1. Introduction
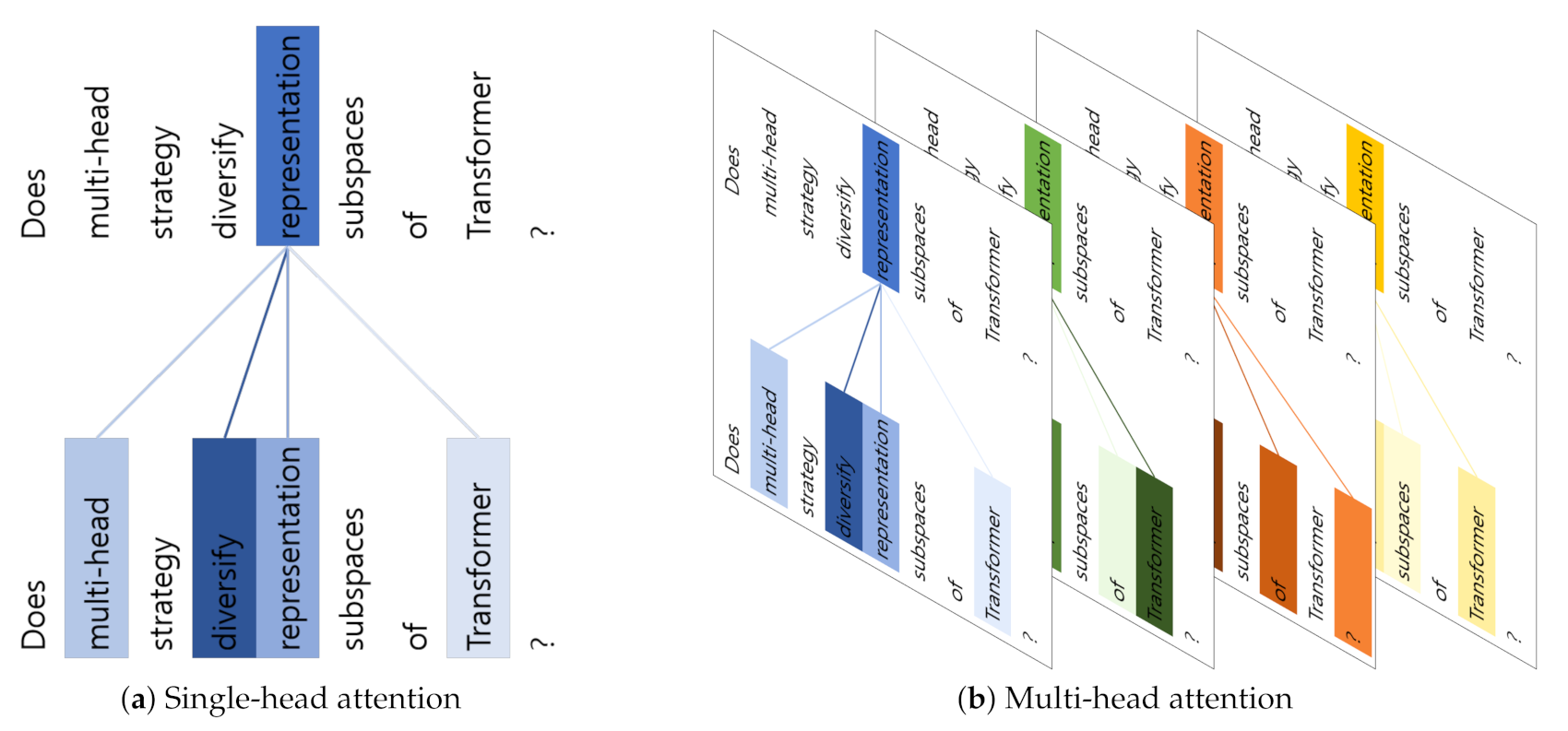
Since multi-head attention has been introduced by Vaswani et al. [
1], it has become a standard setting across various Natural Language Processing (NLP) tasks. Vaswani et al. have stated that multi-head strategy can collocate information from different representation subspaces and thus improves the performance of attention mechanism, whereas single-head attention averages the information. Most of the state-of-the-arts models report that multi-head attention is helpful to increase their performances, including BERT [
2] and XLNet [
3] for language understanding, Transformer [
1] for machine translation, and HIBERT [
4] for document summarizing.
Despite its huge empirical success and dominant usage, few studies have explored the roles of the multi-head strategy to give us a better understanding on how it enhances a model’s performance. Clark et al. [
5] have analyzed attention maps of multi-head attention and showed that certain heads are relevant to specific linguistic phenomena. Similarly, Voita et al. [
6] has analyzed that certain heads are respectively sensitive to various linguistic features by using layer-wise relevant propagation. Although these studies imply that there exists diversity of representation subspaces among multiple heads, their analyses are mainly focused on linguistic diversity.
In order to inspect essential effects of multi-head attention in representational subspaces, Li et al. [
7] have proposed the disagreement score which measures cosine similarity between two heads’ representation and maximized the disagreement score to diversify inter-head representations. Li et al. have shown that maximizing the disagreement score increases performance, which implies that inter-head statistics in multi-head attention are closely related to the model’s performance. However, disagreement score has its limitation since cosine similarity of two random vectors in high dimension are close to 1, as known as the curse of dimensionality.
To overcome the limitations of previous studies, we seek answers to following three fundamental questions; (1) Does multi-head strategy diversify the subspace representations of each head? (2) Can we finely optimize the degree of inter-head diversity without changing model’s architecture? and finally (3) Does controlling inter-head diversity improve a model’s performance?
We measure the inter-head similarity of multi-head attention with Singular Vector Canonical Correlation Analysis (SVCCA) [
8] and Centered Kernel Alignment (CKA) [
9], as they are recently developed tools to measure similarities of two deep representations. Applying these similarity measures, we empirically show that the diversity of multi-head representations does increase as the number of heads increases which is solid evidence supporting the statement of Vaswani et al. [
1] that the multi-head strategy utilizes diverse representational subspaces. Furthermore, we suggest three techniques to optimize the degree of diversity among heads without architectural change of a model.
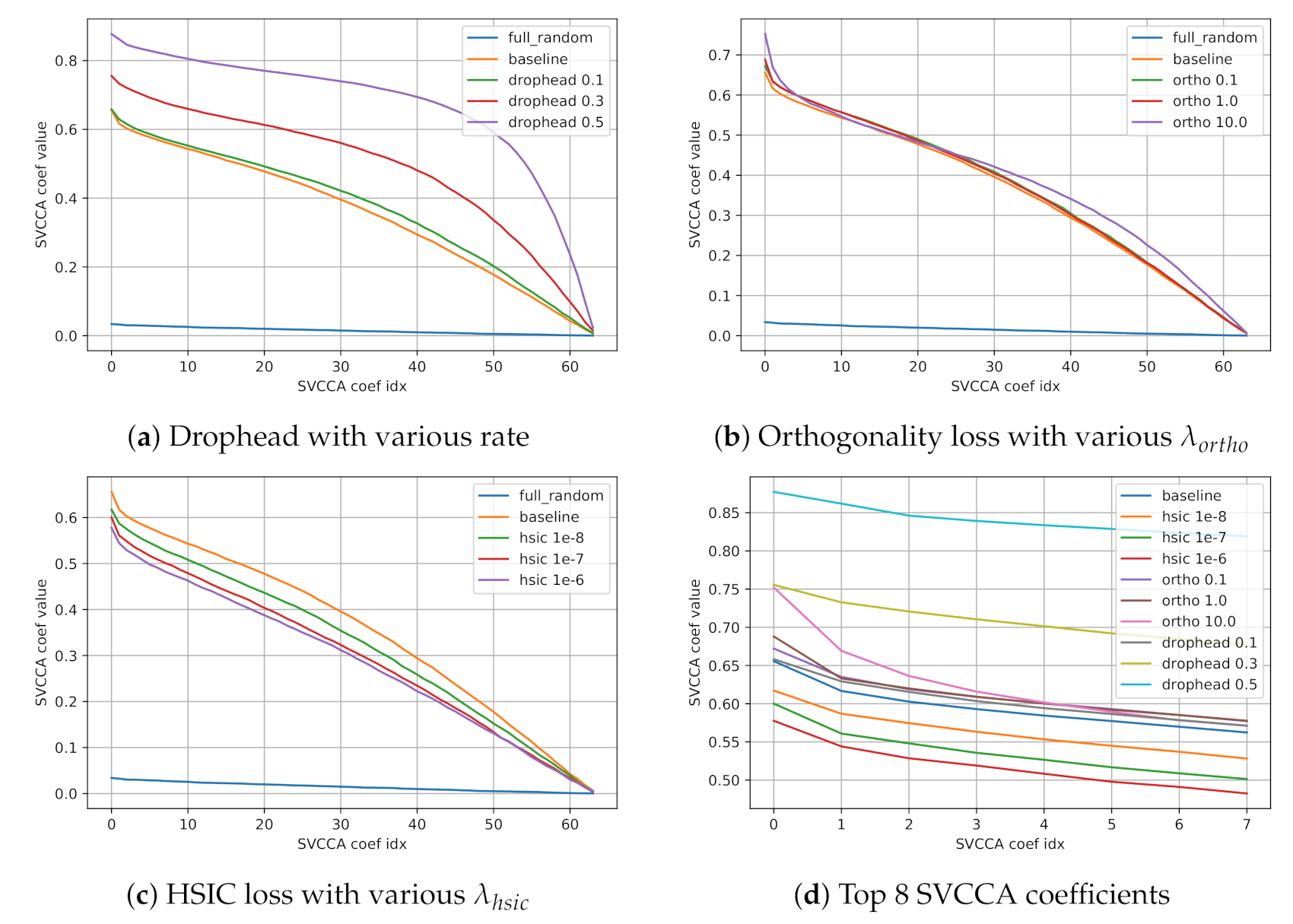
We first focus on trainability of CKA because CKA is differentiable and its gradients can be easily computed with popular frameworks such as Tensorflow [
10]. We adopt Hilbert-Schmidt Independence Criterion (HSIC) inspired by CKA as an augmented loss in order to directly diversify the inter-head diversity of a model.
Then, we revisit the orthogonality regularizer that adds disagreement loss [
7] between representations of heads. Surprisingly, opposed to the expectation of Li et al. [
7] expected, we empirically show that the orthogonality regularizer does not force a model’s inter-head diversity to increase measured in SVCCA and CKA. Instead, we find that it helps a model by encouraging top-few SVCCA directions to be closer which can be interpreted as core representations [
11].
Lastly, we inspect Drophead method [
12] by which a model randomly drops outputs of each head at training to show that we also can decrease the inter-head diversity without architectural change. Drophead reduces an effective number of heads at each training step and hence increases the inter-head similarity, while a model also benefits from the advantages of Dropout [
13].
We test our methods on various tasks including De-En IWSLT17 corpus [
14], Zh-En in UN parallel corpus [
15] on machine translation, and also PTB corpus on language modeling. Our results show that the suggested three methods complement each other and find the optimal inter-head diversity. The models with our methods achieve higher performances compared to their baselines in all experiments.
2. Related Works
As the multi-head strategy has shown its strength in many NLP tasks, there have been several attempts to analyze it with various approaches. By evaluating attention weights of ambiguous nouns in machine translation, Tang et al. [
16] have shown that multi-head attention tends to focus on ambiguous tokens more than general tokens. Clark et al. [
5] and Raganato et al. [
17] also have analyzed attention weights and concluded that each head plays different roles to understand syntactic features. Voita et al. [
6] and Michel et al. [
18] have claimed that most of the heads can be pruned once the model trained as they have analyzed the multi-head mechanism via layer-wise relevant propagation and ablating heads respectively.
On the other hand, several works have tried to analyze the similarity between representation spaces of neural networks in favor of achieving interpretability. Li et al. [
19] have proposed alignment methods with a correlation of neurons’ responses and claimed that core representations are shared between different networks while some rare representations are learned only in one network. More recently, Raghu et al. [
8] have first applied CCA as a similarity measure and proposed SVCCA in order to pick out perturbing directions from deep representations, and Morcos et al. [
20] have suggested Projection Weighted CCA (PWCCA) as a method to make SVCCA more reflective to the subspaces of representations via projection. Kornblith et al. [
9] have proposed CKA as a more robust similarity measure to small numbers of samples using a normalized index of HSIC with kernel methods.
Towards the interpretability of the deep representation, some studies have utilized similarity measures of deep representations. Maheswaranathan et al. [
21] have applied CCA, SVCCA, and CKA to Recurrent Neural Networks (RNN) and discovered that the geometry of RNN varies by tasks, but the underlying scaffold is universal. Kudugunta et al. [
22] have applied SVCCA across languages on multilingual machine translation to show there are shared representations among language representations. Bau et al. [
11] also have applied SVCCA to identify meaningful directions in machine translation and showed that top-few directions in SVCCA similarity are core representations since they are critical to a model’s performance when erased.
Closely related to our orthogonal loss, decorrelation methods have been proposed in node level [
23,
24,
25] and in group of nodes level [
7,
26]. Rodriguez et al. [
23], Xie et al. [
24], and Bansal et al. [
25] have shown that decorrelating each node through orthogonal constraint can achieve higher performances. Li et al. [
7] have applied the decorrelating term to multi-head attention, which inspires us to use orthogonal constraints in order to control inter-head diversity. Gu et al. [
26] have showed that cosine similarity based constraint in group of nodes can achieve higher performances, as it improves generalization capacity of the model.
5. Inter-Head Similarity Analysis
In this section, we investigate how SVCCA and CKA values change with respect to the number of heads. By analyzing the diversity of representation subspaces, we show that how SVCCA and CKA reflect the dynamics of inter-head similarity in terms of the numbers of heads.
5.1. Experimental Details for Similarity Analysis
Data and Setups: We choose De→En IWSLT17 machine translation task [
14] for our analysis in this section. Training set consists of 223,162 sentences, development set consists of 8130 sentences, and test set consists of 1116 sentences. To tokenize the corpus, we use Byte Pair Encoding [
30] with a vocabulary size of 16,384. We use Transformer [
1] architectures with various numbers of heads and hidden dimension sizes for comparison. For all models, we use 6 layers for encoder’s self-attention, decoder’s self-attention, and encoder-decoder attention modules.
Performances of trained models:Table 1 shows BLEU scores of models with various hidden dimension sizes and numbers of heads. As represented in
Table 1, increasing hidden size
d results in higher BLEU performances with a fixed number of heads, although increasing the number of heads does not always assure higher performance with fixed hidden size.
5.2. Applying SVCCA and CKA
In order to verify whether the multi-head strategy affects models’ representation subspaces, we examine SVCCA statistics between representations of heads in each model. To utilize SVCCA and CKA, we collect responses of each head at the last layers of three modules (encoder’s self-attention, decoder’s self-attention, and encoder-decoder attention) from development dataset consisting of num_sentence sentences, so that we have many d-dimensional vectors. We compare nine models with a number of heads and hidden size in order to examine how those architectural parameters change inter-head diversity. We report our results of the last layer of the encoder-decoder attention module only, yet we find the same tendency through every layer of every module.
5.3. Analysis on Inter-Model Similarity
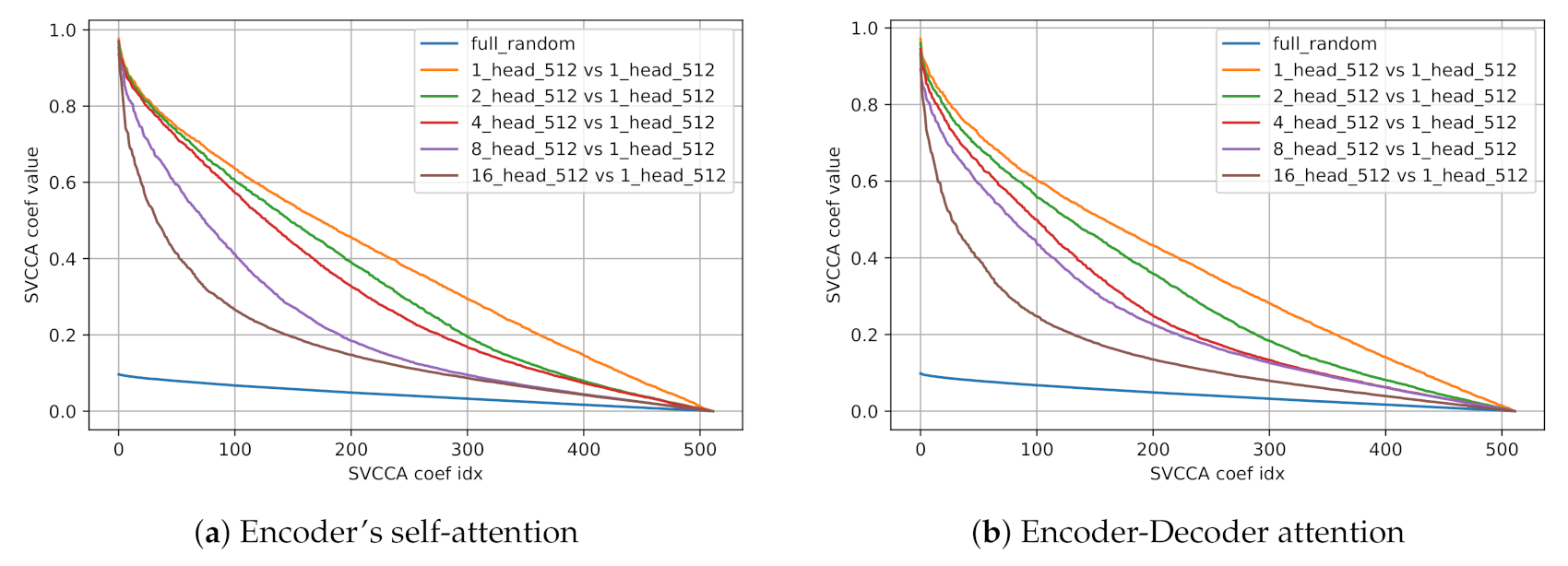
We first examine SVCCA statistics of representations of five models versus representation of a single-headed model. We compare five models with varying numbers of heads ( and 16) and fixed hidden size d as 512.
As shown in
Table 2, SVCCA similarities between multi-headed models and a single-headed model, we can see that the response of a model is getting more dissimilar to a single-headed model as the number of heads increases. SVCCA coefficient curves also show similar results in
Figure 2. SVCCA coefficients drop more rapidly with large number of heads in every layer. These results indicate that multi-head strategy can induce a model to find some representations uncorrelated to a single-headed model while its core representations remain, as shown as top few SVCCA coefficients are high.
5.4. Does Multi-Head Strategy Diversify a Model’s Representation Subspaces?
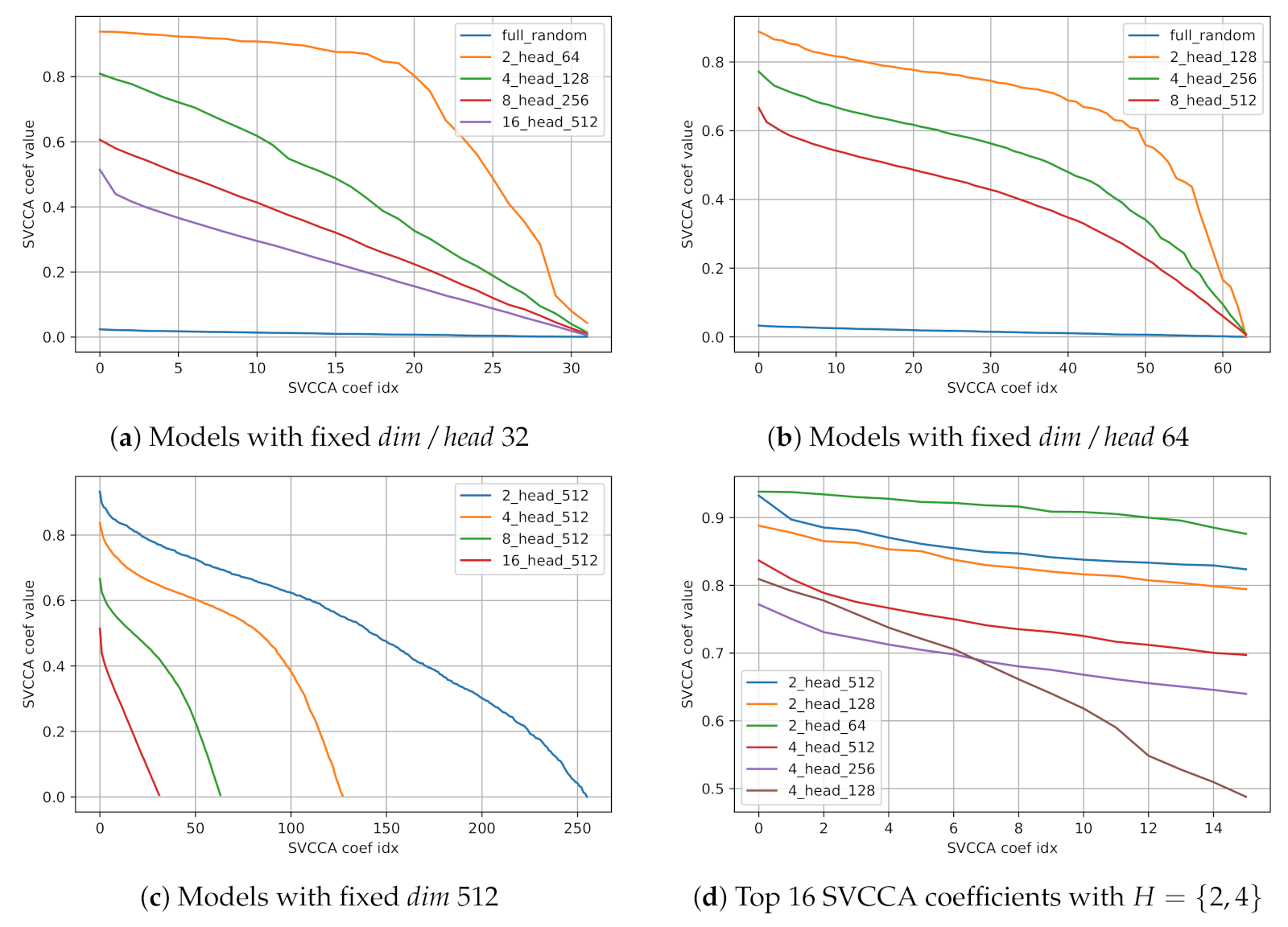
Table 3 shows inter-head similarity using SVCCA and CKA of each model. Both inter-head similarity measures using SVCCA and CKA show a persistent tendency that the inter-head similarity of each model decreases as the number of heads increases. On the other hand, we observe that increasing hidden dimension size
d does not meaningfully affect the inter-head similarity with a fixed number of heads.
In addition to
Table 3, we plot SVCCA coefficient curves of inter-head similarity in
Figure 3. With various number of heads
and fixed
((a) and (b) in
Figure 3), we observe that increasing number of heads make SVCCA coefficients smaller, indicating that inter-head diversity also increases. We also observe the same tendency with fixed
((c) in
Figure 3), while we cannot find any consistency of inter-head similarity with fixed number of heads ((d) in
Figure 3). Besides, we observed an interesting feature of SVCCA similarity curves that well-trained models have steep slopes on top-few SVCCA coefficients. We later discuss the steepness of top-few SVCCA coefficients in
Section 6. Our analysis of inter-head similarity measured by SVCCA and CKA statistically support the hypothesis that multi-head attention diversifies deep representations.
7. Conclusions
In this paper, we analyze the inter-head similarity of multi-head attention using SVCCA and CKA to unveil representation of each heads’ subspaces. We show an empirical proof that multi-head attention diversifies its representations as the number of heads increases. Based on our observation, we hypothesize that there is an optimal degree of inter-head diversity that fully utilizes a model’s capability. Then, we introduce three methods to control the degree of inter-head diversity; (1) HSIC regularizer, (2) the orthogonality regularizer revisited, and (3) Drophead method. The three methods are all able to fine-tune the inter-head diversity without architectural change. We show that HSIC regularizer diversifies the inter-head diversity and Drophead works the other way, whereas the orthogonality regularizer gathers the core representations of multi-head attention. Finally, we empirically show that controlling inter-head diversity can make the model utilize its own capability better resulting in higher performances on various machine translation and language modeling tasks. Our methods to control inter-head diversity can be easily applied to every model that uses multi-head attention including Transformer, BERT, and XLNet.








{kind=link}
{kind=link}
{kind=link}
{kind=link}