
An Approach for Pronunciation Classification of Classical Arabic Phonemes Using Deep Learning

 , ,
, ,
Abstract
:1. Introduction
1.1. Arabic Phonemes and Their Pronunciation
1.2. Motivation for Pronunciation Classification
1.3. Objectives and Contributions
- Collection of an audio dataset for the Arabic alphabet focused on the three states of vowels for each alphabet.
- Classification of Arabic short vowels by recognizing the correct short vowels from a recorded phoneme.
- Constructing a general CNN architecture for phoneme classification. This allows replicating the architecture for similar tasks or a different number of classes.
- Sharing our experience of model optimization and fine-tuning with the researchers and practitioners to aid their knowledge of building better models in the future.
2. Related Work
2.1. Pronunciation Detection
2.2. Audio Features
2.3. Tools in Arabic Learning
2.4. Audio Datasets in CA
2.5. Summary of the Literature
3. Materials and Methods
3.1. Data Collection
3.2. Data Preprocessing
3.3. Spectrogram Conversion
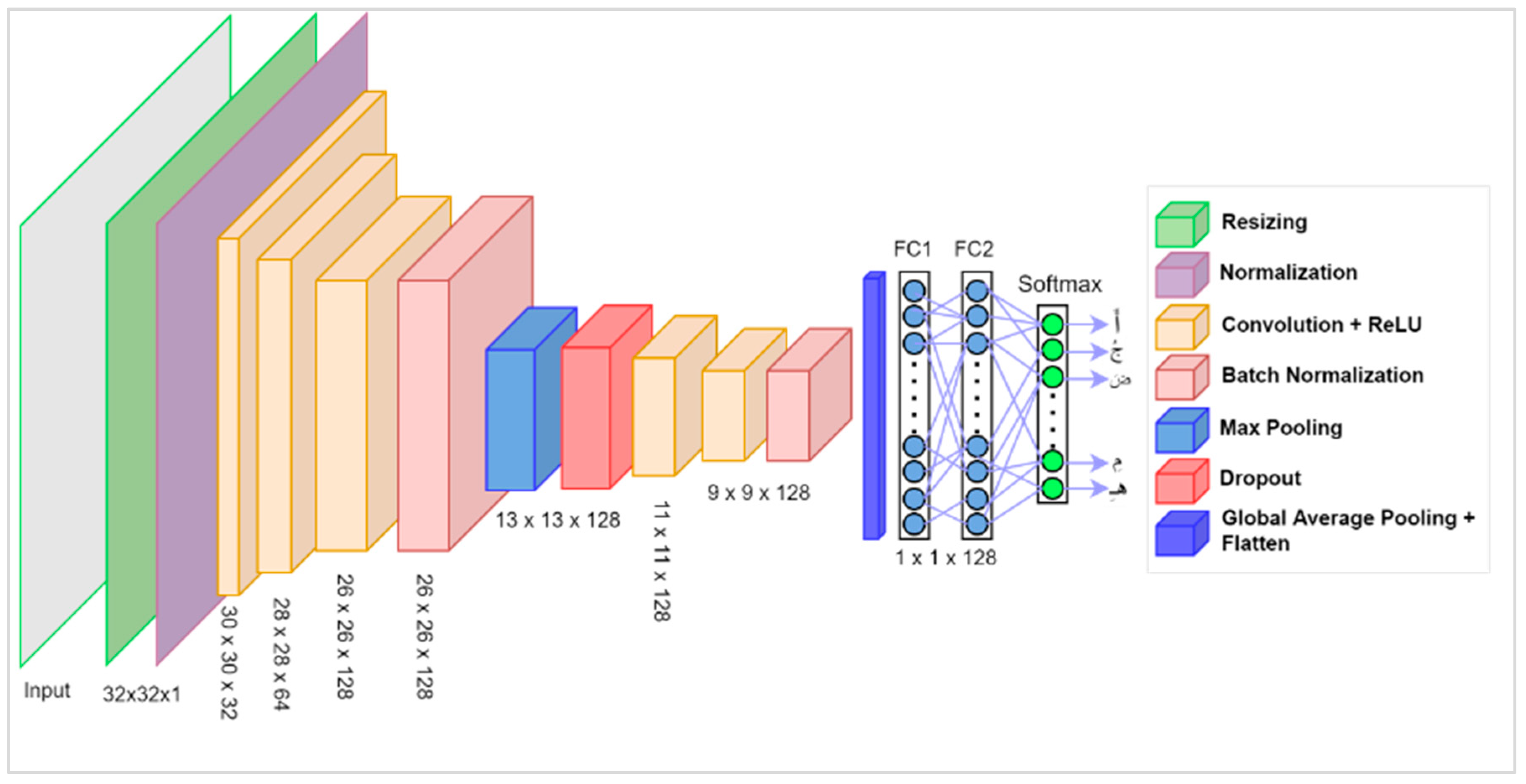
4. CNN Model for Arabic Short Vowels Classification
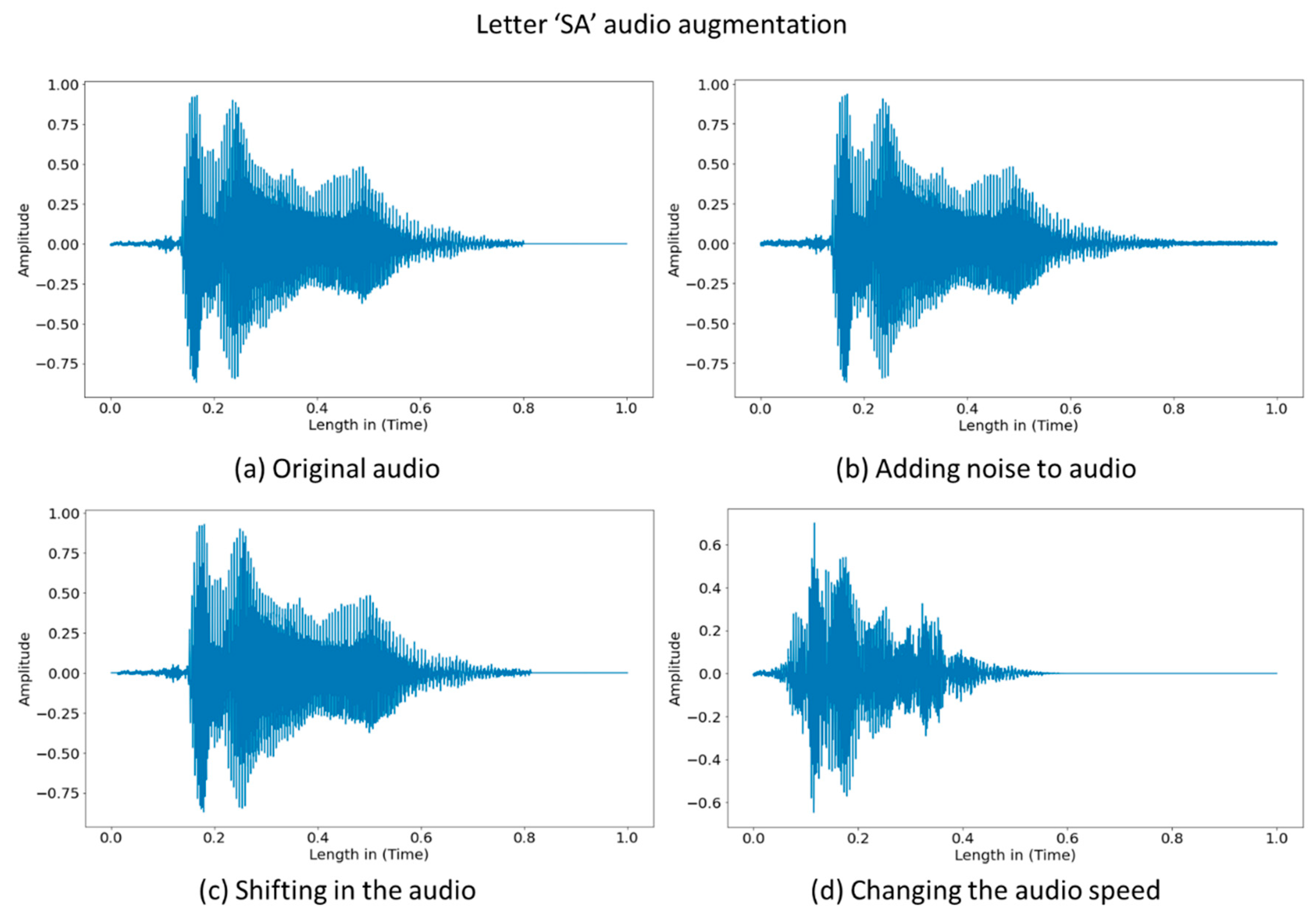
4.1. Data Augmentation
4.2. Fine-Tuning the CNN Architecture
4.3. Hyperparameters Tuning
| Algorithm 1: Steps of classification of Arabic short vowels on a fully optimized and fine-tuned neural network |
| Input aDataset = Audio dataset labels = Labels of classes train_files, val_files, test_files = split(aDataset(80,10,10)) Output Accuracy = Model accuracy Loss = Model learning loss y_pred = Predicted labels Algorithm Begin waveform_ds = Map waveform and labels from aDataset spectrogram_ds = Map spectrogram and labels from waveform_ds Function preprocess_dataset(files) output_ds = Map waveform_ds from files_ds of files output_ds = Map spectrogram_ds of output_ds Return output_ds Endfunction train_ds = preprocess_dataset from train_files val_ds = preprocess_dataset from val_files test_ds = preprocess_dataset from test_files input_shape = Shape of spectrogram in spectrogram_ds norm_layer = Normalization in preprocessing model = Sequential(input_shape, Resizing(32, 32), norm_layer, layers) trainNetwork train_ds, val_ds, callbacks = [lr_scheduler,callback_Early_stopping, model_checkpoint_callback, tensorboard_callback] load weights of best_model model train accuracy = Evaluate(train_ds) model val accuracy = Evaluate(val_ds) model test_accuracy = Evaluate(test_ds) Loss_graph metrics[‘loss’], metrics[‘val_loss’] Accuracy_graph metrics[‘Accuracy’], metrics[‘val_ Accuracy’] End |
4.4. Model Execution
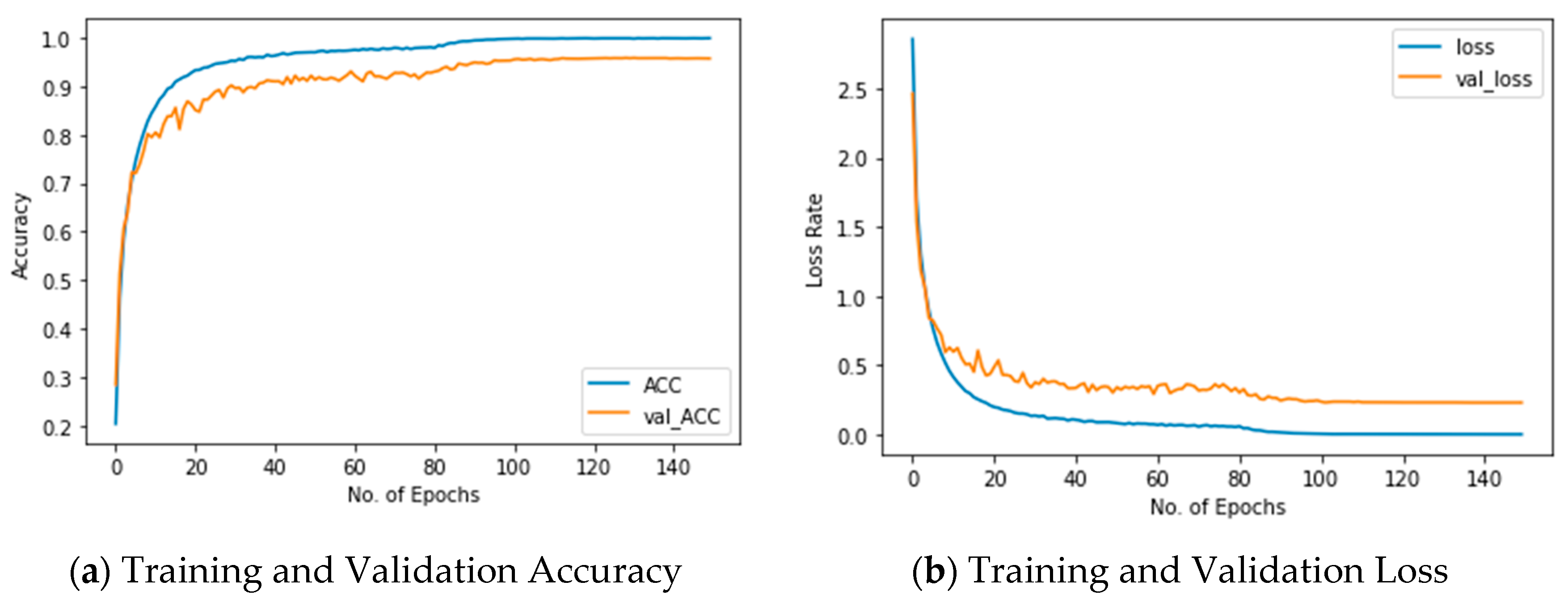
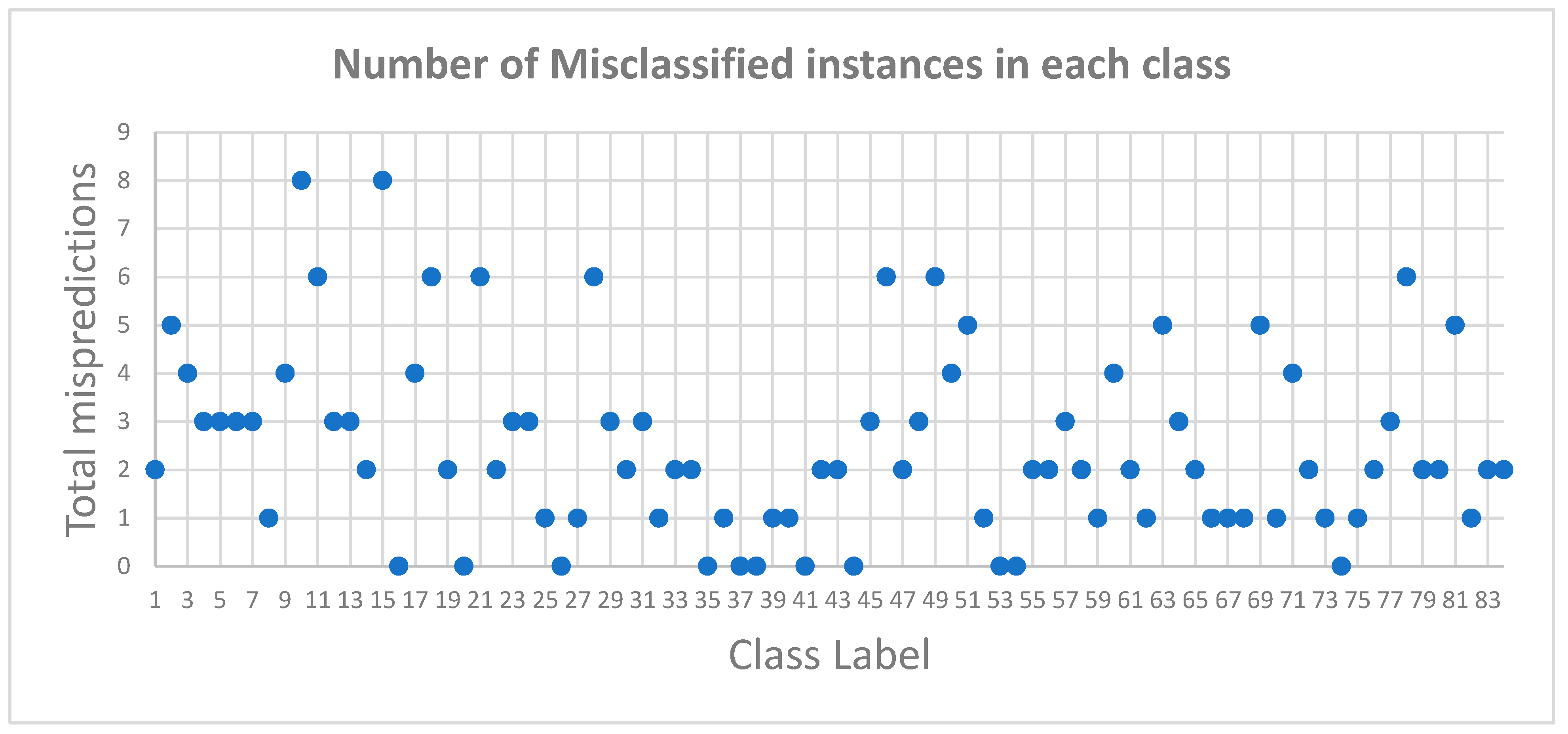
5. Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Julian, G. What are the most spoken languages in the world. Retrieved May 2020, 31, 2020. [Google Scholar]
- Ali, A.; Chowdhury, S.; Afify, M.; El-Hajj, W.; Hajj, H.; Abbas, M.; Hussein, A.; Ghneim, N.; Abushariah, M.; Alqudah, A. Connecting Arabs: Bridging the gap in dialectal speech recognition. Commun. ACM 2021, 64, 124–129. [Google Scholar] [CrossRef]
- Twaddell, W.F. On defining the phoneme. Language 1935, 11, 5–62. [Google Scholar] [CrossRef]
- Ibrahim, A.B.; Seddiq, Y.M.; Meftah, A.H.; Alghamdi, M.; Selouani, S.-A.; Qamhan, M.A.; Alotaibi, Y.A.; Alshebeili, S.A. Optimizing arabic speech distinctive phonetic features and phoneme recognition using genetic algorithm. IEEE Access 2020, 8, 200395–200411. [Google Scholar] [CrossRef]
- Witt, S.M. Automatic error detection in pronunciation training: Where we are and where we need to go. In Proceedings of the International Symposium on Automatic Detection on Errors in Pronunciation Training, Stockholm, Sweden, 6–8 June 2012. [Google Scholar]
- Huang, H.; Xu, H.; Hu, Y.; Zhou, G. A transfer learning approach to goodness of pronunciation based automatic mispronunciation detection. J. Acoust. Soc. Am. 2017, 142, 3165–3177. [Google Scholar] [CrossRef] [PubMed]
- Al-Marri, M.; Raafat, H.; Abdallah, M.; Abdou, S.; Rashwan, M. Computer Aided Qur’an Pronunciation using DNN. J. Intell. Fuzzy Syst. 2018, 34, 3257–3271. [Google Scholar] [CrossRef]
- Ibrahim, N.J.; Idris, M.Y.I.; Yusoff, M.Z.M.; Anuar, A. The problems, issues and future challenges of automatic speech recognition for quranic verse recitation: A review. Al-Bayan J. Qur’an Hadith Stud. 2015, 13, 168–196. [Google Scholar] [CrossRef]
- Arafa, M.N.M.; Elbarougy, R.; Ewees, A.A.; Behery, G. A Dataset for Speech Recognition to Support Arabic Phoneme Pronunciation. Int. J. Image Graph. Signal Process. 2018, 10, 31–38. [Google Scholar] [CrossRef] [Green Version]
- Ziafat, N.; Ahmad, H.F.; Fatima, I.; Zia, M.; Alhumam, A.; Rajpoot, K. Correct Pronunciation Detection of the Arabic Alphabet Using Deep Learning. Appl. Sci. 2021, 11, 2508. [Google Scholar] [CrossRef]
- Czerepinski, K. Tajweed Rules of the Qur’an: Part 1; Dar Al Khair: Riyadh, Saudi Arabia, 2005. [Google Scholar]
- Alghamdi, M.M. A spectrographic analysis of Arabic vowels: A cross-dialect study. J. King Saud Univ. 1998, 10, 3–24. [Google Scholar]
- Nazir, F.; Majeed, M.N.; Ghazanfar, M.A.; Maqsood, M. Mispronunciation detection using deep convolutional neural network features and transfer learning-based model for Arabic phonemes. IEEE Access 2019, 7, 52589–52608. [Google Scholar] [CrossRef]
- Nassif, A.B.; Shahin, I.; Attili, I.; Azzeh, M.; Shaalan, K. Speech recognition using deep neural networks: A systematic review. IEEE Access 2019, 7, 19143–19165. [Google Scholar] [CrossRef]
- Duan, R.; Kawahara, T.; Dantsuji, M.; Nanjo, H. Efficient learning of articulatory models based on multi-label training and label correction for pronunciation learning. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 6239–6243. [Google Scholar]
- Necibi, K.; Bahi, H. An arabic mispronunciation detection system by means of automatic speech recognition technology. In Proceedings of the 13th International Arab Conference on Information Technoloy Proceedings, Zarqa, Jordan, 10–13 December 2012; pp. 303–308. [Google Scholar]
- Al Hindi, A.; Alsulaiman, M.; Muhammad, G.; Al-Kahtani, S. Automatic pronunciation error detection of nonnative Arabic Speech. In Proceedings of the 2014 IEEE/ACS 11th International Conference on Computer Systems and Applications (AICCSA), Doha, Qatar, 10–13 November 2014; pp. 190–197. [Google Scholar]
- Khan, A.F.A.; Mourad, O.; Mannan, A.M.K.B.; Dahan, H.B.A.M.; Abushariah, M.A. Automatic Arabic pronunciation scoring for computer aided language learning. In Proceedings of the 2013 1st International Conference on Communications, Signal Processing, and their Applications (ICCSPA), Sharjah, United Arab Emirates, 12–14 February 2013; pp. 1–6. [Google Scholar]
- Marlina, L.; Wardoyo, C.; Sanjaya, W.M.; Anggraeni, D.; Dewi, S.F.; Roziqin, A.; Maryanti, S. Makhraj recognition of Hijaiyah letter for children based on Mel-Frequency Cepstrum Coefficients (MFCC) and Support Vector Machines (SVM) method. In Proceedings of the 2018 International Conference on Information and Communications Technology (ICOIACT), Yogyakarta, Indonesia, 6–7 March 2018; pp. 935–940. [Google Scholar]
- Akhtar, S.; Hussain, F.; Raja, F.R.; Ehatisham-ul-haq, M.; Baloch, N.K.; Ishmanov, F.; Zikria, Y.B. Improving mispronunciation detection of arabic words for non-native learners using deep convolutional neural network features. Electronics 2020, 9, 963. [Google Scholar] [CrossRef]
- Leung, W.-K.; Liu, X.; Meng, H. CNN-RNN-CTC based end-to-end mispronunciation detection and diagnosis. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8132–8136. [Google Scholar]
- Zainon, N.Z.; Ahmad, Z.; Romli, M.; Yaacob, S. Speech quality based on Arabic pronunciation using MFCC and LDA: Investigating the emphatic consonants. In Proceedings of the 2012 IEEE International Conference on Control System, Computing and Engineering, Penang, Malaysia, 23–25 November 2012; pp. 398–403. [Google Scholar]
- Aissiou, M. A genetic model for acoustic and phonetic decoding of standard Arabic vowels in continuous speech. Int. J. Speech Technol. 2020, 23, 425–434. [Google Scholar] [CrossRef]
- Abdou, S.M.; Rashwan, M. A Computer Aided Pronunciation Learning system for teaching the holy quran Recitation rules. In Proceedings of the 2014 IEEE/ACS 11th International Conference on Computer Systems and Applications (AICCSA), Doha, Qatar, 10–13 November 2014; pp. 543–550. [Google Scholar]
- Necibi, K.; Frihia, H.; Bahi, H. On the use of decision trees for arabic pronunciation assessment. In Proceedings of the International Conference on Intelligent Information Processing, Security and Advanced Communication, Batna, Algeria, 23–25 November 2015; pp. 1–6. [Google Scholar]
- Abdelhamid, A.A.; Alsayadi, H.A.; Hegazy, I.; Fayed, Z.T. End-to-End Arabic Speech Recognition: A Review. In Proceedings of the 19th Conference of Language Engineering (ESOLEC’19), Alexandria, Egypt, 26–30 September 2020. [Google Scholar]
- Fadel, A.; Tuffaha, I.; Al-Ayyoub, M. Arabic text diacritization using deep neural networks. In Proceedings of the 2019 2nd International Conference on computer Applications & Information Security (ICCAIS), Riyadh, Saudi Arabia, 1–3 May 2019; pp. 1–7. [Google Scholar]
- Al-Anzi, F.S.; AbuZeina, D. Synopsis on Arabic speech recognition. Ain Shams Eng. J. 2021, 13, 9. [Google Scholar] [CrossRef]
- Lamel, L.; Messaoudi, A.; Gauvain, J.-L. Automatic speech-to-text transcription in Arabic. TALIP 2009, 8, 1–18. [Google Scholar] [CrossRef]
- Alotaibi, Y.A.; Hussain, A. Comparative analysis of Arabic vowels using formants and an automatic speech recognition system. Int. J. Signal Process. Image Process. Pattern Recognit. 2010, 3, 11–22. [Google Scholar]
- Yu, D.; Li, J. Recent progresses in deep learning based acoustic models. IEEE/CAA J. Autom. Sin. 2017, 4, 396–409. [Google Scholar] [CrossRef]
- Alqadheeb, F.; Asif, A.; Ahmad, H.F. Correct Pronunciation Detection for Classical Arabic Phonemes Using Deep Learning. In Proceedings of the 2021 International Conference of Women in Data Science at Taif University (WiDSTaif), Taif, Saudi Arabia, 30–31 March 2021; pp. 1–6. [Google Scholar]
- Wyse, L. Audio Spectrogram Representations for Processing with Convolutional Neural Networks. In Proceedings of the First International Conference on Deep Learning and Music, Anchorage, AK, USA, 17–18 May 2017; pp. 37–41. [Google Scholar]
- Mukhtar, H.; Qaisar, S.M.; Zaguia, A. Deep Convolutional Neural Network Regularization for Alcoholism Detection Using EEG Signals. Sensors 2021, 21, 5456. [Google Scholar] [CrossRef]
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional Neural Networks for Medical Image Analysis: Full Training or Fine Tuning? IEEE Trans. Med. Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef] [Green Version]
- Shorten, C.; M. Khoshgoftaar, T. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Wei, S.; Zou, S.; Liao, F. A Comparison on Data Augmentation Methods Based on Deep Learning for Audio Classification. J. Phys. Conf. Ser. 2020, 1453, 012085. [Google Scholar] [CrossRef]
- Nanni, L.; Maguolo, G.; Paci, M. Data augmentation approaches for improving animal audio classification. Ecol. Inform. 2020, 57, 101084. [Google Scholar] [CrossRef] [Green Version]
- Abd Almisreb, A.; Abidin, A.F.; Tahir, N.M. An acoustic investigation of Arabic vowels pronounced by Malay speakers. J. King Saud Univ. -Comput. Inf. Sci. 2016, 28, 148–156. [Google Scholar] [CrossRef] [Green Version]
- Traore, B.B.; Kamsu-Foguem, B.; Tangara, F. Deep convolution neural network for image recognition. Ecol. Inform. 2018, 48, 257–268. [Google Scholar] [CrossRef] [Green Version]
- Sun, M.; Song, Z.; Jiang, X.; Pan, J.; Pang, Y. Learning pooling for convolutional neural network. Neurocomputing 2017, 224, 96–104. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Baldi, P.; Sadowski, P.J. Understanding dropout. Adv. Neural Inf. Process. Syst. 2013, 26, 2814–2822. [Google Scholar]
- Sharma, S.; Sharma, S. Activation functions in neural networks. Towards Data Sci. 2017, 6, 310–316. [Google Scholar] [CrossRef]
- Young, H.P. Learning by trial and error. Games Econ. Behav. 2009, 65, 626–643. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z. Improved adam optimizer for deep neural networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; pp. 1–2. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Brownlee, J. How to Configure the Learning Rate When Training Deep Learning Neural Networks. Available online: https://machinelearningmastery.com/learning-rate-for-deep-learning-neural-networks/ (accessed on 10 November 2021).
- Google. TensorBoard: TensorFlow’s Visualization Toolkit. Available online: https://www.tensorflow.org/tensorboard (accessed on 19 August 2021).
- Lee, A.; Zhang, Y.; Glass, J. Mispronunciation detection via dynamic time warping on deep belief network-based posteriorgrams. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 8227–8231. [Google Scholar]
- Maqsood, M.; Habib, H.A.; Nawaz, T. An efficientmis pronunciation detection system using discriminative acoustic phonetic features for arabic consonants. Int. Arab J. Inf. Technol. 2019, 16, 242–250. [Google Scholar]
- Maqsood, M.; Habib, H.; Anwar, S.; Ghazanfar, M.; Nawaz, T. A comparative study of classifier based mispronunciation detection system for confusing Arabic phoneme pairs. Nucleus 2017, 54, 114–120. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gender | Status | Number of Records | Age Distribution |
|---|---|---|---|
| Male | Native | 40 | 7–50+ years old |
| Non-native | 2 | ||
| Female | Native | 41 | 7–40 years old |
| Non-native | 2 |
| Arabic short vowel | أَ | إِ | أُ | بَ | بِ | بُ | تَ | تِ | تُ | ثَ | ثِ | ثُ | جَ | جِ |
| Class label | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| IPA symbol | aa | ai | au | Ba | bi | bu | Ta | Ti | Tu | θa | θi | θu | dӡa | dӡi |
| Arabic short vowel | جُ | حَ | حِ | حُ | خَ | خِ | خُ | دَ | دِ | دُ | ذَ | ذِ | ذُ | رَ |
| Class label | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| IPA symbol | dӡu | ћa | ћi | Ћu | xa | xi | Xu | Da | Di | du | ða | Ði | ðu | ra |
| Arabic short vowel | رِ | رُ | زَ | زِ | زُ | سَ | سِ | سُ | شَ | شِ | شُ | صَ | صِ | صُ |
| Class label | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 |
| IPA symbol | ri | ru | za | Zi | zu | sa | Si | Su | ʃa | ʃi | ʃu | sҁa | sҁi | sҁu |
| Arabic short vowel | ضَ | ضِ | ضُ | طَ | طِ | طُ | ظَ | ظِ | ظُ | عَ | عِ | عُ | غَ | غِ |
| Class label | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 | 53 | 54 | 55 | 56 |
| IPA symbol | dҁa | dҁi | dҁu | tҁa | tҁi | tҁu | ðҁa | ðҁi | ðҁu | ʢa | ʢi | ʢu | ʁa | ʁi |
| Arabic short vowel | غُ | فَ | فِ | فُ | قَ | قِ | قُ | كَ | كِ | كُ | لَ | لِ | لُ | مَ |
| Class label | 57 | 58 | 59 | 60 | 61 | 62 | 63 | 64 | 65 | 66 | 67 | 68 | 69 | 70 |
| IPA symbol | ʁu | fa | fi | Fu | qa | Qi | Qu | Ka | Ki | ku | la | Li | lu | ma |
| Arabic short vowel | مِ | مُ | نَ | نِ | نُ | هـَ | هـِ | هـُ | وَ | وِ | وُ | يَ | يِ | يُ |
| Class label | 71 | 72 | 73 | 74 | 75 | 76 | 77 | 78 | 79 | 80 | 81 | 82 | 83 | 84 |
| IPA symbol | mi | Mu | na | Ni | nu | Ha | Hi | Hu | Wa | wi | wu | Ja | ji | ju |
| Exp. No. | Experiment Settings | Accuracy | ||
|---|---|---|---|---|
| Training | Validation | Testing | ||
| 1 | The original dataset on baseline CNN model (n = 6229) | 84.27% | 40.15% | 36.0% |
| 2 | The original dataset on fine-tuned model (n = 6229) | 99.74% | 59.33% | 56.91% |
| 3 | The augmented dataset using baseline CNN model (n = 49,829) | 98.93% | 90.63% | 90.0% |
| 4 | Model optimization, hyperparameter tuning, and augmented dataset (n = 49,829) | 99.9% | 95.87% | 95.77% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asif, A.; Mukhtar, H.; Alqadheeb, F.; Ahmad, H.F.; Alhumam, A. An Approach for Pronunciation Classification of Classical Arabic Phonemes Using Deep Learning. Appl. Sci. 2022, 12, 238. https://doi.org/10.3390/app12010238
Asif A, Mukhtar H, Alqadheeb F, Ahmad HF, Alhumam A. An Approach for Pronunciation Classification of Classical Arabic Phonemes Using Deep Learning. Applied Sciences. 2022; 12(1):238. https://doi.org/10.3390/app12010238
Chicago/Turabian StyleAsif, Amna, Hamid Mukhtar, Fatimah Alqadheeb, Hafiz Farooq Ahmad, and Abdulaziz Alhumam. 2022. "An Approach for Pronunciation Classification of Classical Arabic Phonemes Using Deep Learning" Applied Sciences 12, no. 1: 238. https://doi.org/10.3390/app12010238
APA StyleAsif, A., Mukhtar, H., Alqadheeb, F., Ahmad, H. F., & Alhumam, A. (2022). An Approach for Pronunciation Classification of Classical Arabic Phonemes Using Deep Learning. Applied Sciences, 12(1), 238. https://doi.org/10.3390/app12010238