1. Introduction
Bipartite graphs are widely used in many real-world applications to model the complex relationships across different types of entities, such as customer–product network and author–paper collaboration network [
1,
2,
3,
4]. A bipartite graph
consists of two sets of disjoint nodes, i.e.,
L and
R. Only nodes from different sets can be connected. For example,
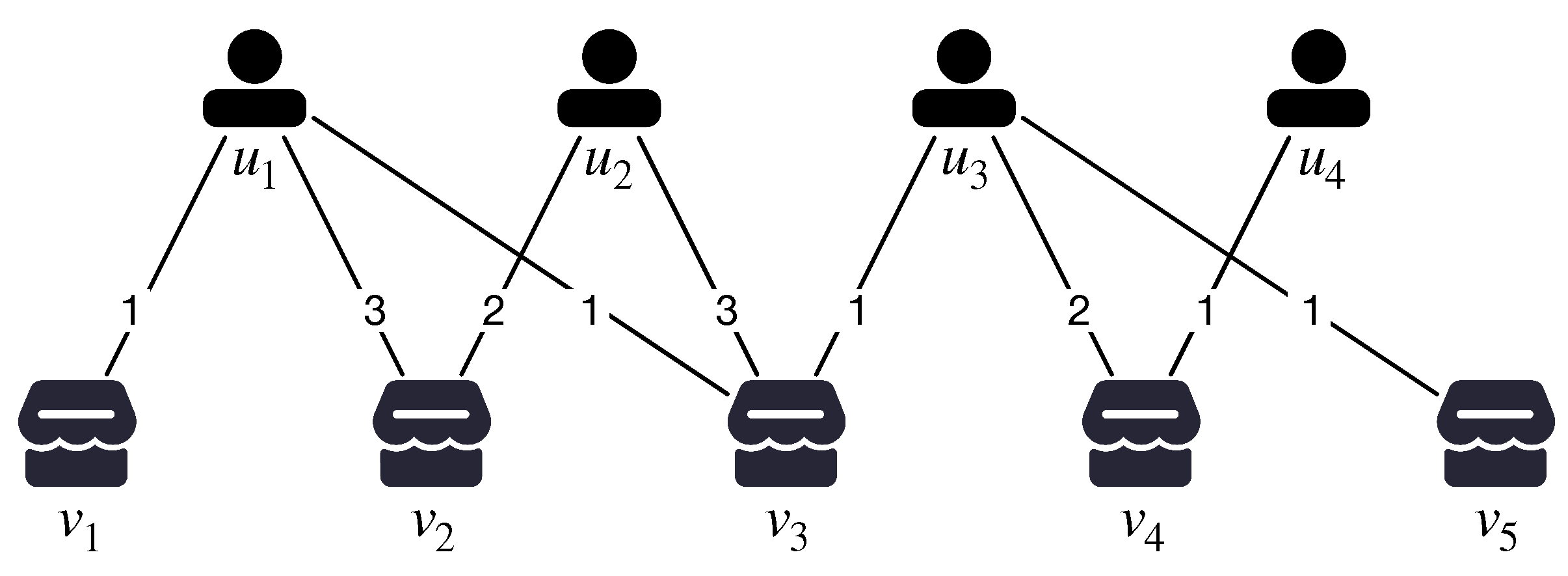
Figure 1 shows an example of customer–product bipartite network, where edges represent the purchase relationships. The left layer
L is a set of customers and the right layer
R consists of a set of products purchased. There is no edge between the customers
L (resp. products
R).
As a fundamental problem in graph analysis, cohesive subgraph identification is widely studied in the literature (e.g., [
5,
6,
7,
8]). For bipartite graphs, a variety of cohesive subgraph models have been proposed to identify important structures, such as
-core [
3], bitruss [
9] and biclique [
10]. Biclique is the most cohesive model, which requires the nodes inside to be fully connected. However, the computation complexity, i.e., NP-hard, makes it hard to apply in many time-efficient applications. Bitruss [
11] adopts the butterfly motif (i.e., a
-biclique) to investigate the cohesiveness of bipartite graphs. The
-core of bipartite graphs, which can be computed in linear time, has attracted great attention recently [
3,
12,
13]. However, the model still has a drawback.
Motivations: Given a bipartite graph
,
-core is the maximal subgraph, where each node in
L has at least
neighbors in
R while each node in
R has at least
neighbors in
L. It can be computed in linear time by iteratively deleting the node with a degree less than
or
. For instance, in
Figure 1, the subgraph consisting of nodes
is a (2,1)-core. However, in the
-core, it only emphasizes the engagement of each node, i.e., each node has a sufficient number of neighbors in the subgraph and treats each edge equally. However, in real applications, edges usually tend to have quite different weights. For example, in the customer–product network (e.g.,
Figure 1), each edge is assigned a weight, which reflects the frequency between a customer and a product. The frequency denotes the number of times the customer has bought the product.
To make sense of the weight information, we propose a novel model,
-core, to detect the densely frequent communities, which ensures that the nodes in the left layer have a sufficient number of neighbors and the nodes in the right layer have enough weights. Given a bipartite graph, the
-core is the maximal subgraph where each node in
L (resp.
R) has at least
k neighbors (resp.
weight). The weight of a node is the sum of the weights of each adjacent edge. For instance, reconsidering the graph in
Figure 1, the weights of products
are
, and the subgraph consisting of
is a (2,2)-core. The nodes
are excluded from the (2,2)-core, since customer
has not bought a sufficient number of distinct products while products
have not been purchased enough times.
Applications: The proposed -core model can be used in many real-world applications, such as product recommendation and fraud detection.
Product recommendation: In a product–customer network (e.g.,
Figure 1), a
-core means a group of users with sufficient common tastes. Then, we can use the group information for product recommendation. For example, in
Figure 1,
is the (2,2)-core. Then, we can recommend product
to user
, since
shares many common interests with
and
.
Fraud detection: For an online shopping website, fraudsters use a larger number of accounts to frequently purchase some selected products in order to boost the ranking of these products. This behavior can be modeled with a -core. By carefully selecting the parameters, we can use the detected -core to narrow down the searching space of fraudster accounts.
In real-life applications, the value of
k (resp.
) is determined by users based on their own requirements. The two parameters provide more flexibility when adjusting the resulting communities. As observed, the
-core is a special case of the
-core when all the weights in the graph equal 1. Naively, we can extend the solution of computing
-core by iteratively deleting the nodes violating the constraints. The time complexity is linear to the input graph. However, in real applications, the graph size is usually large, which means algorithms that are linear to the input graph size are also not affordable [
14]. In addition, different users may have different requirements of the input parameters
k and
, which can lead to a large amount of queries. Therefore, more efficient methods are expected to handle the massive graphs and queries.
In this paper, we resort to index-based approaches. A straightforward solution is to compute all possible -cores and maintain all the results. However, it will cause a huge computational cost by visiting the same subgraph multiple times. Thus, the time cost of computing all -cores becomes unaffordable on large graphs. To reduce the cost, we propose different index construction strategies to ensure a balance between building space-efficient indexes and supporting efficient-scalable query processing. Our major contributions are summarized as follows:
We propose a new cohesive subgraph model -core on weighted bipartite graphs by considering both density and frequency of the subgraph.
To efficiently handle massive graphs and queries, we develop three advanced index construction strategies, i.e., RowIndex, OptionIndex and UnionIndex, to reduce index construction cost. In addition, the corresponding querying algorithms by using the three index structures are provided.
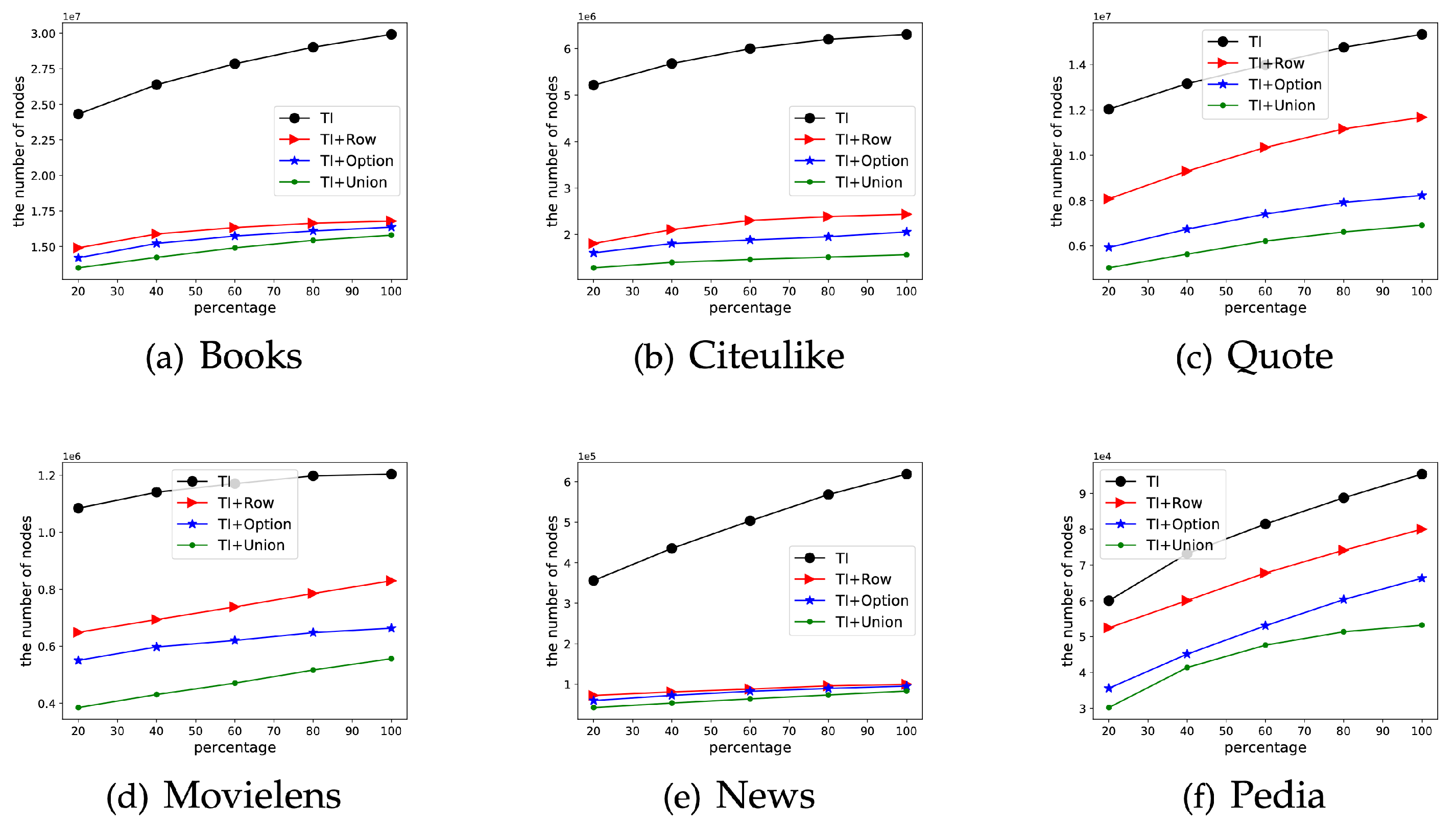
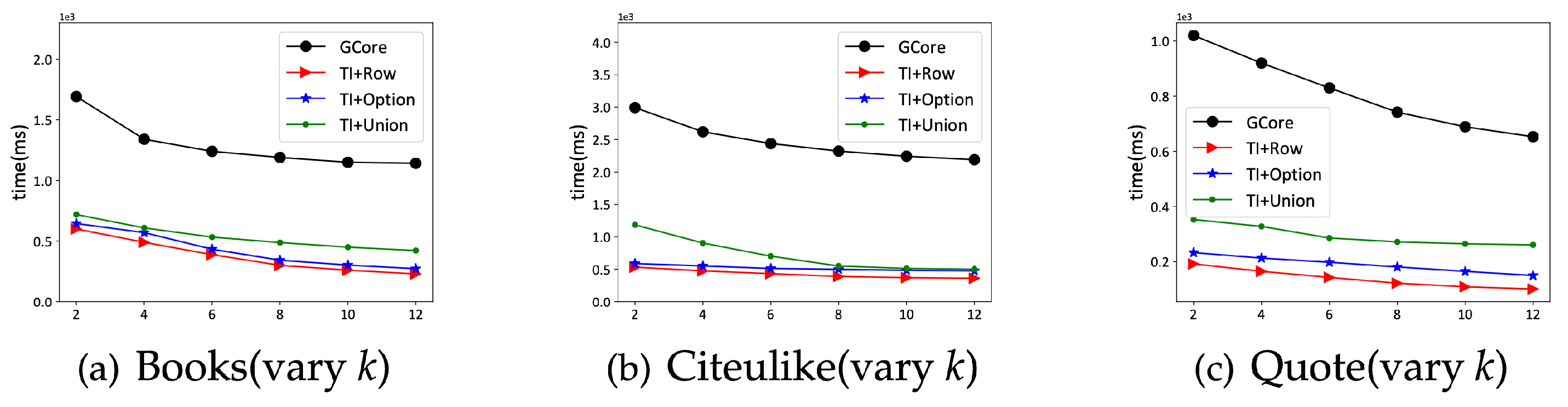
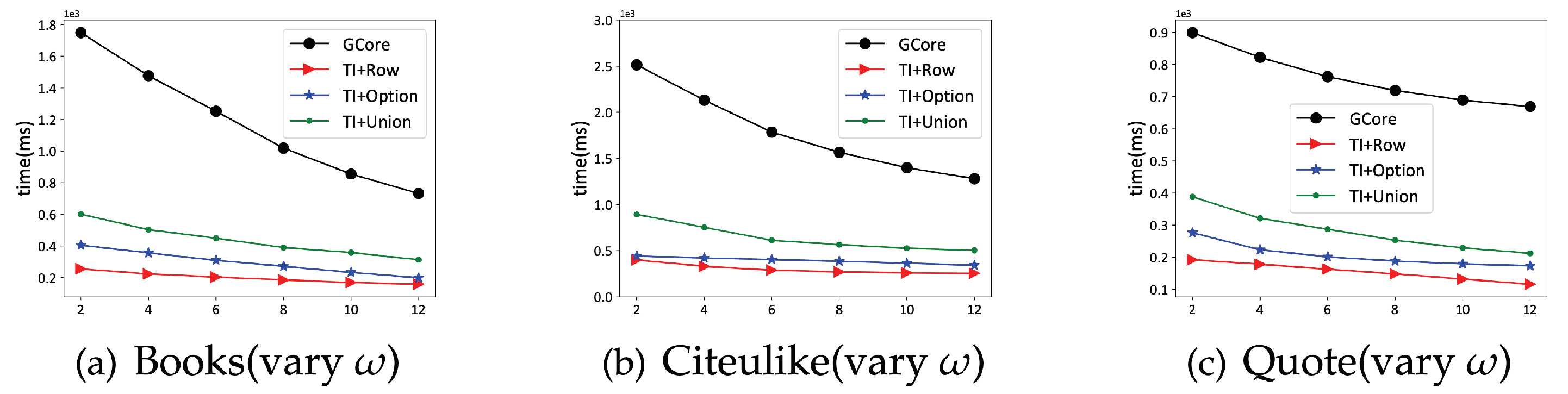
We validate the advantages of the proposed algorithms through extensive experiments on real-world datasets. The results show that the index-based algorithms outperform the baselines significantly. Moreover, users can make a trade-off between the time and space cost when selecting from the three strategies.
Roadmap: The rest of the paper is organized as follows. In
Section 2, we introduce the
-core model and formulate our problem.
Section 3 introduces the naive online algorithm.
Section 4 presents the index-based algorithms and advanced index structures. We report our experimental results in
Section 5 and review the related work in
Section 6. Finally, we present the conclusion and future work in
Section 7.
2. Preliminaries
We use to denote a weighted bipartite graph, where nodes in G are partitioned into two disjoint sets L and R, such that each edge from connects two nodes from L and R, respectively. We use and to denote the number of nodes and edges, respectively. is the set of adjacent nodes of u in G, which is also called the neighbor set of u in G. The degree of a node , denoted by , is the number of neighbors of u in G. For each edge , we assign it a positive weight , defined as the frequency of edge . The weight of a node , denoted by , is the sum of weights of each adjacent edge. We use and to denote the maximum degree and weight for nodes in G, respectively. For a bipartite graph G and two node sets and , the bipartite subgraph induced by and is the subgraph of G such that . To evaluate the cohesiveness and frequency of communities in weighted bipartite subgraphs, we resort to the minimum degree for node set L and minimum weight for node set R. In detail, for an induced subgraph, we request that nodes in have a degree of at least k and nodes in have a weight no less than .
Definition 1 (()-core). Given a weighted bipartite graph and two query parameters k and ω, the induced subgraph is the -core of G, denoted by , if S satisfies:
Degree constraint. For each node , it has degree at least k, i.e., ;
Weight constraint. For each node , it has weight no less than ω, i.e., ;
Maximal. Any supergraph is not a -core.
Example 1. Figure 1 is a toy weighted bipartite graph for modeling the customer–product affiliations. It consists of two layers of nodes, i.e., the four nodes in the left layer denote the customers and five nodes in the right layer denote the products. The edges between nodes represent the purchase relationships and the weight of edges reflects the purchase frequency. Given the query parameters and , we can obtain consisting of nodes . For simplicity, we refer to a weighted bipartite graph as a graph, and omit in the notations if the context is self-evident. In the following lemma, we show that -core has the nested property. It is easy to verify the correctness of the lemma based on the definition. Thus, we omit the proof here.
Lemma 1. Given a weighted bipartite graph G, the -core is nested to the -core, i.e., ⊆ if and .
Example 2. As shown in Example 1, consists of nodes . Suppose and . We can find that contains , i.e., .
Problem 1. Given a weighted. bipartite graph G and two query parameters k and ω, we aim to design algorithms to compute the -core correctly and efficiently.
3. Online Solution
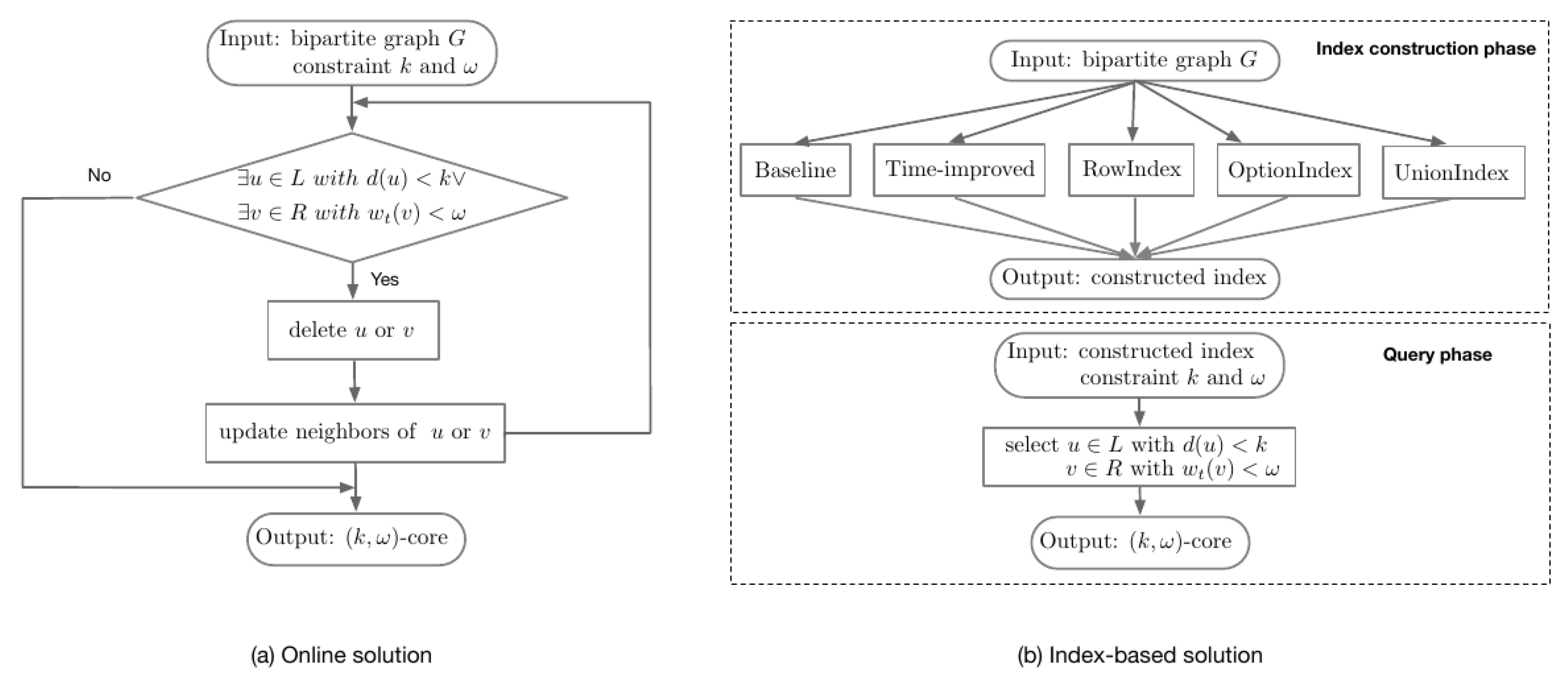
Before introducing the detailed algorithms,
Figure 2 shows the general framework of the proposed techniques in this paper. To identify the
-core, an online solution is first developed in
Section 3. To efficiently handle large networks and different input parameters, an index-based solution is further proposed in
Section 4. The index-based solution consists of two phases: an index construction phase and query phase. In addition, different optimization techniques are proposed to ensure a balance between the index construction time and index space.
For the online solution, we introduce a baseline algorithm, named
GCore, by extending the solution for
-core computation. The main idea of
GCore is to iteratively remove nodes with a degree less than
k in
L and a weight less than
in
R.
GCore terminates until the size of
G stays unchanged, i.e., there is no node that violates the constraints. Then, we output the remaining graph as
-core. The details are shown in Algorithm 1. In Lines 2–5, we check the degree constraint for nodes in
L. For each node
with
, we remove it with its adjacent edges. Then, we update the weight of node
v in
, i.e, subtract the weight of corresponding removed edge
from the total weight
. In Lines 6–9, we examine the weight constraint for nodes in
R. For each node
v with
, we remove it with its incident edges. Accordingly, we decrease the degree of
u by 1 for each
u in
, which may cause the node to violate the degree constraint. The algorithm terminates until both constraints are satisfied and finally returns the
-core of
G.
| Algorithm 1:
Generate -core |
![Applsci 11 09051 i001]() |
Discussion: The time complexity of Algorithm 1 is linear to the size of the graph. However, as discussed in the introduction, the method is still not affordable, especially for massive graphs and queries.
4. Index-Based Solution
For each input parameter, Algorithm 1 has to compute the -core from scratch, which is time-consuming and cannot support a large number of queries. To tackle the challenges, in this section, index-based algorithms are developed. The main idea is that we effectively organize all the -cores in the index, so that a query could be efficiently answered. Firstly, a baseline solution is presented. To speed up the processing of the baseline, we devise a time-improved solution. Then, several novel index structures are developed to shrink the storage space.
4.1. Baseline Solution
Intuitively, the naive index-based algorithm is to compute all the
-cores by repeatedly using the
GCore algorithm and then storing all of them in the index. As a result, we can quickly return the
-core for any given query parameters. In details, we organize all the
-cores in a two-dimensional index. That is, the nodes in
-core are all stored in
-cell, where
-cell is in the
k-th row and
-th column
of the index. The procedure terminates until all the possible
-cores are found. As a result, we can immediately obtain
-core for any given pair of parameters
k and
, according to the two-dimensional locations of cells.
Table 1 shows the index for the graph in
Figure 1. For example, the set of nodes in the
-core, i.e.,
, are all stored in the
-cell. If querying the
-core, we only need to visit the
-cell. Hence,
can be easily solved in optimal time, with
time complexity.
4.2. Time-Improved Method
The baseline index method is time-consuming, since we need to compute all the possible -cores one by one. Due to the nested property of -core, many subgraphs will be computed multiple times. To reduce the time consumption, we resort to the time-improved solution by escaping the unnecessary -core computations. Before going to the detailed method, we first introduce the concept of to help present the algorithm.
Definition 2 . Given a weighted bipartite graph , where , and a specific value k, for each node , is the maximum value of ω for which there exists a -core that contains u.
For a node
and a specific value
k, we know that the
-core contains
u by Definition 2. According to the nested property of
-core by Lemma 1, we can infer that the
-core is also contained in
-cores of
G, where
is no larger than
. Thus, there are many redundant computations in the process of constructing index structure. To address the above concerns, we devise an improved index-based algorithm. Given a graph
G and an integer
k, we first compute
for each node
and then store
u in the
-cells where
. Note that we store all nodes in
for a specific input
k. The details are shown in Algorithm 2.
| Algorithm 2:
ComputeRow()
|
![Applsci 11 09051 i002]() |
In Algorithm 2, we first initialize as empty and as 1 (Line 1). Then, we generate the -core as the candidate subgraph by using the GCore algorithm. In Lines 5–10, if node violates the degree constraint, we remove it with its adjacent edges and update the weight of the node which is also included in the neighbor set of u. After obtaining , we put node u into [i] where . Similarly, we check the weight constraint. In Lines 11–16, if node dissatisfies the weight constraint, we decrease the degree of the node u inside the neighbor set of v by 1. Then, we obtain and put node v into [i], where . We continue the iteration until all the nodes are removed from . Finally, we return as the resulting index for a given specific k. Note that we can obtain the index structure for the whole graph by repeatedly invoking Algorithm 2 with different input values of k.
Discussion: Although the time-improved method can speedup the processing, it is prohibitive for large graphs due to the large index storage cost. This is because a node can be stored in multiple cells due to the nested property. For instance, given a fixed , the nodes in the -cell will also be stored in -cell, -cell and -cell. Similarly, for a specific , the same problem still exists when computing the column index.
4.3. Advanced Index Structures
As discussed, the baseline index method suffers from storage issues. To shrink the index space without sacrificing much efficiency, we introduce three novel index structures, i.e., RowIndex: by utilizing the nested property of -core, we compress each of the index; OptionIndex: by comparing the shrink size of compression in and , we select the better compression direction; UnionIndex: by considering both and compression, we conduct the union operations on cells of the index. In addition, the corresponding query algorithms are presented.
4.3.1. Rowindex
According to the nested property in Lemma 1, we know that is always a subset of . Thus, we resort to the RowIndex by compressing of the index, since it can avoid storing a single node many times. Given a specific k, we say that all the -cells are in the k-th row, where the symbol “∗” represents any possible value of . The main difference between RowIndex and the index structure proposed above is that we only store each node in the -cell, instead of putting it into -cells where . Thus, we only need to deposit each node at most once in each of the index, which can save space from the redundant copies of nodes. Meanwhile, we also record the shrink direction (i.e., “→”) in the , which is a direction table. As the procedure of RowIndex is easy to understand, we omit its pseudo-codes in the context.
RowIndex Query Algorithm: Given query parameters k and , we first locate the -cell. Then, we collect all the nodes contained in the -cell where , and output them together as the resulting -core.
Example 3. As shown in Table 1, for , the -cell containing nodes can be compressed to the -cell and the -cell. That is, nodes only need to be saved in the -cell and nodes only need to be stored in the -cell. Thus, only the remaining nodes and are stored in the -cell. Obviously, RowIndex saves a lot of space. When querying the -core, we first locate the -cell and output nodes in the -cell and -cell together. Thus, we have . 4.3.2. OptionIndex
As discussed above, RowIndex utilizes the nested property to reduce the redundant storage for each node in each
of the index. Similarly, we can construct ColumnIndex to compress each
of the index in the same manner, which also enjoys the same space cost. Naturally, it is possible that certain cells may compress more storage by ColumnIndex than RowIndex. That is,
compression may contribute more to space saving for some cells. Motivated by this, we devised the OptionIndex structure, which is constructed by traversing all cells one by one. Specifically, when visiting a specific cell, we first compared the compression size of different compression directions, i.e., RowIndex or ColumnIndex, and then selected the better one to reduce more space. For example, in
Table 1, the compression size is 7 if we use RowIndex to shrink the
-cell to the
-cell with shrink direction “→”. Additionally, the compression size is 8 if we use ColumnIndex to shrink the
-cell to the
-cell with shrink direction “↓”. Since ColumnIndex shrinks more than the RowIndex for the
-cell, we chose ColumnIndex and shrank
-cell to the
-cell. Similarly, we chose RowIndex for the
-cell, as RowIndex saves a space of five nodes while ColumnIndex saves four. The details of the construction procedure for OptionIndex are shown in Algorithm 3.
| Algorithm 3:
OptionIndex Construction Algorithm |
![Applsci 11 09051 i003]() |
In Algorithm 3, we first initialize the and as empty (Line 1). In Line 2, the algorithm computes -core as the initialization of the current processing row and deals with each row in the main loop (Lines 4–17). We set the row next to the as at Line 4. Then, we compressed the storage space for all possible -cores in (Lines 5–16). In each inner iteration, we first initialized both of the resulting sizes of the ()-cell after shrink () and shrink () as positive infinity. In Lines 7–8, we use RowIndex to shrink the -cell to the -cell and the resulting size of the -cell is reserved in . Meanwhile, in Lines 9–10, we utilize ColumnIndex to shrink the -cell to the -cell and the resulting size of the -cell is reserved in . It is obvious that smaller the resulting size of the -cell is, the better the result of compression. Hence, in Lines 11–16, for a specific -cell, if the value of is no larger than , we choose RowIndex to compress and put the nodes contained in the -core but not in the -core into -cell, with the corresponding direction “→” recorded in . Otherwise, we select ColumnIndex to compress, and put the nodes contained in the -core but not in the -core into -cell, with the corresponding direction “↓” reserved in . We deal with each cell the same way one by one. Finally, we shrink the last of the in Line 18 by using Algorithm 2 and then return the resulting OptionIndex with its corresponding direction table in Line 19.
OptionIndex Query Algorithm: Based on the pre-computed OptionIndex, we devised an efficient option query algorithm, and the details are shown in Algorithm 4. In Line 1, we first initialize the
-core
Q as empty. In Lines 2–3, for given
k and
, we locate index[
k][
] and then add the nodes contained in the
-cell to
Q. At the same time, we obtain the shrink direction
d from
[
k][
] (Line 4). In Lines 6–9, if the direction is “→”, it implies the current
-cell adopts the
compression. Then, we add the nodes contained in the
-cell to
Q and then turn to the
-cell. In Lines 10–13, if the direction is “↓”, it suggests that the shrink direction is down the column. Accordingly, the nodes stored in the
-cell are added into
Q, and then we turn to
-cell for the next iteration. The procedure terminates until the shrink direction is null and finally we return
Q as the resulting
-core.
| Algorithm 4:
OptionIndex based Query Algorithm |
![Applsci 11 09051 i004]() |
4.3.3. Unionindex
To further reduce index cost, we propose the UnionIndex. The main difference between UnionIndex and OptionIndex is that we compress certain cells both in
and
directions at the same time to narrow more space. For example, recall that in
Table 1, the
-cell can be shrunk to the
-cell with compression size 7, or to the
-cell with compression size 8. However, the compression size can be up to 9 (i.e., all nodes in the graph) if we shrink the
-cell to both the
-cell and
-cell simultaneously with shrink directions “→” and “↓”. Thus, we chose both of the two directions to shrink space storage. In detail, we deposited the nodes contained in the
-core but not in the union set of
-core and
-core into the
-cell with shrink directions “→” and “↓” recorded simultaneously in the direction table.
The pseudo-codes to construct UnionIndex are presented in Algorithm 5. Since the UnionIndex structure is similar to the OptionIndex structure, we only demonstrate the difference from Algorithm 3 for simplicity. In Lines 6–8, for a specific
k, if the
-core is nested to the
-core, it indicates that the compression size of RowIndex is larger than that of ColunmIndex. Thus, we put the nodes contained in the
-core but not in the
-core into the
-cell with shrink direction “→”. On the contrary, if the
-core contained the
-core, we deposited the nodes included in the
-core but not in the
-core into the
-cell with shrink direction “↓” in Lines 9–11. Otherwise, in Lines 12–14, we compress the
-cell to the
-cell and the
-cell at the same time with shrink directions “→” and “↓” recorded in the direction table, by avoiding the redundant storage of nodes in the union set of the
-core and the
-core. Finally, the algorithm returns UnionIndex with its corresponding direction table
in Line 17.
| Algorithm 5:
UnionIndex Construction Algorithm |
![Applsci 11 09051 i005]() |
UnionIndex Query Algorithm: The procedure for querying UnionIndex is simple and the details are shown as follows. When given two query parameters k and , we first locate the -cell and collect the nodes stored inside it. Then, we obtain the corresponding shrink direction in the direction table , which is obtained with Algorithm 5. If the direction is only “→” (resp. “↓”), then we locate the -cell (resp. -cell) and collect the nodes contained inside it. Particularly, if there are two shrink directions “→” and “↓” recorded in the , we visit the -cell and the -cell at the same time, collecting their nodes together without duplications. We did the same for all visited cells until the current shrink direction was null and finally we outputted all the collected nodes as the resulting -core.
6. Related Work
Graphs are widely used to model the complex relationships between entities [
16]. As a special graph, many real-life systems are modeled in bipartite graphs, such as author–paper networks [
17], customer–product networks [
18] and gene co-expression networks [
19]. Bipartite graph analysis is of great importance and has attracted great attention in the literature. Guillaume et al. show that all complex networks can be viewed as bipartite structures sharing some important statistics, such as degree distributions [
20]. In [
21], Kannan et al. utilize simple Markov chains for the problem of generating labeled bipartite graphs with a given degree sequence. Borgatti et al. present and discuss ways of applying and interpreting traditional network analysis techniques to two-mode data [
22].
Cohesive subgraph identification is a fundamental problem in graph analysis, and different models are proposed, such as
k-core [
23],
k-truss [
24] and clique [
25]. Due to the unique properties of bipartite graphs, many studies are conducted to design and investigate the cohesive subgraph models for bipartite graphs, such as
-core, bitruss and biclique. Ahmed et al. [
26] are the first to formally propose and investigate the
-core model. The authors of [
3] further extend the linear
k-core mining algorithm to compute the
-core. In [
4], the authors combine the influence property with
-core for community detection. Considering the structure properties, Zou et al. [
9] propose the bitruss model, where each edge in the community is contained in at least
k butterflies. To further study the clustering ability in bipartite graphs, Flajolet et al. [
27] use the ratio of the number of butterflies to the number of three paths for modeling the cohesiveness of the graph. In [
28], Robins et al. resort to the
-biclique to model the cohesion. In [
10], a progressive method is proposed to speed up the computation of biclique. As we can see, the previous studies do not consider the weight factor for cohesive subgraph identification. Thus, in this paper, we propose
-core to capture the weight property for bipartite network analysis. Even though we can extend the computation procedure of
-core for
-core identification (i.e., online solution), it cannot handle large graphs and different parameters efficiently. Therefore, in this paper, we propose index-based solutions with different optimization strategies to deal with this issue.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}