
A Novel Method for Fault Diagnosis of Bearings with Small and Imbalanced Data Based on Generative Adversarial Networks

 , , and
, , and
Abstract
:1. Introduction
- We propose a new GAN model, named ACGAN-SN, by introducing the SN skill. This model improves the training stability of the GAN model and can generate high-quality data of corresponding labels arbitrarily, which provides a new idea for fault diagnosis under S & I data.
- In the fault diagnosis stage, seven fault datasets were made based on the original S & I data and synthetic data, and a bidirectional LSTM model was proposed to fit the nonlinear fault classification function to realize the classification of the fault data.
- To fully test the performance of the proposed method, we adopted seven classification models and four data synthesis methods for comparative research, and selected three data synthesis quality indicators to quantitatively describe the data synthesis ability of ACGAN-SN.
2. Problem Formulation
3. Methods
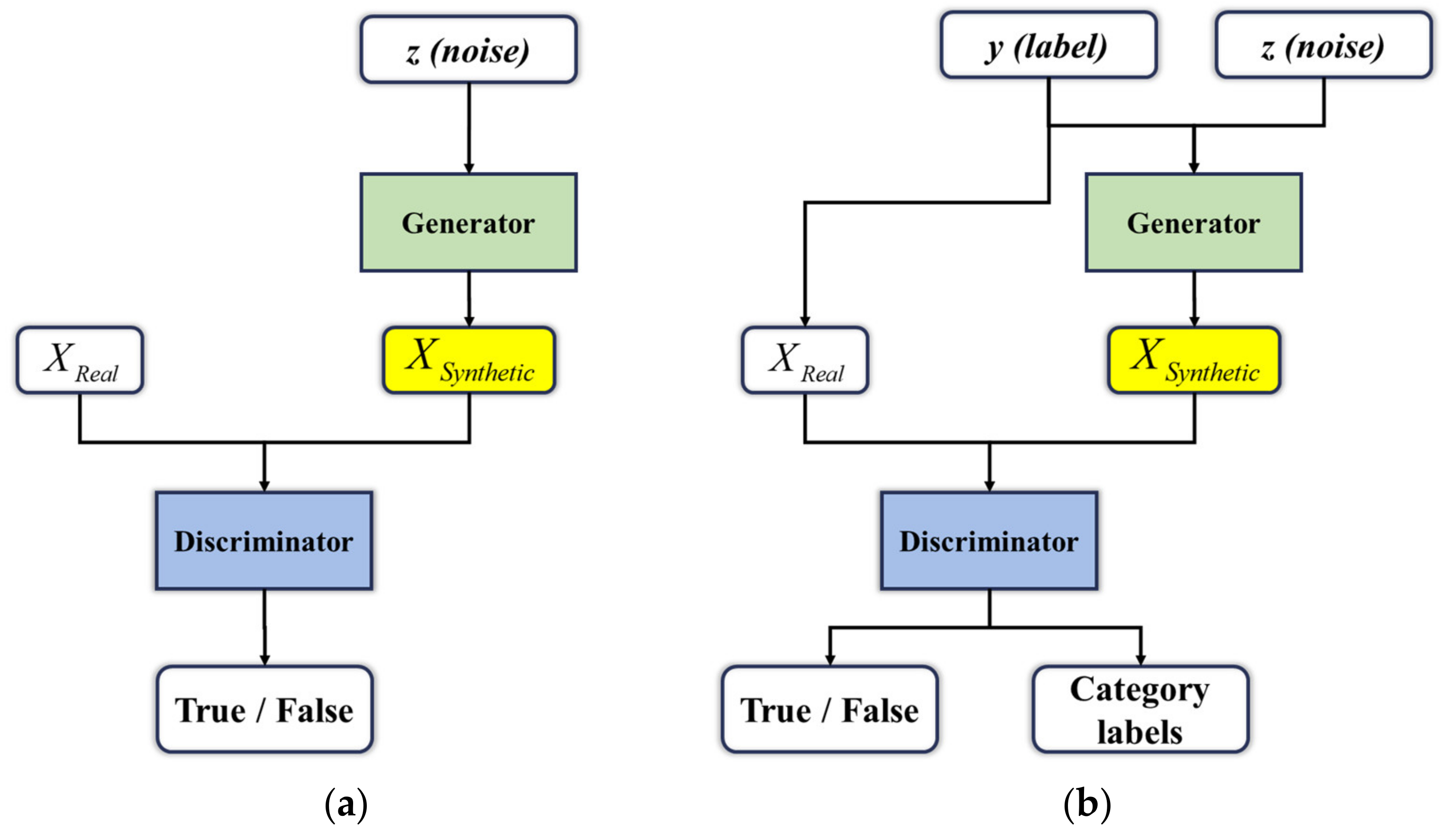
3.1. Auxiliary Classifier Generative Adversarial Networks
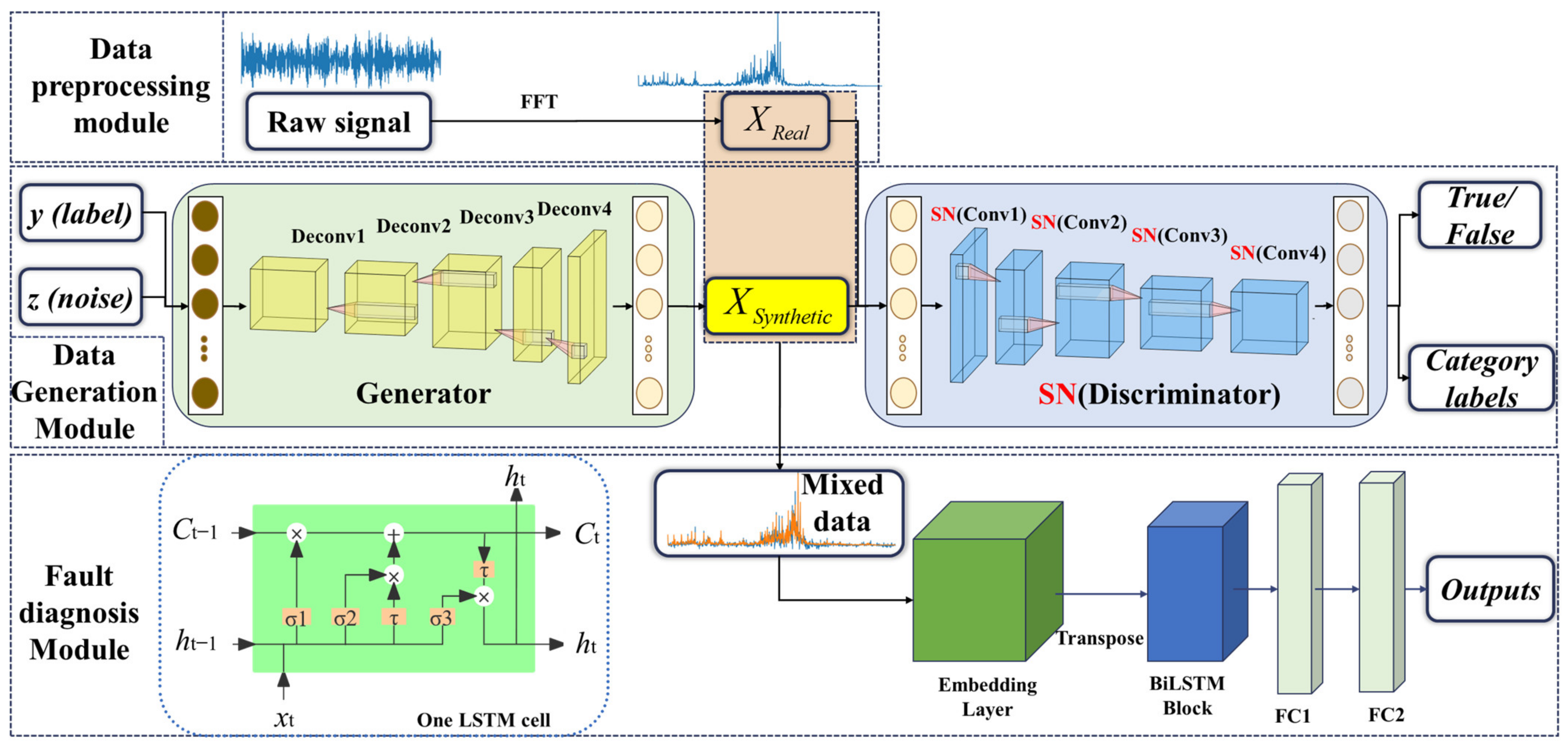
3.2. Overall Framework
3.2.1. Data Preprocessing Module
3.2.2. Data Generation Module
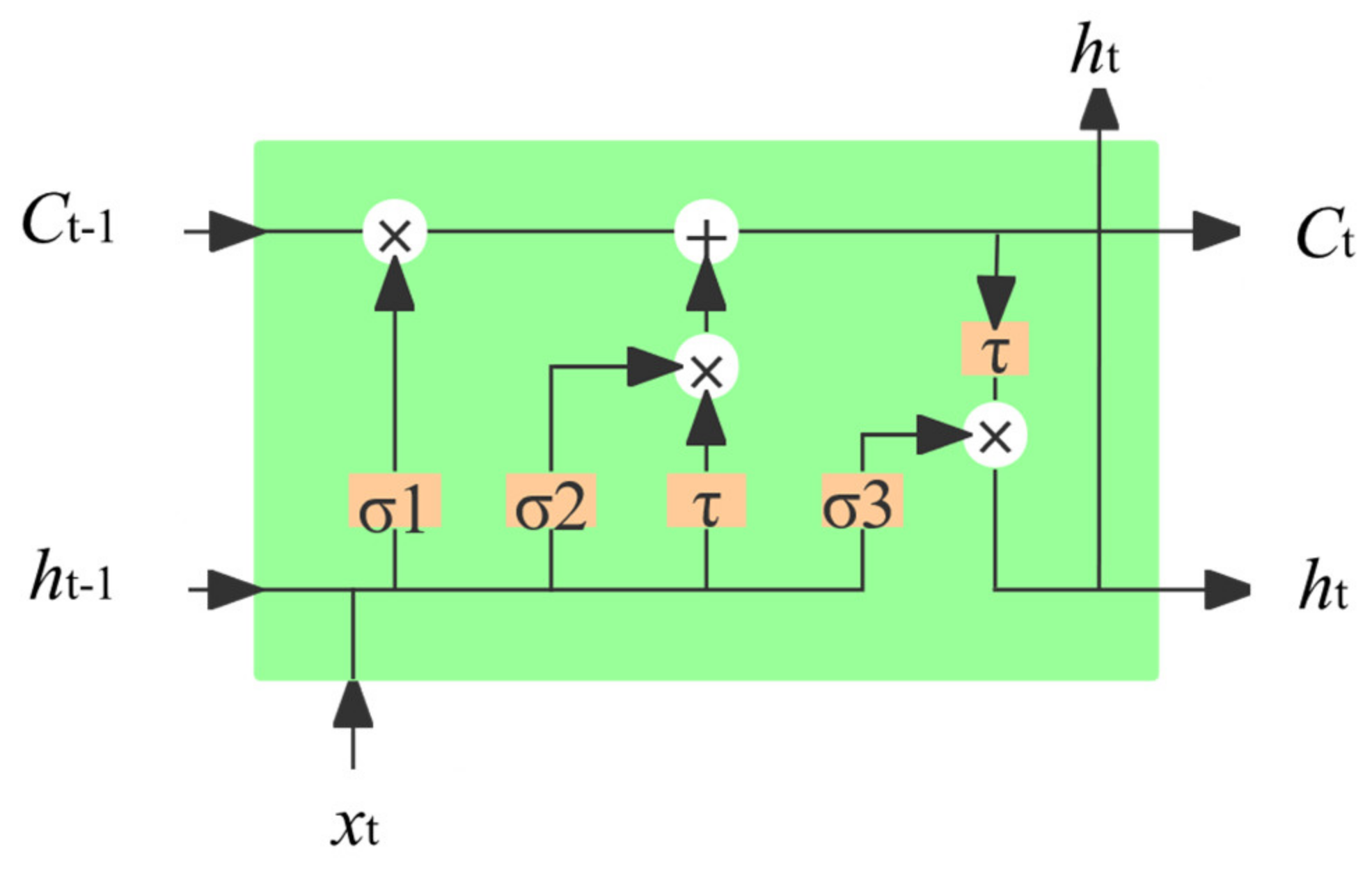
3.2.3. Fault Diagnosis Module
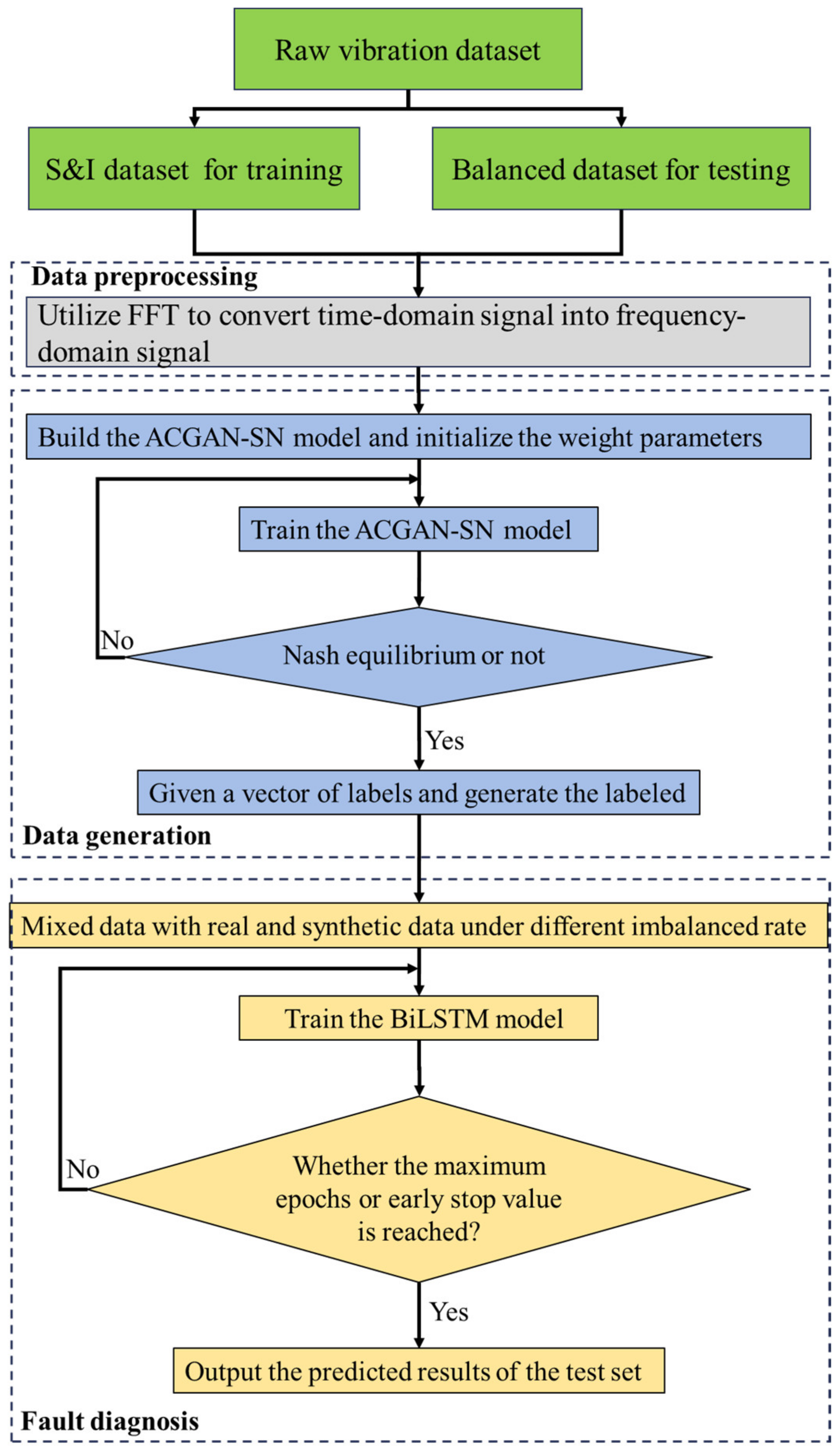
3.2.4. Training and Testing Procedure of the Proposed Fault Diagnosis Framework
- The raw vibration signal data are acquired and divided into an S & I dataset for training and a balanced dataset for testing.
- FFT is performed on the two datasets to obtain the preprocessed frequency domain signal.
- The ACGAN-SN model described in Section 3.2.2. is built to initialize the model weight parameters and hyperparameters, and to train the ACGAN-SN until the Nash equilibrium conditions are met. The trained model is used to synthesize the data that require labels.
- Real data and synthetic data are mixed to form a variety of datasets with different imbalance ratios for the training of the fault diagnosis models.
- The BiLSTM-based fault diagnosis model described in Section 3.2.3 is built, the BiLSTM model is trained with different datasets, the fault state of the test set with the trained model is predicted and compared with the other methods to evaluate the performance of the proposed fault diagnosis method.
4. Results
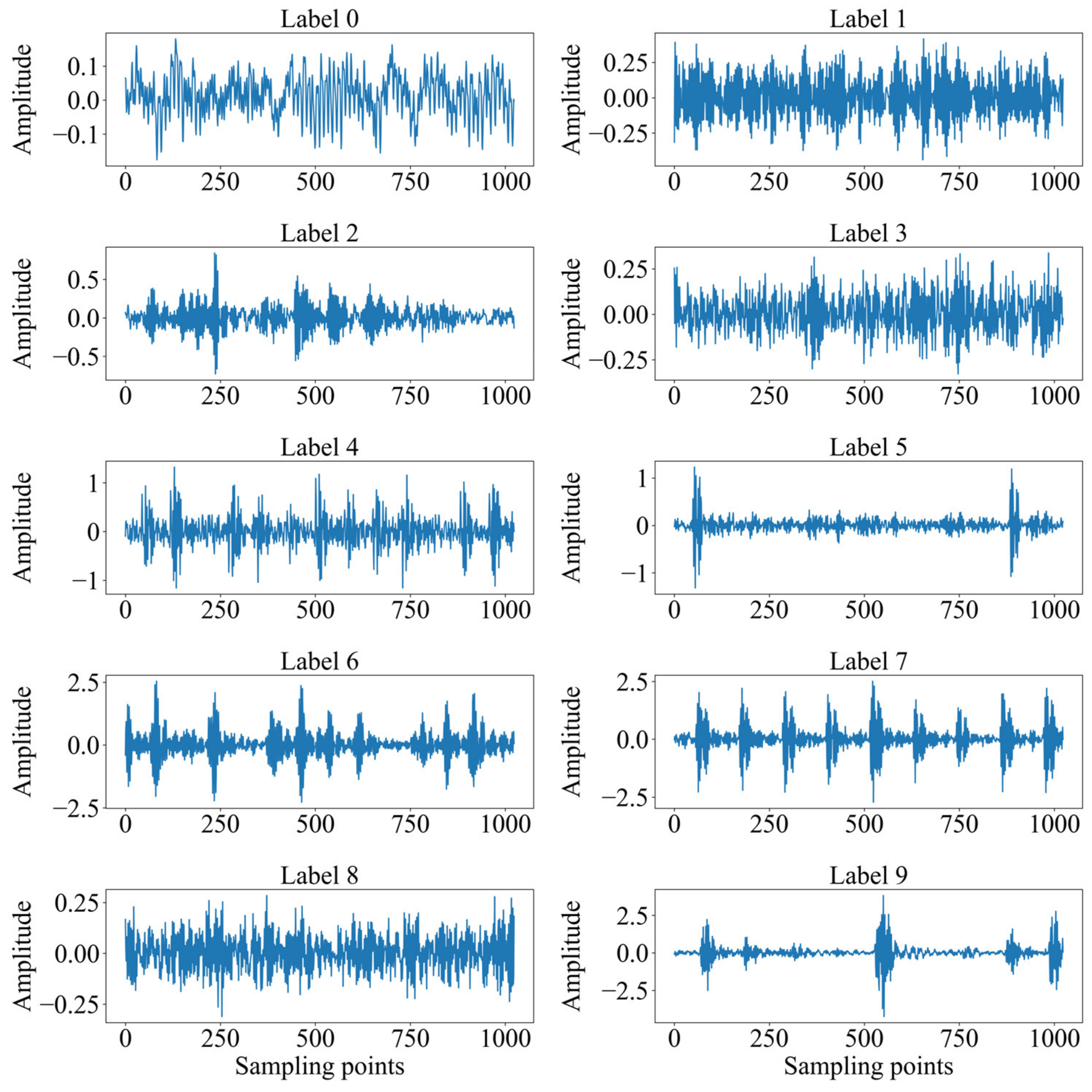
4.1. Dateset Introduction
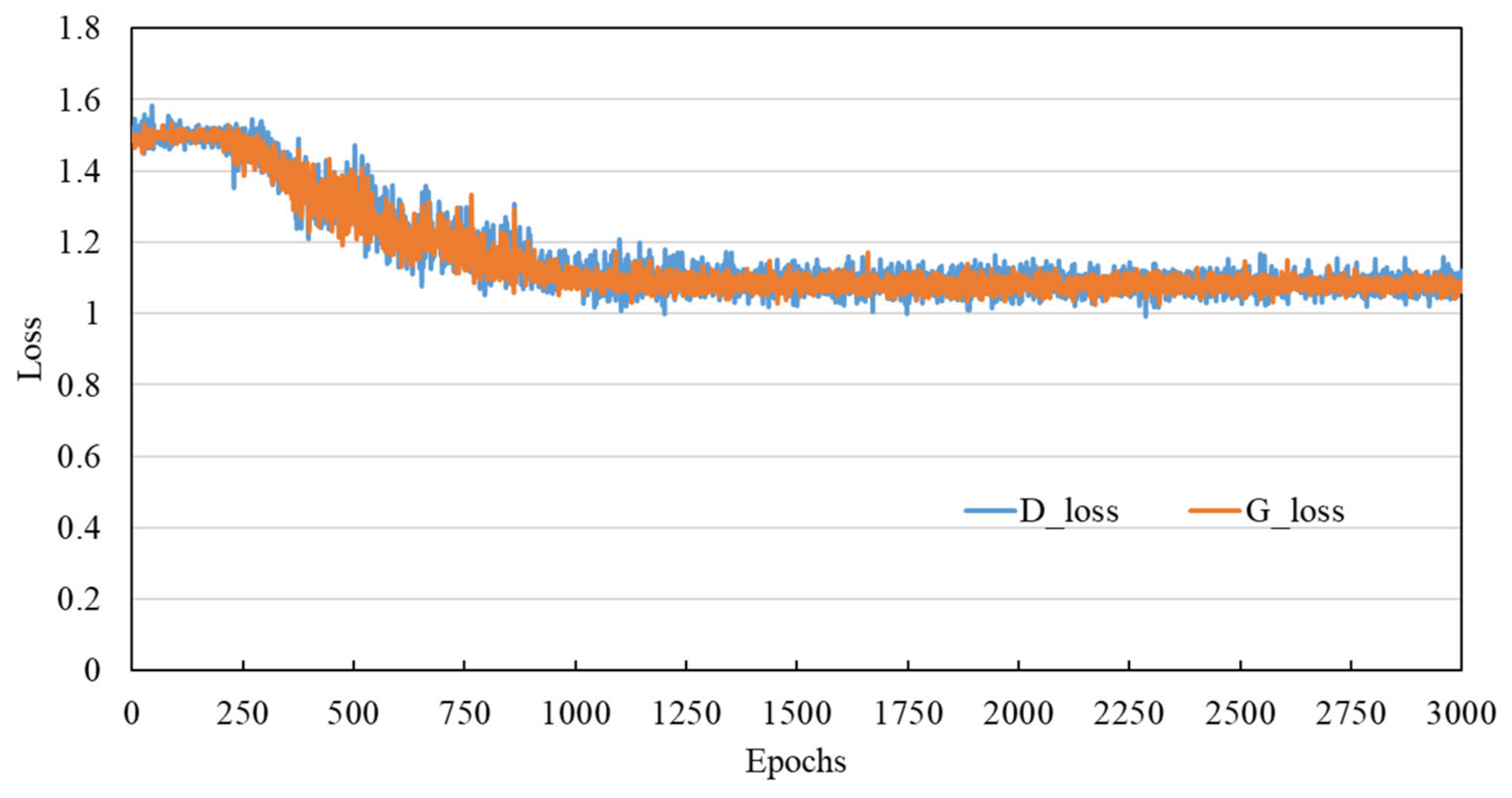
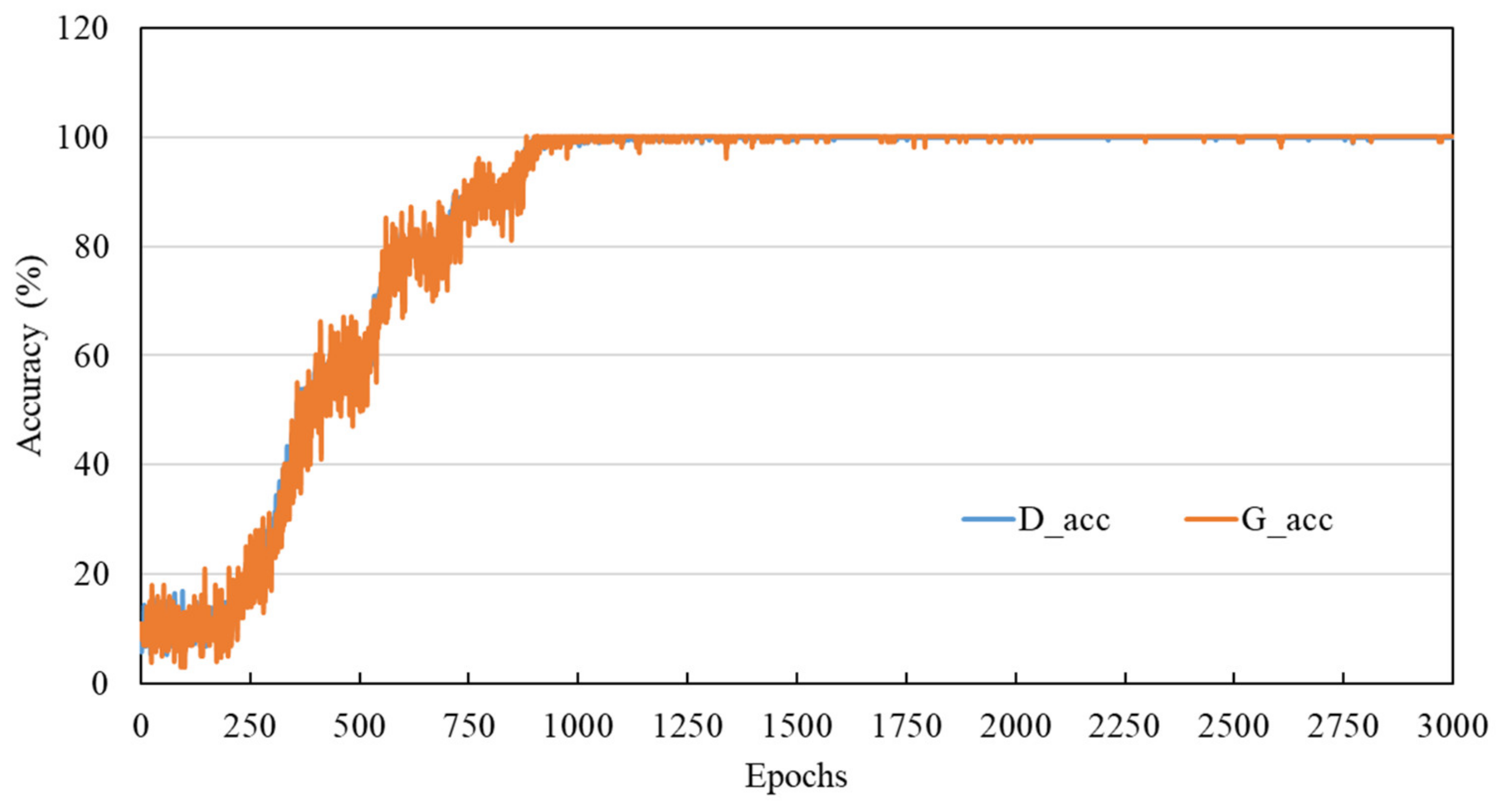
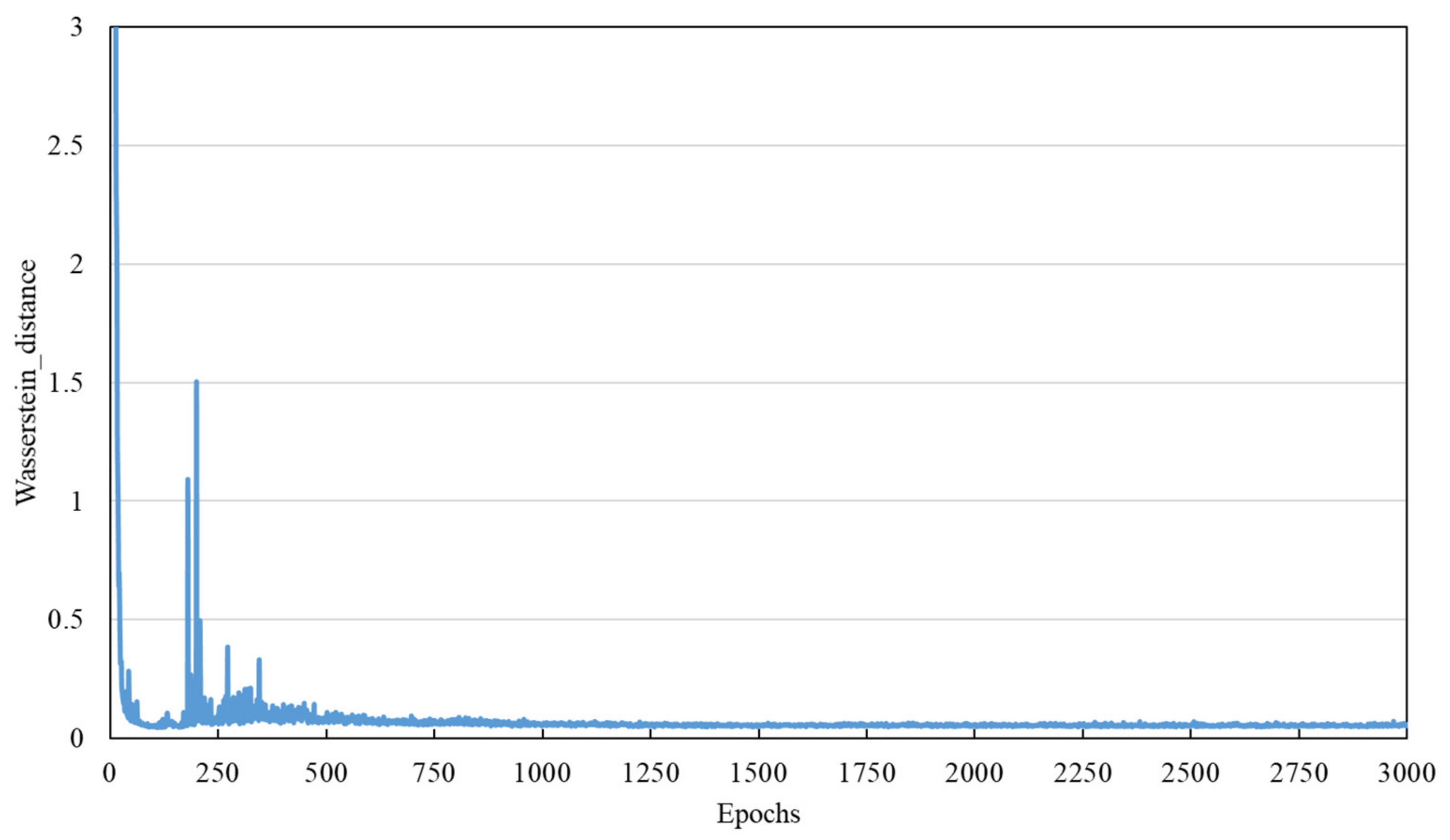
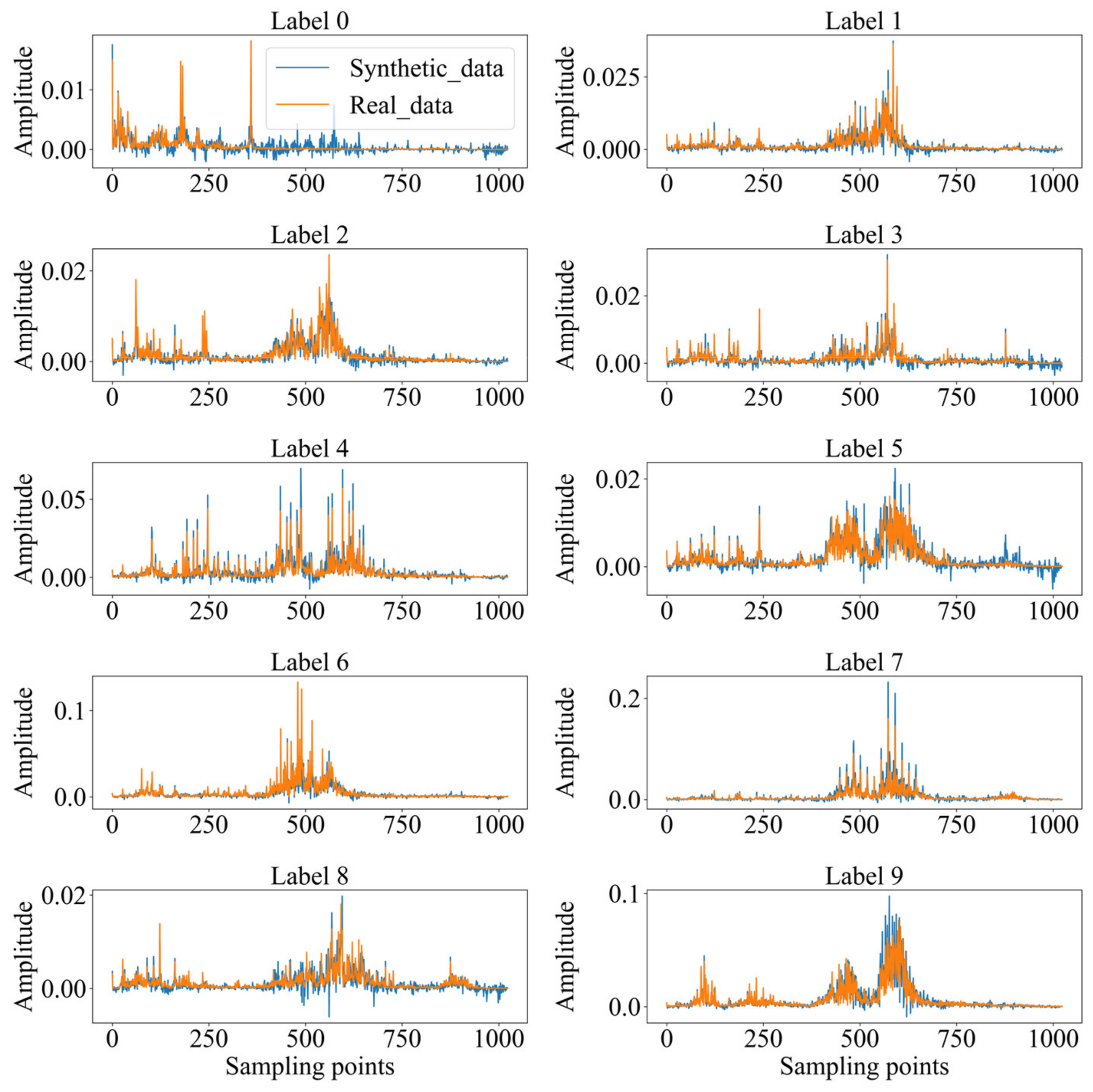
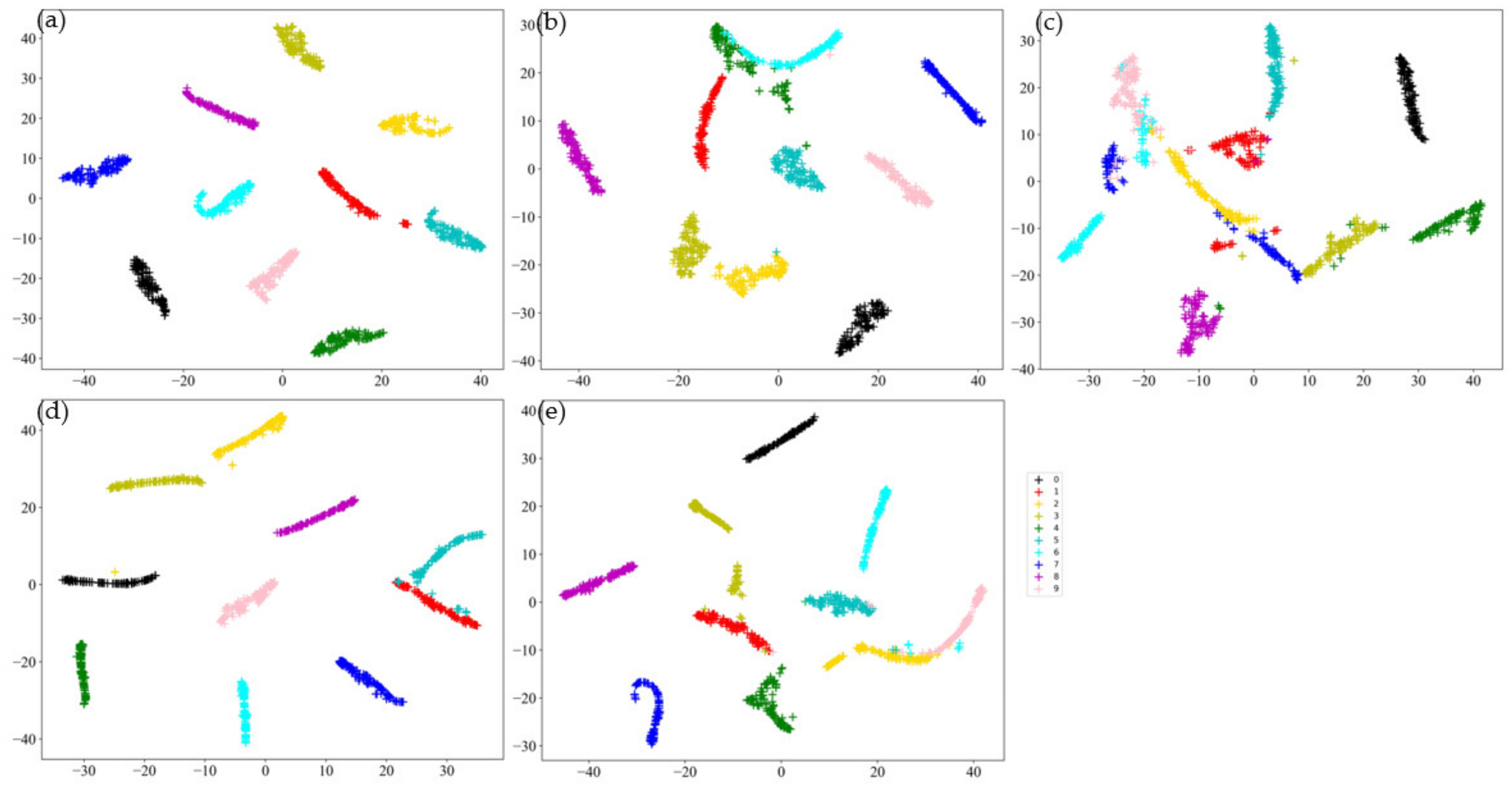
4.2. Sample Generation and Evaluation
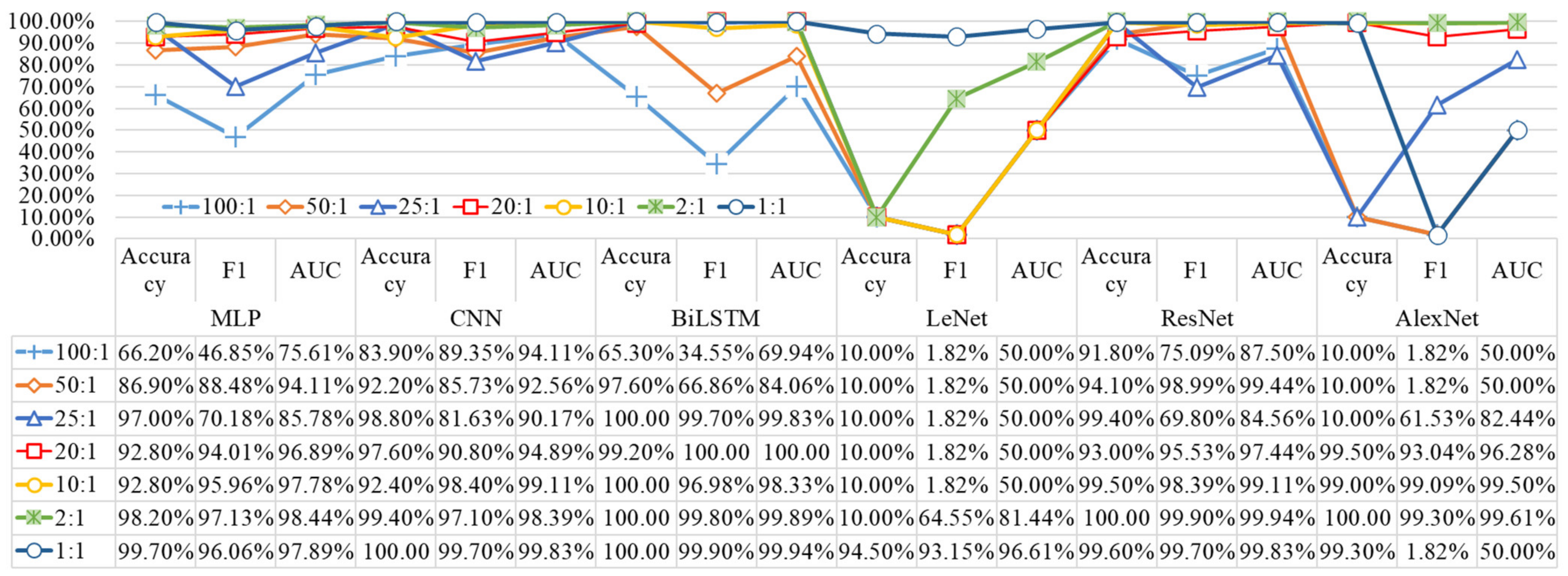
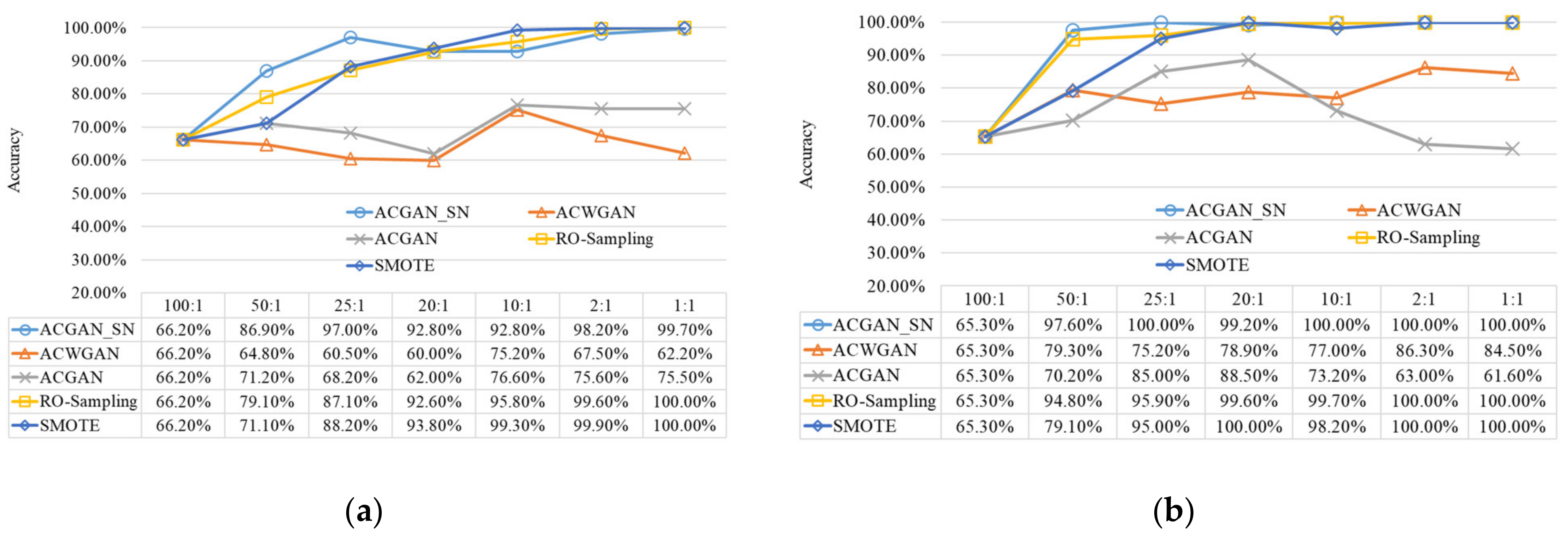
4.3. Imbalanced Fault Diagnosis
- LeNet and AlexNet have the worst performance in processing S & I data. The possible reason for this is that they cannot fit the data distribution of the test set from the S & I data. A diagnostic accuracy of 10% corresponds to the prediction results of the normal data, which indicates that the imbalanced data do indeed affect the prediction results of the model.
- The diagnosis accuracy of the MLP, CNN, ResNet, and LSTM models has been greatly improved since dataset 2, which shows that the synthetic fault data promote the training process of the model, and the synthetic data are very similar to the real data.
- We found that BiLSTM achieved an accuracy of 97.6% in dataset 2, and the diagnostic accuracy in dataset 2−dataset 7 was higher than that of the comparison method, which shows that BiLSTM has a strong classification performance for the bearing frequency domain data. Although the effect of CNN and ResNet is also very good, the calculation time of ResNet is too long. Considering the time cost and diagnosis accuracy, BiLSTM is used in this paper to perform fault diagnosis tasks on S & I data.
5. Conclusions
- By introducing kernel norm regularization into the ACGAN model, the training stability of the model can be effectively improved, and gradient disappearance and model collapse can be avoided.
- Compared with traditional SMOTE and RO-Sampling data synthesis algorithms, ACGAN-SN can synthesize high-quality fault sample data. The similarity between the synthetic data and real data can reach 95.84%.
- The data synthesized by ACGAN-SN effectively improve the fault diagnosis accuracy under S & I data.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Heras, I.; Aguirrebeitia, J.; Abasolo, M.; Coria, I.; Escanciano, I. Load distribution and friction torque in four-point contact slewing bearings considering manufacturing errors and ring flexibility. Mech. Mach. Theory 2019, 137, 23–36. [Google Scholar] [CrossRef]
- Ambrożkiewicz, B.; Syta, A.; Gassner, A.; Georgiadis, A.; Litak, G.; Meier, N. The influence of the radial internal clearance on the dynamic response of self-aligning ball bearings. Mech. Syst. Signal Process. 2022, 171, 108954. [Google Scholar] [CrossRef]
- Gao, S.; Chatterton, S.; Pennacchi, P.; Han, Q.; Chu, F. Skidding and cage whirling of angular contact ball bearings: Kinematic-hertzian contact-thermal-elasto-hydrodynamic model with thermal expansion and experimental validation. Mech. Syst. Signal Process. 2021, 166, 108427. [Google Scholar] [CrossRef]
- Chen, H.; Jiang, B.; Ding, S.X.; Huang, B. Data-Driven Fault Diagnosis for Traction Systems in High-Speed Trains: A Survey, Challenges, and Perspectives. Mech. Syst. Signal Process. 2022, 23, 1700–1716. [Google Scholar] [CrossRef]
- Lee, J.; Wu, F.; Zhao, W.; Ghaffari, M.; Liao, L.; Siegel, D. Prognostics and health management design for rotary machinery systems—Reviews, methodology and applications. Mech. Syst. Signal Process. 2014, 42, 314–334. [Google Scholar] [CrossRef]
- Li, W.; Huang, R.; Li, J.; Liao, Y.; Chen, Z.; He, G.; Yan, R.; Gryllias, K. A perspective survey on deep transfer learning for fault diagnosis in industrial scenarios: Theories, applications and challenges. Mech. Syst. Signal Process. 2022, 167, 108487. [Google Scholar] [CrossRef]
- Zhang, T.; Chen, J.; Li, F.; Zhang, K.; Lv, H.; He, S.; Xu, E. Intelligent fault diagnosis of machines with small & imbalanced data: A state-of-the-art review and possible extensions. ISA Trans. 2022, 119, 152–171. [Google Scholar]
- Randall, R.B.; Antoni, J. Rolling element bearing diagnostics—A tutorial. Mech. Syst. Signal Process. 2011, 25, 485–520. [Google Scholar] [CrossRef]
- Georgoulas, G.; Loutas, T.; Stylios, C.D.; Kostopoulos, V. Bearing fault detection based on hybrid ensemble detector and empirical mode decomposition. Mech. Syst. Signal Process. 2013, 41, 510–525. [Google Scholar] [CrossRef]
- Zhang, W.; Li, C.; Peng, G.; Chen, Y.; Zhang, Z. A deep convolutional neural network with new training methods for bearing fault diagnosis under noisy environment and different working load. Mech. Syst. Signal Process. 2018, 100, 439–453. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, S.; Li, W. Bearing performance degradation assessment using long short-term memory recurrent network. Comput. Ind. 2018, 106, 14–29. [Google Scholar] [CrossRef]
- Li, T.; Zhao, Z.; Sun, C.; Yan, R.; Chen, X. Multireceptive Field Graph Convolutional Networks for Machine Fault Diagnosis. IEEE Trans. Ind. Electron. 2021, 68, 12739–12749. [Google Scholar] [CrossRef]
- Shao, S.; Wang, P.; Yan, R. Generative adversarial networks for data augmentation in machine fault diagnosis. Comput. Ind. 2019, 106, 85–93. [Google Scholar] [CrossRef]
- Xing, S.; Lei, Y.; Yang, B.; Lu, N. Adaptive Knowledge Transfer by Continual Weighted Updating of Filter Kernels for Few-Shot Fault Diagnosis of Machines. IEEE Trans. Ind. Electron. 2021, 69, 1968–1976. [Google Scholar] [CrossRef]
- He, Z.; Shao, H.; Cheng, J.; Zhao, X.; Yang, Y. Support tensor machine with dynamic penalty factors and its application to the fault diagnosis of rotating machinery with unbalanced data. Mech. Syst. Signal Process. 2019, 141, 106441. [Google Scholar] [CrossRef]
- Patterson, J.; Gibson, A. Deep Learning: A Practitioner’s Approach; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2017. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- Yi, H.; Jiang, Q.; Yan, X.; Wang, B. Imbalanced Classification Based on Minority Clustering Synthetic Minority Oversampling Technique With Wind Turbine Fault Detection Application. IEEE Trans. Ind. Inform. 2020, 17, 5867–5875. [Google Scholar] [CrossRef]
- Haibo, H.; Yang, B.; Garcia, E.A.; Shutao, L. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 2, 2672–2680. [Google Scholar]
- Navidan, H.; Moshiri, P.F.; Nabati, M.; Shahbazian, R.; Ghorashi, S.A.; Shah-Mansouri, V.; Windridge, D. Generative Adversarial Networks (GANs) in networking: A comprehensive survey & evaluation. Comput. Netw. 2021, 194, 108149. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2016, arXiv:1511.06434. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved Training of Wasserstein GANs. arXiv 2017, arXiv:1704.00028. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional Image Synthesis with Auxiliary Classifier GANs. arXiv 2016, arXiv:1610.09585. [Google Scholar]
- Bui, V.; Pham, T.; Nguyen, H.; Jang, Y. Data Augmentation Using Generative Adversarial Network for Automatic Machine Fault Detection Based on Vibration Signals. Appl. Sci. 2021, 11, 2166. [Google Scholar] [CrossRef]
- Li, Z.; Zheng, T.; Wang, Y.; Cao, Z.; Guo, Z.; Fu, H. A Novel Method for Imbalanced Fault Diagnosis of Rotating Machinery Based on Generative Adversarial Networks. IEEE Trans. Instrum. Meas. 2020, 70, 1–17. [Google Scholar] [CrossRef]
- Chang, H.-C.; Wang, Y.-C.; Shih, Y.-Y.; Kuo, C.-C. Fault Diagnosis of Induction Motors with Imbalanced Data Using Deep Convolutional Generative Adversarial Network. Appl. Sci. 2022, 12, 4080. [Google Scholar] [CrossRef]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral Normalization for Generative Adversarial Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Miao, J.; Wang, J.; Zhang, D.; Miao, Q. Improved Generative Adversarial Network for Rotating Component Fault Diagnosis in Scenarios with Extremely Limited Data. IEEE Trans. Instrum. Meas. 2021, 71, 1–13. [Google Scholar] [CrossRef]
- Sanagavarapu, S.; Sridhar, S.; Chitrakala, S. News Categorization using Hybrid BiLSTM-ANN Model with Feature Engineering. In Proceedings of the IEEE Annual Computing and Communication Workshop and Conference, Las Vegas, NV, USA, 27–30 January 2021. [Google Scholar]
- Zhao, Z.; Li, T.; Wu, J.; Sun, C.; Wang, S.; Yan, R.; Chen, X. Deep learning algorithms for rotating machinery intelligent diagnosis: An open source benchmark study. ISA Trans. 2020, 107, 224–255. [Google Scholar] [CrossRef]
- Zhang, P.; Wen, G.; Dong, S.; Lin, H.; Huang, X.; Tian, X.; Chen, X. A Novel Multiscale Lightweight Fault Diagnosis Model Based on the Idea of Adversarial Learning. IEEE Trans. Instrum. Meas. 2021, 70, 1–15. [Google Scholar] [CrossRef]
- Zhang, H.; Li, M. RWO-Sampling: A random walk over-sampling approach to imbalanced data classification. Inf. Fusion 2014, 20, 99–116. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. arXiv 2011, arXiv:1106.1813. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Parameters Setting | Output Size | |
|---|---|---|---|
| Discriminator | Input | Reshape: 1024–32 × 32 | 1 × 32 × 32 |
| Conv1 | Kernel size: 32 × 5 × 5, 8, 2, LeakyReLU, dropout | 32 × 16 × 16 | |
| Conv2 | Kernel size: 64 × 5 × 5, 8, 2, LeakyReLU, dropout, BN | 64 × 8 × 8 | |
| Conv3 | Kernel size: 128 × 5 × 5, 8, 2, LeakyReLU, dropout, BN | 128 × 4 × 4 | |
| Conv4 | Kernel size: 256 × 5 × 5, 8, 2, LeakyReLU, dropout, BN | 256 × 2 × 2 | |
| Output_1 | 1024 × 1, Sigmoid | 1 | |
| Output_2 | 1024 × 10, Softmax | 10 | |
| Generator | Input | Fully connection layer: 100 × 1024; Reshape: 1 × 1024–256 × 2 × 2 | 256 × 2 × 2 |
| Deconv1 | Kernel size: 128 × 5 × 5, 1, 1, ReLU, BN | 128 × 4 × 4 | |
| Deconv2 | Kernel size: 64 × 5 × 5, 1, 0, ReLU, BN | 64 × 8 × 8 | |
| Deconv3 | Kernel size: 32 × 5 × 5, 3, 5, ReLU, BN | 32 × 16 × 16 | |
| Deconv4 | Kernel size: 1 × 5 × 5, 3, 9, Tanh | 1 × 32 × 32 | |
| Output | Reshape: 32 × 32–1024 | 1 × 1024 |
| Layer | Parameters Setting | Output Size |
|---|---|---|
| Embedding1 | Conv1d: 16 × 3, 1, ReLU, BN, Maxpool1d: (2,2) | 1 × 1024 |
| Embedding2 | Conv1d: 32 × 3, 1, ReLU, BN, AdaptiveMaxpool1d: 25 | 16 × 512 |
| Transpose | Reshape: 16 × 512–32 × 25; Data replacement between 1 and 2 dimensional | 25 × 32 |
| BiLSTM | 32 × 64 × 2, Tanh | 25 × 128 |
| Reshape | 25 × 128–1 × 3200 | 1 × 3200 |
| FC1 | 3200 × 256 | 1 × 256 |
| FC2 | 256 × 10, Softmax | 1 × 10 |
| Bearing Type | Pitch Diameter | Ball Diameter | Number of Balls | Speed | Load |
|---|---|---|---|---|---|
| 6205-2RS JEM SKF | 39.04 mm | 7.94 mm | 9 | 1750 rpm | 2 hp |
| Sample Class | Damage Diameter (Inches) | Sample Length | Training Set | Testing Set | Label | |
|---|---|---|---|---|---|---|
| Majority | Normal | — | 2048 | 100 | 100 | 0 |
| Majority | Ball1 | B0.007 | 2048 | 10 | 100 | 1 |
| Ball2 | B0.014 | 2048 | 10 | 100 | 2 | |
| Ball3 | B0.021 | 2048 | 10 | 100 | 3 | |
| Inner1 | I0.007 | 2048 | 10 | 100 | 4 | |
| Inner2 | I0.014 | 2048 | 10 | 100 | 5 | |
| Inner3 | I0.021 | 2048 | 10 | 100 | 6 | |
| Outer1 | O0.007 | 2048 | 10 | 100 | 7 | |
| Outer2 | O0.014 | 2048 | 10 | 100 | 8 | |
| Outer3 | O0.021 | 2048 | 10 | 100 | 9 | |
| Sample class | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| PCC | 0.8225 | 0.8702 | 0.7494 | 0.8388 | 0.9314 | 0.8125 | 0.9506 | 0.9530 | 0.7957 | 0.8990 |
| CS | 0.8378 | 0.8962 | 0.8142 | 0.8700 | 0.9481 | 0.8721 | 0.9584 | 0.9609 | 0.8463 | 0.9232 |
| Wasserstein distance | 0.0530 | 0.0530 | 0.0530 | 0.0530 | 0.0530 | 0.0530 | 0.0530 | 0.0530 | 0.0530 | 0.0530 |
| Dataset | Dataset1 | Dataset2 | Dataset3 | Dataset4 | Dataset5 | Dataset6 | Dataset7 | |
|---|---|---|---|---|---|---|---|---|
| Testing sample number of each class | Real | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| Synthetic | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Training sample number of majority class | Real | 100 | 100 | 100 | 100 | 100 | 100 | 100 |
| Synthetic | 0 | 0 | 0 | 0 | 0 | 0 | 20 | |
| Training sample number of each minority class | Real | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Synthetic | 0 | 1 | 3 | 4 | 9 | 49 | 99 | |
| Imbalance ratio (majority/minority) | 100:1 | 50:1 | 25:1 | 20:1 | 10:1 | 2:1 | 1:1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tong, Q.; Lu, F.; Feng, Z.; Wan, Q.; An, G.; Cao, J.; Guo, T. A Novel Method for Fault Diagnosis of Bearings with Small and Imbalanced Data Based on Generative Adversarial Networks. Appl. Sci. 2022, 12, 7346. https://doi.org/10.3390/app12147346
Tong Q, Lu F, Feng Z, Wan Q, An G, Cao J, Guo T. A Novel Method for Fault Diagnosis of Bearings with Small and Imbalanced Data Based on Generative Adversarial Networks. Applied Sciences. 2022; 12(14):7346. https://doi.org/10.3390/app12147346
Chicago/Turabian StyleTong, Qingbin, Feiyu Lu, Ziwei Feng, Qingzhu Wan, Guoping An, Junci Cao, and Tao Guo. 2022. "A Novel Method for Fault Diagnosis of Bearings with Small and Imbalanced Data Based on Generative Adversarial Networks" Applied Sciences 12, no. 14: 7346. https://doi.org/10.3390/app12147346
APA StyleTong, Q., Lu, F., Feng, Z., Wan, Q., An, G., Cao, J., & Guo, T. (2022). A Novel Method for Fault Diagnosis of Bearings with Small and Imbalanced Data Based on Generative Adversarial Networks. Applied Sciences, 12(14), 7346. https://doi.org/10.3390/app12147346