
A Multilayer CARU Framework to Obtain Probability Distribution for Paragraph-Based Sentiment Analysis


Abstract
:1. Introduction
2. Related Work
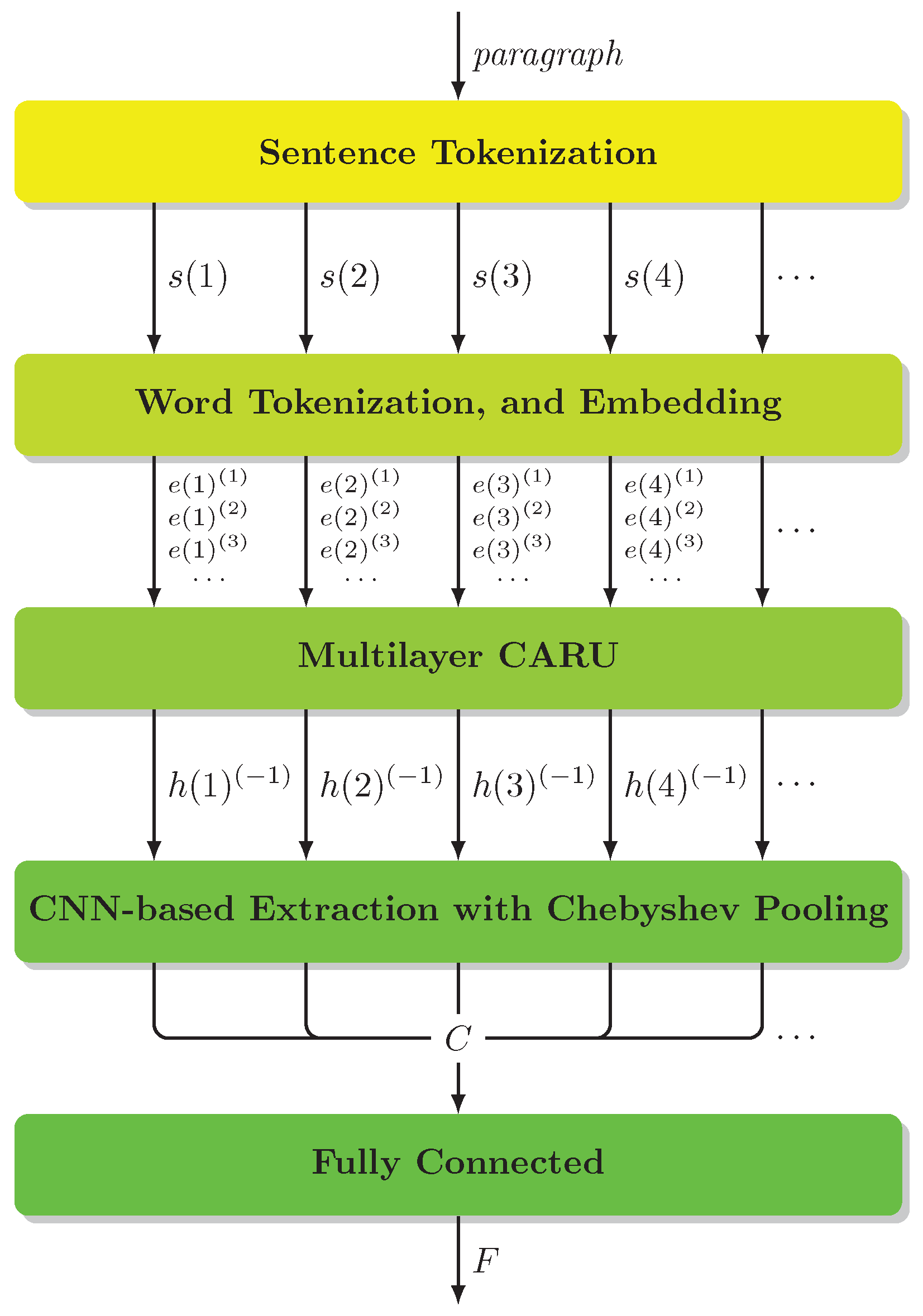
3. Framework
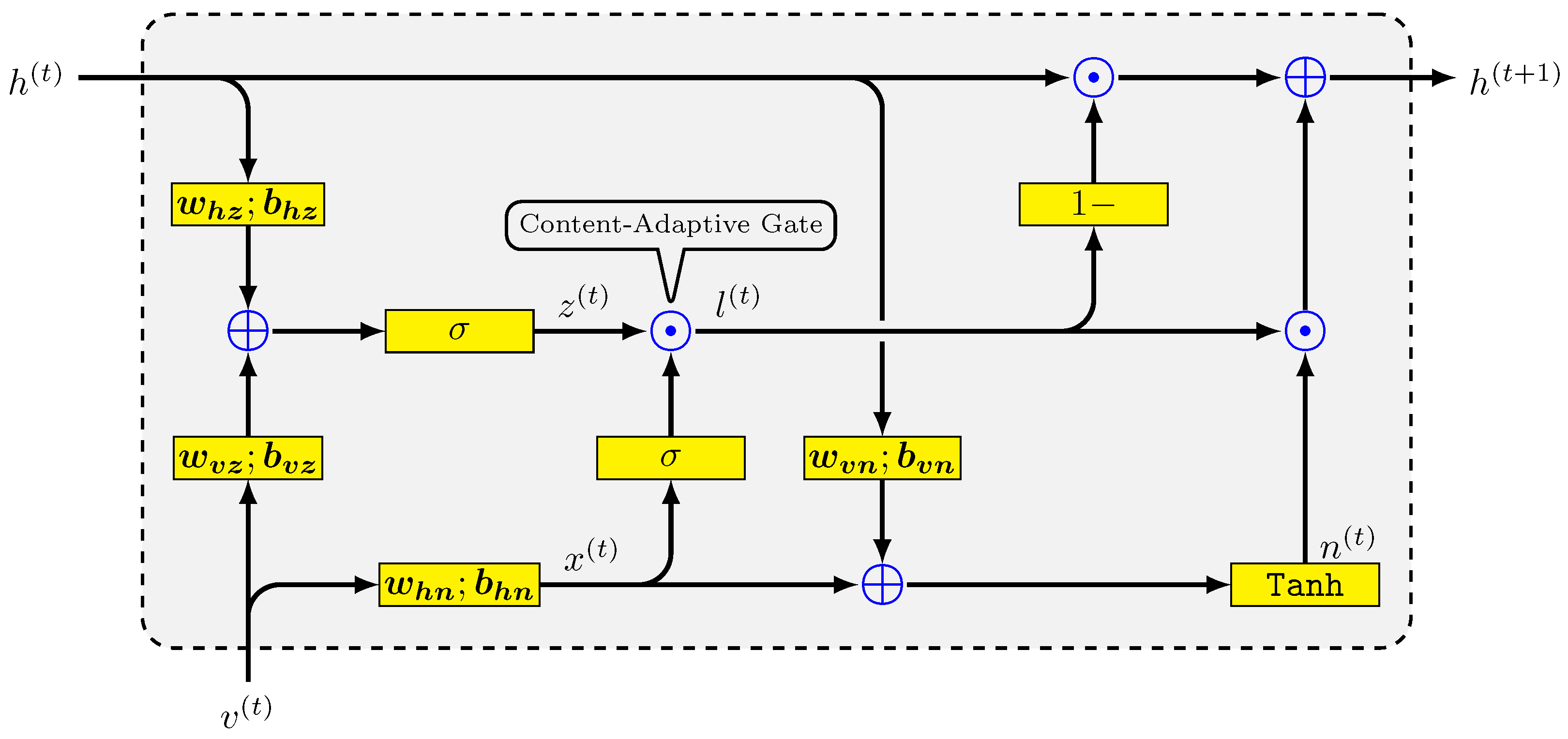
- The first step focused on the sentence analysis. We extended our previous work [8] to implement CARU in a multilayer architecture, where the output, i.e., a hidden state, of each CARU cell was connected to the input of the upper cell in a higher level. It also allowed different dynamic lengths of the data stream.
- The second step focused on feature extraction for the entire paragraph. After the multilayer CARU network, each sentence produced the latest hidden state for decision making. In order to extract the key information, we stacked a set of convolutional layers and then connected them through the Chebyshev pooling designed particularly for feature extraction.
3.1. Multilayer CARU
3.2. Chebyshev Pooling
3.2.1. Chebyshev’s Inequality
3.2.2. Derivative and Gradient
4. Implementation
| Algorithm 1: Pseudo code of CARU unit architecture, with regard to Figure 2. |
 |
| Algorithm 2: Pseudo code for complete multilayer CARU. |
 |
| Algorithm 3: Pseudo code for the whole processing of Chebyshev pooling. |
 |
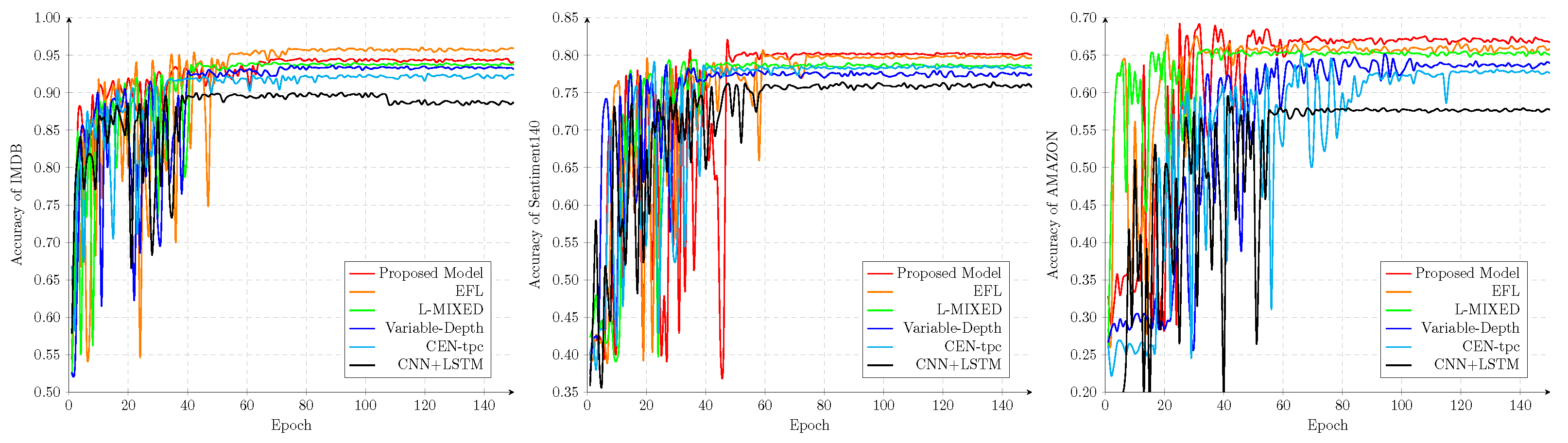
5. Experiment
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alakus, T.B.; Gonen, M.; Türkoglu, I. Database for an emotion recognition system based on EEG signals and various computer games—GAMEEMO. Biomed. Signal Process. Control. 2020, 60, 101951. [Google Scholar] [CrossRef]
- Alakus, T.B.; Turkoglu, I. Emotion recognition with deep learning using GAMEEMO data set. Electron. Lett. 2020, 56, 1364–1367. [Google Scholar] [CrossRef]
- Chan, K.H.; Im, S.K.; Ke, W. Variable-Depth Convolutional Neural Network for Text Classification. ICONIP (5). In Communications in Computer and Information Science; Springer: Berlin/Heidelberg, Germany, 2020; Volume 1333, pp. 685–692. [Google Scholar]
- Mikolov, T.; Kombrink, S.; Burget, L.; Cernocký, J.; Khudanpur, S. Extensions of recurrent neural network language model. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 5528–5531. [Google Scholar]
- Marcheggiani, D.; Täckström, O.; Esuli, A.; Sebastiani, F. Hierarchical Multi-label Conditional Random Fields for Aspect-Oriented Opinion Mining. ECIR. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8416, pp. 273–285. [Google Scholar]
- Alboaneen, D.A.; Tianfield, H.; Zhang, Y. Sentiment analysis via multi-layer perceptron trained by meta-heuristic optimisation. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 4630–4635. [Google Scholar]
- Hazarika, D.; Poria, S.; Vij, P.; Krishnamurthy, G.; Cambria, E.; Zimmermann, R. Modeling Inter-Aspect Dependencies for Aspect-Based Sentiment Analysis; NAACL-HLT (2); Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 266–270. [Google Scholar]
- Chan, K.H.; Ke, W.; Im, S.K. CARU: A Content-Adaptive Recurrent Unit for the Transition of Hidden State in NLP. ICONIP (1). In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12532, pp. 693–703. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation Learning: A Review and New Perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Mu, L.; Zan, H.; Zhang, K. Research on Chinese Parsing Based on the Improved Compositional Vector Grammar. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 649–658. [Google Scholar] [CrossRef]
- Goldberg, Y. Neural Network Methods for Natural Language Processing. Synth. Lect. Hum. Lang. Technol. 2017, 10, 1–309. [Google Scholar] [CrossRef]
- Munikar, M.; Shakya, S.; Shrestha, A. Fine-grained Sentiment Classification using BERT. In Proceedings of the 2019 Artificial Intelligence for Transforming Business and Society (AITB), Kathmandu, Nepal, 5 November 2019. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Xu, B.; Xu, J.; Tian, G.; Liu, C.L.; Hao, H. Semantic expansion using word embedding clustering and convolutional neural network for improving short text classification. Neurocomputing 2016, 174, 806–814. [Google Scholar] [CrossRef]
- Havaei, M.; Davy, A.; Warde-Farley, D.; Biard, A.; Courville, A.; Bengio, Y.; Pal, C.; Jodoin, P.M.; Larochelle, H. Brain tumor segmentation with Deep Neural Networks. Med. Image Anal. 2017, 35, 18–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Takase, S.; Okazaki, N.; Inui, K. Modeling semantic compositionality of relational patterns. Eng. Appl. Artif. Intell. 2016, 50, 256–264. [Google Scholar] [CrossRef] [Green Version]
- Bahdanau, D.; Chorowski, J.; Serdyuk, D.; Brakel, P.; Bengio, Y. End-to-end attention-based large vocabulary speech recognition. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016. [Google Scholar] [CrossRef] [Green Version]
- Zia, T. Hierarchical recurrent highway networks. Pattern Recognit. Lett. 2019, 119, 71–76. [Google Scholar] [CrossRef]
- Chan, K.H.; Im, S.K.; Ke, W. Multiple classifier for concatenate-designed neural network. Neural Comput. Appl. 2021. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Stewart, I.; Arendt, D.; Bell, E.; Volkova, S. Measuring, Predicting and Visualizing Short-Term Change in Word Representation and Usage in VKontakte Social Network; ICWSM; AAAI Press: Palo Alto, CA, USA, 2017; pp. 672–675. [Google Scholar]
- Khan, M.; Malviya, A. Big data approach for sentiment analysis of twitter data using Hadoop framework and deep learning. In Proceedings of the 2020 International Conference on Emerging Trends in Information Technology and Engineering (ic-ETITE), Vellore, India, 24–25 February 2020. [Google Scholar] [CrossRef]
- dos Santos, C.N.; Gatti, M. Deep Convolutional Neural Networks for Sentiment Analysis of Short Texts. In Proceedings of the COLING 2014, The 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 69–78. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Janvin, C. A Neural Probabilistic Language Model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Bengio, Y.; Senecal, J.S. Adaptive Importance Sampling to Accelerate Training of a Neural Probabilistic Language Model. IEEE Trans. Neural Netw. 2008, 19, 713–722. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, E.H.; Socher, R.; Manning, C.D.; Ng, A.Y. Improving Word Representations via Global Context and Multiple Word Prototypes; ACL (1); The Association for Computer Linguistics: Stroudsburg, PA, USA, 2012; pp. 873–882. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification. In Proceedings of the 23rd International Conference on Machine Learning—ICML ’06; ACM Press: New York, NY, USA, 2006. [Google Scholar] [CrossRef]
- Li, X.; Wu, X. Labeling unsegmented sequence data with DNN-HMM and its application for speech recognition. In Proceedings of the 9th International Symposium on Chinese Spoken Language Processing, Singapore, 12–14 September 2014. [Google Scholar] [CrossRef]
- Tang, D.; Wei, F.; Yang, N.; Zhou, M.; Liu, T.; Qin, B. Learning Sentiment-Specific Word Embedding for Twitter Sentiment Classification; ACL (1); The Association for Computer Linguistics: Stroudsburg, PA, USA, 2014; pp. 1555–1565. [Google Scholar]
- Chan, K.H.; Im, S.K.; Zhang, Y. A Self-Weighting Module to Improve Sentiment Analysis. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021. [Google Scholar] [CrossRef]
- Zhao, R.; Mao, K. Fuzzy Bag-of-Words Model for Document Representation. IEEE Trans. Fuzzy Syst. 2018, 26, 794–804. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Conneau, A.; Schwenk, H.; Barrault, L.; LeCun, Y. Very Deep Convolutional Networks for Text Classification; EACL (1); Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 1107–1116. [Google Scholar]
- Ren, R.; Liu, Z.; Li, Y.; Zhao, W.X.; Wang, H.; Ding, B.; Wen, J.R. Sequential Recommendation with Self-Attentive Multi-Adversarial Network. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 89–98. [Google Scholar]
- Chan, K.H.; Im, S.K.; Ke, W. Fast Binarisation with Chebyshev Inequality. In Proceedings of the 2017 ACM Symposium on Document Engineering, Valletta, Malta, 4–7 September 2017; pp. 113–116. [Google Scholar]
- Chan, K.H.; Pau, G.; Im, S.K. Chebyshev Pooling: An Alternative Layer for the Pooling of CNNs-Based Classifier. In Proceedings of the 2021 IEEE 4th International Conference on Computer and Communication Engineering Technology (CCET), Beijing, China, 13–15 August 2021. [Google Scholar] [CrossRef]
- Ghosh, B. Probability inequalities related to Markov’s theorem. Am. Stat. 2002, 56, 186–190. [Google Scholar] [CrossRef]
- Ogasawara, H. The multiple Cantelli inequalities. Stat. Methods Appl. 2019, 28, 495–506. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library; NeurIPS: San Diego, CA, USA, 2019; pp. 8024–8035. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Maas, A.L.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning Word Vectors for Sentiment Analysis; The Association for Computer Linguistics: Stroudsburg, PA, USA, 2011; pp. 142–150. [Google Scholar]
- Go, A.; Bhayani, R.; Huang, L. Twitter sentiment classification using distant supervision. CS224N Proj. Rep. Stanf. 2009, 1, 2009. [Google Scholar]
- Majumder, B.P.; Li, S.; Ni, J.; McAuley, J.J. Interview: Large-scale Modeling of Media Dialog with Discourse Patterns and Knowledge Grounding; EMNLP (1); Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 8129–8141. [Google Scholar]
- Kim, M.; Moirangthem, D.S.; Lee, M. Towards Abstraction from Extraction: Multiple Timescale Gated Recurrent Unit for Summarization; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016. [Google Scholar] [CrossRef] [Green Version]
- Chai, J.; Li, A. Deep Learning in Natural Language Processing: A State-of-the-Art Survey. In Proceedings of the 2019 International Conference on Machine Learning and Cybernetics (ICMLC), Kobe, Japan, 7–10 July 2019. [Google Scholar] [CrossRef]
- Sachan, D.S.; Zaheer, M.; Salakhutdinov, R. Revisiting LSTM Networks for Semi-Supervised Text Classification via Mixed Objective Function; AAAI Press: Palo Alto, CA, USA, 2019; pp. 6940–6948. [Google Scholar]
- Wang, S.; Fang, H.; Khabsa, M.; Mao, H.; Ma, H. Entailment as Few-Shot Learner. arXiv 2021, arXiv:2104.14690. [Google Scholar]
- Camacho-Collados, J.; Pilehvar, M.T. On the Role of Text Preprocessing in Neural Network Architectures: An Evaluation Study on Text Categorization and Sentiment Analysis; BlackboxNLP@EMNLP; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 40–46. [Google Scholar]
- Al-Shedivat, M.; Dubey, A.; Xing, E.P. Contextual Explanation Networks. J. Mach. Learn. Res. 2020, 21, 194:1–194:44. [Google Scholar]
- Chan, K.H.; Im, S.K.; Ke, W. VGGreNet: A Light-Weight VGGNet with Reused Convolutional Set. In Proceedings of the 2020 IEEE/ACM 13th International Conference on Utility and Cloud Computing (UCC), Leicester, UK, 7–10 December 2020. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | MTGRU [43] | RNN-LM [44] | Multilayer CARU |
|---|---|---|---|
| 1 | |||
| 2 | |||
| 3 | |||
| 4 | |||
| Chebyshev Pooling |
| Layer | MTGRU [43] | RNN-LM [44] | Multilayer CARU |
|---|---|---|---|
| 1 | |||
| 2 | |||
| 3 | |||
| 4 | |||
| Chebyshev Pooling |
| IMDB [40] | Sentiment140 [41] | AMAZON [42] | |
|---|---|---|---|
| Proposed Model | 94.89 | 80.90 | 66.49 |
| EFL [46] | 95.14 | 80.06 | 65.84 |
| L-MIXED [45] | 94.72 | 78.49 | 65.07 |
| Variable-Depth [3] | 93.57 | 77.42 | 63.51 |
| CEN-tpc [48] | 93.20 | 78.20 | 62.52 |
| CNN+LSTM [47] | 88.01 | 75.69 | 57.07 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ke, W.; Chan, K.-H. A Multilayer CARU Framework to Obtain Probability Distribution for Paragraph-Based Sentiment Analysis. Appl. Sci. 2021, 11, 11344. https://doi.org/10.3390/app112311344
Ke W, Chan K-H. A Multilayer CARU Framework to Obtain Probability Distribution for Paragraph-Based Sentiment Analysis. Applied Sciences. 2021; 11(23):11344. https://doi.org/10.3390/app112311344
Chicago/Turabian StyleKe, Wei, and Ka-Hou Chan. 2021. "A Multilayer CARU Framework to Obtain Probability Distribution for Paragraph-Based Sentiment Analysis" Applied Sciences 11, no. 23: 11344. https://doi.org/10.3390/app112311344
APA StyleKe, W., & Chan, K. -H. (2021). A Multilayer CARU Framework to Obtain Probability Distribution for Paragraph-Based Sentiment Analysis. Applied Sciences, 11(23), 11344. https://doi.org/10.3390/app112311344