
Unstructured Data Analysis for Risk Management of Electric Power Transmission Lines †

 , , ,
, , , {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
3. Background
3.1. Phases of the Energy Transmission Segment
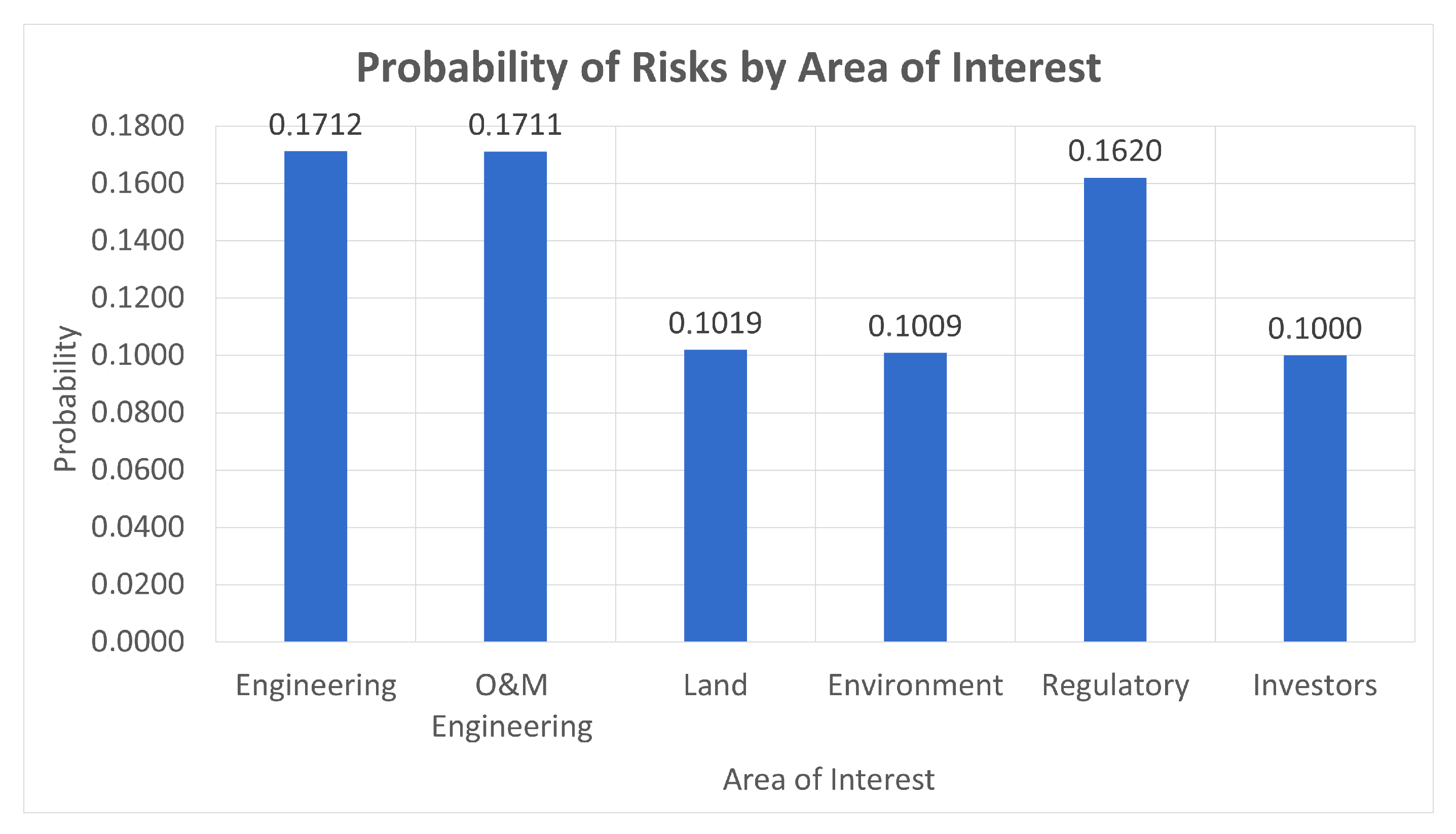
3.2. Areas of Interest for Risk Management
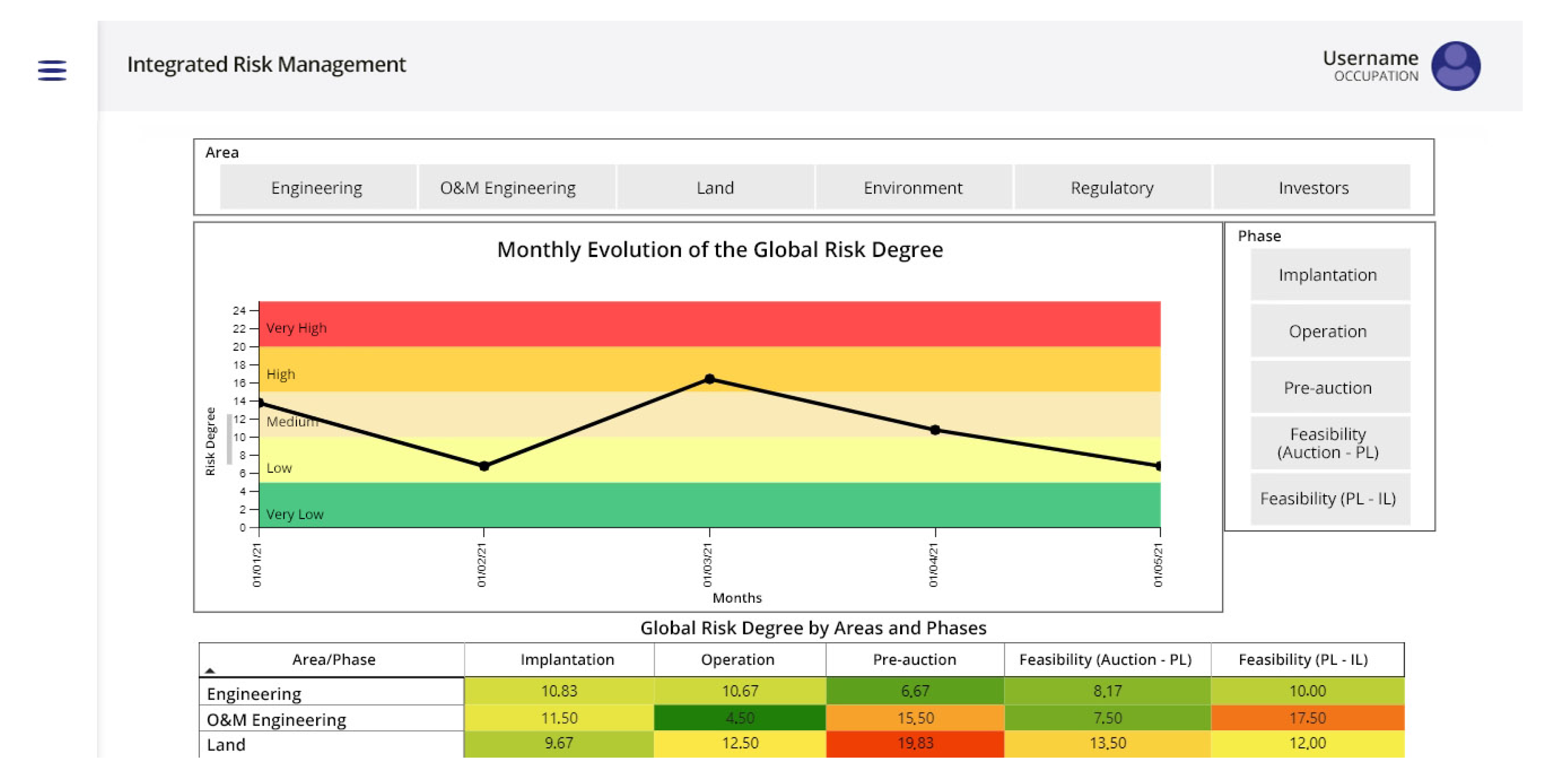
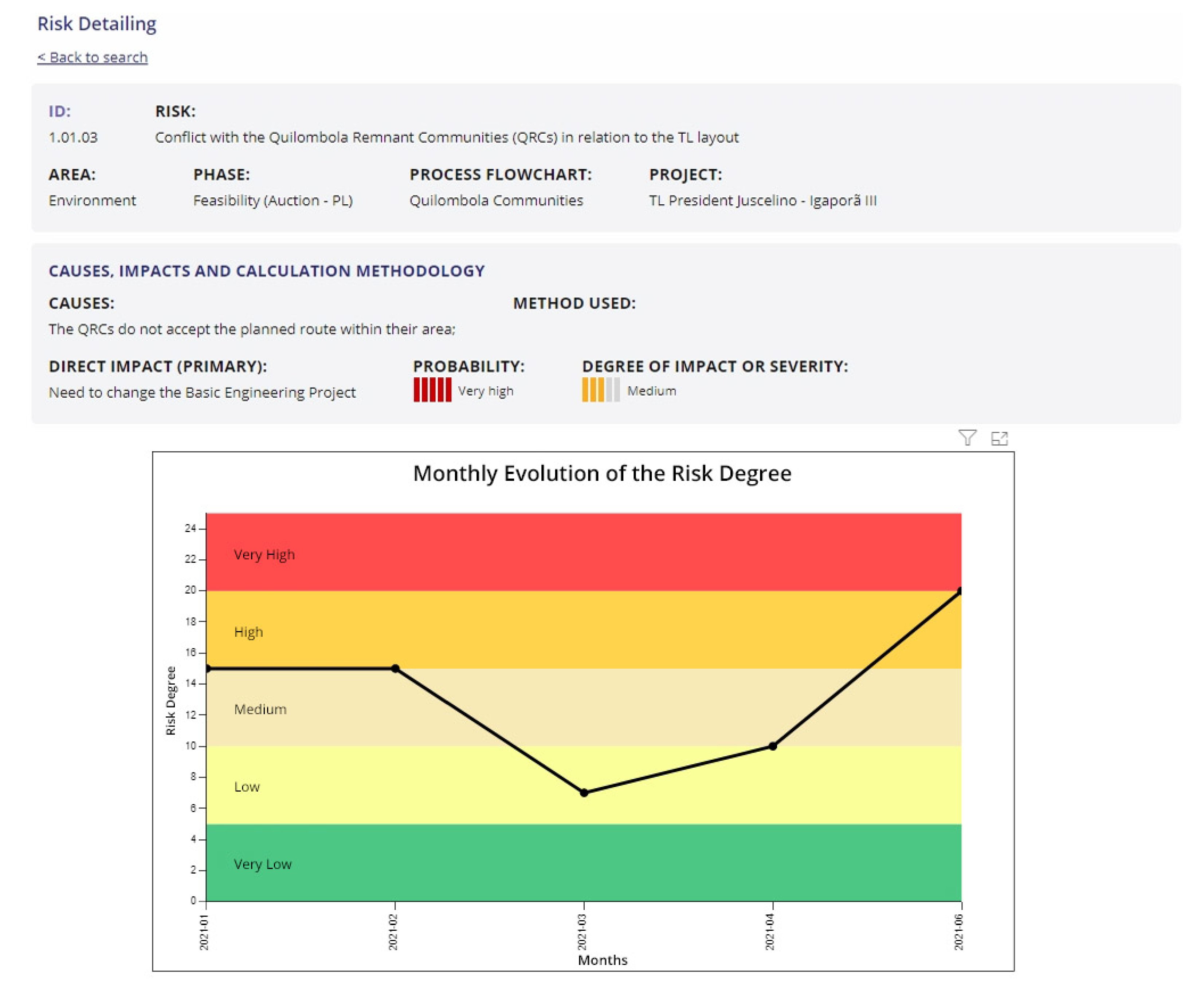
3.3. Risk Management
- Non-approval of the study of regions with indigenous settlements;
- Increase in the number of malaria cases registered;
- Political changes in local governments;
- Weakened entrepreneur financial health;
- Variation in the basic interest rate provided in the business plan for financing the project;
- Embargoes for environmental reasons for long periods;
- The existence of unresolved environmental issues.
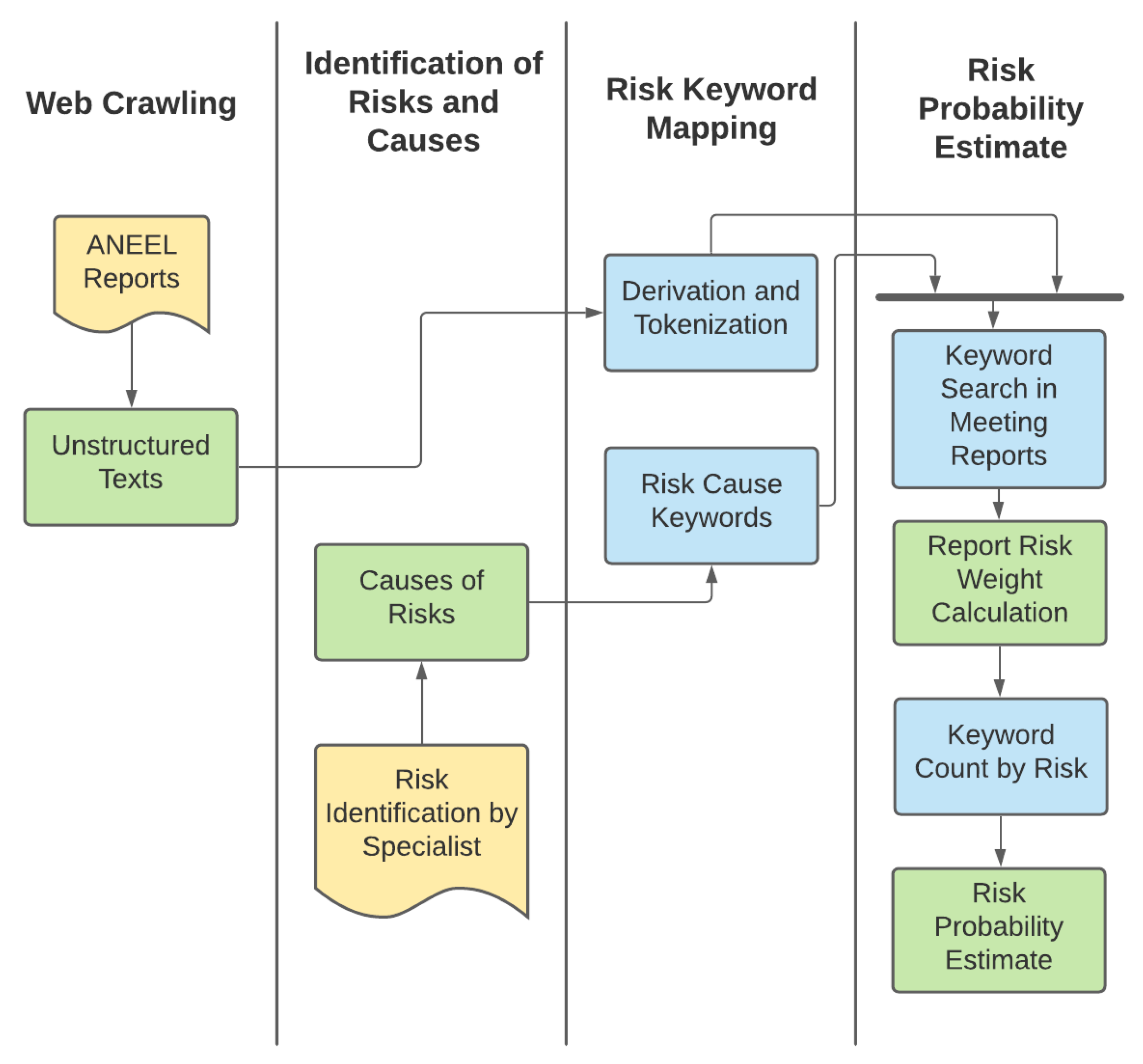
4. Methodology
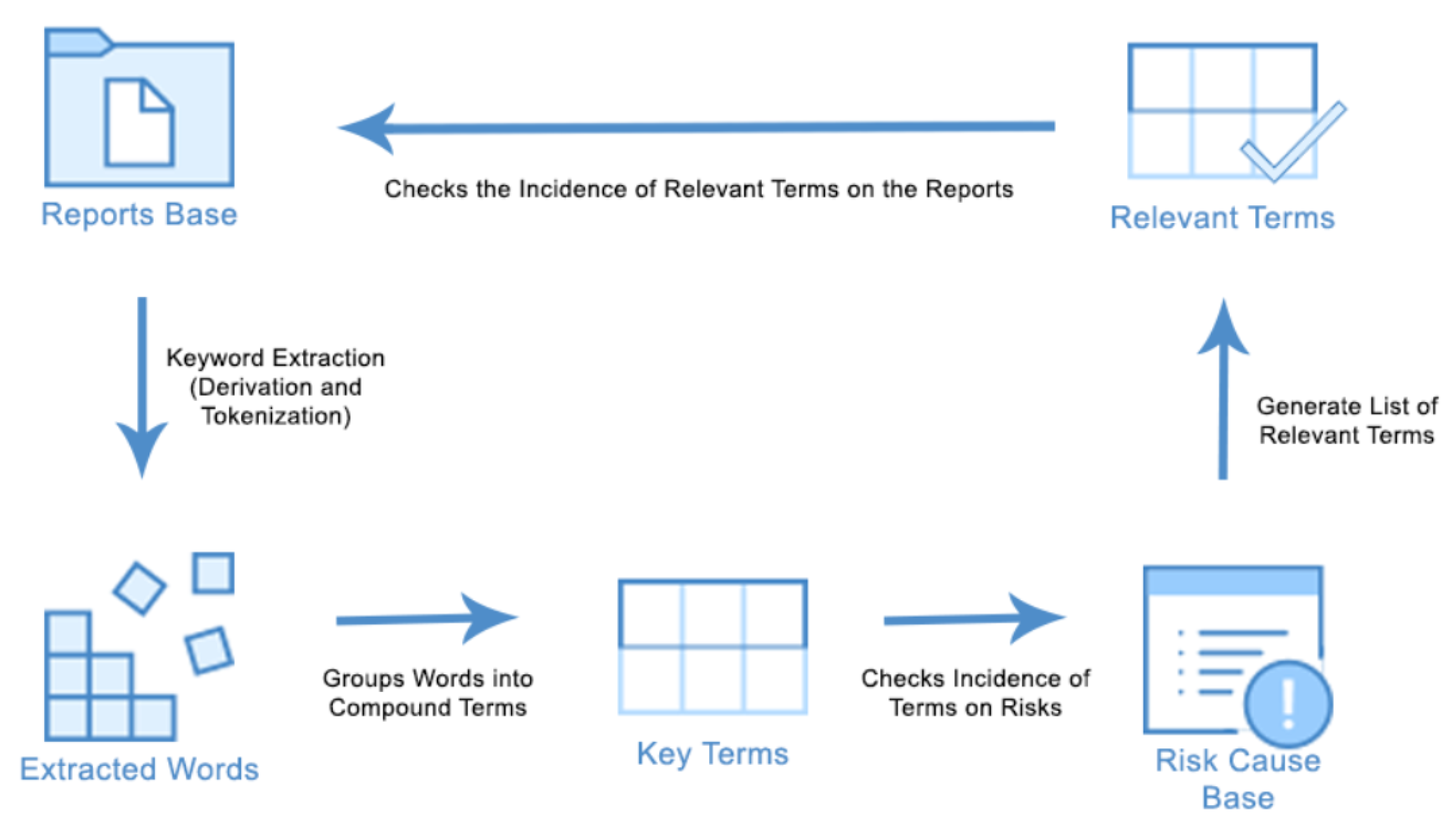
4.1. Web Crawling
4.2. Risk and Cause Identification
4.3. Risk Keyword Mapping
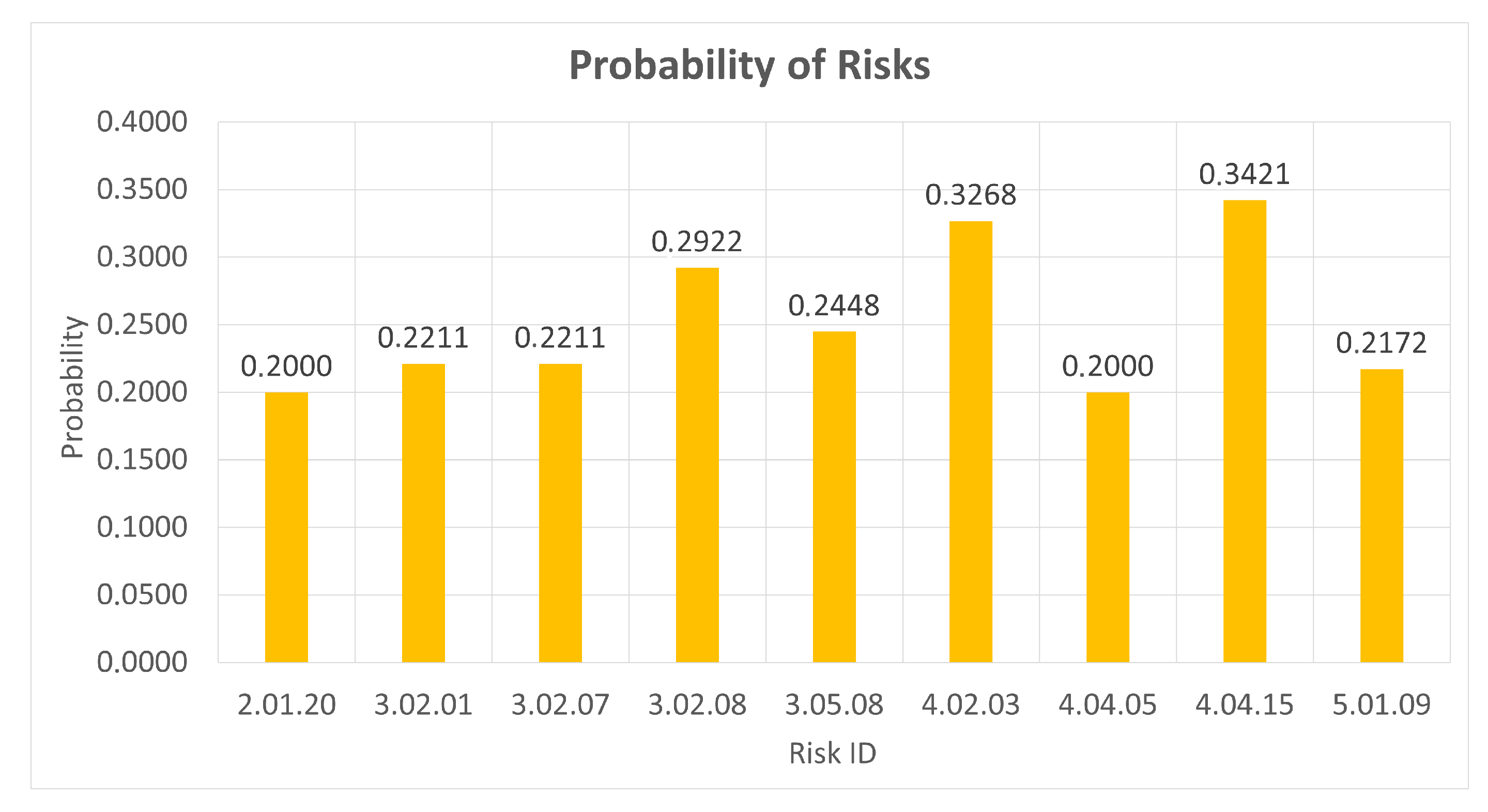
4.4. Risk Probability Estimation
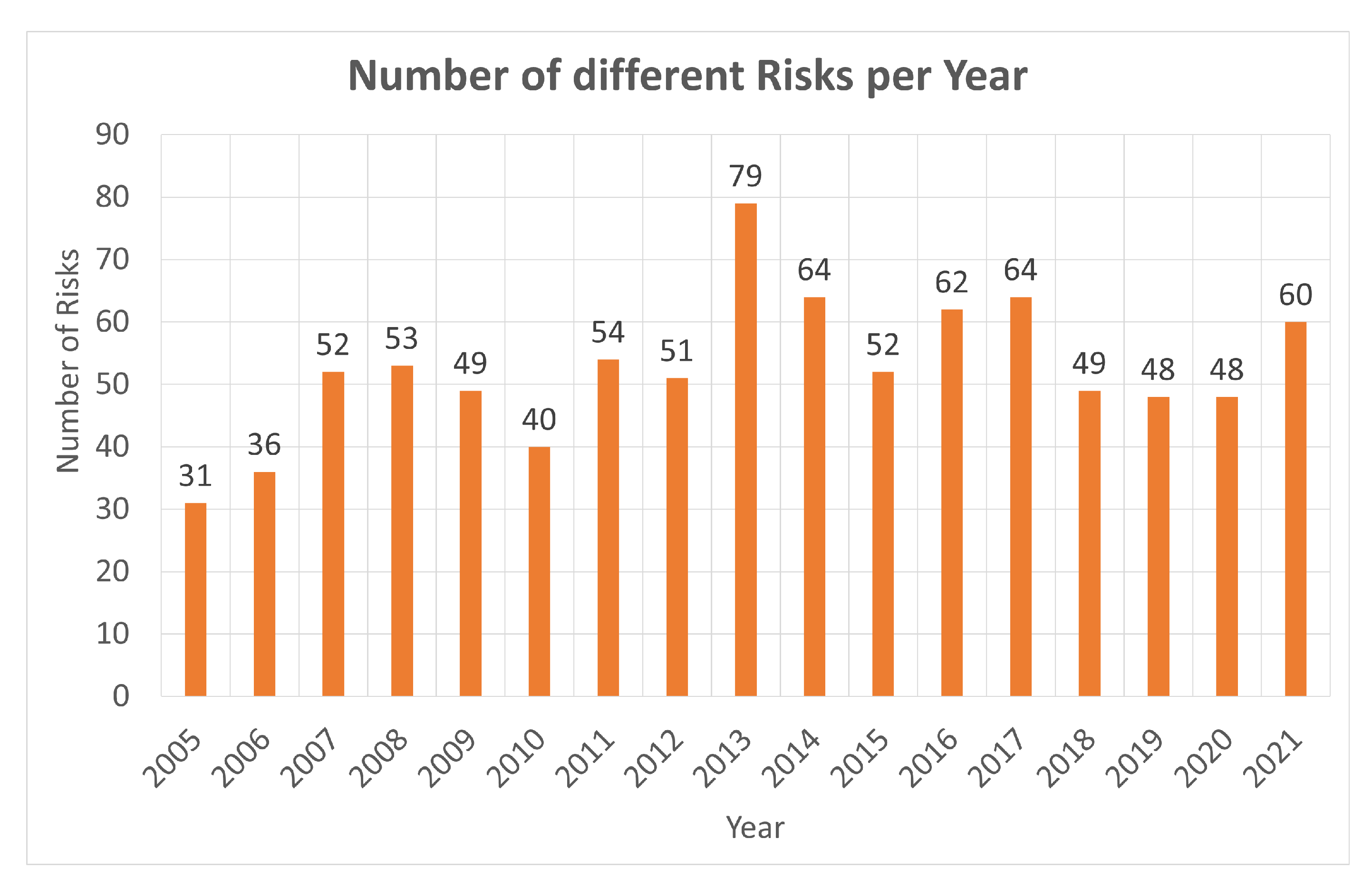
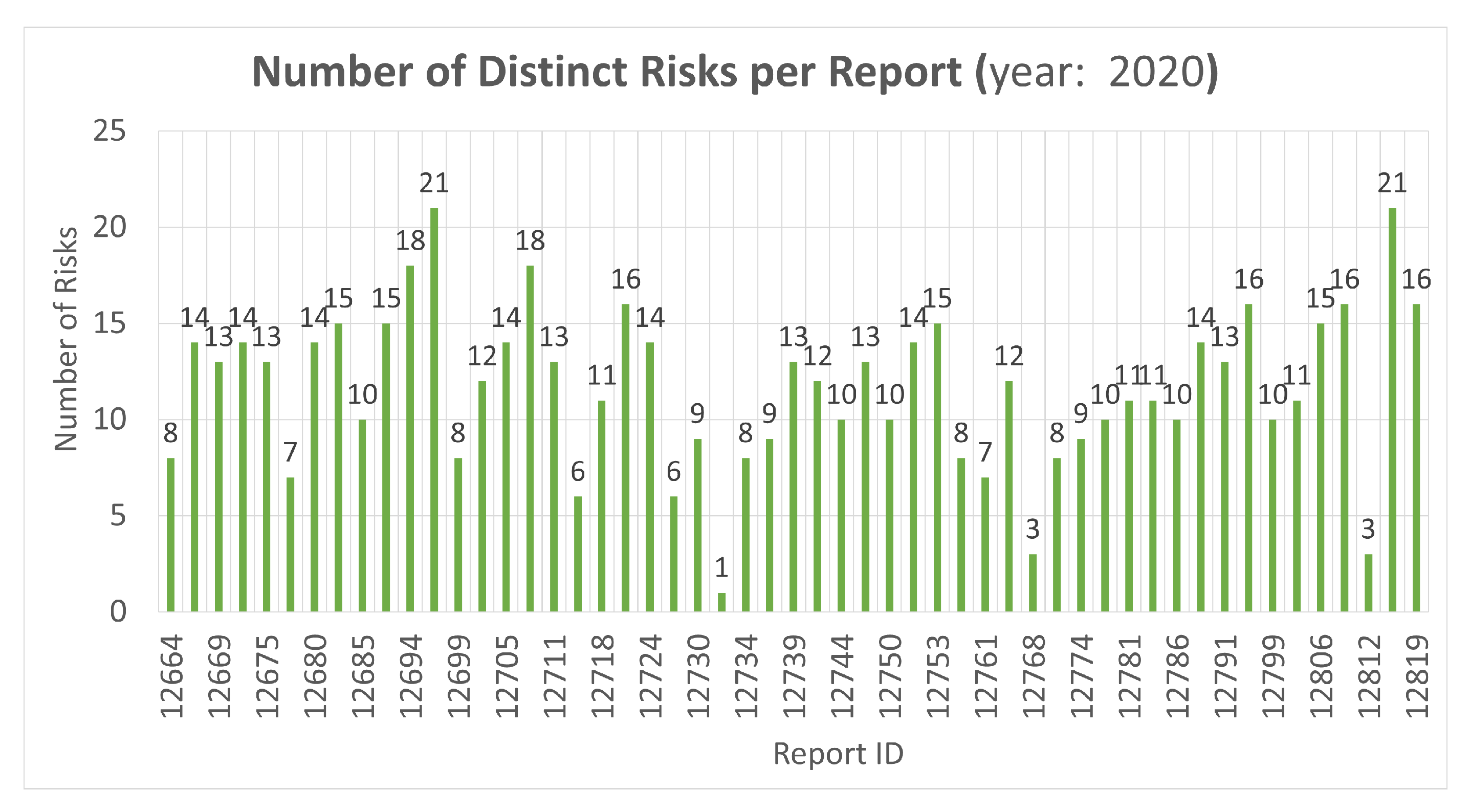
5. Experiments
5.1. Experimental Set-Up
5.2. Experimental Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANEEL | Brazilian National Electric Energy Agency |
| FUNAI | Justice’s National Foundation for Indigenous Affairs |
References
- Sadeghi, M.; Shavvalpour, S. Energy risk management and value at risk modeling. Energy Policy 2006, 34, 3367–3373. [Google Scholar] [CrossRef]
- Bhusal, N.; Abdelmalak, M.; Kamruzzaman, M.; Benidris, M. Power System Resilience: Current Practices, Challenges, and Future Directions. IEEE Access 2020, 8, 18064–18086. [Google Scholar] [CrossRef]
- Analui, B.; Scaglione, A. A Dynamic Multistage Stochastic Unit Commitment Formulation for Intraday Markets. IEEE Trans. Power Syst. 2018, 33, 3653–3663. [Google Scholar] [CrossRef]
- Du, E.; Zhang, N.; Kang, C.; Xia, Q. Scenario Map Based Stochastic Unit Commitment. IEEE Trans. Power Syst. 2018, 33, 4694–4705. [Google Scholar] [CrossRef]
- Zhang, N.; Kang, C.; Xia, Q.; Liang, J. Modeling Conditional Forecast Error for Wind Power in Generation Scheduling. IEEE Trans. Power Syst. 2014, 29, 1316–1324. [Google Scholar] [CrossRef]
- Romero, N.R.; Nozick, L.K.; Dobson, I.D.; Xu, N.; Jones, D.A. Transmission and Generation Expansion to Mitigate Seismic Risk. IEEE Trans. Power Syst. 2013, 28, 3692–3701. [Google Scholar] [CrossRef]
- Linares, P. Multiple criteria decision making and risk analysis as risk management tools for power systems planning. IEEE Trans. Power Syst. 2002, 17, 895–900. [Google Scholar] [CrossRef]
- Bruno, S.; Ahmed, S.; Shapiro, A.; Street, A. Risk neutral and risk averse approaches to multistage renewable investment planning under uncertainty. Eur. J. Oper. Res. 2016, 250, 979–989. [Google Scholar] [CrossRef]
- Song, Y.; Liu, Z.; Rønnquist, A.; Nåvik, P.; Liu, Z. Contact Wire Irregularity Stochastics and Effect on High-Speed Railway Pantograph–Catenary Interactions. IEEE Trans. Instrum. Meas. 2020, 69, 8196–8206. [Google Scholar] [CrossRef]
- Huang, K.; Liu, Z.; Su, D.; Zheng, Z. A Traction Network Chain-Circuit Model With Detailed Consideration of Integrated Grounding System in Tunnel Path. IEEE Trans. Transp. Electrif. 2019, 5, 535–551. [Google Scholar] [CrossRef]
- Ni, M.; McCalley, J.; Vittal, V.; Tayyib, T. Online risk-based security assessment. IEEE Power Eng. Rev. 2002, 22, 59. [Google Scholar] [CrossRef]
- Kirschen, D.; Jayaweera, D. Comparison of risk-based and deterministic security assessments. IET Gener. Transm. Distrib. 2007, 1, 527–533. [Google Scholar] [CrossRef]
- Izadi, M.; Safdarian, A. Financial Risk Evaluation of RCS Deployment in Distribution Systems. IEEE Syst. J. 2019, 13, 692–701. [Google Scholar] [CrossRef]
- Liu, K.; Wu, X.; Shi, C. Risk early warning of distribution power system based on data mining technology. In Proceedings of the 2017 China International Electrical and Energy Conference (CIEEC), Beijing, China, 25–27 October 2017; pp. 40–45. [Google Scholar]
- Hao, J.; Jinming, C.; Yajuan, G. Data-driven lean Management for Distribution Network. In Proceedings of the 2018 China International Conference on Electricity Distribution (CICED), Tianjin, China, 17–19 September 2018; pp. 701–705. [Google Scholar]
- Zhao, X.; Luo, L.; Ma, G.; Cai, Z.; Gu, Z.; Wang, Q. Operation and Maintenance Management and Decision Analysis in Distribution Network Based on Big Data Mining. In Proceedings of the 2018 International Conference on Power System Technology (POWERCON), Guangzhou, China, 6–9 November 2018; pp. 4855–4861. [Google Scholar]
- de Menezes, V.P. Linhas de Transmissão de Energia elétrica—Aspectos Técnicos, Orçamentários e Construtivos. Rio de Janeiro 2015, 1, 1–75. [Google Scholar]
- Lim, E.P.; Chen, H.; Chen, G. Business Intelligence and Analytics: Research Directions. ACM Trans. Manag. Inf. Syst. 2013, 3, 1–10. [Google Scholar] [CrossRef]
- Parvizimosaed, M.; Farmani, F.; Monsef, H.; Rahimi-Kian, A. A multi-stage Smart Energy Management System under multiple uncertainties: A data mining approach. Renew. Energy 2017, 102, 178–189. [Google Scholar] [CrossRef]
- Ciarapica, F.; Bevilacqua, M.; Antomarioni, S. An approach based on association rules and social network analysis for managing environmental risk: A case study from a process industry. Process. Saf. Environ. Prot. 2019, 128, 50–64. [Google Scholar] [CrossRef]
- Tummala, V.R.; Burchett, J.F. Applying a risk management process (RMP) to manage cost risk for an EHV transmission line project. Int. J. Proj. Manag. 1999, 17, 223–235. [Google Scholar] [CrossRef]
- Chermack, T.J. Scenario Planning in Organizations: How to Create, Use, and Assess Scenarios; Berrett-Koehler Publishers: Oakland, CA, USA, 2011. [Google Scholar]
- Ralston, B.; Wilson, I. The Scenario-Planning Handbook: A Practitioner’s Guide to Developing and Using Scenarios to Direct Strategy in Today’s Uncertain Times; South-Western Pub: Cincinnati, OH, USA, 2006. [Google Scholar]
- Ekel, P.; Pedrycz, W.; Pereira, J., Jr. Multicriteria Decision-Making under Conditions of Uncertainty: A Fuzzy Set Perspective; John Wiley & Sons: Hoboken, NJ, USA, 2019. [Google Scholar]
- Leskovec, J.; Rajaraman, A.; Ullman, J.D. Mining of Massive Datasets, 2nd ed.; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]










Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pereira, L.H.; Pereira, R.B.; Prado, P.H.S.; Cunha, F.D.; Góes, F.; Fiusa, R.S.; da Silva, L.F.L. Unstructured Data Analysis for Risk Management of Electric Power Transmission Lines. Appl. Sci. 2022, 12, 5292. https://doi.org/10.3390/app12115292
Pereira LH, Pereira RB, Prado PHS, Cunha FD, Góes F, Fiusa RS, da Silva LFL. Unstructured Data Analysis for Risk Management of Electric Power Transmission Lines. Applied Sciences. 2022; 12(11):5292. https://doi.org/10.3390/app12115292
Chicago/Turabian StylePereira, Lucas H., Rafael B. Pereira, Pedro H. S. Prado, Felipe D. Cunha, Fabrício Góes, Roger S. Fiusa, and Lorrany Fernanda Lopes da Silva. 2022. "Unstructured Data Analysis for Risk Management of Electric Power Transmission Lines" Applied Sciences 12, no. 11: 5292. https://doi.org/10.3390/app12115292
APA StylePereira, L. H., Pereira, R. B., Prado, P. H. S., Cunha, F. D., Góes, F., Fiusa, R. S., & da Silva, L. F. L. (2022). Unstructured Data Analysis for Risk Management of Electric Power Transmission Lines. Applied Sciences, 12(11), 5292. https://doi.org/10.3390/app12115292