
Empirical Evaluation on Utilizing CNN-Features for Seismic Patch Classification



Abstract
:Featured Application
Abstract
1. Introduction
2. Related Work
2.1. Seismic Fault Detection
2.2. CNN-Features
2.3. Data Complexity
3. Methods and Data
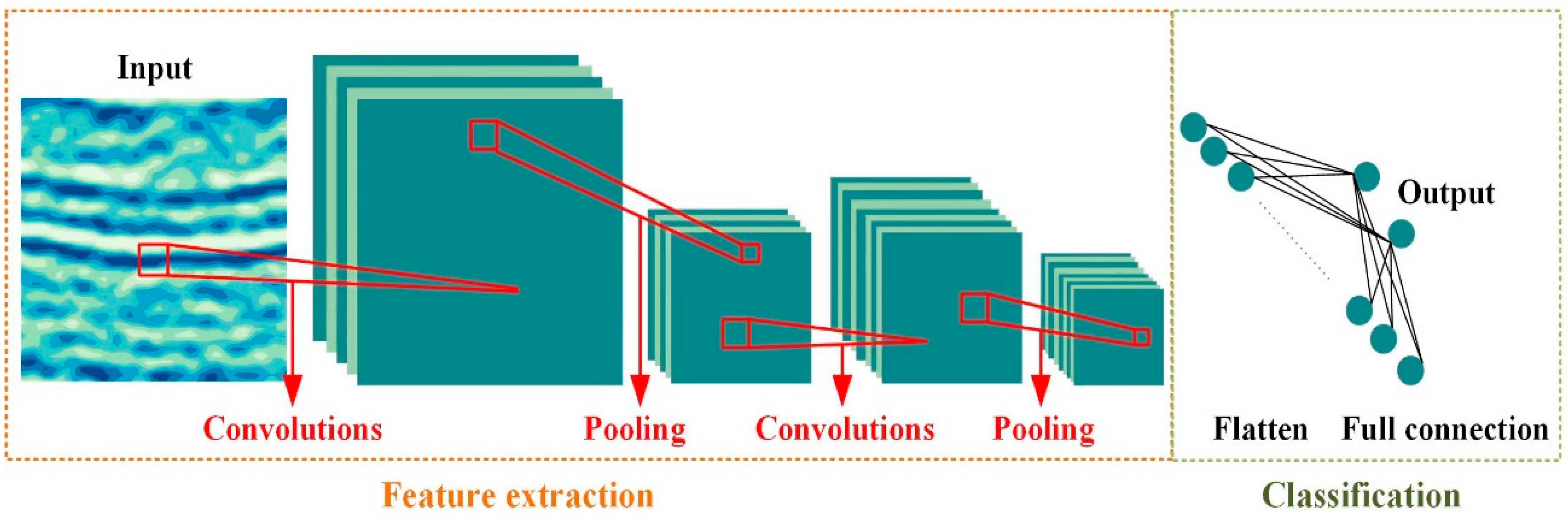
3.1. Classification Methods
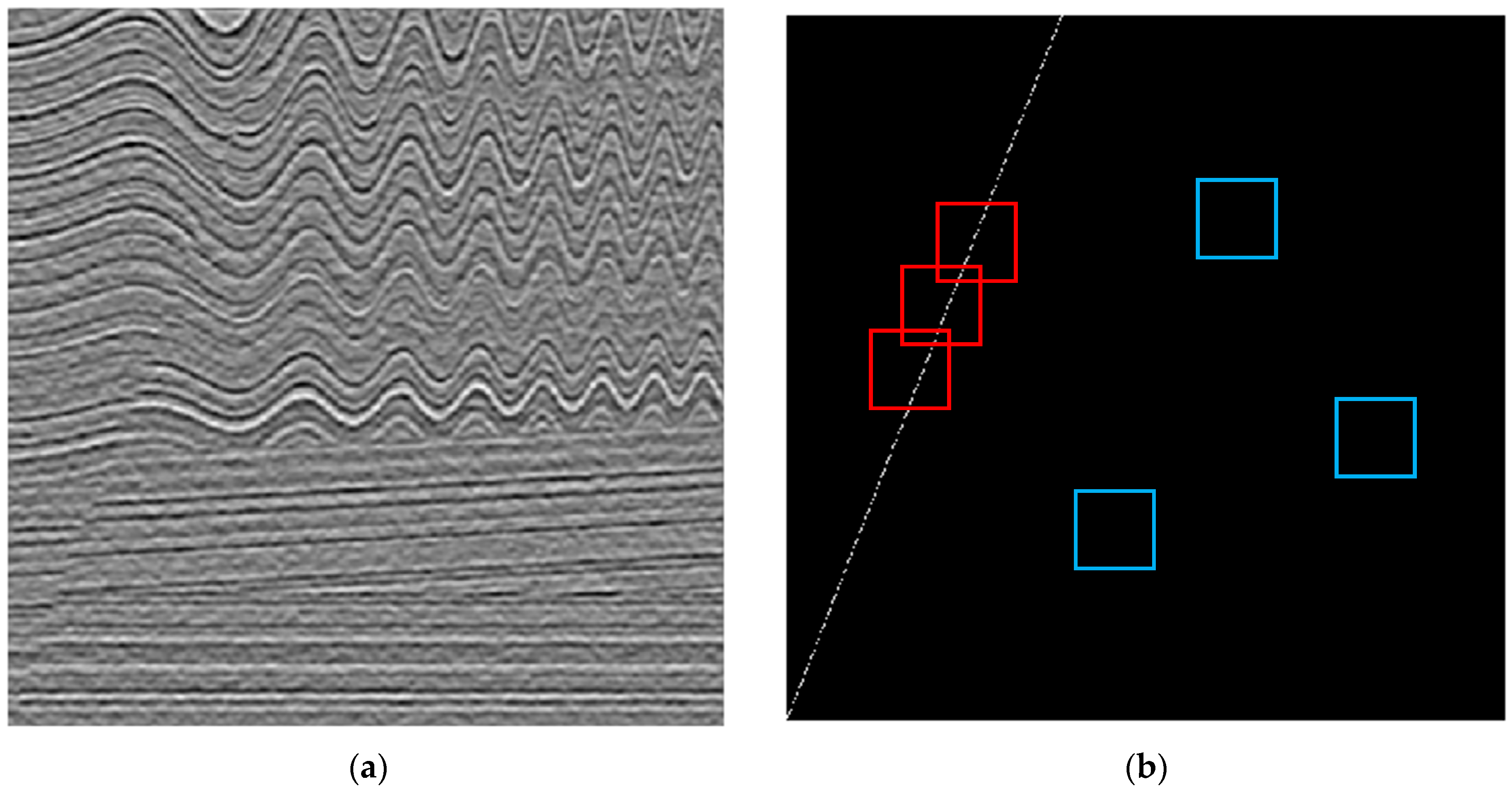
3.2. Seismic Data
4. Experimental Study
4.1. Synthetic and Real Experimental Data
4.2. CNN Models Implemented
4.3. Classification Accuracy Rates
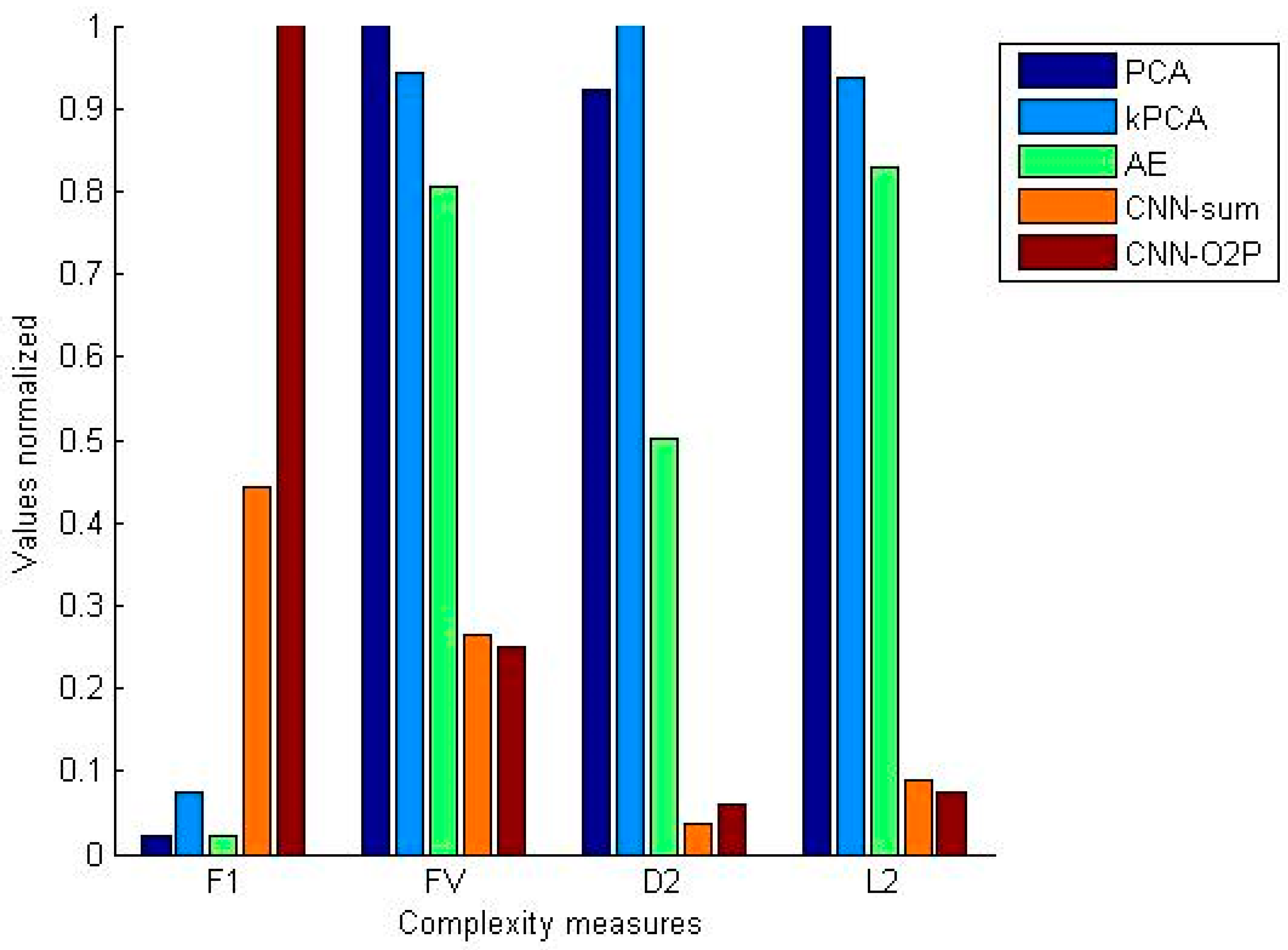
4.4. Data Complexity Measures
4.5. Time Complexity
4.6. Summary and Future Challenges
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Glossary
| Abbreviation | Meaning |
| AE | auto-encoder |
| B-CNN | bilinear convolutional neural network |
| BP | backward propagation |
| BiP | bilinear pooling |
| C | convolutional |
| CNN | convolutional neural network |
| FC | fully connected layer |
| FP | forward propagation |
| GPU | graphics computing units |
| HOG | histogram of oriented gradients |
| HYB | hybrid method of combining linear (nonlinear) classifier with CNN |
| iSQRT-COV | iterative matrix square root normalization of covariance pooling |
| LBP | local binary pattern |
| MPN-COV | matrix power normalized covariance pooling |
| O2P | second-order pooling |
| PCA | principal component analysis |
| PR | pattern recognition |
| SVM | support vector machine |
References
- Cunha, A.; Pochet, A.; Lopes, H.; Gattass, M. Seismic fault detection in real data using transfer learning from a convolutional neural network pre-trained with synthetic seismic data. Comput. Geosci. 2020, 135, 104344. [Google Scholar] [CrossRef]
- Di, H.; Wang, Z.; AlRegib, G. Seismic fault detection from post-stack amplitude by convolutional neural networks. In Proceedings of the 80th EAGE Conference & Exhibition, Copenhagen, Denmark, 11–14 June 2018; pp. 1–5. [Google Scholar] [CrossRef] [Green Version]
- Hung, L.; Dong, X.; Clee, T. A scalable deep learning platform for identifying geologic features from seismic attributes. Lead. Edge 2017, 36, 249–256. [Google Scholar] [CrossRef]
- Pochet, A.; Diniz, P.H.B.; Lopes, H.; Gattass, H. Seismic fault detection using convolutional neural networks trained on synthetic poststacked amplitude maps. IEEE Geosci. Remote Sens. Lett. 2019, 16, 352–356. [Google Scholar] [CrossRef]
- Wang, Z.; Di, H.; Shafiq, M.A.; Alaudah, Y.; AlRegib, G. Successful leveraging of image processing and machine learning in seismic structural interpretation: A review. Lead. Edge 2018, 37, 451–461. [Google Scholar] [CrossRef]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. DeCAF: A deep convolutional activation feature for generic visual recognition. In Proceedings of the 31st International Conference on Machine Learning (ICML), Beijing, China, 21–26 June 2014; pp. 647–655. [Google Scholar]
- Alshazly, H.; Linse, C.; Barth, E.; Martinetz, T. Handcrafted versus CNN features for ear recognition. Symmetry 2019, 11, 1493. [Google Scholar] [CrossRef] [Green Version]
- Athiwaratkun, B.; Kang, K. Feature representation in convolutional neural networks. arXiv 2015, arXiv:1507.02313. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Razavian, L.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN features off-the-shelf: An astounding baseline for recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 806–813. [Google Scholar] [CrossRef] [Green Version]
- Weimer, D.; Scholz-Reiter, B.; Shpitalni, M. Design of deep convolutional neural network architectures for automated feature extraction in industrial inspection. CIRP Ann.-Manuf. Technol. 2016, 65, 417–420. [Google Scholar] [CrossRef]
- Lin, T.-Y.; RoyChowdhury, A.; Maji, S. Bilinear CNN models for fine-grained visual recognition. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1449–1457. [Google Scholar] [CrossRef]
- Lorena, A.C.; Garcia, L.P.F.; Lehmann, J.; Souto, M.C.P.; Ho, T.K. How complex is your classification problem? A survey on measuring classification complexity. ACM Comput. Surv. 2018, 52, 1–34. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.-X.; Wei, X.-L.; Kim, S.-W. Empirical evaluation on utilizing CNN-features for seismic patch classification. In Proceedings of the 10th International Conference on Pattern Recognition Applications and Methods (ICPRAM), Online, 4–6 February 2021; pp. 166–173. [Google Scholar] [CrossRef]
- Carreira, J.; Caseiro, R.; Batista, J.; Sminchisescu, C. Semantic segmentation with second-order pooling. In Proceedings of the 12th European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 430–443. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef] [Green Version]
- Marfurt, K.; Kirlin, R.; Farmer, S.; Bahorich, M. 3-D seismic attributes using a semblance-based coherency algorithm. Geophysics 1998, 63, 1150–1165. [Google Scholar] [CrossRef] [Green Version]
- Marfurt, K.J.; Sudhaker, V.; Gersztenkorn ACrawford, K.D.; Nissen, S.E. Coherency calculations in the presence of structural dip. Geophysics 1999, 64, 104–111. [Google Scholar] [CrossRef]
- Wang, Z.; Alregib, G. Interactive fault extraction in 3-D seismic data using the Hough Transform and tracking vectors. IEEE Trans. Comput. Imaging 2017, 3, 99–109. [Google Scholar] [CrossRef]
- Di, H.; Amir Shaq, M.; AlRegib, G. Seismic fault detection based on multi-attribute support vector machine analysis. In SEG Technical Program Expanded Abstracts; SEG: Houston, TX, USA, 2017; pp. 2039–2244. [Google Scholar] [CrossRef] [Green Version]
- Di, H.; Shaq, M.; AlRegib, G. Patch-level MLP classification for improved fault detection. In SEG Technical Program Expanded Abstracts; SEG: Anaheim, CA, USA, 2018; pp. 2211–2215. [Google Scholar] [CrossRef] [Green Version]
- An, Y.; Guo, J.; Ye, Q.; Childs, C.; Walsh, J.; Dong, R. Deep convolutional neural network for automatic fault recognition from 3D seismic datasets. Comput. Geosci. 2021, 153, 104776. [Google Scholar] [CrossRef]
- Wei, X.; Zhang, C.; Kim, S.; Jing, K.; Wang, Y.; Xu, S.; Xie, Z. Seismic fault detection using convolutional neural networks with focal loss. Comput. Geosci. 2022, 158, 104968. [Google Scholar] [CrossRef]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Learning and transferring mid-level image representations using convolutional neural networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 6–7 September 2014; pp. 1717–1724. [Google Scholar] [CrossRef] [Green Version]
- Hertel, L.; Barth, E.; Käster, T.; Martinetz, T. Deep convolutional neural networks as generic feature extractors. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–4. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks, Advances. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting unreasonable effectiveness of data in deep learning era. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 843–852. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning Research (PMLR), Vancouver, CA, USA, 9–15 June 2019; Volume 97, pp. 6105–6114. [Google Scholar]
- Gao, Y.; Beijbom, O.; Zhang, N.; Darrell, T. Compact bilinear pooling. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 317–326. [Google Scholar] [CrossRef] [Green Version]
- Ionescu, C.; Vantzos, O.; Sminchisescu, C. Training deep networks with structured layers by matrix backpropagation. arXiv 2016, arXiv:1509.07838v4. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maji, S. Improved bilinear pooling with CNNs. In Proceedings of the 31st British Machine Vision Conference (BMVC), London, UK, 7–10 September 2017. [Google Scholar] [CrossRef] [Green Version]
- Li, P.; Xie, J.; Wang, Q.; Zuo, W. Is second-order information helpful for large-scale visual recognition? In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [CrossRef] [Green Version]
- Li, P.; Xie, J.; Wang, Q.; Zuo, W. Towards faster training of global covariance pooling networks by iterative matrix square root normalization. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 947–955. [Google Scholar] [CrossRef] [Green Version]
- Ho, T.K.; Basu, M. Complexity measures of supervised classification problems. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 289–300. [Google Scholar] [CrossRef] [Green Version]
- Cano, J.-R. Analysis of data complexity measures for classification. Expert Syst. Appl. 2013, 40, 4820–4831. [Google Scholar] [CrossRef]
- Sotoca, J.M.; Mollineda, R.A.; Sánchez, J.S. A meta-learning framework for pattern classification by means of data complexity measures. Revista Iberoamericana de Inteligencia Artificial 2006, 10, 31–38. [Google Scholar] [CrossRef]
- Hale, D. Seismic Image Processing for Geologic Faults. 2014. Available online: https://github.com/dhale/ipf (accessed on 28 August 2020).
- Wang, Q. Kernel principal component analysis and its applications in face recognition and active shape models. arXiv 2012, arXiv:1207.3538. [Google Scholar]
- Gogna, A.; Majumdar, A. Discriminative autoencoder for feature extraction: Application to character recognition. Neural Process. Lett. 2019, 49, 1723–1735. [Google Scholar] [CrossRef] [Green Version]
- Palm, R.B. Prediction as a Candidate for Learning Deep Hierarchical Models of Data. 2012. Available online: https://github.com/rasmusbergpalm/DeepLearnToolbox (accessed on 15 October 2020).
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. Available online: https://www.csie.ntu.edu.tw/~cjlin/libsvm (accessed on 8 February 2021). [CrossRef]
- Netherland Offshore F3 Block Complete. Available online: https://www.opendtect.org/osr/Main/NetherlandsOffshoreF3BlockComplete4GB (accessed on 15 September 2021).
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014; pp. 1–14. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Layer Descriptions | Input Size | Output Size | Feature Maps | Kernel Size |
|---|---|---|---|---|
| 1st convolution and subsampling | 45 × 45 | 40 × 40 | 4 (8) | 6 × 6 |
| 2nd convolution and subsampling | 20 × 20 | 16 × 16 | 8 (16) | 5 × 5 |
| Fully connected | 512 × 1 | 2 × 1 |
| Classifiers (Types) | Feature Extraction Methods | ||||
|---|---|---|---|---|---|
| PCA | kPCA | AE | CNN-Sum | CNN-O2P | |
| kNN (k = 1) | 92.47 | 93.10 | 86.33 | 95.67 | 99.03 |
| kNN (k = 3) | 84.52 | 86.56 | 74.59 | 93.19 | 98.47 |
| SVM (polyn.) | 80.20 | 86.69 | 72.69 | 85.88 | 96.21 |
| SVM (RBF) | 91.16 | 93.32 | 83.58 | 95.91 | 97.99 |
| Data | PCA | kPCA | AE | CNN |
|---|---|---|---|---|
| Train1 | 8.3 | 7775.0 | 9560.8 | 35.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Wei, X.; Kim, S.-W. Empirical Evaluation on Utilizing CNN-Features for Seismic Patch Classification. Appl. Sci. 2022, 12, 197. https://doi.org/10.3390/app12010197
Zhang C, Wei X, Kim S-W. Empirical Evaluation on Utilizing CNN-Features for Seismic Patch Classification. Applied Sciences. 2022; 12(1):197. https://doi.org/10.3390/app12010197
Chicago/Turabian StyleZhang, Chunxia, Xiaoli Wei, and Sang-Woon Kim. 2022. "Empirical Evaluation on Utilizing CNN-Features for Seismic Patch Classification" Applied Sciences 12, no. 1: 197. https://doi.org/10.3390/app12010197
APA StyleZhang, C., Wei, X., & Kim, S. -W. (2022). Empirical Evaluation on Utilizing CNN-Features for Seismic Patch Classification. Applied Sciences, 12(1), 197. https://doi.org/10.3390/app12010197