
Attention to Fires: Multi-Channel Deep Learning Models for Wildfire Severity Prediction

 , ,
, ,  , ,
, ,  ,
,  ,
,  and
and
Abstract
:1. Introduction
- Extensive experimental comparison of a wide range of model architectures and loss functions for deep learning wildfire severity prediction models on real-world satellite data.
- Application of state-of-the-art deep-learning models to a very large dataset (24 GB) for wildfire severity prediction.
- Extension of a state-of-the-art Double-Step deep learning Framework (DSF) by introducing an attention mechanism to the UNet segmentation model.
- Analysis of multi-channel model interpretability by exploiting both the newly introduced attention-based mechanism and domain knowledge.
2. Related Work
2.1. Explainable Artificial Intelligence
3. Double-Step Deep-Learning Framework (DSF)
3.1. Wildfire Detection Task (First Step)
3.2. Severity Prediction Task (Second Step)
3.3. Backbone Architectures
| Algorithm 1 Pseudocode for the DFS pipeline. |
| freeze model-R |
| while and not do |
| train model |
| freeze model-B |
| un-freeze model-R |
| while and not do |
| train model |
4. Experimental Results
4.1. Dataset Description
4.2. Hardware and Software Setting
4.3. Experimental Design
4.4. Loss Function Selection
4.5. Double-Step Architecture Comparison
- DS-UNet: 1.857 (mean), 2 (median);
- DS-UNet++: 1.857 (mean), 2 (median);
- DS-AttU: 2.429 (mean), 2 (median);
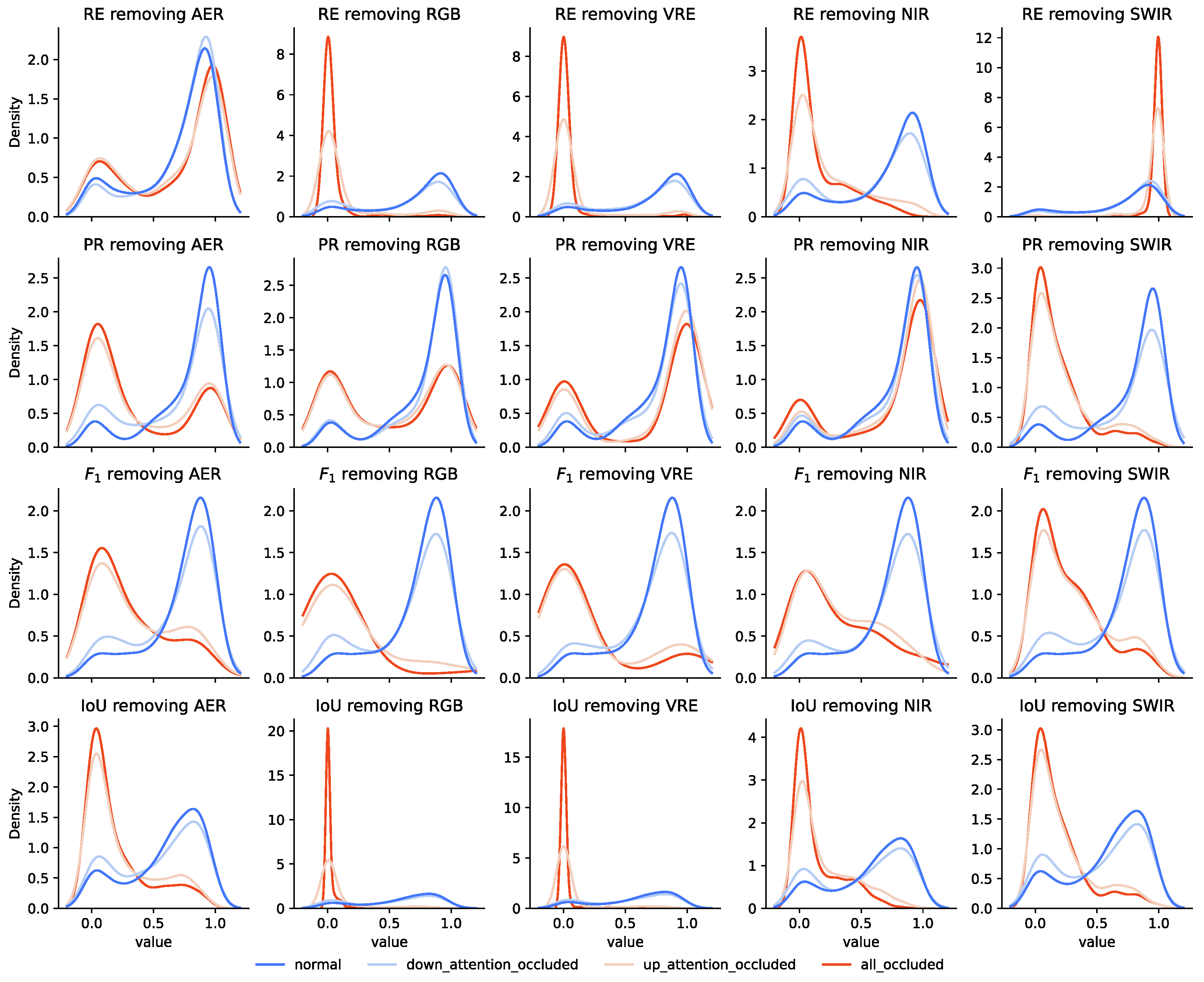
4.6. Multi-Channel Attention-Based Analysis
- The all_occlusion perturbation sets to zero all the pixels belonging to the given macro-band group (i.e., all its channels/bands).
- The up_attention_occlusion perturbation sets to zero all the pixels belonging to the given macro-band and with an attention value greater than a defined threshold.
- The down_attention_occlusion perturbation, instead, sets to zero all the pixels belonging to the given macro-band and with an attention value lower than a defined threshold.
- If the performance decreases, the perturbation negatively affected the model, and therefore the original perturbed inputs were positively impacting on the original correct model’s predictions.
- If the performance remains the same, the perturbed inputs were neutral for the model.
- Finally, if the performance increases, the perturbed inputs were negatively impacting the model’s behavior on the original inputs.
4.6.1. Binary Backbone
4.6.2. Regression Backbone
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- San-Miguel-Ayanz, J.; Durrant, T.; Boca, R.; Liberta, G.; Branco, A.; De Rigo, D.; Ferrari, D.; Maianti, P.; Artes Vivancos, T.; Pfeiffer, H.; et al. Forest Fires in Europe, Middle East and North Africa 2018; Publications Office of the European Union: Luxembourg, 2019. [Google Scholar] [CrossRef]
- San-Miguel-Ayanz, J.; Durrant, T.; Boca, R.; Maianti, P.; Liberta, G.; Artes Vivancos, T.; Branco, A.; De Rigo, D.; Ferrari, D.; Pfieffer, H.; et al. Advance EFFIS Report on Forest Fires in Europe, Middle East and North Africa 2019; Publications Office of the European Union: Luxembourg, 2020. [Google Scholar] [CrossRef]
- European Forest Fire Information System (EFFIS)—Annual Reports. 2019. Available online: https://effis.jrc.ec.europa.eu/reports-and-publications/annual-fire-reports (accessed on 28 September 2021).
- Euronews. 2019. Available online: https://www.euronews.com/2019/08/15/there-have-been-three-times-more-wildfires-in-the-eu-so-far-this-year (accessed on 28 September 2021).
- Santopaolo, A.; Saif, S.S.; Pietrabissa, A.; Giuseppi, A. Forest Fire Risk Prediction from Satellite Data with Convolutional Neural Networks. In Proceedings of the 2021 29th Mediterranean Conference on Control and Automation (MED), Puglia, Italy, 22–25 June 2021; pp. 360–367. [Google Scholar]
- Lestari, A.I.; Luhurkinanti, D.L.; Fitriasari, H.I.; Harwahyu, R.; Sari, R.F. Machine learning approaches for burned area identification using Sentinel-2 in Central Kalimantan. J. Appl. Eng. Sci. 2020, 18, 207–215. [Google Scholar]
- Wittenberg, L. Post-fire soil erosion–the Mediterranean perception. In Pines and Their Mixed Forest Ecosystems in the Mediterranean Basin; Springer: Berlin/Heidelberg, Germany, 2021; pp. 481–496. [Google Scholar]
- Chuvieco, E.; Mouillot, F.; van der Werf, G.R.; San Miguel, J.; Tanase, M.; Koutsias, N.; García, M.; Yebra, M.; Padilla, M.; Gitas, I.; et al. Historical background and current developments for mapping burned area from satellite Earth observation. Remote Sens. Environ. 2019, 225, 45–64. [Google Scholar] [CrossRef]
- Klein, T.; Cahanovitc, R.; Sprintsin, M.; Herr, N.; Schiller, G. A nation-wide analysis of tree mortality under climate change: Forest loss and its causes in Israel 1948–2017. For. Ecol. Manag. 2019, 432, 840–849. [Google Scholar] [CrossRef]
- Vaglio Laurin, G.; Francini, S.; Luti, T.; Chirici, G.; Pirotti, F.; Papale, D. Satellite open data to monitor forest damage caused by extreme climate-induced events: A case study of the Vaia storm in Northern Italy. For. Int. J. For. Res. 2021, 94, 407–416. [Google Scholar] [CrossRef]
- Khryashchev, V.; Larionov, R. Wildfire Segmentation on Satellite Images using Deep Learning. In Proceedings of the 2020 Moscow Workshop on Electronic and Networking Technologies (MWENT), Moscow, Russia, 11–13 March 2020; pp. 1–5. [Google Scholar]
- Farasin, A.; Colomba, L.; Palomba, G.; Nini, G.; Rossi, C. Supervised Burned Areas delineation by means of Sentinel-2 imagery and Convolutional Neural Networks. In Proceedings of the 17th International Conference on Information Systems for Crisis Response and Management (ISCRAM 2020), Virginia Tech, Blacksburg, VA, USA, 23–26 May 2020; pp. 24–27. [Google Scholar]
- Knopp, L.; Wieland, M.; Rättich, M.; Martinis, S. A deep learning approach for burned area segmentation with Sentinel-2 data. Remote Sens. 2020, 12, 2422. [Google Scholar] [CrossRef]
- Loboda, T.; O’Neal, K.; Csiszar, I. Regionally adaptable dNBR-based algorithm for burned area mapping from MODIS data. Remote Sens. Environ. 2007, 109, 429–442. [Google Scholar] [CrossRef]
- Cicala, L.; Angelino, C.V.; Fiscante, N.; Ullo, S.L. Landsat-8 and Sentinel-2 for fire monitoring at a local scale: A case study on Vesuvius. In Proceedings of the 2018 IEEE International Conference on Environmental Engineering (EE), Delhi, India, 11–13 March 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Miller, J.D.; Thode, A.E. Quantifying burn severity in a heterogeneous landscape with a relative version of the delta Normalized Burn Ratio (dNBR). Remote Sens. Environ. 2007, 109, 66–80. [Google Scholar] [CrossRef]
- Llorens, R.; Sobrino, J.A.; Fernández, C.; Fernández-Alonso, J.M.; Vega, J.A. A methodology to estimate forest fires burned areas and burn severity degrees using Sentinel-2 data. Application to the October 2017 fires in the Iberian Peninsula. Int. J. Appl. Earth Obs. Geoinf. 2021, 95, 102243. [Google Scholar] [CrossRef]
- Gao, B.C. NDWI—A normalized difference water index for remote sensing of vegetation liquid water from space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring vegetation systems in the Great Plains with ERTS. NASA Spec. Publ. 1974, 351, 309. [Google Scholar]
- Filipponi, F. BAIS2: Burned area index for Sentinel-2. Proceedings 2018, 2, 364. [Google Scholar] [CrossRef] [Green Version]
- Van der Meer, F.; Van der Werff, H.; Van Ruitenbeek, F. Potential of ESA’s Sentinel-2 for geological applications. Remote Sens. Environ. 2014, 148, 124–133. [Google Scholar] [CrossRef]
- Dkhala, B.; Mezned, N.; Gomez, C.; Abdeljaouad, S. Hyperspectral field spectroscopy and SENTINEL-2 Multispectral data for minerals with high pollution potential content estimation and mapping. Sci. Total Environ. 2020, 740, 140160. [Google Scholar] [CrossRef]
- Salehi, S.; Mielke, C.; Brogaard Pedersen, C.; Dalsenni Olsen, S. Comparison of ASTER and Sentinel-2 spaceborne datasets for geological mapping: A case study from North-East Greenland. Geol. Surv. Den. Greenl. Bull. 2019, 43, e2019430205. [Google Scholar] [CrossRef]
- Castaldi, F.; Hueni, A.; Chabrillat, S.; Ward, K.; Buttafuoco, G.; Bomans, B.; Vreys, K.; Brell, M.; van Wesemael, B. Evaluating the capability of the Sentinel 2 data for soil organic carbon prediction in croplands. ISPRS J. Photogramm. Remote Sens. 2019, 147, 267–282. [Google Scholar] [CrossRef]
- Bin, W.; Ming, L.; Dan, J.; Suju, L.; Qiang, C.; Chao, W.; Yang, Z.; Huan, Y.; Jun, Z. A Method of Automatically Extracting Forest Fire Burned Areas Using Gf-1 Remote Sensing Images. In Proceedings of the IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 9953–9955. [Google Scholar] [CrossRef]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Sezgin, M.; Sankur, B. Survey over image thresholding techniques and quantitative performance evaluation. J. Electron. Imaging 2004, 13, 146–165. [Google Scholar] [CrossRef]
- Roy, D.P.; Boschetti, L.; Trigg, S.N. Remote sensing of fire severity: Assessing the performance of the normalized burn ratio. IEEE Geosci. Remote Sens. Lett. 2006, 3, 112–116. [Google Scholar] [CrossRef] [Green Version]
- Navarro, G.; Caballero, I.; Silva, G.; Parra, P.C.; Vázquez, Á.; Caldeira, R. Evaluation of forest fire on Madeira Island using Sentinel-2A MSI imagery. Int. J. Appl. Earth Obs. Geoinf. 2017, 58, 97–106. [Google Scholar] [CrossRef] [Green Version]
- Fernández-Manso, A.; Quintano, C.; Roberts, D.A. Can Landsat-Derived Variables Related to Energy Balance Improve Understanding of Burn Severity From Current Operational Techniques? Remote Sens. 2020, 12, 890. [Google Scholar] [CrossRef] [Green Version]
- Rapid Damage Assessment. 2019. Available online: https://effis.jrc.ec.europa.eu/about-effis/technical-background/rapid-damage-assessment (accessed on 28 September 2021).
- Fernández-Manso, A.; Fernández-Manso, O.; Quintano, C. SENTINEL-2A red-edge spectral indices suitability for discriminating burn severity. Int. J. Appl. Earth Obs. Geoinf. 2016, 50, 170–175. [Google Scholar] [CrossRef]
- Liu, M.; Popescu, S.; Malambo, L. Feasibility of burned area mapping based on ICESAT-2 photon counting data. Remote Sens. 2020, 12, 24. [Google Scholar] [CrossRef] [Green Version]
- Key, C.H.; Benson, N.C. Landscape assessment (LA). In FIREMON: Fire Effects Monitoring and Inventory System; Lutes Duncan, C., Keane, R.E., Caratti, J.F., Key, C.H., Benson, N.C., Sutherland, S., Gangi, L.J., Eds.; Gen. Tech. Rep. RMRS-GTR-164-CD; U.S. Department of Agriculture, Forest Service, Rocky Mountain Research Station: Fort Collins, CO, USA, 2006; Volume 64, p. LA-1-55. [Google Scholar]
- Hardtke, L.A.; Blanco, P.D.; del Valle, H.F.; Metternicht, G.I.; Sione, W.F. Semi-automated mapping of burned areas in semi-arid ecosystems using MODIS time-series imagery. Int. J. Appl. Earth Obs. Geoinf. 2015, 38, 25–35. [Google Scholar] [CrossRef]
- Ramo, R.; Chuvieco, E. Developing a random forest algorithm for MODIS global burned area classification. Remote Sens. 2017, 9, 1193. [Google Scholar] [CrossRef] [Green Version]
- Ban, Y.; Zhang, P.; Nascetti, A.; Bevington, A.R.; Wulder, M.A. Near Real-Time Wildfire Progression Monitoring with Sentinel-1 SAR Time Series and Deep Learning. Sci. Rep. 2020, 10, 1–15. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pinto, M.M.; Libonati, R.; Trigo, R.M.; Trigo, I.F.; DaCamara, C.C. A deep learning approach for mapping and dating burned areas using temporal sequences of satellite images. ISPRS J. Photogramm. Remote Sens. 2020, 160, 260–274. [Google Scholar] [CrossRef]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; Van Der Laak, J.A.; Van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Qi, X.; Yu, L.; Heng, P.A. DCAN: Deep contour-aware networks for accurate gland segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2487–2496. [Google Scholar]
- Gabruseva, T.; Poplavskiy, D.; Kalinin, A. Deep Learning for Automatic Pneumonia Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional Networks for Biomedical Image Segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Li, H.; Wang, C.; Cui, Y.; Hodgson, M. Mapping salt marsh along coastal South Carolina using U-Net. ISPRS J. Photogramm. Remote Sens. 2021, 179, 121–132. [Google Scholar] [CrossRef]
- Cao, K.; Zhang, X. An improved res-unet model for tree species classification using airborne high-resolution images. Remote Sens. 2020, 12, 1128. [Google Scholar] [CrossRef] [Green Version]
- Jiao, L.; Huo, L.; Hu, C.; Tang, P. Refined UNet: UNet-Based refinement network for cloud and shadow precise segmentation. Remote Sens. 2020, 12, 2001. [Google Scholar] [CrossRef]
- Rashkovetsky, D.; Mauracher, F.; Langer, M.; Schmitt, M. Wildfire Detection from Multisensor Satellite Imagery Using Deep Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7001–7016. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Farasin, A.; Colomba, L.; Garza, P. Double-Step U-Net: A Deep Learning-Based Approach for the Estimation of Wildfire Damage Severity through Sentinel-2 Satellite Data. Appl. Sci. 2020, 10, 4332. [Google Scholar] [CrossRef]
- Monaco, S.; Pasini, A.; Apiletti, D.; Colomba, L.; Garza, P.; Baralis, E. Improving Wildfire Severity Classification of Deep Learning U-Nets from Satellite Images. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 5786–5788. [Google Scholar]
- Ciprián-Sánchez, J.F.; Ochoa-Ruiz, G.; Rossi, L.; Morandini, F. Assessing the Impact of the Loss Function, Architecture and Image Type for Deep Learning-Based Wildfire Segmentation. Appl. Sci. 2021, 11, 7046. [Google Scholar] [CrossRef]
- Jadon, S.; Leary, O.P.; Pan, I.; Harder, T.J.; Wright, D.W.; Merck, L.H.; Merck, D.L. A comparative study of 2D image segmentation algorithms for traumatic brain lesions using CT data from the ProTECTIII multicenter clinical trial. In Medical Imaging 2020: Imaging Informatics for Healthcare, Research, and Applications; International Society for Optics and Photonics: Bellingham, WA, USA, 2020; Volume 11318, p. 113180Q. [Google Scholar]
- Monaco, S.; Pasini, A.; Apiletti, D.; Colomba, L.; Farasin, A.; Garza, P.; Baralis, E. Double-Step deep learning framework to improve wildfire severity classification. In Proceedings of the Workshops of the EDBT/ICDT 2021 Joint Conference, Nicosia, Cyprus, 23 March 2021; Volume 2841. [Google Scholar]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A Survey of Methods for Explaining Black Box Models. ACM Comput. Surv. 2018, 51, 1–42. [Google Scholar] [CrossRef] [Green Version]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef] [Green Version]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-CAM++: Generalized Gradient-Based Visual Explanations for Deep Convolutional Networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 839–847. [Google Scholar] [CrossRef] [Green Version]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar] [CrossRef] [Green Version]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. arXiv 2013, arXiv:1311.2901. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. arXiv 2014, arXiv:1312.6034. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for Simplicity: The All Convolutional Net. arXiv 2015, arXiv:1412.6806. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Ventura, F.; Cerquitelli, T.; Giacalone, F. Black-Box Model Explained Through an Assessment of Its Interpretable Features. In New Trends in Databases and Information Systems; Benczúr, A., Thalheim, B., Horváth, T., Chiusano, S., Cerquitelli, T., Sidló, C., Revesz, P.Z., Eds.; Springer International Publishing: Cham, Switzerland, 2018. [Google Scholar]
- Shapley, L.S. A value for n-person games. Contrib. Theory Games 1953, 2, 307–317. [Google Scholar]
- Schorr, C.; Goodarzi, P.; Chen, F.; Dahmen, T. Neuroscope: An Explainable AI Toolbox for Semantic Segmentation and Image Classification of Convolutional Neural Nets. Appl. Sci. 2021, 11, 2199. [Google Scholar] [CrossRef]
- Ma, J. Segmentation Loss Odyssey. arXiv 2020, arXiv:2005.13449. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Kamal, U.; Tonmoy, T.I.; Das, S.; Hasan, M.K. Automatic traffic sign detection and recognition using SegU-Net and a modified Tversky loss function with L1-constraint. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1467–1479. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Handa, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for robust semantic pixel-wise labelling. arXiv 2015, arXiv:1505.07293. [Google Scholar]
- Yakubovskiy, P. Segmentation Models Pytorch. 2020. Available online: https://github.com/qubvel/segmentation_models.pytorch (accessed on 28 September 2021).
- Gu, R.; Wang, G.; Song, T.; Huang, R.; Aertsen, M.; Deprest, J.; Ourselin, S.; Vercauteren, T.; Zhang, S. CA-Net: Comprehensive attention convolutional neural networks for explainable medical image segmentation. IEEE Trans. Med. Imaging 2020, 40, 699–711. [Google Scholar] [CrossRef]
- SentinelHub. Available online: https://www.sentinel-hub.com (accessed on 28 October 2021).
- Xu, H. Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery. Int. J. Remote Sens. 2006, 27, 3025–3033. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; pp. 56–61. [Google Scholar] [CrossRef] [Green Version]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- HPC@POLITO. 2019. Available online: https://hpc.polito.it/legion_cluster.php (accessed on 28 September 2021).
- Candra, D.S. Deforestation detection using multitemporal satellite images. In IOP Conference Series: Earth and Environmental Science; IOP Publishing: Bristol, UK, 2020; Volume 500, p. 012037. [Google Scholar]
- Poursanidis, D.; Traganos, D.; Reinartz, P.; Chrysoulakis, N. On the use of Sentinel-2 for coastal habitat mapping and satellite-derived bathymetry estimation using downscaled coastal aerosol band. Int. J. Appl. Earth Obs. Geoinf. 2019, 80, 58–70. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | BCE | Dice | B + D | B + S | sIoU |
|---|---|---|---|---|---|
| DS-UNet | 0.75 | 0.43 | 0.55 | 0.12 | 0.20 |
| DS-UNet++ | 0.74 | 0.57 | 0.46 | 0.21 | 0.20 |
| DS-SegU | 0.65 | 0.26 | 0.24 | 0.17 | 0.18 |
| DS-AttU | 0.72 | 0.45 | 0.44 | 0.29 | 0.22 |
| Model | BCE MSE | Dice MSE | B + D MSE | B + S MSE | BCE MSE·F1 | sIoU sIoU | sIoU MSE |
|---|---|---|---|---|---|---|---|
| DS-UNet | 1.32 | 1.30 | 1.42 | 1.83 | 1.33 | 2.26 | 1.73 |
| DS-UNet++ | 1.41 | 1.41 | 1.39 | 1.55 | 1.40 | 2.23 | 1.61 |
| DS-SegU | 1.66 | 1.82 | 1.88 | 2.05 | 1.79 | 2.97 | 2.17 |
| DS-AttU | 1.38 | 1.47 | 1.41 | 1.45 | 1.35 | 2.62 | 2.18 |
| Group | Sentinel-2 L2A Band | Central Wavelength (nm) |
|---|---|---|
| AER | Band 1—Coastal aerosol | 442.7 |
| RGB | Band 2—Blue | 492.4 |
| Band 3—Green | 559.8 | |
| Band 4—Red | 664.6 | |
| VRE | Band 5—Vegetation red edge | 704.1 |
| Band 6—Vegetation red edge | 740.5 | |
| Band 7—Vegetation red edge | 782.8 | |
| NIR | Band 8—NIR | 832.8 |
| Band 8A—Narrow NIR | 864.7 | |
| Band 9—Water vapour | 945.1 | |
| SWIR | Band 11—SWIR | 1613.7 |
| Band 12—SWIR | 2202.4 |
| Multi-Band | ||||
|---|---|---|---|---|
| AER | 0.75 | 0.02 | 0.64 | 0.83 |
| RGB | 0.60 | 0.04 | 1.36 | 2.19 |
| VRE | 0.73 | 0.03 | 0.97 | 1.30 |
| NIR | 0.81 | 0.04 | 0.74 | 0.87 |
| SWIR | 0.78 | 0.03 | 0.95 | 1.17 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Monaco, S.; Greco, S.; Farasin, A.; Colomba, L.; Apiletti, D.; Garza, P.; Cerquitelli, T.; Baralis, E. Attention to Fires: Multi-Channel Deep Learning Models for Wildfire Severity Prediction. Appl. Sci. 2021, 11, 11060. https://doi.org/10.3390/app112211060
Monaco S, Greco S, Farasin A, Colomba L, Apiletti D, Garza P, Cerquitelli T, Baralis E. Attention to Fires: Multi-Channel Deep Learning Models for Wildfire Severity Prediction. Applied Sciences. 2021; 11(22):11060. https://doi.org/10.3390/app112211060
Chicago/Turabian StyleMonaco, Simone, Salvatore Greco, Alessandro Farasin, Luca Colomba, Daniele Apiletti, Paolo Garza, Tania Cerquitelli, and Elena Baralis. 2021. "Attention to Fires: Multi-Channel Deep Learning Models for Wildfire Severity Prediction" Applied Sciences 11, no. 22: 11060. https://doi.org/10.3390/app112211060
APA StyleMonaco, S., Greco, S., Farasin, A., Colomba, L., Apiletti, D., Garza, P., Cerquitelli, T., & Baralis, E. (2021). Attention to Fires: Multi-Channel Deep Learning Models for Wildfire Severity Prediction. Applied Sciences, 11(22), 11060. https://doi.org/10.3390/app112211060