
Bayesian Optimization Based Efficient Layer Sharing for Incremental Learning




Abstract
:1. Introduction
- i
- The subsequent data from new tasks should be trainable and be accommodated incrementally without forgetting any knowledge in old tasks, i.e., it should not suffer from catastrophic forgetting [7].
- ii
- The overhead of incremental training should be minimal.
- iii
- The previously seen data of old task should not be accessible when it is training incrementally.
- We firstly define the sharing layer ratio estimation problem for incremental learning as discrete combinatorial optimization problem with the global optimization strategy.
- By utilizing BayesOpt, the proposed method effectively computes the global optimal sharing capacity of the existing network for accommodating the new task without computing all possible cases.
- The proposed algorithm can adaptively find the global optimal sharing configuration with the target accuracy via adjusting the threshold accuracy parameter in the proposed loss function.
- To employ BayesOpt, the proposed objective function should be continuous. It is a discrete function due to the number of layers, designed to represent the continuous combinatorial optimization problem with a step function.
2. Preliminaries
2.1. Incremental Learning Algorithm Based on ‘Clone-and-Branch’
2.1.1. Step 1: Empirical Searching
2.1.2. Step 2: Utilizing Similarity Score
2.1.3. Problem Definition
3. Proposed Algorithm
3.1. Combined Classification Accuracy
3.2. Target Combined Classification Accuracy
3.3. Proposed Objective Function
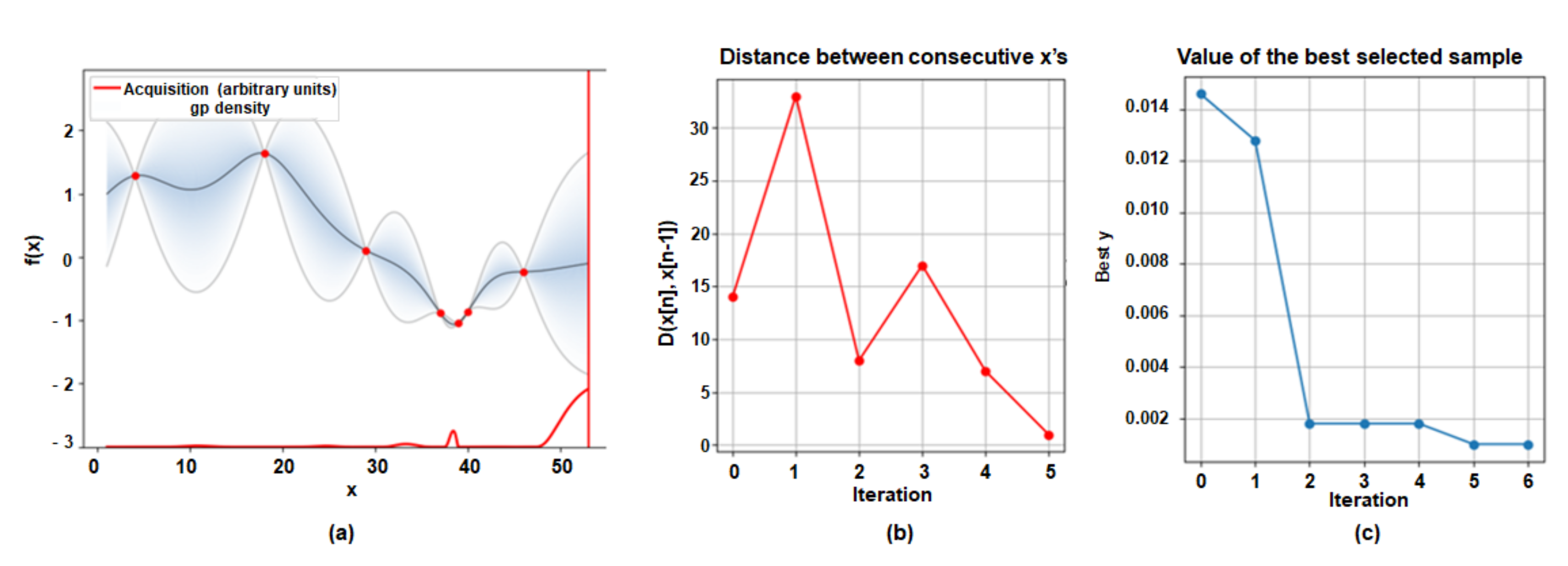
3.4. Global Optimal Layer Selection via BayesOpt
3.4.1. Gaussian Process (GP) Regression
3.4.2. Probability of Improvement (PI)
3.4.3. Expected Improvement (EI)
4. Experiment Results
4.1. Implementation Details
4.2. Comparison of Experimental Results for ‘PI’ and ‘EI’
4.3. Experimental Results on Resnet50 with CIFAR-100
- Case 1: utilizing base network which was trained with 70 classes among 100 classes dataset.
- Case 2: utilizing base network which was trained with 60 classes among 100 classes dataset.
4.3.1. Experimental Results on Case 1
4.3.2. Experimental Results on Case2
4.4. Experimental Results on MobileNetV2 with EMNIST
4.5. Comparison of Experimental Results for the ‘Clone and Branch’
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BayesOpt | Bayesian optimization |
| DCNN | Deep convolutional neural network |
Appendix A. Overview of Bayesian Optimization
References
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Sun, Y.; Wang, X.; Tang, X. Deep Learning Face Representation from Predicting 10,000 Classes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1891–1898. [Google Scholar]
- French, R.M. Catastrophic forgetting in connectionist networks. Trends Cogn. Sci. 1999, 3, 128–135. [Google Scholar] [CrossRef]
- Martial, M.; Bugaiska, A.; Bonin, P. The stability-plasticity dilemma: Investigating the continuum from catastrophic forgetting to age-limited learning effects. Front. Psychol. 2013, 4, 504. [Google Scholar]
- Biederman, I. Recognition-by-Components: A Theory of Human ImageUnderstanding. Psychol. Rev. 1987, 94, 115–147. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bendale, A.; Boult, T. Towards open world recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1893–1902. [Google Scholar]
- Goodfellow, I.J.; Mirza, M.; Courville, A.; Bengio, Y. An empirical investigation of catastrophic forgetting in gradient-based neural networks. arXiv 2015, arXiv:1312.6211v3. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; Volume 27, pp. 1–9. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Li, Z.; Hoiem, D. Learning without Forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2935–2947. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Michieli, U.; Zanuttigh, P. Knowledge Distillation for Incremental Learning in Semantic Segmentation. arXiv 2019, arXiv:1911.03462. [Google Scholar]
- Sarwar, S.S.; Ankit, A.; Roy, K. Incremental Learning in deep convolutional neural networks using partial network sharing. IEEE Access 2019, 8, 4615–4628. [Google Scholar] [CrossRef]
- Sze, V.; Chen, Y.; Emer, J.; Suleiman, A.; Zhang, Z. Hardware for machine learning: Challenges and opportunities. In Proceedings of the IEEE Custom Integrated Circuits Conference (CICC), Austin, TX, USA, 30 April–3 May 2017; pp. 1–8. [Google Scholar]
- Chen, Y.; Luo, T.; Liu, S.; Zhang, S.; He, L.; Wang, J.; Li, L.; Chen, T.; Xu, Z.; Sun, N.; et al. DaDianNao: A Machine-Learning Supercomputer. In Proceedings of theAnnual IEEE/ACM International Symposium on Microarchitecture, Cambridge, UK, 13–17 December 2014; pp. 609–622. [Google Scholar]
- Maji, P.; Mullins, R. On the Reduction of Computational Complexity of Deep Convolutional Neural Networks. Entropy 2018, 20, 305. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. In Proceedings of the ICLR, Banff, AB, Canada, 14–16 April 2014; pp. 1–8. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland,6–12 September 2014; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Dumitru, E.; Bengio, Y.; Courville, A.; Vincent, P. Visualizing Higher-Layer Features of a Deep Network; University of Montreal: Montreal, QC, Canada, 2009; Volume 1341, p. 1. [Google Scholar]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. Decaf: A deep convolutional activation feature for generic visual recognition. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Haftka, R.T.; Scott, E.P.; Cruz, J.R. Optimization and Experiments: A Survey. Appl. Mech. Rev. 1998, 51, 435–448. [Google Scholar] [CrossRef]
- Hare, W.; Nutini, J.; Tesfamariam, S. A survey of non-gradient optimization methods in structural engineering. Adv. Eng. Softw. 2013, 59, 19–28. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sulskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1–9. [Google Scholar]
- Kim, T.; Lee, J.; Choe, Y. Bayesian Optimization-Based Global Optimal Rank Selection for Compression of Convolutional Neural Networks. IEEE Access 2020, 8, 17605–17618. [Google Scholar] [CrossRef]
- Kim, T.; Choe, Y. Background subtraction via exact solution of Bayesian L1-norm tensor decomposition. In Proceedings of the International Workshop on Advanced Imaging Technology (IWAIT) 2020, Yogyakarta, Indonesia, 5–7 January 2020; International Society for Optics and Photonics: Washington, DC, USA, 2020; Volume 11515. [Google Scholar]
- Kim, B.; Kim, T.; Choe, Y. A Novel Layer Sharing-based Incremental Learning via Bayesian Optimization. In Proceedings of the MDPI in 1st International Electronic Conference on Applied Sciences session Computing and Artificial Intelligence, Online, 10–30 November 2020. [Google Scholar]
- Frazier, P.I. A tutorial on bayesian optimization. arXiv 2018, arXiv:1807.02811. [Google Scholar]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical bayesian optimization of machine learning algorithms. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Brochu, E.; Cora, V.M.; Freitas, N.D. A tutorial on Bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning. arXiv 2010, arXiv:1012.2599. [Google Scholar]
- Pelikan, M.; Goldberg, D.E.; Cantú-Paz, E. BOA: The Bayesian optimization algorithm. In Proceedings of the Genetic and eVolutionary Computation Conference GECCO-99, Orlando, FL, USA, 13–17 July 1999; Volume 1. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Alex, K.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report; Citeseer: Princeton, NJ, USA, 2009; Volume 1. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Cohen, G.; Afshar, S.; Tapson, J.; van Schaik, A. EMNIST: An extension of MNIST to handwritten letters. 2017; arXiv, 1702. [Google Scholar]
- Kushner, H.J. A new method of locating the maximum point of an arbitrary multipeak curve in the presence of noise. J. Basic Eng. 1964, 86, 97–106. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning (Adaptive Computation and Machine Learning); MIT Press: Cambridge, MA, USA, 2005; ISBN 026218253X. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | Classes | Network | With Sharing Layers | w/o Sharing Layers | |
|---|---|---|---|---|---|
| Accuracy Degradation 2% | Accuracy Degradation 3% | - | |||
| T0 | 70 (Base) |
ResNet 50: 53 convolution, 53 BN, 49 ReLU, 1 Averpool, 1 FC layer | - | - | 81.73% |
| T1 | 30 | 83.33% | 81.17% | 84.40% | |
| T0–T1 | 100 | 67.84% (the optimal configuration: 39) | 67.03% (the optimal configuration: 47) | 69.74% (Baseline) | |
| T0′ | 60 (Base) | - | - | 82.27% | |
| T1′ | 40 | 82.10% | 78.38% | 83.93% | |
| T0′–T1′ | 100 | 67.78% (the optimal configuration: 44) | 66.82% (the optimal configuration: 49) | 69.81% (Baseline) | |
| Task | Classes | With Sharing Layers in Base Network | w/o Sharing Layers | ||||
|---|---|---|---|---|---|---|---|
| ‘Clone-and-Branch’ Technique | The Proposed Method | ||||||
| Accuracy | Time (hours) | Accuracy | The Optimal Layer | # of Attempts/ Time (hours) | Accuracy (Baseline) | ||
| T0 | 60(base) | - | - | - | - | 80.90% | |
| T0–T1 | 60–30 | 66.73% (45th layers) | 63.23 | 66.73% | 45 | 4/3.34 | 68.96% |
| T0–T2 | 60–10 | 68.74% (46th layers) | 68.74% | 46 | 9/3.88 | 70.34% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, B.; Kim, T.; Choe, Y. Bayesian Optimization Based Efficient Layer Sharing for Incremental Learning. Appl. Sci. 2021, 11, 2171. https://doi.org/10.3390/app11052171
Kim B, Kim T, Choe Y. Bayesian Optimization Based Efficient Layer Sharing for Incremental Learning. Applied Sciences. 2021; 11(5):2171. https://doi.org/10.3390/app11052171
Chicago/Turabian StyleKim, Bomi, Taehyeon Kim, and Yoonsik Choe. 2021. "Bayesian Optimization Based Efficient Layer Sharing for Incremental Learning" Applied Sciences 11, no. 5: 2171. https://doi.org/10.3390/app11052171
APA StyleKim, B., Kim, T., & Choe, Y. (2021). Bayesian Optimization Based Efficient Layer Sharing for Incremental Learning. Applied Sciences, 11(5), 2171. https://doi.org/10.3390/app11052171