1. Introduction
Supervised learning is the machine learning task of learning a function that maps an input to an output based on example input-output pairs [
1]. An inducer receives a set of labeled examples as training data and makes predictions for unseen inputs [
2,
3]. Traditionally, each example is associated with a single label. However, in some problems an example might be associated with multiple labels. Multi-label machine learning has received significant attention in fields such as text categorization [
4], image classification [
5], health risk prediction [
6], or electricity load monitoring [
7], among others. In computer vision in particular, there are more and more applications and available data sets that involve multi-label learning [
8,
9,
10].
Formally [
11], suppose
(or
) denotes the
d-dimension instance space, and
denotes the label space with
q possible class labels. The task of multi-label learning is to learn a function
from the multi-label training set
. For each multi-label example
is a
d-dimensional feature vector
and
is the set of labels associated with
. For any unseen instance
, the multi-label classifier
predicts
as the set of proper labels for
x.
In supervised learning, experiments typically involve a first step of distributing the examples of a data set into two or more disjoint subsets [
12]. If a large amount of training data is available, the holdout method [
3] is used to distribute the examples into two mutually exclusive subsets called training set and test set, or holdout set. Sometimes the training set is also divided into two disjoint subsets to create a validation set. When training data is limited,
k-fold cross-validation is used, which splits the data set into
k disjoint subsets of approximately equal size.
In single-label data sets, those disjoint subsets are built by distributing equally and randomly the examples in the original data set belonging to the different class labels. However, splitting a multi-label data set is not straightforward, as an over-represented class in one subset will be an under-represented in the other/s [
3].
Furthermore [
12], random distribution of multi-label training examples into subsets suffers from the following practical problem: it can lead to test subsets lacking even just one example of a rare label, which in turn causes calculation problems for a number of multi-label evaluation measures. The typical way these problems get by-passed in the literature is through complete removal of rare labels. This, however, implies that the performance of the learning systems on rare labels is unimportant, which is seldom true.
As mentioned by [
13], multi-label classification usually follows predetermined train/test splits set by data set providers, without the analysis in terms of how well the examples are distributed into those train/test splits. Therefore, a method called stratification [
3] or stratified sampling [
12] was developed, in which a data set is split so that the proportion of examples of each class label in each subset is approximately equal to that in the complete data set. Stratification improves upon standard cross-validation both in terms of bias and variance, when compared to regular cross-validation [
3].
The data used for learning a classifier is often imbalanced [
14,
15]. Thus, the class labels assigned to each instance are not equally represented. Traditionally, imbalanced classification has been faced through techniques such as resampling, cost-sensitive learning, and algorithmic-specific adaptations [
16,
17]. In deep learning, data augmentation is a technique that has been successful in order to address imbalanced data sets [
18,
19].
Different measures have been proposed to estimate the degree of multi-labelledness and the imbalance level of a data set [
11,
20,
21]. The
label cardinality indicates the average number of labels per example (Equation (
1)). This measure can be normalized by the number
q of possible labels to obtain the
label density (Equation (
2)). The
label diversity is the number of distinct label combinations that appear in the data set (Equation (
3)), which can also be normalized by the number of examples to indicate the proportion of distinct label sets (Equation (
4)). The
Theoretical Complexity Score (Equation (
5)) integrates the number of input features, the number of labels, and distinct label combinations into a single measure.
As mentioned in [
15], in binary classification the imbalance level is measured taking into account only two classes: the majority class and the minority class. In multi-label data sets the presence of the different labels can vary considerably. The
average Imbalance Ratio is the average of the imbalance ratios (
) between the majority label and each label
(Equation (
6)).
is equal to 1 for the most frequent label and greater for the other labels. Therefore, a larger value of the
average Imbalance Ratio represents a higher imbalance level in the data set.
The
measure (Equation (
7)) aims to quantify the imbalance variance among the labels present in each data sample. This measure allows the estimation of the level of co-occurrence between minority and majority labels, i.e., if minority labels appear in their own or jointly with majority ones.
Table 1 presents these measures for well-known multi-label data sets, and recent large multi-label image data sets that are used in machine learning and computer vision applications. The complexity of these later data sets in terms of size, number of labels, cardinality, and diversity, is much higher than
traditional multi-label data sets. Some of these data sets, e.g., Microsoft COCO, are labeled not only with the different classes that appear in one example but with the exact number of appearances of each class. This is the reason why the frequency of the label appearing the most in the Microsoft COCO data set is higher than one, as it appears several times, on average, per example (
Figure 1).
The remainder of this paper is organized as follows: Next, in
Section 2 a review of available methods for the stratification of multi-label data sets is presented;
Section 3 introduces and evaluates an evolutionary approach to obtain a stratified sampling of a data set;
Section 4 proposes a multi-objective evolutionary algorithm to obtain an improved stratification;
Section 5 evaluates the effect that this new splitting algorithm has on the classification metrics; and
Section 6 validates this latest evolutionary approach with large image data sets currently used in computer vision and machine learning applications, and compares the results with the official splits usually employed in the literature. Finally,
Section 7 discusses the methods proposed in the paper and presents some future work.
2. Related Works
The first approach to apply stratification to multi-label data sets was proposed by Sechidis et al. [
12]. They proposed a greedy algorithm, Iterative Stratification (IS), that assigns iteratively examples from the original data set to each subset. The algorithm starts by taking the label with fewer examples in the data set. Those examples are, then, iteratively distributed among the different subsets based on the expected proportion of that label in each subset, i.e., an example is assigned to the subset that deviates more from the expected proportion. This process is repeated for each label until all the examples in the data set are distributed.
Sechidis et al. compared their approach against a random splitting using different measures. Following the notation presented in [
12], let’s consider a data set,
D, annotated with a set of labels,
, a desired number
k of disjoints subsets
of
D, and a desired proportion of examples
in each of these subsets. The desired number of examples at each subset
is denoted as
and is equal to
. The subsets of
D and
that contain positive examples of label
are denoted
and
respectively.
The Label Distribution (
) measure [
12] (Equation (
8)) evaluates the extent to which the distribution of positive and negative examples of each label in each subset follows the distribution of that label in the whole data set. For each label
, the measure computes the absolute difference between the ratio of positive to negative examples in each subset
with the ratio of positive to negative examples in the whole data set
D, and then averages the results across all labels. This measure is calculated as:
The Examples Distribution (
) measure (Equation (
9)) evaluates the extent to which the final number of examples in each subset
deviates from the desired/expected number of examples in that subset.
Other measures are the number of folds that contain at least one label with zero positive examples (), and the number of fold-label pairs with zero positive examples ().
Using these measures, Sechidis et al. demonstrated that their iterative approach maintains better the ratio of positive to negative examples of each label in each subset (
) and produces the smallest number of folds (
) and fold-label pairs (
) with zero positive examples. However, their algorithm does not consider the desired number of examples in each subset as a hard constraint, getting worse results in terms of Examples Distribution (
). They also mentioned that their approach might get worse results for multi-label classification methods that consider pairs of labels, e.g., Calibrated Label Ranking [
34], as their stratification method only considers the distribution of single labels.
Similarly to the measures presented in
Section 1, measures could be defined not only for single labels appearing in a data set but also to higher order relations between them, i.e., simultaneous appearance of labels (label pairs, triplets...), such as
,
,
, and
. For instance,
would indicate the average number of label pairs per example.
Table 2 shows these measures for order 2 for the data sets previously analyzed.
Given the limitation mentioned by Sechidis et al. regarding pairs of labels, Szymański and Kajdanowicz [
13] extended the Iterative Stratification approach to take into account second-order relationships between labels, i.e. label pairs, and not just single labels into account when performing stratification. The proposed algorithm, Second Order Iterative Stratification (SOIS), behaves similarly to Sechidis et al.’ stratification method but considering label pairs instead of single labels. The algorithm intends to maintain the same proportion of label pairs in each subset than in the original data set, considering at each point the label pair with fewer examples, distributing them among the subsets and repeating this process iteratively until no more label pairs are available. Finally, if there are examples with no label pairs these are assigned to the different subsets to comply with their expected size.
Szymański and Kajdanowicz compared SOIS with IS and random distribution using the same measures (
,
,
,
). They also included a new measure, the Label Pair Distribution (
) (Equation (
10)), an extension of the
measure that operates on positive and negative subsets of label pairs instead of labels. Given
E the set of label pairs appearing in the data set,
and
are the sets of samples that have the
i-th label pair from
E assigned in subset
and the entire data set respectively. In most cases, SOIS obtains better results than IS.
3. First Approach: Single-Objective Evolutionary Algorithm
This work proposes an evolutionary algorithm (EA), EvoSplit, to obtain the distribution of a data set into disjoint subsets, considering their desired size as a hard constraint. The structure of the evolutionary algorithm follows the process presented in Algorithm 1.
| Algorithm 1 EvoSplit |
![Applsci 11 02823 i001]() |
3.1. Characteristics of the Algorithm
Let D be a multi-label data set, k the desired number of disjoints subsets of D, and the desired number of examples at each subset. Each individual is encoded as an integer vector of size , in which each gene represents the subset to which each example is assigned.
Different possibilities can be used to generate new individuals by crossover and mutation. EvoSplit selects parents by ranking, recombination is performed using 1-point crossover, and a mutation is carried out by reassigning randomly 1% of the genes to a different subset. This process to generate new individuals would produce in most cases individuals that do not comply with the constraint of having examples in subset , . Therefore, a repairing process is applied to randomly reassign examples/genes to other subsets to fully comply with the constraint.
This work considers two different fitness functions: a variant of the Label Distribution (
) and the Label Pair Distribution (
), which were introduced in
Section 2. The Label Distribution is appropriate for data sets in which a specific label can appear only once in an example. However, for data sets that might include in a particular example several instances of the same label, Equation (
8) is not appropriate. This is the case, as it was shown earlier of well-known data sets in computer vision, as Microsoft COCO [
8]. Therefore, the
has being modified to consider also data sets with this characteristic.
Let’s consider
and
the number of appearances of label
in subset
and data set
D respectively,
and
the total number of labels in subset
and data set
D respectively. The modified Label Distribution measure, which is used as fitness function in EvoSplit, is then calculated following Equation (
11).
We could proceed similarly with the measure. However, EvoSplit does not consider in its calculation the number of appearances of each label in each example, but only the co-occurrence of labels, as in the original measure. In this case, a variant of the would increase considerably the number of pair combinations and make difficult that different examples share the same pair.
3.2. Constraints
The application of evolutionary computation allows the introduction of constraints that all the individuals in the population must fulfill to be feasible. In
Section 1, it was mentioned that the distribution of labels with few examples might lead to subsets lacking examples having that label, which can difficult validation and test of multi-label classifiers. Therefore, EvoSplit introduces an optional constraint to ensure that, if possible, all subsets contain, at least, one example of each label. For instance, if a data set has to be split into three subsets and a label only appears in three examples, each of those examples will be distributed to a different subset. The constraint is not considered for those class labels which number of examples is lower than the number of subsets. Some other constraints could also be considered, if needed.
In case of generating an individual that does not fulfill the constraint, a repairing process similar to that explained before would be applied.
3.3. Results
Next, this work presents a comparison of the performance of the proposed evolutionary approach with other alternatives to split a data set into disjoint subsets, i.e., random and stratified (SOIS) (The stratified alternative has been obtained using the algorithm provided by scikit-multilearn [
35].). Similarly to the literature [
12,
13], this work has evaluated the different methods considering 10-fold cross-validation of well-know multi-label data sets.
For the evolutionary approaches, the parameters have been selected experimentally:
Size of the population (n): 50
Individuals created by crossover (c): 10
Individuals created by mutation (m): 10
Number of generations without changes in the best individual (): 25
The splitting has been carried out using both the Label Distribution and the Label Pair Distribution as fitness functions. For each of these alternatives, results have been obtained without and with the constraint presented in
Section 3.2 that tries to ensure that, if possible, all folds have examples for all the labels. For each alternative, given the probabilistic behavior of evolutionary algorithms, the best result of five runs of the algorithm has been selected.
Table 3 shows the results in the case of using the Label Distribution as fitness function. In this case, the optimization algorithm tries to create subsets in which the proportion of examples of each class is close to that in the complete data set. In both cases, whether considering or not the constraint, the evolutionary approach obtains better results than any other method. Something similar happens (
Table 4) when the Label Pair Distribution is employed as fitness function, i.e., the algorithm tries to approximate theproportion of label pairs. However, in most cases, when the evolutionary algorithm tries to improve the distribution of single labels (by using
) fails to distribute label pairs better than the Stratification method. Something similar happens when the fitness function is the
measure and the results are measured in terms of
.
It is worth mentioning that the Stratification method does not consider the desired number of samples per fold as a hard constraint. Therefore, the final sizes of the subsets might deviate from the pre-established ones, as measured by the Examples Distribution and shown in
Table 5. This is not allowed for the evolutionary approaches.
Following [
12], besides using the Label Distribution and the Label Pair Distribution, the result of each alternative is also measured (see
Table 6 and
Table 7) in terms of the number of folds that contain at least one label with zero positive examples (
), and the number of fold-label pairs with zero positive examples (
). The
measure shows the effect of introducing the constraint of ensuring that subsets contain, if possible, one example of each label. In the constrained version of EvoSplit, the
values are lower than with all the other methods.
Table 3 and
Table 4 show that the evolutionary approach gets better results than Stratification only for the metric that is employed as fitness function. There are only some few cases in which good results are obtained for both metrics, the Label Distribution and the Label Pair Distribution simultaneously. On the other hand, the Stratification method obtains splits that behave well for both metrics, even if the best results for each metric are obtained with the evolutionary approaches. This is probably due to the process that the Stratification method follows to distribute examples to subsets: first, considering label pairs in the distribution and, later, assigning remaining examples based on single labels, i.e., taking into consideration both labels and label pairs in the splitting.
4. Second Approach: Multi-Objective Evolutionary Algorithm
Then, it seems appropriate to consider both statistical measures, the Label Distribution and the Label Pair Distribution, in the optimization algorithm to split a data set into disjoint subsets. Multi-objective optimization problems are those problems where the goal is to optimize simultaneously several objective functions. These different functions have conflicting objectives, i.e., optimizing one affects the others. Therefore, there is not a unique solution but a set of solutions. The set of solutions in which the different objective components cannot be simultaneously improved constitute a Pareto front. Each solution in the Pareto front represents a trade-off between the different objectives. Similarly to evolutionary algorithms for single objective problems, multi-objective evolutionary algorithms (MOEA) [
36] are heuristic algorithms to solve problems with multiple objective functions. The three goals of an MOEA are [
37]: (1) to find a set of solutions as close as possible to the Pareto front (known as convergence); (2) to maintain a diverse population that contains dissimilar individuals to promote exploration and to avoid poor performance due to premature convergence (known as diversity); and (3) to obtain a set of solutions that spreads in a more uniform way over the Pareto front (known as coverage). Several MOEAs have been proposed in the literature. This work employs the Non-dominated Sorting Genetic Algorithm II (NSGA-II) [
38].
NSGA-II has the three following features: (1) it uses an elitist principle, i.e., the elites of a population are given the opportunity to be carried to the next generation; (2) it uses an explicit diversity preserving mechanism (Crowding distance); and (3) it emphasizes the non-dominated solutions.
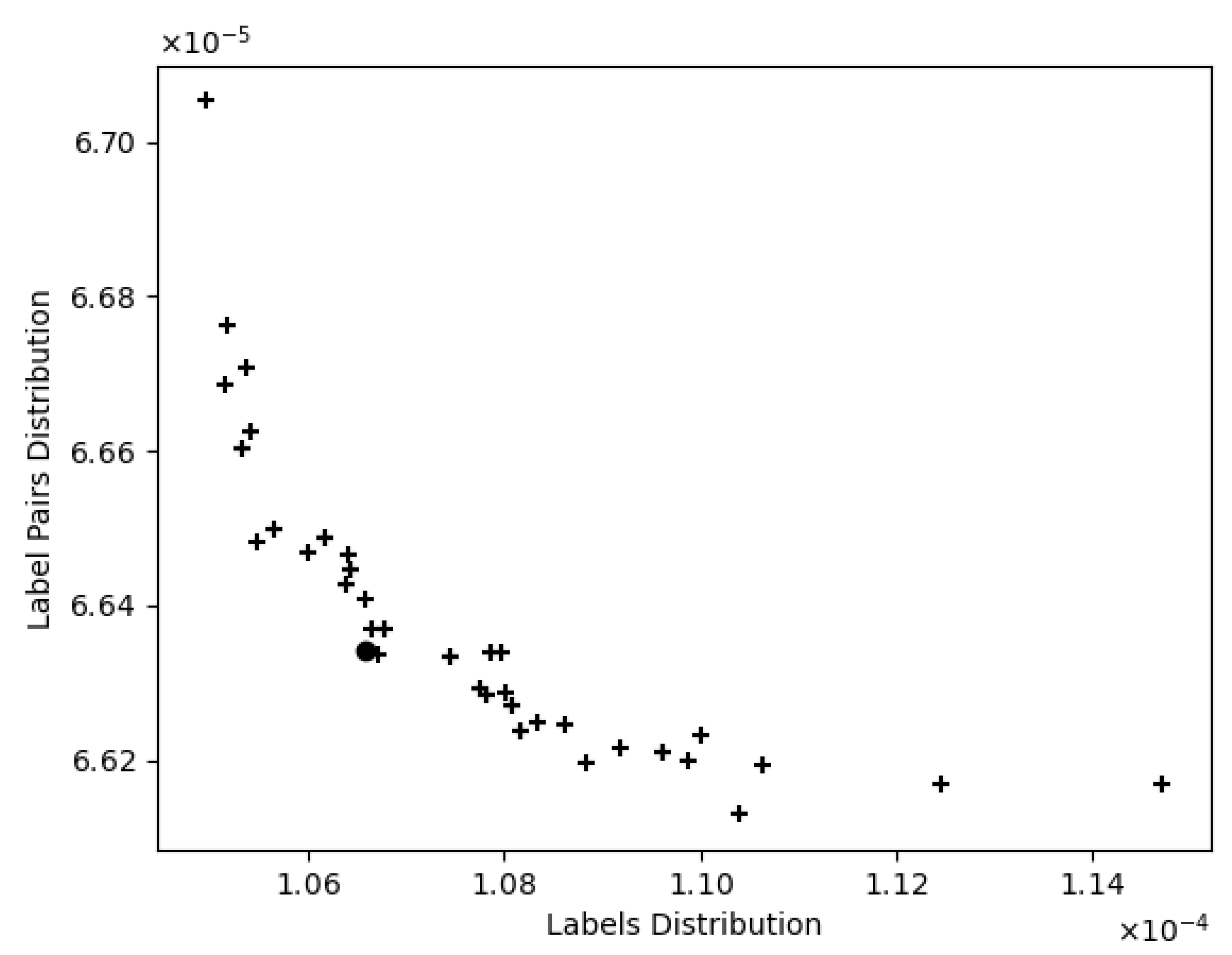
Therefore, this work employs NSGA-II to distribute the data set into subsets optimizing simultaneously both the Label Distribution and the Label Pair Distribution. The algorithm will obtain a set of solutions, some of them optimizing one over the other objective and vice versa. From these set of solutions, EvoSplit selects the solution closer (using Euclidean distance) to the coordinates origin (
Figure 2).
This work has employed the implementation of NSGA-II offered by pymoo [
39], a multi-objective optimization framework in Python, using the same parameters in terms of individuals, size of offspring and ending condition presented in
Section 3.3.
Results
Table 8 shows the results obtained for the different measures of the splits obtained using the MOEA unconstrained approach. The Examples Distribution measure is not shown as it is always zero, as with the previous evolutionary approaches. The obtained results are, in most cases, better that those obtained with the Stratification method. In this approach, unlike the previous single-objective evolutionary alternatives, results are good in terms of both
and
. The MOEA approach obtains results in terms of
close to those obtained by the single-objective approach optimizing only
(see
Table 3), and close in terms of
when the optimization is based only in
(see
Table 4). These are more balanced results than those obtained with the single-objective evolutionary approaches, i.e., a good result in one of the measures does not affect a good result in the other one. Additionally, results are also quite similar in terms of
and
. For those data sets with
different to zero,
Table 9 shows the results obtained with the constrained alternative. For some data sets,
is reduced without affecting considerably the
and
measures.
5. Evaluation of Classification
Next, this work evaluates the effect that the distribution of examples in a multi-label data set into subsets has on the classification metrics. Similarly to [
13], the evaluation is carried out employing two standard multi-label classification algorithms: Binary Relevance (BR) and Label Powerset (LP). The results of the classification are measured using recall, precision,
score and Jaccard index. These metrics are calculated using both micro-average (i.e., calculate metrics globally by counting the total true positives, false negatives and false positives) and macro-average (i.e., calculate metrics for each label, and then their unweighted mean). The variance in the classification across different folds is also analyzed, which provides information about the generalization stability of the different approaches.
Following [
12,
13], the results are discussed based on the average ranking of the different methods. The best method for a particular measure obtains a rank of 1, the next one a rank of 2, and so on.
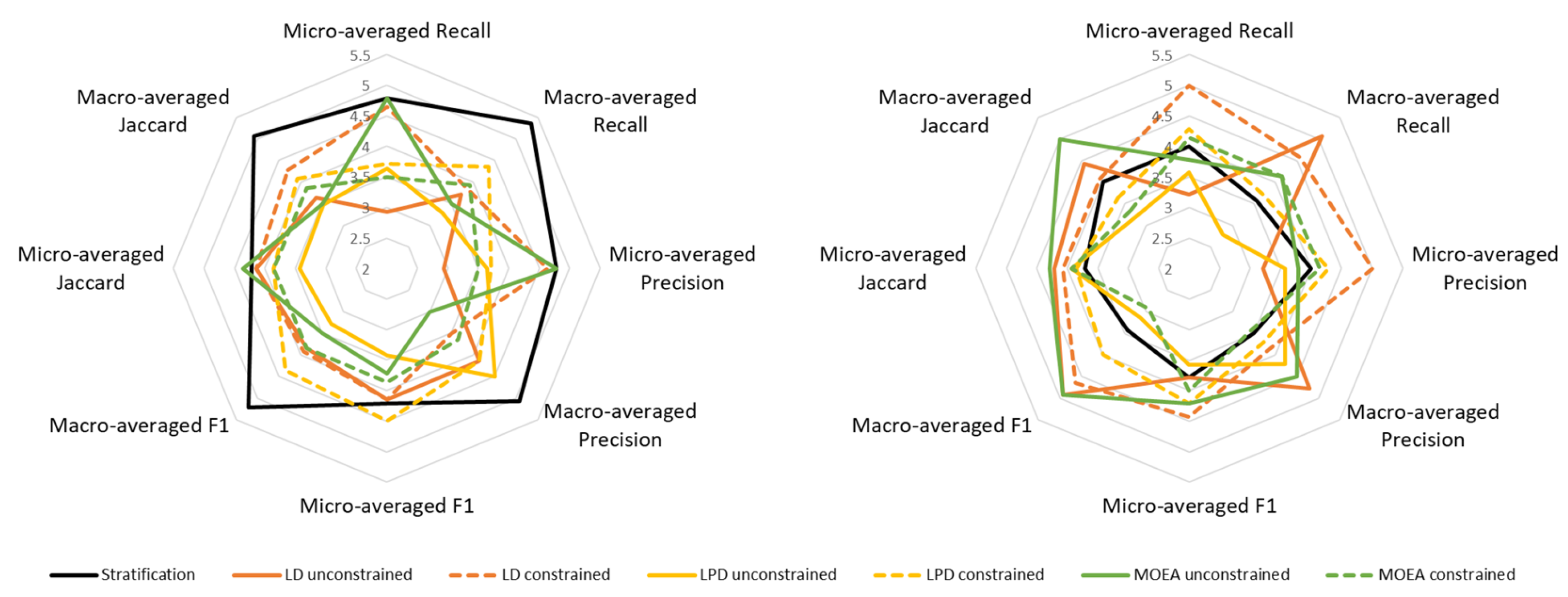
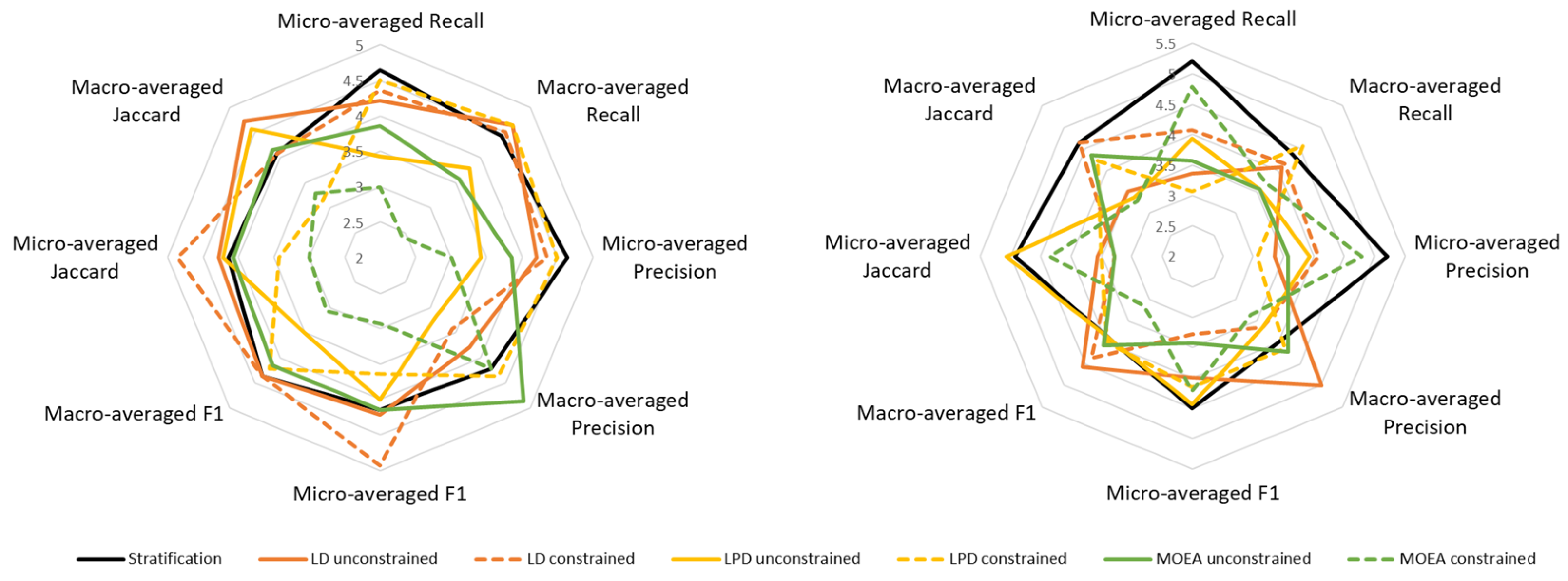
Figure 3 and
Figure 4 show the evaluations for both classification algorithms, BR and LP. Evolutionary approaches obtain, in general, better classification results than the Stratification method for all the metrics (left part of the figures). Even in the case of the constrained approaches, in which it is supposed to favor better results in macro-averaged metrics maybe in prejudice of micro-averaged metrics, evolutionary approaches behave better than Stratification. Using BR the best classification metrics are obtained by the unconstrained EA using LPD as fitness function followed by the constrained MOEA. Regarding variance over folds, these two methods are also the best ones. Using LP the best method is, for almost all the metrics, the constrained MOEA followed by the unconstrained EA using LPD. In terms of variance over folds, all the evolutionary approach have globally a similar behavior, being better than Stratification.
7. Conclusions
This paper presents EvoSplit, a novel evolutionary method to split a multi-label data set into disjoint subsets. Different proposals, single-objective and multi-objective, using diverse measures as fitness function, have been proposed. A constraint has also been introduced in order to ensure that, if possible, labels are distributed among all subsets. In almost all the cases, the multi-objective proposal obtains state-of-the-art results, improving or matching the quality of the splits officially provided or obtained with iterative stratification methods. The improvement of EvoSplit over previous methods is highlighted when applied to very large data sets, as those currently used in machine learning and computer vision applications.
Moreover, the introduction of the constrained optimization decreases the chance of producing subsets with zero positive examples for one or more labels. This should have an effect on the training as there will be fewer labels for which there are no training or validation examples. A very relevant result is that EvoSplit is able to find splits that fulfill the constrain without affecting too much the distribution of labels and label pairs.
EvoSplit is able to obtain better distributions of the original data sets considering the desired size of the subsets as a hard constraint, i.e., ensuring that the Examples Distribution is equal to zero. This is not the case for the iterative stratification method. The subsets obtained with EvoSplit allow better classification results and reduce the variance in the performance across subsets/folds.
Only in the case of the Imagenet data set, the best results are not obtained by the multi-objective EA but by the single-objective EA optimizing the Label Pair Distribution measure. An explanation to this might be related to the relation in the diversity between labels and pair labels for this data set. This data set has a particular characteristic: there are almost eight times more different pair labels than different labels in the data set (see the Diversity measure in
Table 1 and
Table 2). For all the other data sets, the relation is close to one. Therefore, this larger proportion in the diversity of label pairs might have an influence, benefiting the optimization based only on label pairs.
In conclusion, EvoSplit supports researchers in the process of creating a data set by providing different evolutionary alternatives to split that data set by optimizing the distribution of examples into the different subsets. EvoSplit can, in the future, be extended to higher levels of relationship between labels, e.g., triplets, by implementing a many-objective evolutionary algorithm [
40].









{kind=link}
{kind=link}
{kind=link}
{kind=link}