In our experimental studies, five datasets having various properties were tested. Furthermore, the job posting texts in these five datasets belonged to various job categories, from the most popular ones such as Accounting (Acc.), Computer Science and Engineering (CSE), and Marketing (Mar.), to the ordinary ones such as Machinery Industry (MI) and Cooking (Coo.). These popularities were determined according to the associated densities in the Kariyer.net database.
5.2. Results
While the complexity tests were measured in milliseconds for database queries and the semantic network, the response time was measured as the number of hops within the clusters for the machine Learning algorithms. This is because machine learning algorithms have a better complexity performance than other methods, and it is desirable to more accurately determine the differences between them. For accuracy tests, sum of square error (
) values—see Equation (
7)—were calculated with respect to the elements in the cluster determined to be included in the new job posting by the clustering algorithms (including the semantic network, as SOM was used). The
was calculated between the instance cluster returning from the queries, using the accuracy values for the database query methods and the current new job posting.
where
k is the number of clusters,
n is the number of data points in the
ith cluster,
is a data point in the
ith cluster, and
c is the centroid of the
ith cluster.
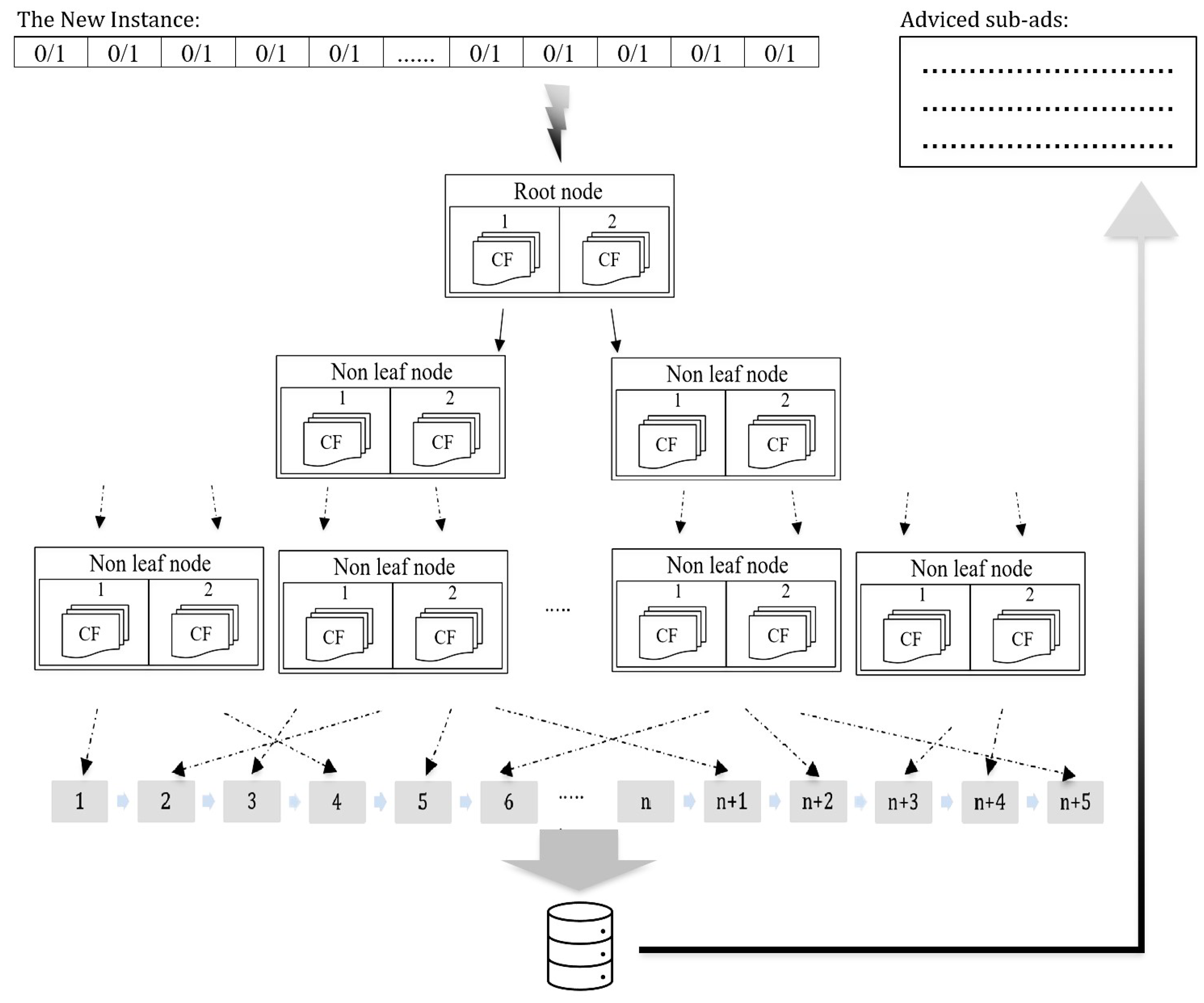
The complexities of the models were tested through two types of analyses, in terms of their running performance and the number of levels in the trees (i.e., the number of hops to reach the leaves). The number of levels in the trees is an important indicator, detailing how much effort is required to reach the data points in the leaves.
The comparison analyses were carried out using five different methods: database queries (DQ), SOM (used for semantic networking), k-Means++, BIRCH, and the proposed S-CF Tree. The S-CF Tree algorithm was diversified into cases of 2, 3, or 4 clusters in an entity, all of which were tested. In addition, the features of the server where the analyses were conducted were as follows: Intel(R) Xeon(R) CPU E5-2403 0 @ 1.80 GHz, 64 GB memory, 1 TB hard-disk capacity, and Windows Server 2012 R2 operating system. Implementations and tests were performed using the C# language in Microsoft Visual Studio 2019, the Python language in Google Colaboratory, and the R language in R Studio.
In
Table 1, the complexity analyses performed for the five different job groups are detailed, preserving all features without the FP-Growth algorithm. The complexity was assessed in terms of milliseconds (ms) by measuring the time required to find job postings close to a new job posting. As expected, the highest time was observed with DQ for all datasets, as there was no previous clustering pattern in DQ. In the other methods, the performances were proportionally distributed according to the size of the dataset.
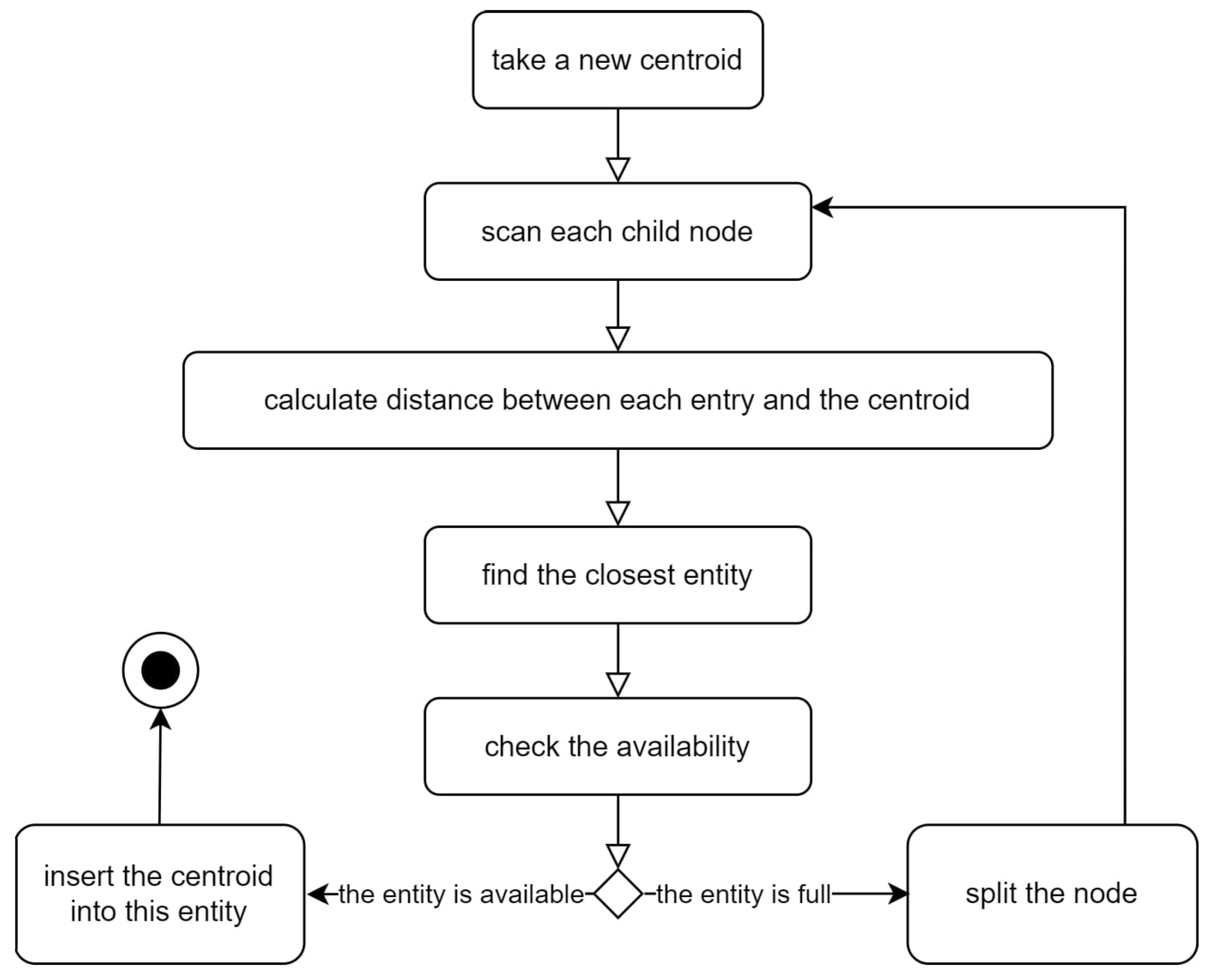
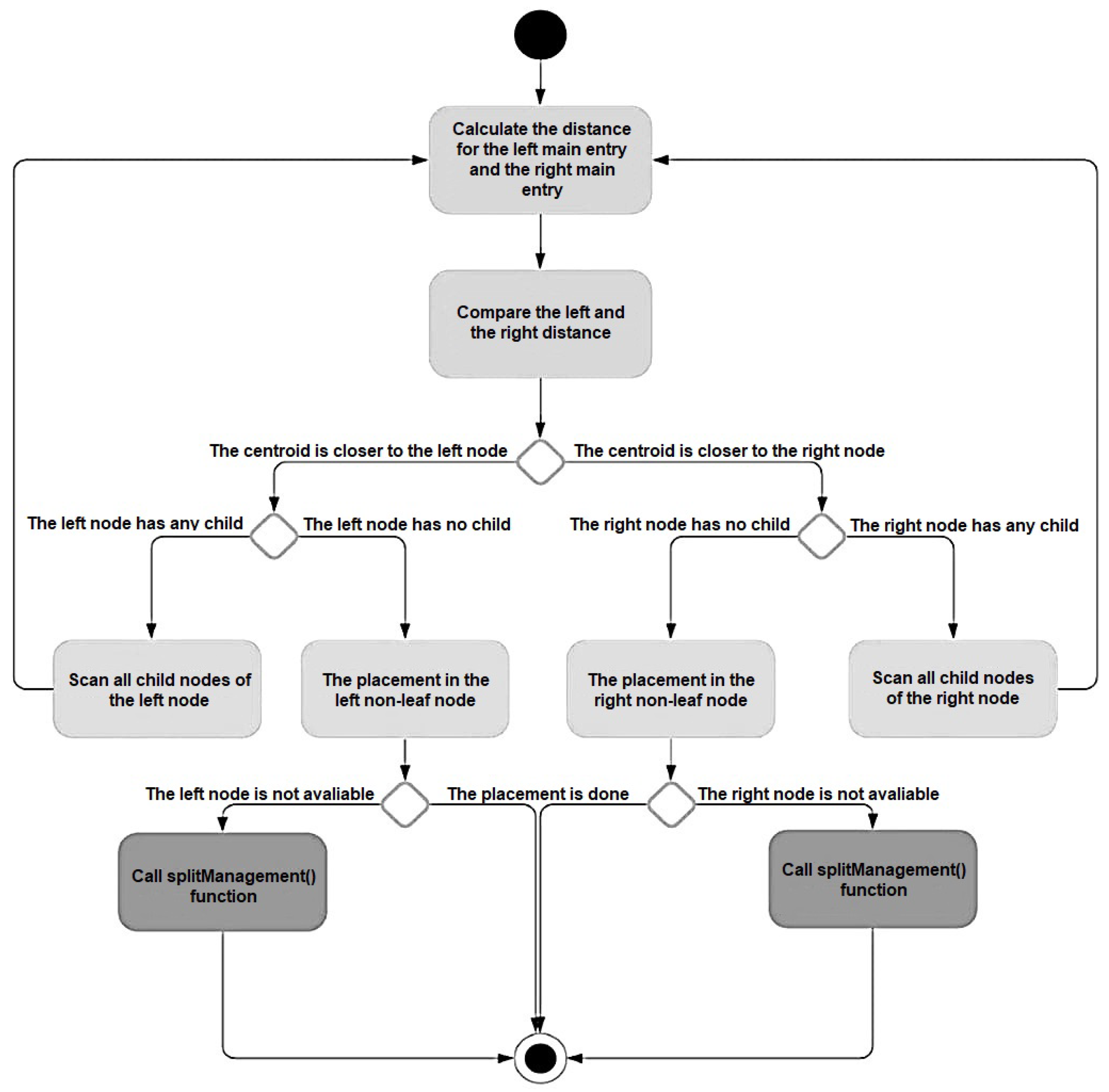
The SC-F Tree acts like a balanced search tree. When each node has two children (or, in other words, two clusters), it acts a binary search tree. When each node has three children, it acts as a ternary search tree. Therefore, it can be said that the height of the SC-F Tree becomes for the binary structure or for the ternary structure. However, while searching, it is also necessary to compare the number of clusters (k) for each node. Therefore, the time complexity of SC-F Tree Operations was O(× k).
As an important outcome, we observed that the versions of the proposed S-CF Tree algorithm presented the lowest values, and they had almost the same results, regardless of whether the number of clusters in any entity was 2, 3, or 4. The explanation for this outcome is that when the number of clusters in any entity increases, the number of levels in the tree decreases. Thus, to reach the cluster where a new job posting is located, it is necessary to compare the number of clusters in each entity from the root. No matter how low the level is to reach the leaves, there will be a performance loss, which is relative to the number of clusters, for the comparison to find the closest cluster in each entity. For example, let the total number of clusters be 16. If we create the tree in a binary structure, the number of levels will be = 4. This means that we must carry out 2 × 4 = 8 comparison operations. If we create the tree in a triple structure, the number of levels will be = 2.5237. This means that we must carry out 3 × 2.5237 = 7.5711 comparison operations. If we create the tree with a structure of 4, the number of levels will be = 2. This means the 4 × 2 = 8 comparison operations must be carried out. In other tests, it was expected that the number of clusters would not have affected the performance obtained by the S-CF Tree algorithm.
As detailed in
Table 2, complexity analyses were performed for five different job groups, again preserving all features without the FP-Growth algorithm. The analyses were performed by measuring the number of hops (for tree structures) or comparisons (for cluster patterns) required to find job postings close to a new job posting. As there was no clustering model, DQ could not be evaluated according to the number of hops. In the other methods, it was again observed that the hops were proportionally distributed according to the size of the dataset. Moreover, due to the advantageous nature of the tree structure for the search operation, the BIRCH and S-CF Tree algorithms had the lowest hop counts.
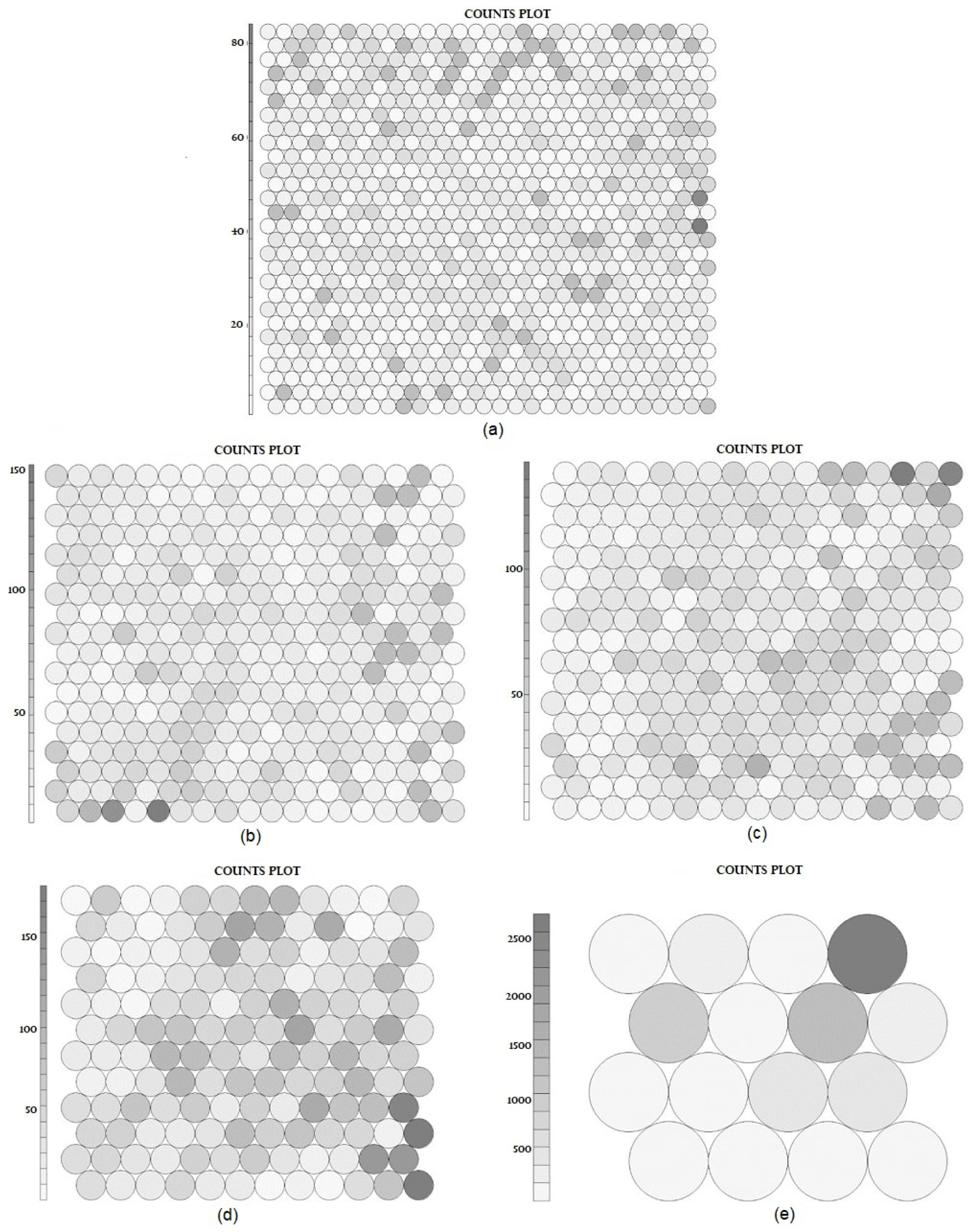
In
Figure 5, SOM patterns for all datasets are shown. The coding for this was performed using the R programming language. The outputs were obtained in hexagonal structure to supply the semantic network structure. The densities of instances in the clusters are indicated by different tones of gray. These patterns had the number of clusters set according to the optimal SSE values for all datasets. The patterns show that the counts of instances in each cluster were distributed nearly homogeneously, with only a few clusters presenting small agglomerations. This even distribution provides a smooth environment in which to search for job postings similar to a new job posting.
As shown in
Table 3, complexity analyses were performed for five different job groups, again preserving all features without the FP-Growth algorithm. The analyses were performed by measuring the accuracy according to the SSE values. For the accuracy tests of DQs, each job posting was evaluated as a new job posting, and the returned job postings were assumed to be a cluster. The count of job postings illustrated as new job postings was determined as the count of clusters in SOM and
k-Means++ patterns; furthermore, they were selected randomly. Cross-validation was used for the measurements; thus, each job posting could be evaluated. This approach was repeated until the count of clusters in the SOM and
k-Means++ patterns had been obtained separately for each dataset. Finally, cluster patterns were obtained, as in the clustering algorithms, and these approaches could be compared with the clustering algorithms. The SSE values were calculated according to the centroids of all clusters. For the first outcome in the table, it was observed that the SSE values of DQs were the highest. The reason for this is that there was not any categorization operation for the queries associating irrelevant job postings to the new job postings. For the second outcome, the SOM,
k-Means++, and BIRCH algorithms presented almost the same patterns, with lower SSE values for each dataset. For the last outcome, all versions of the proposed S-CF Tree had the lowest SSE values for each dataset.
As the BIRCH algorithm is also a tree algorithm, it was expected to have values close to those of the S-CF Tree algorithm. However, the SSE values of the BIRCH algorithm were almost twice as high. This is because the BIRCH algorithm forces its tree to be created as a balanced tree. Although the BIRCH algorithm is a very efficient algorithm, in terms of search pattern, it obtained patterns close to those of standard clustering algorithms in our study focused on capturing similar job postings.
In
Table 4 and
Table 5, the complexity analyses for the five different job groups are detailed, where we selected all features using the FP-Growth algorithm.
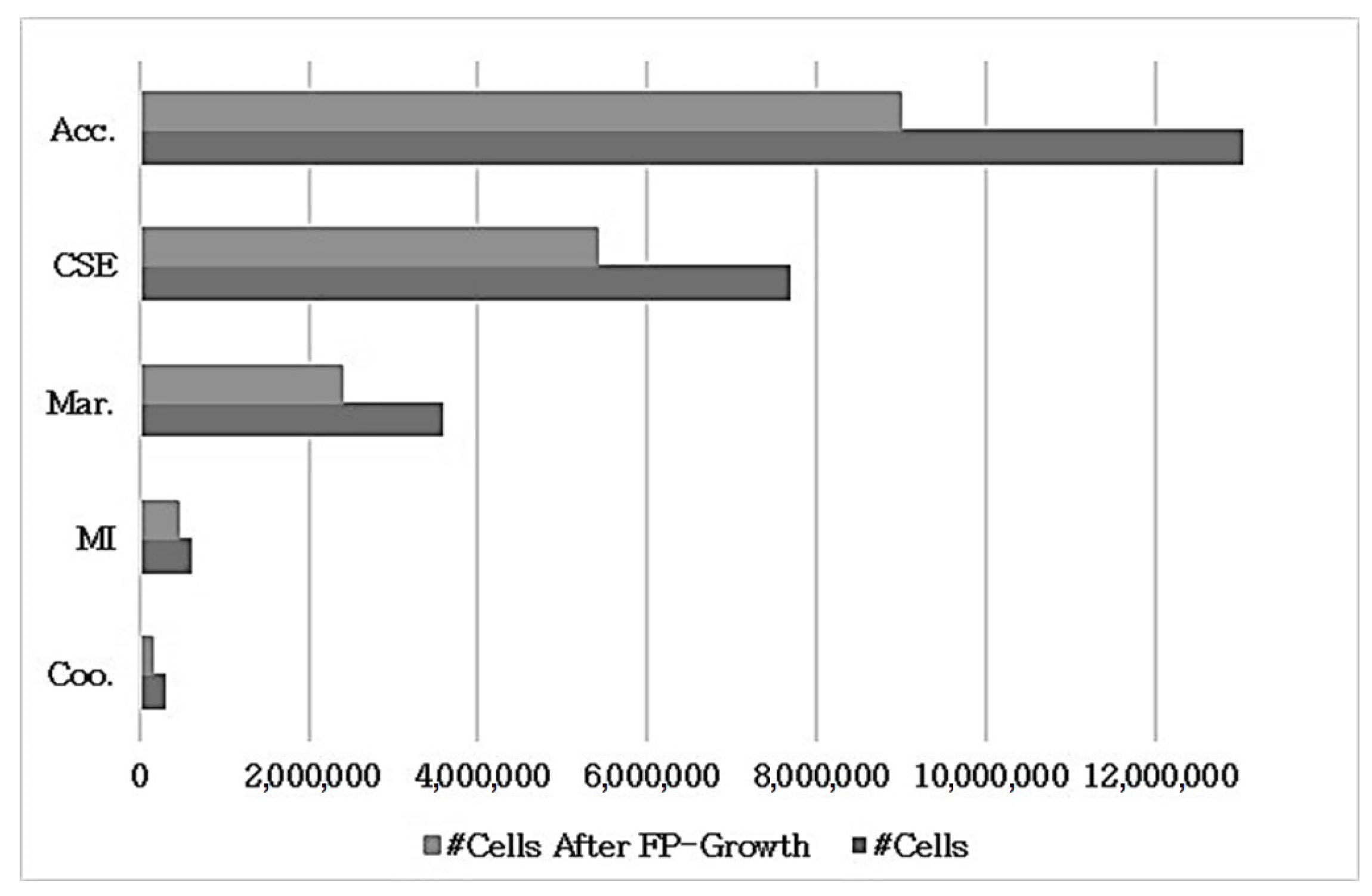
The first outcome of this analysis is that due to the dimensionality reduction operations, noticeable increases in performance were observed for all datasets. As the second outcome, the best performances in terms of both time and number of hops were observed for algorithms using a tree data structure. However, in all versions of the proposed S-CF Tree algorithm, better performances were achieved in terms of time compared to the BIRCH algorithm. Finally, for all datasets, it was found that the variety of the number of clusters in any entity in the S-CF Tree did not have an effect on the hop counts and time.
In
Table 6, the complexity analyses performed for five different job groups are detailed, again eliminating some features with the FP-Growth algorithm. The analyses were performed by measuring the accuracy according to the SSE values. The accuracy values of DQs were obtained similar to those in
Table 3. The values in
Table 6 show that the SSE values slightly increased as some significant features had been eliminated by FP-Growth. It can be observed that the SSE values of the S-CF Tree versions increased, which presented the highest accuracy values by between 6% and 7%.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}