
Fast Drivable Areas Estimation with Multi-Task Learning for Real-Time Autonomous Driving Assistant


Abstract
:1. Introduction
- Drivable area estimation, lane line segmentation, and scene classification are integrated into one end-to-end framework;
- The proposed method can perform multi-task inference in real-time by utilizing shared representation efficiently;
- We demonstrated the effectiveness of the proposed method on the public BDD dataset.
2. Related Work
2.1. Drivable Area Estimation
2.2. Lane Line Segmentation
2.3. Scene Classification
2.4. Multi-Task Learning for Intelligent Vehicle
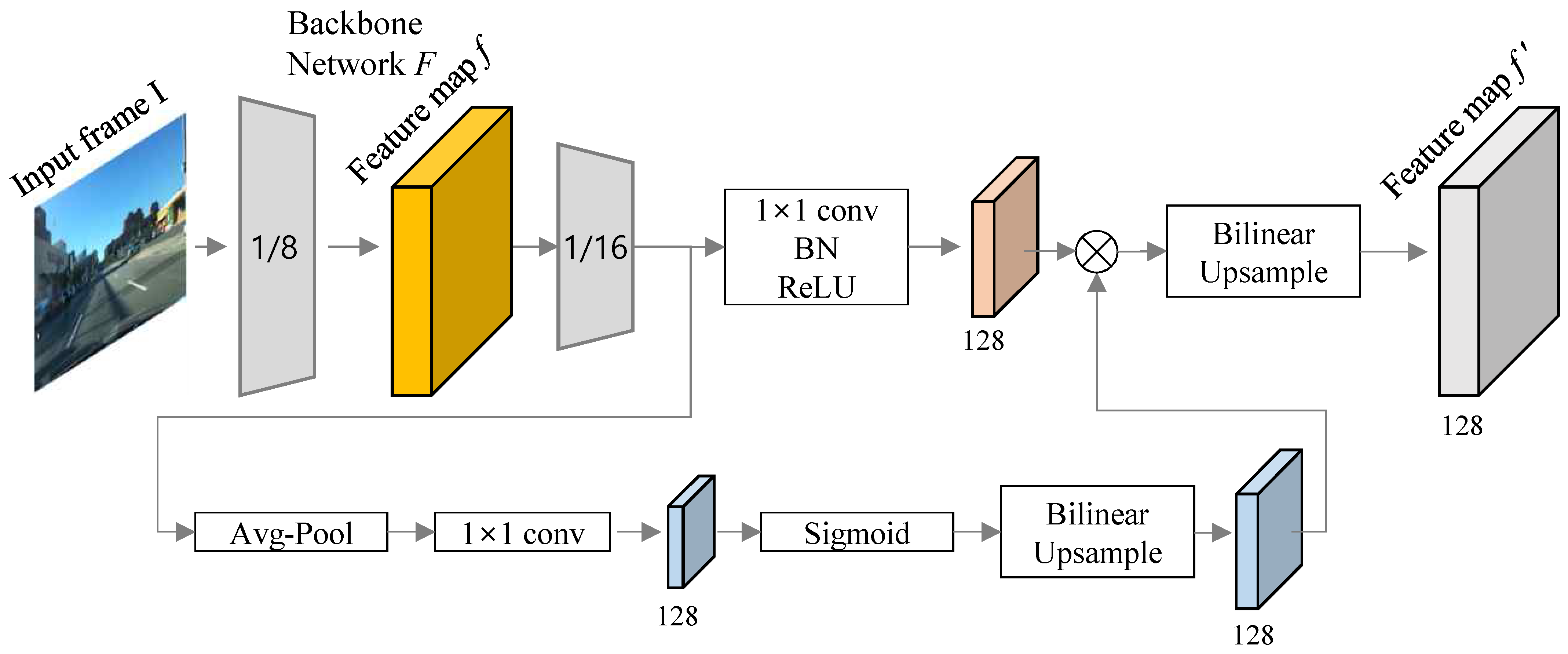
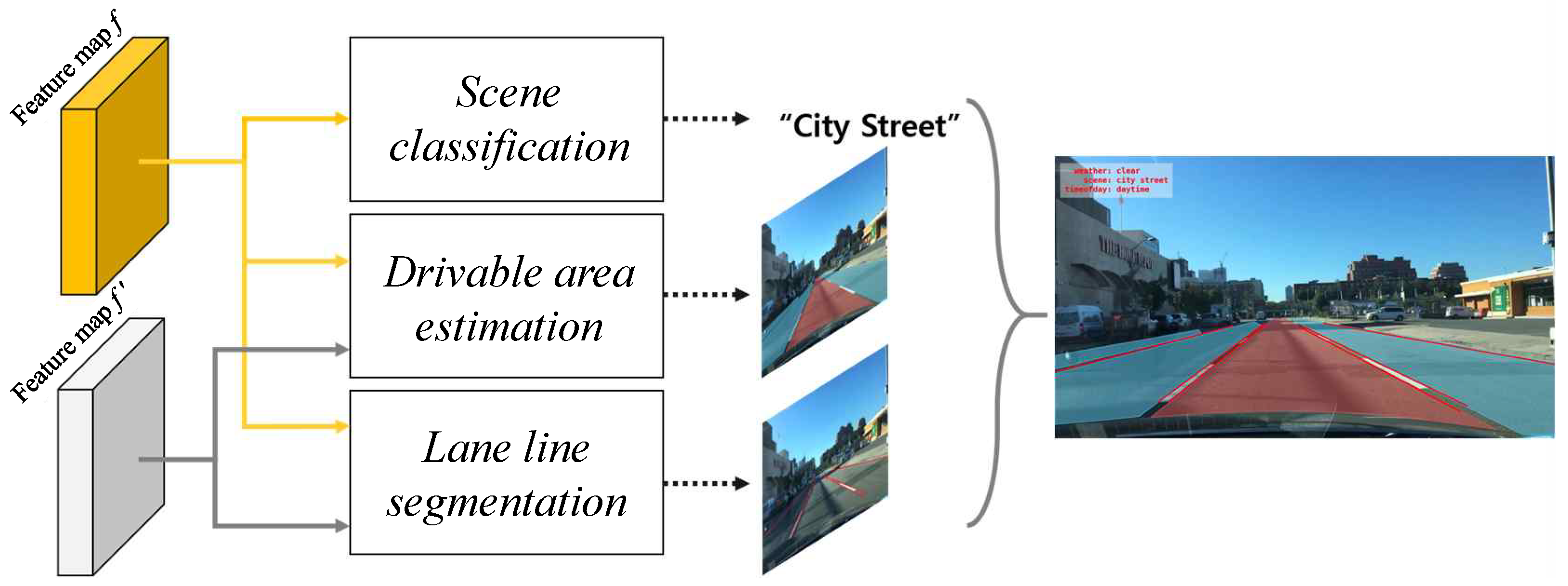
3. Methods
3.1. Encoder-Decoder Structure
3.2. Multi-Task Learning
4. Experiment and Result Analysis
4.1. Dataset
4.2. Implementation Details
4.3. Experimental Results
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Teichmann, M.; Weber, M.; Zoellner, M.; Cipolla, R.; Urtasun, R. Multinet: Real-time joint semantic reasoning for autonomous driving. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1013–1020. [Google Scholar]
- Pizzati, F.; García, F. Enhanced free space detection in multiple lanes based on single CNN with scene identification. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2536–2541. [Google Scholar]
- Qian, Y.; Dolan, J.M.; Yang, M. DLT-Net: Joint detection of drivable areas, lane lines, and traffic objects. IEEE Trans. Intell. Transp. Syst. (IVS) 2019, 21, 4670–4679. [Google Scholar] [CrossRef]
- Yu, F.; Xian, W.; Chen, Y.; Liu, F.; Liao, M.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving video database with scalable annotation tooling. arXiv 2018, arXiv:1805.04687. [Google Scholar]
- Kendall, A.; Gal, Y.; Cipolla, R. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7482–7491. [Google Scholar]
- Chen, Z.; Chen, Z. Rbnet: A deep neural network for unified road and road boundary detection. In International Conference on Neural Information Processing; Springer: Berlin, Germany, 2017; pp. 677–687. [Google Scholar]
- Han, X.; Lu, J.; Zhao, C.; You, S.; Li, H. Semisupervised and weakly supervised road detection based on generative adversarial networks. IEEE Signal Process. Lett. 2018, 25, 551–555. [Google Scholar] [CrossRef]
- Munoz-Bulnes, J.; Fernandez, C.; Parra, I.; Fernández-Llorca, D.; Sotelo, M.A. Deep fully convolutional networks with random data augmentation for enhanced generalization in road detection. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 366–371. [Google Scholar]
- Asgarian, H.; Amirkhani, A.; Shokouhi, S.B. Fast Drivable Area Detection for Autonomous Driving with Deep Learning. In Proceedings of the 2021 5th International Conference on Pattern Recognition and Image Analysis (ICPRIA), Kashan, Iran, 28–29 April 2021; pp. 1–6. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder–decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Romera, E.; Alvarez, J.M.; Bergasa, L.M.; Arroyo, R. Erfnet: Efficient residual factorized convnet for real-time semantic segmentation. IEEE Trans. Intell. Transp. Syst. (ITS) 2017, 19, 263–272. [Google Scholar] [CrossRef]
- Neven, D.; De Brabandere, B.; Georgoulis, S.; Proesmans, M.; Van Gool, L. Towards end-to-end lane detection: An instance segmentation approach. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 286–291. [Google Scholar]
- Lee, M.; Lee, J.; Lee, D.; Kim, W.; Hwang, S.; Lee, S. Robust lane detection via expanded self attention. arXiv 2021, arXiv:2102.07037. [Google Scholar]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as deep: Spatial cnn for traffic scene understanding. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. (NeurIPS) 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 1314–1324. [Google Scholar]
- Liu, X.; Gao, J.; He, X.; Deng, L.; Duh, K.; Wang, Y.Y. Representation Learning Using Multi-Task Deep Neural Networks for Semantic Classification and Information Retrieval. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Simultaneous detection and segmentation. In European Conference on Computer Vision (ECCV); Springer: Berlin, Germany, 2014; pp. 297–312. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Dvornik, N.; Shmelkov, K.; Mairal, J.; Schmid, C. Blitznet: A real-time deep network for scene understanding. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4154–4162. [Google Scholar]
- Yang, T.J.; Howard, A.; Chen, B.; Zhang, X.; Go, A.; Sandler, M.; Sze, V.; Adam, H. Netadapt: Platform-aware neural network adaptation for mobile applications. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 285–300. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Dutchess County, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Pan, X.; Luo, P.; Shi, J.; Tang, X. Two at once: Enhancing learning and generalization capacities via ibn-net. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 464–479. [Google Scholar]
- Zhao, H.; Zhang, Y.; Liu, S.; Shi, J.; Loy, C.C.; Lin, D.; Jia, J. Psanet: Point-wise spatial attention network for scene parsing. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 267–283. [Google Scholar]
- Bulo, S.R.; Porzi, L.; Kontschieder, P. In-place activated batchnorm for memory-optimized training of dnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 5639–5647. [Google Scholar]
- Hou, Y.; Ma, Z.; Liu, C.; Loy, C.C. Learning lightweight lane detection cnns by self attention distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 1013–1021. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Operator | Exp Size | #out | SE | Stride |
|---|---|---|---|---|---|
| conv2d | - | 16 | - | 2 | |
| bneck, 3 × 3 | 16 | 16 | - | 1 | |
| bneck, 3 × 3 | 64 | 24 | - | 2 | |
| bneck, 3 × 3 | 72 | 24 | - | 1 | |
| bneck, 5 × 5 | 72 | 40 | ✓ | 2 | |
| bneck, 5 × 5 | 120 | 40 | ✓ | 1 | |
| bneck, 5 × 5 | 120 | 40 | ✓ | 1 | |
| bneck, 3 × 3 | 240 | 80 | - | 2 | |
| bneck, 3 × 3 | 200 | 80 | - | 1 | |
| bneck, 3 × 3 | 184 | 80 | - | 1 | |
| bneck, 3 × 3 | 184 | 80 | - | 1 | |
| bneck, 3 × 3 | 480 | 112 | ✓ | 1 | |
| bneck, 3 × 3 | 672 | 112 | ✓ | 1 | |
| bneck, 5 × 5 | 672 | 160 | ✓ | 2 | |
| bneck, 5 × 5 | 960 | 160 | ✓ | 1 | |
| bneck, 5 × 5 | 960 | 160 | ✓ | 1 | |
| bneck, conv2d, 1 × 1 | - | 960 | - | 1 | |
| bneck, pool, 7 × 7 | - | - | - | 1 | |
| bneck, conv2d 1 × 1 NBN | - | 1280 | - | 1 | |
| bneck, conv2d 1 × 1, NBN | - | k | - | 1 |
| Method | DAE | Lane | Scene | Multi | Speed |
|---|---|---|---|---|---|
| mIoU(%) | mIoU(%) | Acc.(%) | Yes/No | fps | |
| IBN_PSA/P [26] | 86.18 | - | - | no | 3.81 |
| Mapillary [27] | 86.04 | - | - | no | 0.153 |
| DiDiLabs [28] | 84.01 | - | - | no | 3.35 |
| Asgarian [9] | 83.50 | - | - | no | 322 |
| ENet-SAD [29] | - | 47.72 | - | no | 12.1 |
| SCNN [14] | - | 47.34 | - | no | 123.6 |
| ERFNet [13] | - | 51.77 | - | no | 7.3 |
| DLT-Net [3] | 72.10 | - | - | yes | 9.30 |
| MultiNet [1] | 71.60 | - | - | yes | 8.6 |
| VisLabs (DAE) [2] | 83.35 | - | - | yes | 23.86 |
| VisLabs (Scene) [2] | - | - | 77.73 | yes | 27.58 |
| VisLabs (DAE + Scene) [2] | 82.62 | - | 76.53 | yes | 22.59 |
| Ours (Lane + Scene) | - | 74.46 | 76.76 | yes | 96.34 |
| Ours (DAE + Scene) | 82.55 | - | 76.51 | yes | 106.38 |
| Ours (DAE + Lane) | 83.34 | 75.66 | - | yes | 104.43 |
| Ours (DAE + Lane + Scene) | 84.56 | 78.57 | 78.4 | yes | 93.81 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, D.-G. Fast Drivable Areas Estimation with Multi-Task Learning for Real-Time Autonomous Driving Assistant. Appl. Sci. 2021, 11, 10713. https://doi.org/10.3390/app112210713
Lee D-G. Fast Drivable Areas Estimation with Multi-Task Learning for Real-Time Autonomous Driving Assistant. Applied Sciences. 2021; 11(22):10713. https://doi.org/10.3390/app112210713
Chicago/Turabian StyleLee, Dong-Gyu. 2021. "Fast Drivable Areas Estimation with Multi-Task Learning for Real-Time Autonomous Driving Assistant" Applied Sciences 11, no. 22: 10713. https://doi.org/10.3390/app112210713
APA StyleLee, D. -G. (2021). Fast Drivable Areas Estimation with Multi-Task Learning for Real-Time Autonomous Driving Assistant. Applied Sciences, 11(22), 10713. https://doi.org/10.3390/app112210713