
SMM: Leveraging Metadata for Contextually Salient Multi-Variate Motif Discovery


Abstract
:1. Introduction
1.1. Multi-Variate Motif Search
1.2. Key Questions
- Can the re-occurring pattern stretch or shrink in time, due to variations in speed, or does it have to be, more or less, the same length as the original?
- Is there a lower bound on the number of times a pattern repeats, before being marked as a motif, or is repeating once sufficient?
- Does any re-occurring pattern count as a motif, or do these patterns have to satisfy some additional constraints, such as being concentrated on a set of variates which are contextually related (such as sensors on the same arm)?
1.3. Our Contributions: Contextually Salient Motifs
2. Related Works
2.1. Motifs
2.2. Multi-Variate Motifs
3. Problem Definition
3.1. Uni-Variate Motifs and Local Saliency
- is a sub-sequence of double length, centered at the same time instance as(i.e.,);
- is a function that subsamples a time series into half its length.
- ;
- ;
- is a sub-sequence of double length, centered at the same time instance as(i.e.,);
- is a sub-sequence of half length, centered at the same time instance as;
- is a function that supersamples a time series into double length;
- is a function that subsamples a time series into half its length.
3.2. Multi-Variate Motifs and Contextual Saliency
- is a multi-variate subsequence with the same center and length as , but has twice as large a variate width topologically centered around , based on the variate context C;
- is a function that compresses a given multi-variate time series from its original variate scope down to the variate scope defined by .
3.3. Problem Statement
4. SMM: Contextually Salient Multi-Variate Motif (-) Discovery
4.1. Salient Multi-Variate Sub-Sequences (SMSs)
- Firstly, the scale-space extrema detection process in the first step ensures that only those subsequences that are significantly different from their neighbors (both in time and variates) are considered as candidate patterns for motifs. Consequently, the overall efficiency of the process is significantly improved by being selective during motif search.
- Secondly, since the process identifies subsequences of different temporal and variate scopes, we can potentially avoid fixing the motif patterns’ sizes in advance.
- The process can also take into account the contextual information that may describe the relationships among the variates.
4.1.1. Scale-Spaces of Multi-Variate Time Series
Temporal and Variate Smoothing
Descriptor Creation for Multi-Variate Sub-Sequences
4.1.2. Identifying Contextually Salient Sub-Sequences
Smoothing-Based Contextual Saliency
Entropy-Based Contextual Saliency
4.2. Frequently Recurring Motif Search
- (1)
- Finding motifs across the same variate groups, by considering all the features extracted from a multi-variate time series. This requires a three-step process: (a) We create groups of features existing in the same or a similar variate scope; the results are clusters of features sharing the same or a similar variate scope. (b) To identify groups of features with similar behaviors, in each of the groups we apply one cluster (adaptive K-means). (c) In each group of these features, a pruning process is applied to clean the outlier instances from the clusters using standard deviation from the feature centroid.
- (2)
- Targeting motifs across multiple (potentially different) variate groups. Considering all the features extracted from a multi variate time series, we apply the following steps: (a) First, a clustering technique is applied; in our results, we use adaptive K-means. The clustering process would allow us to identify groups of instances with similar behaviors across potentially different variate groups. (b) For each cluster identified, a pruning step is applied, which takes each cluster centroid and the corresponding standard deviation into consideration. This would allow the proposed framework to arrive at bags of motifs, each containing instances from multiple variate sets. (c) The final step is sub-clustering (we group instances in each motif bag having a similar or the same variate scope), which would be applied to the search for motifs existing on the same variate groups.
- The degree of variate alignment. As we have seen in the Introduction, Figure 1, while, in some applications, we may wish to ensure that the repeating patterns occur on the same set of variates, in some others, it might be acceptable that re-occurring patterns cover different subsets of variates (Figure 2);
- The degree of length alignment. Again, as stated in the Introduction, Figure 1, while, in some applications, we may wish to ensure that the repeating patterns have the same length, in some others, it might be acceptable that re-occurring patterns are of different lengths.
5. Experimental Evaluation
5.1. Datasets
- The motion capture (MoCap) dataset [10] consists of movement records from sensors placed on subjects’ bodies as they perform 8 types of tasks. We use the Acclaim-Skeleton-File/Acclaim Motion Capture (ASF/AMC) data format, where the original coordinate readings are converted into 62 joint angles’ data. We treat the readings for each joint angle as a different uni-variate time series. The hierarchical spatial distribution (e.g., left foot, right foot, left leg, etc.) of the joint angles on the body is used to create the underlying correlation matrix used as contextual metadata.
- The building energy dataset consists of energy simulations generated through the EnergyPlus simulation software [36]. In this case, the variate context is defined based on the topology of the building being simulated.
- The BirdSong dataset [37] consists of Mel-frequency cepstral coefficient (MFCC) features for different bird calls. Each MFCC coefficient captures the short-term power spectrum of a sound for a given frequency band. The original dataset contains 13 MFCC coefficients (i.e., variates) for 154 bird calls of 8 classes, with the average time length of 397 time stamps. For our experiments, we convert these into the frequency domain and produce a multi-variate time-series composed of 52 variates. The context is defined in terms of the proximity of the constituent frequencies; in particular, we consider them to be equally spaced on the Mel scale.
5.2. Motifs Used as Ground Truth
- First, we identify and extract multi-variate dominant behaviors/patterns in the form of RMT features (robust multivariate time-series feature) from the series in a given dataset.
- Then, we select a random set of distinct patterns to be injected as motifs.
- Next, we generate a set of multi-variate random walks to be used as the motif-free time series; to ensure that the generated series closely match the characteristics of the original series, we perform the following operations:
- We compute, from each motif pattern, the value of average displacement;
- We scale the generated random walks to match a specific percentage of the average displacement of the motif patterns for making the motif instances injected consistent within the global behavior over the time series.
- We finally inject the selected patterns onto the created motif-free random walks.
- Number of motifs (m): this is the number of motifs inserted into a single multivariate series;
- Recurrence count (k): this is the number of patterns inserted for each motif;
- Length flexibility (f): for a given motif, we allowed the length of its subsequences to vary—f denotes the lowerbound on the length of the subsequences as a percentage of the original pattern.
5.3. Evaluation Criteria
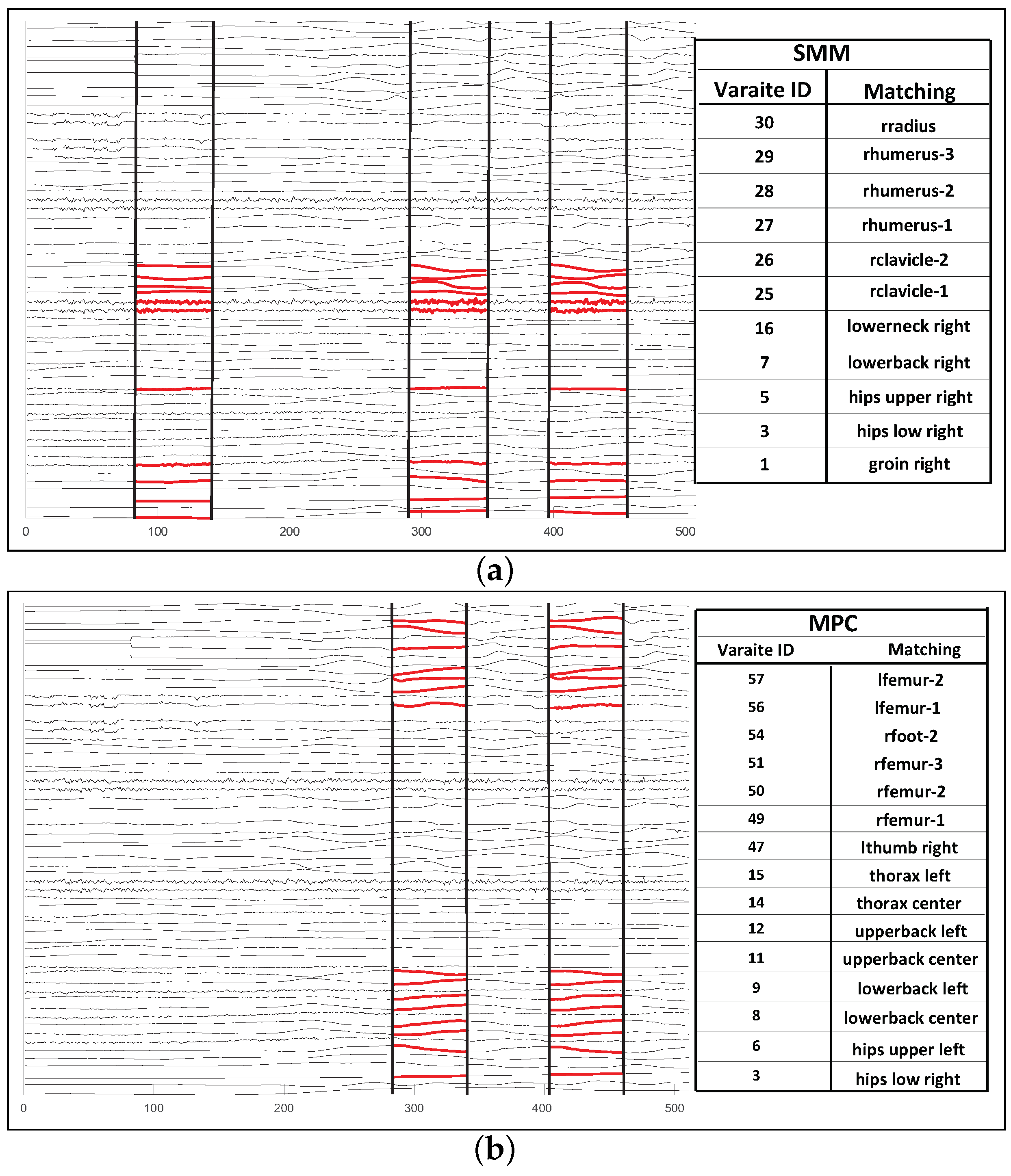
5.4. Indicative Sample Result
- The motif identified by the SMM approach consists of data from sensors that are logically related in the context of action recognition. In contrast, the motif identified by the MPC approach is highly noisy; since it aims to maximize the coverage (rather than maximizing their contextual relevance), the number of sensors’ pattern includes many irrelevant sensors.
- As a side effect of this, while SMM is able to identify 3 instances of the repeated pattern, MPC is able to identify only 2 occurrences; extra sensors prevent the effective clustering of the patterns thus resulting in lower recall.
5.5. Results for the Mocap and Energy Datasets
5.5.1. Accuracy
5.5.2. Efficiency
- SMM-s took 6.67 s for one time series (of length 2500) to locate motifs. Roughly 97% of this (6.48 s) was spent on locating salient multi-variate subsequences (SMSs) and the rest (0.19 s) was spent on identifying frequently recurring patterns.
- In contrast, MPC took 68.2 s for the same series. Roughly 57.7% of this (39.3 s) was spent on locating matching sub-sequence pairs and the rest (28.8 s) was spent on identifying frequent patterns.
5.6. Results for the BirdSong Dataset
6. Conclusions
- Visual media data: Visual media (images, videos) often contain repeated patterns that can be analyzed to classify the activity in the video, to identify real-world events, or to render the video content searchable. Sample applications include gesture detection, manufacturing and texture analysis;
- Audio media data: Audio data also often contain repeated patterns that are analyzed to classify the audio, to identify events, or to index the audio content. Sample applications include zoology and audio surveillance;
- Other sensory media data: The use of multi-variate sensory media is increasing in many smart-media applications, including healthcare, robotics, transportation and energy.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mei, T.; Rui, Y.; Li, S.; Tian, Q. Multimedia search reranking: A literature survey. ACM Comput. Surv. (CSUR) 2014, 46, 38. [Google Scholar]
- Yang, X.; Zhang, C.; Tian, Y. Recognizing actions using depth motion maps-based histograms of oriented gradients. In Proceedings of the 20th ACM International Conference on Multimedia, Nara, Japan, 29 October–2 November 2012; pp. 1057–1060. [Google Scholar]
- Weinland, D.; Ronfard, R.; Boyer, E. A survey of vision-based methods for action representation, segmentation and recognition. Comput. Vis. Image Underst. 2011, 115, 224–241. [Google Scholar]
- Scovanner, P.; Ali, S.; Shah, M. A 3-dimensional sift descriptor and its application to action recognition. In Proceedings of the 15th ACM International Conference on Multimedia, Augsburg, Germany, 25–29 September 2007; pp. 357–360. [Google Scholar]
- Torkamani, S.; Lohweg, V. Survey on time series motif discovery. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2017, 7, e1199. [Google Scholar]
- Tanaka, Y.; Iwamoto, K.; Uehara, K. Discovery of time-series motif from multi-dimensional data based on MDL principle. Mach. Learn. 2005, 58, 269–300. [Google Scholar]
- Balasubramanian, A.; Wang, J.; Prabhakaran, B. Discovering Multidimensional Motifs in Physiological Signals for Personalized Healthcare. IEEE J. Sel. Top. Signal Process. 2016, 10, 832–841. [Google Scholar] [CrossRef]
- Balasubramanian, A.; Prabhakaran, B. Flexible exploration and visualization of motifs in biomedical sensor data. In Proceedings of the Workshop on Data Mining for Healthcare (DMH), in Conjunction with ACM KDD, Chicago, IL, USA, 11 August 2013. [Google Scholar]
- Yeh, C.C.M.; Kavantzas, N.; Keogh, E. Matrix Profile VI: Meaningful Multidimensional Motif Discovery. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017; pp. 565–574. [Google Scholar] [CrossRef]
- Lab, C.G. Motion Capture Database. 2018. Available online: http://mocap.cs.cmu.edu/ (accessed on 10 October 2021).
- Buhler, J.; Tompa, M. Finding motifs using random projections. In Proceedings of the Fifth Annual International Conference on Computational Biology, ACM, RECOMB ’01, Montreal, QC, Canada, 22–25 April 2001; pp. 69–76. [Google Scholar]
- Patel, P.; Keogh, E.; Lin, J.; Lonardi, S. Mining Motifs in Massive Time Series Databases. Proceedings of IEEE International Conference on Data Mining (ICDM’02), Maebashi City, Japan, 9–12 December 2002; pp. 370–377. [Google Scholar]
- Keogh, E.; Lin, J.; Truppel, W. Clustering of Time Series Subsequences is Meaningless: Implications for Previous and Future Research. In Proceedings of the Third IEEE International Conference on Data Mining, ICDM ’03, Melbourne, FL, USA, 19–22 November 2003; pp. 115–125. [Google Scholar]
- Zhang, X.; Wu, J.; Yang, X.; Ou, H.; Lv, T. A novel pattern extraction method for time series classification. Optim. Eng. 2009, 10, 253–271. [Google Scholar]
- Esling, P.; Agon, C. Time-series data mining. ACM Comput. Surv. 2012, 45, 1–34. [Google Scholar] [CrossRef] [Green Version]
- Tang, H.; Liao, S.S. Discovering original motifs with different lengths from time series. Know.-Based Syst. 2008, 21, 666–671. [Google Scholar] [CrossRef]
- Ferreira, P.G.; Azevedo, P.J.; Silva, C.G.; Brito, R.M.M. Mining Approximate Motifs in Time Series. In Discovery Science; Todorovski, L., Lavrac, N., Jantke, K., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4265, pp. 89–101. [Google Scholar]
- Lin, J.; Keogh, E.; Lonardi, S.; Chiu, B. A symbolic representation of time series, with implications for streaming algorithms. In Proceedings of the 8th ACM SIGMOD Workshop on Research Issues in Data Mining and Knowledge Discovery, San Diego, CA, USA, 13 June 2003; pp. 2–11. [Google Scholar]
- Chiu, B.; Keogh, E.; Lonardi, S. Probabilistic discovery of time series motifs. In Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’03, Washington, DC, USA, 24–27 August 2003; pp. 493–498. [Google Scholar]
- Yankov, D.; Keogh, E.; Medina, J.; Chiu, B.; Zordan, V. Detecting time series motifs under uniform scaling. In Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’07, San Jose, CA, USA, 12–15 August 2007; pp. 844–853. [Google Scholar]
- Castro, N.; Azevedo, P. Multiresolution Motif Discovery in Time Series. In Proceedings of the SIAM International Conference on Data Mining, Columbus, OH, USA, 29 April–1 May 2010; pp. 665–676. [Google Scholar]
- Mueen, A.; Keogh, E.J.; Zhu, Q.; Cash, S.; Westover, M.B. Exact Discovery of Time Series Motifs. In Proceedings of the SIAM International Conference on Data Mining, Sparks, NV, USA, 30 April–2 May 2009; pp. 473–484. [Google Scholar]
- Lam, H.T.; Calders, T.; Pham, N. Online Discovery of Top-k Similar Motifs in Time Series Data. In Proceedings of the SIAM International Conference on Data Mining, Mesa, AZ, USA, 28–30 April 2011; pp. 1004–1015. [Google Scholar]
- Mohammad, Y.; Nishida, T. Constrained Motif Discovery in Time Series. New Gener. Comput. 2009, 27, 319–346. [Google Scholar] [CrossRef]
- Yeh, C.C.M.; Zhu, Y.; Ulanova, L.; Begum, N.; Ding, Y.; Dau, H.A.; Silva, D.F.; Mueen, A.; Keogh, E. Matrix Profile I: All Pairs Similarity Joins for Time Series: A Unifying View That Includes Motifs, Discords and Shapelets. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 1317–1322. [Google Scholar] [CrossRef]
- Grünwald, P.D.; Myung, I.J.; Pitt, M.A. Advances in Minimum Description Length: Theory and Applications; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Vahdatpour, A.; Amini, N.; Sarrafzadeh, M. Toward Unsupervised Activity Discovery Using Multi-Dimensional Motif Detection in Time Series. In Proceedings of the 21st International Joint Conference on Artificial Intelligence, Pasadena, CA, USA, 11–17 July 2009; Volume 9, pp. 1261–1266. [Google Scholar]
- Minnen, D.; Isbell, C.; Essa, I.; Starner, T. Detecting subdimensional motifs: An efficient algorithm for generalized multivariate pattern discovery. In Proceedings of the Seventh IEEE International Conference on Data Mining (ICDM 2007), Omaha, NE, USA, 28–31 October 2007; pp. 601–606. [Google Scholar]
- Minnen, D.; Starner, T.; Essa, I.A.; Isbell, C.L., Jr. Improving Activity Discovery with Automatic Neighborhood Estimation. In Proceedings of the 20th International Joint Conference on Artificial Intelligence, Hyderabad, India, 6–12 January 2007; Volume 7, pp. 2814–2819. [Google Scholar]
- Minnen, D.; Isbell, C.L.; Essa, I.; Starner, T. Discovering multivariate motifs using subsequence density estimation and greedy mixture learning. In Proceedings of the National Conference on Artificial Intelligence, Vancouver, BC, Canada, 22–26 July 2007; AAAI Press: Menlo Park, CA, USA; Cambridge, MA, USA; London, UK; MIT Press: Cambridge, MA, USA, 2007; Volume 22, p. 615. [Google Scholar]
- Minnen, D.; Starner, T.; Essa, I.; Isbell, C. Discovering characteristic actions from on-body sensor data. In Proceedings of the 10th IEEE International Symposium on Wearable Computers, Montreux, Switzerland, 11–14 October 2006; pp. 11–18. [Google Scholar]
- Lowe, D.G. Object Recognition from Local Scale-Invariant Features. In Proceedings of the International Conference on Computer Vision, ICCV ’99, Corfu, Greece, 20–25 September 1999. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar]
- Garg, Y.; Poccia, S.R. On the Effectiveness of Distance Measures for Similarity Search in Multi-Variate Sensory Data: Effectiveness of Distance Measures for Similarity Search. In Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval, ICMR 2017, Bucharest, Romania, 6–9 June 2017; pp. 489–493. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96, Portland, OR, USA, 2–4 August 1996; AAAI Press: Palo Alto, CA, USA, 1996; pp. 226–231. [Google Scholar]
- Energy Data for a Building with 27 Zones. Available online: https://drive.google.com/file/d/1qeL6u5Ik5hMSYDeVFp4WpweHQxQ_JZRH/view?usp=sharing (accessed on 20 May 2021).
- BirdSong (13 MFCC Coefficients for 154 Bird Calls). Available online: http://www.xeno-canto.org/explore/taxonomy (accessed on 20 May 2021).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | # Variates | # Time Series | # Classes | Contextual Strength |
|---|---|---|---|---|
| MoCap [10] | 62 | 184 | 8 | high |
| Building energy [36] | 27 | 100 | n/a | high |
| Birdsong [37] | 52 | 154 | 8 | low |
| Parameters | Values |
|---|---|
| number of motifs (m) | 1, 2, 3 |
| recurrence count (k) | 5, 10, 15 |
| length flexibility percentage (f) | 50, 75, 100 |
| average displacement scaling percentage | 10, 50, 75, 100 |
| Precision | Recall | F-Score | ||||
|---|---|---|---|---|---|---|
| Instances | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC |
| Overlap | M1 | M1 | M1 | M1 | M1 | M1 |
| 50% | 0.84 | 0.54 | 0.52 | 0.51 | 0.61 | 0.45 |
| 75% | 0.87 | 0.53 | 0.57 | 0.54 | 0.65 | 0.45 |
| 90% | 0.92 | 0.51 | 0.64 | 0.49 | 0.71 | 0.43 |
| 100% | 0.87 | 0.34 | 0.62 | 0.34 | 0.68 | 0.311 |
| F-Score MoCap (1 Motif 10, 50–100%) | ||||||||
|---|---|---|---|---|---|---|---|---|
| Instances | RW 10% | 50% | RW 75% | RW 100% | ||||
| Overlap | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC |
| 50% | 0.61 | 0.45 | 0.59 | 0.32 | 0.56 | 0.33 | 0.53 | 0.33 |
| 75% | 0.65 | 0.45 | 0.64 | 0.28 | 0.61 | 0.26 | 0.56 | 0.25 |
| 90% | 0.71 | 0.43 | 0.69 | 0.22 | 0.66 | 0.22 | 0.62 | 0.21 |
| 100% | 0.68 | 0.31 | 0.65 | 0.17 | 0.62 | 0.16 | 0.58 | 0.15 |
| F-Score Energy (1 Motif 10, 50–100%) | ||||||||
| Instances | RW 10% | RW 50% | RW 75% | RW 100% | ||||
| Overlap | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC |
| 50% | 0.62 | 0.38 | 0.51 | 0.35 | 0.46 | 0.33 | 0.43 | 0.31 |
| 75% | 0.52 | 0.27 | 0.41 | 0.22 | 0.37 | 0.21 | 0.35 | 0.19 |
| 90% | 0.45 | 0.17 | 0.37 | 0.14 | 0.33 | 0.13 | 0.31 | 0.10 |
| 100% | 0.38 | 0.09 | 0.31 | 0.08 | 0.28 | 0.07 | 0.27 | 0.06 |
| F-Score MoCap (2 Motifs 10, 50–100%) | ||||||||
| Instances | RW 10% | RW 50% | RW 75% | RW 100% | ||||
| Overlap | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC |
| 50% | 0.59 | 0.45 | 0.55 | 0.37 | 0.50 | 0.33 | 0.46 | 0.32 |
| 75% | 0.62 | 0.42 | 0.56 | 0.28 | 0.52 | 0.25 | 0.48 | 0.25 |
| 90% | 0.67 | 0.32 | 0.61 | 0.24 | 0.57 | 0.22 | 0.51 | 0.23 |
| 100% | 0.62 | 0.24 | 0.55 | 0.19 | 0.52 | 0.17 | 0.47 | 0.18 |
| F-Score Energy (2 Motifs 10, 50–100%) | ||||||||
| Instances | RW 10% | RW 50% | RW 75% | RW 100% | ||||
| Overlap | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC |
| 50% | 0.58 | 0.35 | 0.47 | 0.29 | 0.44 | 0.27 | 0.42 | 0.27 |
| 75% | 0.47 | 0.21 | 0.37 | 0.17 | 0.35 | 0.16 | 0.34 | 0.16 |
| 90% | 0.43 | 0.12 | 0.35 | 0.1 | 0.32 | 0.08 | 0.31 | 0.08 |
| 100% | 0.37 | 0.07 | 0.30 | 0.05 | 0.28 | 0.05 | 0.26 | 0.05 |
| F-Score MoCap (3 Motifs 10, 50–100%) | ||||||||
| Instances | RW 10% | RW 50% | RW 75% | RW 100% | ||||
| Overlap | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC |
| 50% | 0.57 | 0.48 | 0.52 | 0.42 | 0.47 | 0.38 | 0.44 | 0.35 |
| 75% | 0.61 | 0.43 | 0.56 | 0.31 | 0.51 | 0.27 | 0.47 | 0.25 |
| 90% | 0.63 | 0.34 | 0.58 | 0.25 | 0.52 | 0.23 | 0.49 | 0.21 |
| 100% | 0.56 | 0.23 | 0.51 | 0.20 | 0.47 | 0.19 | 0.43 | 0.18 |
| F-Score Energy (3 Motifs 10, 50–100%) | ||||||||
| Instances | RW 10% | RW 50% | RW 75% | RW 100% | ||||
| Overlap | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC |
| 50% | 0.55 | 0.37 | 0.46 | 0.29 | 0.43 | 0.26 | 0.41 | 0.24 |
| 75% | 0.44 | 0.19 | 0.36 | 0.15 | 0.34 | 0.14 | 0.33 | 0.13 |
| 90% | 0.40 | 0.09 | 0.33 | 0.07 | 0.30 | 0.07 | 0.29 | 0.06 |
| 100% | 0.34 | 0.05 | 0.29 | 0.04 | 0.27 | 0.03 | 0.25 | 0.03 |
| F-Score MoCap (1 Motif 5, 50–100%) | ||||||||
|---|---|---|---|---|---|---|---|---|
| Instances | RW 10% | RW 50% | RW 75% | RW 100% | ||||
| Overlap | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC |
| 50% | 0.69 | 0.33 | 0.70 | 0.30 | 0.66 | 0.33 | 0.57 | 0.32 |
| 75% | 0.74 | 0.31 | 0.73 | 0.25 | 0.67 | 0.24 | 0.57 | 0.22 |
| 90% | 0.75 | 0.27 | 0.74 | 0.19 | 0.68 | 0.20 | 0.57 | 0.17 |
| 100% | 0.70 | 0.18 | 0.67 | 0.15 | 0.61 | 0.15 | 0.51 | 0.14 |
| F-Score Energy (1 Motif 5, 50–100%) | ||||||||
| Instances | RW 10% | RW 50% | RW 75% | RW 100% | ||||
| Overlap | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC |
| 50% | 0.66 | 0.14 | 0.60 | 0.17 | 0.50 | 0.15 | 0.43 | 0.14 |
| 75% | 0.52 | 0.10 | 0.45 | 0.11 | 0.37 | 0.09 | 0.32 | 0.09 |
| 90% | 0.45 | 0.07 | 0.41 | 0.07 | 0.34 | 0.06 | 0.29 | 0.07 |
| 100% | 0.34 | 0.05 | 0.30 | 0.06 | 0.24 | 0.05 | 0.20 | 0.05 |
| F-Score MoCap (1 Motif 15, 50–100%) | ||||||||
| Instances | RW 10% | RW 50% | RW 75% | RW 100% | ||||
| Overlap | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC |
| 50% | 0.80 | 0.55 | 0.66 | 0.49 | 0.59 | 0.49 | 0.55 | 0.48 |
| 75% | 0.60 | 0.56 | 0.51 | 0.48 | 0.47 | 0.43 | 0.45 | 0.40 |
| 90% | 0.53 | 0.48 | 0.47 | 0.38 | 0.44 | 0.32 | 0.43 | 0.26 |
| 100% | 0.41 | 0.14 | 0.37 | 0.14 | 0.35 | 0.14 | 0.34 | 0.13 |
| F-Score Energy (1 Motif 15, 50–100%) | ||||||||
| Instances | RW 10% | RW 50% | RW 75% | RW 100% | ||||
| Overlap | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC |
| 50% | 0.62 | 0.29 | 0.57 | 0.30 | 0.50 | 0.31 | 0.41 | 0.28 |
| 75% | 0.53 | 0.23 | 0.47 | 0.24 | 0.41 | 0.23 | 0.36 | 0.19 |
| 90% | 0.47 | 0.16 | 0.42 | 0.18 | 0.37 | 0.16 | 0.32 | 0.12 |
| 100% | 0.41 | 0.06 | 0.37 | 0.09 | 0.32 | 0.09 | 0.28 | 0.07 |
| Instances | RW 10% | RW 50% | RW 75% | RW 100% | ||||
|---|---|---|---|---|---|---|---|---|
| Overlap | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC |
| V-ALIGNED: F-Score v- MoCap (1 Motif 10, 50–100%) | ||||||||
| 50% | 0.61 | 0.45 | 0.59 | 0.32 | 0.56 | 0.33 | 0.53 | 0.33 |
| 75% | 0.65 | 0.45 | 0.64 | 0.28 | 0.61 | 0.26 | 0.56 | 0.25 |
| 90% | 0.71 | 0.43 | 0.69 | 0.22 | 0.66 | 0.22 | 0.62 | 0.21 |
| 100% | 0.68 | 0.31 | 0.65 | 0.17 | 0.62 | 0.16 | 0.58 | 0.15 |
| V-STRUCTURE: F-Score MoCap (1 Motif 10, 50–100%) | ||||||||
| 50% | 0.46 | 0.25 | 0.42 | 0.24 | 0.38 | 0.23 | 0.34 | 0.24 |
| 75% | 0.46 | 0.23 | 0.41 | 0.18 | 0.37 | 0.16 | 0.31 | 0.16 |
| 90% | 0.47 | 0.10 | 0.41 | 0.08 | 0.37 | 0.08 | 0.31 | 0.09 |
| 100% | 0.43 | 0.00 | 0.38 | 0.00 | 0.33 | 0.00 | 0.27 | 0.00 |
| V-ALIGNED: F-Score MoCap (1 Motif 10, 100%) | ||||||||
| 50% | 0.78 | 0.63 | 0.79 | 0.60 | 0.74 | 0.61 | 0.64 | 0.61 |
| 75% | 0.81 | 0.62 | 0.84 | 0.60 | 0.82 | 0.61 | 0.73 | 0.60 |
| 90% | 0.79 | 0.58 | 0.83 | 0.58 | 0.79 | 0.60 | 0.71 | 0.57 |
| 100% | 0.64 | 0.45 | 0.65 | 0.45 | 0.63 | 0.44 | 0.55 | 0.43 |
| V-STRUCTURE: F-Score MoCap (1 Motif 10, 100%) | ||||||||
| 50% | 0.54 | 0.29 | 0.50 | 0.30 | 0.45 | 0.30 | 0.39 | 0.30 |
| 75% | 0.52 | 0.27 | 0.47 | 0.27 | 0.41 | 0.26 | 0.38 | 0.25 |
| 90% | 0.51 | 0.21 | 0.45 | 0.22 | 0.39 | 0.23 | 0.35 | 0.21 |
| 100% | 0.40 | 0.00 | 0.34 | 0.00 | 0.28 | 0.00 | 0.24 | 0.00 |
| V-ALIGNED: F-Score Energy (1 Motif 10, 50–100%) | ||||||||
| 50% | 0.62 | 0.38 | 0.51 | 0.35 | 0.46 | 0.33 | 0.43 | 0.31 |
| 75% | 0.52 | 0.27 | 0.41 | 0.22 | 0.37 | 0.21 | 0.35 | 0.19 |
| 90% | 0.45 | 0.17 | 0.37 | 0.14 | 0.33 | 0.13 | 0.31 | 0.10 |
| 100% | 0.38 | 0.09 | 0.31 | 0.08 | 0.28 | 0.07 | 0.27 | 0.06 |
| V-STRUCTURE: F-Score Energy (1 Motif 10, 50–100%) | ||||||||
| 50% | 0.51 | 0.15 | 0.42 | 0.16 | 0.32 | 0.13 | 0.29 | 0.11 |
| 75% | 0.41 | 0.07 | 0.33 | 0.06 | 0.27 | 0.06 | 0.25 | 0.05 |
| 90% | 0.32 | 0.02 | 0.25 | 0.02 | 0.19 | 0.02 | 0.19 | 0.02 |
| 100% | 0.28 | 0.00 | 0.22 | 0.00 | 0.16 | 0.00 | 0.16 | 0.00 |
| V-ALIGNED: F-Score Energy (1 Motif 10, 100%) | ||||||||
| 50% | 0.77 | 0.48 | 0.59 | 0.49 | 0.55 | 0.48 | 0.46 | 0.45 |
| 75% | 0.58 | 0.47 | 0.47 | 0.43 | 0.45 | 0.40 | 0.40 | 0.34 |
| 90% | 0.52 | 0.40 | 0.44 | 0.32 | 0.43 | 0.26 | 0.38 | 0.23 |
| 100% | 0.41 | 0.12 | 0.35 | 0.14 | 0.34 | 0.13 | 0.30 | 0.13 |
| V-STRUCTURE: F-Score Energy (1 Motif 10, 100%) | ||||||||
| 50% | 0.67 | 0.26 | 0.52 | 0.27 | 0.41 | 0.27 | 0.35 | 0.26 |
| 75% | 0.64 | 0.23 | 0.60 | 0.21 | 0.55 | 0.19 | 0.38 | 0.13 |
| 90% | 0.48 | 0.09 | 0.54 | 0.07 | 0.53 | 0.07 | 0.35 | 0.05 |
| 100% | 0.48 | 0.00 | 0.54 | 0.00 | 0.53 | 0.00 | 0.35 | 0.00 |
| F-Score MoCap v-Structure (10 Motif 10, 50–100%) | ||||||||
|---|---|---|---|---|---|---|---|---|
| Instances | RW 10% | RW 50% | RW 75% | RW 100% | ||||
| Overlap | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC |
| 50% | 0.53 | 0.14 | 0.53 | 0.14 | 0.53 | 0.14 | 0.53 | 0.14 |
| 75% | 0.54 | 0.12 | 0.54 | 0.12 | 0.54 | 0.12 | 0.54 | 0.12 |
| 90% | 0.55 | 0.07 | 0.55 | 0.08 | 0.55 | 0.08 | 0.55 | 0.08 |
| 100% | 0.49 | 0.05 | 0.48 | 0.05 | 0.48 | 0.05 | 0.48 | 0.05 |
| F-Score BirdSong (1 Motif 10, 50–100%) | ||||||||
|---|---|---|---|---|---|---|---|---|
| Instances | RW 10% | RW 50% | RW 75% | RW 100% | ||||
| Overlap | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC |
| 50% | 0.61 | 0.47 | 0.60 | 0.41 | 0.56 | 0.40 | 0.48 | 0.38 |
| 75% | 0.58 | 0.49 | 0.57 | 0.40 | 0.55 | 0.40 | 0.47 | 0.36 |
| 90% | 0.65 | 0.50 | 0.64 | 0.45 | 0.58 | 0.43 | 0.48 | 0.36 |
| 100% | 0.55 | 0.53 | 0.55 | 0.52 | 0.49 | 0.46 | 0.38 | 0.36 |
| F-Score BirdSong (1 Motif 10, 100%) | ||||||||
| Instances | RW 10% | RW 50% | RW 75% | RW 100% | ||||
| Overlap | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC |
| 50% | 0.89 | 0.76 | 0.85 | 0.82 | 0.75 | 0.79 | 0.59 | 0.77 |
| 75% | 0.91 | 0.77 | 0.92 | 0.82 | 0.83 | 0.80 | 0.61 | 0.78 |
| 90% | 0.85 | 0.77 | 0.83 | 0.82 | 0.68 | 0.80 | 0.49 | 0.79 |
| 100% | 0.42 | 0.76 | 0.39 | 0.82 | 0.33 | 0.80 | 0.22 | 0.78 |
| F-Score BirdSong v-Structure (1 Motif 10, 50–100%) | ||||||||
|---|---|---|---|---|---|---|---|---|
| Instances | RW 10% | RW 50% | RW 75% | RW 100% | ||||
| Overlap | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC | SMM-s | MPC |
| 50% | 0.48 | 0.23 | 0.48 | 0.25 | 0.45 | 0.27 | 0.38 | 0.24 |
| 75% | 0.41 | 0.16 | 0.40 | 0.17 | 0.40 | 0.18 | 0.35 | 0.13 |
| 90% | 0.34 | 0.15 | 0.32 | 0.15 | 0.32 | 0.15 | 0.25 | 0.12 |
| 100% | 0.28 | 0.14 | 0.27 | 0.14 | 0.26 | 0.13 | 0.19 | 0.11 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Poccia, S.R.; Candan, K.S.; Sapino, M.L. SMM: Leveraging Metadata for Contextually Salient Multi-Variate Motif Discovery. Appl. Sci. 2021, 11, 10873. https://doi.org/10.3390/app112210873
Poccia SR, Candan KS, Sapino ML. SMM: Leveraging Metadata for Contextually Salient Multi-Variate Motif Discovery. Applied Sciences. 2021; 11(22):10873. https://doi.org/10.3390/app112210873
Chicago/Turabian StylePoccia, Silvestro R., K. Selçuk Candan, and Maria Luisa Sapino. 2021. "SMM: Leveraging Metadata for Contextually Salient Multi-Variate Motif Discovery" Applied Sciences 11, no. 22: 10873. https://doi.org/10.3390/app112210873
APA StylePoccia, S. R., Candan, K. S., & Sapino, M. L. (2021). SMM: Leveraging Metadata for Contextually Salient Multi-Variate Motif Discovery. Applied Sciences, 11(22), 10873. https://doi.org/10.3390/app112210873