
EEG Signal Processing and Supervised Machine Learning to Early Diagnose Alzheimer’s Disease

 and
and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Acquisition and Preprocessing
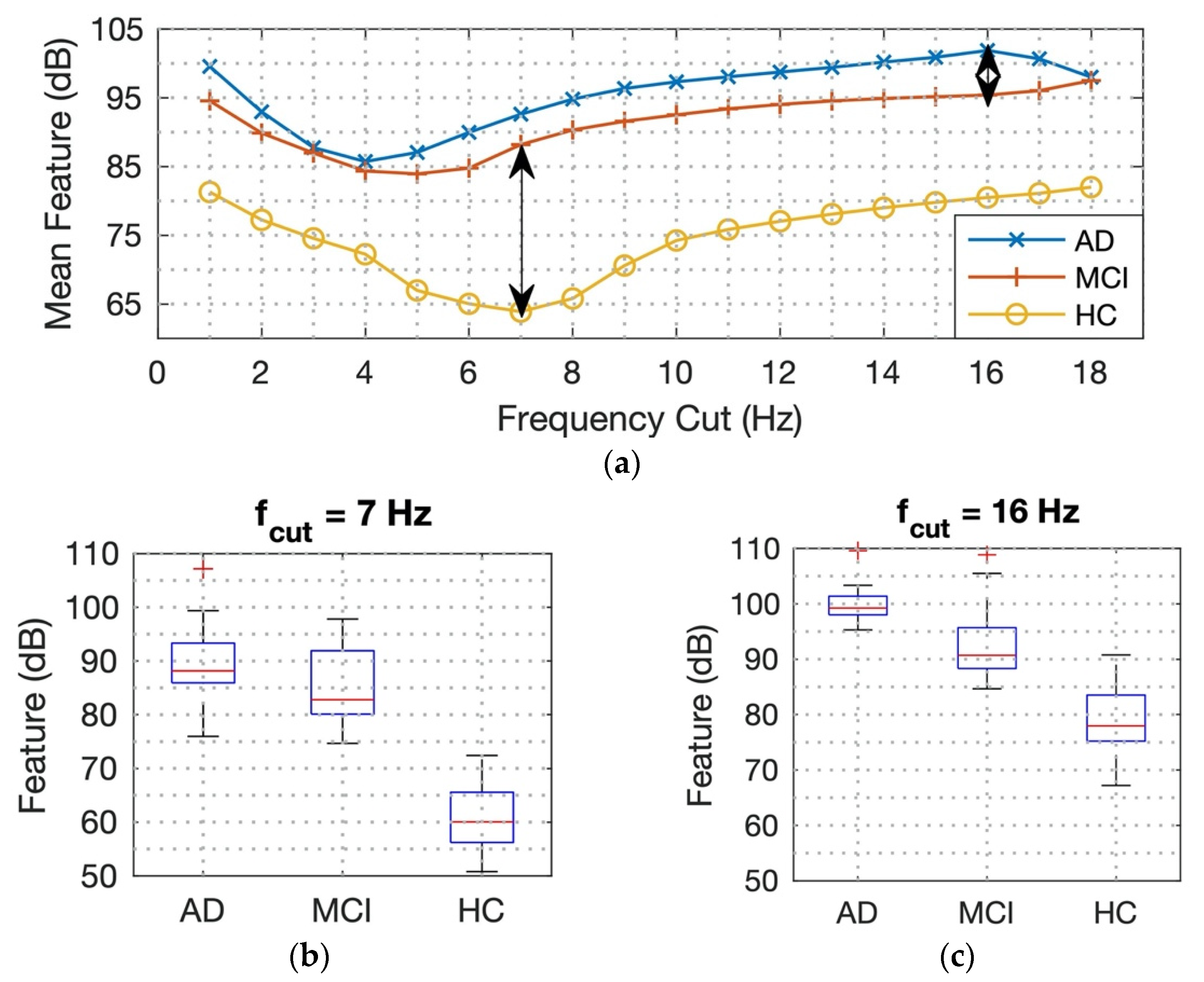
2.2. Feature Extraction
2.2.1. Data Exploration in the Time–Frequency Domains
2.2.2. Double Digital Filter Construction
2.3. Classification
- Dataset splitting in training 70% and data tests 30%, except for the (v) case where the data has been divided into 80% training and 20% data tests;
- Dataset size reduction with the Linear Discriminant Analysis (LDA) [31];
- Application of the three aforementioned supervised machine learning methods;
- Tuning of the hyperparameters of the machine learning algorithms combined with k-fold cross validation [32];
- Data validation and performance evaluation through the confusion matrices.
3. Results
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Finkel, S.I.; Costa, E.; Silva, J.; Cohen, G.; Miller, S.; Sartorius, N. Behavioral and psychological signs and symptoms of dementia: A consensus statement on current knowledge and implications for research and treatment. Int. Psychogeriatr. 1996, 8, 497–500. [Google Scholar] [CrossRef] [PubMed]
- Patterson, C. World Alzheimer Report 2018. The State of the Art of Dementia Research: New Frontiers; Alzheimer’s Disease International: London, UK, 2018. [Google Scholar]
- Benbow, S.M.; Jolley, D. Dementia: Stigma and his effects. Neurodegener. Dis. Manag. 2012, 2, 165–172. [Google Scholar] [CrossRef]
- Hugo, J.; Ganguli, M. Dementia and cognitive impairment: Epidemiology, diagnosis, and treatment. Clin. Geriatr. Med. 2014, 30, 421–442. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brooker, D.; La Fontaine, J.; Evans, S.; Bray, J.; Saad, K. Public health guidance to facilitate timely diagnosis of dementia: Alzheimer’s Cooperative Valuation in Europe recommendations. Int J. Geriatr. Psychiatry 2014, 29, 682–693. [Google Scholar] [CrossRef]
- Verbeek, H.; Meyer, G.; Leino-Kilpi, H.; Zabalegui, A.; Hallberg, I.R.; Saks, K.; Soto, M.E.; Challis, D.; Sauerland, D.; Hamers, J.P. RightTimePlaceCare Consortium. A European study investigating patterns of transition from home care towards institutional dementia care: The protocol of a RightTimePlaceCare study. BMC Public Health 2012, 12, 68. [Google Scholar] [CrossRef]
- Perez-Valero, E.; Lopez-Gordo, M.A.; Morillas, C.; Pelayo, F.; Vaquero-Blasco, M.A. A Review of Automated Techniques for Assisting the Early Detection of Alzheimer’s Disease with a Focus on EEG. J. Alzheimers Dis. 2021, 80, 1363–1376. [Google Scholar] [CrossRef]
- Thatcher, R.W. Maturation of the human frontal lobes: Physiological evidence for staging. Dev. Neuropsychol. 1991, 7, 397–419. [Google Scholar] [CrossRef]
- Sharma, N.; Kolekar, M.H.; Jha, K.; Kumar, Y. EEG and Cognitive Biomarkers Based Mild Cognitive Impairment Diagnosis. Irbm 2019, 40, 113–121. [Google Scholar] [CrossRef]
- Abasolo, D.; Hornero, R.; Escudero, J.; Espino, P. A Study on the Possible Usefulness of Detrended Fluctuation Analysis of the Electroencephalogram Background Activity in Alzheimer’s Disease. IEEE Trans. Biomed. Eng. 2008, 55, 2171–2179. [Google Scholar] [CrossRef] [Green Version]
- Amini, M.; Pedram, M.; Moradi, A.; Ouchani, M. Diagnosis of Alzheimer’s Disease by Time-Dependent Power Spectrum Descriptors and Convolutional Neural Network Using EEG Signal. Comput. Math. Methods Med. 2021, 2021, 5511922. [Google Scholar] [CrossRef]
- Benz, N.; Hatz, F.; Bousleiman, H.; Ehrensperger, M.M.; Gschwandtner, U.; Hardmeier, M.; Ruegg, S.; Schindler, C.; Zimmermann, R.; Monch, A.U.; et al. Slowing of EEG background activity in Parkinson’s and Alzheimer’s disease with early cognitive dysfunction. Front. Aging Neurosci. 2014, 6, 314. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Courtney, S.M.; Hinault, T. When the time is right: Temporal dynamics of brain activity in healthy aging and dementia. Prog. Neurobiol. 2021, 203, 102076. [Google Scholar] [CrossRef] [PubMed]
- Susana, C.F.; Mónica, L.; Fernando, D. Event-related brain potential indexes provide evidence for some decline in healthy people with subjective memory complaints during target evaluation and response inhibition processing. Neurobiol. Learn. Mem. 2021, 182, 107450. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Zhao, Y.; Durongbhan, P.; Chen, L.; Liu, J.; Billings, S.A.; Zis, P.; Unwin, Z.C.; De Marco, M.; Venneri, A.; et al. Imaging of Nonlinear and Dynamic Functional Brain Connectivity Based on EEG Recordings With the Application on the Diagnosis of Alzheimer’s Disease. IEEE Trans. Med. Imaging 2020, 39, 1571–1581. [Google Scholar] [CrossRef]
- Miltiadous, A.; Tzimourta, K.D.; Giannakeas, N.; Tsipouras, M.G.; Afrantou, T.; Ioannidis, P.; Tzallas, A.T. Alzheimer’s Disease and Frontotemporal Dementia: A Robust Classification Method of EEG Signals and a Comparison of Validation Methods. Diagnostics 2021, 11, 1437. [Google Scholar] [CrossRef]
- Musaeus, C.S.; Salem, L.C.; Sabers, A.; Kjaer, T.W.; Waldemar, G. Associations between electroencephalography power and Alzheimer’s disease in persons with Down syndrome. J. Intellect. Disabil. Res. 2019, 63, 1151–1157. [Google Scholar] [CrossRef]
- Ahmedt-Aristizabal, D.; Fernando, T.; Denman, S.; Robinson, J.E.; Sridharan, S.; Johnston, P.J.; Fookes, C. Identification of Children at Risk of Schizophrenia via Deep Learning and EEG Responses. IEEE J. Biomed. Health Inform. 2021, 25, 69–76. [Google Scholar] [CrossRef]
- Dauwels, J.; Vialatte, F.; Cichocki, A. Diagnosis of Alzheimer’s disease from EEG signals: Where are we standing? Curr. Alzheimer Res. 2010, 7, 487–505. [Google Scholar] [CrossRef] [Green Version]
- Moretti, D.V. Theta and alpha EEG frequency interplay in subjects with mild cognitive impairment: Evidence from EEG, MRI, and SPECT brain modifications. Front. Aging Neurosci. 2015, 7, 31. [Google Scholar] [CrossRef]
- Rodrigues, P.M.; Bispo, B.C.; Garrett, C.; Alves, D.; Teixeira, J.T.; Freitas, D. Lacsogram: A New EEG Tool to Diagnose Alzheimer’s Disease. IEEE J. Biomed. Health Inform. 2021, 25, 3384–3395. [Google Scholar] [CrossRef]
- Kanda, P.A.M.; Oliveira, E.F.; Fraga, F.J. EEG epochs with less alpha rhythm improve discrimination of mild Alzheimer’s. Comput. Methods Programs Biomed. 2017, 138, 13–22. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Geng, X.; Wang, Y.; Guo, Y.; Gao, Y.; Zhang, S.; Du, W.; Liu, L.; Sun, M.; Jiao, F.; et al. The Significance of EEG Alpha Oscillation Spectral Power and Beta Oscillation Phase Synchronization for Diagnosing Probable Alzheimer Disease. Front. Aging Neurosci. 2021, 13, 291. [Google Scholar] [CrossRef] [PubMed]
- Fiscon, G.; Weitschek, E.; Cialini, A.; Felici, G.; Bertolazzi, P.; De Salvo, S.; Bramanti, A.; Bramanti, P.; De Cola, M.C. Combining EEG signal processing with supervised methods for Alzheimer’s patients classification. BMC Med. Inform. Decis. Mak. 2018, 18, 35. [Google Scholar] [CrossRef] [PubMed]
- Kuo, C.E.; Chen, G.T.; Liao, P.Y. An EEG spectrogram-based automatic sleep stage scoring method via data augmentation, ensemble convolution neural network, and expert knowledge. Biomed. Signal Process. Control 2021, 70, 102981. [Google Scholar] [CrossRef]
- Fang, W.; Wang, K.; Fahier, N.; Ho, Y.; Huang, Y. Development and Validation of an EEG-Based Real-Time Emotion Recognition System Using Edge AI Computing Platform with Convolutional Neural Network System-on-Chip Design. IEEE J. Emerg. Sel. Top. Circuits Syst. 2019, 9, 645–657. [Google Scholar] [CrossRef]
- Sumaiyah, I.K.; Maha, S.D.; Soliman, A.M. Design of low power Teager Energy Operator circuit for Sleep Spindle and K-Complex extraction. Microelectron. J. 2020, 100, 104785. [Google Scholar]
- Tzimourta, K.D.; Christou, V.; Tzallas, A.T.; Giannakeas, N.; Astrakas, L.G.; Angelidis, P.; Dimitrios, T.; Tsipouras, M.G. Machine Learning Algorithms and Statistical Approaches for Alzheimer’s Disease Analysis Based on Resting-State EEG Recordings: A Systematic Review. Int. J. Neural Syst. 2021, 31, 2130002. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Chato, L.; Latifi, S. Machine learning and deep learning techniques to predict overall survival of brain tumor patients using MRI images. In Proceedings of the 2017 IEEE 17th International Conference on Bioinformatics and Bioengineering, Washington, DC, USA, 23–25 October 2017; pp. 9–14. [Google Scholar]
- Sosulski, J.; Kemmer, J.P.; Tangermann, M. Improving Covariance Matrices Derived from Tiny Training Datasets for the Classification of Event-Related Potentials with Linear Discriminant Analysis. Neuroinformatics 2021, 19, 461–476. [Google Scholar] [CrossRef]
- Fushiki, T. Estimation of prediction error by using K-fold cross-validation. Stat. Comput. 2011, 21, 137–146. [Google Scholar] [CrossRef]
- Lyu, Y.; Li, H.; Sayagh, M.; Jiang, Z.M.; Hassan, A.E. An empirical study of the impact of data splitting decisions on the performance of AIOps solutions. ACM Trans. Softw. Eng. Methodol. 2021, 30, 54. [Google Scholar] [CrossRef]
- Xanthopoulos, P.; Pardalos, P.M.; Trafalis, T.B. Principal Component Analysis. In Robust Data Mining; Springer: New York, NY, USA, 2013; pp. 27–33. [Google Scholar]
- Fu, R.; Tian, Y.; Shi, P.; Bao, T. Automatic Detection of Epileptic Seizures in EEG Using Sparse CSP and Fisher Linear Discrimination Analysis Algorithm. J. Med. Syst. 2020, 44, 43. [Google Scholar] [CrossRef] [PubMed]
- Kandasamy, K.; Vysyaraju, K.R.; Neiswanger, W.; Paria, B.; Collins, C.R.; Schneider, J.; P’oczos, B.; Xing, E.P. Tuning Hyperparameters without Grad Students: Scalable and Robust Bayesian Optimisation with Dragonfly. J. Mach. Learn. Res. 2020, 21, 1–27. [Google Scholar]
- Weerts, H.J.; Mueller, A.C.; Vanschoren, J. Importance of tuning hyperparameters of machine learning algorithms. arXiv 2020, arXiv:2007.07588. [Google Scholar]
- Shekar, B.H.; Dagnew, G. Grid Search-Based Hyperparameter Tuning and Classification of Microarray Cancer Data. Proceeedings of the 2019 Second International Conference on Advanced Computational and Communication Paradigms (ICACCP), Gangtok, India, 25–28 February 2019; pp. 1–8. [Google Scholar]
- Friedrichs, F.; Igel, C. Evolutionary tuning of multiple SVM parameters. Neurocomputing 2005, 64, 107–117. [Google Scholar] [CrossRef]
- Wong, T.T.; Yeh, P.Y. Reliable accuracy estimates from k-fold cross validation. IEEE Trans. Knowl. Data Eng. 2019, 32, 1586–1594. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. K-fold Cross validation. In An Introduction to Statistical Learning with Application in R; Casella, G., Fienberg, S., Olkin, I., Eds.; Springer: New York, NY, USA, 2013; Volume 112. [Google Scholar]
- Phyu, T.N. Survey of classification techniques in data mining. In Proceedings of the International Multiconference of Engineers and Computer Scientists, Hong Kong, China, 18–20 March 2009. [Google Scholar]
- Kulkarni, N.; Bairagi, V. EEG-based Diagnosis of Alzheimer Disease: A Review and Novel Approaches for Feature Extraction and Classification Techniques; Elsevier Academic Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Elgandelwar, S.M.; Bairagi, V.K. Power analysis of EEG bands for diagnosis of Alzheimer dis-ease. Int. J. Med. Eng. Inform. 2021, 13, 376–385. [Google Scholar]
- Bairagi, V. EEG signal analysis for early diagnosis of Alzheimer disease using spectral and wavelet based features. Int. J. Inf. Technol. 2018, 10, 403–412. [Google Scholar] [CrossRef]
- Cejnek, M.; Vysata, O.; Valis, M.; Bukovsky, I. Novelty detection-based approach for Alzheimer’s disease and mild cognitive impairment diagnosis from EEG. Med. Biol. Eng. Comput. 2021, 59, 2287–2296. [Google Scholar] [CrossRef]
- Oltu, B.; Akşahin, M.F.; Kibaroğlu, S. A novel electroencephalography based approach for Alzheimer’s disease and mild cognitive impairment detection. Biomed. Signal. Process. Control 2021, 63, 102223. [Google Scholar] [CrossRef]
- Ieracitano, C.; Mammone, N.; Hussain, A.; Morabito, F.C. A novel multi-modal machine learning based approach for automatic classification of EEG recordings in dementia. Neural Netw. 2021, 121, 176–190. [Google Scholar] [CrossRef] [PubMed]
- Kulkarni, N.N.; Bairagi, V.K. Extracting salient features for EEG-based diagnosis of Alzheimer’s disease using support vector machine classifier. IETE J. Res. 2017, 63, 11–22. [Google Scholar] [CrossRef]
- Available online: https://coral.ai/docs/dev-board/datasheet/#features (accessed on 18 March 2022).
- Cariolaro, G. Classical Signal Theory. In Unified Signal Theory; Springer: London, UK, 2011; p. 23. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N-Subjects | EEG Signals | Label | Extracted Features |
|---|---|---|---|
| 1 | EEG1, EEG2, …, EEG19 | AD | |
| 2 | EEG1, EEG2, …, EEG19 | MCI | |
| … | ….. | … | ….. |
| 109 | EEG1, EEG2, …, EEG19 | HC |
| Case | fcut (Hz) | Time (s) DT/SVM/K-NN | Tot. Time (s) |
|---|---|---|---|
| AD vs. HC | 7 | 21.8/14.0/3.0 | 38.8 |
| 16 | 20.9/14.0/3.0 | 38.0 | |
| AD vs. MCI | 7 | 22.3/14.8/3.0 | 40.1 |
| 16 | 21.1/15.0/3.0 | 39.1 | |
| MCI vs. HC | 7 | 20.7/13.3/3.0 | 37.0 |
| 16 | 21.1/13.6/3.0 | 37.7 | |
| AD + MCI vs. HC | 7 | 20.6/16.4/3.0 | 40.0 |
| 16 | 21.1/18.5/3.0 | 42.6 | |
| AD vs. MCI vs. HC | 7 | 25.0/22.6/4.0 | 51.6 |
| 16 | 25.9/24.1/4.8 | 54.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pirrone, D.; Weitschek, E.; Di Paolo, P.; De Salvo, S.; De Cola, M.C. EEG Signal Processing and Supervised Machine Learning to Early Diagnose Alzheimer’s Disease. Appl. Sci. 2022, 12, 5413. https://doi.org/10.3390/app12115413
Pirrone D, Weitschek E, Di Paolo P, De Salvo S, De Cola MC. EEG Signal Processing and Supervised Machine Learning to Early Diagnose Alzheimer’s Disease. Applied Sciences. 2022; 12(11):5413. https://doi.org/10.3390/app12115413
Chicago/Turabian StylePirrone, Daniele, Emanuel Weitschek, Primiano Di Paolo, Simona De Salvo, and Maria Cristina De Cola. 2022. "EEG Signal Processing and Supervised Machine Learning to Early Diagnose Alzheimer’s Disease" Applied Sciences 12, no. 11: 5413. https://doi.org/10.3390/app12115413
APA StylePirrone, D., Weitschek, E., Di Paolo, P., De Salvo, S., & De Cola, M. C. (2022). EEG Signal Processing and Supervised Machine Learning to Early Diagnose Alzheimer’s Disease. Applied Sciences, 12(11), 5413. https://doi.org/10.3390/app12115413