
CAIT: A Predictive Tool for Supporting the Book Market Operation Using Social Networks


Abstract
:1. Introduction
- Find a better segmentation method.
- Adjust the prediction of copies to print to each segment found.
- Create a combined model of Artificial Intelligence techniques (CAIT), which will serve as a support tool to predict the number of books copies contributes to increasing revenue (publishers only).
2. Background
2.1. The Influence of Social Networks on Sales
2.2. The Success of a Book Based on Sales
2.3. Sales Segmentation Forecast Techniques
3. Research Design and Method
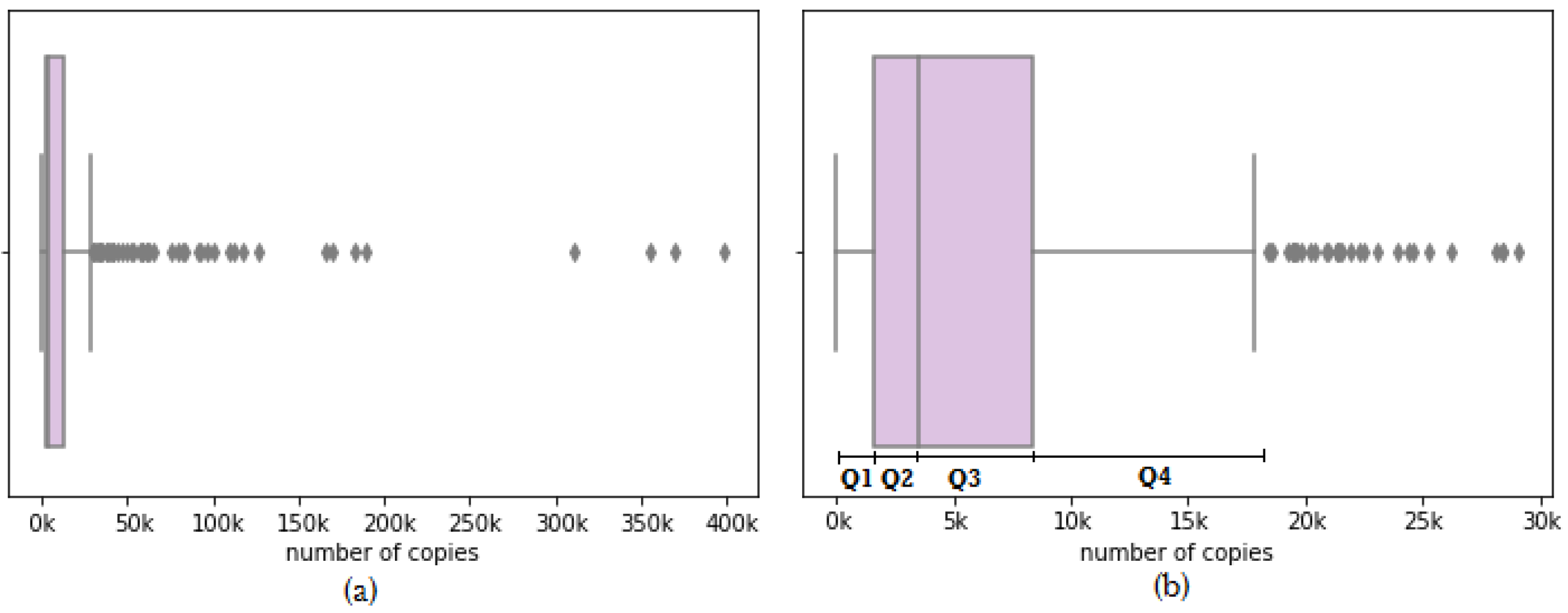
3.1. Description of the Dataset
3.2. CAIT: The Proposal
3.2.1. Part A: The Classifier
- Decision Tree: It is a representation in the form of a tree whose branches branch according to the values taken by the variables and which end in a specific action. It is generally used when the number of conditions is not very large in this study. See [20,21] for a detailed description of this algorithm.
- Random Forest: It is a combination of predictor trees such that each tree depends on the values of a random vector tested independently and with the same distribution for each of these. It is implemented in data mining to classify or forecast a target variable. See [22,23] for a detailed description of this algorithm.
- XGBoost: Part of the decision tree that is implemented in data mining to classify or forecast on a target variable (book copies), through machine learning that is performed on a set of data, using several weak classifiers. In this case, they are the decision trees, but enhancing the results of these, due to the sequential processing of the data with a loss or cost function, minimizes the error iteration after iteration, thus making it a strong predictor. However, this will depend on the level of adjustment of the parameters used in the function. See [26,27] for a detailed description of this algorithm.
| Algorithm 1 Classifier phase |
Split: in and (from K-Fold stratified cross-validation, in this case k = 10) Input: = (, ) Where the target variable will be the segmentation
Output:, predicted segmentation. |
3.2.2. Part B: The Regressors
- Gradient Boosting: It is a machine learning technique [28,29] which produces a predictive model in the form of a set of weak prediction models (typically decision trees). When building the model, it is done in a stepwise manner (as boosting methods do), and it generalizes them, allowing the arbitrary optimization of a differentiable loss function.
- XGBoost: Described in previous section.
- LightGBM: It is a distributed gradient impulse framework for machine learning. It is based on decision tree algorithms but does not grow at the tree level but in leaves. Therefore, by choosing the one will produce the greatest decrease in loss. See [30] for a detailed description of this algorithm.
| Algorithm 2 Regressor phase |
Split: in and (from K-Fold stratified cross-validation, in this case k = 10) Input: = (, ) Where the target variable will be the number of copies
Output:, predicted number of copies. |
3.2.3. CAIT: A Predictive Support Tool
| Algorithm 3 CAIT algorithm |
Input:
|
4. Results
4.1. Quartiles Segmentation (the Most Basic Segmentation)
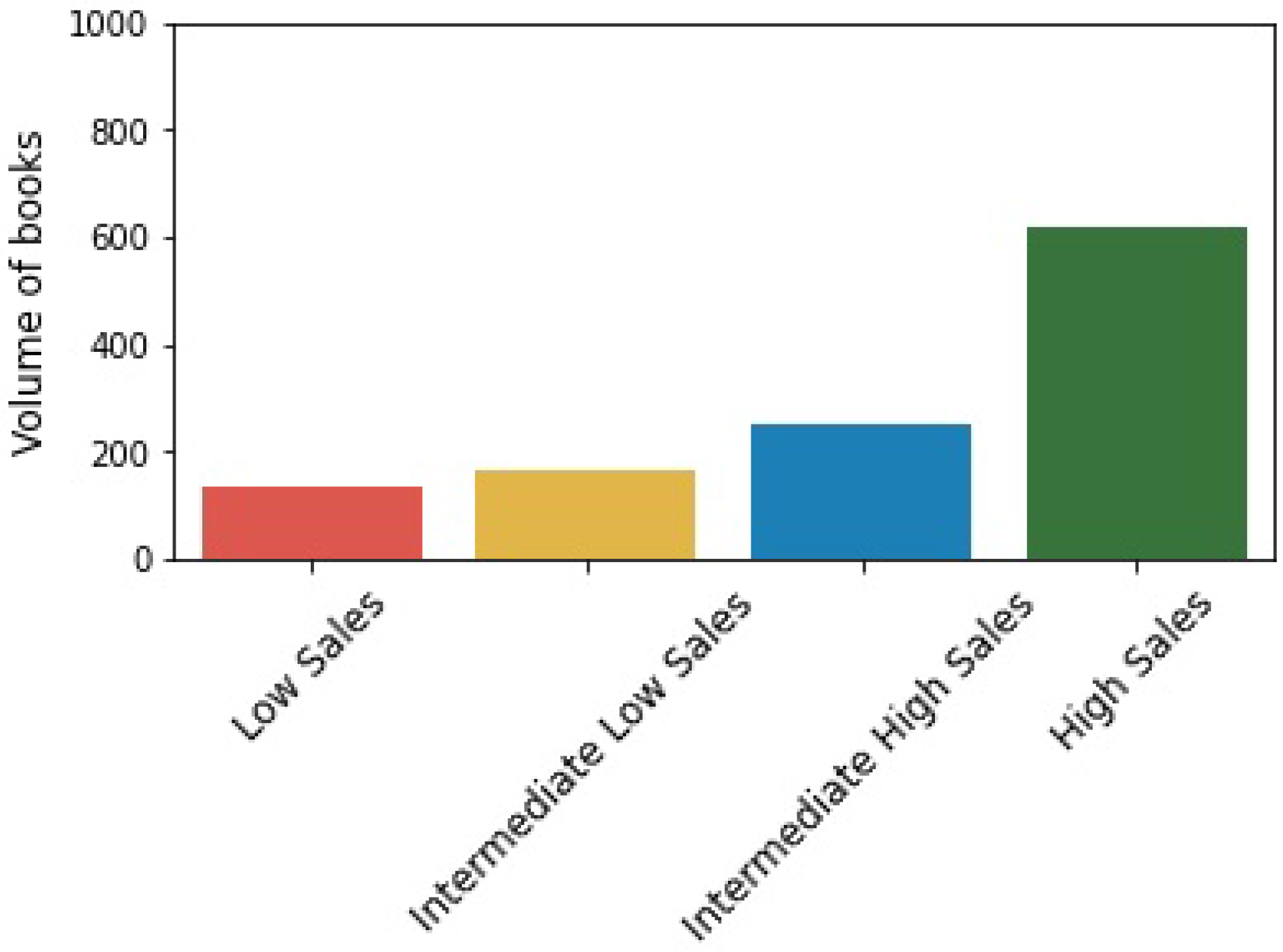
4.2. Expert’s Segmentation (the Current Segmentation)
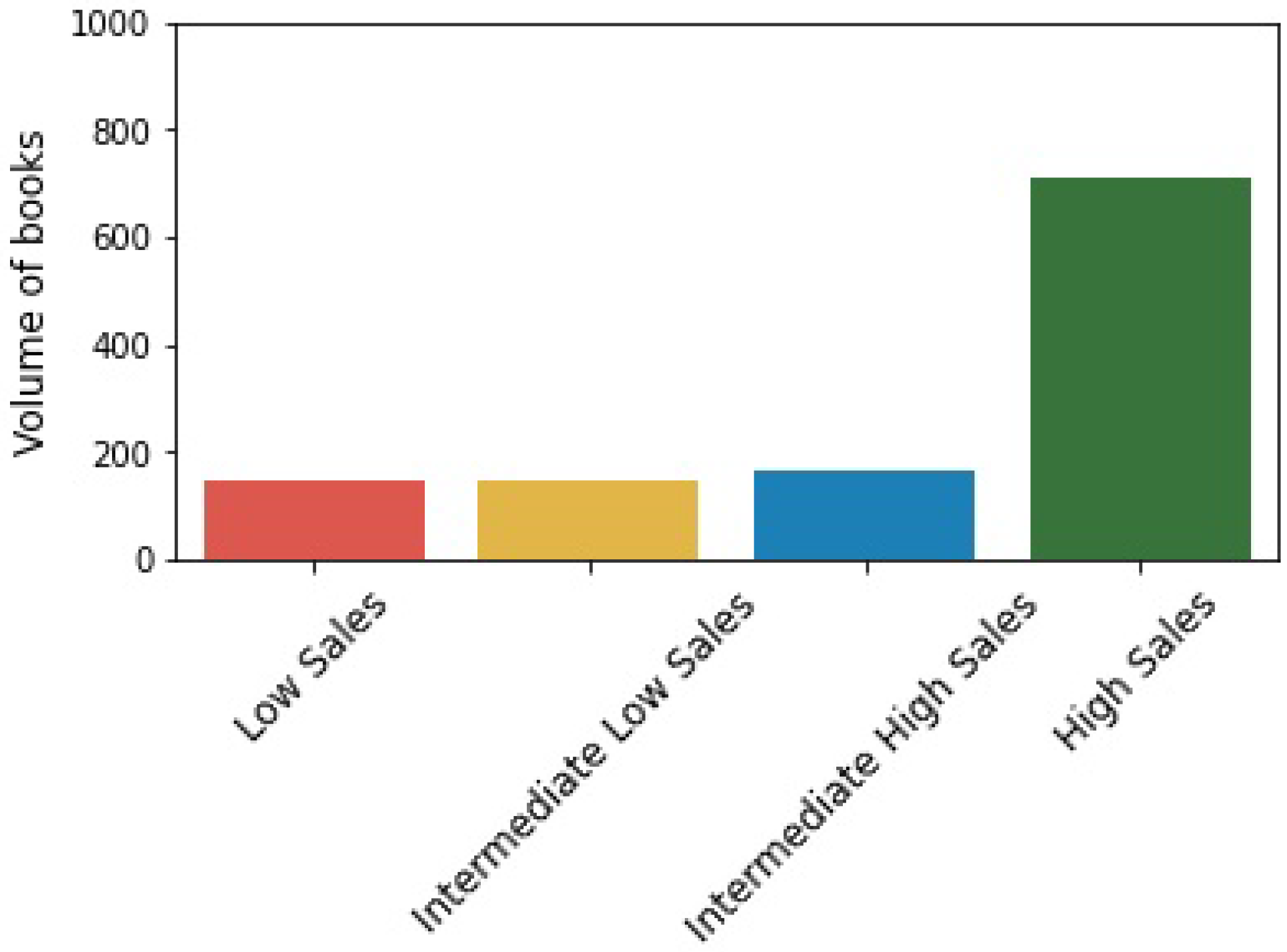
4.3. Clustering (the Automatic Segmentation)
4.4. Performance Evaluation Methods: For Classification Part
- K-Fold stratified cross-validation, this validation seeks to ensure that each k group is representative in all data strata. It is intended to ensure that each class is (roughly represented equally in each test fold) and thus avoid overtraining. In this specific case, our variable k = 10
- Accuracy (Equation (2)), which refers to how close a sample statistic is to a population parameter, being TP (true positive value), TN (true negative value), FP (false positive value), FN (false negative value).
- Precision (Equation (3)) with which this algorithm hits each of the classes is also analyzed.
- Recall (Equation (4)), represents the model’s ability to correctly predict the positives out of actual positives.
- F1-Score (Equation (5)), this gives a weighted average of the precision and recall metrics. It is the best metric for averaging out and balancing all the evaluation metrics as a whole.
- Mean Absolute Error (MAE) is used, which is a measure of the difference between two continuous variables (Equation (6)). Where is the prediction, and the true value.
Algorithm Comparison Analysis
4.5. Performance Evaluation Methods: For Regression Part
Algorithm Comparison Analysis
- Regressor 1: lambda = 3; booster = “gblinear”, alpha = 5, feature selector = “shuffle”
- Regressor 2: lambda = 5; booster = “gblinear”, alpha = 18, feature selector = “cyclic”
- Regressor 3: lambda = 4; booster = “gblinear”, alpha = 12, feature selector = “cyclic”
- Regressor 4: lambda = 8; booster = “gblinear”, alpha = 2, feature selector = “shuffle”
5. Discussion and Conclusions
5.1. General Discussion
5.2. Ethical and Social Considerations
5.3. Conclusions and Futher Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- ElPais. Available online: https://elpais.com/cultura/2018/07/09/actualidad/1531163370_371133.html#:~:text=Babelia%C3%9Altimas%20noticias-,Hasta%20un%2040%25%20de%20los%20225%20millones%20de,editados%20en%20Espa%C3%B1a%20se%20devuelve (accessed on 8 November 2021).
- Fischbein, M.; Ajzen, I. Belief, Attitude, Intention and Behavior; Addison-Wesley: Boston, MA, USA, 1975. [Google Scholar]
- Park, J.; Ciampaglia, G.L.; Ferrara, E. Style in the age of instagram: Predicting success within the fashion industry using social media. In Proceedings of the 19th ACM Conference on Computer-Supported Cooperative Work & Social Computing, San Francisco, CA, USA, 27 February–2 March 2016; pp. 64–73. [Google Scholar]
- Lassen, N.B.; Madsen, R.; Vatrapu, R. Predicting iphone sales from iphone tweet. In Proceedings of the 2014 IEEE 18th International Enterprise Distributed Object Computing Conference, Ulm, Germany, 1–2 September 2014; pp. 81–90. [Google Scholar]
- Abel, F.; Diaz-Aviles, E.; Henze, N.; Krause, D.; Siehndel, P. Analyzing the blogosphere for predicting the success of music and movie products. In Proceedings of the 2010 International Conference on Advances in Social Networks Analysis and Mining, Odense, Denmark, 9–11 August 2010; pp. 276–280. [Google Scholar]
- Moon, G.C.; Kikuta, G.; Yamada, T.; Yoshikawa, A.; Terano, T. Blog information considered useful for book sales prediction. In Proceedings of the 7th International Conference on Service Systems and Service Management, Tokyo, Japan, 28–30 June 2010; pp. 1–5. [Google Scholar]
- Rapp, A.; Beitelspacher, L.S.; Grewal, D.; Hughes, D.E. Understanding social media effects across seller, retailer, and consumer interactions. J. Acad. Mark. Sci. 2013, 41, 547–566. [Google Scholar] [CrossRef]
- Guesalaga, R. The use of social media in sales: Individual and organizational antecedents, and the role of customer engagement in social media. Ind. Mark. Manag. 2016, 54, 71–79. [Google Scholar] [CrossRef]
- Wang, X.; Yucesoy, B.; Varol, O.; Eliassi-Rad, T.; Barabási, A.L. Success in books: Predicting book sales before publication. EPJ Data Sci. 2019, 8, 31. [Google Scholar] [CrossRef] [Green Version]
- Namil, K.I.M.; Wonjoon, K.I.M. Do your social media lead you to make social deal purchases? Consumer-generated social referrals for sales via social commerce. Int. J. Inf. Manag. 2018, 39, 38–48. [Google Scholar]
- Yucesoy, B.; Wang, X.; Huang, J.; Barabási, A.L. Success in books: A big data approach to bestsellers. EPJ Data Sci. 2018, 7, 7. [Google Scholar] [CrossRef] [Green Version]
- Feng, T.Q.; Choy, M.; Laik, M.N. Predicting book sales trend using deep learning framework. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 28–39. [Google Scholar] [CrossRef]
- Rew, H. Francis Galton. J. R. Stat. Soc. 1922, 85, 293–298. [Google Scholar]
- Winfrey, W.; Heaton, L. Market Segmentation Nalysis of the Indonesian Family Planning Market: Consumer, Provider and Product Market Segments and Public Sector Procurement Costs of Family Planning under; USAID: Washington, DC, USA, 1996. [Google Scholar]
- Lehmann, H.; Zaiceva, A. Informal Employment in Russia: Incidence, Determinants and Labor Market Segmentation. 2013. Available online: https://ssrn.com/abstract=2330214 (accessed on 15 January 2021).
- Duncan, G.T.; Gorr, W.L.; Szczypula, J. Forecasting analogous time series. In Principles of Forecasting; Springer: Boston, MA, USA, 2001; pp. 195–213. [Google Scholar]
- Maharaj, E.A.; Inder, B.A. Forecasting time series from clusters. In Monash Econometrics and Business Statistics Working Papers; Department of Econometrics and Business Statistics, Monash University: Melbourne, Australia, 1999. [Google Scholar]
- Mitchell, R. Forecasting Electricity Demand using Clustering. In Proceedings of 21st IASTED International Conference on Applied Informatics; UNSPECIFIED: Innsbruck, Austria, 2003; pp. 225–230. [Google Scholar]
- GFK. Available online: https://www.gfk.com/home (accessed on 6 February 2019).
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. Decision trees and decision-making. IEEE Trans. Syst. Man Cybern. 1990, 20, 339–346. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 1, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Guo, G.; Wang, H.; Bell, D.; Bi, Y.; Greer, K. KNN model-based approach in classification. In Proceedings of the OTM Confederated International Conferences on the Move to Meaningful Internet Systems, Catania, Italy, 3–7 November 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 986–996. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting systems. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Nielsen, D. Tree Boosting with Xgboost-Why Does Xgboost Win Every Machine Learning Competition? Master’s Thesis, NTNU, Taipei, Taiwan, 2016. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. ICML 1996, 96, 148–156. [Google Scholar]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]
- Python. Available online: https://www.python.org/ (accessed on 6 February 2019).
- Nagelkerke, N.J. A note on a general definition of the coefficient of determination. Biometrika 1991, 78, 691–692. [Google Scholar] [CrossRef]
- Agenda2030. Available online: https://www.agenda2030.gob.es/recursos/docs/METAS_DE_LOS_ODS.pdf (accessed on 8 November 2021).
- Alla, S.; Adari, S.K. What Is MLOps? In Beginning MLOps with MLFlow; Apress: Berkeley, CA, USA, 2021; pp. 79–124. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Decision Tree | K-Neares Neighbors | Random Forest | XGBoost | |
|---|---|---|---|---|
| Accuracy | 0.86 | 0.86 | 0.89 | 0.91 |
| MAE | 0.21 | 0.23 | 0.16 | 0.12 |
| Precision | 0.86 | 0.86 | 0.89 | 0.91 |
| Recall | 0.86 | 0.86 | 0.89 | 0.91 |
| F1-Score | 0.86 | 0.86 | 0.89 | 0.91 |
| Decision Tree | K-Nearest Neighbors | Random Forest | XGBoost | |
|---|---|---|---|---|
| Accuracy | 0.89 | 0.87 | 0.90 | 0.93 |
| MAE | 0.19 | 0.21 | 0.16 | 0.11 |
| Precision | 0.89 | 0.87 | 0.90 | 0.93 |
| Recall | 0.89 | 0.87 | 0.90 | 0.93 |
| F1-Score | 0.89 | 0.87 | 0.90 | 0.93 |
| Decision Tree | K-Nearest Neighbors | Random Forest | XGBoost | |
|---|---|---|---|---|
| Accuracy | 0.99 | 1.00 | 0.99 | 1.00 |
| MAE | 0.01 | 0.00 | 0.02 | 0.00 |
| Precision | 0.99 | 1.00 | 0.99 | 1.00 |
| Recall | 0.99 | 1.00 | 0.99 | 1.00 |
| F1-Score | 0.99 | 1.00 | 0.99 | 1.00 |
| Class 1 | Class 2 | Class 3 | Class 4 | |
|---|---|---|---|---|
| GBoosting | 0.75 | 0.72 | 0.51 | 0.16 |
| XGBoost | 0.93 | 0.96 | 0.98 | 0.94 |
| LGBM | 0.87 | 0.72 | 0.51 | 0.43 |
| Class 1 | Class 2 | Class 3 | Class 4 | |
|---|---|---|---|---|
| GBoosting | 0.32 | 0.34 | 0.77 | 0.06 |
| XGBoost | 0.94 | 0.96 | 1.00 | 0.96 |
| LGBM | 0.20 | 0.00 | 0.00 | 0.38 |
| Class 1 | Class 2 | Class 3 | Class 4 | |
|---|---|---|---|---|
| GBoosting | 0.73 | 0.73 | 0.13 | 0.16 |
| XGBoost | 0.95 | 0.97 | 1.00 | 0.96 |
| LGBM | 0.90 | 0.87 | 0.86 | 0.41 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martín Sujo, J.C.; Golobardes i Ribé, E.; Vilasís Cardona, X. CAIT: A Predictive Tool for Supporting the Book Market Operation Using Social Networks. Appl. Sci. 2022, 12, 366. https://doi.org/10.3390/app12010366
Martín Sujo JC, Golobardes i Ribé E, Vilasís Cardona X. CAIT: A Predictive Tool for Supporting the Book Market Operation Using Social Networks. Applied Sciences. 2022; 12(1):366. https://doi.org/10.3390/app12010366
Chicago/Turabian StyleMartín Sujo, Jessie C., Elisabet Golobardes i Ribé, and Xavier Vilasís Cardona. 2022. "CAIT: A Predictive Tool for Supporting the Book Market Operation Using Social Networks" Applied Sciences 12, no. 1: 366. https://doi.org/10.3390/app12010366
APA StyleMartín Sujo, J. C., Golobardes i Ribé, E., & Vilasís Cardona, X. (2022). CAIT: A Predictive Tool for Supporting the Book Market Operation Using Social Networks. Applied Sciences, 12(1), 366. https://doi.org/10.3390/app12010366