
SRP: A Microscopic Look at the Composition Mechanism of Website Fingerprinting

Abstract
:1. Introduction
- We proposed a new concept called send-and-receive pair (SRP), which provides a microscopic perspective for us to study website traffic.
- We demonstrated that website traffic could be bionic by reorganizing SRPs generated by web page loading. Furthermore, we proposed a bionic trace generation method based on the browser working mechanism and network state fluctuation simulation.
- We further investigate the concept drift problem of website traffic in closed-world and open-world scenarios. We reveal that bionic traces and SRP-based cumulative features can help mitigate the effects of concept drift.
- Expensive experiments show that bionic traces we generated can significantly alleviate the data hunger problem of deep learning-based WF attacks. It can achieve a nontrivial increase in performance when incorporating the state-of-the-art deep learning model.
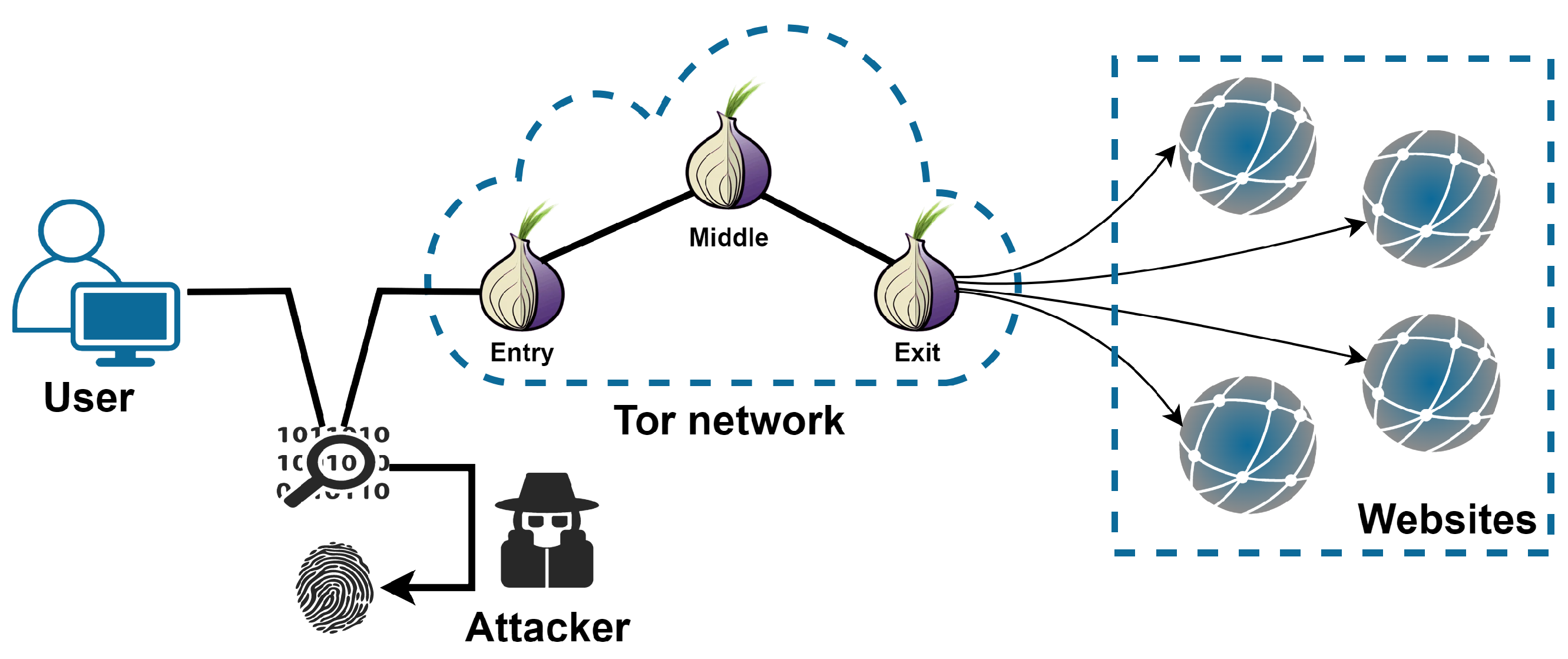
2. Threat Model
- Closed-world scenario. The closed-world scenario assumes that the user only visits a fixed collection of K websites, which is monitored by the attacker. We assume a weak attacker could only gather N instances for each monitored website. The attacker trains his classifier with the training instances and the test instances belong to one of the K monitored websites. Despite many criticisms for being unrealistic, this scenario is widely used to evaluate the basic classification performance of WF attacks in previous studies.
- Open-world scenario. The open-world scenario is a realistic but challenging setting. It considers that users may visit a large number of websites that the attacker may not be interested in, to be called unmonitored websites. The attack gathers instances for the unmonitored websites to join with the monitored instances as the training set. In reality, the number of unmonitored websites is over the capability of an attacker can monitor. Therefore, the unmonitored instances in the test set would be from other never-seen websites. The attacker must identify whether an instance belongs to the unmonitored or monitored set. If it belongs to the latter, the attacker should further figure out which is a monitored website.
3. Related Work
4. Methodology
4.1. Data Representation
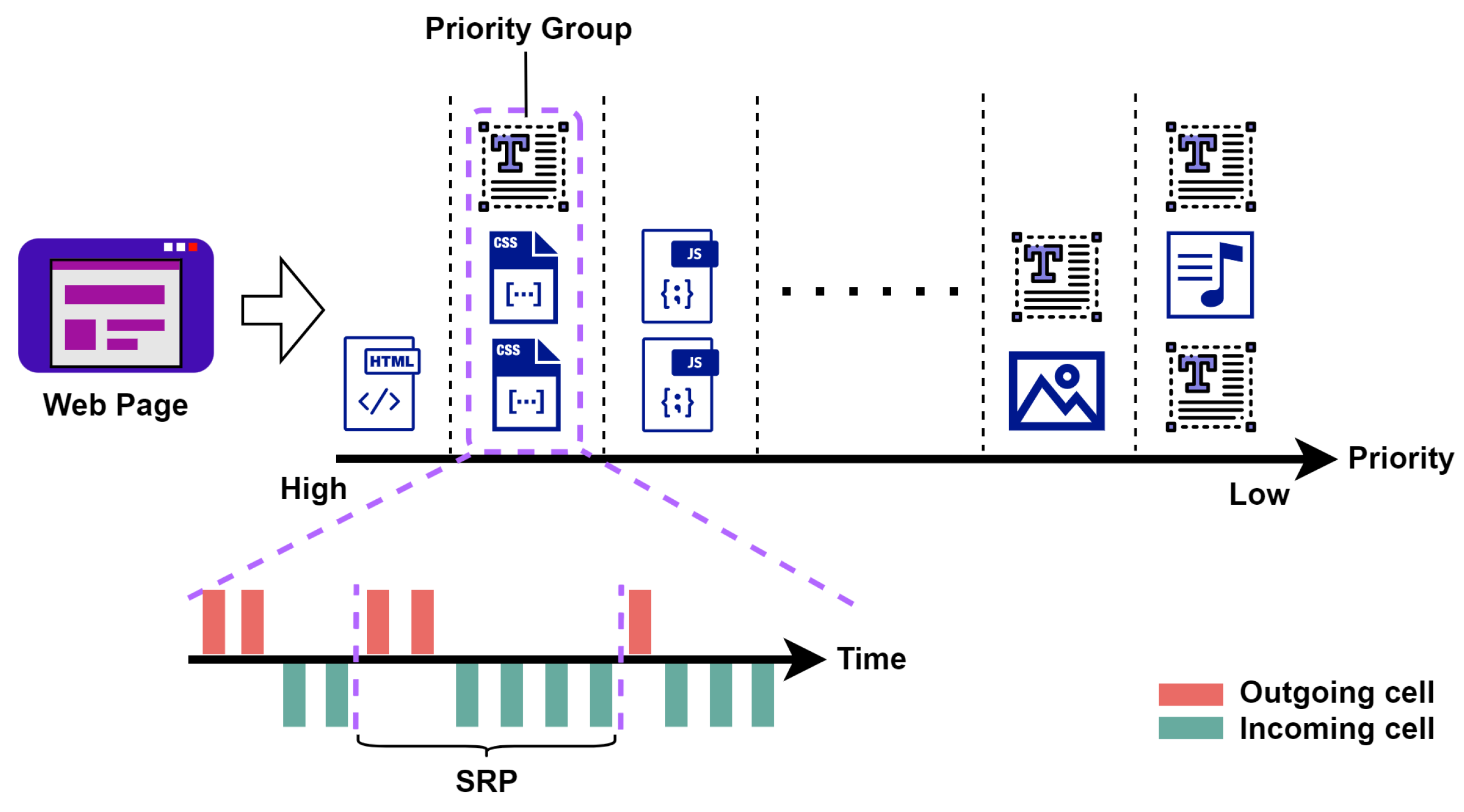
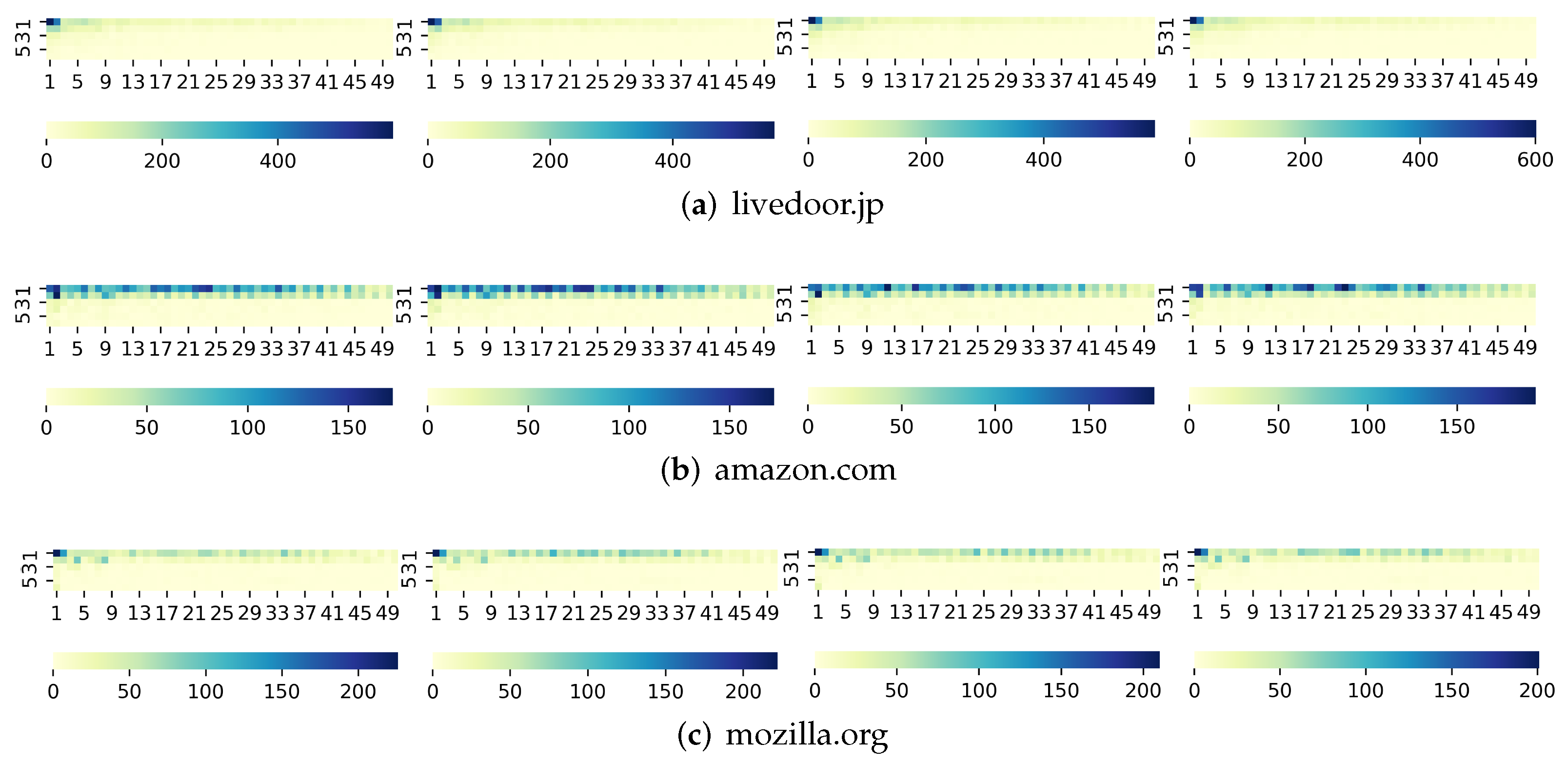
4.2. A Microscopic Look
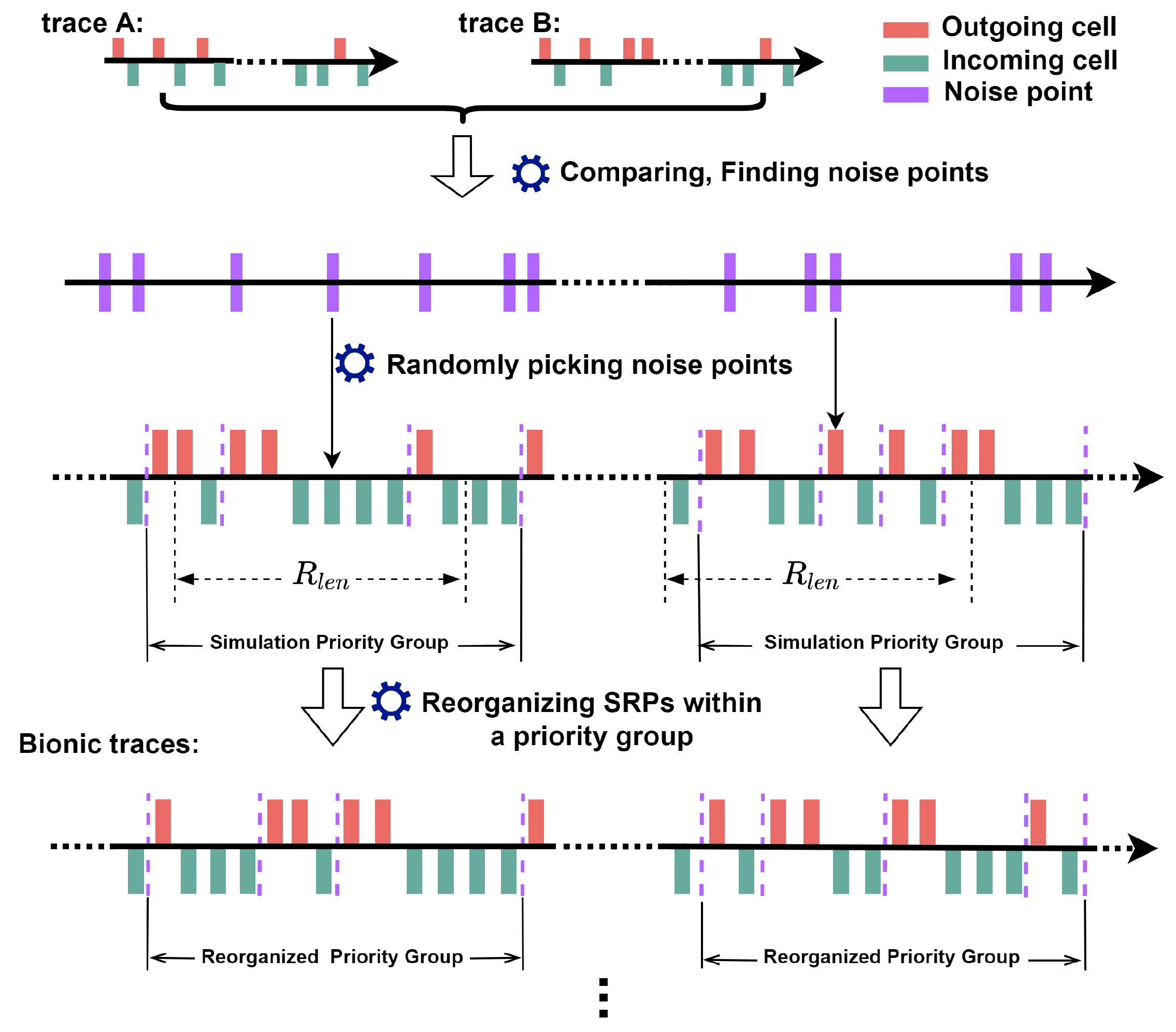
4.3. Bionic Traffic Generation
| Algorithm 1 Search and reorganize simulation priority group. |
|
| Algorithm 2 Bionic traffic generation. |
Input: Traffic trace , Traffic trace Output: Bionic traffic trace
|
4.4. SRP-Based Cumulative Feature
4.5. Base Model
5. Experiment
5.1. Dataset
- [5]: This dataset is the largest WF dataset collected in 2017 with Tor browser 6.5, We use three subsets in our study:
- -
- . The set consists of the top 100 Alexa websites, with 2500 instances each.
- -
- . The set consists of the other 775 websites, with 2500 traffic traces each.
- -
- . The set consists of the top 400,000 Alexa websites, with one instance each.
- -
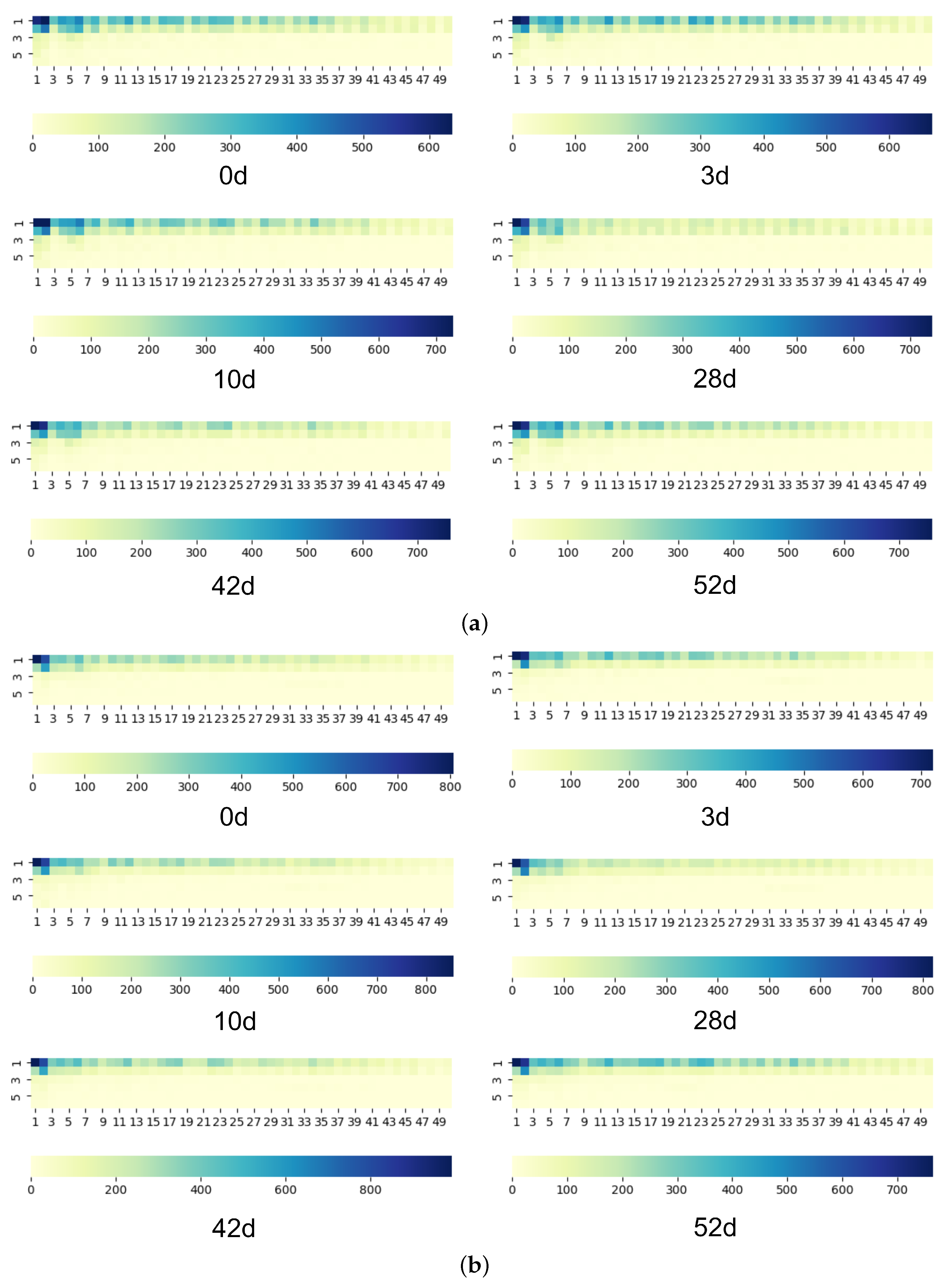
- . The set consists of the top 200 Alexa websites, with 500 traffic traces each. 100 instances of these 200 sites were gathered at each point in time over a two-month period: 3 days, 10 days, 28 days, 42 days, and 56 days after the end of the initial data collection.
- [3]: This dataset was collected by using Tor Browser 3.5.1 in 2013, which contains 100 monitored websites. Each website has 90 instances available.
5.2. Metric
5.3. Hyperparameter Tuning
5.3.1. Experimental Setting
5.3.2. Results
5.4. Closed-World Evaluation
5.4.1. Experimental Setting
5.4.2. Results
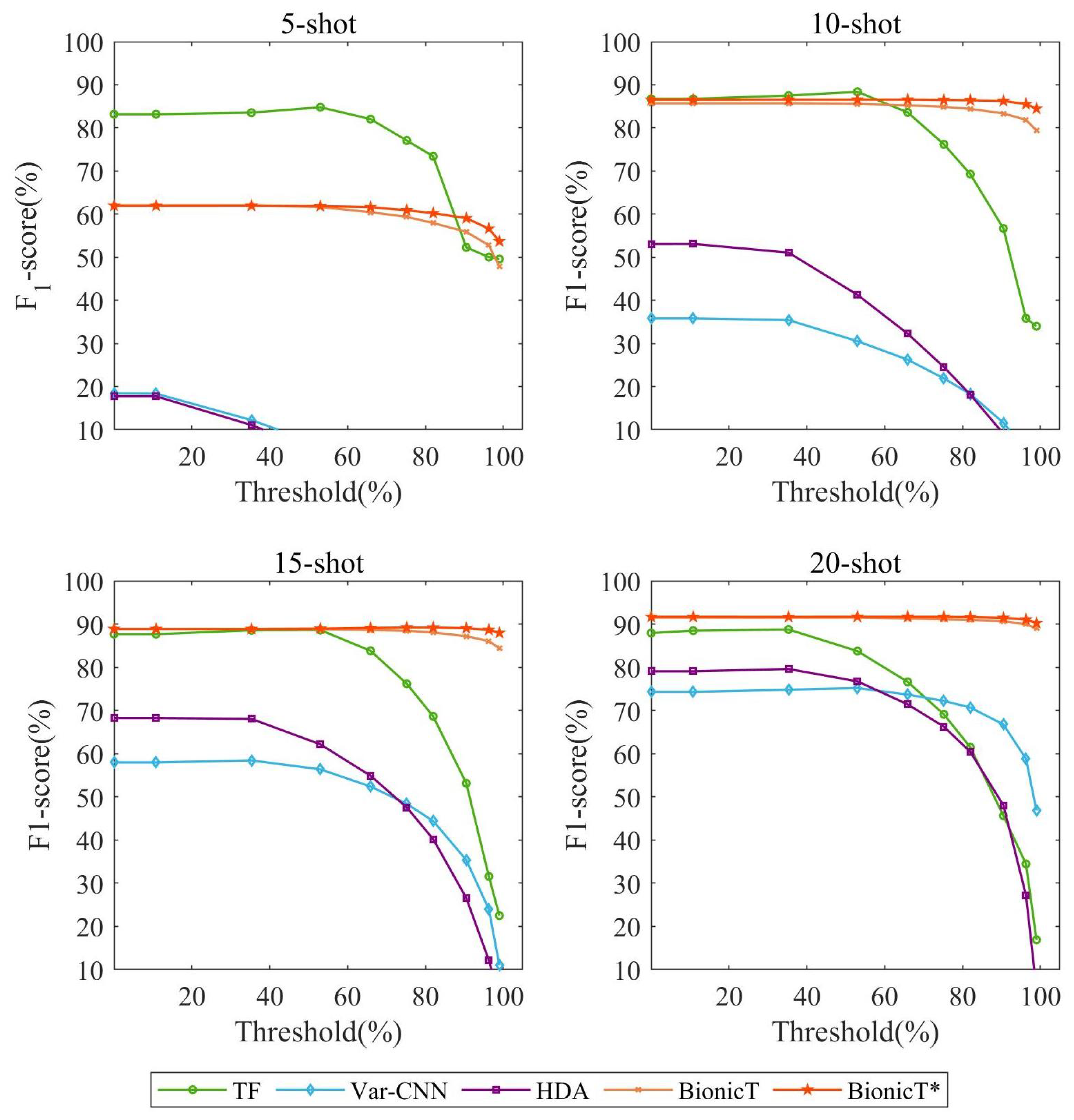
5.5. Open-World Evaluation
5.5.1. Experimental Setting
5.5.2. Results
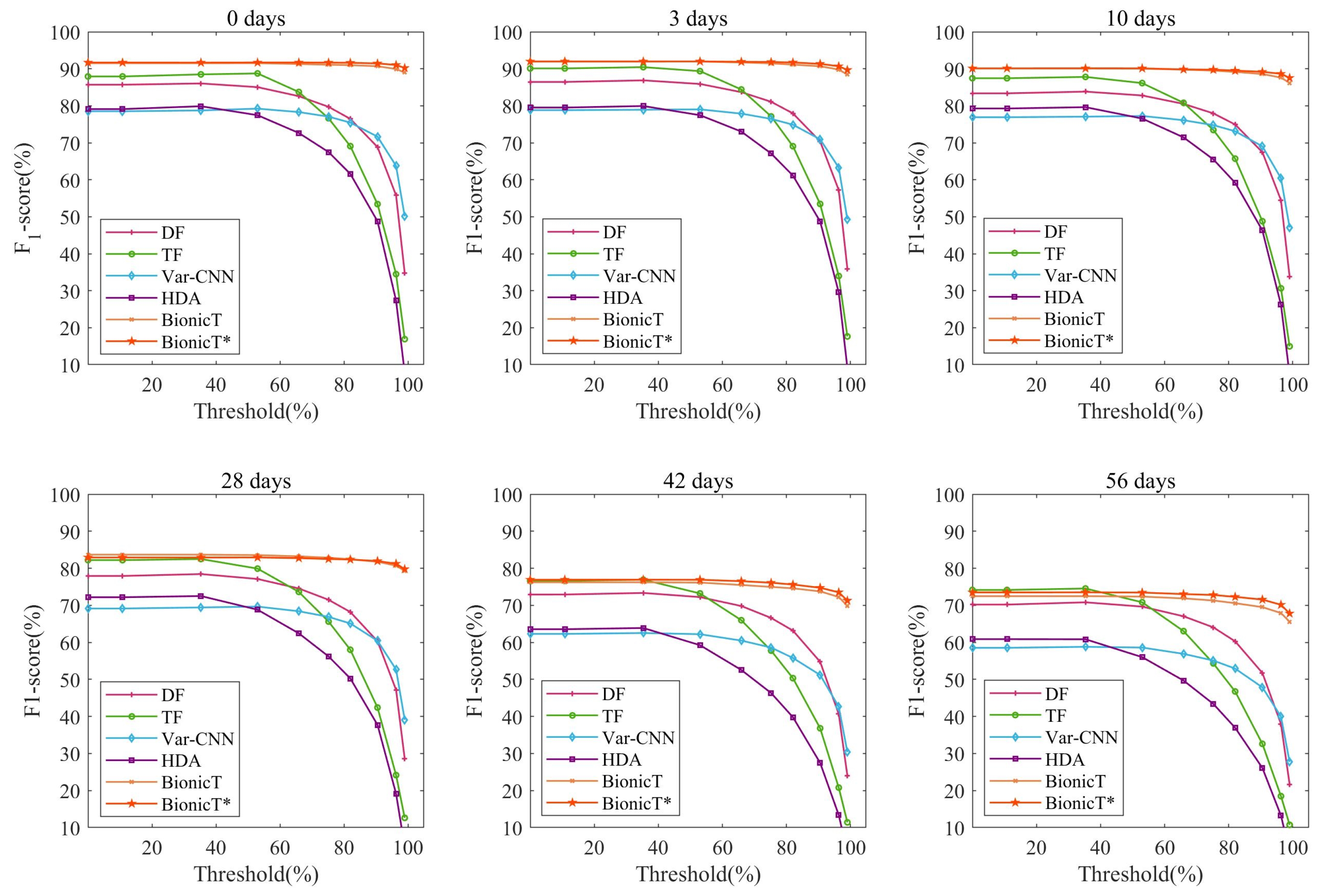
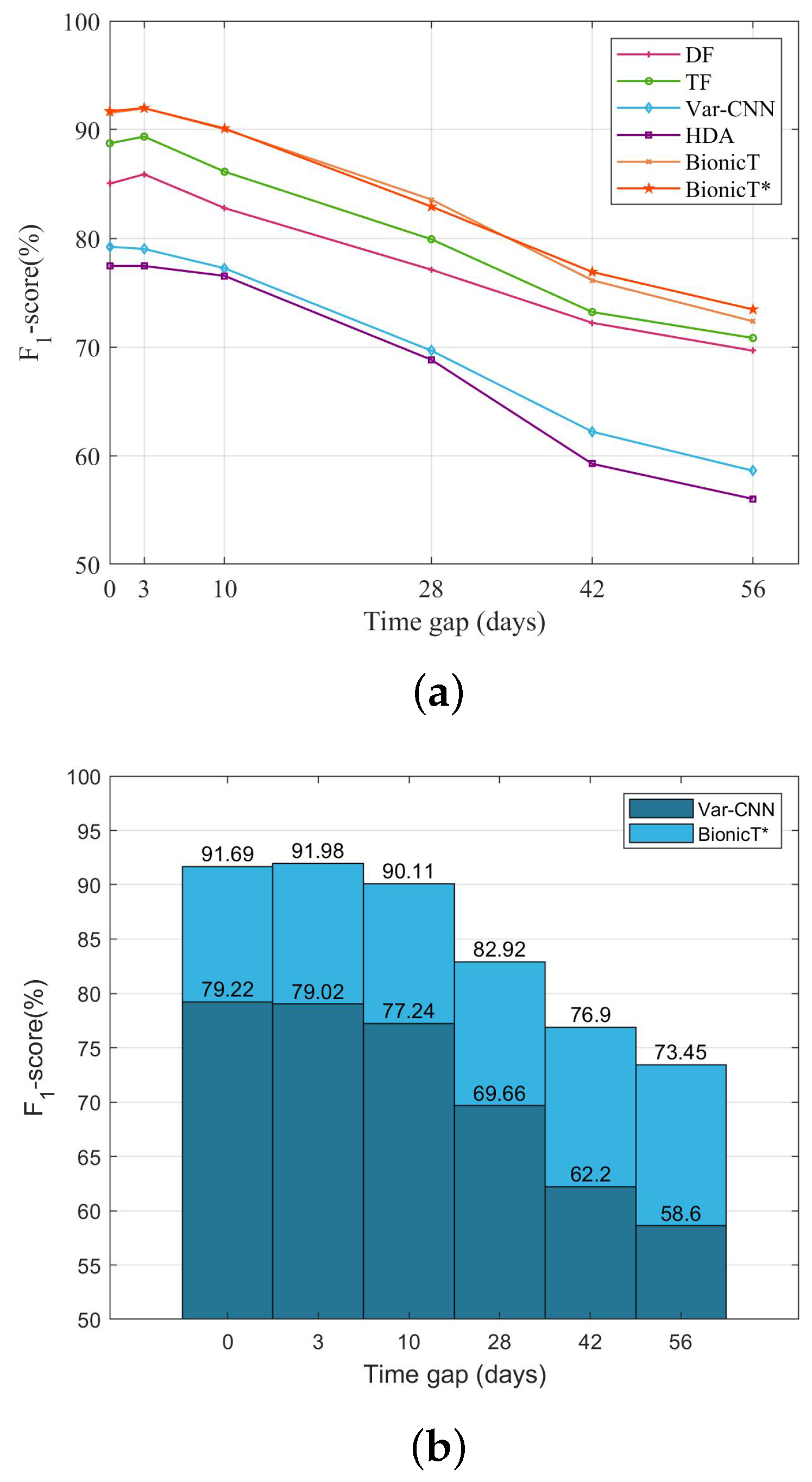
5.6. Evaluation on Concept Drift
5.6.1. Experimental Setting
5.6.2. Results
5.7. Closed-World Evaluation on the Defended Dataset
5.7.1. Experimental Setting
5.7.2. Results
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Panchenko, A.; Niessen, L.; Zinnen, A.; Engel, T. Website fingerprinting in onion routing based anonymization networks. In Proceedings of the WPES’11: Proceedings of the 10th Annual ACM Workshop on Privacy in the Electronic Society, Chicago, IL, USA, 17 October 2011; pp. 103–114. [Google Scholar]
- Cai, X.; Zhang, C.X.; Joshi, B.; Johnson, R. Touching from a distance: Website fingerprinting attacks and defenses. In Proceedings of the CCS’12: Proceedings of the 2012 ACM Conference on Computer and Communications Securit, Los Angeles, CA, USA, 16–18 October 2012. [Google Scholar]
- Wang, T.; Cai, X.; Nithyanand, R.; Johnson, R.; Goldberg, I. Effective attacks and provable defenses for website fingerprinting. In Proceedings of the 23rd USENIX Security Symposium, San Diego, CA, USA, 20–22 August 2014; pp. 143–157. [Google Scholar]
- Hayes, J.; Danezis, G. k-fingerprinting: A Robust Scalable Website Fingerprinting Technique. In Proceedings of the 25th USENIX Security Symposium (USENIX Security 16), Austin, TX, USA, 10–12 August 2016. [Google Scholar]
- Rimmer, V.; Preuveneers, D.; Juárez, M.; Goethem, v.T.; Joosen, W. Automated Website Fingerprinting through Deep Learning. In Proceedings of the 25th Symposium on Network and Distributed System Security (NDSS 2018), San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- Cai, X.; Nithyanand, R.; Wang, T.; Johnson, R.; Goldberg, I. A Systematic Approach to Developing and Evaluating Website Fingerprinting Defenses. In Proceedings of the 2014 ACM Conference on Computer and Communications Security, Scottsdale AZ, USA, 3–7 November 2014; pp. 227–238. [Google Scholar]
- Juárez, M.; Imani, M.; Perry, M.; Díaz, C.; Wright, M. Toward An Efficient Website Fingerprinting Defense. In Proceedings of the Computer Security—ESORICS 2016, Heraklion, Greece, 28–30 September 2016; pp. 27–46. [Google Scholar]
- Cherubin, G.; Hayes, J.; Juárez, M. Website Fingerprinting Defenses at the Application Layer. PoPETs 2017, 2017, 186–203. [Google Scholar] [CrossRef] [Green Version]
- Oh, E.S.; Sunkam, S.; Hopper, N. p1-FP: Extraction, Classification, and Prediction of Website Fingerprints with Deep Learning. In Proceedings of the Privacy Enhancing Technologies, Minneapolis, MN, USA, 18–21 July 2017. [Google Scholar]
- Bhat, S.; Lu, D.; Kwon, A.; Devadas, S. Var-CNN: A Data-Efficient Website Fingerprinting Attack Based on Deep Learning. PoPETs 2019, 4, 292–310. [Google Scholar] [CrossRef] [Green Version]
- Sirinam, P.; Mathews, N.; Rahman, S.M.; Wright, M. Triplet Fingerprinting: More Practical and Portable Website Fingerprinting with N-shot Learning. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; pp. 1131–1148. [Google Scholar]
- Chen, M.; Wang, Y.; Xu, H.; Zhu, X. Few-shot website fingerprinting attack. Comput. Networks 2021, 198, 108298. [Google Scholar] [CrossRef]
- Chen, M.; Wang, Y.; Zhu, X. Few-shot Website Fingerprinting Attack with Meta-Bias Learning. Pattern Recognit. 2022, 130, 108739. [Google Scholar] [CrossRef]
- Chen, M.; Wang, Y.; Qin, Z.; Zhu, X. Few-Shot Website Fingerprinting Attack with Data Augmentation. Secur. Commun. Netw. 2021, 2021, 2840289. [Google Scholar] [CrossRef]
- Wagner, D.; Schneier, B. Analysis of the SSL 3.0 protocol. In Proceedings of the WOEC’96 Proceedings of the 2nd conference on Proceedings of the Second USENIX Workshop on Electronic Commerce, Oakland, CA, USA, 18–21 November 1996; Volume 2, p. 4. [Google Scholar]
- Sun, Q.; Simon, R.D.; Wang, Y.M.; Russell, W.; Padmanabhan, N.V.; Qiu, L. Statistical Identification of Encrypted Web Browsing Traffic. In Proceedings of the IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 12–15 May 2002; p. 19. [Google Scholar]
- Hintz, A. Fingerprinting websites using traffic analysis. In Privacy Enhancing Technologies; Springer: Berlin/Heidelberg, Germany, 2002; pp. 171–178. [Google Scholar]
- Liberatore, M.; Levine, N.B. Inferring the source of encrypted HTTP connections. In Proceedings of the ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 30 October–3 November 2006; pp. 255–263. [Google Scholar]
- Bissias, D.G.; Liberatore, M.; Jensen, D.; Levine, N.B. Privacy vulnerabilities in encrypted HTTP streams. In Privacy Enhancing Technologies; Springer: Berlin/Heidelberg, Germany, 2005; pp. 1–11. [Google Scholar]
- Lu, L.; Chang, E.C.; Chan, M.C. Website fingerprinting and identification using ordered feature sequences. In Proceedings of the European Symposium on Research in Computer Security, Athens, Greece, 20–22 September 2010. [Google Scholar]
- Herrmann, D.; Wendolsky, R.; Federrath, H. Website fingerprinting: Attacking popular privacy enhancing technologies with the multinomial naïve-bayes classifier. In Proceedings of the CCSW, Chicago, IL, USA, 13 November 2009; pp. 31–42. [Google Scholar]
- Panchenko, A.; Lanze, F.; Pennekamp, J.; Engel, T.; Zinnen, A.; Henze, M.; Wehrle, K. Website Fingerprinting at Internet Scale. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 21–24 February 2016. [Google Scholar]
- Abe, K.; Goto, S. Fingerprinting attack on tor anonymity using deep learning. In Proceedings of the Asia-Pacific Advanced Network, Pasay City, Philippines, 25–29 January 2016. [Google Scholar]
- Sirinam, P.; Imani, M.; Juárez, M.; Wright, M. Deep Fingerprinting: Undermining Website Fingerprinting Defenses with Deep Learning. In Proceedings of the ACM Conference on Computer and Communications Security, Toronto, Canada, 15–19 October 2018; pp. 1928–1943. [Google Scholar]
- Juárez, M.; Afroz, S.; Acar, G.; Díaz, C.; Greenstadt, R. A Critical Evaluation of Website Fingerprinting Attacks. In Proceedings of the ACM Conference on Computer and Communications Security, Scottsdale, AZ, USA, 3–7 November 2014; pp. 263–274. [Google Scholar]
- Wang, T.; Goldberg, I. Improved website fingerprinting on Tor. In Proceedings of the 12th ACM Workshop on Workshop on Privacy in the Electronic Society, Berlin, Germany, 4 November 2013; pp. 201–212. [Google Scholar]
- Rahman, S.M.; Sirinam, P.; Matthews, N.; Gangadhara, G.K.; Wright, M. Tik-Tok: The Utility of Packet Timing in Website Fingerprinting Attacks. Cryptography and Security. arXiv 2019, arXiv:1902.06421,. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning For Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 May 2016; pp. 770–778. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 10% | 20% | 30% | 40% | 50% | 60% | 70% | 80% | 90% | 100% | |
| Var-CNN + BionicT | 93.273 | 92.885 | 93.507 | 94.042 | 93.621 | 93.831 | 93.464 | 93.803 | 93.6 | 93.389 |
| 6 | 8 | 10 | 12 | 14 | 16 | |
| Var-CNN + BionicT | 92.831 | 93.468 | 93.434 | 94.251 | 93.728 | 93.838 |
| Method | 5-Shot | 10-Shot | 15-Shot | 20-Shot |
|---|---|---|---|---|
| CUMUL [22] | 72.2 ± 1.7 | 79.7 ± 1.4 | 83.3 ± 2.0 | 85.9 ± 0.6 |
| k-FP [4] | 79.3 ± 1.0 | 83.9 ± 1.0 | 85.9 ± 0.6 | 87.5 ± 0.8 |
| DF [24] | 3.2 ± 0.6 | 66.4 ± 5.3 | 89.3 ± 1.3 | 90.3 ± 2.4 |
| TF [11] | 92.2 ± 0.6 | 93.9 ± 0.2 | 94.4 ± 0.3 | 94.5 ± 0.2 |
| Var-CNN [10] | 24.6 ± 3.0 | 61.9 ± 4.3 | 79.3 ± 2.6 | 87.9 ± 0.7 |
| Var-CNN + HDA [14] | 59.7 ±1.5 | 74.7 ± 2.6 | 86.4 ± 1.3 | 90.7 ± 0.8 |
| Var-CNN + BionicT | 76.3 ± 2.4 | 92.5 ± 0.3 | 95.1 ± 0.1 | 95.7 ± 0.2 |
| Var-CNN + BionicT * | 78.2 ± 0.6 | 93.1 ± 0.2 | 95.0 ± 0.2 | 96.1 ± 0.2 |
| Method | 5-Shot | 10-Shot | 15-Shot | 20-Shot |
|---|---|---|---|---|
| DF [24] | 1.2 ± 0.3 | 8.9 ± 3.4 | 58.6 ± 6.5 | 85.2 ± 2.3 |
| TF [11] | 84.5 ± 0.4 | 86.2 ± 0.4 | 86.6 ± 0.3 | 87.0 ± 0.3 |
| Var-CNN [10] | 37.4 ± 2.8 | 69.4 ± 1.8 | 79.9 ± 3.5 | 88.1 ± 0.2 |
| Var-CNN + HDA [14] | 76.9 ± 2.4 | 87.1 ± 0.6 | 89.8 ± 0.4 | 90.6 ± 0.4 |
| Var-CNN + BionicT | 78.8 ± 0.3 | 87.9 ± 0.7 | 90.2 ± 0.2 | 91.3 ± 0.1 |
| Var-CNN + BionicT * | 79.3 ± 0.3 | 88.1 ± 0.2 | 90.2 ± 0.3 | 91.0 ± 0.3 |
| Method | 0-Day | 3-Days | 10-Days | 28-Days | 42-Days | 56-Days |
|---|---|---|---|---|---|---|
| DF [24] | 91.5 | 91.5 | 87.1 | 78.6 | 72.2 | 66.4 |
| TF [11] | 95.5 | 95.5 | 92.8 | 87.3 | 82.1 | 78.7 |
| Var-CNN [10] | 87.2 | 87.2 | 84.2 | 76.4 | 70.3 | 65.4 |
| Var-CNN + HDA [14] | 89.6 | 89.9 | 88.2 | 79.8 | 72.9 | 70.2 |
| Var-CNN + BionicT | 95.7 | 95.7 | 94.5 | 88.7 | 81.8 | 77.2 |
| Var-CNN + BionicT * | 96.3 | 96.5 | 94.7 | 88.2 | 83.1 | 78.9 |
| Method | 5-Shot | 10-Shot | 15-Shot | 20-Shot |
|---|---|---|---|---|
| DF [24] | 1.1 ± 0.1 | 8.6 ± 1.5 | 28.0 ± 6.8 | 42.5 ± 4.1 |
| TF [11] | 54.1 ± 0.7 | 57.8 ± 0.6 | 60.2 ± 0.4 | 61.2 ± 0.4 |
| Var-CNN [10] | 6.4 ± 0.4 | 7.8 ± 0.4 | 12.4 ± 0.9 | 12.9 ± 0.9 |
| Var-CNN + HDA [14] | 25.3 ± 2.2 | 46.9 ± 1.9 | 48.7 ± 1.4 | 63.2 ± 1.8 |
| Var-CNN + BionicT | 27.3 ± 1.1 | 44.2 ± 1.0 | 53.1 ± 0.5 | 59.9 ± 1.0 |
| Var-CNN + BionicT * | 20.4 ± 0.9 | 39.9 ± 1.1 | 51.9 ± 0.5 | 56.3 ± 0.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Wang, Y.; Yang, L. SRP: A Microscopic Look at the Composition Mechanism of Website Fingerprinting. Appl. Sci. 2022, 12, 7937. https://doi.org/10.3390/app12157937
Chen Y, Wang Y, Yang L. SRP: A Microscopic Look at the Composition Mechanism of Website Fingerprinting. Applied Sciences. 2022; 12(15):7937. https://doi.org/10.3390/app12157937
Chicago/Turabian StyleChen, Yongxin, Yongjun Wang, and Luming Yang. 2022. "SRP: A Microscopic Look at the Composition Mechanism of Website Fingerprinting" Applied Sciences 12, no. 15: 7937. https://doi.org/10.3390/app12157937
APA StyleChen, Y., Wang, Y., & Yang, L. (2022). SRP: A Microscopic Look at the Composition Mechanism of Website Fingerprinting. Applied Sciences, 12(15), 7937. https://doi.org/10.3390/app12157937