
Automated Detection of Greenhouse Structures Using Cascade Mask R-CNN


Abstract
:1. Introduction
2. Background
3. Materials and Methods
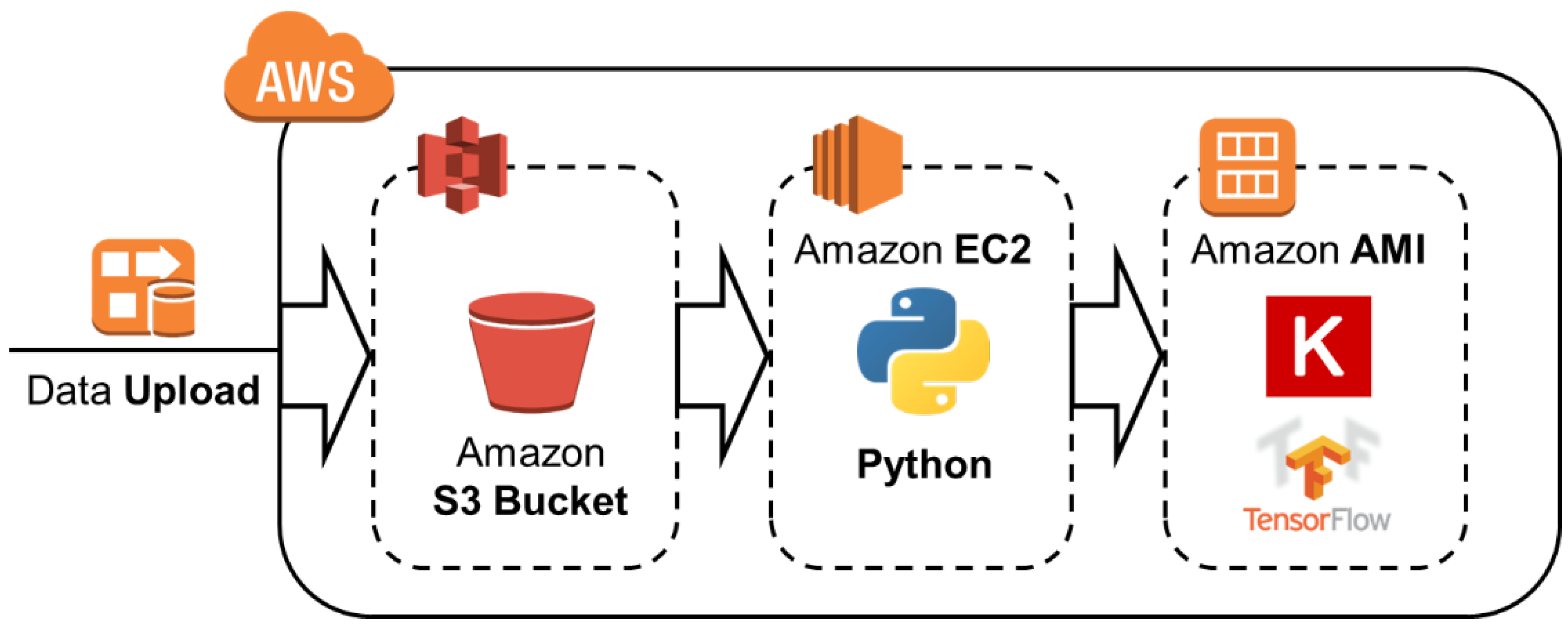
3.1. Area of Study and Data
3.2. Mask R-CNN
3.3. Cascade Mask R-CNN
4. Results and Discussion
- We explain the results obtained from our experimental design, in which the transfer learning, hyperparameter tuning, and the values of the final hyperparameters are explained.
- We scrutinize the performance of our proposed model, and compare it with two existing models (baseline Mask R-CNN and Mask R-CNN).
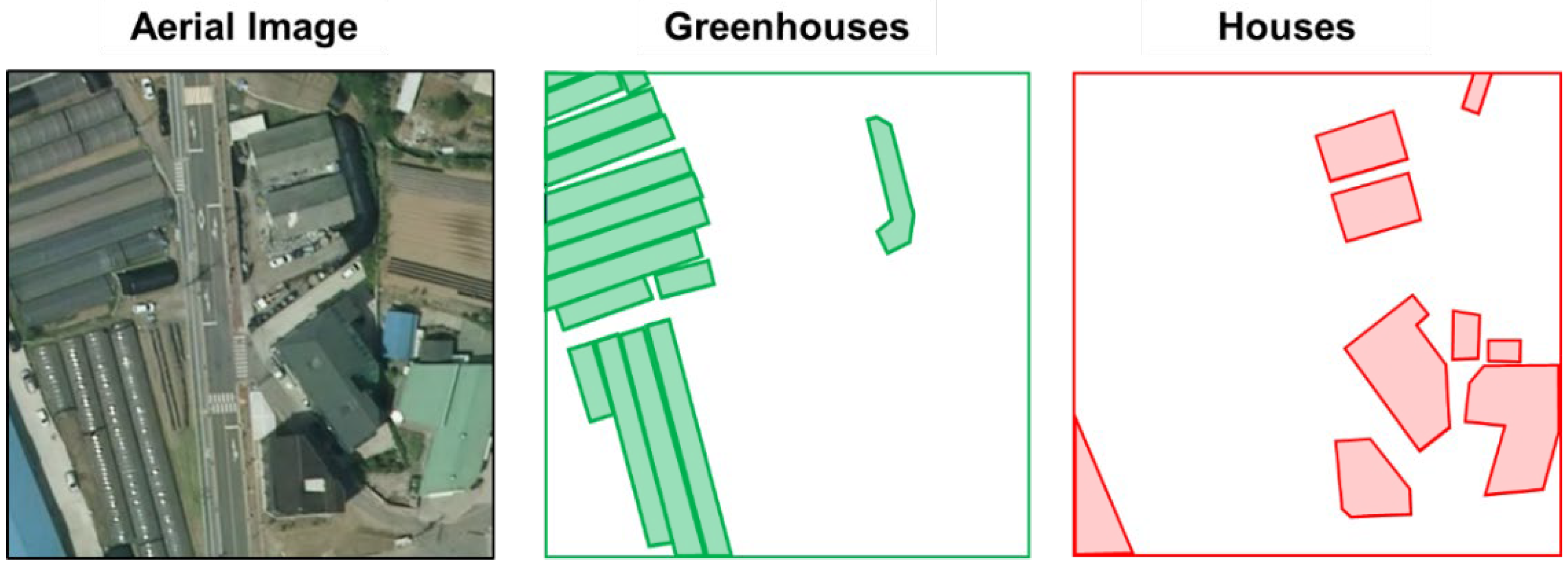
- We visualize the object-detection results obtained from the Cascade Mask R-CNN.
5. Conclusions and Future Prospects
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Park, J.H. A Study on Policy Changes the Green Belt by Analyzing of Official Gazette. Geogr. J. Korea 2021, 55, 57–72. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krišto, M.; Ivasic-Kos, M.; Pobar, M. Thermal object detection in difficult weather conditions using YOLO. IEEE Access 2020, 8, 125459–125476. [Google Scholar] [CrossRef]
- Devaguptapu, C.; Akolekar, N.; Sharma, M.M.; Balasubramanian, V.N. Borrow from anywhere: Pseudo multi-modal object detection in thermal imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 1029–1038. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Khan, M.S.; Jeon, S.B.; Jeong, M.-H. Gap-Filling Eddy Covariance Latent Heat Flux: Inter-Comparison of Four Machine Learning Model Predictions and Uncertainties in Forest Ecosystem. Remote Sens. 2021, 13, 4976. [Google Scholar] [CrossRef]
- Shang-Liang, C.; Li-Wu, H. Using Deep Learning Technology to Realize the Automatic Control Program of Robot Arm Based on Hand Gesture Recognition. Int. J. Eng. Technol. Innov. 2021, 11, 241. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4203–4212. [Google Scholar]
- Wu, B.; Iandola, F.; Jin, P.H.; Keutzer, K. Squeezedet: Unified, small, low power fully convolutional neural networks for real-time object detection for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 129–137. [Google Scholar]
- Tao, A.; Barker, J.; Sarathy, S. Detectnet: Deep Neural Network for Object Detection in Digits. Parallel Forall 2016. Available online: https://devblogs.nvidia.com/detectnet-deep-neural-network-object-detection-digits (accessed on 22 December 2021).
- Lee, T.-Y.; Jeong, M.-H.; Peter, A. Object Detection of Road Facilities Using YOLOv3 for High-definition Map Updates. Sens. Mater. 2022, 34, 251–260. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 29, 379–387. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Gidaris, S.; Komodakis, N. Object detection via a multi-region and semantic segmentation-aware cnn model. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1134–1142. [Google Scholar]
- Yoo, D.; Park, S.; Lee, J.-Y.; Paek, A.S.; So Kweon, I. Attentionnet: Aggregating weak directions for accurate object detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2659–2667. [Google Scholar]
- Li, H.; Lin, Z.; Shen, X.; Brandt, J.; Hua, G. A convolutional neural network cascade for face detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5325–5334. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W. Hybrid task cascade for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4974–4983. [Google Scholar]
- Wu, X.; Sahoo, D.; Zhang, D.; Zhu, J.; Hoi, S.C. Single-shot bidirectional pyramid networks for high-quality object detection. Neurocomputing 2020, 401, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Zhu, C.; Cai, X.; Huang, K.; Li, T.H.; Li, G. PDNet: Prior-model guided depth-enhanced network for salient object detection. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 199–204. [Google Scholar]
- Chen, Z.; Cong, R.; Xu, Q.; Huang, Q. DPANet: Depth potentiality-aware gated attention network for RGB-D salient object detection. IEEE Trans. Image Process. 2020, 30, 7012–7024. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Sun, J.; Xie, Y.; Zhang, S.; Shuai, Q.; Jiang, Q.; Zhang, G.; Bao, H.; Zhou, X. Shape Prior Guided Instance Disparity Estimation for 3D Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]
- Ma, Y.; Sun, D.; Meng, Q.; Ding, Z.; Li, C. Learning multiscale deep features and SVM regressors for adaptive RGB-T saliency detection. In Proceedings of the 2017 10th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 9–10 December 2017; pp. 389–392. [Google Scholar]
- Ha, Q.; Watanabe, K.; Karasawa, T.; Ushiku, Y.; Harada, T. MFNet: Towards real-time semantic segmentation for autonomous vehicles with multi-spectral scenes. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5108–5115. [Google Scholar]
- MOLIT. Restricted Development Zone Data in Republic of Korea. 2022. Available online: http://data.nsdi.go.kr/dataset/15147 (accessed on 22 December 2021).
- Dutta, A.; Gupta, A.; Zissermann, A. VGG Image Annotator (VIA). 2016. Available online: http://www.robots.ox.ac.uk/~vgg/software/via (accessed on 22 December 2021).
- Jeong, M.H.; Sullivan, C.J.; Gao, Y.; Wang, S. Robust abnormality detection methods for spatial search of radioactive materials. Trans. GIS 2019, 23, 860–877. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2cnn: Rotational region cnn for orientation robust scene text detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic ship detection in remote sensing images from google earth of complex scenes based on multiscale rotation dense feature pyramid networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Shang, K.; Wu, H.; Wang, C. Decoupled R-CNN: Sensitivity-Specific Detector for Higher Accurate Localization. IEEE Trans. Circuits Syst. Video Technol. 2022. [Google Scholar] [CrossRef]
- Liu, N.; Li, L.; Zhao, W.; Han, J.; Shao, L. Instance-Level Relative Saliency Ranking with Graph Reasoning. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Input | Cascade Mask R-CNNmAP | Mask R-CNN mAP |
|---|---|---|---|
| Transfer Learning | Heads | 49.29 | 48.28 |
| 5+ | 77.11 | 55.08 | |
| 4+ | 78.95 | 74.24 | |
| 3+ | 79.79 | 74.52 | |
| all | 79.96 | 72.64 | |
| Learning Rate | 0.005 | 67.00 | 59.63 |
| 0.001 | 75.47 | 66.72 | |
| 0.0001 | 76.23 | 63.18 | |
| 0.0003 | 78.86 | 61.13 | |
| Backbone | Resnet-50 | 77.32 | 67.94 |
| Resnet-101 | 78.95 | 70.57 | |
| Image Size | 256 × 256 | 60.62 | 48.68 |
| 512 × 512 | 65.63 | 67.59 | |
| 768 × 768 | 76.38 | 70.45 | |
| 1024 × 1024 | 76.85 | 70.56 |
| Hyperparameters | Input |
|---|---|
| NUM classes | 1 + 2 |
| Step per epoch | 200 |
| Detection min confidence | 0.9 |
| Backbone | Resnet-101 |
| Image resize mode | square |
| Image max dim | 768 |
| Image channel count | 3(RGB) |
| Max GT instances | 70 |
| Train ROIS per image | 256 |
| RP anchor scales | (12, 32, 64, 128, 256) |
| Detection max instances | 50 |
| Learning rate | 0.0003 |
| Weight decay | 0.00003 |
| RPN train anchors per image | 320 |
| Layers | 3+ |
| Hyperparameters | Input |
|---|---|
| NUM classes | 1 + 2 |
| Step per epoch | 200 |
| Detection min confidence | 0.9 |
| Backbone | Resnet-101 |
| Image resize mode | square |
| Image max dim | 768 |
| Image channel count | 3(RGB) |
| Max GT instances | 70 |
| Train ROIS per image | 256 |
| RP anchor scales | (12, 32, 64, 128, 256) |
| Detection max instances | 50 |
| Learning rate | 0.001 |
| Weight decay | 0.00003 |
| RPN train anchors per image | 320 |
| Layers | 3+ |
| Model | mAP | F1-Score |
|---|---|---|
| baseline Mask R-CNN | 70.77 | 52.33 |
| Mask R-CNN (hyperparameter tuning and transfer learning) | 81.70 | 59.13 |
| Cascade Mask R-CNN (hyperparameter tuning and transfer learning) | 83.60 | 62.07 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oh, H.Y.; Khan, M.S.; Jeon, S.B.; Jeong, M.-H. Automated Detection of Greenhouse Structures Using Cascade Mask R-CNN. Appl. Sci. 2022, 12, 5553. https://doi.org/10.3390/app12115553
Oh HY, Khan MS, Jeon SB, Jeong M-H. Automated Detection of Greenhouse Structures Using Cascade Mask R-CNN. Applied Sciences. 2022; 12(11):5553. https://doi.org/10.3390/app12115553
Chicago/Turabian StyleOh, Haeng Yeol, Muhammad Sarfraz Khan, Seung Bae Jeon, and Myeong-Hun Jeong. 2022. "Automated Detection of Greenhouse Structures Using Cascade Mask R-CNN" Applied Sciences 12, no. 11: 5553. https://doi.org/10.3390/app12115553
APA StyleOh, H. Y., Khan, M. S., Jeon, S. B., & Jeong, M. -H. (2022). Automated Detection of Greenhouse Structures Using Cascade Mask R-CNN. Applied Sciences, 12(11), 5553. https://doi.org/10.3390/app12115553