
Towards Machine Learning Algorithms in Predicting the Clinical Evolution of Patients Diagnosed with COVID-19


 , , ,
, , , 
Abstract
:1. Introduction
2. Background and Research
2.1. Highlights of COVID-19 Pandemic Concepts
2.2. Exposure of Healthcare Professionals to the COVID-19 Pandemic
2.3. Applying Artificial Intelligence to Pandemic Data
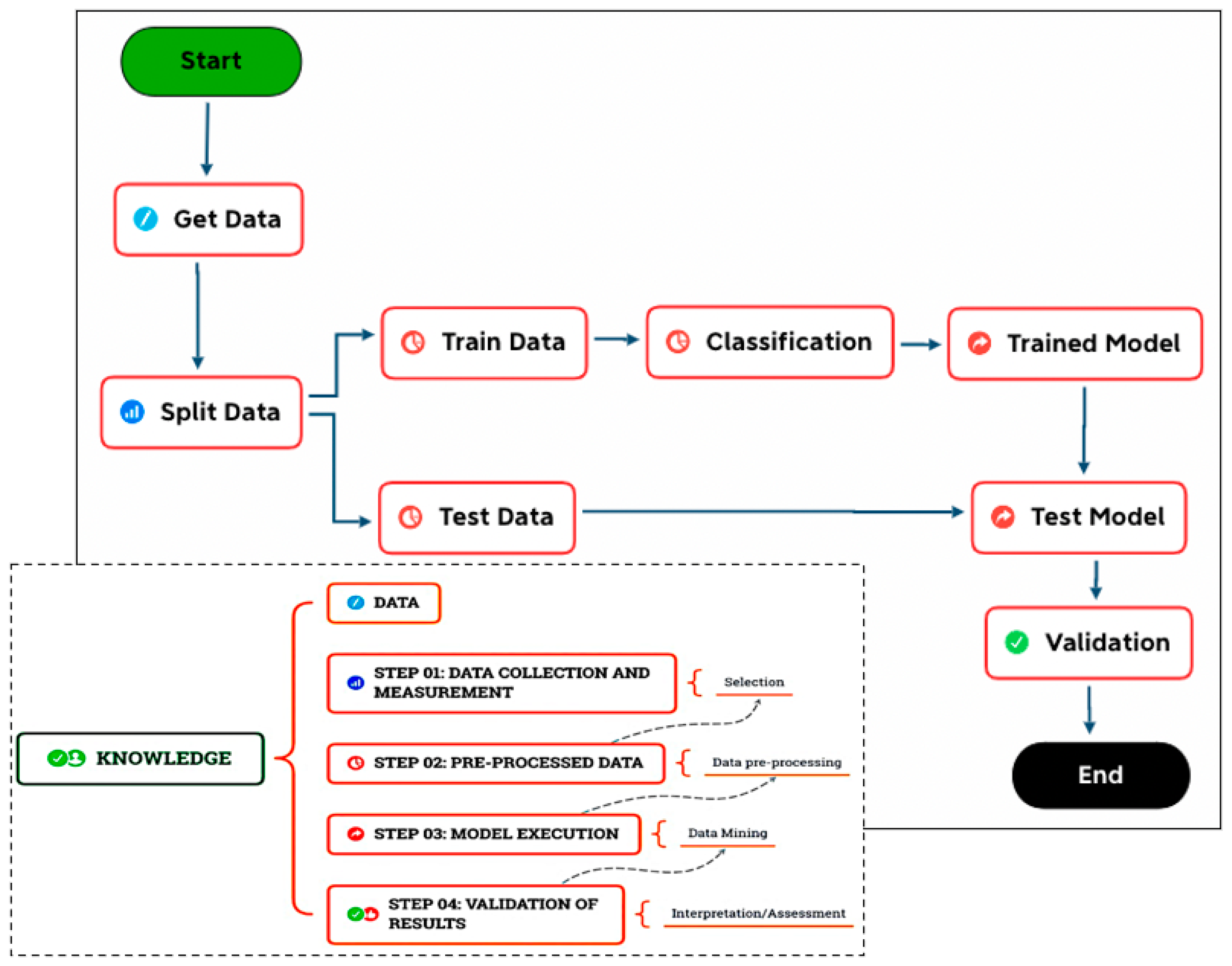
3. Methodology
- Step 01: Data collection and measurement (selection);
- Step 02: Data pre-processing;
- Step 03: Model execution (transformation/mining);
- Step 04: Validation of the results (interpretation/knowledge).
3.1. Data Collection and Measurement
3.1.1. Data Collection
3.1.2. Data Dictionary
3.1.3. Data Measurement
3.2. Data Preprocessing
3.2.1. Definition of Input Data
3.2.2. Training and Test Data
3.3. Model Execution
3.4. Validation of Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
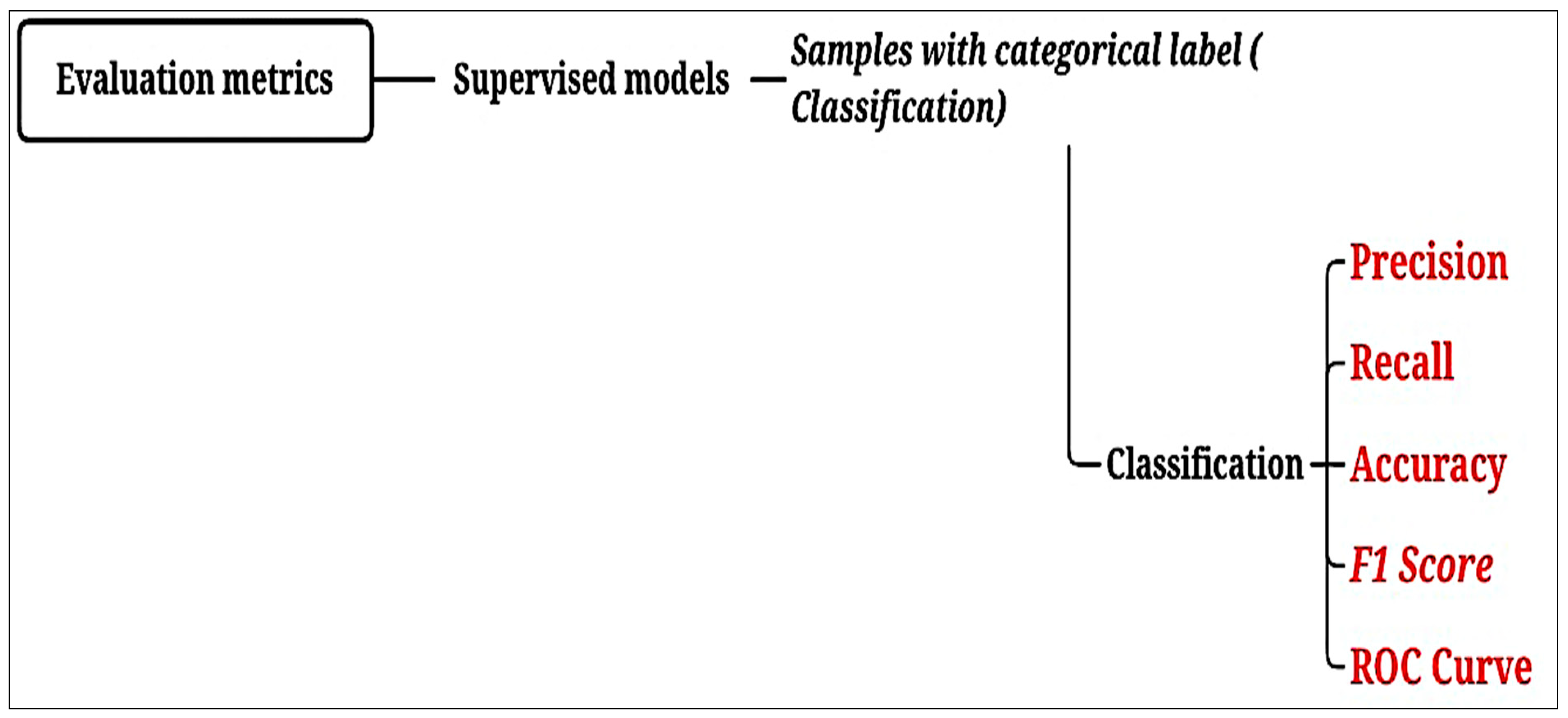
| Evaluation Metrics | |
|---|---|
| Accuracy | Defines the overall performance of the model [43]. |
| Precision | Indicates whether the model is accurate in its classifications [44]. |
| Recall | Is the number of samples classified as belonging to a class divided by the total number of samples belonging to it, even if classified in another [44]. |
| F1 score | Indicates the overall quality of the model [44]. |
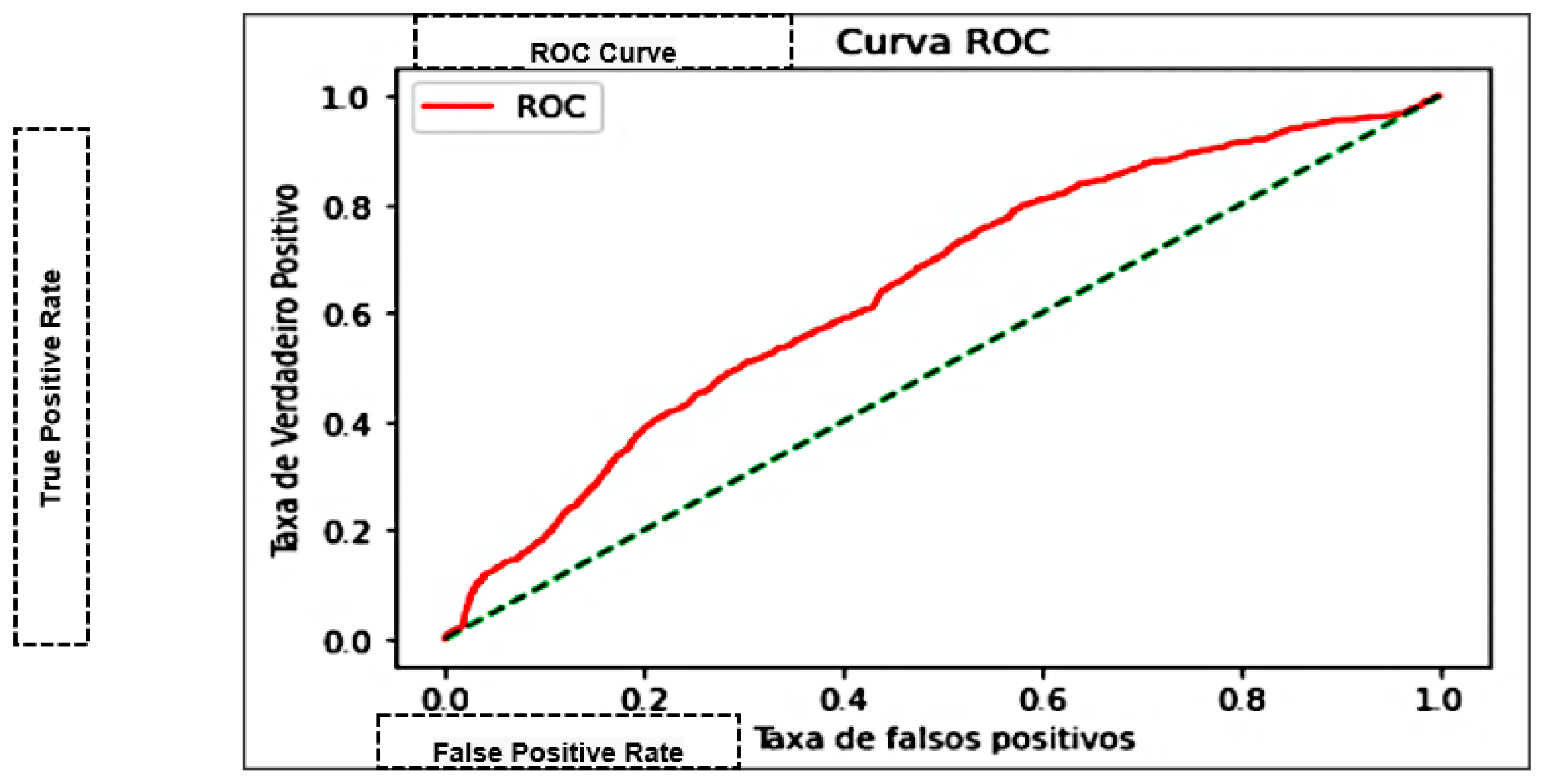
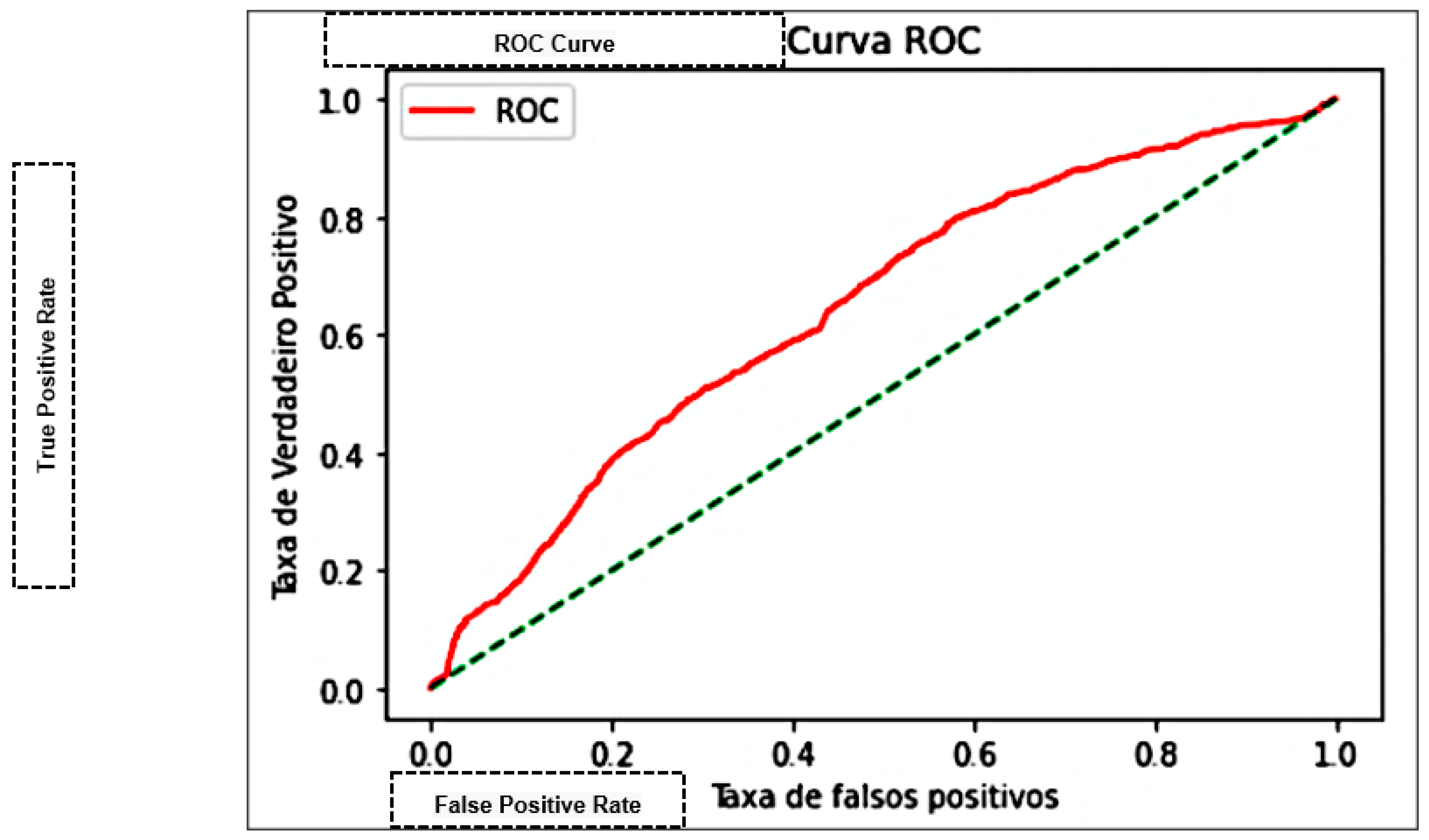
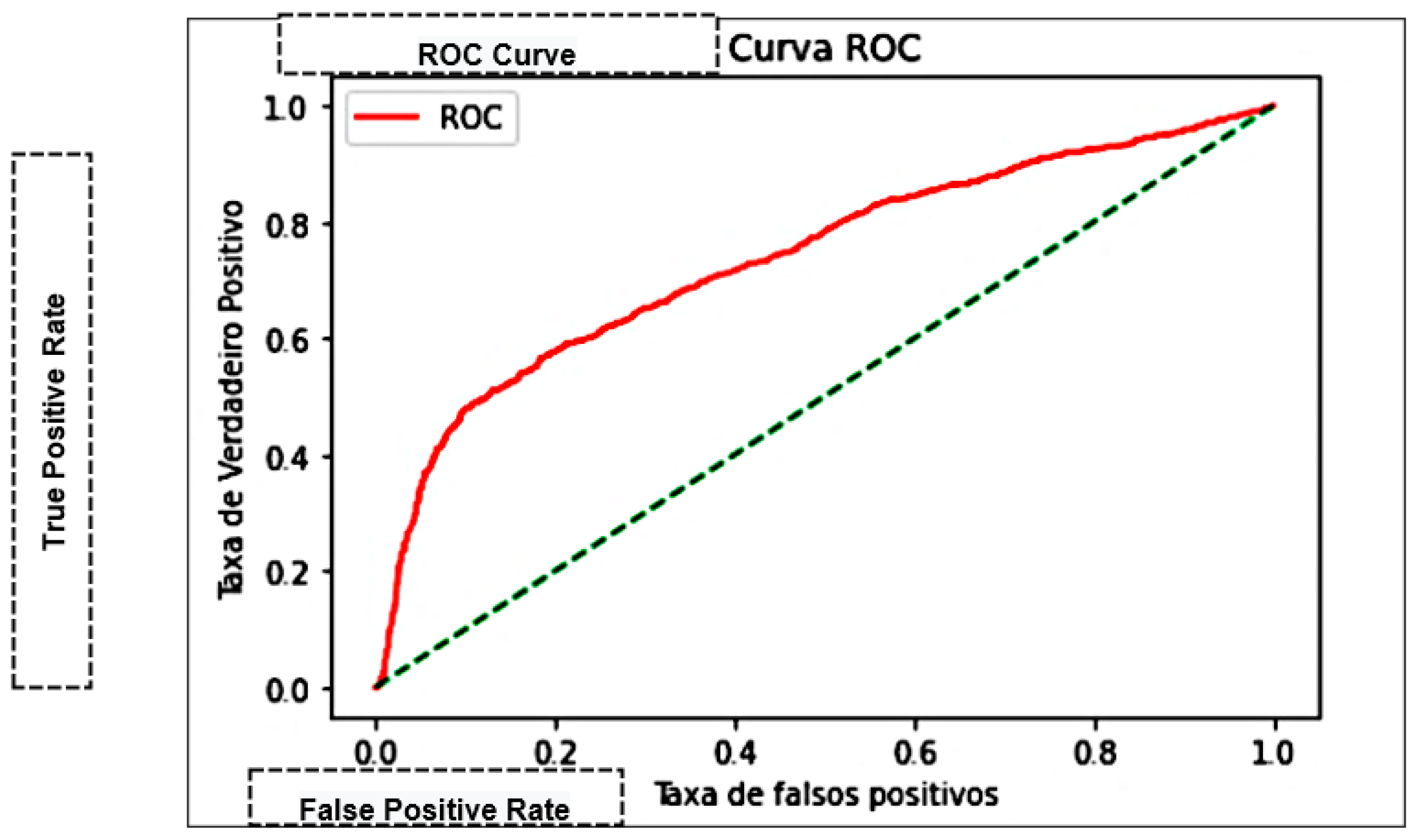
| Area Under the Curve (AUC) | Measures the area under the curve formed between the rate of positive examples and false positives [45]. |
4. Results and Discussion
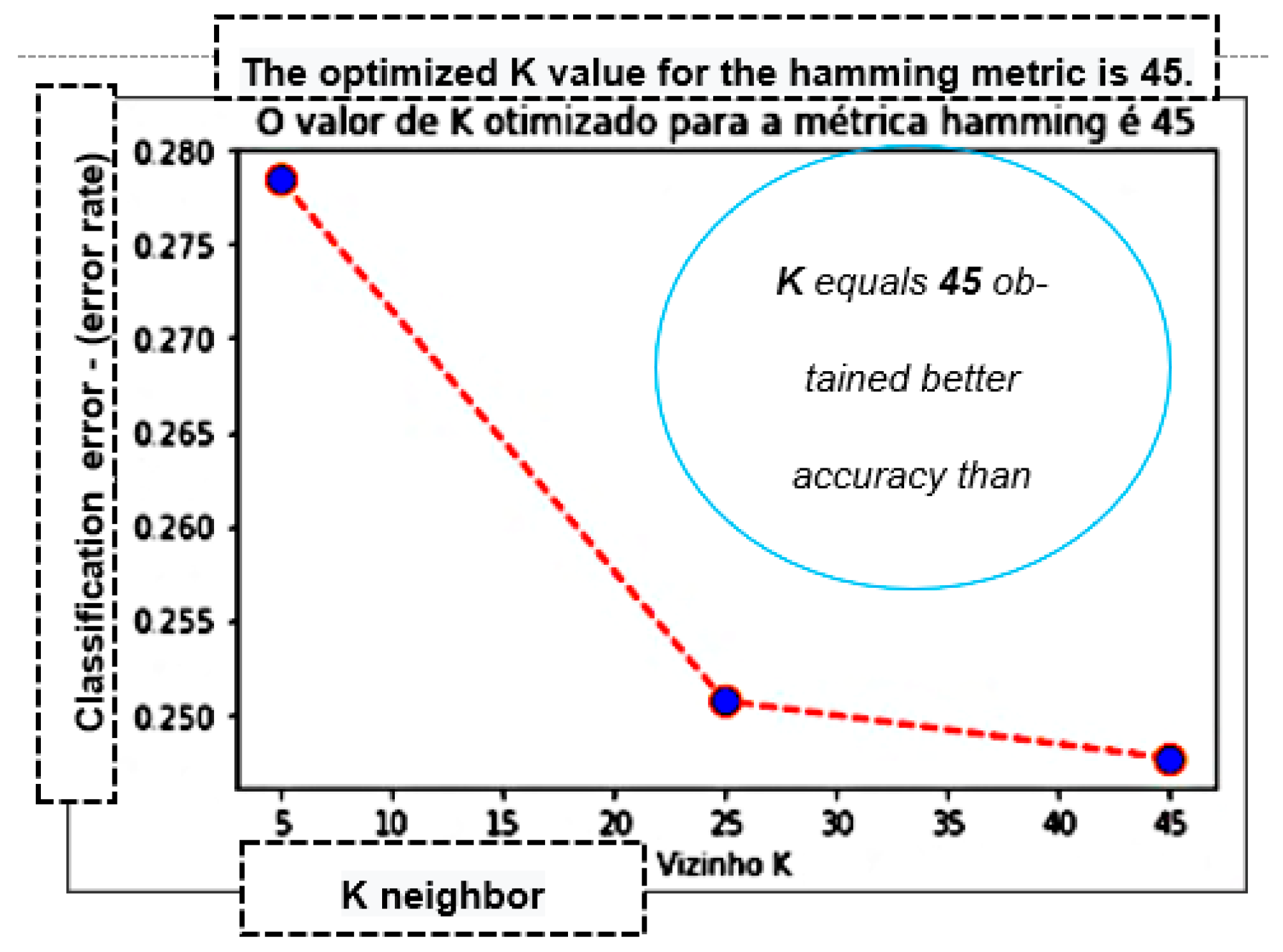
4.1. KNN Results
4.2. Naive Bayes Results
4.3. Results of the Decision Trees
4.4. Multilayer Perceptron Results
4.5. Results of the Support Vector Machine
4.6. Discussion
5. Experimental Evaluation
- Model: Multilayer Perceptron (MLP):
- Parameter 01: Learning rate = adaptive;
- Parameter 02: Momentum = 0.9;
- Parameter 03: Solver = SGD.
5.1. Definition of Values
5.2. Prediction of Clinical Evolution
- In general, the model obtains a probability above 70% in the classification of the target class (hospital discharge or death);
- Patient 01 has a 73% probability of being discharged from the hospital;
- Patient 02 has an 84% probability of clinical evolution to death;
- Patient 03 obtained a chance of 92% that their clinical case would evolve to an end;
- Patient 04 has an 86% probability of clinical evolution to an end;
- Patient 05 reaches an 85% probability of discharge from the hospital.
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- WHO. Coronavirus Disease (COVID-19) Weekly Epidemiological Update and Weekly Operational Update. Available online: https://www.who.int/emergencies/diseases/novel-coronavirus-2019/situation-reports (accessed on 9 December 2020).
- Heidari, A.; Navimipour, N.J.; Unal, M.; Toumaj, S. Machine learning applications for COVID-19 outbreak management. Neural Comput. Appl. 2022, 34, 15313–15348. [Google Scholar] [CrossRef] [PubMed]
- Heidari, A.; Toumaj, S.; Navimipour, N.J.; Unal, M. A privacy-aware method for COVID-19 detection in chest CT images using lightweight deep conventional neural network and blockchain. Comput. Biol. Med. 2022, 145, 105461. [Google Scholar] [CrossRef] [PubMed]
- Andrade, E.A. Hybrid Model in Machine Learning and Verbal Decision Analysis Applied to the Diagnosis of Master. Master’s Thesis, University of Fortaleza, Fortaleza, Brazil, 2020. [Google Scholar]
- Souza, R.W.R.; Silva, D.S.; Passos, L.A.; Roder, M.; Santana, M.C.; Pinheiro, P.R.; Albuquerque, V.H.C. Computer-Assisted Parkinson’s Disease Diagnosis Using Fuzzy Optimum-Path Forest, and Restricted Boltzmann Machines. Comput. Biol. Med. 2021, 131, 104260. [Google Scholar] [CrossRef]
- Andrade, E.C.; Pinheiro, P.R.; Filho, R.H.; Nunes, L.C.; Pinheiro, M.C.D.; Abreu, W.C.; Filho, M.S.; Pinheiro, L.I.C.C.; Pereira, M.L.D.; Pinheiro, P.G.C.D.; et al. Application of Machine Learning to Infer Symptoms and Risk Factors of COVID-19. In The International Research & Innovation Forum; Springer: Cham, Switzerland, 2022; pp. 13–24. [Google Scholar]
- Pinheiro, P.R.; Tamanini, I.; Pinheiro, M.C.D.; Albuquerque, V.H.C. Evaluation of Alzheimer’s Disease Clinical Stages under the Optics of Hybrid Approaches in Verbal Decision Analysis. Telemat. Inform. 2018, 35, 776–789. [Google Scholar] [CrossRef]
- Andrade, E.; Portela, S.; Pinheiro, P.R.; Comin, L.N.; Filho, M.S.; Costa, W.; Pinheiro, M.C.D. A Protocol for the Diagnosis of Autism Spectrum Disorder Structured in Machine Learning and Verbal Decision Analysis. Comput. Math. Methods Med. 2021, 2021, 1628959. [Google Scholar] [CrossRef]
- Ruiz-Fernández, M.D.; Pérez-García, E.; Ortega-Galán, M. Quality of Life in Nursing Professionals: Burnout, Fatigue, and Compassion Satisfaction. Int. J. Environ. Res. Public Health 2020, 17, 1253. [Google Scholar] [CrossRef]
- Shereen, M.A.; Khan, S.; Kazmi, A.; Bashir, N.; Siddique, R. COVID-19 infection: Origin, transmission, and characteristics of human coronaviruses. J. Adv. Res. 2020, 24, 91–98. [Google Scholar] [CrossRef]
- Heidari, A.; Navimipour, N.J.; Unal, M.; Toumaj, S. The COVID-19 epidemic analysis and diagnosis using deep learning: A systematic literature review and future directions. Comput. Biol. Med. 2021, 141, 105141. [Google Scholar] [CrossRef]
- Matos, P.; Costa, A.; Silva, C. COVID-19, stock market and sectoral contagion in the U.S.: A time-frequency analysis. Res. Int. Bus. Financ. 2021, 57, 101400. [Google Scholar] [CrossRef]
- Vizheh, M.; Qorbani, M.; Arzaghi, S.M.; Muhidin, S.; Javanmard, Z.; Esmaeili, M. The mental health of healthcare workers in the COVID-19 pandemic: A systematic review. J. Diabetes Metab. Disord. 2020, 19, 1967–1978. [Google Scholar] [CrossRef]
- Jin, C.; Chen, W.; Cao, Y.; Xu, Z.; Tan, Z.; Zhang, X.; Deng, L.; Zheng, C.; Zhou, J.; Shi, H.; et al. Development and evaluation of an artificial intelligence system for COVID-19 diagnosis. Nat. Commun. 2020, 11, 5088. [Google Scholar] [CrossRef] [PubMed]
- Carvalho, D.; Pinheiro, P.R.; Pinheiro, M.C.D. A Hybrid Model to Support the Early Diagnosis of Breast Cancer. Procedia Comput. Sci. 2016, 91, 927–934. [Google Scholar] [CrossRef]
- Lalmuanawma, S.; Hussain, J.; Chhakchhuak, L. Applications of machine learning and artificial intelligence for the covid-19 (SARS-COV-2) pandemic: A review. Chaos Solitons Fractals 2020, 139, 110059. [Google Scholar] [CrossRef]
- Booth, A.L.; Abels, E.; McCaffrey, P. Development of a prognostic model for mortality in covid-19 infection using machine learning. Mod. Pathol. 2021, 34, 522–531. [Google Scholar] [CrossRef] [PubMed]
- Liang, W.; Yao, J.; Chen, A.; Lv, Q.; Zanin, M.; Liu, J.; Wong, S.; Li, Y.; Lu, J.; Liang, H.; et al. Early triage of critically ill COVID-19 patients using deep learning. Nat. Commun. 2020, 11, 3543. [Google Scholar] [CrossRef] [PubMed]
- Yang, P.; Xie, Y.; Rao, X.; Frix, A.N.; Moutschen, M.; Li, J.; Du, D.; Zhao, S.; Ding, Y.; Liu, B.; et al. Development of a clinical decision support system for severity risk prediction and triage of COVID-19 patients at hospital admission: An international multicenter study. Eur. Respir. J. 2020, 56, 2001104. [Google Scholar]
- Gao, Y.; Cai, G.-Y.; Fang, W.; Li, H.-Y.; Wang, S.-Y.; Chen, L.; Yu, Y.; Liu, D.; Xu, S.; Cui, P.-F.; et al. Machine learning based early warning system enables accurate mortality risk prediction for COVID-19. Nat. Commun. 2020, 11, 5033. [Google Scholar] [CrossRef]
- Pinheiro, L.I.C.C.; Pereira, M.L.D.; Andrade, E.C.; Nunes, L.C.; Abreu, W.C.; Pinheiro, P.G.C.D.; Filho, R.H.; Pinheiro, P.R. An Intelligent Multicriteria Model for Diagnosing Dementia in People Infected with Human Immunodeficiency Virus. Appl. Sci. 2021, 11, 10457. [Google Scholar] [CrossRef]
- Castro, A.K.A.; Pinheiro, P.R.; Pinheiro, M.C.D.; Tamanini, I. Towards the Applied Hybrid Model in Decision Making: A Neuropsychological Diagnosis of Alzheimer’s Disease Study Case. Int. J. Comput. Intell. Syst. 2011, 4, 89–99. [Google Scholar] [CrossRef]
- Russell, J.; Norvig, P. Artificial Intelligence: A Modern Approach, 3rd ed.; Prentice-Hall: Hoboke, NJ, USA, 2010. [Google Scholar]
- Shilo, S.; Rossman, H.; Segal, E. Axes of a revolution challenges and promises big data in healthcare. Nat. Med. 2020, 26, 29–38. [Google Scholar] [CrossRef]
- Yu, K.H.; Beam, L.A.; Kohane, I.S. Artificial intelligence in healthcare. Nat. Biomed. Eng. 2018, 2, 719–731. [Google Scholar] [CrossRef]
- Alimadadi, A.; Aryal, S.; Manandhar, I.; Munroe, P.B.; Joe, B.; Cheng, X. Artificial intelligence and machine learning to fight COVID-19. Physiol. Genom. 2020, 52, 200–202. [Google Scholar] [CrossRef] [PubMed]
- Mei, X.; Lee, H.C.; Diao, K.Y.; Huang, M.; Lin, B.; Liu, C.; Xie, Z.; Ma, Y.; Robson, P.M.; Chung, M.; et al. Artificial intelligence-enabled rapid diagnosis of patients with COVID-19. Nat. Med. 2020, 26, 1224–1228. [Google Scholar] [CrossRef] [PubMed]
- Yan, L.; Zhang, H.-T.; Goncalves, J.; Xiao, Y.; Wang, M.; Guo, Y.; Sun, C.; Tang, X.; Jing, L.; Zhang, M.; et al. An interpretable mortality prediction model for COVID-19 patients. Nat. Mach. Intell. 2020, 2, 283–288. [Google Scholar] [CrossRef]
- Pan, P.; Li, Y.; Xiao, Y.; Han, B.; Su, L.; Su, M.; Li, Y.; Zhang, S.; Jiang, D.; Chen, X.; et al. Prognostic assessment of COVID-19 in the intensive care unit by machine learning methods: Model development and validation. J. Med. Internet Res. 2020, 22, e23128. [Google Scholar] [CrossRef]
- Waheed, A.; Goyal, M.; Gupta, D.; Khanna, A.; Al-Turjman, F.; Pinheiro, P.R. CovidGAN: Data Augmentation Using Auxiliary Classifier GAN for Improved COVID-19 Detection. IEEE Access 2020, 8, 91916–91923. [Google Scholar] [CrossRef]
- Bai, T.; Zhu, X.; Zhou, X.; Grathwohl, D.; Yang, P.; Zha, Y.; Jin, Y.; Chong, H.; Yu, Q.; Isberner, N.; et al. Reliable and Interpretable Mortality Prediction With Strong Foresight in COVID-19 Patients: An International Study From China and Germany. Front. Artif. Intell. 2021, 4, 672050. [Google Scholar] [CrossRef]
- Heldt, F.S.; Vizcaychipi, M.P.; Peacock, S.; Cinelli, M.; McLachlan, L.; Andreotti, F.; Jovanović, S.; Dürichen, R.; Lipunova, N.; Fletcher, R.A.; et al. Early risk assessment for COVID-19 patients from emergency department data using machine learning. Sci. Rep. 2021, 11, 4200. [Google Scholar] [CrossRef]
- Abdullah, D.; Susilo, S.; Ahmar, A.S.; Rusli, R.; Hidayat, R. The application of K-means clustering for province clustering in Indonesia of the risk of the COD-19 pandemic based on COVID-19 data. Qual. Quant. 2021, 56, 1283–1291. [Google Scholar] [CrossRef]
- Ryan, L.; Lam, C.; Mataraso, S.; Allen, A.; Green-Saxen, A.; Pellegrini, E.; Hoffman, J.; Barton, C.; McCoy, A.; Das, R. A Mortality prediction model for the triage of COVID-19, pneumonia, and mechanically ventilated ICU patients: A retrospective study. Ann. Med. Surg. 2020, 59, 207–216. [Google Scholar] [CrossRef]
- Assaf, D.; Gutman, Y.; Neuman, Y.; Segal, G.; Amit, S.; Gefen-Halevi, S.; Shilo, N.; Epstein, A.; Mor-Cohen, R.; Biber, A.; et al. Utilization of machine-learning models to accurately predict the risk for critical COVID-19. Intern. Emerg. Med. 2020, 15, 1435–1443. [Google Scholar] [CrossRef] [PubMed]
- Fernandes, F.T.; de Oliveira, T.A.; Teixeira, C.E.; Batista, A.F.D.M.; Costa, G.D.; Filho, A.D.P.C. A multipurpose machine learning approach to predict COVID-19 negative prognosis in São Paulo, Brazil. Sci. Rep. 2021, 11, 3343. [Google Scholar] [CrossRef] [PubMed]
- Numpy. Available online: https://numpy.org/ (accessed on 5 January 2022).
- Pandas. Available online: https://pandas.pydata.org/ (accessed on 15 January 2022).
- Seaborn. Available online: https://seaborn.pydata.org/ (accessed on 12 January 2022).
- Scikit-Learn. Available online: https://scikit-learn.org/stable/ (accessed on 7 January 2022).
- Python. Available online: https://www.python.org/ (accessed on 11 January 2022).
- Korbut, D. Machine Learning Algorithms: Which to Choose for Your Problem. Available online: https://blog.statsbot.co/machine-learning-algorithms-183cc73197c (accessed on 7 January 2022).
- Presesti, E.; Gosmaro, F. Trueness, Precision and Accuracy: A Critical Overview of the Concepts and Proposals for revision. Accredit. Qual. Assur. 2015, 20, 33–40. [Google Scholar] [CrossRef]
- Powers, D.M. Evaluation: From precision, recall, and f-measure to roc, informedness, markedness, and correlation. ArXiv 2020, arXiv:2010.16061. [Google Scholar]
- Fawcett, T. Roc graphs: Notes and practical considerations for researchers. Mach. Learn. 2004, 31, 1–38. [Google Scholar]
- Zrigat, E.; Altamimi, A.; Azzeh, M. A Comparative Study for Predicting Heart Diseases Using Data Mining Classification Methods. Int. J. Comput. Sci. Inf. Secur. 2016, 14, 868–879. [Google Scholar]
- Shayanfar, H.; Gharehchopogh, F.S. Farmland fertility: A new metaheuristic algorithm for solving continuous optimization problems. Appl. Soft Comput. 2018, 71, 728–746. [Google Scholar] [CrossRef]
- Abdollahzadeh, B.; Gharehchopogh, F.S.; Mirjalili, S. African vultures optimization algorithm: A new nature-inspired metaheuristic algorithm for global optimization problems. Comput. Ind. Eng. 2021, 158, 107408. [Google Scholar] [CrossRef]
- Abdollahzadeh, B.; Gharehchopogh, F.S.; Mirjalili, S. Artificial gorilla troops optimizer: A new nature-inspired metaheuristic algorithm for global optimization problems. Int. J. Intell. Syst. 2021, 36, 5887–5958. [Google Scholar] [CrossRef]








| Individual Record Form—Hospitalised Severe Acute Respiratory Syndrome Cases | |||
|---|---|---|---|
| Field Name | Type | Allowed Values | Description |
| FEVER | Varchar2 (1) | 1—Yes 2—No 0—Ignored 9—Ignored | Did the patient have a fever? |
| COUGH | Varchar2 (1) | Did the patient cough? | |
| DYSPNEA | Varchar2 (1) | Did the patient have dyspnea? | |
| THROAT | Varchar2 (1) | Did the patient have a sore throat? | |
| PAIN_ABD | Varchar2 (1) | Did the patient have abdominal pain? | |
| FATIGUE | Varchar2 (1) | Did the patient experience fatigue? | |
| DIARRHEA | Varchar2 (1) | Did the patient have diarrhoea? | |
| SATURATION | Varchar2 (1) | Did the patient have O2 saturation <95%? | |
| VOMIT | Varchar2 (1) | Did the patient experience vomiting? | |
| PERD_OLFT | Varchar2 (1) | Did the patient experience a loss of smell? | |
| LOST_PALA | Varchar2 (1) | Did the patient experience taste loss? | |
| RISC_FACTOR | Varchar2 (1) | Does the patient have risk factors? | |
| OBESITY | Varchar2 (1) | Does the patient have obesity? | |
| VACCINE | Varchar2 (1) | Was the patient vaccinated against influenza in the last campaign? | |
| SUPPORT_VEN | Varchar2 (1) | 1—Yes, invasive 2—Yes, non-invasive 3—N 0—Ignored 9—Ignored | Did the patient use ventilatory support? |
| EVOLUTION | Varchar2 (1) | 1—Cure 2—Death | Evolution of the case |
| Attribute 01 | Attribute 02 | Correlation Value |
|---|---|---|
| THROAT | VOMIT | 0.81 |
| PAIN_ABD | PERD_OLFT | 0.85 |
| FATIGUE | PAIN_ABD | 0.86 |
| DIARRHEA | PAIN_ABD | 0.82 |
| VOMIT | DIARRHEA | 0.9 |
| PERD_OLFT | LOST_PALA | 0.96 |
| Attribute 01 | Attribute 02 | Correlation Value |
|---|---|---|
| EVOLUTION | SUPPORT_VEN | −0.19 |
| K-Nearest Neighbor—KNN | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metrics/Distance KNN | Accuracy | Precision | Recall That | F1 Score | Accuracy | Precision | Recall That | F1 Score | Accuracy | Precision | Recall That | F1 Score |
| Neighbor K | 5 | 25 | 45 | |||||||||
| Euclidean | 71.17% | 74.31% | 0.8518 | 0.79380 | 73.47% | 74.25% | 0.9073 | 0.81671 | 74.45% | 75.04% | 9107 | 0.82283 |
| Manhattan | 71.17% | 74.32% | 0.8516 | 0.79375 | 74.07% | 74.62% | 0.9122 | 0.82090 | 74.87% | 75.09% | 0.9191 | 0.82654 |
| Hamming | 71.87% | 74.61% | 0.8613 | 0.79957 | 74.65% | 74.71% | 0.9235 | 0.82599 | 75.27% | 74.93% | 0.9322 | 0.83082 |
| Naive Bayes | ||||
|---|---|---|---|---|
| Metrics/Distribution | Accuracy | Precision | Recall That | F1 Score |
| Gaussian | 65.13% | 66.42% | 0.9401 | 0.77843 |
| Bernoulli | 59.37% | 66.93% | 0.7439 | 0.70462 |
| Multinomial | 66.62% | 66.98% | 0.9618 | 0.78966 |
| Decision Tree | ||||
|---|---|---|---|---|
| Metrics/Criteria | Accuracy | Precision | Recall That | F1 Score |
| Gini index | 71.58% | 74.61% | 0.8546 | 0.79670 |
| Entropy | 71.83% | 74.87% | 0.8544 | 0.79808 |
| Multilayer Perceptron—MLP | ||||
|---|---|---|---|---|
| Metrics/Learning Rate and Momentum | Accuracy | Precision | Recall That | F1 Score |
| learning_rate = constantmomentum = 0.1 | 69.86% | 70.48% | 0.70633 | 0.70556 |
| learning_rate = invscalingmomentum = 0.9 | 61.1% | 65.23% | 0.64333 | 0.64781 |
| learning_rate = adaptive momentum = 0.9 | 76.3% | 76.41% | 0.76466 | 0.76441 |
| Support Vector Machine—SVM | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metrics/Kernel | Accuracy | Precision | Recall That | F1 Score | Accuracy | Precision | Recall That | F1 Score | Accuracy | Precision | Recall That | F1 Score |
| Cost | 1 | 2 | 3 | |||||||||
| kernel = linearGamma = scale | 66.25% | 66.25% | 1.0 | 0.79699 | 66.25% | 66.25% | 1.0 | 0.79699 | 66.25% | 66.25% | 1.0 | 0.79699 |
| Kernel = LinearGamma = auto | 66.25% | 66.25% | 1.0 | 0.79699 | 66.25% | 66.25% | 1.0 | 0.79699 | 66.25% | 66.25% | 1.0 | 0.79699 |
| Kernel = RBFGamma = scale | 72.08% | 73.35% | 0.9086 | 0.81173 | 72.80% | 73.83% | 0.91320 | 0.81646 | 73.28% | 74.27% | 0.91283 | 0.81902 |
| Kernel = RBFGamma = auto | 74.92% | 75.53% | 0.91924 | 0.82927 | 75.58% | 76.43% | 0.91283 | 0.83198 | 75.78% | 76.61% | 0.91320 | 0.83318 |
| Kernel = POLYGamma = scale | 66.25% | 66.25% | 1.0 | 0.79699 | 66.25% | 66.25% | 1.0 | 0.79699 | - | - | - | - |
| Kernel = POLYGamma = scale | 66.25% | 66.46% | 0.99018 | 0.79539 | 66.27% | 66.48% | 0.99018 | 0.79551 | 66.33% | 66.51% | 0.99056 | 0.79581 |
| Kernel = POLYGamma = scale | 66.95% | 67.82% | 0.95358 | 0.79265 | - | - | - | - | - | - | - | - |
| Kernel = POLYGamma = auto | 66.25% | 66.25% | 1.0 | 0.79699 | - | - | - | - | - | - | - | - |
| Kernel = POLYGamma = auto | - | - | - | 66.30% | 66.51% | 0.98981 | 0.79557 | - | - | - | - | |
| Comparative Benchmark between Prediction Models | ||||||
|---|---|---|---|---|---|---|
| Metric/Prediction Model | Accuracy | Precision | Recall That | F1 Score | ROC | Time (s) |
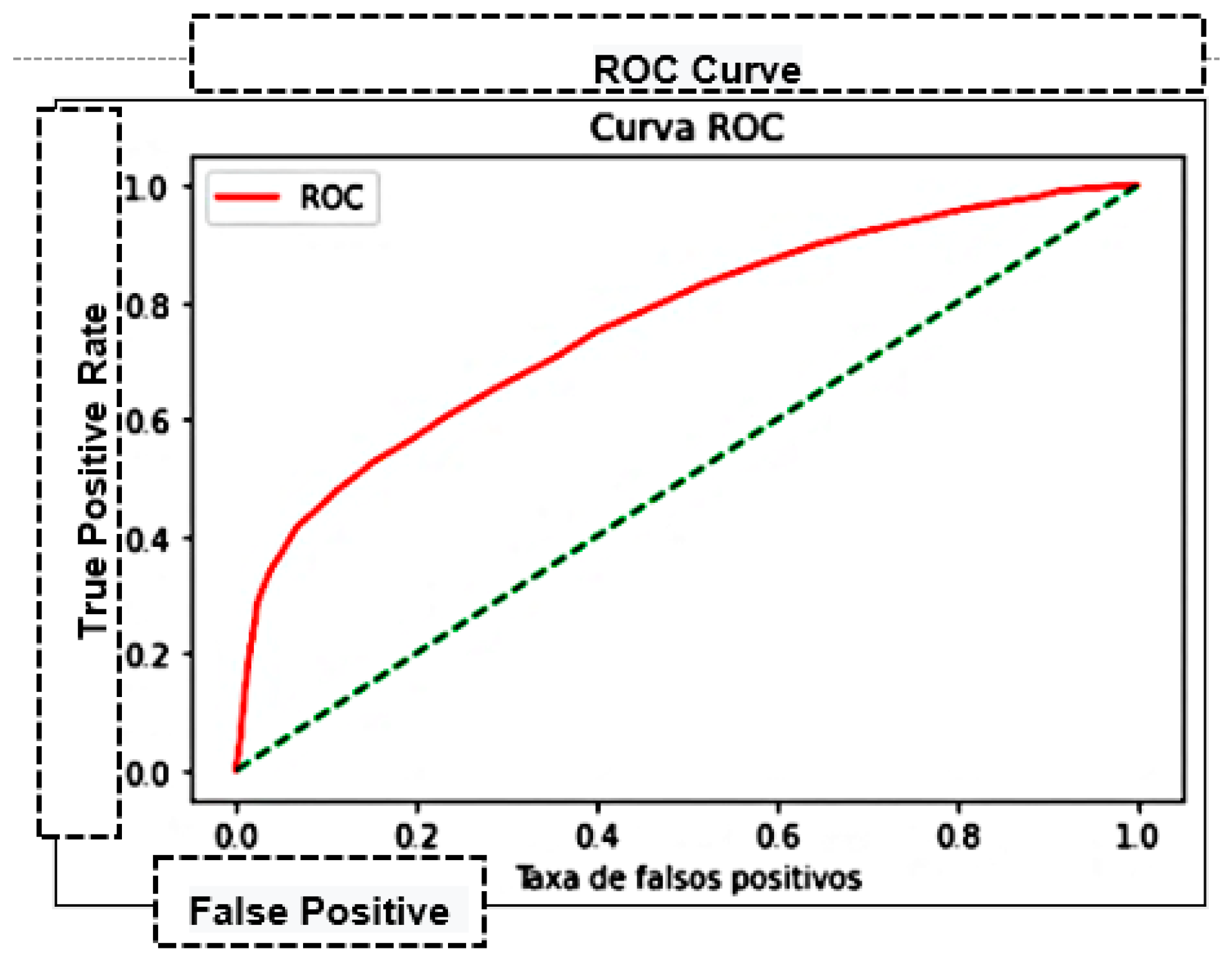
| K-Nearest Neighbor—KNN | 75.27% | 74.93% | 0.9322 | 0.83082 | 0.76202 | 69.995 |
| Naive Bayes | 66.62% | 66.98% | 0.9618 | 0.78966 | 0.64363 | 0.0826 |
| Decision trees | 71.83% | 74.87% | 0.8544 | 0.79808 | 0.69686 | 0.5455 |
| Multilayer Perceptron—MLP | 76.3% | 76.41% | 0.7646 | 0.76441 | 0.84300 | 286.023 |
| Support Vector Machine—SVM | 75.78% | 76.61% | 0.91320 | 0.83318 | 0.73772 | 0.00101 |
| Individual Record Form—Hospitalised Severe Acute Respiratory Syndrome Cases | |
|---|---|
| 1. Did the patient have a fever? | 9. Did the patient experience vomiting? |
| 2. Did the patient have a cough? | 10. Did the patient use ventilatory support? |
| 3. Did the patient have dyspnea? | 11. Did the patient experience a loss of smell? |
| 4. Did the patient have a sore throat? | 12. Did the patient experience a loss of taste? |
| 5. Did the patient have abdominal pain? | 13. Does the patient have any risk factors? |
| 6. Did the patient experience fatigue? | 14. Does the patient have obesity? |
| 7. Did the patient have diarrhoea? | 15. Was the patient vaccinated against influenza in the last campaign? |
| 8. Did the patient have O2 saturation <95%? | |
| Questions/Patients | Patient 01 | Patient 02 | Patient 03 | Patient 04 | Patient 05 |
|---|---|---|---|---|---|
| 1. Did the patient have a fever? | 1—Yes | 2—No | 1—Yes | 1—Yes | 1—Yes |
| 2. Did the patient have a cough? | 1—Yes | 2—No | 1—Yes | 1—Yes | 1—Yes |
| 3. Did the patient have dyspnea? | 1—Yes | 1—Yes | 1—Yes | 2—No | 2—No |
| 4. Did the patient have a sore throat? | 0—Ignored | 2—No | 2—No | 2—No | 2—No |
| 5. Did the patient have abdominal pain? | 0—Ignored | 2—No | 2—No | 2—No | 2—No |
| 6. Did the patient experience fatigue? | 1—Yes | 2—No | 1—Yes | 1—Yes | 1—Yes |
| 7. Did the patient have diarrhoea? | 1—Yes | 2—No | 1—Yes | 2—No | 2—No |
| 8. Did the patient have O2 saturation < 95%? | 0—Ignored | 2—No | 1—Yes | 2—No | 2—No |
| 9. Did the patient experience vomiting? | 1—Yes | 2—No | 2—No | 2—No | 2—No |
| 10. Did the patient use ventilatory support? | 0—Ignored | 1—Yes | 1—Yes | 1—Yes | 2—No |
| 11. Did the patient experience a loss of smell? | 0—Ignored | 2—No | 1—Yes | 1—Yes | 1—Yes |
| 12. Did the patient experience a loss of taste? | 0—Ignored | 2—No | 1—Yes | 1—Yes | 1—Yes |
| 13. Does the patient have any risk factors? | 1—Yes | 1—Yes | 2—No | 2—No | 1—Yes |
| 14. Does the patient have obesity? | 1—Yes | 2—No | 2—No | 1—Yes | 2—No |
| 15. Was the patient vaccinated against influenza in the last campaign? | 0—Ignored | 1—Yes | 1—Yes | 1—Yes | 1—Yes |
| Clinical Case Evolution | 73%—the case progressed to the cure (1) of the patient | 84%—the case progressed to death (2) of the patient | 92%—the case progressed to death (2) of the patient | 86%—the case progressed to death (2) of the patient | 85%—the case progressed to the cure (1) of the patient |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Andrade, E.C.d.; Pinheiro, P.R.; Barros, A.L.B.d.P.; Nunes, L.C.; Pinheiro, L.I.C.C.; Pinheiro, P.G.C.D.; Holanda Filho, R. Towards Machine Learning Algorithms in Predicting the Clinical Evolution of Patients Diagnosed with COVID-19. Appl. Sci. 2022, 12, 8939. https://doi.org/10.3390/app12188939
Andrade ECd, Pinheiro PR, Barros ALBdP, Nunes LC, Pinheiro LICC, Pinheiro PGCD, Holanda Filho R. Towards Machine Learning Algorithms in Predicting the Clinical Evolution of Patients Diagnosed with COVID-19. Applied Sciences. 2022; 12(18):8939. https://doi.org/10.3390/app12188939
Chicago/Turabian StyleAndrade, Evandro Carvalho de, Plácido Rogerio Pinheiro, Ana Luiza Bessa de Paula Barros, Luciano Comin Nunes, Luana Ibiapina C. C. Pinheiro, Pedro Gabriel Calíope Dantas Pinheiro, and Raimir Holanda Filho. 2022. "Towards Machine Learning Algorithms in Predicting the Clinical Evolution of Patients Diagnosed with COVID-19" Applied Sciences 12, no. 18: 8939. https://doi.org/10.3390/app12188939
APA StyleAndrade, E. C. d., Pinheiro, P. R., Barros, A. L. B. d. P., Nunes, L. C., Pinheiro, L. I. C. C., Pinheiro, P. G. C. D., & Holanda Filho, R. (2022). Towards Machine Learning Algorithms in Predicting the Clinical Evolution of Patients Diagnosed with COVID-19. Applied Sciences, 12(18), 8939. https://doi.org/10.3390/app12188939