1. Introduction
Wireless sensor networks (WSNs), which contain with operation-driven sensors in wireless networks, reveal a major system of wireless environments for many application systems in the modern world, such as solar systems [
1], mobile systems [
2], railway systems [
3], agricultural systems [
4], 3-D camera systems [
5], traffic systems [
6], Internet of Things (IoT) [
7], smart cities [
8], and body sensing systems [
9].
Because of their greater flexibility and efficiency over wired networks [
10,
11,
12,
13,
14], sensors are deployed, operated, and embedded widely in devices, buildings, vehicles, and other items to model, gather, sense, investigate, and exchange data; to interconnect objects; and to improve production efficiency and offer more efficient resource consumption [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14].
The sensing coverage problem is one of the fundamental issues in wireless sensor networks, which is a kind of tool used to measure the quality of service (QoS). Coverage in wireless sensor networks refers to the extent of the area to which the wireless signals are transmitted. Thus, the sensing coverage problem has attracted much research investment in recent years. For example, Kim and Choi optimized the sensing coverage by the deployment of sensing nodes using the machine learning method in radio networks in 2019 [
15]. Singh and Chen enhanced the sensing coverage by finding the sensing coverage holes using the chord-based hole covering approach in 2020 [
16]. Huang et al. addressed sensing coverage by the detection of sensing coverage using the reactive real-time control method for unmanned aerial vehicles in 2020 [
17]. Chen et al. optimized the sensing coverage using a reciprocal decision approach for unmanned aerial vehicles in 2018 [
18]. Wang et al. maximized the sensing coverage and minimized the distance of objective nodes and the sensor nodes by the deployment of nodes using a non-dominated method in 2021 [
19], and Zhou et al. targeted coverage by a routing design with minimized costs in WSN [
20]. The increase in the sensing coverage rate requires considerable investment. However, most sensing coverage studies have seldom discussed the cost limitation. Therefore, how to maximize the sensing coverage rate within the budget limitation is an important research topic, which is the subject of this work.
Research on coverage enhancing, either comprehensive coverage-enhancing studies or the k-coverage over the years, shows that sensor deployment is a very effective method. Therefore, numerous studies have used the sensor deployment strategy to optimize the coverage in WSNs [
21,
22,
23,
24,
25,
26]. For example, Nguyen and Liu aimed to optimize sensor coverage by planning the sensor deployment in mobile WSNs [
21]. Alia and Al-Ajouri investigated sensor deployment via planning of the optimal locations to place sensors to maximize the sensor coverage with consideration of cost by a harmony search approach in WSNs [
22]. Dash deployed the minimum number of sensors to achieve optimal sensor coverage under cost limitation in a transport WSN [
23]. Al-Karaki and Gawanmeh maximized the sensor coverage by planning an optimal strategy of sensor deployment in a WSN [
24]. Yu et al. focused on optimizing a decided area of sensor coverage, i.e., k-coverage, by sensor deployment planning under limited energy in a WSN [
25]. Manju et al. guaranteed a predefined range of coverage, such as Q-coverage, by the sensor deployment strategy with an energy constraint using the greedy heuristic method in a WSN [
26]. To achieve enhanced coverage by the sensor deployment approach, perfect sensor planning is necessary. However, one of the challenges is planning sensor deployment to maximize coverage if the required number of sensors is known and fixed.
For some unstructured WSN types, such as battleground monitoring and plantation administering, it is impossible to plan the sensor deployment. According to the budget limitation, the maintenance of coverage with at least a certain value must be provided in these unstructured types of WSNs. In this situation, the sensors can be randomly deployed in the decided range of coverage in WSNs. However, maximizing sensor coverage while simultaneously minimizing budget are conflicting objectives.
A mathematical optimization model for the proposed budget-limited WSN sensing coverage problem is derived to maximize the number of coverage grids in the presence of the grid concept in our work. The sensor coverage problem and the strategy of sensor deployment in WSNs are NP-Hard, which indicates it is difficult to obtain the solution within a polynomial time. Therefore, numerous studies in these fields have adopted various heuristic algorithms to solve this difficulty, such as the harmony search method [
22,
27], the greedy heuristic method [
26], GA [
28,
29], and PSO [
30].
The swarm intelligence algorithm, which belongs to the family of heuristic algorithms, is efficient and simple as shown by countless studies solving various problems that are NP-Hard in many fields. Simplified swarm optimization (SSO), which is included in the swarm intelligence algorithm, was originally developed by Yeh [
31] in 2009. The SSO algorithm has been indicated to be efficient, simple, and flexible by numerous studies for resolving different problems in various areas, such as intelligence microgrids [
32], parameter identification for solar cells [
33,
34], power generator dispatch [
35], cloud computing [
36], the task assignment problem [
37,
38], Internet of Things (IoT) [
39], supply chain networks [
40], the disassembly sequencing problem [
41], WSNs [
42], and forecasting of the stock market [
43].
In this study, a new swarm algorithm called bi-tuning SSO (bi-SSO) based on SSO is proposed. The proposed bi-SSO improves the SSO by tuning the parameter settings, which is always an important issue in all AI algorithms. The proposed Bi-SSO can also be implemented to tune the update mechanism at the same time to enhance the quality of solutions found by SSO. The proposed algorithm targets optimization of the proposed budget-limited WSN sensing coverage problem to maximize the number of coverage grids in the presence of the grid concept.
The remainder of this paper is organized as follows. The related work of the sensing coverage problem is analyzed in
Section 2.
Section 3 introduces grids and WSNs.
Section 4 presents the traditional SSO. The proposed novel bi-tuning SSO is shown in
Section 5.
Section 6 presents the numerical experiments. Conclusions and future research are discussed in
Section 7.
3. Problem Description
The coverage problem is derived from real-life applications, and it is one of the essential topics in sensor networks. The coverage problem is used to measure the quality of the sensors that are able to monitor or track in WSNs. In this section, the mathematical optimization model for the budget-limited WSN sensing coverage problem is presented to maximize the coverage in WSNs under the budget constraint to balance various characteristics in evaluating WSNs, together with the terminologies used in this study.
3.1. Grids and WSNs
The grid is often used in the geographic information system (GIS) to manage assets and outages and map the location of overhead and underground circuits [
1,
2]. The grid separates the area needed to be monitored by sensors into grids with uniformly spaced horizontal and vertical lines. Due to the convenience of use, the grid is adapted, such that the whole WSN monitor area is divided into
XUB ×
YUB sensing grids in this study, where
XUB and
YUB mean the maximum radius of the
x axis and
y axis in the grid, respectively. Each grid is a location, object, city, etc., and each sensor is also located in a grid, say (
x,
y), where
x = 0, 1, …,
XUB−1, and
y = 0, 1, …,
YUB − 1.
Let WSN(S, AREA, RADIUS, COST) be a WSN with a hybrid topology, where S = {1, 2, …, n} is a set of sensors; AREA = [0, XUB) × [0, YUB) is the area for WSN to cover, monitor, or track, etc.; RADIUS is the radius level for each sensor; and COST is the price corresponding to the RADIUS level for each sensor.
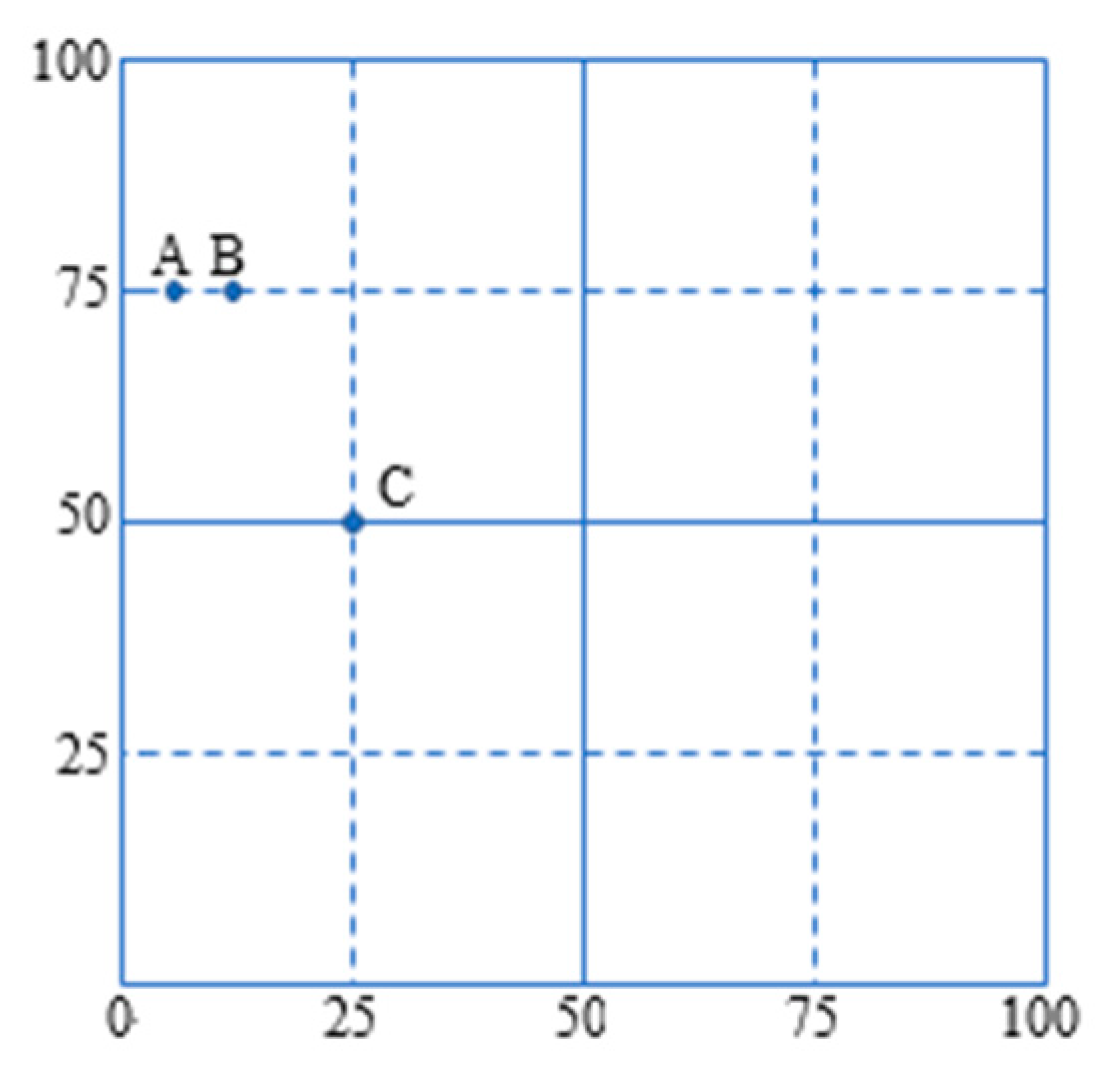
For instance, in
Figure 1, the WSN has AREA = [0, 99) × [0, 99) and three sensors are labeled at A, B, and C located at (5, 75), (12, 75), and (25, 50), respectively. The RADIUS
r(
x,
y) and COST(
r(
x,
y)) for each sensor in the WSN in
Figure 1 are provided in
Table 1. From
Table 1, the price needed for the sensor located at A to have RADIUS 10 is 4 units of cost., i.e.,
r(5, 75) = 10 and COST(
r(5, 75)) = 4.
3.2. Effective Covered Grids and COST
Let |●| be the number of elements in ● and the sensing radius of the sensor located at (
x,
y) be
r(
x,
y). In WSN(
S, AREA, RADIUS, COST), the effectively covered grids ECG of the sensor in
S located at (
x,
y) ϵ AREA is the set of grids inside the circle under radius
r(
x,
y), i.e.,
where CIRCLE(
r(
x,
y)) is the circle with center (
x,
y) and radius and
r(
x,
y).
For example, in
Figure 1, assume the sensor A located at (5, 75) is with
r(A) =
r(5, 75) = 10, and 255 grids are inside the circle under radius 10, i.e., the number of grids in {
p | grid
p is inside in (the circle with center and radius (5, 75) and
r(5, 75)) } is 255. However, the area we are interested in is only in AREA = [0, 99) × [0, 99). Hence, these grids that are out of these range should be removed, i.e., (−1, 75), (−2, 75), (−3, 75), (−4, 75), (−5, 75), …., and 50 grids are removed because of this and only |ECG(
r(5, 75) = 10)| = 255 grids are left.
The total ECG of a whole WSN is calculated based on Equation (1) after removing these grids outside AREA or in the intersection ranges of sensors as follows:
The total grids coved by all sensors is:
For example, |ECG(
r(A) = 10)| = 255 as shown before, |ECG(
r(B) = 8)| = 193, and |ECG(
r(C) = 5)| = 69. There are 124 grids in ECG(
r(A) = 10) ∩ ECG(
r(B) = 8) and ECG(
r(A) = 10) ∩ ECG(
r(C) = 5) = ECG(
r(B) = 8) ∩ ECG(
r(C) = 5) = ∅, where sensors A, B, and C are located at (5, 75), (12, 75), and (25, 50), respectively. We have:
Moreover, from COST in WSN(
S, AREA, RADIUS, COST), if the cost of the sensor located in (
x,
y) with radius
r(
x,
y) is COST(
r(
x,
y)), the total cost to have the above deploy plan for all sensors in
S is:
For the same example in
Figure 1, based on
Table 1, the cost to have
r(A) = 10, (B) = 8, and
r(C) = 5 is COST(
r(A) = 10) = 4, COST(
r(B) = 8) =3, and COST(
r(C) = 5) =5. The total cost to achieve this is:
3.3. Proposed Mathematical Model
It is assumed that WSN(S, AREA, RADIUS, COST) are the WSN we considered, where the location, the levels of radius, and the prices of each radius level are all provided in S, RADIUS, and COST for each sensor, respectively. The proposed budget-limited WSN sensing coverage problem needs to determine the radius level for each sensor to have the maximal effective covered grids of the whole WSN under a limited budget to improve the WSN service quality.
A mathematical model for the problem is presented below:
The objective function in Equation (7) maximizes the number of grids covered by sensors. The only constraint of Equation (8) is the budget-limited total cost of the sensors. Note that, if without Equation (8), each sensor can be set to its maximum radius level, i.e., it is impractical.
The proposed budget0-limited WSN sensing coverage problem is one of the variants of the knapsack problem. Hence, the proposed problem is also an NP-Hard problem, and it is impossible to be solved in polynomial time [
22,
23]. It is always necessary to have an efficient algorithm to solve the important and practical sensor problem. This study thus proposes a new algorithm based on SSO to overcome the NP-Hard obstacles to improve the SSO to enhance the obtained WSN service quality.
5. Results
Proposed by Yeh in 2009 [
31], the simplified swarm optimization (SSO) is said to be the simplest of all machine learning methods [
13,
14,
21,
22]. The SSO was initially called the discrete PSO (DPSO) to tackle the shortcomings of the PSO in discrete problems and is appealing due to its smooth and straightforward implementation, a fast convergence rate, and fewer parameters to tune, which has been shown by numerous related works of SSO, such as optimization of the vehicle routing in a supply chain [
47], solving of reliability redundancy allocation problems [
48,
49], optimization of related problems in wireless sensor networks [
42,
50], resolving of redundancy allocation problems considering uncertainty [
39,
51], optimization of the capacitated facility location problems [
52], improvement of the update mechanism of SSO [
53], recognition of lesions in medical images [
54], resolving of service in a traffic network [
55], and optimization of numerous types of network research [
56,
57,
58,
59,
60,
61,
62,
63].
As a population-based stochastic optimization technique, the SSO belongs to the category of swarm intelligence methods with leaders to follow. The SSO is also an evolutionary computational method used to update the solution from generation to generation.
Moreover, SSO is a very influential tool in data mining for certain datasets [
13,
14,
21] and is therefore implemented to solve the proposed budget-limited WSN sensing coverage problem.
5.1. Parameters
Each AI algorithm has its parameters in its update mechanism and/or the selection procedure, e.g., crossover rate cx and mutation rate cm in GA, c1 and c2 in PSO, and Cg, Cp, and Cw in the SSO, etc.
It is assumed that Xi, Pi, and PgBest are the ith solution, the best ith solution in its evolutionary history, and the best solution among all solutions, respectively. Let xi,j, pi,j, and pgBest,j be the jth variable of Xi, Pi, and PgBest, respectively. SSO is the adapted all-variable update, i.e., all variables need to be updated, such that xi,j is obtained from either pgBest,j, pi,j, xi,j, and a random generated feasible value x with probabilities cg, cp, cw, and cr, respectively.
Because cg + cp + cw + cr = 1, there are three parameters to tune in SSO: Cg = cg, Cp = Cg + cp, and Cw = Cp + cw. Additionally, in the proposed algorithm, cg = 0.5, cp = 0.95, and cw = 0.95.
5.2. Update Mechanism
Hence, the update procedure of each variable can be presented as a stepwise-function:
where ρ
[0,1] is a random number generated within [0,1] consistently.
From Equation (9), the update in SSO is simple to code, runs efficiently, and flexible amd made-to-fit [
20,
23,
24,
25,
26,
27,
28,
46]. Each AI algorithm has its own update mechanism, e.g., crossover and mutation in GA, vectorized update mechanism in PSO, etc. The stepwise update function is a unique update mechanism of SSO [
23,
24,
37,
38,
39,
40,
41,
42]. All SSO variants are based on their made-to-fit stepwise function to update solutions.
The stepwise-function update mechanism shown in Equation (9) is powerful, straightforward, and efficient with proven success, as evidenced through successful applications, e.g., the redundancy allocation problem [
37,
38], disassembly sequencing problem [
39,
40], artificial neural network [
41], energy problems [
42], etc. Moreover, the stepwise-function update mechanism allows for greater ease of customization to made-to-fit by replacing any item of its stepwise function with other algorithms [
38,
41], even hybrid algorithms [
43] applied in sequence or parallel [
41], to address different problems as opposed to tedious customization of other algorithms [
23,
24,
37,
38,
39,
40,
41,
42,
43].
5.3. Pseudocode, Flowchart, and Example
The SSO is very easy to code using any computer language and its pseudocode is provided below [
17,
18,
35,
36,
37,
38,
39]:
- STEP S0.
Generate Pi = Xi randomly, calculate F(Pi) = F(Xi), find gBest, and let t = 1 and k = 1 for i = 1, 2, …, Nsol.
- STEP S1.
Update Xk based on Equation (9).
- STEP S2.
If F(Xk) > F(Pk), let Pk = Xk. Otherwise, go to STEP S5.
- STEP S3.
If F(Pk) > F(PgBest), let gBest = k.
- STEP S4.
If k < Nsol, let k = k + 1 and go to STEP S1.
- STEP S5.
If t < Ngen, let t = t + 1, k = 1, and go to STEP S1. Otherwise, halt.
The flowchart of the above pseudocode is given in
Figure 2:
STEP S0 initializes all solutions randomly because the SSO is a population-based algorithm. STEP S1 implements the SSO stepwise function shown in Equation (9) to update the solution. STEPs S2 and S3 test whether
Pk is replaced with
Xk and
PgBest is replaced with
Pk, respectively. STEP S5 is the stopping criteria, which is the number of generations. Note that the stopping criteria are changed to the runtime in this study and the details are discussed in
Section 4.
For example, let
Cg = 0.4,
Cp = 0.7,
Cw = 0.9, and ρ = (ρ
1, ρ
2, ρ
3, ρ
4, ρ
5) = (0.53, 0.78, 0.16, 0.97, 0.32). Assume that we have the solution in the second generation, i.e.,
X15 = (4, 3, 2, 1, 4),
P15 = (1, 4, 2, 3, 2), and
PgBest = (1, 4, 2, 3, 2), which are the 15 solutions in the second generation of the evolutionary, the best 15 solutions before the second generation, and the best solution before the second generation, respectively. Now, we are going to update
X15 to obtain the new
X15 of the third generation, which is presented in
Table 2, based on the stepwise function of the SSO update mechanism provided in Equation (9).
From the above pseudocode, flowchart, and example, we can find that the update mechanism of the SSO is simple, convenient, and efficient.
5.4. Fitness Function and Penalty Fitness Function
The fitness function F(X) guides solution X towards optimization, which, in turn, will attain goals in artificial intelligence, such as the SSO, GA, and PSO. All suitable fitness functions vary, depending on the optimization problem defined by the corresponding application. In this study, Equation (7) is adopted here to represent the fitness function, which is to be maximized in the proposed problem. For example, without considering the budget limit, F(X5) = 393, as discussed in Equation (4) for X5 = (4, 3, 4).
The penalty fitness function FP(X) helps deal with these problems without too many constraints and it is not easy to generate feasible solutions that satisfy the constraints, e.g., Equation (5). Penalty functions can force these infeasible solutions near the feasible boundary back to the feasible region by adding or subtracting larger positive values to the fitness for the maximum or minimum problems, respectively.
If the larger positive value is not large enough, the final solution may be not feasible. Hence, a novel self-adaptive penalty function based on the budget and the deploy plan is provided below:
where:
For example, let COST
UB = 10 in
Figure 1. The total cost for the fifth solution
X5 = (4, 3, 4) is COST(
X5) = COST(4, 3, 4) = 12 from Equation (6). Because COST(
X5) =12 > 10, we have:
The penalty fitness function of
X5 is:
Here, the penalty fitness function is that the fitness function subtracts the penalty if the cost is over the COSTUB.
5.5. The Bi-Tuning Method
All machine learning algorithms have their parameters in each update procedure and/or the selection procedure. Thus, there is a need to tune parameters for better results. In the SSO, there are already two main concerns regarding the improvement of the solution quality by either focusing on the parameter-tuning to tune parameters or paying attention to the item-tuning to remove an item from Equation (9), e.g., Equations (12) and (13) remove the second and the third items from Equation (9). However, none of them can deal with the above two processes, i.e., the parameter-tuning and the item-tuning, at the same time:
Hence, a new bi-tuning method is provided to achieve the above goal to determine the best parameters Cp, Cp, and Cw together with the best solution to answer whether any item in Equation (9) should be removed to obtain a better result.
Seven different settings are adapted and named as SSO1–SSO7 as shown in
Table 3.
If
Cg =
Cp in SSO2, SSO3, and SSO5 or
Cp =
Cw in SSO4, SSO6, and SSO7, the items 2 or 3 are redundant, i.e.,
Pi is never used as in Equation (12) and
xi,j must be replaced with a value as shown in Equation (13), respectively, from
Table 3.
Additionally, SSO2 and SSO4 are used to test whether having a larger value of cr = 1 − Cw is useful in improving the efficiency and solution quality. Similarly, SSO5 and SSO7 are applied to determine whether having a larger value of cg = Cg improves the efficiency and solution quality.
5.6. Pseudocode of Bi-Tuning SSO
The bi-tuning SSO is a new SSO and can be used to tune both the parameters, i.e., Cg, Cp, and Cw, and update the mechanism in the traditional SSO efficiently and easily. The pseudocode of the proposed bi-tuning SSO is designated for the budget-limited WSN sensing coverage problem by the following procedures:
- STEP 0.
Let i = 1.
- STEP 1.
The parameters of SSO
i are listed in
Table 3 and let the best solution be
Gi.
- STEP 2.
If i < 8, go to STEP 1.
- STEP 3.
The best one among G1, G2, …, and G7, is the one we need.
It is always a very critical task to determine the time complexity of any algorithms and the time complexity is always based on the worst time complexity, i.e., the O-notation. Additionally, the time complexity of the fitness calculation depends on the problems and was ignored in some studies. Hence, due to the simplicity of the SSO, the computational complexity of the proposed bi-tuning SSO is determined mainly by the update mechanism.
The proposed bi-tuning SSO implementing the all-variable update mechanism needs to be run N
var times for each solution in each generation. Hence, the time complexity of the proposed bi-tuning SSO is
O(7 × N
gen × N
sol × N
var). Furthermore, the practical performance of the proposed bi-tuning SSO was tested for nine problems, as described in
Section 5.
6. Numerical Experiments
To demonstrate the performance of the proposed bi-tuning SSO, three numerical experiments with three different values of N
var = 20, 100, and 300 were implemented based on the bi-tuning method mentioned in
Section 5.3. Similar published literature to this work could not be found so the experimental results of the bi-tuning SSO could not be compared with any other published contribution. However, the experimental results of the bi-tuning SSO were compared with the state-of-the-art algorithms PSO, GA, and SSO, which are listed as SSO1 in
Table 3.
6.1. Parameters and Experimental Environment Settings
The performance of each AI algorithm is always affected by the parameter setting and experimental environment setting. The parameter settings for both GA and PSO are listed below:
The crossover rate cx = 0.7, the mutation rate cm = 0.3, and elite selection.
c1 = c2 =2.0, w = 0.95, the lower and upper bounds of velocities VLB = −2 and VUB = 2, the lower and upper bounds of positions XLB = 1 and XUB = the maximum radius.
Nine algorithms were tested, i.e., the bi-tuning SSO included seven SSO variants based on
Table 3, GA, and PSO. To perform a fair performance evaluation of all algorithms, each algorithm was run 30 times, i.e., N
run = 30, with N
sol = 100, and the stopping criteria were based on the run time, which was defined as Nvar/10 s.
All algorithms were tested on three datasets, where the coordinate of X has a uniform distribution: 0 ~ (square of the number of vertices/32767)/(the number of vertices) and the coordinate of Y has a uniform distribution: 0 ~ (square of the number of vertices/32767)-the coordinate of X*(the number of vertices). Without loss of generality, each dataset has 1000 data of which the ith data in the dataset is a 2-tuple vector (x, y) representing the location of the ith sensor and it was generated randomly within [0,99] × [0,99] based on the grid concept. To verify the capacity of the proposed bi-tuning SSO, each dataset was separated into sub datasets based on the number of sensors Nvar = 20, 100, and 300 by choosing the first Nvar data to denote small-sized, middle-sized, and larger-sized problems.
All nine algorithms including the proposed bi-tuning SSO were coded in DEV C++ on a 64-bit Windows 10 PC, implemented on an Intel Core i7-6650U CPU @ 2.20 GHz notebook with 16 GB of memory.
6.2. Analysis of Results
The descriptive statistics including the maximum (denoted by MAX), i.e., the best solution, minimum (denoted by MIN), average (denoted by AVG), and standard deviation (denoted by STD) of the run time (denoted by T, in seconds), fitness function value (denoted by F), number of generations to obtain the optimal solution (denoted by Best), how many generations were run during the provided time (denoted by Ngen), and total cost (denoted by Cost) were employed for the nine algorithms including GA, PSO, and the proposed bi-tuning SSO including seven SSO variates (denoted by SSO1 to SSO7) and the best solutions compared among the nine algorithms are shown in bold. Hence, the following
Table 4,
Table 5 and
Table 6 indicate the experimental results obtained by all algorithms for the first dataset to the third dataset of the small-sized problem,
Table 7,
Table 8 and
Table 9 indicate the experimental results obtained by all algorithms for the first dataset to the third dataset of the middle-sized problem, and
Table 10,
Table 11 and
Table 12 indicate the experimental results obtained by all algorithms for the first dataset to the third dataset of the larger-sized problem.
For a more abundant and detailed analysis of the experimental results, the statistical boxplots of the displayed images were adopted to show the performance including the maximum, interquartile range (75th percentile, median, and 25th percentile), and minimum and are shown in
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8.
Figure 3 and
Figure 4 indicate the sensor coverage (fitness function value) and run time for all algorithms for the small-sized problem,
Figure 5 and
Figure 6 indicate the sensor coverage (fitness function value) and run time for all algorithms for the middle-sized problem, and
Figure 7 and
Figure 8 indicate the sensor coverage (fitness function value) and run time for all algorithms for the larger-sized problem, respectively.
Here, for the small-sized problem, the experimental results in terms of the fitness function of sensor coverage (F), the run time (T), the number of generations to obtain the optimal solution (Best), how many generations were run during the provided time (Ngen), and total cost (Cost) obtained by the GA, PSO, and the proposed bi-tuning SSO (SSO1–SSO7) are shown in
Table 4,
Table 5 and
Table 6 and
Figure 3 and
Figure 4 and were analyzed as follows:
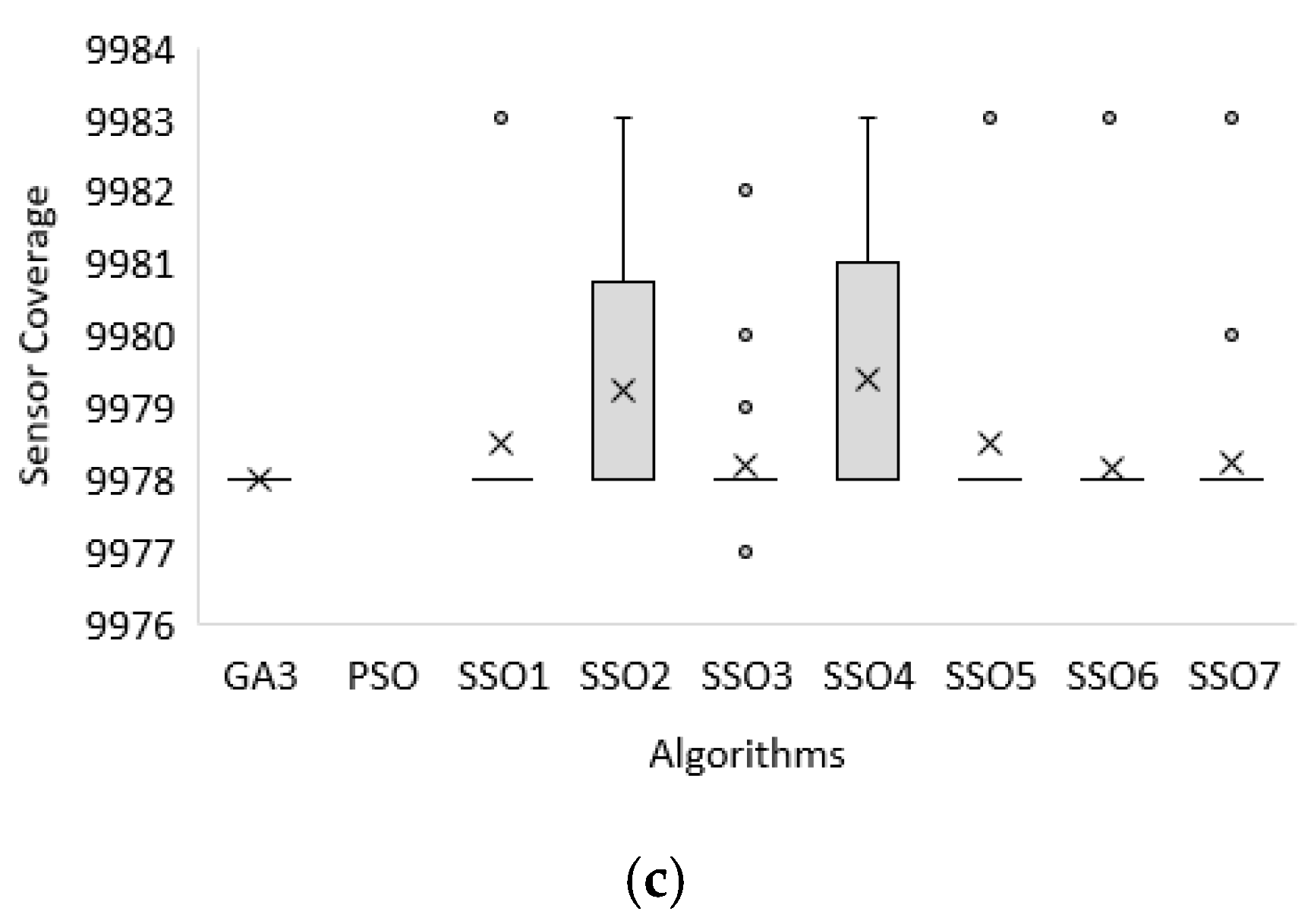
For the fitness function value (F):
The best solution (MAX) of the fitness function value (F) obtained by SSO1-SSO6 is
9983, which is the best among all algorithms for the first dataset of the small-sized problem as shown in
Table 4 and
Figure 3a.
The best solution (MAX) of the fitness function value (F) obtained by GA is
9989, which is the best among all algorithms for the second dataset of the small-sized problem as shown in
Table 5 and
Figure 3b.
The best solution (MAX) of the fitness function value (F) obtained by SSO1-2 and SSO4-7 is
9983, which is the best among all algorithms for the third dataset of the small-sized problem as shown in
Table 6 and
Figure 3c.
The average (AVG) of the fitness function value (F) was obtained by SSO4, GA. The AVG values in each database are
9979.83333,
9981.4, and
9979.36667, which are the best among all algorithms for the first dataset to the third dataset of the small-sized problem, respectively, as shown in
Table 4,
Table 5 and
Table 6.
The minimum (MIN) fitness function value (F) obtained by GA, SSO1-5, and SSO7 is
9978, which is the best among all algorithms for the first dataset of the small-sized problem, as shown in
Table 4.
The minimum (MIN) fitness function value (F) obtained by GA, SSO1-2, and SSO4-7 is
9978, which is the best among all algorithms for the second dataset to the third dataset of the small-sized problem, as shown in
Table 5 and
Table 6.
The standard deviation (STD) values of the fitness function value (F) obtained by GA, SSO3, and GA are
0,
1.055364, and
0, which are the best among all algorithms for the first dataset to the third dataset of the small-sized problem, respectively, as shown in
Table 4,
Table 5 and
Table 6.
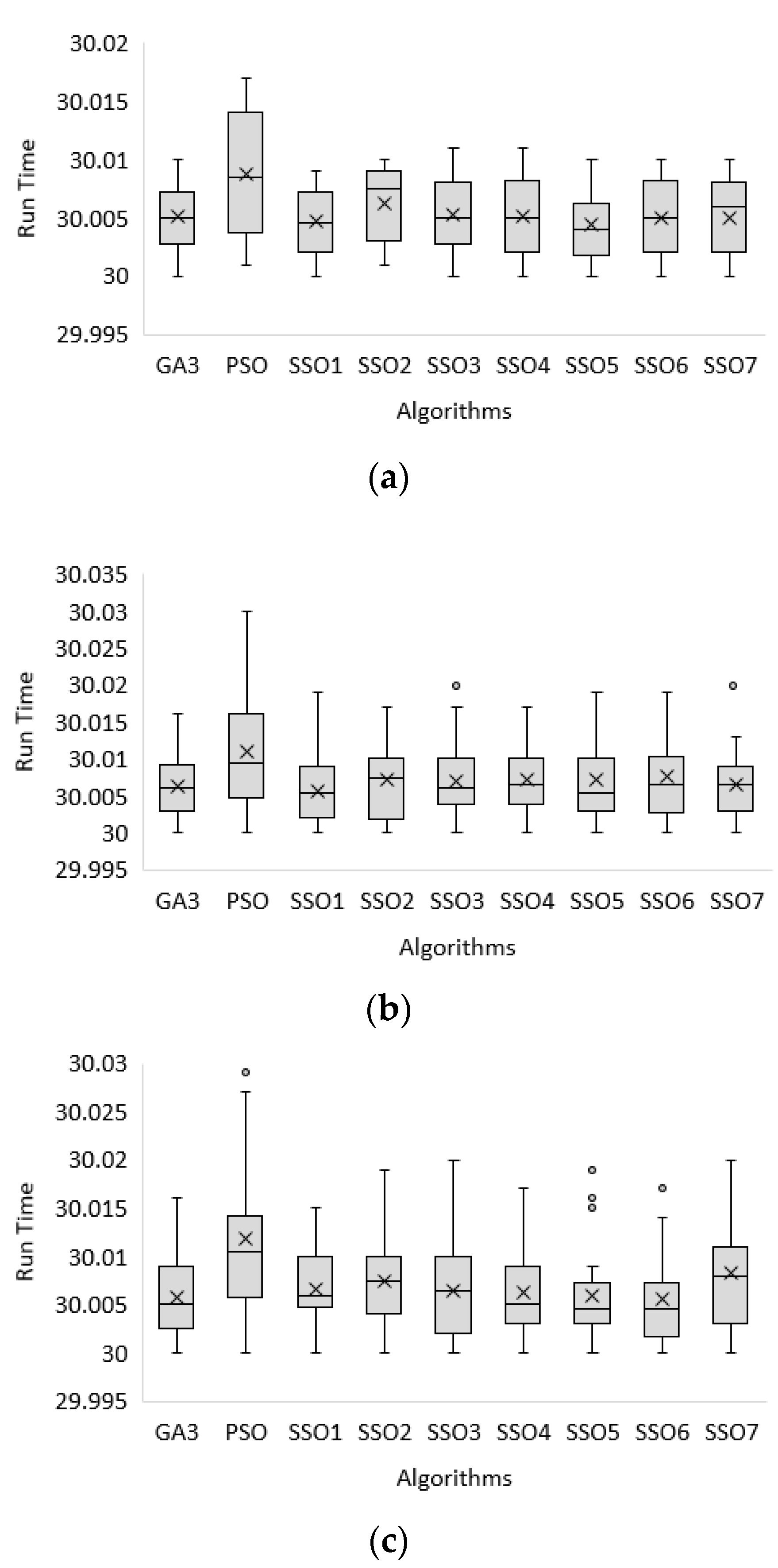
For the run time (T):
The best solution (MAX), average (AVG), and minimum (MIN) run time (T) obtained by all 9 algorithms is around 30 s for the first dataset to the third dataset of the small-sized problem, respectively, as shown in
Table 4,
Table 5 and
Table 6.
If it is compared more accurately, the best solution (MAX) for the run time (T) obtained by PSO shows the worst performance because it has the longest time for the first dataset to the third dataset of the small-sized problem, respectively, as shown in
Table 4,
Table 5 and
Table 6 and
Figure 4.
For the number of generations obtains the optimal solution (Best):
The average (AVG) number of generations to obtain the optimal solution (Best) obtained by PSO is around 1 for the first dataset to the third dataset of the small-sized problem, respectively, as shown in
Table 4,
Table 5 and
Table 6. In the same run time, the PSO converges faster but the solution is not better, which indicates it is trapped in the local solution and cannot escape.
For how many generations were run during the provided time (Ngen):
For the total cost (Cost):
The best solution (MAX) values of the total cost (Cost) obtained by PSO are
2197,
2182, and
2200, which exceed the cost limit of 2000 for the first dataset to the third dataset of the small-sized problem, respectively, as shown in
Table 4,
Table 5 and
Table 6.
The total cost obtained by GA and the proposed SSO1–SSO7 comply with the cost limit of 2000 for the first dataset to the third dataset of the small-sized problem, respectively, as shown in
Table 4,
Table 5 and
Table 6.
Secondly, for the middle-sized problem, the experimental results in terms of the fitness function value (F), the run time (T), the number of generations to obtain the optimal solution (Best), how many generations were run during the provided time (Ngen), and total cost (Cost) obtained by the GA, PSO, and the proposed bi-tuning SSO (SSO1–SSO7) are shown in
Table 7,
Table 8 and
Table 9 and
Figure 5 and
Figure 6 and were analyzed as follows:
For the fitness function value (F):
The best solution (MAX) of the fitness function value (F) obtained by SSO1–SSO7 is
9983, which is the best among all algorithms for the first dataset of the middle-sized problem as shown in
Table 7 and
Figure 5a.
The best solution (MAX) of the fitness function value (F) obtained by GA and SSO1–SSO7 is
9983, which is the best among all algorithms for the second dataset to the third dataset of the middle-sized problem as shown in
Table 8 and
Table 9 and
Figure 5b,c.
The average (AVG) fitness function values (F) obtained by SSO2, SSO4, and SSO4 are
9979.767,
9979.9, and
9980.633, which are the best among all algorithms for the first dataset to the third dataset of the middle-sized problem, respectively, as shown in
Table 7,
Table 8 and
Table 9.
The minimum (MIN) fitness function value (F) obtained by GA, SSO1–7 is
9978, which is the best among all algorithms for the first dataset of the middle-sized problem, as shown in
Table 7.
The minimum (MIN) fitness function value (F) obtained by GA, SSO1-2, SSO4, and SSO6-7 is
9978, which is the best among all algorithms for the second dataset of the middle-sized problem, as shown in
Table 8.
The minimum (MIN) fitness function value (F) obtained by GA and SSO1-5 is
9978, which is the best among all algorithms for the third dataset of the middle-sized problem, as shown in
Table 9.
The standard deviation (STD) values of the fitness function value (F) obtained by GA, GA, and SSO3 are
0,
0.912871, and
1.302517, which are the best among all algorithms for the first dataset to the third dataset of the middle-sized problem, respectively, as shown in
Table 7,
Table 8 and
Table 9.
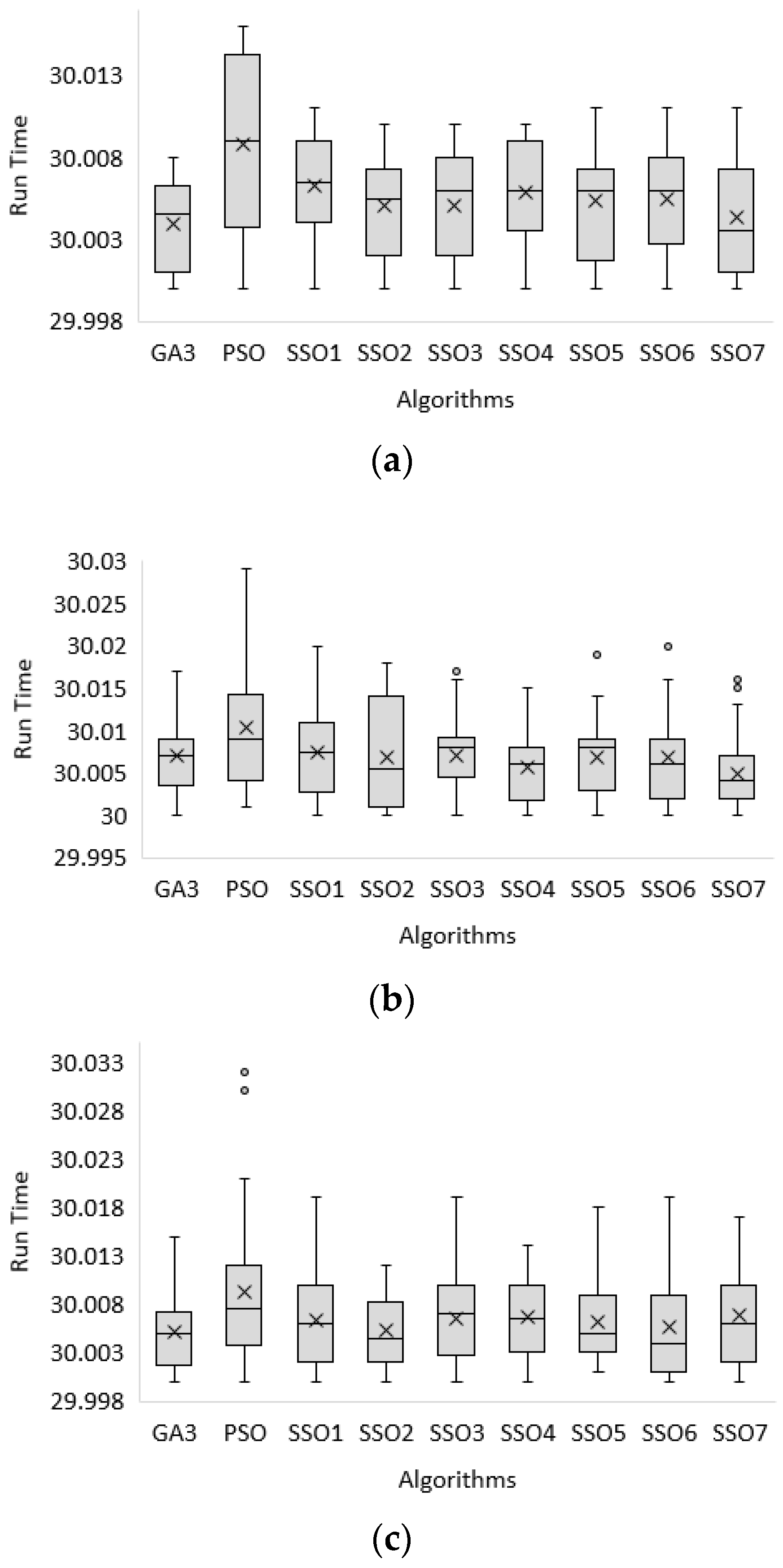
For the run time (T):
The best solution (MAX), average (AVG), and minimum (MIN) for the run time (T) obtained by all 9 algorithms are around 30 s for the first dataset to the third dataset of the middle-sized problem, respectively, as shown in
Table 7,
Table 8 and
Table 9.
If it is compared more accurately, the best solution (MAX) for the run time (T) obtained by PSO shows the worst performance because it has the longest time for the first dataset to the third dataset of the middle-sized problem, respectively, as shown in
Table 7,
Table 8 and
Table 9 and
Figure 6.
For the number of generations to obtain the optimal solution (Best):
The average (AVG) number of generations to obtain the optimal solution (Best) obtained by PSO is around 1 for the first dataset to the third dataset of the middle-sized problem, respectively, as shown in
Table 7,
Table 8 and
Table 9. In the same run time, the PSO converges faster but the solution is not better, which indicates it is trapped in the local solution and cannot escape.
For how many generations were run during the provided time (Ngen):
For the total cost (Cost):
The best solution (MAX) values of the total cost (Cost) obtained by PSO are
2165,
2189, and
2172, which exceed the cost limit of 2000 for the first dataset to the third dataset of the middle-sized problem, respectively, as shown in
Table 7,
Table 8 and
Table 9.
The total cost obtained by GA and the proposed SSO1–SSO7 comply with the cost limit of 2000 for the first dataset to the third dataset of the middle-sized problem, respectively, as shown in
Table 7,
Table 8 and
Table 9.
Finally, for the larger-sized problem, the experimental results in terms of the fitness function value (F), the run time (T), the number of generations to obtain the optimal solution (Best), how many generations were run during the provided time (Ngen), and total cost (Cost) obtained by the GA, PSO, and the proposed bi-tuning SSO (SSO1–SSO7) are shown in
Table 10,
Table 11 and
Table 12 and
Figure 7 and
Figure 8 and were analyzed as follows:
For the fitness function value (F):
The best solution (MAX) of the fitness function value (F) obtained by SSO1–SSO7 is
9983, which is the best among all algorithms for the first dataset of the larger-sized problem as shown in
Table 10 and
Figure 7a.
The best solution (MAX) of the fitness function value (F) obtained by GA and SSO1–SSO7 is
9983, which is the best among all algorithms for the second dataset of the larger-sized problem as shown in
Table 11 and
Figure 7b.
The best solution (MAX) of the fitness function value (F) obtained by SSO2-SSO7 is
9983, which is the best among all algorithms for the third dataset of the larger-sized problem as shown in
Table 12 and
Figure 7c.
The average (AVG) fitness function values (F) obtained by SSO4, SSO4, and SSO2 are
9980.6,
9980.233, and
9980.1, which are the best among all algorithms for the first dataset to the third dataset of the larger-sized problem, respectively, as shown in
Table 10,
Table 11 and
Table 12.
The minimum (MIN) fitness function value (F) obtained by GA and SSO1-7 is
9978, which is the best among all algorithms for the first dataset and the third dataset of the larger-sized problem, as shown in
Table 10 and
Table 12.
The minimum (MIN) fitness function value (F) obtained by GA and SSO1-6 is
9978, which is the best among all algorithms for the second dataset of the larger-sized problem, as shown in
Table 11.
The standard deviation (STD) values of the fitness function value (F) obtained by GA, SSO5, and GA are
0.915386,
1.159171, and
0, which are the best among all algorithms for the first dataset to the third dataset of the larger-sized problem, respectively, as shown in
Table 10,
Table 11 and
Table 12.
For the run time (T):
The best solution (MAX), average (AVG), and minimum (MIN) of the run time (T) obtained by all 9 algorithms are around 30 s for the first dataset to the third dataset of the larger-sized problem, respectively, as shown in
Table 10,
Table 11 and
Table 12.
If it is compared more accurately, the best solution (MAX) of the run time (T) obtained by PSO shows the worst performance because it has the longest time for the first dataset to the third dataset of the larger-sized problem, respectively, as shown in
Table 10,
Table 11 and
Table 12 and
Figure 8.
For the number of generations to obtain the optimal solution (Best):
The average (AVG) number of generations to obtain the optimal solution (Best) obtained by PSO is around 1 for the first dataset to the third dataset of the larger-sized problem, respectively, as shown in
Table 10,
Table 11 and
Table 12. In the same run time, the PSO converges faster but the solution is not better, which indicates it is trapped in the local solution and cannot escape.
For how many generations were run during the provided time (Ngen):
For the total cost (Cost):
The best solution (MAX) values of the total cost (Cost) obtained by PSO are
2196,
2187, and
2191, which exceed the cost limit 2000 for the first dataset to the third dataset of the larger-sized problem, respectively, as shown in
Table 10,
Table 11 and
Table 12.
The total cost obtained by GA and the proposed SSO1–SSO7 comply with the cost limit of 2000 for the first dataset to the third dataset of the larger-sized problem, respectively, as shown in
Table 10,
Table 11 and
Table 12.
Therefore, a more streamlined summary from the above analysis is shown as follows.
For the small-sized problem, the experimental results obtained by the proposed bi-tuning SSO outperform those found by PSO, GA, and SSO in terms of the fitness function of the sensor coverage (F) for the first dataset and the third dataset and comply with the cost limit of 2000 for the first dataset to the third dataset.
For the middle-sized problem and larger-sized problem, the experimental results obtained by the proposed bi-tuning SSO outperform those found by PSO, GA, and SSO in terms of the fitness function of the sensor coverage (F) for the first dataset to the third dataset and comply with the cost limit of 2000 for the first dataset to the third dataset.
Thus, the experimental results obtained by the proposed bi-tuning SSO achieve an excellent performance in terms of the fitness function of the sensor coverage (F) and comply with the cost limit of 2000 for all size problems including the small-sized, middle-sized, and larger-sized problems.
7. Conclusions
The WSN reveals a major system of wireless environments for many application systems in the modern world. In this study, a budget-limited WSN sensing coverage problem was considered. To enhance the QoS in WSN, the objective of the budget-limited WSN sensing coverage problem is to maximize the number of sensor coverage grids under the assumption that the number of sensors, the coverage radius level, the related cost of each sensor, and the budget limit are known.
This paper presented a new multi-objective swarm algorithm called the bi-tuning SSO including seven SSO variants (SSO1–SSO7) to optimize the solution of the studied problem in this paper. The proposed bi-tuning SSO was found to improve the SSO by tuning the parameter settings, which is always an important issue in all AI algorithms.
A comparative experiment of the effectiveness and performance of the proposed bi-tuning SSO algorithm was performed and compared to state-of-the-art algorithms including PSO and GA on three datasets with different settings of Nvar = 20, 100, and 300, representing the scale of small, middle, and larger WSNs. The optimization solution obtained by all considered algorithms indicated the proposed bi-tuning SSO performs better than the compared algorithms from the best, the worst, the average, and standard deviation for the fitness function values obtained in all cases in this study. Given these outcomes, the proposed bi-tuning SSO should be extended, with future studies applying it to multi-class datasets with more attributes, classes, and instances.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}