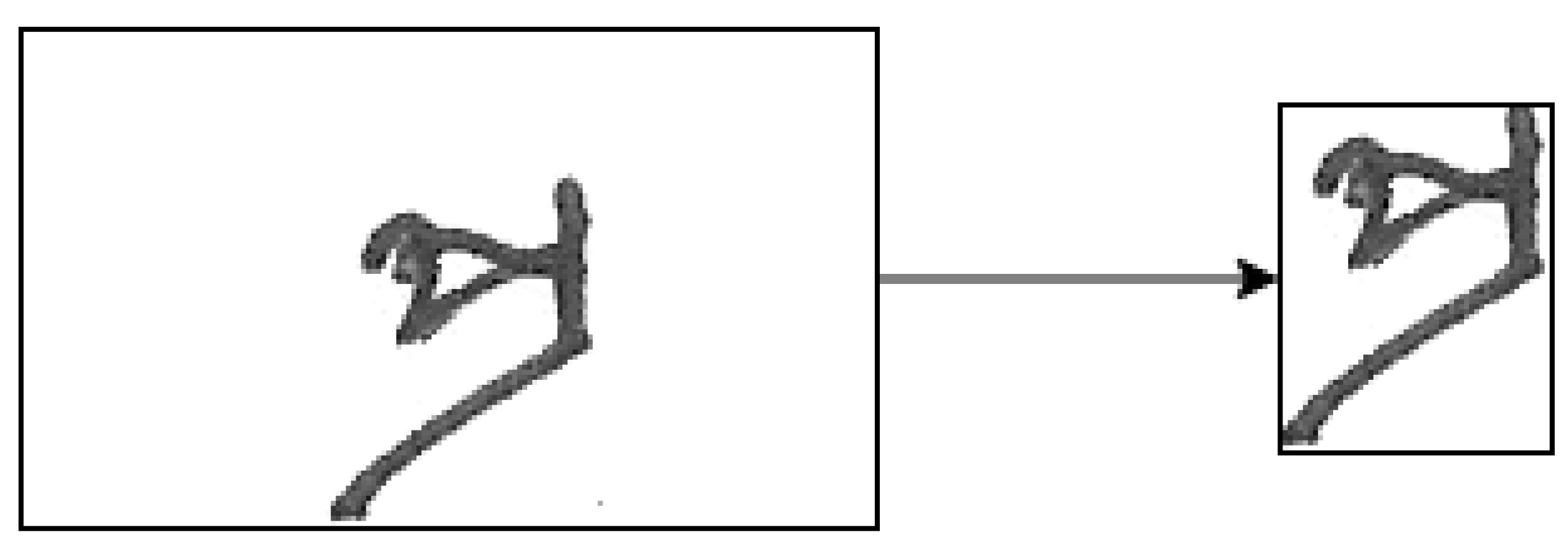
Because of providing images to a convolutional neural network, a heavy preprocessing of the pictures was skipped as CNN is a compelling network that can identify significant features from raw images. However, some preprocessing steps were required. First, all the images were auto-cropped as most of the images had a large area with only background pixels.
Figure 5 illustrates the effect of auto-cropping. After that, all the images were converted to binary images as there were some grayscale images in some of the classes.
Figure 6 illustrates the effect of binarization. As the proposed architectures take inputs of size
, all the input pictures were reshaped to
.
5.2. Experimental Settings
The model was trained for 200 epochs with a batch size of 512 as after that the validation loss grew almost constant for the rest of the epochs. ’Adam’ optimizer [
56] was employed to maximize the error function. A categorical cross-entropy function was employed for the loss or error function. For avoiding overfitting, the dropout technique was used. SoftMax activation [
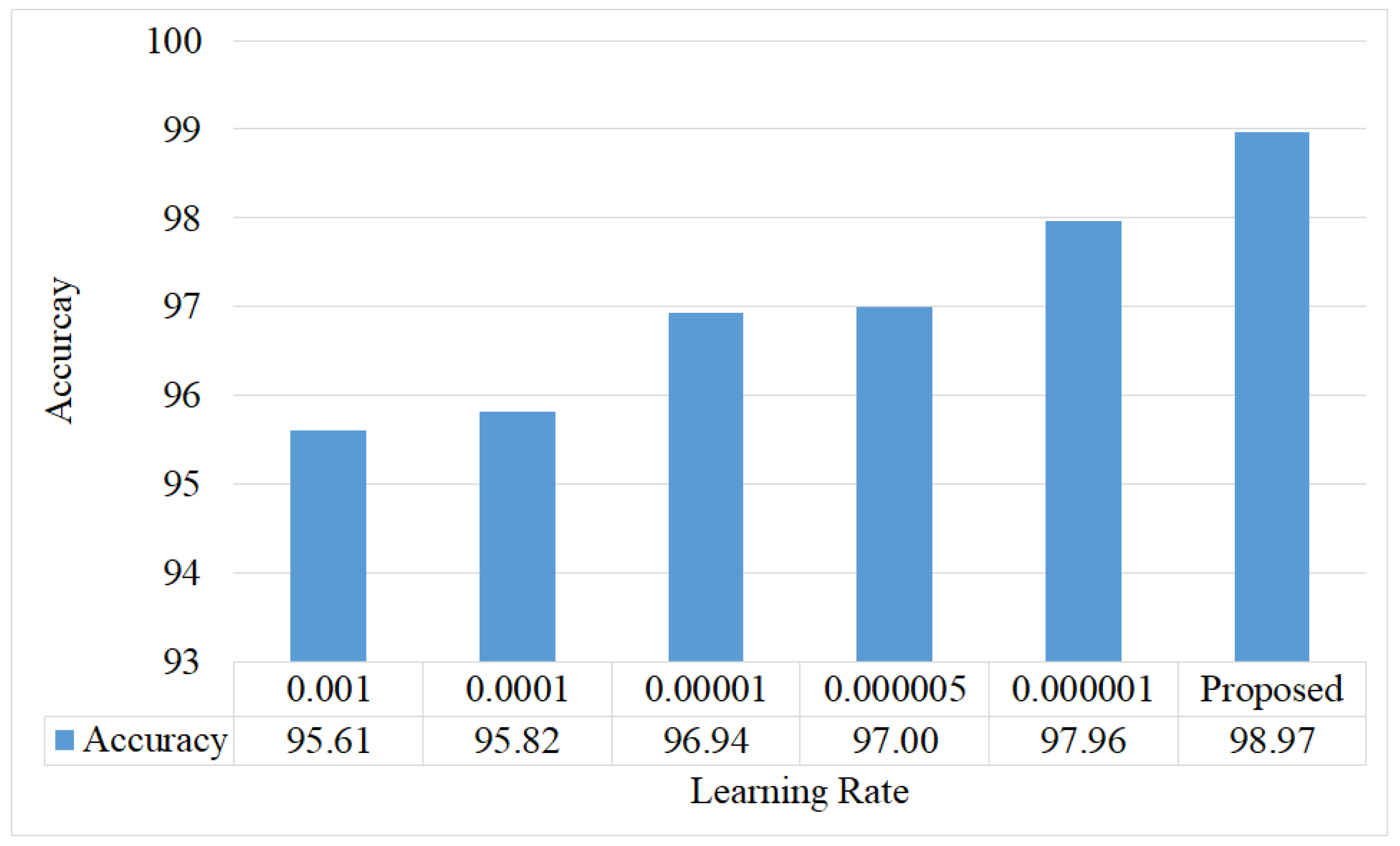
57] was used while applying the output layers. Learning rate of 0.001, 0.0001, 0.00001, 0.000005, and 0.000001 were used for 100, 40, 30, 20, and 10 epochs respectively in a sequential order while learning.
5.3. Result Analysis
After applying the preprocessing approaches, the training sets and validation sets were prepared. After that, the proposed BengaliNet architecture was applied to all the datasets.
Table 3 presents the number of classes and number of parameters for all 8 dataset formations.
Table 4 and
Table 5 represent the overview of overall accuracies for BengaliNet architecture applied on the above-mentioned datasets and other independent datasets i.e., Ekush, BanglaLekha, and NumtaDB. When testing with Ekush, 15% data were taken under consideration and while testing with BanglaLekha and NumtaDB, the whole dataset was considered. For each dataset, we also calculated the class-wise accuracy, precision, recall, and f1-score which can be located in the
supplementary file. Kaggle GPU environment i.e., 4 CPU cores, 16 Gigabytes of RAM, 20 Gigabytes of disk space, was used while calculating the test results. In that environment, the average recognition time per sample for 8 datasets using BengaliNet was 3.6, 4.1, 10.5, 10.5, 11.0, 1.7, 27.3, and 28.6 ms per sample respectively. The training times required for this research for the 8 considered datasets are 1.24, 6.07, 8.36, 8.42, 9.56, 0.95, 25.23, and 26.01 h respectively. Here, it should be mentioned that training the models was a one-time process, and the weights were saved after the training. Therefore, no retraining was needed while testing for independent and unseen datasets. In later sections, it can be observed that for all 8 datasets, BengaliNet achieved the highest accuracy.
5.4. Individual vs. BengaliNet Architecture
To further prove the fact that our proposed architecture can enhance the recognition of Bengali handwritten characters, we measured the performances using 3 × 3, 5 × 5, and 7 × 7 paths individually as well.
Table 6 illustrates the comparison of performances among the BengaliNet architecture and single path architectures for the considered datasets. From the table, it is clear that BengaliNet works better than any of the three architectures alone.
5.5. Tuning of Hyperparameters
The hyperparameters that have been used in this study are the number of epochs, learning rate, and batch size. To justify the tuning of these hyperparameters, classification results for various values of hyperparameters were calculated. In this section, results for dataset-2 have been presented.
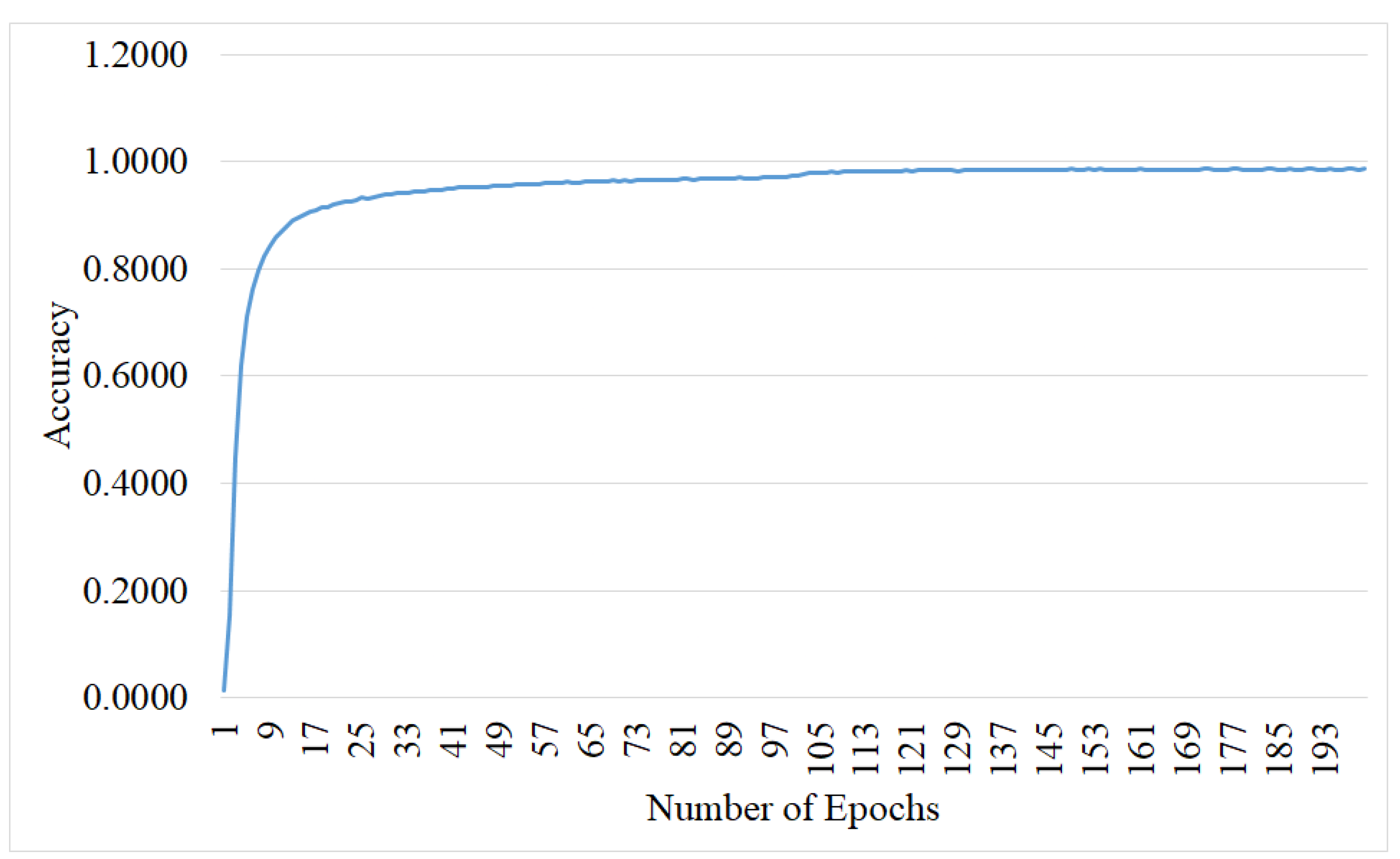
Figure 7 illustrates the accuracy vs. number of epochs graph when the learning rate and batch size are fixed as mentioned in experimental settings.
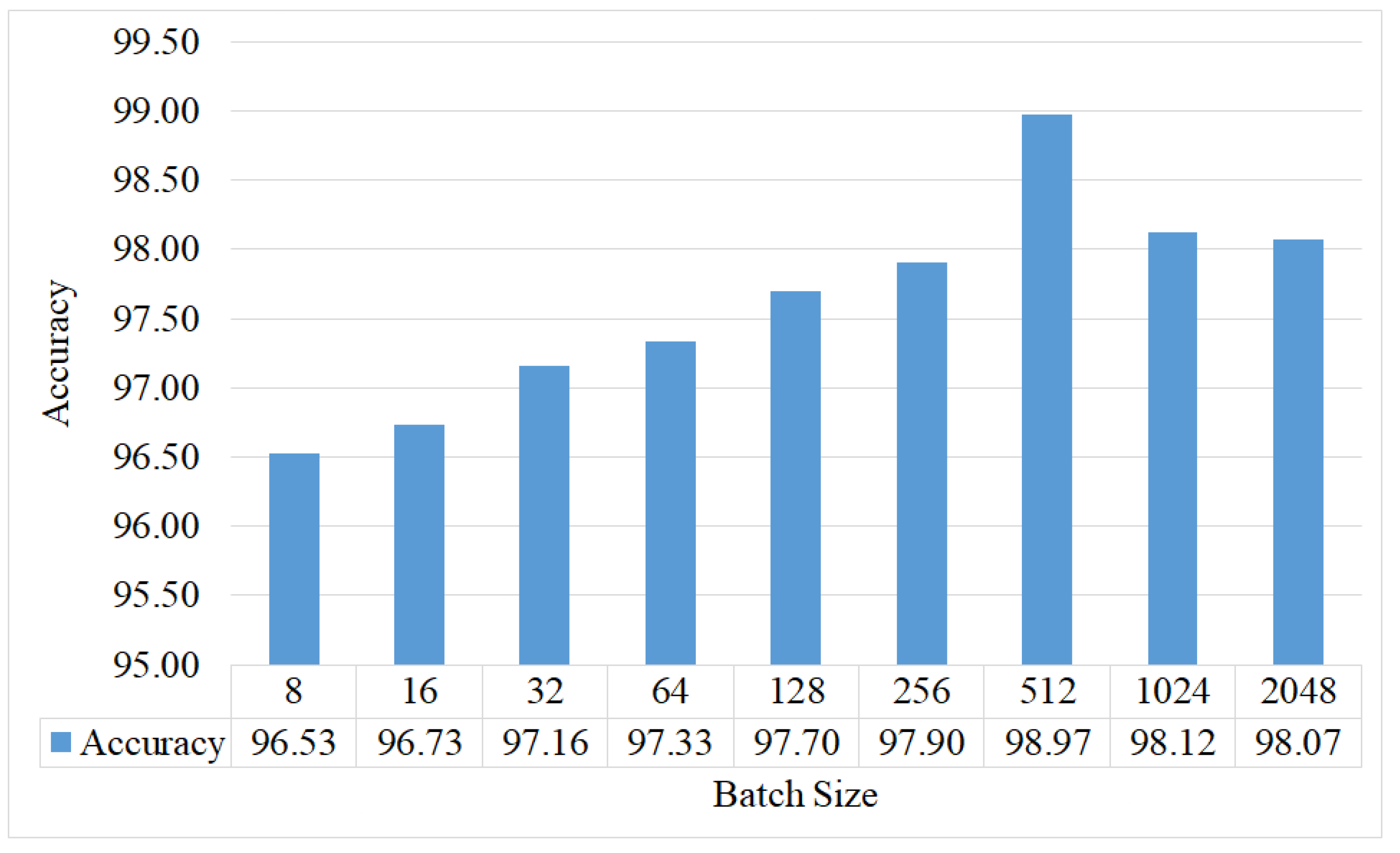
Figure 8 illustrates the accuracy vs. batch size graph when the learning rate and the number of epochs are set to the values mentioned in experimental settings. Finally,
Figure 9 shows the accuracy for different learning rates. It can be noticed that better accuracy can be achieved for the proposed setup.
5.6. Comparison with Previous Works
After measuring the performance of our proposed models, we compared the results with the previous works.
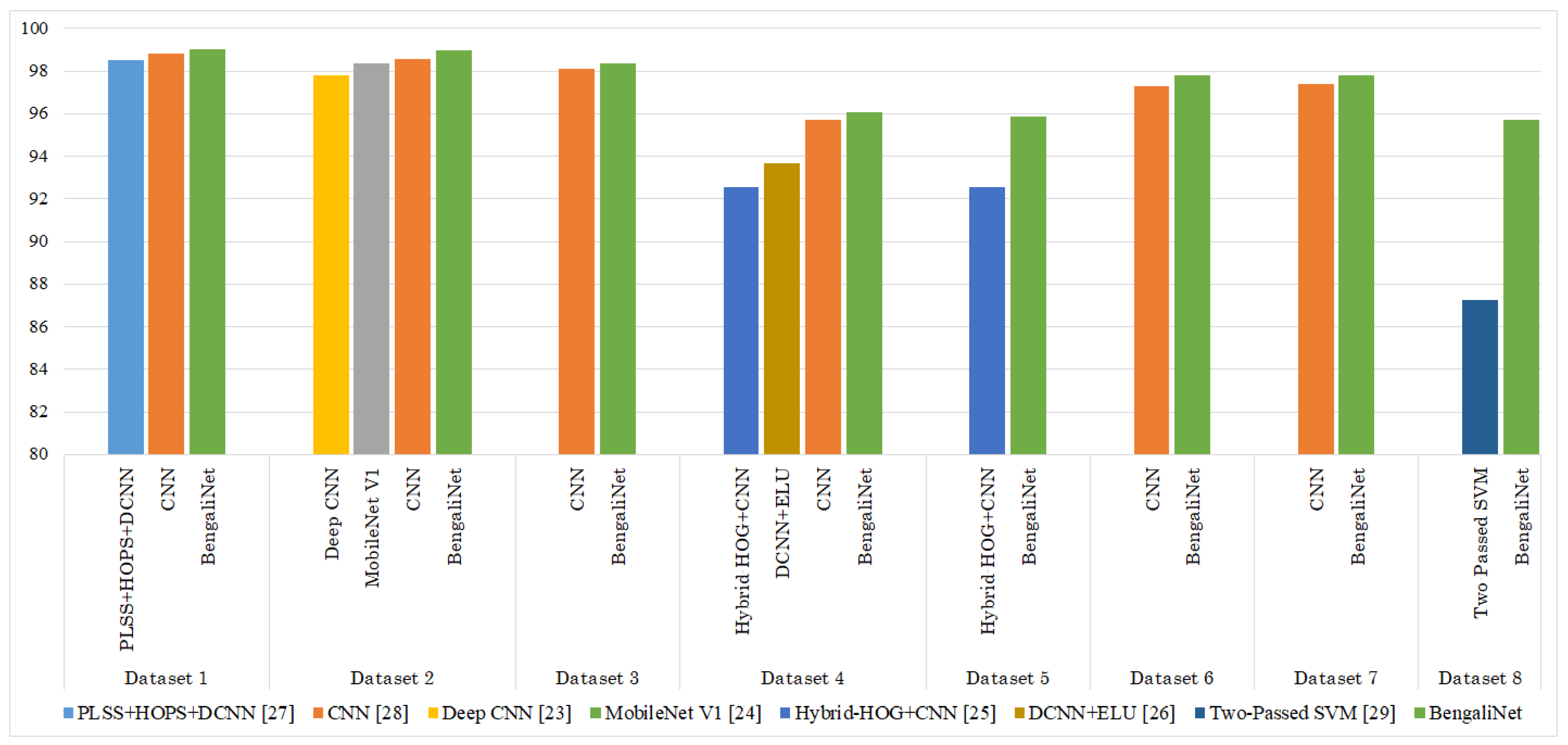
Table 7 illustrates the comparison between our proposed approach and previous works.
Figure 10 illustrates the comparative results in terms of accuracy for all 8 datasets.
From
Table 7, it can be observed that for each formation our proposed approach has outperformed the previous noteworthy works. In the remarks section, we also have provided comments (if required) so that the comparison can be fair. For example, for dataset 7, one research [
40] achieved 97.42% accuracy, our proposed architecture has achieved 97.82% accuracy. It does not seem much improvement although there were 11,804 samples and this slight improvement denotes a lot of corrected misclassifications. However, the research [
40] that achieved 97.42% did not consider the entire train and test sets which makes our outcomes better as ignoring some samples while training and testing may affect the performance positively. Moreover, we provided the results for some popular CNN architectures i.e., GhostNet, InceptionV4, Xception, MobileNetV1, MobileNetV2, MobileNetV3Small, and MobileNetV3Large architectures in
Table 8. Despite being a smaller architecture of 6.5 million parameters, GhostNet did not achieve the desired performance for the considered dataset. InceptionV4 with 43 million parameters and Xception with 23 million parameters achieved a high performance but could not outperform the performance achieved by the proposed BengaliNet architecture. On the other hand, the MobileNet architectures achieved decent performance but could not outperform BengaliNet as well.
Additionally,
Table 9 illustrates a comparison with some previous studies that focused on the recognition of Bengali handwritten characters by using transfer learning. It can be observed that BengaliNet has a fewer number of parameters than previous transfer learning methods which denotes that BengaliNet needs less recognition time. Moreover, in terms of overall accuracy, BengaliNet outperforms all these studies as well. It can be noticed that BengaliNet achieved decent accuracy for Ekush, BanglaLekha, and NumtaDB datasets also as the last achieved highest accuracy for these datasets are 97.73% [
46], 93.45% [
58], and 98.40% [
59] respectively.
5.7. Why Proposed Architecture Performs Better?
BengaliNet works better mainly because of its three-way architecture. When designing the BengaliNet architecture, different combinations of filter sizes were taken into consideration. It was observed that many Bengali characters have complex shapes. To extract these complex shapes, multiple convolutions were needed but to design a deep network, the input size needs to be larger too. These type of architectures already exists i.e., AlexNet, VGG-16, ResNet-50, etc. But the main problem of these architectures is that these architectures are heavy and have 23–138 million parameters. Bengali handwritten character recognition is supposed to be conducted in mobile devices, hence, a low-cost architecture was needed. , , or individual architectures were able to produce a decent accuracy as even in these individual architectures, there were branches. Convolutions with batch normalization and normal convolutions ensured better learning than sequential models. When designing BengaliNet architecture, we took filters of multiple sizes under consideration. The filter size of the convolution layers in three pathways were , , and respectively. Moreover, each of these paths has its own branches with multiple convolution layers, batch normalization, and dropouts. Merging features obtained from the general convolution and the convolution with batch normalization ensured better learning than a simple sequential model. It was observed that and architectures were being able to learn some complex features which were not being learned by architecture. Hence, these three architectures were combined.
Instead of choosing the voting method, the SoftMax averaging technique was chosen for this research. As there were only three architectures in consideration, the voting method was depending on random class selection when the three architectures were producing different test outcomes. But for the SoftMax averaging technique, this randomness can be reduced. Suppose, for a specific test sample, the three paths were predicting A, B, and C classes. In such cases, the voting method chooses a random class among three different predicted classes which can either produce a better accuracy or a worse accuracy. On the other hand, the SoftMax averaging technique takes the average of three SoftMax arrays produced by three paths and therefore, there is a high possibility to omit the possible randomness of the voting method. In
Table 10, the overall accuracy for the voting method and the SoftMax averaging method have been presented. It can be noticed that the SoftMax averaging technique is producing better performance. When there are many architectures under consideration, the efficiency of the voting method will increase. But as in this research, the focus was specifically on cost-effectiveness so that recognition can be performed in mobile devices, only three small architectures were considered. Therefore, with evidence of
Table 10, we chose the SoftMax averaging technique.
Because of combining three lightweight architectures, excessive learning by extracting deep features using big or transfer learned architectures could be ignored. Furthermore, our architecture outperformed MobileNet architecture which used 4.2 million parameters and other studies that worked with low-cost mechanisms [
40,
42,
43] in terms of accuracy and number of parameters. Additionally, the dropout technique was used for bypassing overfitting so that the output cannot rely on some specific neurons only. However, selecting the values of dropouts was an experimental tuning procedure. Moreover, we chose the ‘Adam’ optimizer rather than the momentum function or RMSprop algorithm as the ‘Adam’ optimizer bears both properties of momentum and RMSprop. Furthermore, the learning rate was not kept consistent. The first epoch started with a 0.001 learning rate and ended with a 0.000001 learning rate after the completion of 200 epochs. Because of all these reasons, the proposed BengaliNet performed better despite being a low-cost architecture.
From this discussion, some major differences between the proposed model and the baseline models can be noticed. Unlike the baseline models, the proposed model does not repeat the same convolution block multiple times. Rather, the proposed model introduces a three-way architecture with filters of three sizes with different convolution blocks and branches in each way. Instead of using a voting method, the proposed model uses the SoftMax averaging technique. The input of the proposed model is a grayscale image which is much smaller in size than the baseline approaches. Moreover, dropouts and batch normalization have been used here for better learning.
5.8. Comments on Misclassifications
To find out why misclassifications were occurring, the focus was needed on the worst-performing classes for each of the datasets. This was the reason for which we decided to calculate class-wise performance in the first place.
Table 11 represents the two worst-performing classes for each of the datasets while applying the proposed architectures. If noticed closely, the two worst-performing class accuracy is high for datasets 1, 2, and 6 as these datasets have 10, 50, and 7 classes. Two worst-performing class accuracy is low for other datasets where 171, 199, and 256 classes are under consideration. As the number of test samples is higher in these datasets, a few classes with low accuracy does not hurt the overall accuracy. Additionally, some classes have a very small number of test samples i.e., 10–20 test samples. For these classes, a small number of misclassifications will cause low class-wise accuracy. For example, if 2 out of 10 samples are misclassified, the class-wise accuracy becomes 80%. On the other hand, another class with 2 misclassifications out of 100 samples will produce 98% class-wise accuracy.
From
Table 11, it can be observed that some of the classes are frequently victims of misclassification. We have two observations or comments on these misclassifications. First, some classes are similar in terms of curves and looks. That is why misclassifications happened frequently as the models become confused while recognizing these extremely similar classes.
Figure 11 presents some classes of this type.
Secondly, for compound characters, some characters had more than one writing fashion. For some characters, the writing fashions were similar and for some, the writing fashions were different. Hence, the model struggled whether these writing fashions were merged into one class or considered to be separate classes.
Figure 12 represents some classes of this type. Moreover, there are some samples in the test set which are so noisy that even human eyes cannot predict the classes correctly.
6. Conclusions and Future Scopes
Despite being the seventh most-spoken language in the world, Bengali has not received many contributions in this domain due to a huge number of characters with complex shapes. Previously, very few studies on Bengali handwritten character recognition addressed the importance of low-cost architecture. However, they traded off the performance with fewer parameters. In this study, the focus was on designing a low-cost novel convolutional neural architecture for the Bengali handwritten character recognition so that the recognition can be done on mobile devices. The proposed model called BengaliNet uses only 2.24 to 2.43 million parameters based on the number of output classes and takes an input of size only. When designing the architecture, branches, and filters of multiple sizes i.e., , , and were used which extracted better deep features. Finally, the SoftMax averaging technique was used to make the final decision for the character recognition. The experimental results showed that the proposed architecture can achieve better accuracy than the baseline approaches and the methods used in previous research in terms of performance and number of parameters. The results also showed that the proposed model obtains similar performance for previously unknown datasets as well. We believe the contributions of our study will be beneficial for future research such as automatic digitization of historical documents, automated license plate recognition, automated postal service, and so on. In the future, we will focus on improving the architecture more and apply the architecture to more datasets. Furthermore, the lack of an ideal Bengali handwritten character dataset is also a dilemma in this domain of research. In the future, we will work in this regard also.



 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}