
Emulating Cued Recall of Abstract Concepts via Regulated Activation Networks




Abstract
:1. Introduction
- Distrubuted: Multimodal approaches such as artificial neural networks (ANNs), including the restricted Boltzmann machine (RBM) [30], deep neural networks [31], stacked auto-encoders [32], and convolution neural networks (CNN) [33], have significant contributions in feature recognition [34] and distributed memory representation [35]. Methods like Random Forests have also been used in studies related to visual attention [36].
- Hybrid: Cognitive architectures like Connectionist Learning with Adaptive Rule Induction On-line (CLARION) [37] simulate scenarios related to cognitive and social psychology.
2. Related Work
3. RAN Methodology to Simulate Recall Operations
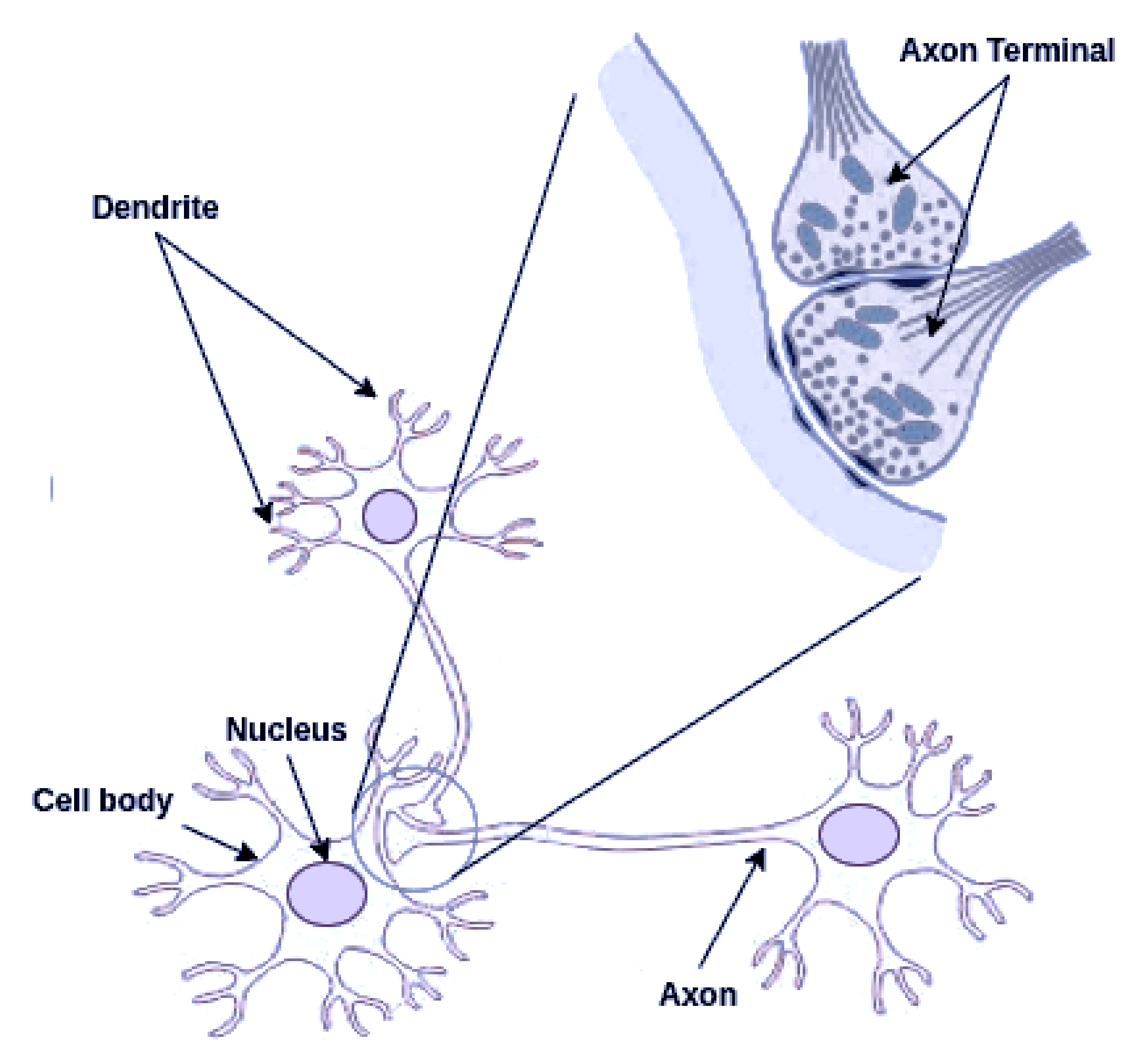
3.1. Biological Inspiration of Regulation Operation on RAN’s Modeling
3.2. Abstract Concept Modeling with RAN
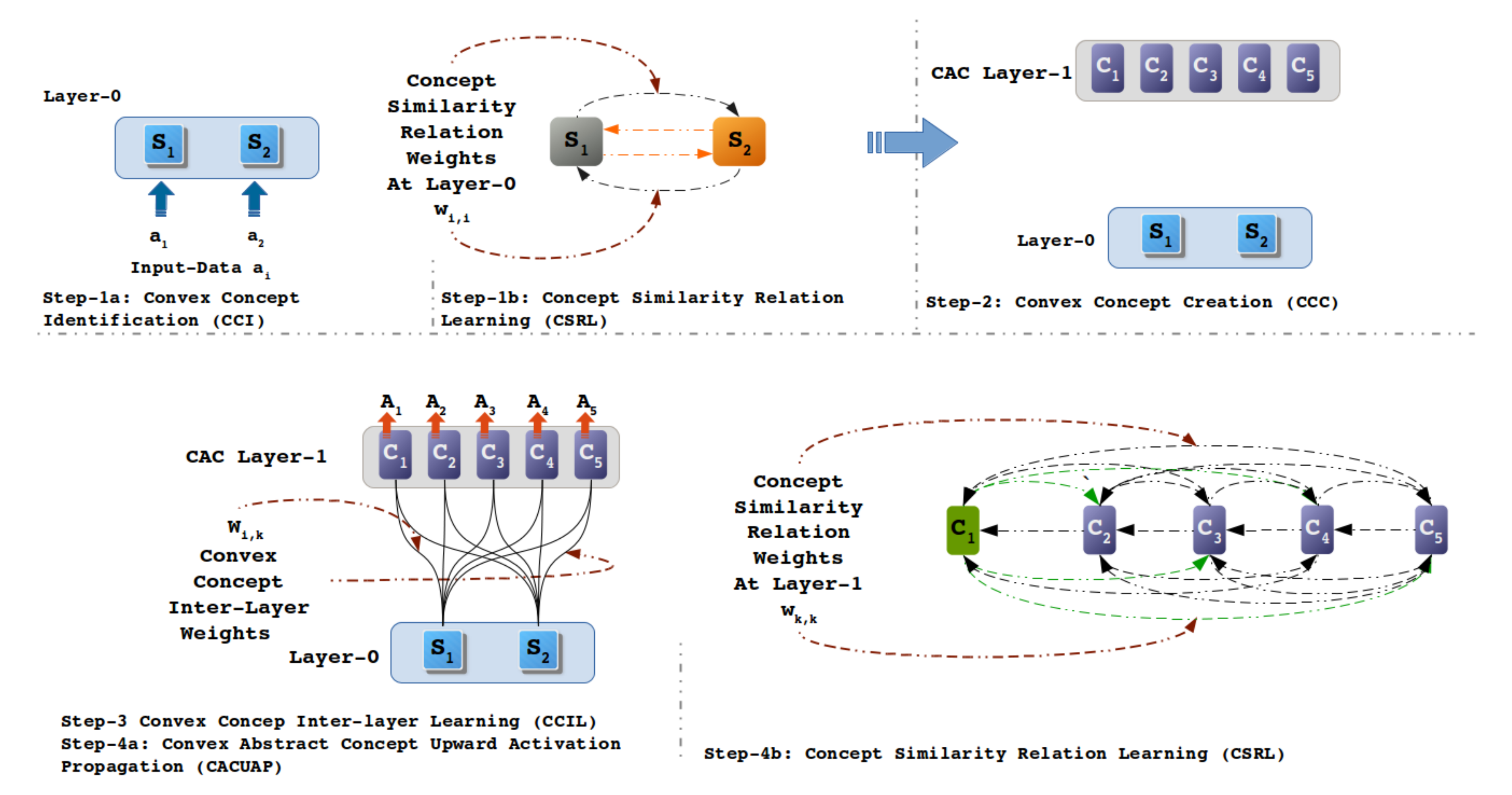
3.2.1. Step 1a: Convex Concept Identification (CCI)
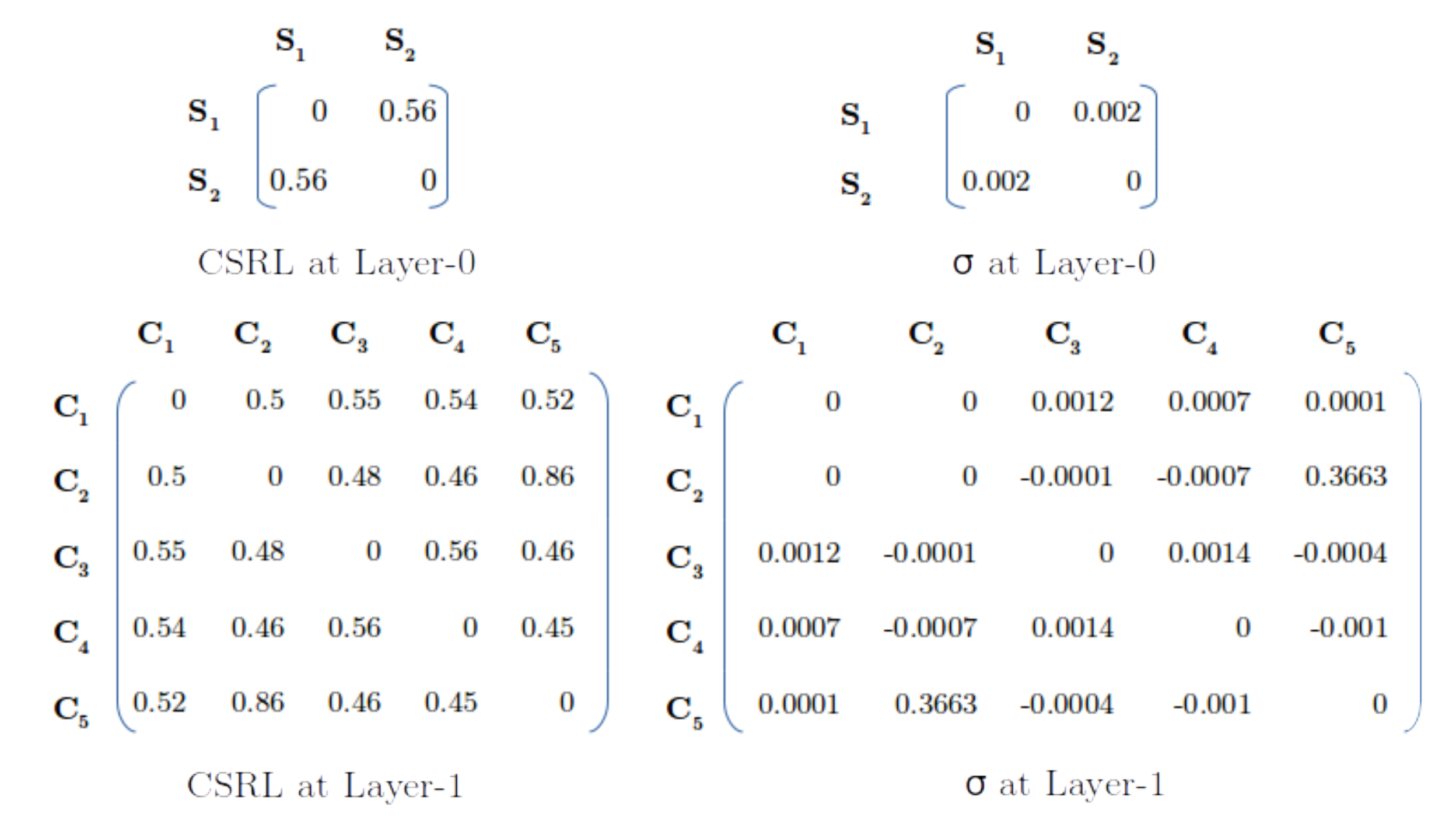
3.2.2. Step 1b and Step 4b: Concept Similarity Relation Learning (CSRL)
3.2.3. Step 2: Convex Abstract Concept Creation (CACC)
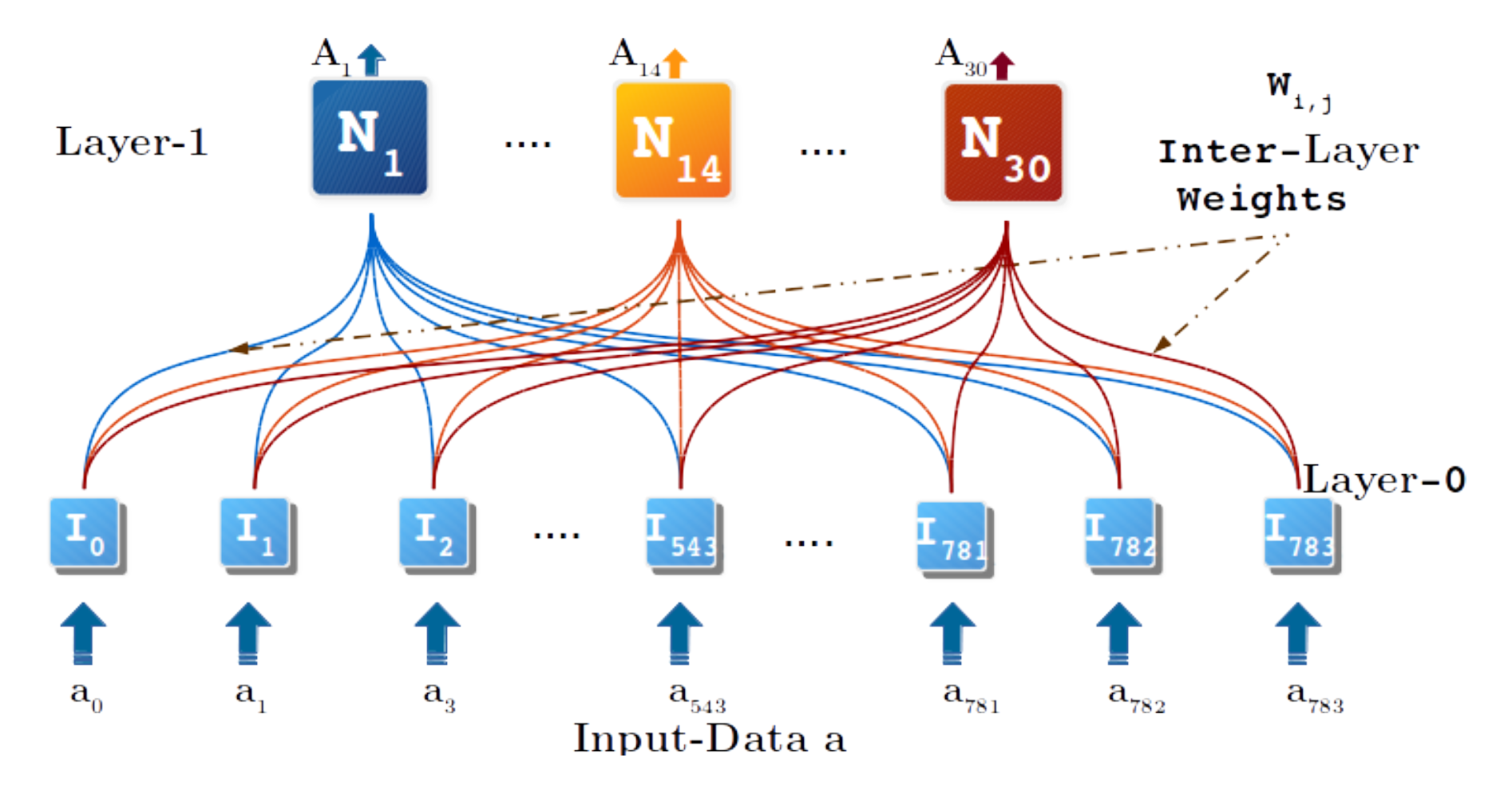
3.2.4. Step 3: Convex Concept Inter-Layer Learning (CCILL)
3.2.5. Step 4a: Convex Abstract Concept Upward Activation Propagation (CACUAP)
3.3. Regulation Mechanism
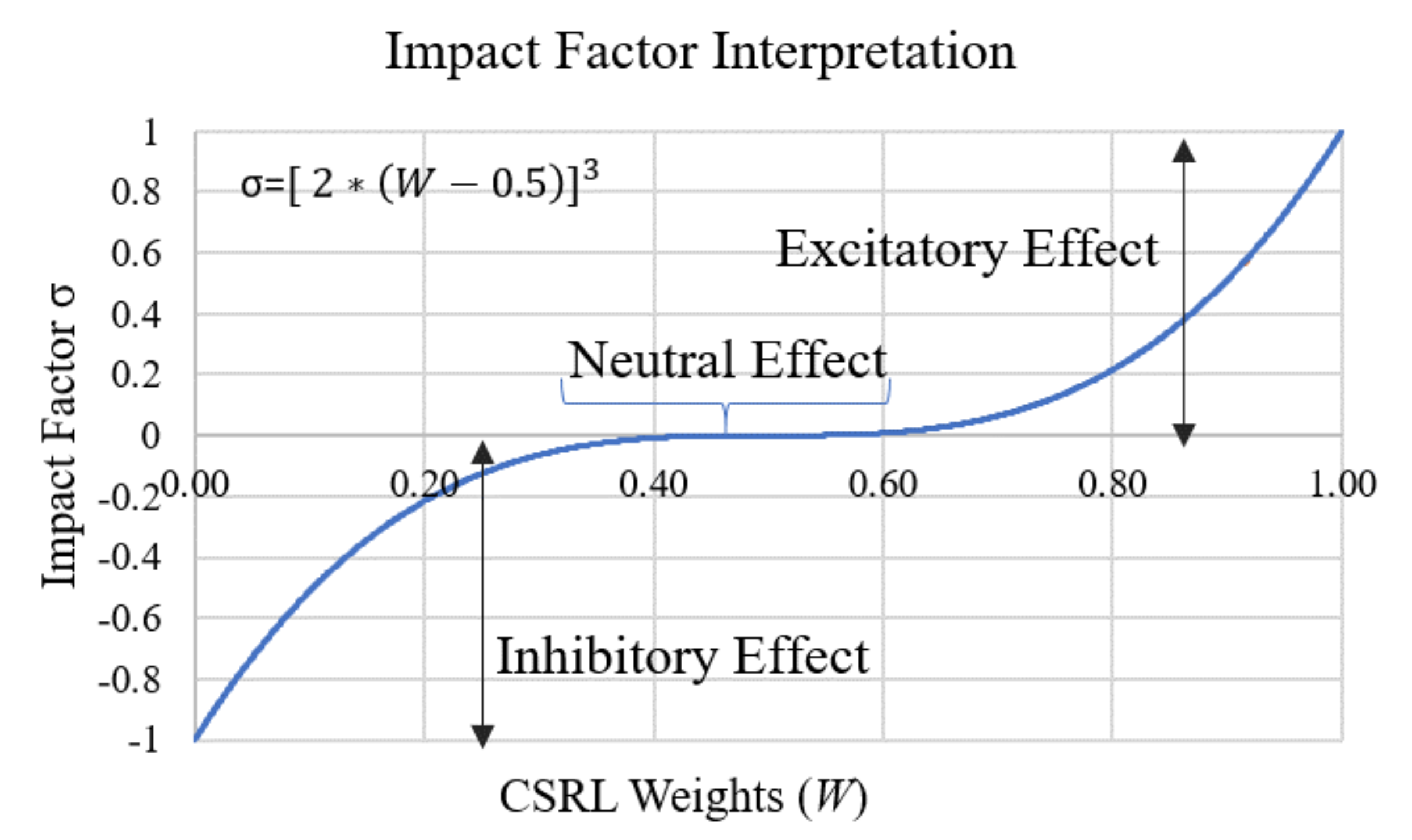
3.3.1. Impact Factor () Construction and Interpretation
3.3.2. Intra-Layer Activation
3.3.3. Intra-Layer Regulation
| Algorithm 1: Intra-Layer Regulation |
 |
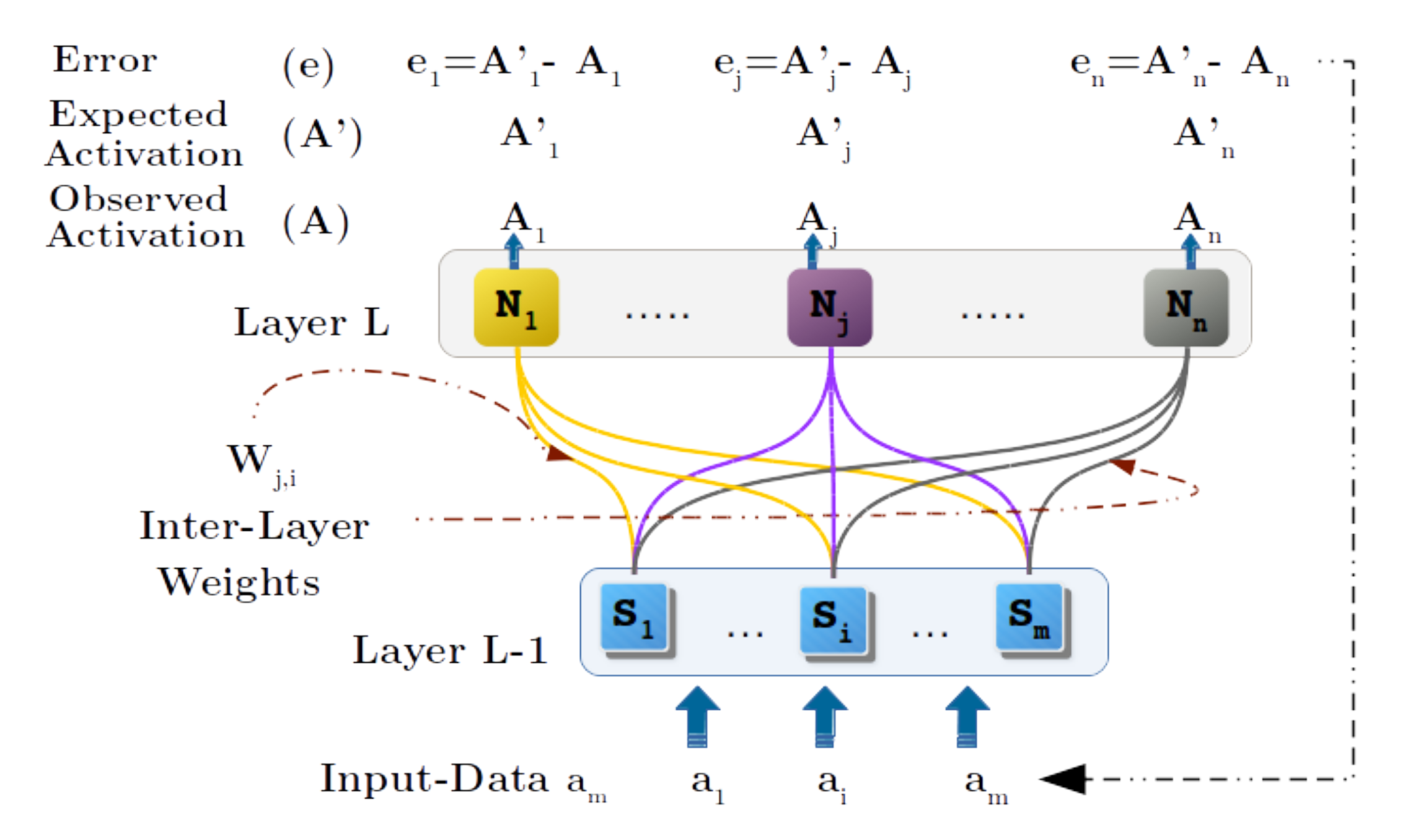
3.4. Geometric Back-Propagation Operation
3.5. Recall Demonstration with Toy-Data
3.5.1. Single-Cue Recall (SCR) Experiment
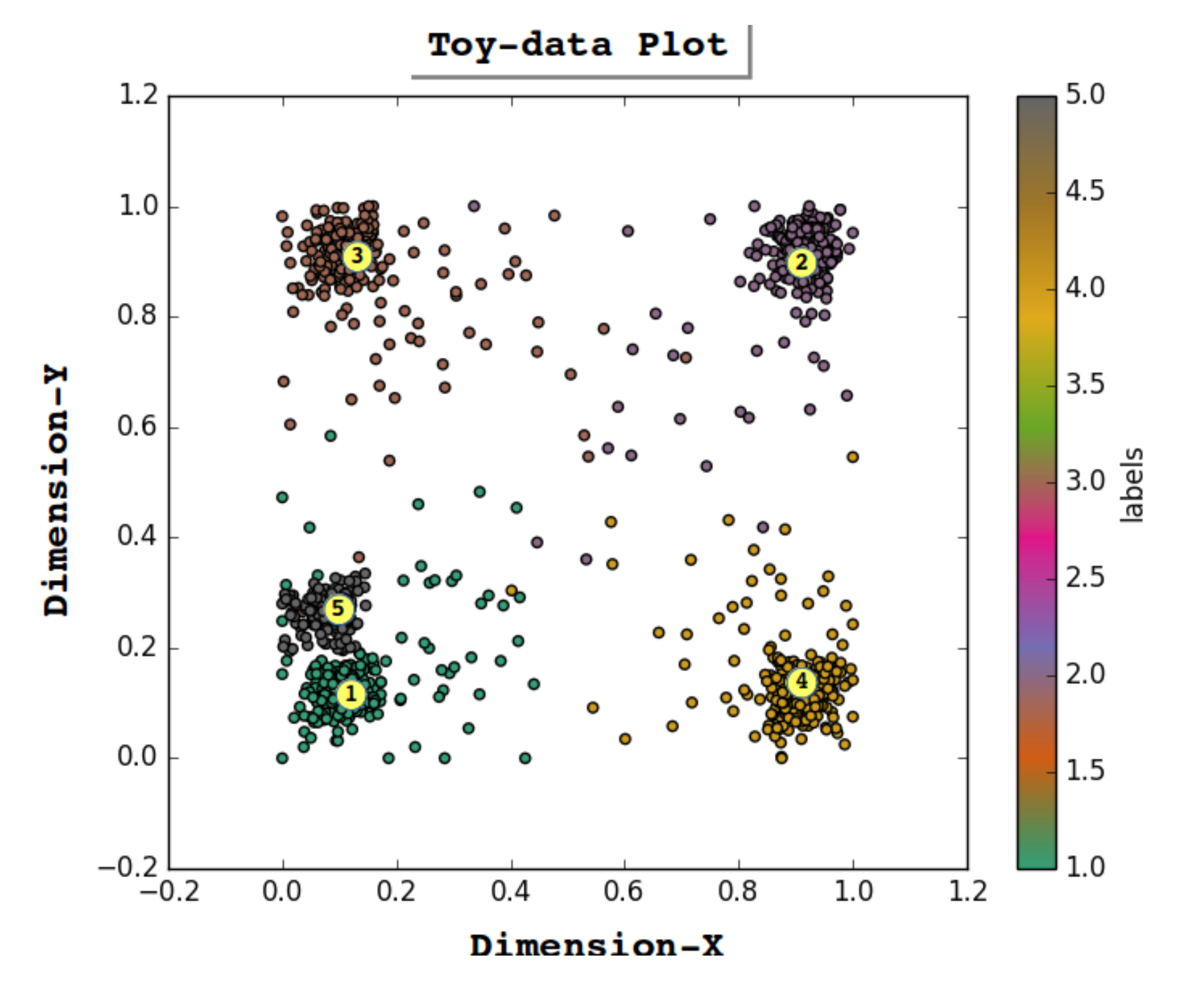
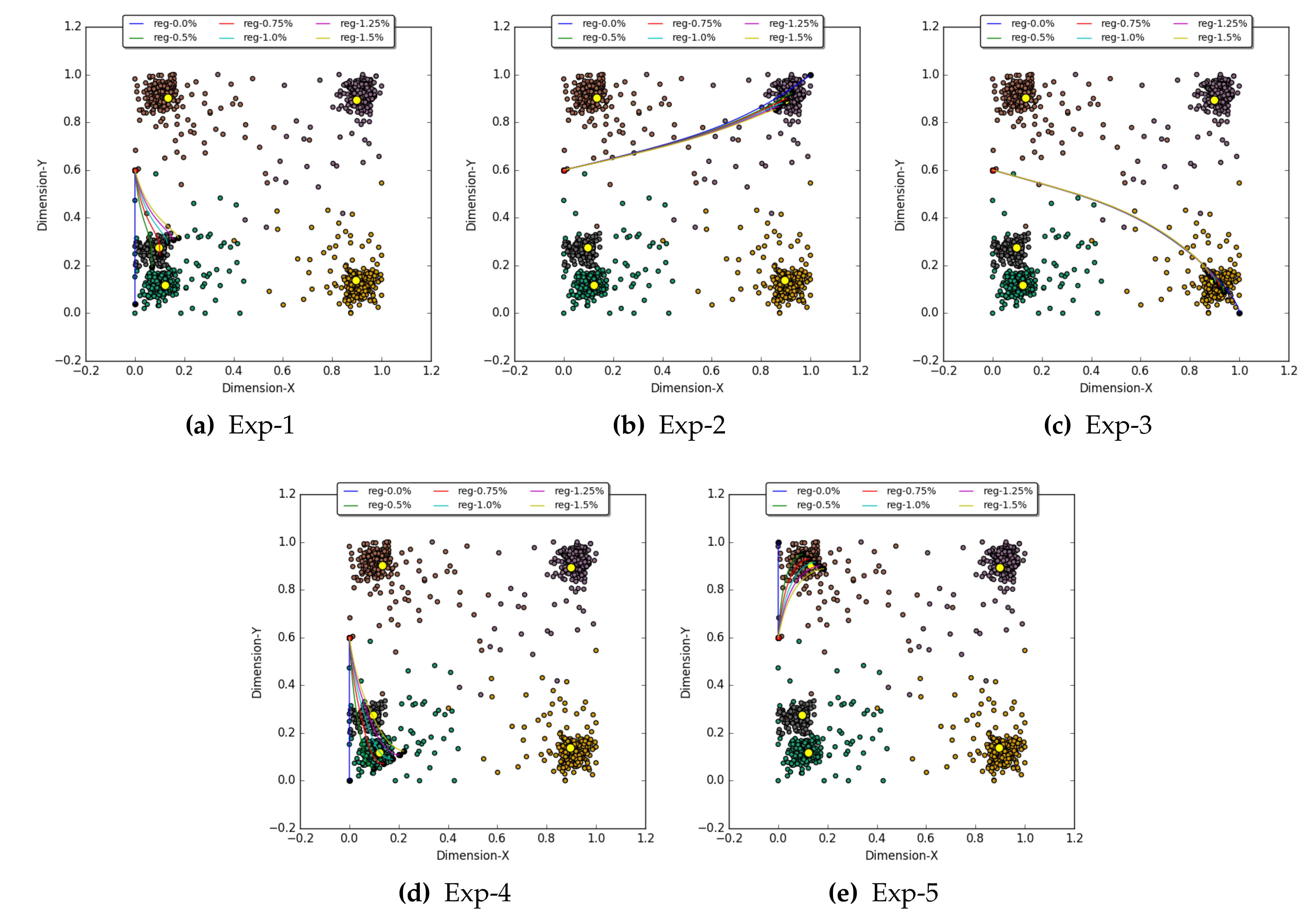
- Exp-1: This is the first experiment in which we injected an E-A vector [0, 0, 0, 0, 1] of activation at abstract concept layer 1. The objective was to recall activations at input layer 0 for which a very high activation was observed at node C at layer 1 and comparatively lower activation for the other four nodes at layer 1. The GBP algorithm was executed six times with an E-A of [0, 0, 0, 0, 1] for the six different regulation factors (). The observation for Exp-1 (see Table 1) shows that with a of %, the maximum activation of was observed at node C. As expected, the node C received good activation because nodes C and C represent clusters 1 and 5 (see Figure 3), which are close to one another. Figure 8a shows the six trajectories for the six regulation factors; each trajectory is formed by one thousand iterations. In Figure 8a, the yellow marker shows the CRDP of cluster C and the trajectory with of % converge closest to this CRPD. Thus, an activation vector [0.1, 0.24] is recalled at input nodes [S, S] for the given E-A vector [0, 0, 0, 0, 1].
- Exp-2: In this experiment, the E-A provided to the GBP algorithm was [0, 0, 0, 1, 0] to recall activation at layer 0, which is strongly represented by node C. For each regulation factor, the GBP algorithm was run; the O-As obtained at layer 1 are listed in Table 1, and the corresponding recalled activation at layer 0 is shown in Figure 8b. From the observations, it can be deduced that the experiment with of % produced the best outcome and recall activation [0.9, 0.9] for input layer 0.
- Exp-3: In this experiment, the GBP algorithm was supplied with an E-A vector of [0, 0, 1, 0, 0] to recall the input layer 0 vector, which is represented by node C at layer 1. Figure 8c and Table 1 shows the recall trajectories at layer 0 and the O-A vector at layer 1, respectively. The experiment with the regulation of % displayed the best representation. A vector [0.92, 0.11] was recalled at layer 0 for the injected E-A vector.
- Exp-4: The aim of this experiment was to recall an input vector that closely represents the abstract concept node C by feeding the GBP algorithm with an E-A vector of [0, 1, 0, 0, 0]. After applying the six regulation factors to each GBP operation, it was observed that the experiment with of % displayed the best result. Table 1 shows the O-A for the E-A. Figure 8d shows the trajectories of the recalled values and shows the best outcome with of % that converges to an activation vector [0.14, 0.07].
- Exp-5: This experiment shows the recall vector obtained by initializing an E-A vector [1, 0, 0, 0, 0] with all GBP experiments with the six regulation values. Unlike the previous experiments, the best O-A was obtained with a regulation factor of 1%. Figure 8d shows the recall outcome for all six regulation factors. At input layer 0, the recall operation with of 1% results into an activation vector [0.15, 0.91] for the given E-A.
| Algorithm 2: Geometric Back-Propagation Operation |
 |
3.5.2. Multiple-Cue Recall (MCR) Experiment
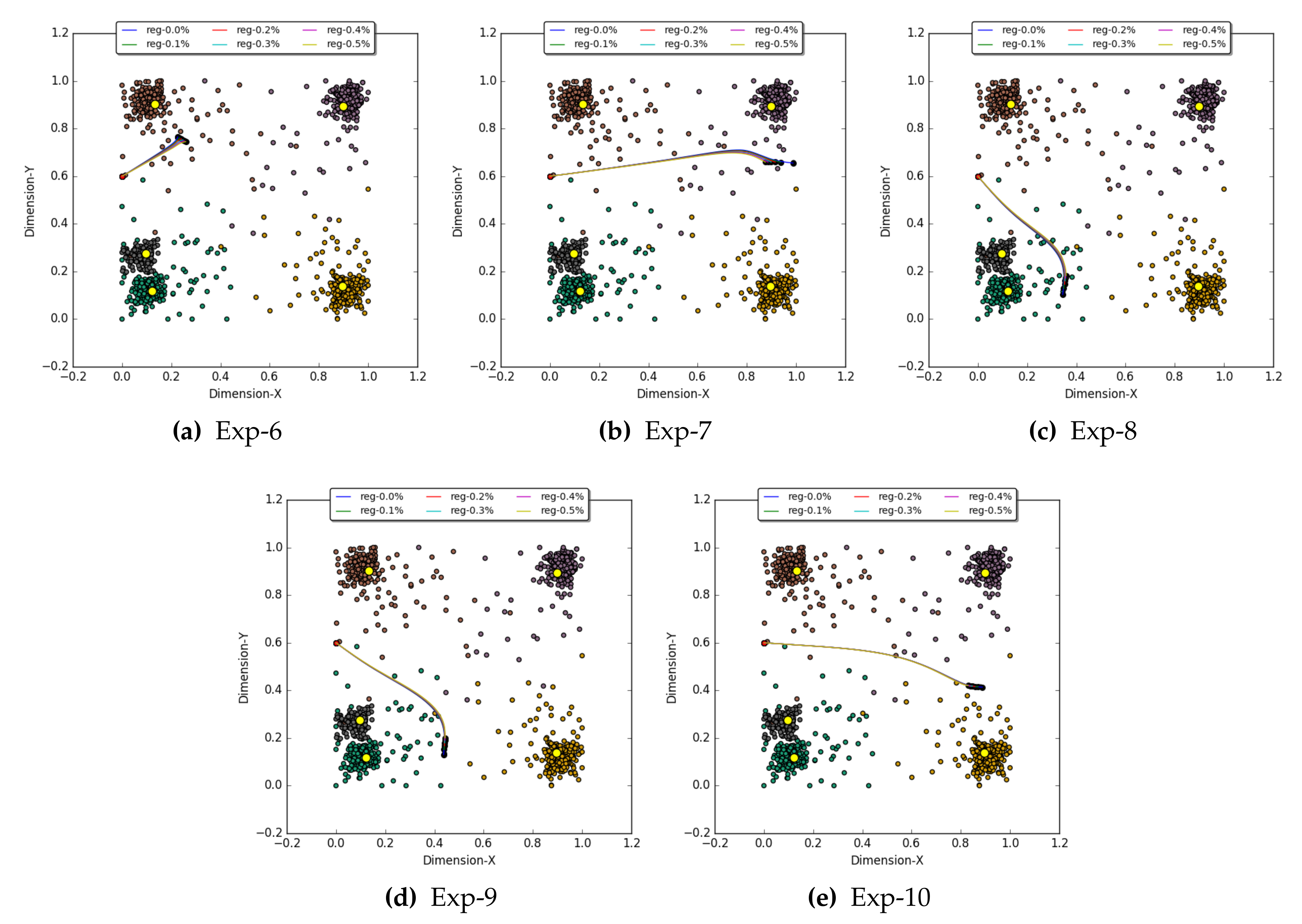
- Exp-6: In this experiment, an E-A vector of [0.57, 0.16, 0.06, 0.15, 0.25] was provided to the GBP algorithm. With this E-A, we wanted to recall activation at input layer 0, that is 57%, 16%, 06%, 15% and 25% represented by nodes C, C, C, C, and C, respectively. Table 2 lists the O-A observed for the six regulation factors. The results with of 0% and % show the outcome, which is almost identical to that of E-A. The E-R vector of this experiment was [0.2256, 0.7610]. With of 0% and %, the observed recall was [0.2260781, 0.7647118] and [0.2343844, 0.7602842], respectively, which are also similar to the expected recall vector. Figure 9a shows the trajectories of all the recalled activation vectors at layer 0 for the E-A vector w.r.t. their six regulation factors.
- Exp-7: For this experiment, the GBP algorithm was injected with an E-A vector of [0.07, 0.04, 0.23, 0.46, 0.05] for recalling an activation vector at input layer 0. The six O-A vectors obtained for the six regulation factors can be seen in Table 2. The O-A vector for of 0% and % was almost the same as the E-A vector. The recalled activations regulation factor 0% was [0.9875402, 0.6551013], which is almost similar to the E-R vector [0.9896, 0.6568]. Figure 9b shows all the recalled trajectories for this experiment.
- Exp-8: In this experiment, the GBP algorithm was initialized with the E-A vector of [0.09, 0.5, 0.22, 0.05, 0.52]. The E-R vector for this experiment was [0.3458, 0.1157], and two similar vectors, [0.3444873, 0.1032499] and [0.3489568, 0.1284956], were recalled in this experiment using regulation of 0% and %, respectively. Figure 9c shows all recalled trajectories. The O-A vectors obtained with the regulation of 0% and % were also identical to the E-A vector of this experiment—see Table 2.
- Exp-9: The recall simulation in this experiment was instantiated with an E-A vector of [0.09, 0.40, 0,28, 0.07, 0.35], and a recall vector of [0.4410, 0.1341] was expected at input layer 0. Upon using the GBP algorithm with six regulation factors, the recall operation without regulation, i.e., of 0%, produced the most similar recall vector [0.4370989, 0.1308456] and the corresponding O-A vector at layer 1. However, the outcome with % regulations was also similar to a recalled vector [0.4392012, 0.1518065] at input layer 0—see Figure 9d.
- Exp-10: This experiment used an E-A vector [0.07, 0.09, 0.44, 0.26, 0.10] in order to obtain an E-R vector [0.8813, 0.4145] at input layer 0. The six simulations were carried out with different regulation factors, and it was observed that the results with of 0% and % produced results very near those of the E-R, i.e., [0.8873921, 0.4137484] and [0.8702277, 0.4153301], respectively—see Figure 9e for all trajectories. The same observations were made at the O-A vectors for of 0% and % at layer 1—see Table 2.
3.5.3. Discussion
4. Cued Recall Demonstration with MNIST Data
4.1. Multiple Binary Valued Cue Recall (MBVCR) Operation
4.1.1. Intuitive MBVCR Experiment
4.1.2. Non-Intuitive MBVCR Experiment
4.2. Multiple-Cue Recall (MCR) Experiment
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Abbreviations | Description |
| CAC | Convex Abstract Concept |
| CACC | Convex Abstract Concept Creation |
| CACUAP | Convex Abstract Concept Upward Activation Propagation |
| CCI | Convex Concept Identification |
| CCILL | Convex Concept Inter-Layer Learning |
| CCILW | Convex Concepts Inter-Layer Weights |
| CI | Concept Identifier |
| CRPD | Cluster Representative Data Points |
| CSRL | Concept Similarity Relation Learning |
| CSRW | Concept Similarity Relation Weights |
| E-A | Expected Activation |
| GBP | Geometric Back Propagation |
| IL | Intra-Layer |
| ILWs | Inter-Layer Weights |
| MBVCR | Multiple Binary Valued Cue Recall |
| MCR | Multiple Cue Recall |
| RAN | Regulated Activation Network |
| SCR | Single Cue Recall |
| Notations | Description |
| W | Convex Concept Inter-layer weight matrix |
| w | Similarity Relation weight matrix |
| C | Cluster center or Centroids |
| A | Output Activation |
| a | Input Activation |
| Variables to represent node index for 0th, 1st and 2nd respectively | |
| Arbitrary node indexes for any layer | |
| I | Ith instance of input data |
| Transfer function to obtain similarity relation | |
| t | Variable used to depict intermediate index |
| Size of input Vector at Layer-0 | |
| Size of Convex Abstract Concept vector at Layer-1 |
References
- Kiefer, M.; Pulvermüller, F. Conceptual representations in mind and brain: Theoretical developments, current evidence and future directions. Cortex 2012, 48, 805–825. [Google Scholar] [CrossRef] [PubMed]
- Bechtel, W.; Graham, G.; Balota, D.A. A Companion to Cognitive Science; Wiley-Blackwell: Hoboken, NJ, USA, 1998. [Google Scholar]
- Xiao, P.; Toivonen, H.; Gross, O.; Cardoso, A.; Correia, J.A.; Machado, P.; Martins, P.; Oliveira, H.G.; Sharma, R.; Pinto, A.M.; et al. Conceptual Representations for Computational Concept Creation. ACM Comput. Surv. 2019, 52, 1–33. [Google Scholar] [CrossRef] [Green Version]
- Rosch, E.; Mervis, C.B.; Gray, W.D.; Johnson, D.M.; Boyes-Braem, P. Basic objects in natural categories. Cogn. Psychol. 1976, 8, 382–439. [Google Scholar] [CrossRef] [Green Version]
- Tversky, B.; Hemenway, K. Objects, parts, and categories. J. Exp. Psychol. Gen. 1984, 113, 169–193. [Google Scholar] [CrossRef]
- Saitta, L.; Zucker, J.D. Semantic abstraction for concept representation and learning. In Proceedings of the Symposium on Abstraction, Reformulation and Approximation, Horseshoe Bay, TX, USA, 26–29 July 2000; pp. 103–120. [Google Scholar]
- Borghi, A.M.; Barca, L.; Binkofski, F.; Tummolini, L. Varieties of abstract concepts: Development, use and representation in the brain. Philos. Trans. R. Soc. Lond. Ser. B Biol. Sci. 2019, 373, 20170121. [Google Scholar] [CrossRef]
- Borghi, A.M.; Binkofski, F.; Castelfranchi, C.; Cimatti, F.; Scorolli, C.; Tummolini, L. The challenge of abstract concepts. Psychol. Bull. 2017, 143, 263–292. [Google Scholar] [CrossRef] [Green Version]
- Sharma, R.; Ribeiro, B.; Pinto, A.M.; Cardoso, F.A. Modeling Abstract Concepts For Internet of Everything: A Cognitive Artificial System. In Proceedings of the 13th APCA International Conference on Automatic Control and Soft Computing (CONTROLO), IEEE, Ponta Delgada, Portugal, 4–6 June 2018; pp. 340–345. [Google Scholar]
- Sharma, R.; Ribeiro, B.; Pinto, A.M.; Cardoso, A.F.; Raposo, D.; Marcelo, A.R.; Silva, J.S.; Boavida, F. Computational Concept Modeling for Student Centric Lifestyle Analysis: A Technical Report on SOCIALITE Case Study; Technical Report; Center of Information Science University of Coimbra: Coimbra, Portugal, 2017. [Google Scholar]
- Sharma, R.; Ribeiro, B.; Miguel Pinto, A.; Cardoso, F.A. Exploring Geometric Feature Hyper-Space in Data to Learn Representations of Abstract Concepts. Appl. Sci. 2020, 10, 1994. [Google Scholar] [CrossRef] [Green Version]
- Paivio, A. Mental Representations: A Dual Coding Approach; Oxford University Press: Oxford, UK, 1990. [Google Scholar]
- Paivio, A. Imagery and Verbal Processes; Holt, Rinehart & Winston: New York, NY, USA, 1971. [Google Scholar]
- Schwanenflugel, P.J.; Akin, C.; Luh, W.M. Context availability and the recall of abstract and concrete words. Mem. Cogn. 1992, 20, 96–104. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bransford, J.D.; McCarrell, N.S. A sketch of a cognitive approach to comprehension: Some thoughts about understanding what it means to comprehend. In Thinking Reading in Cognitive Science; Cambrige University Press: Cambrige, UK, 1974. [Google Scholar]
- Costescu, C.; Rosan, A.; Brigitta, N.; Hathazi, A.; Kovari, A.; Katona, J.; Demeter, R.; Heldal, I.; Helgesen, C.; Thill, S.; et al. Assessing Visual Attention in Children Using GP3 Eye Tracker. In Proceedings of the 2019 10th IEEE International Conference on Cognitive Infocommunications (CogInfoCom), Naples, Italy, 23–25 October 2019; pp. 343–348. [Google Scholar] [CrossRef]
- Ujbanyi, T.; Katona, J.; Sziladi, G.; Kovari, A. Eye-tracking analysis of computer networks exam question besides different skilled groups. In Proceedings of the 2016 7th IEEE International Conference on Cognitive Infocommunications (CogInfoCom), Wroclaw, Poland, 16–18 October 2016; pp. 000277–000282. [Google Scholar] [CrossRef]
- Katona, J.; Ujbanyi, T.; Sziladi, G.; Kovari, A. Examine the effect of different web-based media on human brain waves. In Proceedings of the 2017 8th IEEE International Conference on Cognitive Infocommunications (CogInfoCom), Debrecen, Hungary, 11–14 September 2017; pp. 000407–000412. [Google Scholar] [CrossRef]
- Katona, J.; Ujbanyi, T.; Sziladi, G.; Kovari, A. Speed control of Festo Robotino mobile robot using NeuroSky MindWave EEG headset based brain-computer interface. In Proceedings of the 2016 7th IEEE International Conference on Cognitive Infocommunications (CogInfoCom), Wroclaw, Poland, 16–18 October 2016; pp. 000251–000256. [Google Scholar] [CrossRef]
- Rolls, E.; Loh, M.; Deco, G.; Winterer, G. Computational models of schizophrenia and dopamine modulation in the prefrontal cortex. Nat. Rev. Neurosci. 2008, 9, 696–709. [Google Scholar] [CrossRef]
- Kyaga, S.; Landén, M.; Boman, M.; Hultman, C.M.; Långström, N.; Lichtenstein, P. Mental illness, suicide and creativity: 40-Year prospective total population study. J. Psychiatr. Res. 2013, 47, 83–90. [Google Scholar] [CrossRef] [PubMed]
- Braver, T.; Barch, D.; Cohen, J. Cognition and control in schizophrenia: A computational model of dopamine and prefrontal function. Biol. Psychiatry 1999, 46, 312–328. [Google Scholar] [CrossRef]
- O’Reilly, R.C. Biologically based computational models of high-level cognition. Science 2006, 314, 91–94. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hayes, J.C.; Kraemer, D.J. Grounded understanding of abstract concepts: The case of STEM learning. Cogn. Res. Princ. Implic. 2017, 2, 7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Anderson, J.R.; Matessa, M.; Lebiere, C. ACT-R: A theory of higher level cognition and its relation to visual attention. Hum. Comput. Interact. 1997, 12, 439–462. [Google Scholar] [CrossRef]
- Lovett, M.C.; Daily, L.Z.; Reder, L.M. A source activation theory of working memory: Cross-task prediction of performance in ACT-R. Cogn. Syst. Res. 2000, 1, 99–118. [Google Scholar] [CrossRef]
- Anderson, J.R.; Bothell, D.; Byrne, M.D.; Douglass, S.; Lebiere, C.; Qin, Y. An integrated theory of the mind. Psychol. Rev. 2004, 111, 1036. [Google Scholar] [CrossRef] [PubMed]
- Marewski, J.N.; Mehlhorn, K. Using the ACT-R architecture to specify 39 quantitative process models of decision making. Judgm. Decis. Mak. 2011, 6, 439–519. [Google Scholar]
- Schooler, L.J.; Hertwig, R. How forgetting aids heuristic inference. Psychol. Rev. 2005, 112, 610. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hinton, G. A practical guide to training restricted Boltzmann machines. In Neural Networks: Tricks of the Trade: Second Edition; Springer: Berlin/Heidelberg, Germany, 2012; pp. 599–619. [Google Scholar]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine Learning, ACM, Helsinki, Finland, 5–9 July 2008; pp. 160–167. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Babić, B.R.; Nešić, N.; Miljković, Z. Automatic feature recognition using artificial neural networks to integrate design and manufacturing: Review of automatic feature recognition systems. Artif. Intell. Eng. Des. Anal. Manuf. 2011, 25, 289–304. [Google Scholar] [CrossRef]
- Gritsenko, V.; Rachkovskij, D.; Frolov, A.; Gayler, R.; Kleyko, D.; Osipov, E. Neural distributed autoassociative memories: A survey. Cybern. Comput. Eng. 2017, 22, 5–35. [Google Scholar]
- Frutos-Pascual, M.; Garcia-Zapirain, B. Assessing visual attention using eye tracking sensors in intelligent cognitive therapies based on serious games. Sensors 2015, 15, 11092–11117. [Google Scholar] [CrossRef]
- Sun, R.; Peterson, T. Learning in reactive sequential decision tasks: The CLARION model. In Proceedings of the IEEE International Conference on Neural Networks, Washington, DC, USA, 3–6 June 1996; Volume 2, pp. 1073–1078. [Google Scholar]
- Buzsáki, G. Neural syntax: Cell assemblies, synapsembles, and readers. Neuron 2010, 68, 362–385. [Google Scholar] [CrossRef] [Green Version]
- Bower, G.H. A brief history of memory research. In The Oxford Handbook of Memory; Oxford University Press: Oxford, UK, 2000; pp. 3–32. [Google Scholar]
- Bermingham, D.; Hill, R.D.; Woltz, D.; Gardner, M.K. Cognitive strategy use and measured numeric ability in immediate-and long-term recall of everyday numeric information. PLoS ONE 2013, 8, e57999. [Google Scholar]
- Rafidi, N.S.; Hulbert, J.C.; Brooks, P.P.; Norman, K.A. Reductions in Retrieval Competition Predict the Benefit of Repeated Testing. Sci. Rep. 2018, 8, 11714. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Antony, J.W.; Ferreira, C.S.; Norman, K.A.; Wimber, M. Retrieval as a fast route to memory consolidation. Trends Cogn. Sci. 2017, 21, 573–576. [Google Scholar] [CrossRef]
- Polyn, S.M.; Natu, V.S.; Cohen, J.D.; Norman, K.A. Category-specific cortical activity precedes retrieval during memory search. Science 2005, 310, 1963–1966. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hulbert, J.; Norman, K. Neural differentiation tracks improved recall of competing memories following interleaved study and retrieval practice. Cereb. Cortex 2014, 25, 3994–4008. [Google Scholar] [CrossRef]
- Kapur, S.; Craik, F.I.; Jones, C.; Brown, G.M.; Houle, S.; Tulving, E. Functional role of the prefrontal cortex in retrieval of memories: A PET study. Neuroreport 1995, 6, 1880–1884. [Google Scholar] [CrossRef] [PubMed]
- Sederberg, P.B.; Howard, M.W.; Kahana, M.J. A context-based theory of recency and contiguity in free recall. Psychol. Rev. 2008, 115, 893. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Howard, M.W.; Kahana, M.J. A distributed representation of temporal context. J. Math. Psychol. 2002, 46, 269–299. [Google Scholar] [CrossRef] [Green Version]
- Socher, R.; Gershman, S.; Sederberg, P.; Norman, K.; Perotte, A.J.; Blei, D.M. Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2009; pp. 1714–1722. [Google Scholar]
- Becker, S.; Lim, J. A computational model of prefrontal control in free recall: Strategic memory use in the California Verbal Learning Task. J. Cogn. Neurosci. 2003, 15, 821–832. [Google Scholar] [CrossRef] [Green Version]
- Srivastava, N.; Vul, E. A simple model of recognition and recall memory. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 293–301. [Google Scholar]
- Gillund, G.; Shiffrin, R.M. A retrieval model for both recognition and recall. Psychol. Rev. 1984, 91, 1. [Google Scholar] [CrossRef]
- Wei, X.X.; Stocker, A.A. A Bayesian observer model constrained by efficient coding can explain’anti-Bayesian’percepts. Nat. Neurosci. 2015, 18, 1509. [Google Scholar] [CrossRef] [PubMed]
- Ruppin, E.; Yeshurun, Y. An attractor neural network model of recall and recognition. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 1990; pp. 642–648. [Google Scholar]
- Biggs, D.; Nuttall, A. Neural Memory Networks; Technical Report; Stanford University: Stanford, CA, USA, 2015. [Google Scholar]
- Ruppin, E.; Yeshurun, Y. Recall and recognition in an attractor neural network model of memory retrieval. Connect. Sci. 1991, 3, 381–400. [Google Scholar] [CrossRef]
- Recanatesi, S.; Katkov, M.; Romani, S.; Tsodyks, M. Neural network model of memory retrieval. Front. Comput. Neurosci. 2015, 9, 149. [Google Scholar] [CrossRef] [Green Version]
- Taatgen, N. A model of free-recall using the ACT-R architecture and the phonological loop. In Proceedings of Benelearn-96, Citeseer; Herik, I.H.J., Weijters, T., Eds.; Universiteit Maastricht: Maastricht, The Netherlands, 1996. [Google Scholar]
- Baddeley, A. Working memory. Science 1992, 255, 556–559. [Google Scholar] [CrossRef]
- Thomson, R.; Pyke, A.; Hiatt, L.M.; Trafton, J.G. An Account of Associative Learning in Memory Recall. In Proceedings of the 37th Annual Conference of the Cognitive Science Society, Pasadena, CA, USA, 22–25 July 2015; pp. 2386–2391. [Google Scholar]
- Anderson, J.R.; Matessa, M. A production system theory of serial memory. Psychol. Rev. 1997, 104, 728. [Google Scholar] [CrossRef]
- Hélie, S.; Sun, R.; Xiong, L. Mixed effects of distractor tasks on incubation. In Proceedings of the 30th Annual Meeting of the Cognitive Science Society, Washington, DC, USA, 23–26 July 2008; Cognitive Science Society: Austin, TX, USA, 2008; pp. 1251–1256. [Google Scholar]
- Hélie, S.; Sun, R. Incubation, insight, and creative problem solving: A unified theory and a connectionist model. Psychol. Rev. 2010, 117, 994–1024. [Google Scholar] [CrossRef] [Green Version]
- Garrett, B. Study Guide to Accompany Bob Garrett’s Brain & Behavior: An Introduction to Biological Psychology; Sage Publications: New York, NY, USA, 2014. [Google Scholar]
- Gärdenfors, P. Conceptual Spaces: The Geometry of Thought; MIT Press: Cambridge, MA, USA, 2004. [Google Scholar]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Sharma, R.; Ribeiro, B.; Pinto, A.M.; Cardoso, F.A. Learning non-convex abstract concepts with regulated activation networks. Ann. Math. Artif. Intell. 2020, 88, 1207–1235. [Google Scholar] [CrossRef]
- Rosch, E. Cognitive representations of semantic categories. J. Exp. Psychol. Gen. 1975, 104, 192–233. [Google Scholar] [CrossRef]
- Mervis, C.B.; Rosch, E. Categorization of natural objects. Annu. Rev. Psychol. 1981, 32, 89–115. [Google Scholar] [CrossRef]
- Rosch, E. Prototype classification and logical classification: The two systems. In New Trends in Conceptual Representation: Challenges to Piaget’s Theory; University of California, Berkeley: Berkeley, CA, USA, 1983; pp. 73–86. [Google Scholar]
- LeCun, Y.; Cortes, C.; Burges, C.J. The MNIST DATABASE of Handwritten Digits. 1999. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 10 July 2015).
- Sharma, R.; Ribeiro, B.; Miguel Pinto, A.; Amílcar Cardoso, F. Reconstructing Abstract Concepts and their Blends Via Computational Cognitive Modeling. In Proceedings of the 2020 IEEE International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–6. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Regulation | Experiment | E-A at Layer 1 | O-A at Layer 1 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| % |  | C | C | C | C | C | C | C | C | C | C |
| 0 | Exp-1 | 0 | 0 | 0 | 0 | 1 | 0.08 | 0.61 | 0.07 | 0.01 | 0.47 |
| 0.5 | Exp-1 | 0 | 0 | 0 | 0 | 1 | 0.14 | 0.70 | 0.09 | 0.03 | 0.72 |
| 0.75 | Exp-1 | 0 | 0 | 0 | 0 | 1 | 0.16 | 0.64 | 0.10 | 0.04 | 0.85 |
| 1 | Exp-1 | 0 | 0 | 0 | 0 | 1 | 0.19 | 0.56 | 0.11 | 0.05 | 0.82 |
| 1.25 | Exp-1 | 0 | 0 | 0 | 0 | 1 | 0.19 | 0.54 | 0.12 | 0.06 | 0.75 |
| 1.5 | Exp-1 | 0 | 0 | 0 | 0 | 1 | 0.20 | 0.52 | 0.12 | 0.06 | 0.71 |
| 0 | Exp-2 | 0 | 0 | 0 | 1 | 0 | 0.08 | 0.01 | 0.08 | 0.61 | 0.02 |
| 0.5 | Exp-2 | 0 | 0 | 0 | 1 | 0 | 0.10 | 0.02 | 0.11 | 0.83 | 0.03 |
| 0.75 | Exp-2 | 0 | 0 | 0 | 1 | 0 | 0.11 | 0.02 | 0.11 | 0.93 | 0.04 |
| 1 | Exp-2 | 0 | 0 | 0 | 1 | 0 | 0.12 | 0.03 | 0.12 | 0.90 | 0.04 |
| 1.25 | Exp-2 | 0 | 0 | 0 | 1 | 0 | 0.12 | 0.03 | 0.13 | 0.83 | 0.05 |
| 1.5 | Exp-2 | 0 | 0 | 0 | 1 | 0 | 0.13 | 0.03 | 0.13 | 0.78 | 0.05 |
| 0 | Exp-3 | 0 | 0 | 1 | 0 | 0 | 0.01 | 0.07 | 0.57 | 0.07 | 0.06 |
| 0.5 | Exp-3 | 0 | 0 | 1 | 0 | 0 | 0.02 | 0.09 | 0.76 | 0.10 | 0.08 |
| 0.75 | Exp-3 | 0 | 0 | 1 | 0 | 0 | 0.02 | 0.10 | 0.84 | 0.11 | 0.09 |
| 1 | Exp-3 | 0 | 0 | 1 | 0 | 0 | 0.03 | 0.11 | 0.93 | 0.11 | 0.09 |
| 1.25 | Exp-3 | 0 | 0 | 1 | 0 | 0 | 0.03 | 0.11 | 0.91 | 0.12 | 0.10 |
| 1.5 | Exp-3 | 0 | 0 | 1 | 0 | 0 | 0.03 | 0.12 | 0.84 | 0.13 | 0.10 |
| 0 | Exp-4 | 0 | 1 | 0 | 0 | 0 | 0.06 | 0.57 | 0.07 | 0.01 | 0.42 |
| 0.5 | Exp-4 | 0 | 1 | 0 | 0 | 0 | 0.08 | 0.75 | 0.10 | 0.02 | 0.50 |
| 0.75 | Exp-4 | 0 | 1 | 0 | 0 | 0 | 0.09 | 0.80 | 0.12 | 0.02 | 0.52 |
| 1 | Exp-4 | 0 | 1 | 0 | 0 | 0 | 0.10 | 0.77 | 0.13 | 0.03 | 0.53 |
| 1.25 | Exp-4 | 0 | 1 | 0 | 0 | 0 | 0.10 | 0.73 | 0.14 | 0.03 | 0.54 |
| 1.5 | Exp-4 | 0 | 1 | 0 | 0 | 0 | 0.11 | 0.69 | 0.15 | 0.04 | 0.54 |
| 0 | Exp-5 | 1 | 0 | 0 | 0 | 0 | 0.58 | 0.07 | 0.01 | 0.07 | 0.13 |
| 0.5 | Exp-5 | 1 | 0 | 0 | 0 | 0 | 0.78 | 0.09 | 0.02 | 0.10 | 0.15 |
| 0.75 | Exp-5 | 1 | 0 | 0 | 0 | 0 | 0.85 | 0.10 | 0.02 | 0.11 | 0.16 |
| 1 | Exp-5 | 1 | 0 | 0 | 0 | 0 | 0.88 | 0.10 | 0.03 | 0.12 | 0.17 |
| 1.25 | Exp-5 | 1 | 0 | 0 | 0 | 0 | 0.84 | 0.11 | 0.03 | 0.13 | 0.17 |
| 1.5 | Exp-5 | 1 | 0 | 0 | 0 | 0 | 0.79 | 0.11 | 0.04 | 0.13 | 0.18 |
| E-A, expected activation, O-A, observed activation. | |||||||||||
| Regulation | Experiment | E-A at Layer 1 | O-A at Layer 1 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| % |  | C | C | C | C | C | C | C | C | C | C |
| 0 | Exp-6 | 0.57 | 0.16 | 0.06 | 0.15 | 0.25 | 0.579 | 0.162 | 0.063 | 0.148 | 0.246 |
| 0.1 | Exp-6 | 0.57 | 0.16 | 0.06 | 0.15 | 0.25 | 0.567 | 0.163 | 0.066 | 0.151 | 0.247 |
| 0.2 | Exp-6 | 0.57 | 0.16 | 0.06 | 0.15 | 0.25 | 0.556 | 0.164 | 0.068 | 0.154 | 0.249 |
| 0.3 | Exp-6 | 0.57 | 0.16 | 0.06 | 0.15 | 0.25 | 0.546 | 0.166 | 0.070 | 0.156 | 0.250 |
| 0.4 | Exp-6 | 0.57 | 0.16 | 0.06 | 0.15 | 0.25 | 0.537 | 0.167 | 0.072 | 0.159 | 0.251 |
| 0.5 | Exp-6 | 0.57 | 0.16 | 0.06 | 0.15 | 0.25 | 0.529 | 0.168 | 0.074 | 0.161 | 0.252 |
| 0 | Exp-7 | 0.07 | 0.04 | 0.23 | 0.46 | 0.05 | 0.072 | 0.039 | 0.233 | 0.465 | 0.051 |
| 0.1 | Exp-7 | 0.07 | 0.04 | 0.23 | 0.46 | 0.05 | 0.086 | 0.048 | 0.235 | 0.482 | 0.061 |
| 0.2 | Exp-7 | 0.07 | 0.04 | 0.23 | 0.46 | 0.05 | 0.093 | 0.052 | 0.235 | 0.486 | 0.067 |
| 0.3 | Exp-7 | 0.07 | 0.04 | 0.23 | 0.46 | 0.05 | 0.099 | 0.055 | 0.236 | 0.487 | 0.071 |
| 0.4 | Exp-7 | 0.07 | 0.04 | 0.23 | 0.46 | 0.05 | 0.103 | 0.058 | 0.236 | 0.487 | 0.074 |
| 0.5 | Exp-7 | 0.07 | 0.04 | 0.23 | 0.46 | 0.05 | 0.107 | 0.061 | 0.236 | 0.485 | 0.077 |
| 0 | Exp-8 | 0.09 | 0.50 | 0.22 | 0.05 | 0.42 | 0.091 | 0.502 | 0.218 | 0.051 | 0.414 |
| 0.1 | Exp-8 | 0.09 | 0.50 | 0.22 | 0.05 | 0.42 | 0.099 | 0.497 | 0.221 | 0.056 | 0.424 |
| 0.2 | Exp-8 | 0.09 | 0.50 | 0.22 | 0.05 | 0.42 | 0.105 | 0.492 | 0.223 | 0.061 | 0.430 |
| 0.3 | Exp-8 | 0.09 | 0.50 | 0.22 | 0.05 | 0.42 | 0.110 | 0.486 | 0.224 | 0.064 | 0.434 |
| 0.4 | Exp-8 | 0.09 | 0.50 | 0.22 | 0.05 | 0.42 | 0.114 | 0.481 | 0.225 | 0.067 | 0.437 |
| 0.5 | Exp-8 | 0.09 | 0.50 | 0.22 | 0.05 | 0.42 | 0.117 | 0.476 | 0.226 | 0.070 | 0.439 |
| 0 | Exp-9 | 0.09 | 0.40 | 0.28 | 0.07 | 0.35 | 0.090 | 0.401 | 0.280 | 0.070 | 0.350 |
| 0.1 | Exp-9 | 0.09 | 0.40 | 0.28 | 0.07 | 0.35 | 0.096 | 0.397 | 0.281 | 0.076 | 0.355 |
| 0.2 | Exp-9 | 0.09 | 0.40 | 0.28 | 0.07 | 0.35 | 0.101 | 0.394 | 0.282 | 0.080 | 0.358 |
| 0.3 | Exp-9 | 0.09 | 0.40 | 0.28 | 0.07 | 0.35 | 0.105 | 0.391 | 0.282 | 0.084 | 0.360 |
| 0.4 | Exp-9 | 0.09 | 0.40 | 0.28 | 0.07 | 0.35 | 0.109 | 0.388 | 0.282 | 0.087 | 0.362 |
| 0.5 | Exp-9 | 0.09 | 0.40 | 0.28 | 0.07 | 0.35 | 0.112 | 0.385 | 0.281 | 0.090 | 0.363 |
| 0 | Exp-10 | 0.07 | 0.09 | 0.44 | 0.26 | 0.10 | 0.068 | 0.093 | 0.440 | 0.263 | 0.099 |
| 0.1 | Exp-10 | 0.07 | 0.09 | 0.44 | 0.26 | 0.10 | 0.073 | 0.098 | 0.437 | 0.264 | 0.105 |
| 0.2 | Exp-10 | 0.07 | 0.09 | 0.44 | 0.26 | 0.10 | 0.076 | 0.103 | 0.434 | 0.264 | 0.110 |
| 0.3 | Exp-10 | 0.07 | 0.09 | 0.44 | 0.26 | 0.10 | 0.079 | 0.106 | 0.431 | 0.264 | 0.114 |
| 0.4 | Exp-10 | 0.07 | 0.09 | 0.44 | 0.26 | 0.10 | 0.082 | 0.109 | 0.428 | 0.265 | 0.117 |
| 0.5 | Exp-10 | 0.07 | 0.09 | 0.44 | 0.26 | 0.10 | 0.084 | 0.112 | 0.425 | 0.265 | 0.120 |
| E-A, expected activation, O-A, observed activation. | |||||||||||


| Digit | Exp | Expected Activation (E-A) |
|---|---|---|
| 0 | MBVCR | [ 0,0,0,0,0,1,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0 ] |
| 1 | MBVCR | [ 0,0,1,0,0,0,1,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0 ] |
| 2 | MBVCR | [ 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,1,0,0,0,0,0,0,1,0 ] |
| 3 | MBVCR | [ 0,0,0,1,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,1,0,1,0,0,0 ] |
| 4 | MBVCR | [ 1,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 ] |
| 5 | MBVCR | [ 0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,1,1,0,0,0,0,0,0,0,0,0 ] |
| 6 | MBVCR | [ 0,0,0,0,0,0,0,1,0,0,0,0,0,1,0,0,0,0,1,0,0,0,0,0,0,0,0,1,0,0 ] |
| 7 | MBVCR | [ 0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0 ] |
| 8 | MBVCR | [ 0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1 ] |
| 9 | MBVCR | [ 0,1,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,1,0,0,0,0,0,1,0,0,0,0,0,0 ] |
| 2 and 5 | MBVCR | [ 0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,1,0,0,0,1,1,1,0,0,0,0,0,0,1,0 ] |
| 3 and 5 | MBVCR | [ 0,0,0,1,0,0,0,0,1,0,0,0,1,0,0,0,0,0,0,1,1,0,0,0,1,0,1,0,0,0 ] |
| 0 and 1 | MBVCR | [ 0,0,1,0,0,1,1,0,0,0,1,0,0,0,0,0,1,0,0,0,0,0,0,0,0,1,0,0,0,0 ] |
| 0 | MCR | [ 0.26,0.25,0.22,0.30,0.27,1.00,0.23,0.30,0.28,0.30,0.35,0.26,0.32,0.26,0.25,0.28,0.22,0.23,0.23,0.25,0.33,0.28,0.25,0.29,0.28,0.39,0.28,0.31,0.27,0.30 ] |
| 1 | MCR | [ 0.29,0.37,1.00,0.35,0.43,0.22,0.49,0.33,0.34,0.32,0.26,0.31,0.31,0.28,0.34,0.39,0.38,0.35,0.34,0.39,0.31,0.35,0.43,0.31,0.42,0.27,0.36,0.24,0.31,0.33 ] |
| 2 | MCR | [ 0.28,0.35,0.39,0.38,0.40,0.28,0.38,0.36,0.33,0.31,0.26,0.29,0.36,0.35,0.29,1.00,0.34,0.31,0.37,0.34,0.36,0.43,0.34,0.29,0.47,0.32,0.37,0.33,0.37,0.34 ] |
| 3 | MCR | [ 0.31,0.38,0.31,0.46,0.35,0.32,0.32,0.31,0.35,0.33,0.26,0.32,1.00,0.33,0.31,0.36,0.31,0.33,0.31,0.30,0.40,0.34,0.33,0.35,0.38,0.34,0.46,0.35,0.27,0.37 ] |
| 4 | MCR | [ 1.00,0.46,0.29,0.32,0.38,0.26,0.30,0.38,0.37,0.44,0.31,0.42,0.31,0.39,0.44,0.28,0.31,0.48,0.36,0.37,0.29,0.34,0.37,0.42,0.34,0.34,0.34,0.31,0.32,0.40 ] |
| 5 | MCR | [ 0.37,0.42,0.34,0.44,0.47,0.28,0.36,0.41,1.00,0.29,0.39,0.36,0.35,0.34,0.37,0.33,0.36,0.42,0.43,0.40,0.42,0.33,0.38,0.35,0.43,0.37,0.45,0.29,0.33,0.41 ] |
| 6 | MCR | [ 0.39,0.40,0.28,0.38,0.33,0.26,0.31,0.45,0.34,0.38,0.28,0.31,0.33,1.00,0.34,0.35,0.32,0.36,0.42,0.32,0.32,0.40,0.33,0.35,0.35,0.36,0.34,0.42,0.33,0.33 ] |
| 7 | MCR | [ 0.42,0.45,0.31,0.34,0.35,0.26,0.34,0.32,0.36,0.34,0.28,1.00,0.32,0.31,0.41,0.29,0.35,0.47,0.33,0.35,0.29,0.32,0.43,0.47,0.38,0.30,0.34,0.25,0.28,0.34 ] |
| 8 | MCR | [ 0.38,0.41,0.43,0.39,1.00,0.27,0.40,0.38,0.47,0.32,0.33,0.35,0.35,0.33,0.40,0.40,0.37,0.44,0.42,0.44,0.38,0.39,0.45,0.32,0.44,0.34,0.44,0.29,0.39,0.48 ] |
| 9 | MCR | [ 0.46,1.00,0.37,0.40,0.41,0.25,0.39,0.38,0.42,0.38,0.29,0.45,0.38,0.40,0.40,0.35,0.39,0.51,0.40,0.39,0.32,0.40,0.43,0.44,0.43,0.32,0.44,0.32,0.30,0.40 ] |

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharma, R.; Ribeiro, B.; Pinto, A.M.; Cardoso, A. Emulating Cued Recall of Abstract Concepts via Regulated Activation Networks. Appl. Sci. 2021, 11, 2134. https://doi.org/10.3390/app11052134
Sharma R, Ribeiro B, Pinto AM, Cardoso A. Emulating Cued Recall of Abstract Concepts via Regulated Activation Networks. Applied Sciences. 2021; 11(5):2134. https://doi.org/10.3390/app11052134
Chicago/Turabian StyleSharma, Rahul, Bernardete Ribeiro, Alexandre Miguel Pinto, and Amílcar Cardoso. 2021. "Emulating Cued Recall of Abstract Concepts via Regulated Activation Networks" Applied Sciences 11, no. 5: 2134. https://doi.org/10.3390/app11052134
APA StyleSharma, R., Ribeiro, B., Pinto, A. M., & Cardoso, A. (2021). Emulating Cued Recall of Abstract Concepts via Regulated Activation Networks. Applied Sciences, 11(5), 2134. https://doi.org/10.3390/app11052134