
Biosignal-Based Driving Skill Classification Using Machine Learning: A Case Study of Maritime Navigation

 , ,
, , 
Abstract
:1. Introduction
1.1. Related Research Work
1.2. Objective and Contributions
- Maritime transport requires safety and security. SA in maritime is the effective understanding of activity that could impact the security and safety. This study discovers that the stress level varies according to the experience of the seafarers, which matters in the performance of SA during the maritime navigation.
- SA training is common in the aviation domain and the maritime domain. While SA training-related stress level analysis is widely studied for aviation, SA training-related stress level analysis in maritime navigation is less studied. This paper is a pilot case study towards classifying stress level among the expert and novice seafarers. We have used a ’hybrid’ convolutional neural network approach in combination with statistical, wavelet and higher-order crossing features to classify the stress level based on biosignals during the maritime navigation. We are first extracting features and then passing those features to a Convolutional Neural Network so we refer to is as a ’hybrid Convolutional Neural Network’.
2. Methodology
2.1. Participants
2.2. Materials and Apparatus
- PPG Sensor: Measures blood volume pulse (BVP), from which heart rate variability can be derived [8];
- Infrared Thermopile: Reads peripheral skin temperature [8];
- EDA Sensor (GSR Sensor): Measures the constantly fluctuating changes in certain electrical properties of the skin [8];
- 3-axis Accelerometer: Captures motion-based activity [8].
3. Experiment
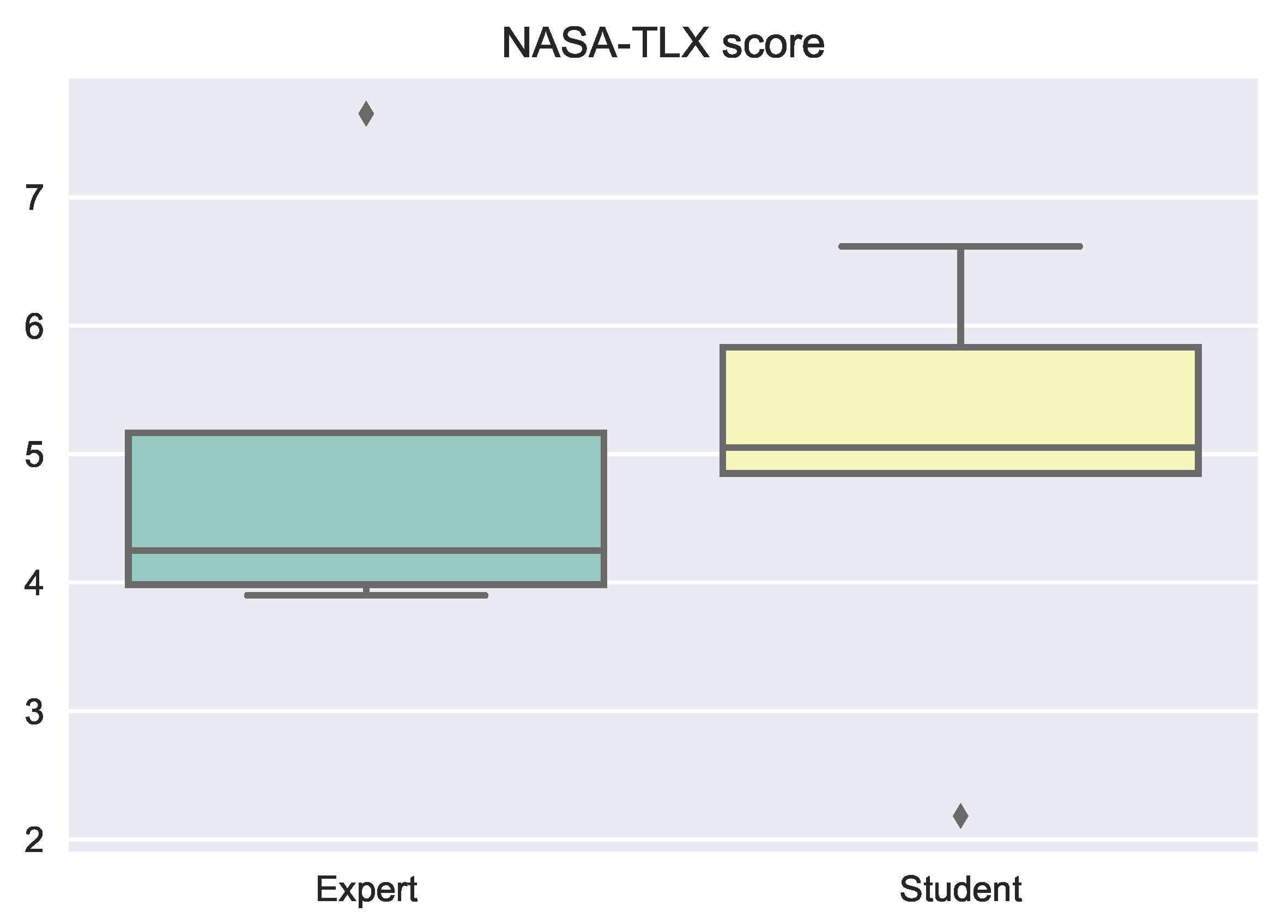
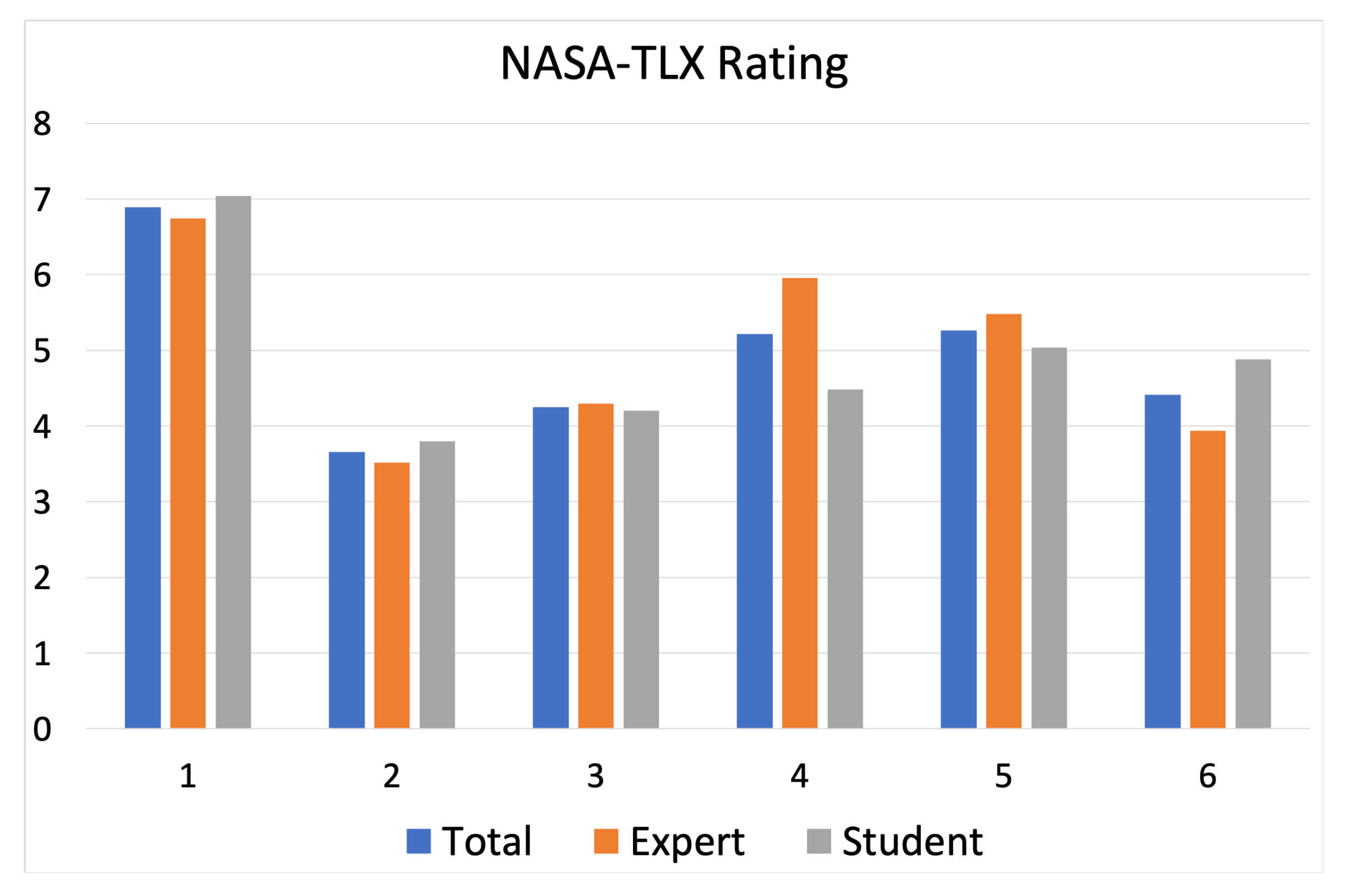
3.1. NASA Task Load Index (NASA-TLX)
NASA-TLX Rating Results
3.2. Data Pre-Processing
3.3. Classification Features Extraction
3.3.1. Statistical-Based Features
- Mean vectorsMean vectors are a collection of the mean of the normalized sample in each signal channel and defined as:where is the mean of the EDA data for each sample, is the mean of body temperature data for each sample, is the mean of the BVP data for each sample, is the mean of heart rate data for each sample, and is the number of the data samples.
- Standard deviation vectorsThe standard deviation vectors are defined in the following (see Equation (5)):where is the standard deviation of the EDA data for each sample, is the standard deviation of body temperature data for each sample, is the standard deviation of the BVP data for each sample, is the standard deviation of heart rate data for each sample, is the number of data samples.
- Variance vectorsVariance is the average of the squared differences from the mean. It is the square of the standard deviation. In a similar manner as above, variance vectors are calculated and represented as . It can be calculated using the following (see Equation (6)):where is the standard deviation of each signal for each sample defined in Equation (5).
- Median skewness vectorsMedian skewness is also called Pearson’s second skewness coefficient. It is defined as [20]):where is the Pearson’s second skewness coefficient, is the mean of the data, is the median, and is the standard deviation of each signal in each file. This formula compares the mean to the median in a precise way and shows how many standard deviations apart they are [21]. The median skewness vectors are the collection of median skewness of each signal channel for each sample:where is the median skewness of the EDA data for each sample, is the median skewness of body temperature data for each sample, is the median skewness of the BVP data for each sample, is the median skewness of heart rate data for each sample, is the number of samples.
- Kurtosis vectorsKurtosis is an important descriptive statistic of data distribution. It describes how much the tails of a distribution differ from the tails of a normal distribution. Is is defined as the fourth central moment divided by the square of the variance [22,23]:where X is the dataset, is the kurtosis value of the normal distribution for the dataset, is the fourth central moment, is the mean (defined in Equation (4)), and is the standard deviation of each signal in each sample defined in Equation (5).The kurtosis vectors are the collection of kurtosis of each signal channel for each sample:where is the kurtosis of the EDA data for each sample, is the kurtosis of body temperature data for each sample, is the kurtosis of the BVP data for each sample, is the kurtosis of heart rate data for each sample, is the number of the samples.
3.3.2. Wavelet-Based Features
3.3.3. Higher-Order Crossings (HOC)-Based Features
3.4. Deep Learning Model
- First, load the dataset and separate the data into training and validation datasets. In this study, 80 percent of the data is used for training and 20 percent for testing. In order to protect against over fitting, cross-validation was applied. Cross-validation is 5-fold.
- Second, define the CNN architecture. For the first layer, the spatial input and output sizes of these convolutional layers are 32-by-32, and the following max pooling layer reduces this to 16-by-16. For the second layer, the spatial input and output sizes of these convolutional layers are 16-by-16, and the following max pooling layer reduces this to 8-by-8. For the next layer, the spatial input and output sizes of these convolutional layers are 8-by-8. The global average pooling layer averages over the 8-by-8 inputs, giving an output of size 1-by-1-by-4 times of initial number of filters. With a global average pooling layer, the final classification output is only sensitive to the total amount of each feature present in the input image, but insensitive to the spatial positions of the features. In the end, add the fully connected layer and the final softmax and classification layers.
- Third, specify the training options. We used Adam (adaptive moment estimation) optimizer, set the maximum number of epochs to 100, mini batch size to 128, and monitored the network accuracy during training by specifying validation data and validation frequency, shuffling the data every epoch, and plotting training progress [31].
- Fourth, train the network using the structure defined by layers, the training data, and the training options.
- Last, predict the labels of the validation data using the trained network, and calculate the final validation accuracy [31].
3.5. Optimization
Choose Variables to Optimize
- Network section depth: Network section depth is the variable which controls the depth of the network.
- Initial learning rate: Select the best initial learning rate.
- Stochastic gradient descent momentum: Momentum adds inertia so that the network can update the parameters more smoothly and reduce the noise inherent in stochastic gradient descent [36].
- regularization strength: Choose a good value of regularization to prevent overfitting issues.
3.6. Results
3.6.1. Dataset
3.6.2. Feature Selection
3.6.3. Results from the Data Classification
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BVP | Blood volume pulse |
| CNN | Convolutional Neural Network |
| EDA | Electrodermal activity |
| FV | Features vector |
| HOC | Higher order crossing |
| HR | Heart rate |
| NASA-TLX | NASA Task Load Index |
| SA | Situation awareness |
| SAGAT | Situation Awareness Global Assessment Technique |
| SFV | Statistical-base feature vector |
| SVM | Support vector machine |
| WFV | Wavelet-based feature vector |
References
- Sanfilippo, F. A multi-sensor fusion framework for improving situational awareness in demanding maritime training. Reliab. Eng. Syst. Saf. 2017, 161, 12–24. [Google Scholar] [CrossRef]
- Marchenko, N.; Andreassen, N.; Borch, O.J.; Kuznetsova, S.; Ingimundarson, V.; Jakobsen, U. Arctic shipping and risks: Emergency categories and response capacities. Transnav Int. J. Mar. Navig. Saf. Sea Transp. 2018, 12.1. [Google Scholar] [CrossRef] [Green Version]
- Grech, M.R.; Horberry, T.; Smith, A. Human error in maritime operations: Analyses of accident reports using the Leximancer tool. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting; Sage Publications Sage CA: Los Angeles, CA, USA, 2002; Volume 46, pp. 1718–1721. [Google Scholar]
- The NauticalInstitute. Situational Awareness-The Sense of Everything, Feb 2020, Issue no. 23. Available online: https://www.nautinst.org/uploads/assets/8f9da438-3486-4b77-a4d79e1af61fe15c/Issue-23-Situational-Awareness.pdf (accessed on 21 August 2020).
- Endsley, M.R. Design and evaluation for situation awareness enhancement. In Proceedings of the Human Factors Society Annual Meeting; SAGE Publications Sage CA: Los Angeles, CA, USA, 1988; Volume 32, pp. 97–101. [Google Scholar]
- Endsley, M.R.; Bolte, B.; Jones, D.G. Designing for Situation Awareness: An Approach to User-Centered Design; CRC press: Boca Raton, FL, USA, 2003; Chapter 2. [Google Scholar]
- Van den Broek, A.; Neef, R.; Hanckmann, P.; van Gosliga, S.P.; Van Halsema, D. Improving maritime situational awareness by fusing sensor information and intelligence. In Proceedings of the 14th International Conference on Information Fusion, Chicago, IL, USA, 5–8 July 2011; pp. 1–8. [Google Scholar]
- © 2019 Empatica Inc. E4 Wristband Real-Time Physiological Data Streaming and Visualization. 2020. Available online: https://www.empatica.com/en-int/research/e4/ (accessed on 30 November 2020).
- Sharek, D. A useable, online NASA-TLX tool. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting; SAGE Publications Sage CA: Los Angeles, CA, USA, 2011; Volume 55, pp. 1375–1379. [Google Scholar]
- Hart, S.G.; Staveland, L.E. Development of NASA-TLX (Task Load Index): Results of empirical and theoretical research. In Advances in Psychology; Elsevier: Amsterdam, The Netherlands, 1988; Volume 52, pp. 139–183. [Google Scholar]
- Rubio, S.; Díaz, E.; Martín, J.; Puente, J.M. Evaluation of subjective mental workload: A comparison of SWAT, NASA-TLX, and workload profile methods. Appl. Psychol. 2004, 53, 61–86. [Google Scholar] [CrossRef]
- Bustamante, E.A.; Spain, R.D. Measurement invariance of the Nasa TLX. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting; SAGE Publications Sage CA: Los Angeles, CA, USA, 2008; Volume 52, pp. 1522–1526. [Google Scholar]
- Hart, S.G. NASA-task load index (NASA-TLX); 20 years later. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting; Sage publications Sage CA: Los Angeles, CA, USA, 2006; Volume 50, pp. 904–908. [Google Scholar]
- Colligan, L.; Potts, H.W.; Finn, C.T.; Sinkin, R.A. Cognitive workload changes for nurses transitioning from a legacy system with paper documentation to a commercial electronic health record. Int. J. Med. Inf. 2015, 84, 469–476. [Google Scholar] [CrossRef] [PubMed]
- © 2019 Empatica Inc. Data Export and Formatting from E4 Connect. January 2020. Available online: https://support.empatica.com/hc/en-us/articles/201608896-Data-export-and-formatting-from-E4-connect- (accessed on 12 May 2020).
- © 2019 Empatica Inc. E4 Data-HR.csv Explanation. January 2020. Available online: https://support.empatica.com/hc/en-us/articles/360029469772-E4-data-HR-csv-explanation (accessed on 12 May 2020).
- Patel, J.K.; Read, C.B. Handbook of the Normal Distribution; Dekker, M., Ed.; International Biometric Society: New York, NY, USA, 1982. [Google Scholar]
- Bohm, G.; Zech, G. Introduction to Statistics and Data Analysis for Physicists; Desy: Hamburg, Germany, 2010; Volume 1, p. 23. [Google Scholar]
- Lane, D.M.; Scott, D.; Hebl, M.; Guerra, R.; Osherson, D.; Zimmer, H. An Introduction to Statistics; Rice University: Houston, TX, USA, 2017; pp. 261–268. [Google Scholar]
- Weisstein, E.W. Pearson’s Skewness Coefficients. From MathWorld–A Wolfram Web Resource. 23 July 2020. Available online: https://mathworld.wolfram.com/PearsonsSkewnessCoefficients.html (accessed on 28 July 2020).
- Doane, D.P.; Seward, L.E. Measuring skewness: A forgotten statistic? J. Stat. Educ. 2011, 19. [Google Scholar] [CrossRef]
- Kokoska, S.; Zwillinger, D. CRC Standard Probability and Statistics Tables and Formulae; CRC Press: Boca Raton, FL, USA, 2000. [Google Scholar]
- Pearson, K., IX. Mathematical contributions to the theory of evolution.—XIX. Second supplement to a memoir on skew variation. Philos. Trans. R. Soc. Lond. Ser. A Contain. Pap. Math. Phys. Character 1916, 216, 429–457. [Google Scholar]
- Akansu, A.N.; Haddad, P.A.; Haddad, R.A.; Haddad, P.R. Multiresolution Signal Decomposition: Transforms, Subbands, and Wavelets; Academic press: Cambridge, MA, USA, 2001. [Google Scholar]
- Daubechies, I. CBMS-NSF regional conference series in applied mathematics. Ten Lect. Wavelets 1992, 61. [Google Scholar] [CrossRef]
- Dickstein, P.; Spelt, J.; Sinclair, A. Application of a higher order crossing feature to non-destructive evaluation: A sample demonstration of sensitivity to the condition of adhesive joints. Ultrasonics 1991, 29, 355–365. [Google Scholar] [CrossRef]
- Kedem, B. Higher-order crossings in time series model identification. Technometrics 1987, 29, 193–204. [Google Scholar] [CrossRef]
- Petrantonakis, P.C.; Hadjileontiadis, L.J. Emotion recognition from EEG using higher order crossings. IEEE Trans. Inf. Technol. Biomed. 2009, 14, 186–197. [Google Scholar] [CrossRef] [PubMed]
- Kedem, B.; Yakowitz, S. Time Series Analysis by Higher Order Crossings; IEEE Press: New York, NY, USA, 1994; p. 19. [Google Scholar]
- Wu, J.; Chen, X.Y.; Zhang, H.; Xiong, L.D.; Lei, H.; Deng, S.H. Hyperparameter optimization for machine learning models based on Bayesian optimization. J. Electron. Sci. Technol. 2019, 17, 26–40. [Google Scholar]
- © 1994–2020 The MathWorks, Inc. Create Simple Deep Learning Network for Classification. 2020. Available online: https://se.mathworks.com/help/deeplearning/ug/create-simple-deep-learning-network-for-classification.html (accessed on 25 November 2020).
- Sameen, M.I.; Pradhan, B.; Lee, S. Application of convolutional neural networks featuring Bayesian optimization for landslide susceptibility assessment. Catena 2020, 186, 104249. [Google Scholar] [CrossRef]
- Pham, V. Bayesian Optimization for Hyperparameter Tuning. 2016. Available online: https://arimo.com/data-science/2016/bayesian-optimization-hyperparameter-tuning/ (accessed on 5 May 2020).
- Dewancker, I.; McCourt, M.; Clark, S. Bayesian optimization for machine learning: A practical guidebook. arXiv 2016, arXiv:1612.04858. [Google Scholar]
- Koehrsen, W. A Conceptual Explanation of Bayesian Hyperparameter Optimization for Machine Learning. 2018. Available online: https://towardsdatascience.com/a-conceptual-explanation-of-bayesian-model-based-hyperparameter-optimization-for-machine-learning-b8172278050f (accessed on 5 May 2020).
- © 1994–2020 The MathWorks, Inc. Deep Learning Using Bayesian Optimization. 2020. Available online: https://se.mathworks.com/help/deeplearning/ug/deep-learning-using-bayesian-optimization.html (accessed on 8 May 2020).
- Janecek, A.; Gansterer, W.; Demel, M.; Ecker, G. On the relationship between feature selection and classification accuracy. In New Challenges for Feature Selection in Data Mining and Knowledge Discovery; PMLR: McKees Rocks, PA, USA, 2008; pp. 90–105. [Google Scholar]
- Xue, H.; Batalden, B.M.; Røds, J.F. Development of a SAGAT Query and Simulator Experiment to Measure Situation Awareness in Maritime Navigation. In Proceedings of the International Conference on Applied Human Factors and Ergonomics, New York, NY, USA, 24–28 July 2020; Springer: Cham, Switzerland, 2020; pp. 468–474. [Google Scholar]
- Thayer, J.F.; Friedman, B.H.; Borkovec, T.D. Autonomic characteristics of generalized anxiety disorder and worry. Biol. Psychiatry 1996, 39, 255–266. [Google Scholar] [CrossRef]
- Lundberg, U.; Hellström, B. Workload and morning salivary cortisol in women. Work. Stress 2002, 16, 356–363. [Google Scholar] [CrossRef]
- Steptoe, A.; Cropley, M.; Griffith, J.; Kirschbaum, C. Job strain and anger expression predict early morning elevations in salivary cortisol. Psychosom. Med. 2000, 62, 286–292. [Google Scholar] [CrossRef] [PubMed]
- Sneddon, A.; Mearns, K.; Flin, R. Stress, fatigue, situation awareness and safety in offshore drilling crews. Saf. Sci. 2013, 56, 80–88. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. of Samples | No. of Participants | No. of Sailing Sections | Signal Channel 1 | Signal Channel 2 | Signal Channel 3 | Signal Channel 4 |
|---|---|---|---|---|---|---|
| Sample 1 | Participant 1 | Sailing section 1 | EDA data | Temp. data | BVP data | HR data |
| Sample 2 | Sailing section 2 | .. | .. | .. | .. | |
| . | Sailing section 3 | .. | .. | .. | .. | |
| . . | Sailing section 4 | .. | .. | .. | .. | |
| . . . | . . . | . . . | . . . | . . . | . . . | |
| Participant 10 | Sailing section 1 | .. | .. | .. | .. | |
| Sailing section 2 | .. | .. | .. | .. | ||
| Sample 39 | Sailing section 3 | .. | .. | .. | .. | |
| Sample 40 | Sailing section 4 | EDA data | Temp. data | BVP data | HR data |
| Name | Possible Values | Type | Transform | Optimize |
|---|---|---|---|---|
| Section Depth | [1, 3] | integer | none | 1 |
| Initial Learn Rate | [0.01, 1] | real | log | 1 |
| Momentum | [0.08, 0.98] | real | none | 1 |
| regularization | [, 0.01] | real | log | 1 |
| Feature Type | Feature Amount | Random Forest | SVM |
|---|---|---|---|
| Statistic-based features | 5 | 0.51 (+/− 0.25) | 0.54 (+/− 0.20) |
| Wavelet-based features | 18 | 0.46 (+/− 0.24) | 0.49 (+/− 0.17) |
| HOC-based features | 50 | 0.64 (+/− 0.30) | 0.58 (+/− 0.09) |
| Statistic-based + Wavelet-based features | 23 | 0.54 (+/− 0.17) | 0.53 (+/− 0.17) |
| Wavelet-based + HOC-based features | 68 | 0.57 (+/− 0.39) | 0.59 (+/− 0.06) |
| Statistic-based + HOC-based features | 55 | 0.61 (+/− 0.40) | 0.59 (+/− 0.21) |
| Statistic-based + Wavelet-based + HOC-based features | 73 | 0.62 (+/− 0.21) | 0.61 (+/− 0.09) |
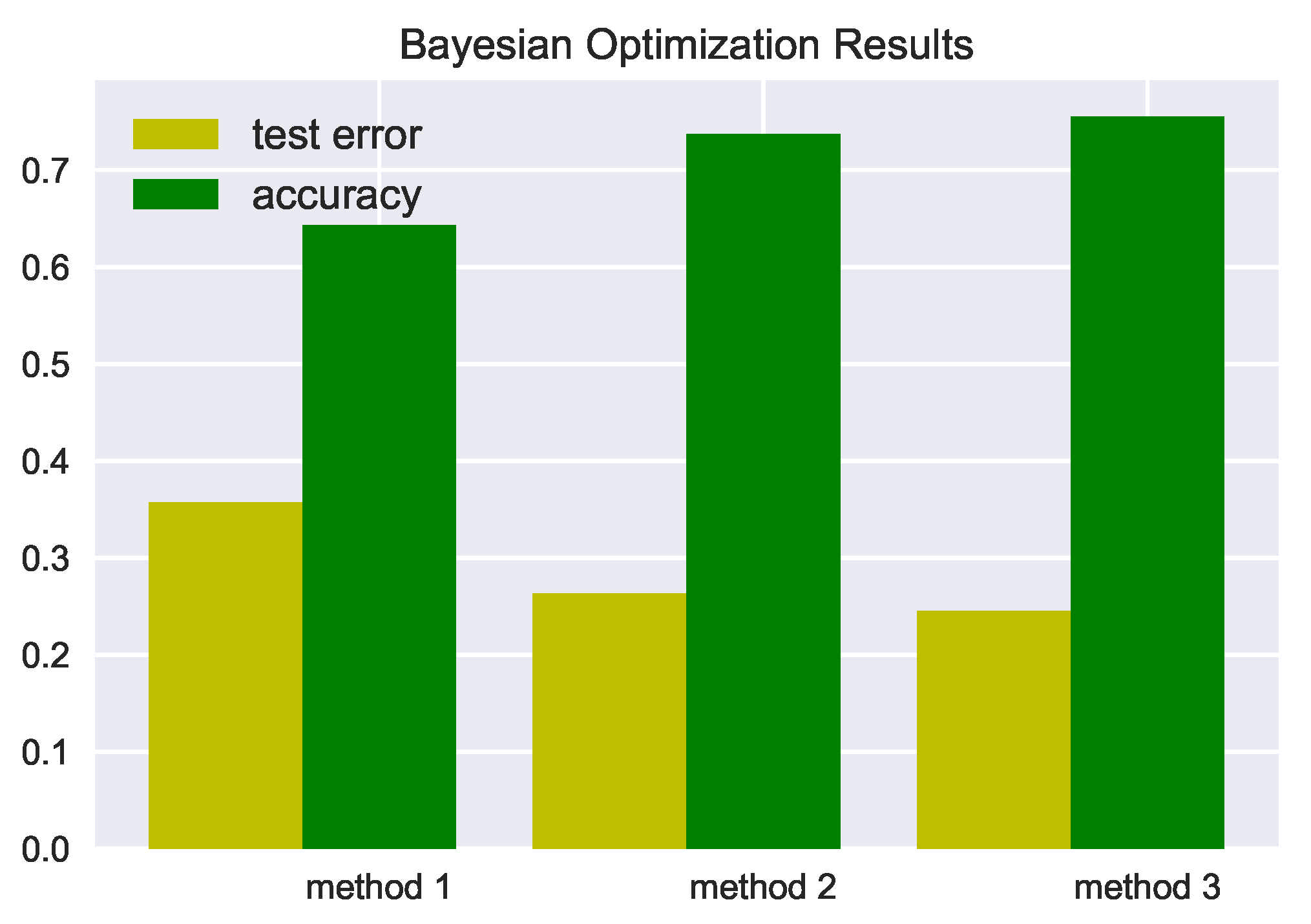
| Feature Types | Validation Error | testError | testError95CI | Accuracy | |
|---|---|---|---|---|---|
| Statistic-base + wavelet-based features (method 1) | 0.357 | 0.357 | 0.193 | 0.522 | 64.3% |
| HOC-base features (method 2) | 0.263 | 0.263 | 0.119 | 0.407 | 73.7% |
| Statistic-based + Wavelet-based + HOC-based features (method 3) | 0.245 | 0.245 | 0.101 | 0.388 | 75.5% |
| Hypothesis Number | Description | Accepted/Rejected |
|---|---|---|
| H1 | The bio-sensor data from experienced experts can be distinguished from the biosensor data from students | Accepted |
| H2 | The stress levels obtained from the bio-sensor data show a correlation to the NASA-TLX rating results | Accepted |
| H3 | Compared to the novices, the experts feel less stress during a navigation task | Accepted |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xue, H.; Batalden, B.-M.; Sharma, P.; Johansen, J.A.; Prasad, D.K. Biosignal-Based Driving Skill Classification Using Machine Learning: A Case Study of Maritime Navigation. Appl. Sci. 2021, 11, 9765. https://doi.org/10.3390/app11209765
Xue H, Batalden B-M, Sharma P, Johansen JA, Prasad DK. Biosignal-Based Driving Skill Classification Using Machine Learning: A Case Study of Maritime Navigation. Applied Sciences. 2021; 11(20):9765. https://doi.org/10.3390/app11209765
Chicago/Turabian StyleXue, Hui, Bjørn-Morten Batalden, Puneet Sharma, Jarle André Johansen, and Dilip K. Prasad. 2021. "Biosignal-Based Driving Skill Classification Using Machine Learning: A Case Study of Maritime Navigation" Applied Sciences 11, no. 20: 9765. https://doi.org/10.3390/app11209765
APA StyleXue, H., Batalden, B. -M., Sharma, P., Johansen, J. A., & Prasad, D. K. (2021). Biosignal-Based Driving Skill Classification Using Machine Learning: A Case Study of Maritime Navigation. Applied Sciences, 11(20), 9765. https://doi.org/10.3390/app11209765