
Wiener Filter and Deep Neural Networks: A Well-Balanced Pair for Speech Enhancement


Abstract
:1. Introduction
- A data-driven Wiener filter estimator that can be generalized to different approaches of the classical spectral-domain speech estimator algorithm, tested with LSA and OMLSA speech estimators.
- In the line of previous works, this paper demonstrates the usefulness of deep learning for expanding the application scope of established speech enhancement schemes in realistic scenarios with challenging environmental noisy patterns.
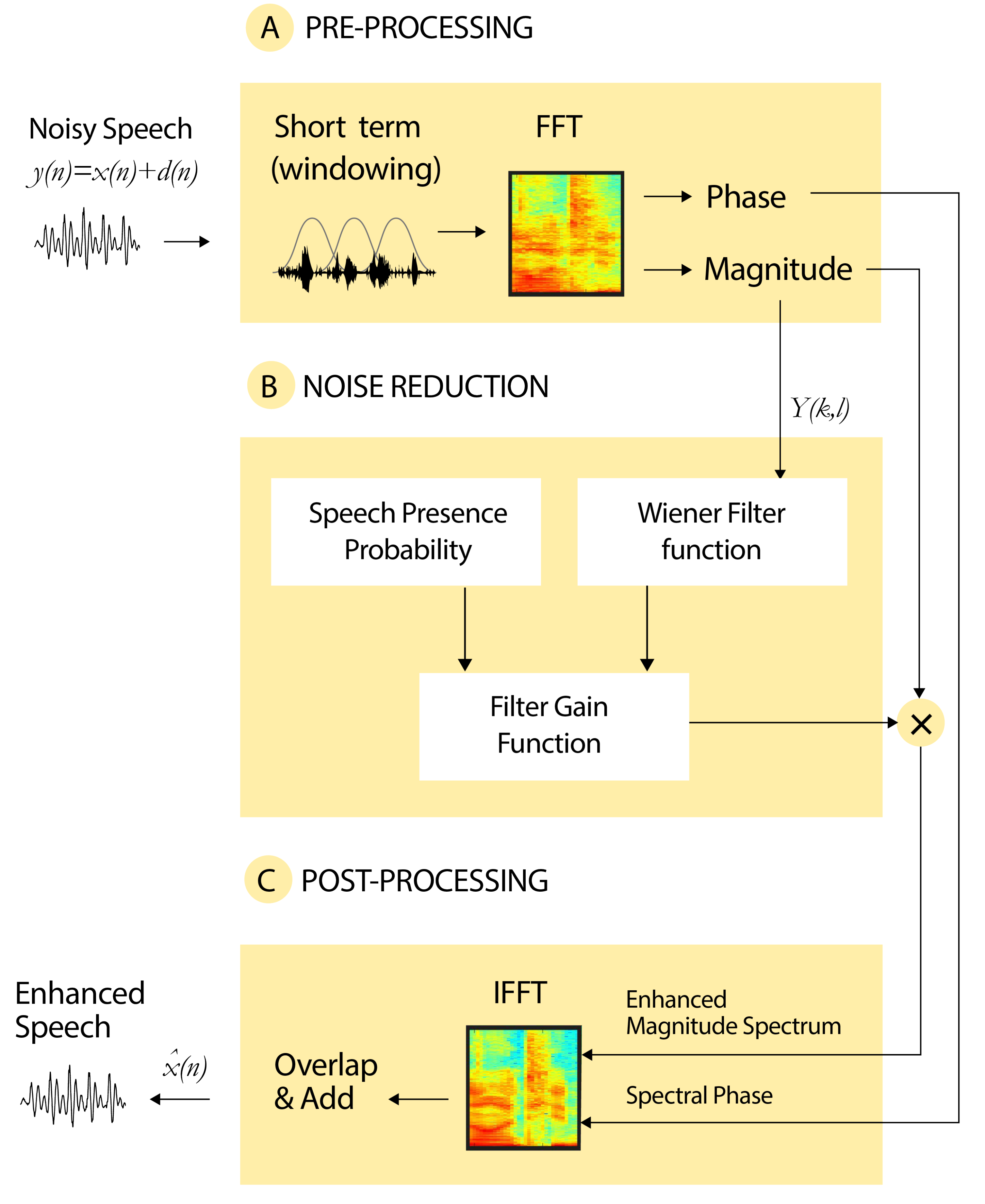
2. Speech Enhancement
2.1. Speech Estimation Algorithms
2.2. SNR Estimation
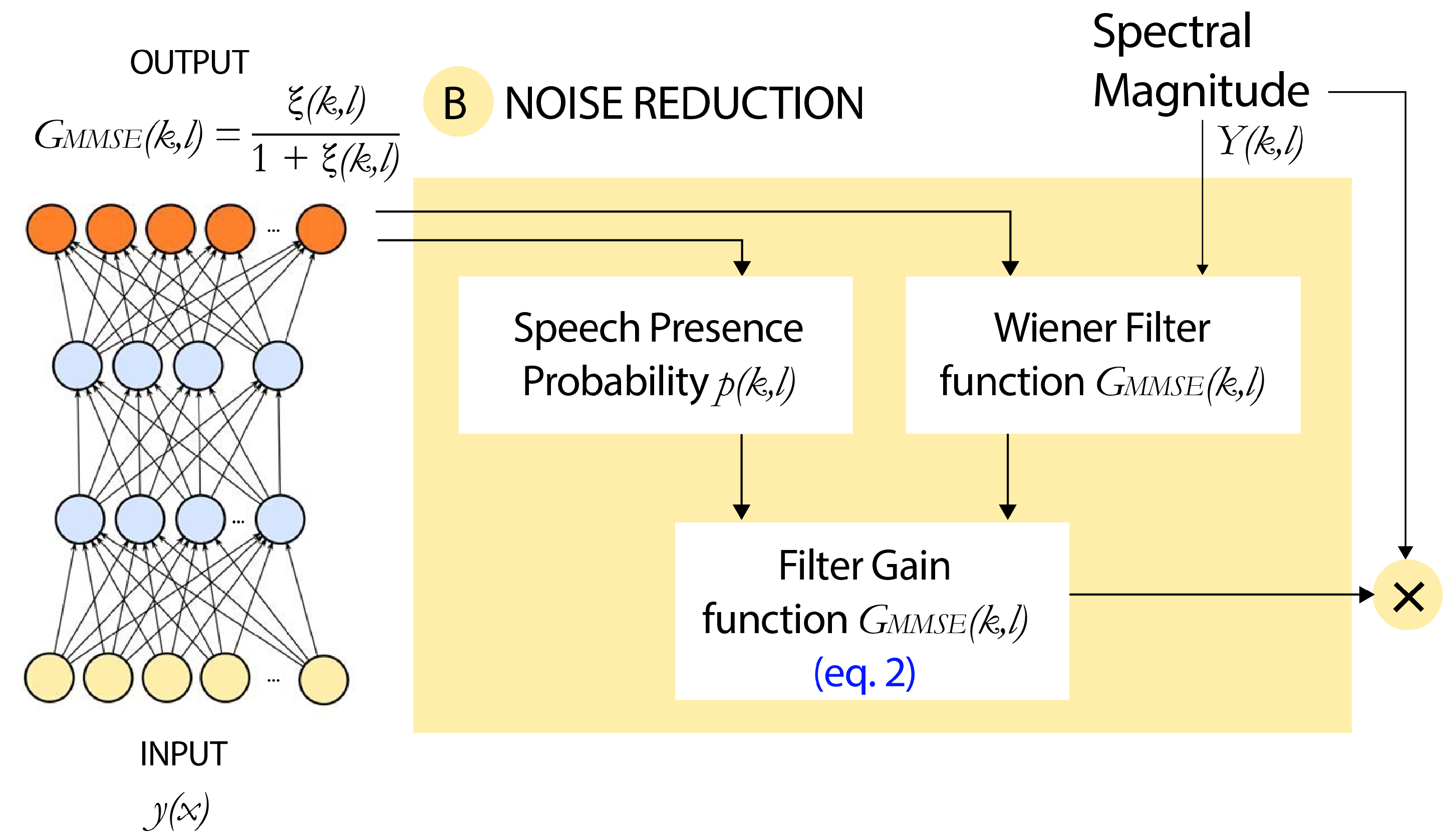
3. Proposal
4. Architecture
5. Experimental Setup
5.1. Datasets
- Babble: Noisy pattern from the talking of many people. It is a special case of non-stationary noise, very difficult to handle because it is highly correlated with the target voice since it is also voice.
- Traffic: Noise from the traffic at a random street, including cars, klaxon, street noise, etc.
- Cafe: Mixture of environmental noises in a cafe, including people talking, noise from cutlery, etc.
- Tram: Environmental noise in a tram station, including some stationary segments when the tram arrives.
5.2. Speech Quality Measures
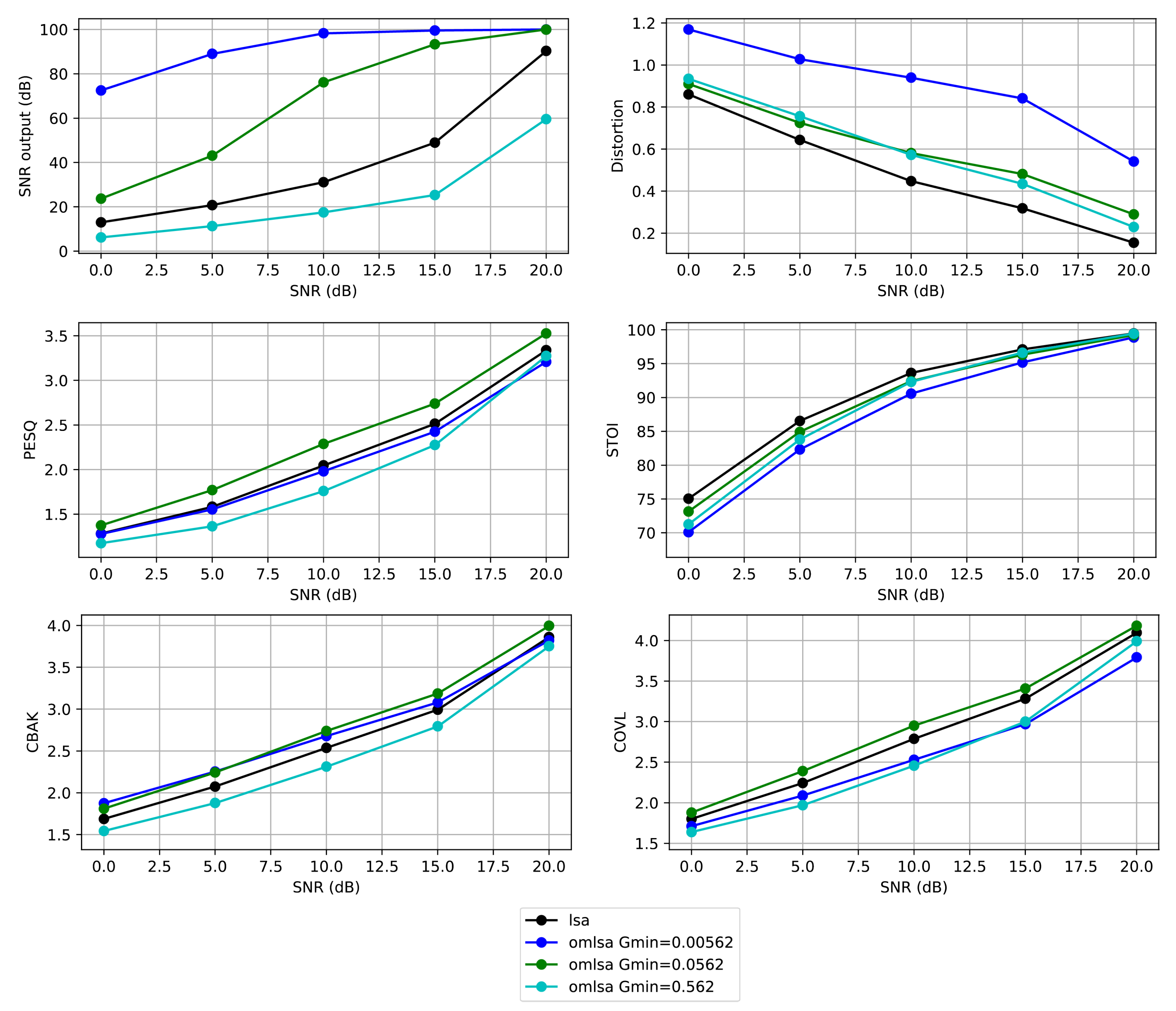
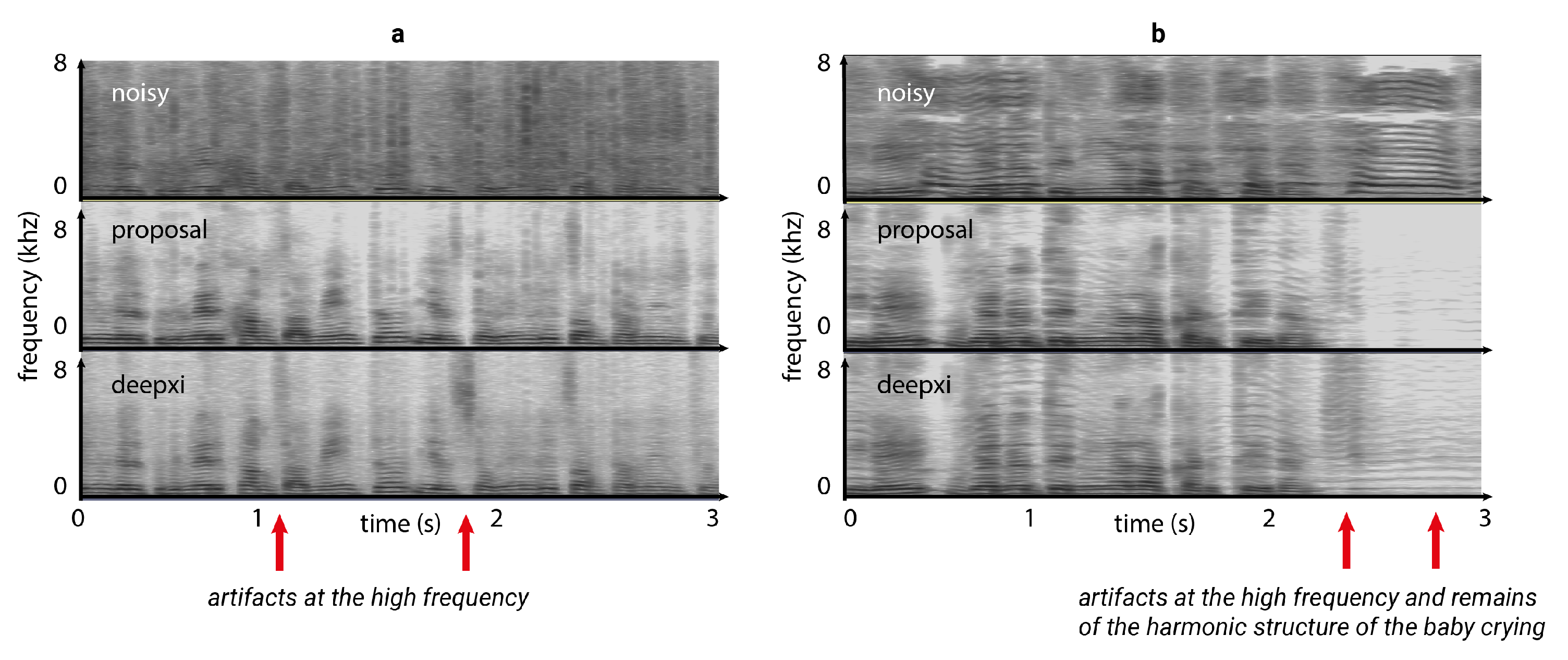
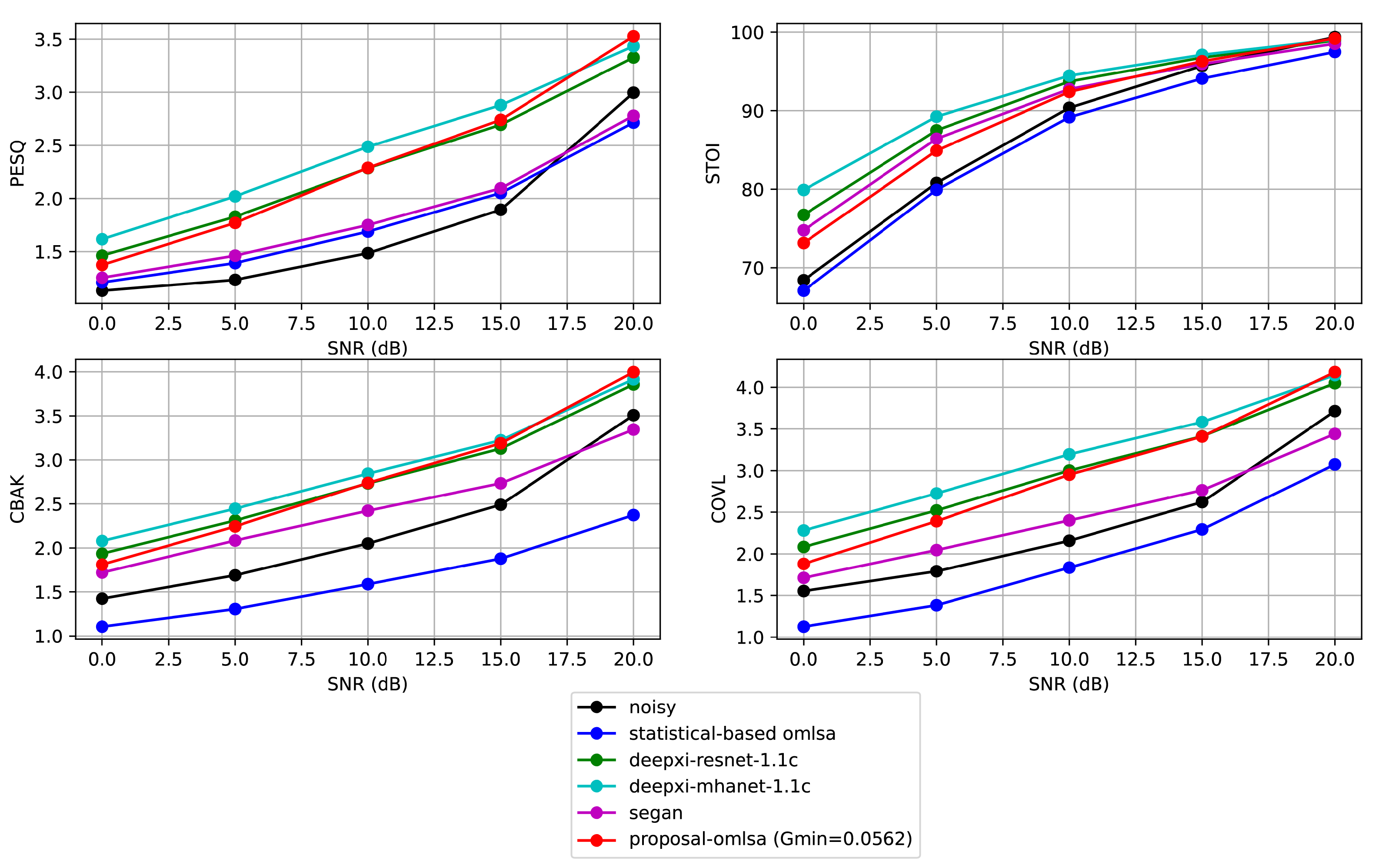
6. Results and Discussion
6.1. Evaluation of the Speech Estimator
6.2. Preview of the Performance
6.3. Objective Quality Metrics
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Sample Availability
Abbreviations
| ADAM | Adaptive Moment Estimator |
| ASR | Automatic Speech Recognition |
| CNN | Convolutional Neural Network |
| DL | Deep Learning |
| DNN | Deep Neural Network |
| DSE | Deep Speech Enhancement |
| Gain of the Minimum Mean Square Error Estimator | |
| IBM | Ideal Binary Mask |
| IRM | Ideal Ratio Mask |
| LSA | Log-Spectral Amplitude |
| MMSE | Minimum Mean Square Error |
| MSE | Mean Square Error |
| OMLSA | Optimal Modified Log-Spectral Amplitude |
| PReLU | Parametric Rectified Linear Unit |
| PSD | Power Spectral Density |
| SNR | Signal-to-Noise Ratio |
| SS | Spectral Subtraction |
| STD | Standard Deviation |
| STFT | Short-Term Fourier Transform |
| STSA | Short-Time Spectral Amplitude |
References
- Loizou, P.C. Speech Enhancement: Theory and Practice; CRC Press: New York, NY, USA, 2013. [Google Scholar]
- Hendriks, R.C.; Gerkmann, T.; Jensen, J. DFT-Domain Based Single-Microphone Noise Reduction for Speech Enhancement: A Survey of the State of the Art. Synthesis Lectures on Speech and Audio Processing; Morgan & Claypool: New York, NY, USA, 2013. [Google Scholar]
- Lim, J.S.; Oppenheim, A.V. Enhancement and bandwidth compression of noisy speech. Proc. IEEE 1979, 67, 1586–1604. [Google Scholar] [CrossRef]
- Boll, S. Suppression of acoustic noise in speech using spectral subtraction. IEEE Trans. Acoust. Speech Signal Process. 1979, 27, 113–120. [Google Scholar] [CrossRef]
- Ephraim, Y.; Malah, D. Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 1109–1121. [Google Scholar] [CrossRef]
- Ephraim, Y.; Malah, D. Speech enhancement using minimum-mean square log spectral amplitude estimator. IEEE Trans. Acoust. Speech Signal Process. 1985, 33, 443–445. [Google Scholar] [CrossRef]
- Breithaupt, C.; Martin, R. Analysis of the Decision-Directed SNR Estimator for Speech Enhancement with Respect to Low-SNR and Transient Conditions. IEEE Trans. Speech Audio Process. 2010, 19, 277–289. [Google Scholar] [CrossRef]
- Xia, B.Y.; Bao, C.C. Speech enhancement with weighted denoising Auto-Encoder. In Proceedings of the 14th Annual Conference of the International Speech Communication Association (Interspeech), Lyon, France, 25–29 August 2013; pp. 3444–3448. [Google Scholar]
- Xia, B.Y.; Bao, C.C. Wiener filtering based speech enhancement with Weighted Denoising Auto-encoder and noise classification. Speech Commun. 2014, 60, 13–29. [Google Scholar] [CrossRef]
- Wang, D.; Chen, J. Binary and ratio time-frequency masks for robust speech recognition. Speech Commun. 2006, 48, 1486–1501. [Google Scholar]
- Wang, D.; Chen, J. Supervised speech separation based on deep learning: An overview. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1702–1726. [Google Scholar] [CrossRef]
- Narayanan, A.; Wang, D.L. Ideal ratio mask estimation using deep neural networks for robust speech recognition. In Proceedings of the IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 7092–7096. [Google Scholar]
- Narayanan, A.; Wang, D.L. Investigation of speech separation as a front-end for noise robust speech recognition. IEEE Trans. Audio, Speech Lang. Process. 2014, 22, 826–835. [Google Scholar] [CrossRef]
- Healy, E.W.; Yoho, S.E.; Wang, Y.; Wang, D. An algorithm to improve speech recognition in noise for hearing-impaired listeners. J. Acoust. Soc. Am. 2013, 134, 3029–3038. [Google Scholar] [CrossRef]
- Healy, E.W.; Yoho, S.E.; Wang, Y.; Apoux, F.; Wang, D. Speech-cue transmission by an algorithm to increase consonant recognition in noise for hearing-impaired listeners. J. Acoust. Soc. Am. 2014, 136, 3325–3336. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Healy, E.W.; Yoho, S.E.; Chen, J.; Wang, Y.; Wang, D. An algorithm to increase speech intelligibility for hearing-impaired listeners in novel segments of the same noise type. J. Acoust. Soc. Am. 2015, 138, 1660–1669. [Google Scholar] [CrossRef] [PubMed]
- Healy, E.W.; Delfarah, M.; Johnson, E.; Wang, D. A deep learning algorithm to increase intelligibility for hearing-impaired listeners in the presence of a competing talker and reverberation. J. Acoust. Soc. Am. 2019, 145, 1378–1388. [Google Scholar] [CrossRef]
- Bolner, F.; Goehring, T.; Monaghan, J.; van Dijk, B.; Wouters, J.; Bleeck, S. Speech enhancement based on neural networks applied to cochlear implant coding strategies. In Proceedings of the ICASSP, Shanghai, China, 20–25 March 2016; pp. 6520–6524. [Google Scholar]
- Goehring, T.; Bolner, F.; Monaghan, J.; van Dijk, B.; Zarowski, A.; Bleeck, S. Speech enhancement based on neural networks improves speech intelligibility in noise for cochlear implant users. J. Hear. Res. 2017, 344, 183–194. [Google Scholar] [CrossRef] [PubMed]
- Goehring, T.; Keshavarzi, M.; Carlyon, R.P.; Moore, B.C.J. Using recurrent neural networks to improve the perception of speech in non-stationary noise by people with cochlear implants. J. Acoust. Soc. Am. 2019, 146, 705–708. [Google Scholar] [CrossRef]
- Zhang, Q.; Nicolson, A.; Wang, M.; Paliwal, K.K.; Wang, C. DeepMMSE: A Deep Learning Approach to MMSE-Based Noise Power Spectral Density Estimation. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1404–1415. [Google Scholar] [CrossRef]
- Nicolson, A.; Paliwal, K.K. Deep learning for minimum mean-square error approaches to speech enhancement. Speech Commun. 2019, 111, 44–45. [Google Scholar] [CrossRef]
- Nicolson, A.; Paliwal, K.K. On training targets for deep learning approaches to clean speech magnitude spectrum estimation. J. Acoust. Soc. Am. 2021, 149, 3273–3293. [Google Scholar] [CrossRef]
- Cohen, I.; Berdugo, B. Speech enhancement for non-stationary noise environments. Signal Process. 2001, 81, 2403–2418. [Google Scholar] [CrossRef]
- McAulay, R.J.; Malpass, M.L. Speech Enhancement using a Soft-Decision Noise Supression Filter. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 137–145. [Google Scholar] [CrossRef]
- Malah, D.; Cox, R.; Accardi, A. Tracking speech-presence uncertainty to improve speech enhancement in non-stationary noise environments. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Phoenix, AZ, USA, 15–19 March 1999. [Google Scholar]
- Hirsch, H.; Ehrlicher, C. Noise estimation techniques for robust speech recognition. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Detroit, MI, USA, 9–12 May 1995; pp. 153–156. [Google Scholar]
- Martin, R. Noise power spectral density estimation based on optimal smoothing and minimum statistics. IEEE Trans. Speech Audio Process. 2001, 9, 504–512. [Google Scholar] [CrossRef] [Green Version]
- Welch, P.D. The use of fast Fourier transforms for the estimation of power spectra: A method based on time averaging over short modified periodograms. IEEE Trans. Audio Electroacoust. 1967, 15, 70–73. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: Amethod for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Loshchilov, I.; Hutter, F. Fixing weight decay regularization in adam. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Snyder, D.; Chen, G.; Povey, D. MUSAN: A Music, Speech, and Noise Corpus. arXiv 2015, arXiv:1510.08484v1. [Google Scholar]
- Ortega, A.; Sukno, F.; Lleida, E.; Frangi, A.; Miguel, A.; Buera, L.; Zacur, E. AV@CAR: A Spanish multichannel multimodal corpus for in-vehicle automatic audio-visual speech recognition. In Proceedings of the Language Resources and Evaluation (LREC), Reykjavik, Iceland, 26–31 May 2004; pp. 763–766. [Google Scholar]
- ITU-T Recommendation PESQ-862; Perceptual Evaluation of Speech Quality (PESQ): An Objective Method for End-to-End Speech Quality Assessment of Narrow-Band Telephone Networks and Speech Codecs. International Telecommunication Union (ITU): Geneva, Switzerland, 2001.
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. A short-time objective intelligibility measure for time-frequency weighted noisy speech. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; pp. 4214–4217. [Google Scholar] [CrossRef]
- Hu, Y.; Loizou, P.C. Evaluation of objective quality measures for speech enhancement. IEEE Trans. Audio Speech Lang. Process. 2007, 16, 229–238. [Google Scholar] [CrossRef]
- Chanwoo Kim, R.M.S. Robust Signal-to-Noise Ratio Estimation Based on Waveform Amplitude Distribution Analysis. In Proceedings of the 9th Annual Conference of the International Speech Communication Association (Interspeech), Brisbane, Australia, 22–26 September 2008; pp. 2598–2601. [Google Scholar]
- Loizou, P.C. Speech Quality Asssessment. In Multimedia Analysis, Processing and Communications; Springer: Berlin/Heidelberg, Germany, 2011; pp. 623–654. [Google Scholar]
- Pascual, S.; Bonafonte, A.; Serr, J. Segan: Speech enhancement generative adversarial network. In Proceedings of the 18th Annual Conference of the International Speech Communication Association (Interspeech), Stockholm, Sweden, 20–24 August 2017; pp. 3642–3646. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Kernel Size | Dilation | Input Dim. | Output Dim. |
|---|---|---|---|---|
| Block 1 (×4 WRN) | 7 | 3 | 512 | 256 |
| Block 2 (×4 WRN) | 5 | 3 | 512 + 256 | 512 |
| Block 3 (×4 WRN) | 3 | 2 | 512 + 512 | 1024 |
| Block 4 (×4 WRN) | 3 | 2 | 512 + 1024 | 2048 |
| Block 5 (×4 WRN) | 3 | 2 | 512 + 2048 | 2048 |
| Output (Linear Layer) | - | - | 512 + 2048 | 512 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ribas, D.; Miguel, A.; Ortega, A.; Lleida, E. Wiener Filter and Deep Neural Networks: A Well-Balanced Pair for Speech Enhancement. Appl. Sci. 2022, 12, 9000. https://doi.org/10.3390/app12189000
Ribas D, Miguel A, Ortega A, Lleida E. Wiener Filter and Deep Neural Networks: A Well-Balanced Pair for Speech Enhancement. Applied Sciences. 2022; 12(18):9000. https://doi.org/10.3390/app12189000
Chicago/Turabian StyleRibas, Dayana, Antonio Miguel, Alfonso Ortega, and Eduardo Lleida. 2022. "Wiener Filter and Deep Neural Networks: A Well-Balanced Pair for Speech Enhancement" Applied Sciences 12, no. 18: 9000. https://doi.org/10.3390/app12189000
APA StyleRibas, D., Miguel, A., Ortega, A., & Lleida, E. (2022). Wiener Filter and Deep Neural Networks: A Well-Balanced Pair for Speech Enhancement. Applied Sciences, 12(18), 9000. https://doi.org/10.3390/app12189000